↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Trojan attacks on deep learning models pose a significant threat. Existing detection methods often fail against sophisticated attacks or require substantial training data. This paper introduces a novel method called TRODO that addresses these limitations. TRODO searches for ‘blind spots’ in trojaned classifiers—regions where the model misclassifies out-of-distribution samples as in-distribution ones.
TRODO identifies these blind spots by adversarially perturbing out-of-distribution samples towards in-distribution. This approach is agnostic to the type of trojan attack and label mapping. Experimental results demonstrate high accuracy across various datasets and attack scenarios, even when training data is limited or unavailable. This work significantly contributes to the field by providing a robust and generalizable approach to detecting trojaned models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on the security and reliability of deep learning models. It introduces a novel, generalizable method for detecting trojaned classifiers, a significant threat to the widespread adoption of AI. The adaptability of the method across various attack scenarios and its performance even with limited data make it highly relevant to current research trends and pave the way for further research on improving AI security.
Visual Insights#

This figure illustrates the TRODO method. Part A shows how near-OOD samples are generated from a small set of benign training samples using harsh augmentations. Part B shows how the ID-Score difference (AID-Score) is calculated for OOD samples before and after an adversarial attack. The AID-Score serves as a signature to differentiate between clean and trojaned classifiers. Clean classifiers show little change in ID-Score after the attack due to the lack of blind spots, while trojaned classifiers show a significant increase due to the presence of blind spots.
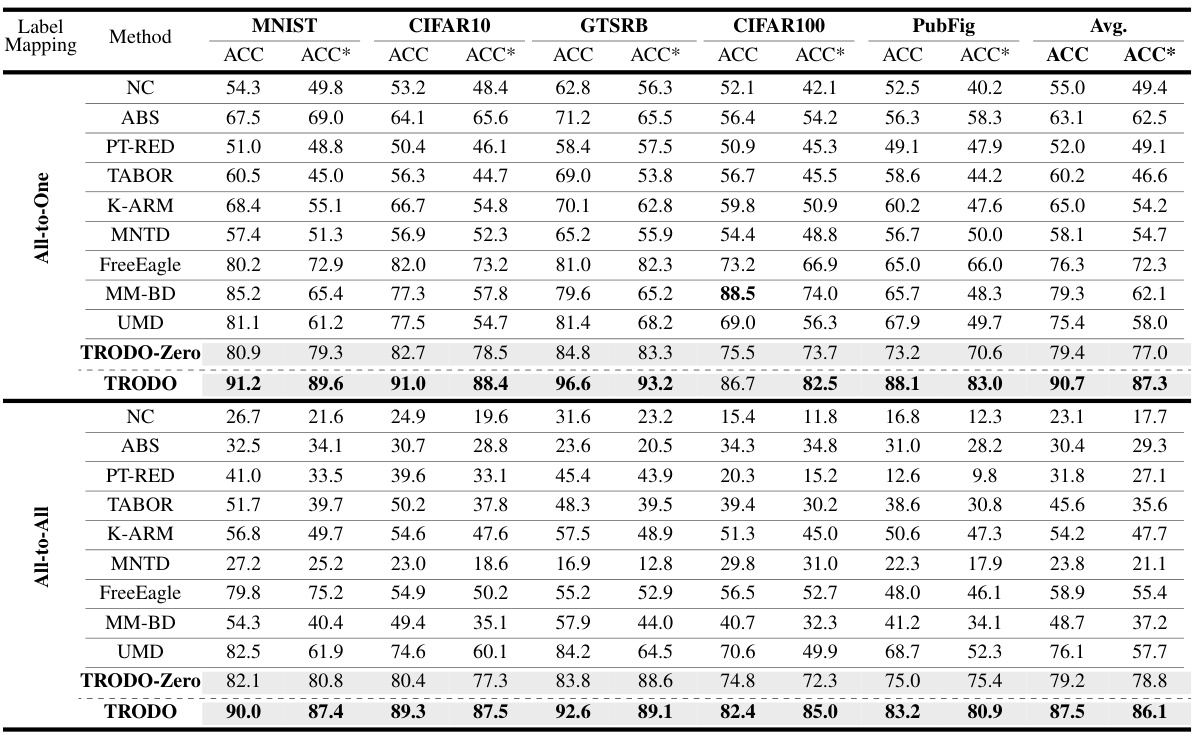
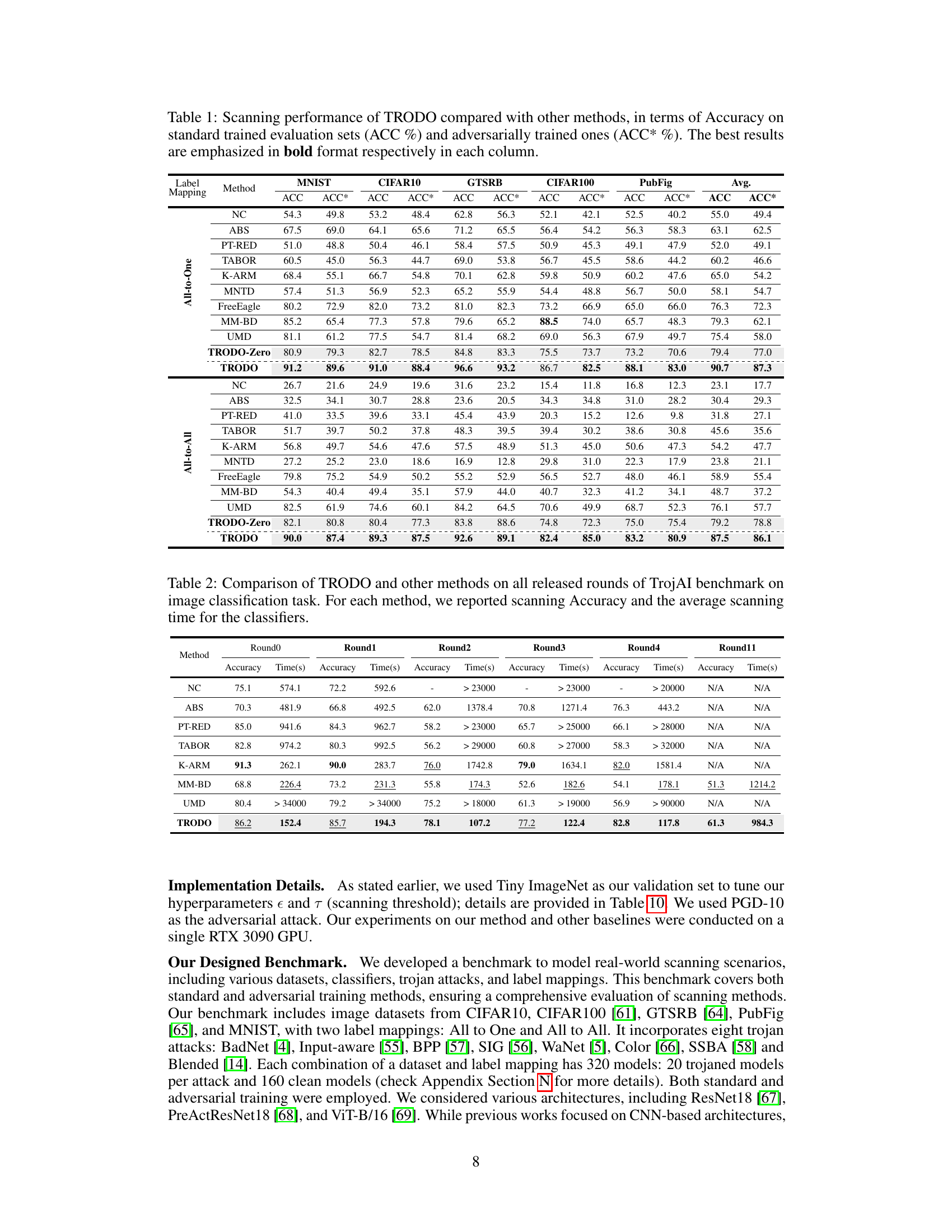
This table presents a comparison of the accuracy of the proposed TRODO method against several other state-of-the-art trojan detection methods. The accuracy is measured on two types of datasets: standard trained models (ACC) and adversarially trained models (ACC*). The results are presented for different label mapping strategies (all-to-one and all-to-all) across multiple datasets (MNIST, CIFAR-10, GTSRB, CIFAR-100, and PubFig). The table allows readers to assess the performance of TRODO against existing methods under various conditions.
In-depth insights#
Trojaned Model Scan#
Trojaned model scanning is a critical area of research focusing on detecting malicious backdoors in machine learning models. Current methods often rely on specific trigger patterns or label mappings, limiting their generalizability and effectiveness against sophisticated attacks. A key challenge is identifying trojans in models trained adversarially, as standard methods fail to detect these subtle manipulations. Ideally, a robust scanning technique should be trigger-agnostic and effective regardless of the adversarial training process, potentially leveraging out-of-distribution (OOD) samples for detection. Research into robust OOD detection methods is crucial to detect these blind spots, where trojaned classifiers misclassify OOD samples as in-distribution. This innovative approach promises a more effective and generalized method for protecting machine learning systems from malicious backdoors.
OOD Adversarial Shift#
The concept of “OOD Adversarial Shift” in the context of trojaned model detection is a fascinating one. It leverages the observation that trojaned models often misclassify out-of-distribution (OOD) samples as in-distribution (ID), creating what the authors term “blind spots”. The core idea is to adversarially perturb OOD samples to force the trojaned model to misclassify them. This adversarial shift is used as a distinguishing feature to detect the presence of trojans, as clean models would be less susceptible to this type of manipulation. The success of this approach relies on the distortion of the decision boundary induced by the backdoor, creating regions where OOD samples are erroneously classified as ID. The approach’s strength lies in its agnosticism towards both the specific backdoor attack and the label mapping, and its ability to detect even adversarially trained trojaned models.
TRODO Algorithm#
The TRODO algorithm presents a novel approach to detecting trojaned models in deep neural networks by leveraging out-of-distribution (OOD) samples. Its core innovation lies in identifying “blind spots” within trojaned models, regions where the model misclassifies OOD samples as in-distribution (ID). The algorithm cleverly uses adversarial attacks to perturb OOD samples, pushing them towards these blind spots, thus revealing the model’s susceptibility. This approach is significant because it is both trojan-agnostic and label-mapping agnostic, meaning it is effective against various trojan attack methodologies regardless of how labels are manipulated. Furthermore, its high accuracy and adaptability across different datasets makes it a robust and generalizable solution. Importantly, TRODO doesn’t require training data, demonstrating its practicality in real-world scenarios where access to training data is limited or impossible. The use of adversarial perturbations to highlight these blind spots provides a distinctive signature for identifying trojaned models, which is a unique and powerful contribution of this approach.
Adaptive Attacks#
The section on “Adaptive Attacks” would explore how adversaries might respond to the proposed TRODO method. It’s crucial to assess the robustness of TRODO against attackers who can adapt their strategies. Two key approaches are likely described: one focusing on modifying the classifier’s loss function to minimize the difference in ID-scores between in-distribution (ID) and out-of-distribution (OOD) samples. This aims to reduce the effectiveness of TRODO’s signature. The second approach likely manipulates the ID-Score difference itself by creating a loss function that tries to reduce this difference between perturbed and unperturbed OOD samples, making the signature less discriminative. The discussion would analyze the effectiveness of TRODO against these adaptive attacks and likely highlight that the randomness of transformations in generating OOD samples provides a degree of resilience against such adaptive strategies. Near-OOD samples are likely to remain more vulnerable, even under adaptive attack, due to their proximity to the decision boundary. This section’s analysis, therefore, provides a critical evaluation of TRODO’s limitations and potential vulnerabilities.
Future Works#
Future work could explore extending TRODO’s capabilities to encompass a wider range of model architectures and attack types beyond those evaluated in the study. Investigating the effectiveness of TRODO on resource-constrained environments would also be valuable. A particularly interesting area for further investigation would be developing more sophisticated adversarial attack strategies against TRODO itself, to assess its robustness and identify potential vulnerabilities. Furthermore, exploring the integration of TRODO with other defense mechanisms could result in a more comprehensive and effective trojan detection system. Finally, a quantitative analysis comparing the computational cost and detection accuracy of TRODO with existing methods would provide valuable insights into its practical applicability.
More visual insights#
More on figures

This figure illustrates the effectiveness of using near-OOD samples in TRODO. It shows that adversarially perturbing near-OOD samples (visually similar to in-distribution but from a different distribution) results in a much larger increase in their ID-Score (likelihood of being classified as in-distribution) in a trojaned model compared to a clean model. This is because the trojaned model has ‘blind spots’ – regions where it mistakenly classifies OOD samples as ID – and near-OOD samples are closer to these blind spots. The difference in ID-Score before and after adversarial perturbation serves as a robust signature to distinguish trojaned and clean models. The histograms and 3D visualizations of decision boundaries further clarify this concept.
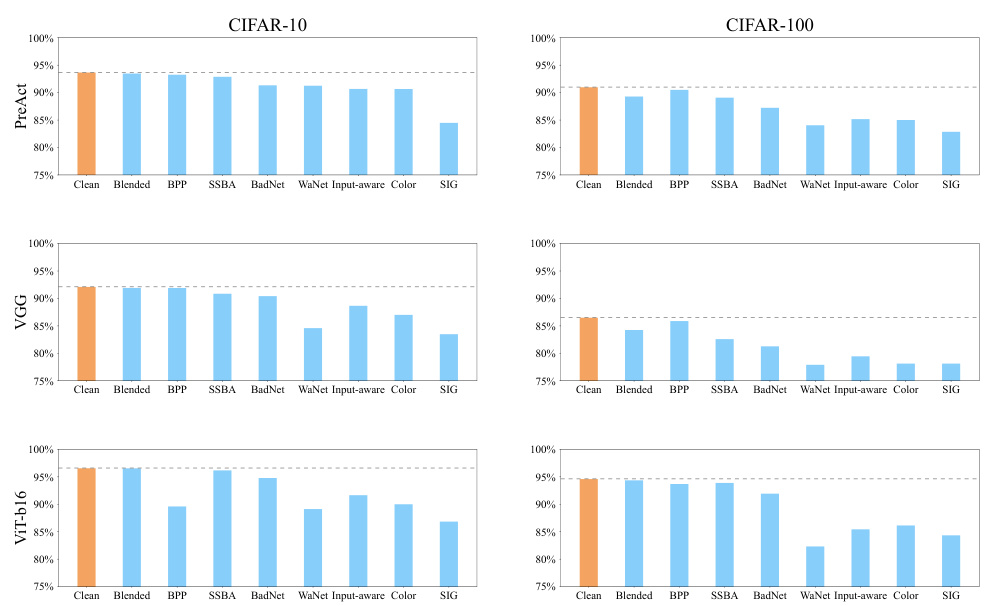
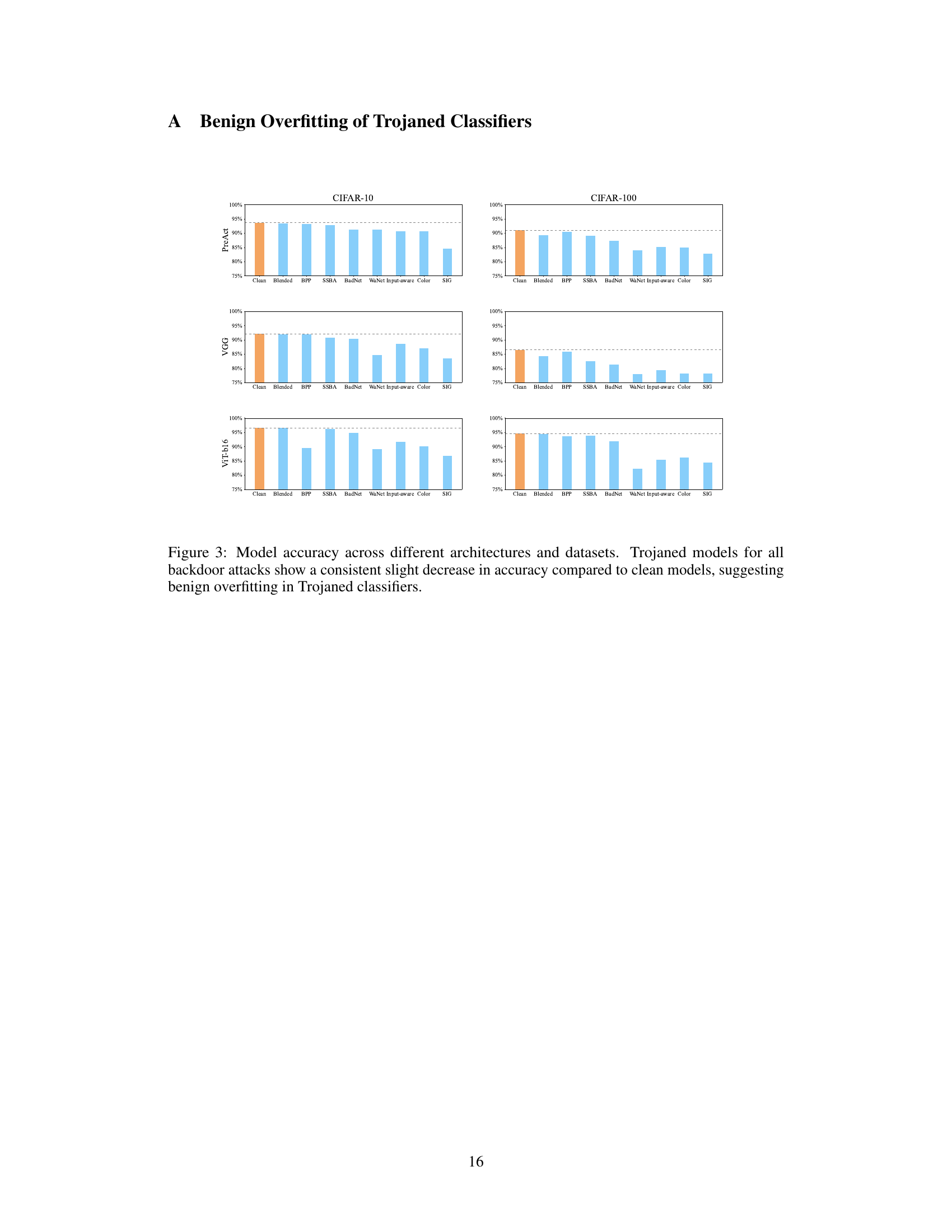
This figure displays the test accuracy for clean and trojaned models across various datasets (CIFAR-10, CIFAR-100) and model architectures (ResNet18, PreActResNet18, VGG, ViT-b16). Each bar represents the average accuracy of multiple models trained with a specific backdoor attack. The figure illustrates the concept of ‘benign overfitting,’ where trojaned models maintain high accuracy on clean data despite the presence of a backdoor. The small accuracy difference between clean and trojaned models supports the claim that the backdoor’s impact is subtle, making it difficult to detect using traditional methods. This subtle change serves as an indicator of malicious functionality within the model.
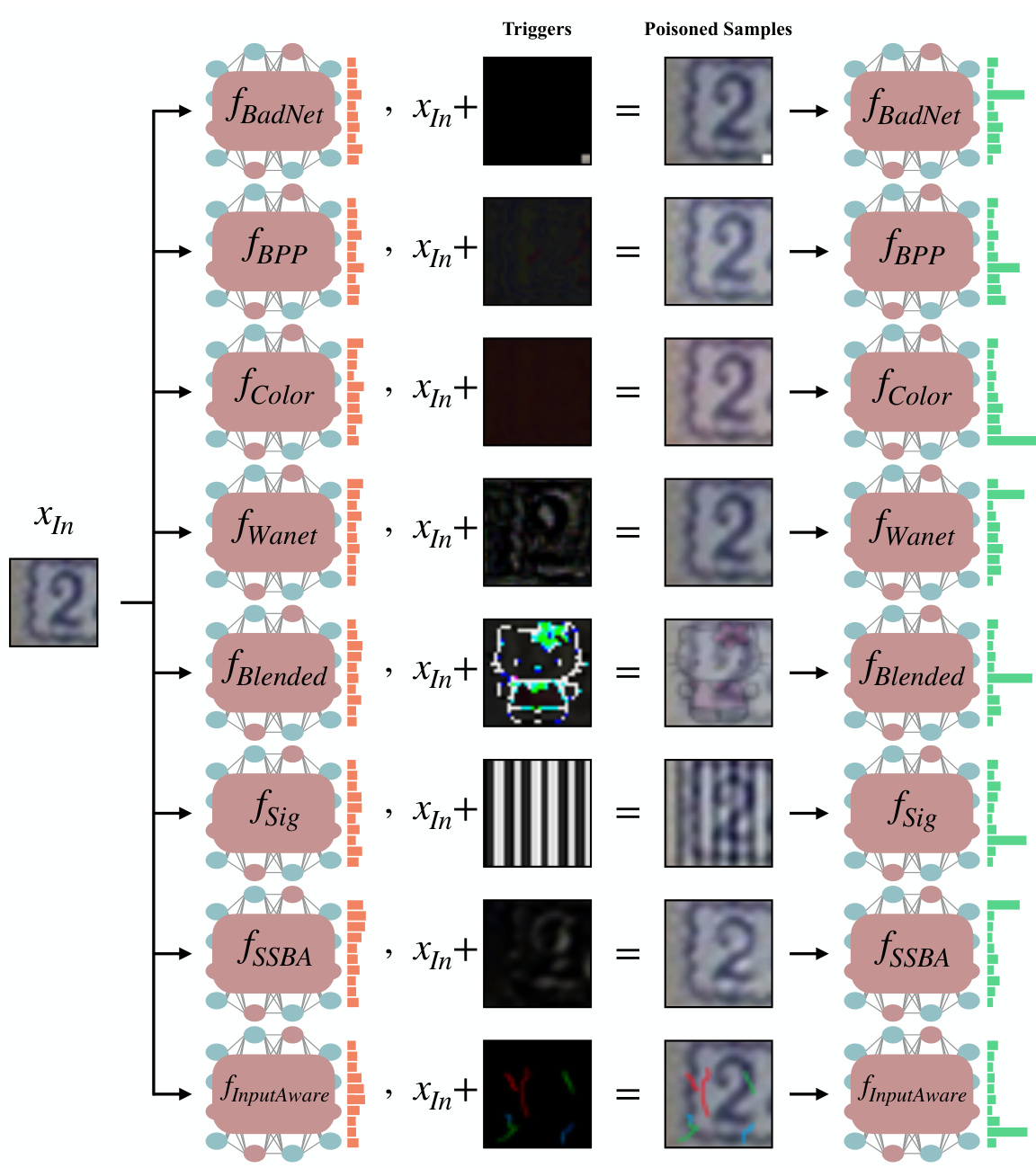
This figure shows the impact of applying trojan triggers to out-of-distribution (OOD) samples. It demonstrates that even when triggers are applied to samples far from the training data distribution, the trojaned model misclassifies them as in-distribution (ID) samples. This is attributed to the phenomenon of ‘benign overfitting’ in the trojaned model, where the model has learned to overfit to the specific trigger patterns.
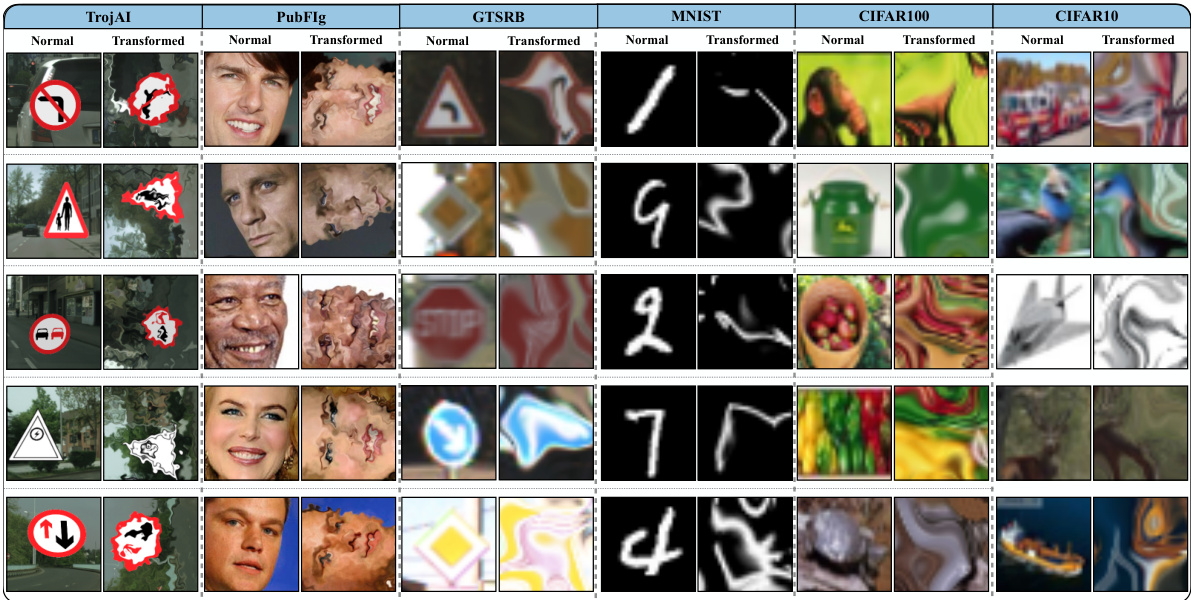
This figure visually demonstrates the concept of near-OOD samples. It shows examples of in-distribution (ID) samples from various datasets (TrojAI, PubFig, GTSRB, MNIST, CIFAR100, CIFAR10) alongside their corresponding near-OOD samples. The near-OOD samples are generated by applying transformations such as elastic deformation, random rotations, and cutpaste to the original ID samples. These transformations alter the image characteristics while maintaining some visual similarity to the original ID samples, making them suitable for probing the ‘blind spots’ of trojaned classifiers. The figure highlights the effectiveness of using near-OOD samples to identify trojaned classifiers as they are more susceptible to misclassification.
More on tables
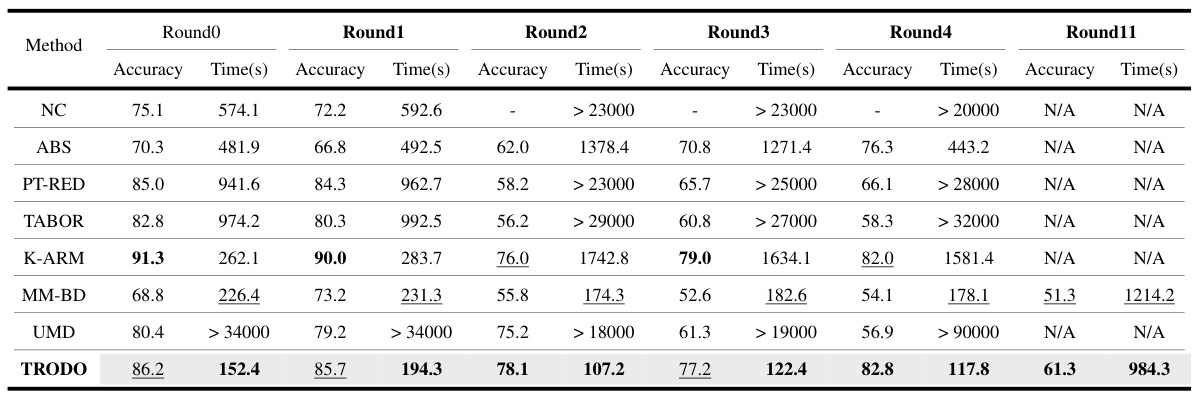
This table compares the performance of TRODO against other state-of-the-art trojan detection methods on the TrojAI benchmark dataset. It shows the accuracy and average scanning time for each method across multiple rounds of the benchmark, highlighting TRODO’s competitive performance in terms of both accuracy and efficiency.
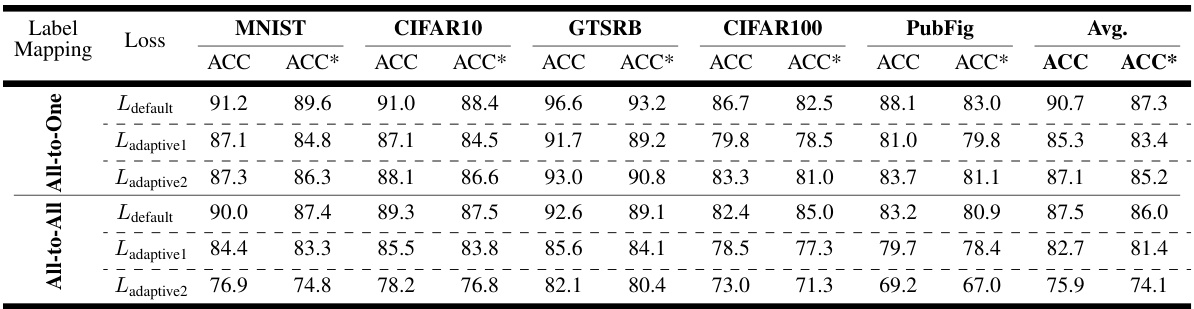
This table presents a comparison of the proposed TRODO method with other state-of-the-art trojan detection methods. The comparison is done across various datasets (MNIST, CIFAR10, GTSRB, CIFAR100, PubFig) and for two types of label mappings (All-to-One and All-to-All). Accuracy is reported for both standard and adversarially trained models, allowing for a comprehensive evaluation of performance under different training regimes and attack scenarios. The best accuracy for each scenario (standard and adversarial) is highlighted in bold.

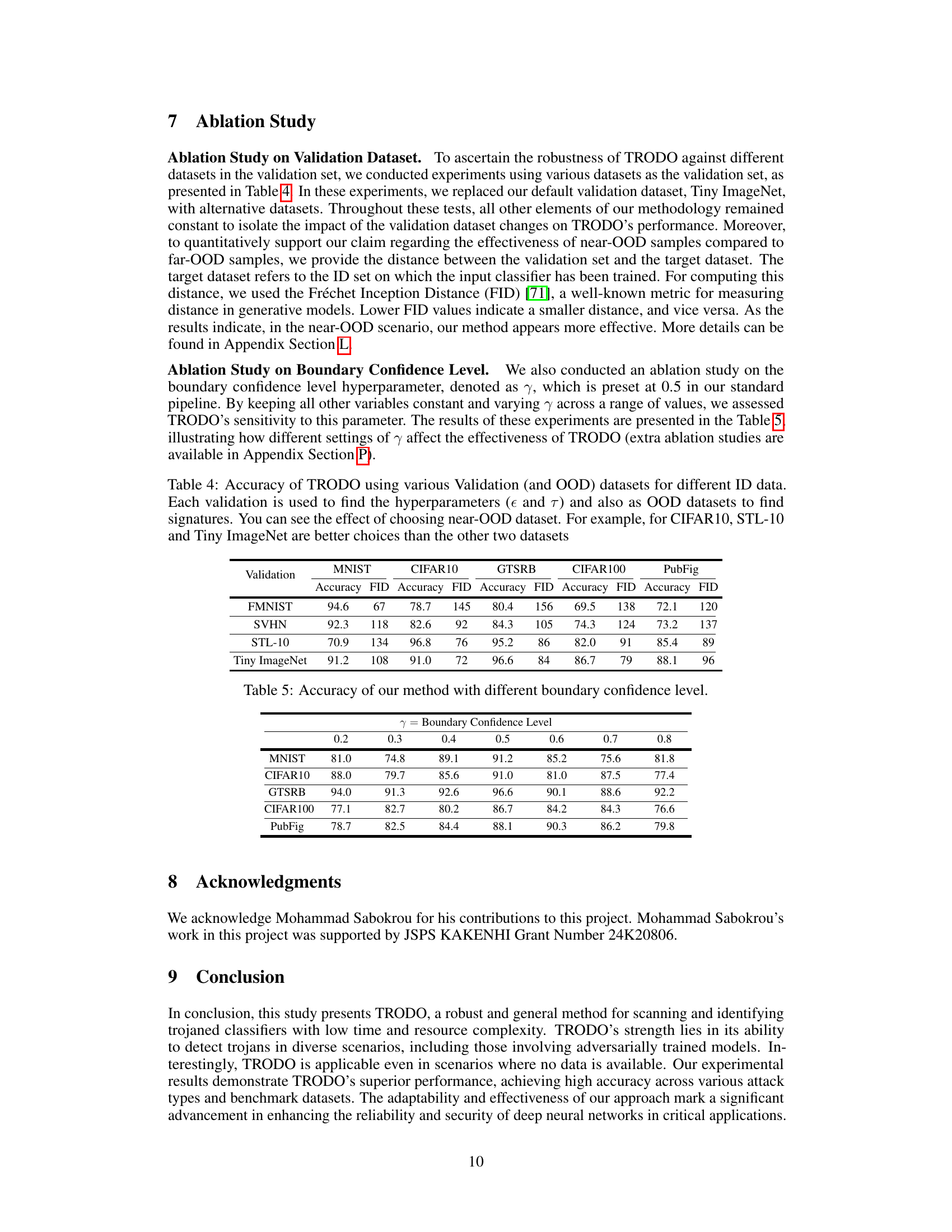
This table presents the accuracy of the TRODO model when using different validation datasets. It demonstrates how the choice of validation dataset (which is also used to create the OOD samples) impacts the accuracy of the model. The Fréchet Inception Distance (FID) is included to show how visually similar the validation dataset is to the training data (ID); lower FID values indicate higher visual similarity. The table suggests that using validation sets which are visually similar to the training data, but not drawn from the same distribution, leads to better performance of TRODO.
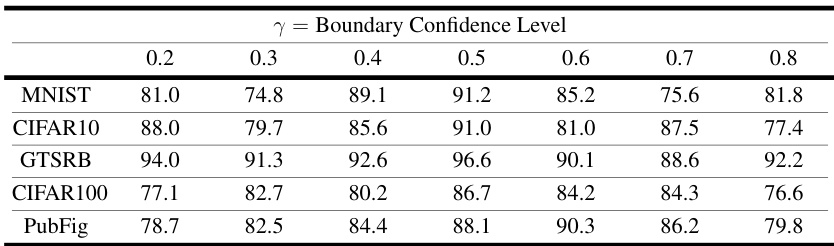
This table presents the results of an ablation study conducted to evaluate the impact of varying the boundary confidence level (γ) on the performance of TRODO. The boundary confidence level is a hyperparameter in TRODO that influences the sensitivity of the method. The table shows the accuracy achieved by TRODO across five different datasets (MNIST, CIFAR10, GTSRB, CIFAR100, PubFig) for different values of γ (0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8). By comparing the accuracy values across different γ values for each dataset, one can gain insights into the optimal value of γ for TRODO, as well as TRODO’s sensitivity to this hyperparameter.
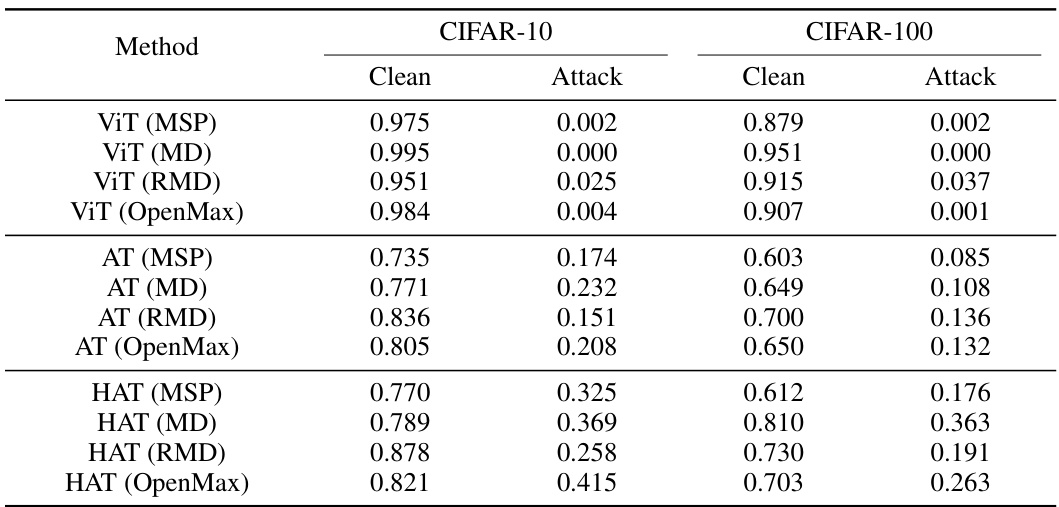
This table presents the Area Under the Receiver Operating Characteristic Curve (AUROC) for Out-of-Distribution (OOD) detection using various methods. It compares the performance of different OOD detection methods (ViT, AT, HAT, with variations in scoring methods like MSP, MD, RMD, and OpenMax) under both clean and attacked conditions. The table shows how the AUROC changes when the test data is perturbed with adversarial noise (Attack) compared to when it’s not (Clean). The results are shown for two datasets, CIFAR-10 and CIFAR-100, demonstrating the robustness (or lack thereof) of these OOD detection methods against adversarial attacks.

This table presents the accuracy of the proposed TRODO method in detecting various backdoor attacks on models with ResNet18 architecture. Each row represents a specific type of backdoor attack, and the columns show the accuracy on different datasets (CIFAR10, MNIST, GTSRB, CIFAR100, PubFig). The key finding is that TRODO achieves high accuracy in detecting trojaned models across all datasets and different backdoor attacks.

This table compares the performance of TRODO against several state-of-the-art trojan detection methods. The accuracy is measured on standard and adversarially trained models, across several datasets (MNIST, CIFAR-10, GTSRB, CIFAR-100, PubFig) and two label mapping strategies (All-to-One, All-to-All). The best results for each dataset and training type are highlighted in bold.

This table presents a comparison of the proposed TRODO method against several state-of-the-art trojan detection methods. The accuracy of each method is evaluated on two sets of data: standard trained (ACC) and adversarially trained (ACC*). The table shows the accuracy for each method across five different datasets (MNIST, CIFAR10, GTSRB, CIFAR100, PubFig), and the average accuracy across all datasets is also provided. The best performing method for each dataset and attack type is highlighted in bold. This allows for a comprehensive comparison of the effectiveness of TRODO in various scenarios and datasets.
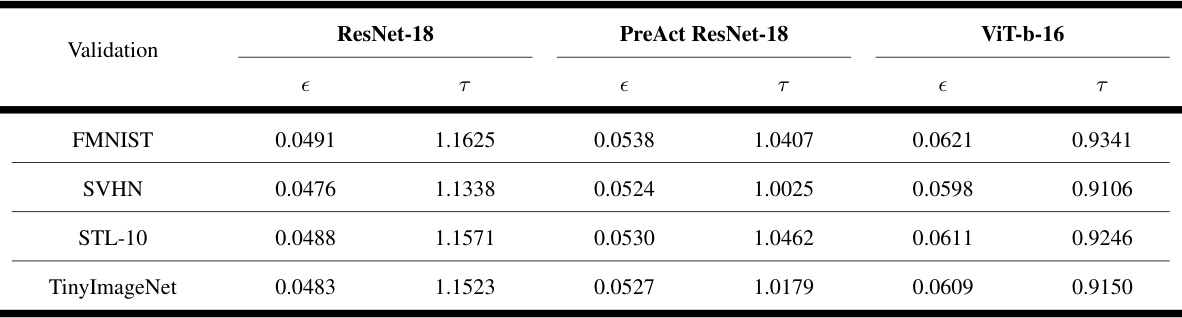
This table shows the values of two hyperparameters, epsilon (e) and tau (τ), used in the TRODO algorithm. Epsilon controls the size of adversarial perturbations, while tau is a threshold used to determine if a classifier is trojaned based on the ID-score difference. The table presents these values for four different validation datasets (FMNIST, SVHN, STL-10, and TinyImageNet) and three different network architectures (ResNet-18, PreAct ResNet-18, and ViT-b-16). These values were determined empirically using each validation set to tune the parameters for the corresponding architecture.

This table presents a comparison of the proposed TRODO method against several state-of-the-art trojan detection methods. The comparison is made across different datasets (MNIST, CIFAR10, GTSRB, CIFAR100, PubFig) and two scenarios: standard training and adversarial training. The accuracy of each method is reported for both scenarios, allowing for a comprehensive evaluation of their performance in various settings. The table highlights the superior performance of TRODO in most cases, especially when the trojaned models are also adversarially trained.

This table presents a comparison of the proposed TRODO method against existing state-of-the-art trojan detection methods across various datasets and label mappings. It shows the accuracy of each method on both standard and adversarially trained models, highlighting TRODO’s superior performance, especially when dealing with adversarially trained models.

This table presents the performance of the TRODO-Zero model under varying OOD sample rates across different datasets. The performance is measured in terms of accuracy (ACC) and adversarially trained accuracy (ACC*) for each dataset (MNIST, CIFAR10, GTSRB, CIFAR100, PubFig). The average accuracy across all datasets is also reported for each OOD sample rate. Different sample rates (0.1%, 0.2%, 0.3%, 0.5%, and 1%) are evaluated to analyze the impact of the amount of OOD data on the model’s performance. The table is part of an ablation study to understand how the size of OOD samples affects the model.
Full paper#