↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) face memory limitations due to the increasing size of the key-value (KV) cache, especially when dealing with long sequences and large batches. This restricts the potential of LLMs and makes it difficult to train and deploy more powerful models. Prior work focused on modifying attention mechanisms (Multi-Query Attention, Grouped-Query Attention) to reduce KV cache size.
This paper proposes Cross-Layer Attention (CLA), a novel method that further reduces KV cache size by sharing key and value activations across adjacent layers in the Transformer architecture. Experiments using 1B and 3B parameter models showed that CLA, combined with MQA, achieves a 2x reduction in KV cache size while maintaining almost the same accuracy. CLA provides a Pareto improvement over existing methods, offering better memory-accuracy trade-offs and enabling future models to handle longer sequences and larger batches.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical issue of memory limitations in large language models (LLMs), a significant bottleneck hindering the development of more powerful and efficient models. By introducing a novel method for reducing KV cache size, this research directly contributes to improving the scalability and efficiency of LLMs, thus enabling the development of models that can handle longer sequences and larger batch sizes. This has significant implications for various applications of LLMs, making the research relevant to a wide range of researchers. The findings also open up new avenues for further research into memory-efficient attention mechanisms and improving overall model performance.
Visual Insights#

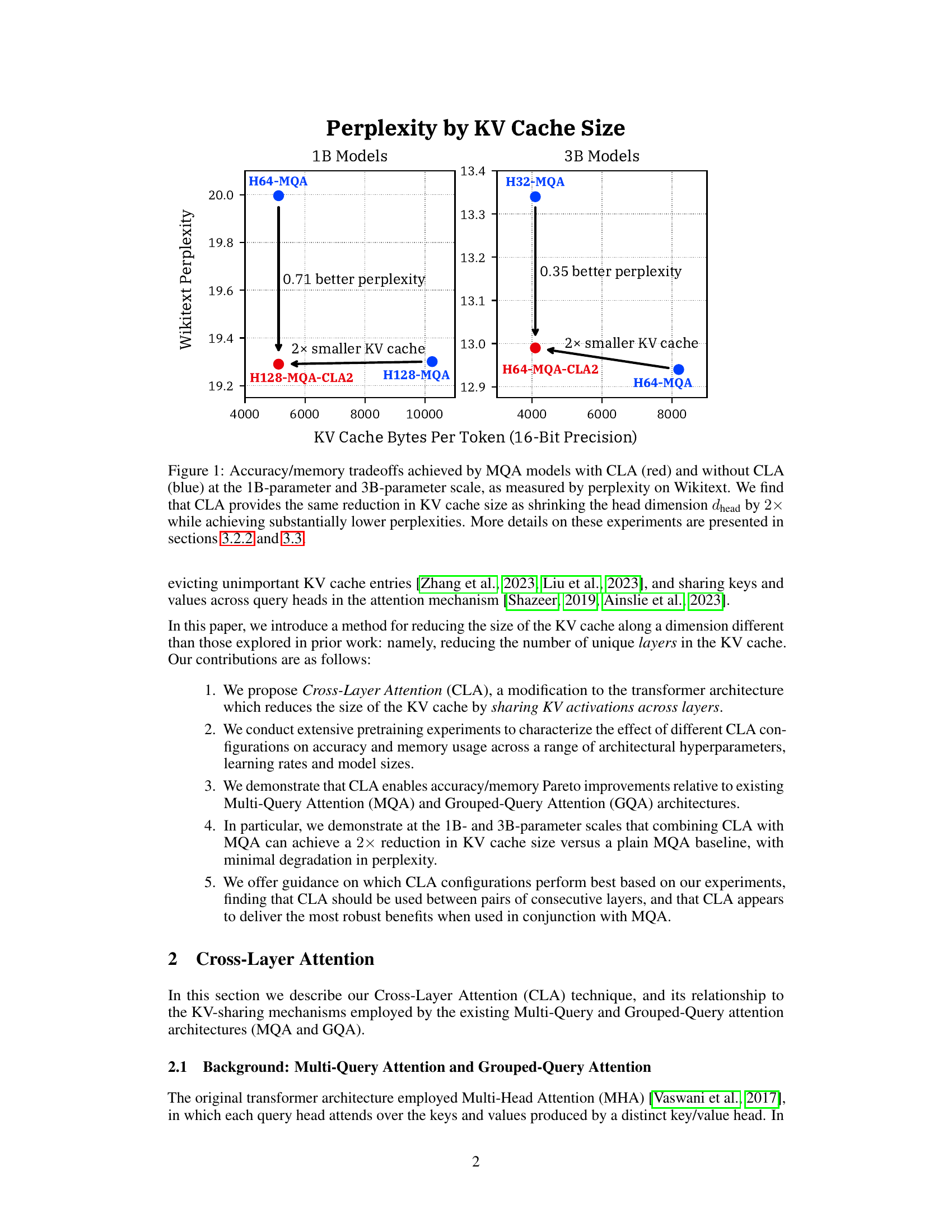
This figure shows the accuracy vs. memory trade-off curves for different model sizes (1B and 3B parameters) using Multi-Query Attention (MQA) with and without Cross-Layer Attention (CLA). The x-axis represents the KV cache size (bytes per token), and the y-axis shows the perplexity on the Wikitext dataset, a measure of model accuracy. The red points represent models using CLA, which achieves a 2x reduction in KV cache size compared to the blue MQA-only models while maintaining similar or even better perplexity. This demonstrates that CLA provides a Pareto improvement over traditional MQA in terms of memory and accuracy.
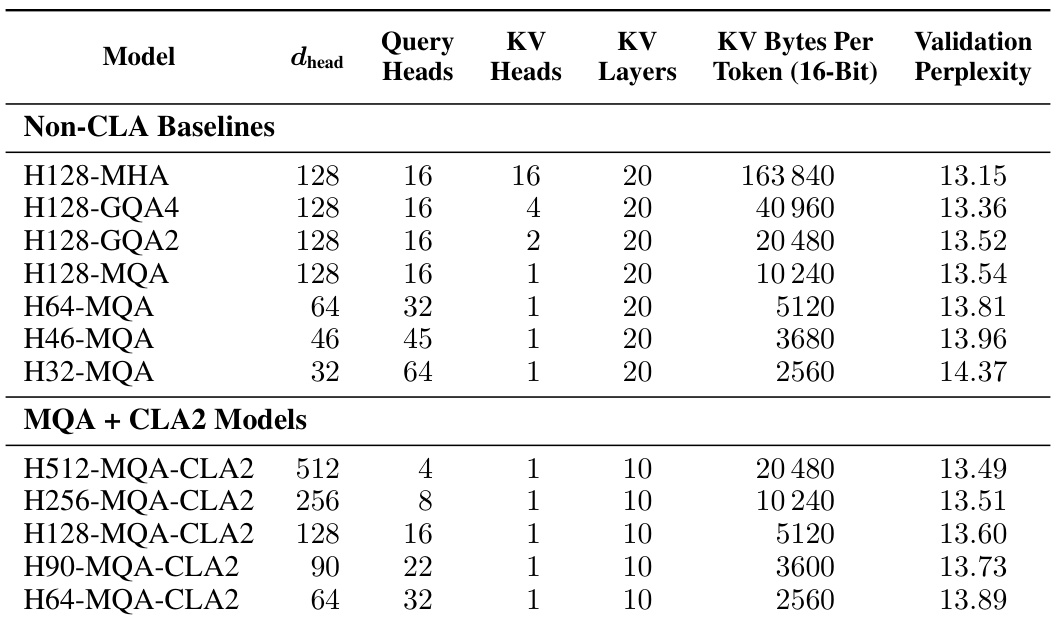
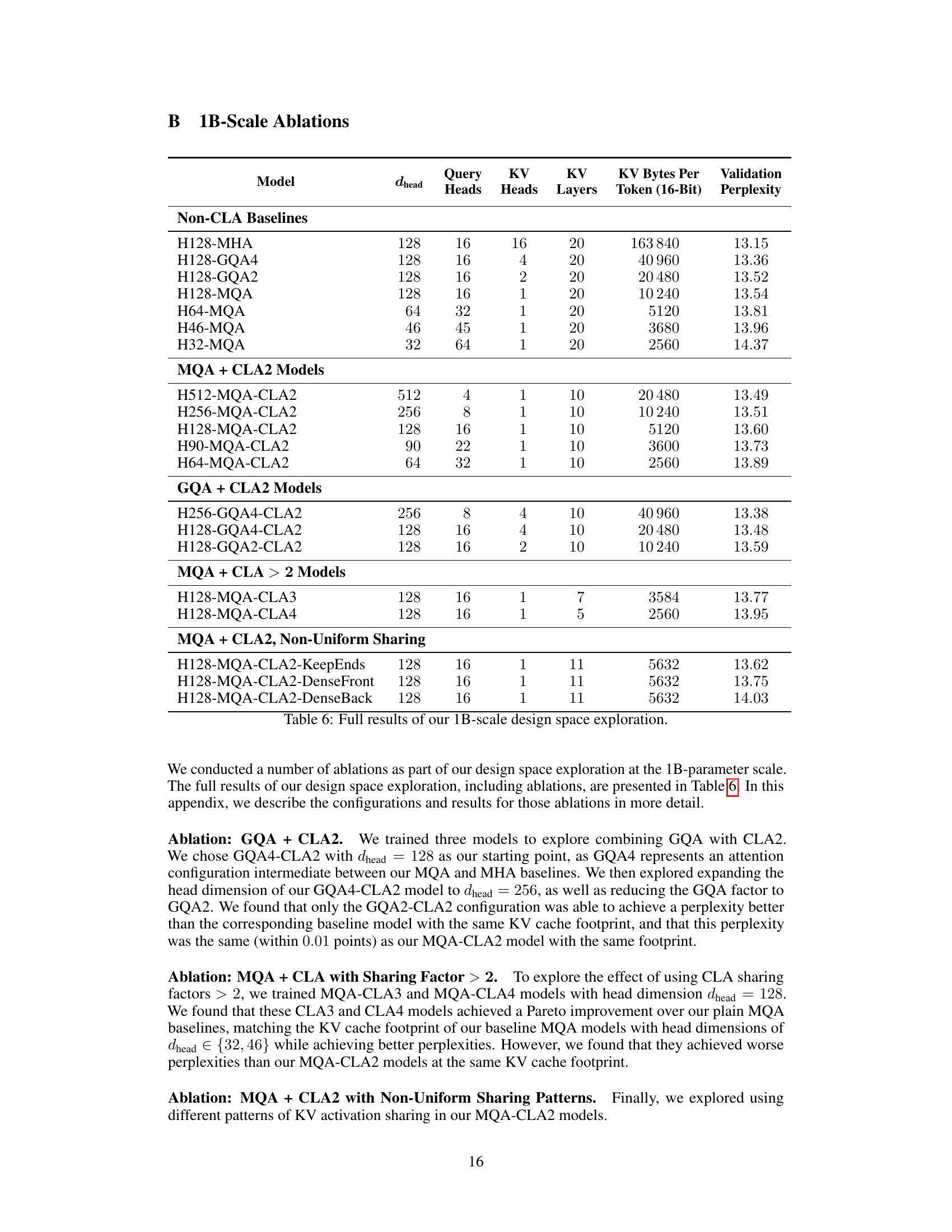
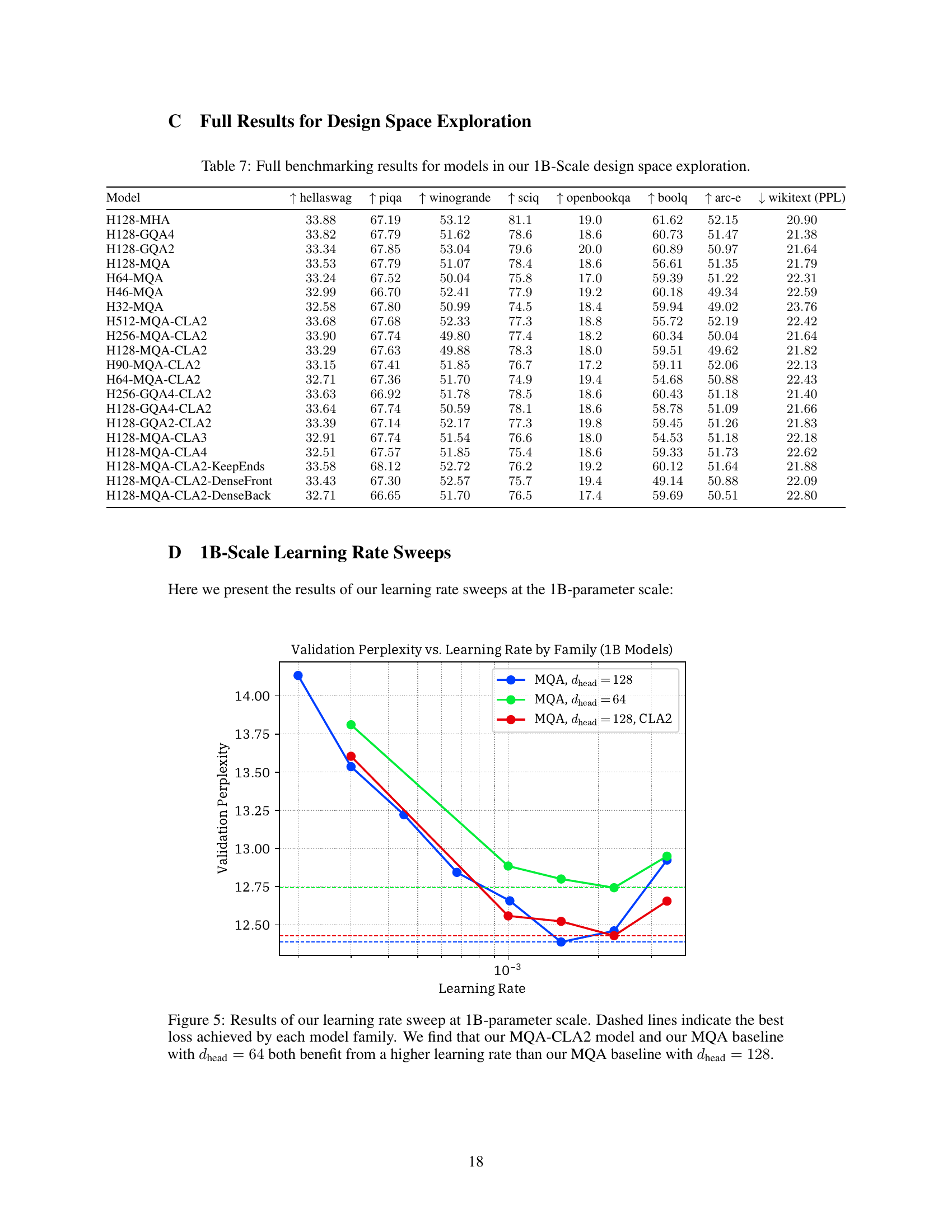
This table presents the results of design space exploration for 1B parameter models. It shows various model configurations using different attention mechanisms (MHA, GQA, MQA) with and without Cross-Layer Attention (CLA). The table lists the hyperparameters used for each model, such as head dimension (‘dhead’), number of query heads, number of KV heads, number of layers, KV bytes per token, and the resulting validation perplexity. The models are categorized into Non-CLA baselines and MQA+CLA2 models. The Appendix B contains more details and ablation studies.
In-depth insights#
Cross-Layer Attention#
The proposed Cross-Layer Attention (CLA) mechanism offers a novel approach to optimize transformer models by reducing the key-value (KV) cache size. Unlike existing methods like Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) that focus on sharing KV heads within a layer, CLA innovatively shares KV activations across adjacent layers. This strategy significantly reduces the memory footprint, potentially enabling the training and deployment of larger models or those handling longer sequences. The effectiveness of CLA is empirically validated through extensive experiments, demonstrating Pareto improvements in the memory-accuracy tradeoff compared to traditional MQA. CLA’s orthogonality to other KV-sharing techniques allows for further optimization by combining it with MQA/GQA. However, the paper acknowledges potential limitations related to the impact of CLA on other aspects of model performance and system-level efficiency. Further research is suggested to explore the full potential of CLA for various architectural hyperparameters and its broader system-level effects.
KV Cache Reduction#
Reducing the key-value (KV) cache size in large language models (LLMs) is crucial for efficient decoding, especially when dealing with long sequences. Multi-Query Attention (MQA) and its generalization, Grouped-Query Attention (GQA), have proven effective in reducing KV cache size by allowing multiple query heads to share a single key-value head. However, further optimizations are needed. This paper introduces Cross-Layer Attention (CLA), a novel technique that shares key and value heads across adjacent layers, leading to a significant reduction in KV cache size with minimal impact on accuracy. CLA is orthogonal to MQA/GQA and can be used in conjunction with them for further memory reduction, showing a clear Pareto improvement in the accuracy-memory tradeoff. Experimental results demonstrate the effectiveness of CLA across different model sizes. The implications of CLA extend to enabling models to operate with longer sequences and larger batch sizes than previously possible, thus significantly enhancing the efficiency and scalability of LLMs.
Pareto Frontier Shift#
A Pareto frontier shift in the context of a research paper signifies a significant advancement where a new method or technique outperforms existing approaches. It suggests a novel solution that improves performance across multiple metrics simultaneously. In the realm of large language models (LLMs), a Pareto frontier shift could represent a breakthrough in balancing model performance (e.g., accuracy measured by perplexity) with resource efficiency (e.g., memory consumption). Specifically, a paper demonstrating a Pareto frontier shift for LLMs might highlight a novel method that drastically reduces memory usage without sacrificing accuracy or even improving it. This is a highly desirable outcome, as memory constraints are major bottlenecks in deploying and scaling large LLMs. This improvement would often be achieved by carefully optimizing model architecture and/or attention mechanisms, for instance through more efficient key-value caching strategies. The existence of such a shift would imply that the proposed method provides a clear advantage over state-of-the-art techniques, offering a more favorable trade-off between accuracy and resource efficiency.
Ablation Studies#
Ablation studies systematically remove components of a model or system to understand their individual contributions. In the context of a research paper, a well-designed ablation study would involve carefully removing key aspects of the proposed method (e.g., cross-layer attention, specific hyperparameter choices) and measuring the impact on performance. The goal is to isolate the effect of each component, determining which are crucial for success and which can be removed without significant loss. A strong ablation study will consider a range of variations, demonstrating the robustness of the key findings. By comparing performance against baselines (e.g., models without the proposed innovations) and models with different configurations, a comprehensive ablation study helps quantify the benefits of each individual contribution, and the overall effectiveness of the proposed system. Such analysis can uncover unexpected interactions between elements, highlighting the nuanced aspects of the approach and leading to a deeper understanding of why and how it works.
Future Work#
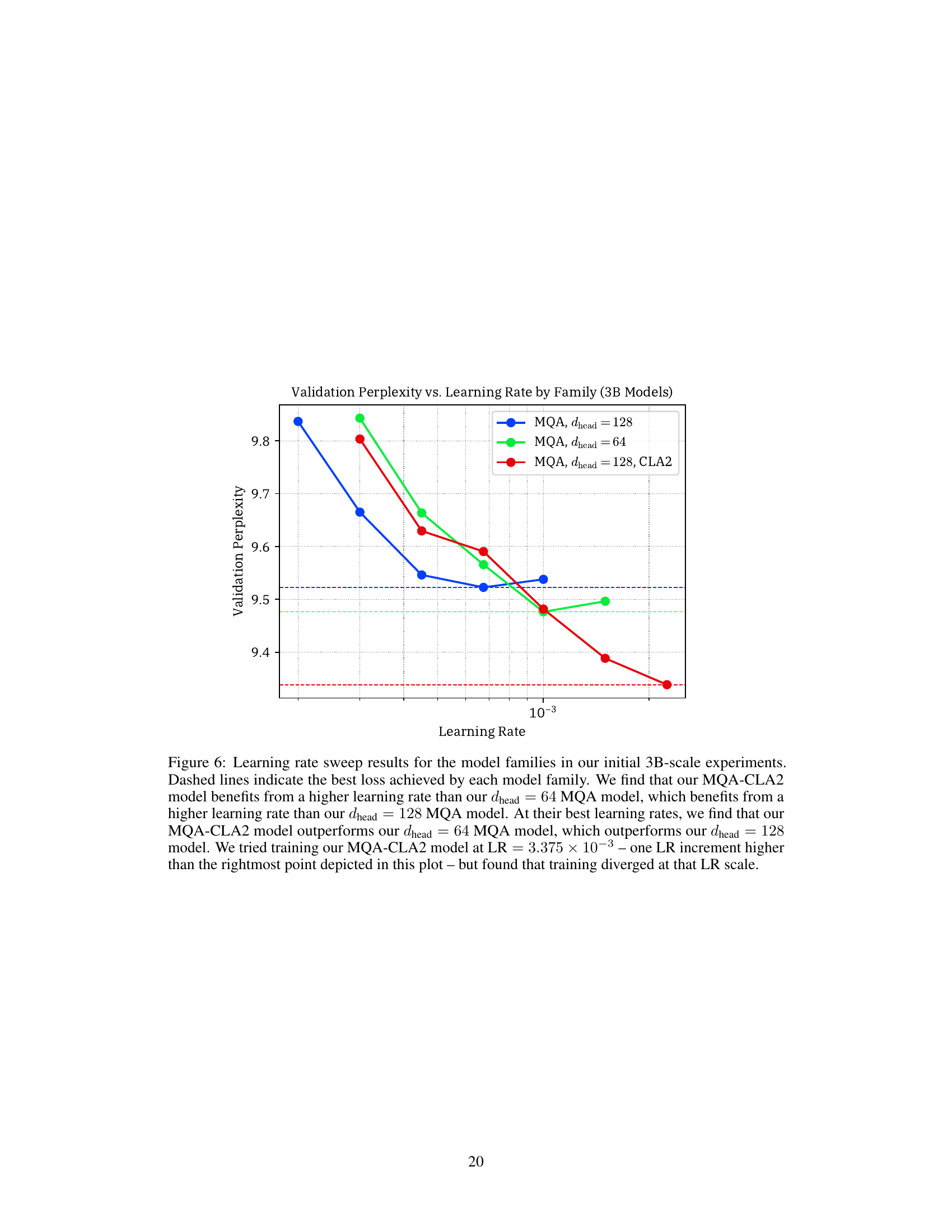
The paper’s “Future Work” section hints at several promising avenues of research. Extending CLA to larger LLMs and evaluating its impact on efficiency at scale is a crucial next step. Investigating the integration of CLA with other KV optimization techniques (low-precision storage, eviction strategies) could lead to synergistic improvements. Furthermore, systematic exploration of different CLA configurations beyond those tested (varying sharing factors, layer selection patterns) could reveal more efficient architectures. Finally, comparing CLA to other non-softmax attention mechanisms is needed to assess its relative strengths and limitations across different language modeling paradigms. These investigations would provide a more comprehensive understanding of CLA’s potential and limitations in various LLM contexts.
More visual insights#
More on figures

This figure illustrates the difference between traditional transformer architecture and the proposed Cross-Layer Attention (CLA) architecture. The left side shows the traditional design where each layer independently calculates and stores key (K) and value (V) activations in the KV cache, resulting in high memory consumption. The right side demonstrates the CLA approach, where some layers reuse the K and V activations from previous layers, thereby reducing the size of the KV cache and improving memory efficiency.
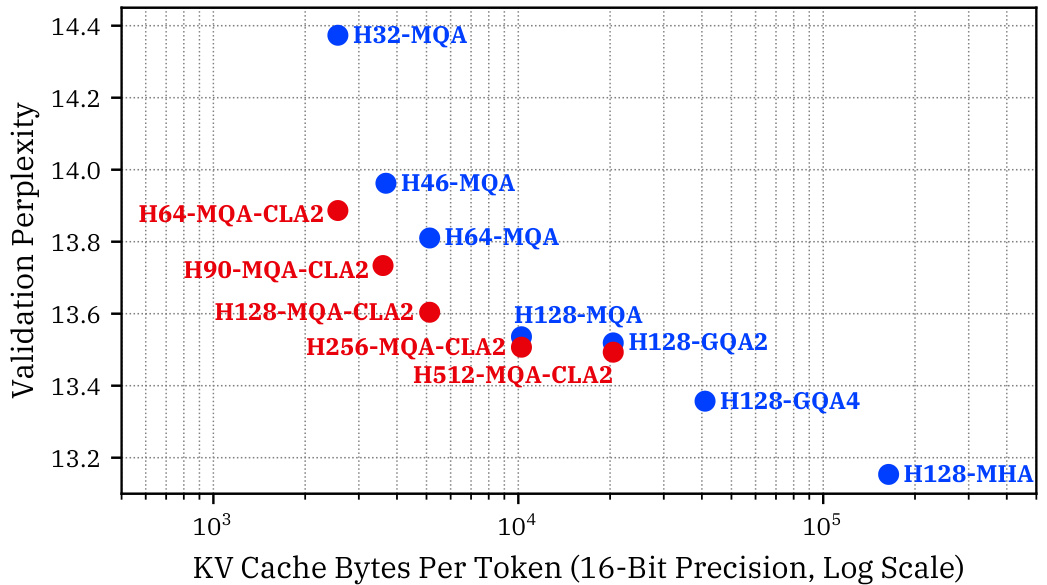
This figure shows the accuracy and memory trade-offs achieved by using multi-query attention (MQA) models with and without cross-layer attention (CLA). The x-axis represents the KV cache size (in bytes per token), and the y-axis shows the perplexity on the Wikitext dataset, a measure of model accuracy. The results demonstrate that CLA provides a comparable reduction in KV cache size as halving the head dimension while achieving significantly better perplexity (lower is better). The figure presents results for both 1B and 3B parameter models.

This figure illustrates the key-value (KV) cache memory usage differences between traditional attention mechanisms and the proposed Cross-Layer Attention (CLA) with sharing factors 2 and 3. Traditional attention has a separate KV cache for each layer, resulting in high memory consumption. CLA2 shares the KV cache between pairs of consecutive layers, while CLA3 shares it among groups of three. The figure visually demonstrates how CLA reduces memory usage by sharing KV activations across multiple layers.

This figure shows the Pareto frontier for accuracy and memory tradeoffs achieved by different language models. The x-axis represents the KV cache size per token (in 16-bit precision) and the y-axis represents the validation perplexity. The Pareto frontier is the set of models where no improvement in accuracy can be achieved without a tradeoff in memory (or vice versa). The figure demonstrates that using cross-layer attention (CLA), represented by red dots, improves upon the memory/accuracy tradeoffs obtainable without CLA (blue dots). This means that CLA models can achieve similar or better perplexity using less memory than their non-CLA counterparts.
This figure shows the Pareto frontier for the accuracy and memory trade-offs achieved by different language models. The x-axis represents the KV cache size (in bytes per token), and the y-axis shows the validation perplexity, which measures model accuracy. Models using Cross-Layer Attention (CLA) are shown in red, demonstrating improvements over traditional models (blue). Lower values on both axes are better, indicating smaller KV caches and higher accuracy. The plot highlights that CLA offers better trade-offs than traditional methods for reducing the memory size of the key-value cache.

This figure shows the accuracy and memory trade-offs achieved by using Multi-Query Attention (MQA) models with and without Cross-Layer Attention (CLA). The x-axis represents the KV cache size (in bytes per token), and the y-axis represents the perplexity on the Wikitext dataset. The results show that adding CLA to MQA leads to a reduction in KV cache size that is comparable to halving the head dimension (dhead) while maintaining or even improving perplexity. This indicates that CLA provides a Pareto improvement in terms of memory and accuracy.
This figure shows the Pareto frontier for accuracy and memory trade-offs achieved by different 1B-parameter models. The x-axis represents the KV cache size (bytes per token), and the y-axis represents the validation perplexity (lower is better, indicating higher accuracy). The red points represent models using Cross-Layer Attention (CLA), while blue points represent models without CLA. The figure demonstrates that CLA allows for models to achieve a better trade-off between accuracy and memory compared to models without CLA.
This figure shows the Pareto frontier of accuracy and memory tradeoffs for 1B parameter models, comparing models with and without Cross-Layer Attention (CLA). The x-axis represents the KV cache size (bytes per token), and the y-axis represents the validation perplexity. Points closer to the lower left corner represent better tradeoffs. Red points indicate models incorporating CLA, showing that CLA achieves comparable or better perplexity with smaller KV cache sizes, resulting in a Pareto improvement over models without CLA.

This figure shows the Pareto frontier of accuracy and memory tradeoffs achieved by the different models in the 1B parameter scale experiments. Models using Cross-Layer Attention (CLA) are shown in red and those without CLA are shown in blue. The x-axis represents KV cache size (bytes per token), and the y-axis represents validation perplexity. The plot demonstrates that CLA models achieve a better tradeoff between accuracy and memory usage compared to the non-CLA models, indicating Pareto improvement.
More on tables

This table presents the results of the design space exploration conducted on 1B parameter models. It shows the different model configurations explored, including variations in head dimension (dhead), the number of query heads and key/value heads, and the number of layers. The key metric is validation perplexity, measured on the Wikitext dataset. The table also includes the size of the KV cache in bytes per token at 16-bit precision. The full results including the ablations are available in Appendix B.
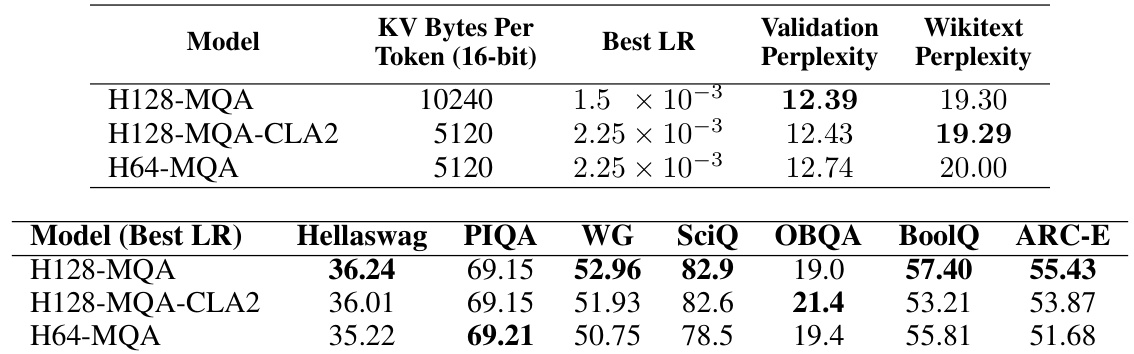
This table presents the results of design space exploration experiments conducted on 1B parameter models. It compares various model configurations (with and without CLA) across different metrics such as dhead, query heads, KV heads, layers, KV bytes per token, and validation perplexity. The table helps analyze the accuracy-memory tradeoff of different configurations and forms the basis for determining the optimal setting. Further details are provided in Appendix B.
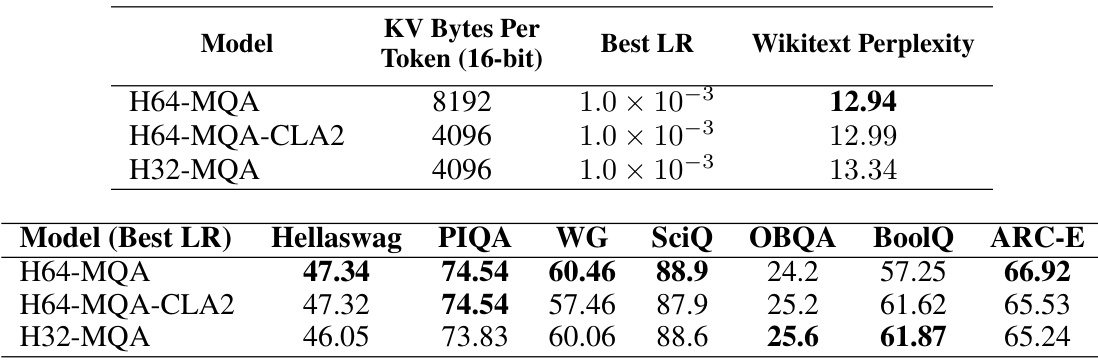
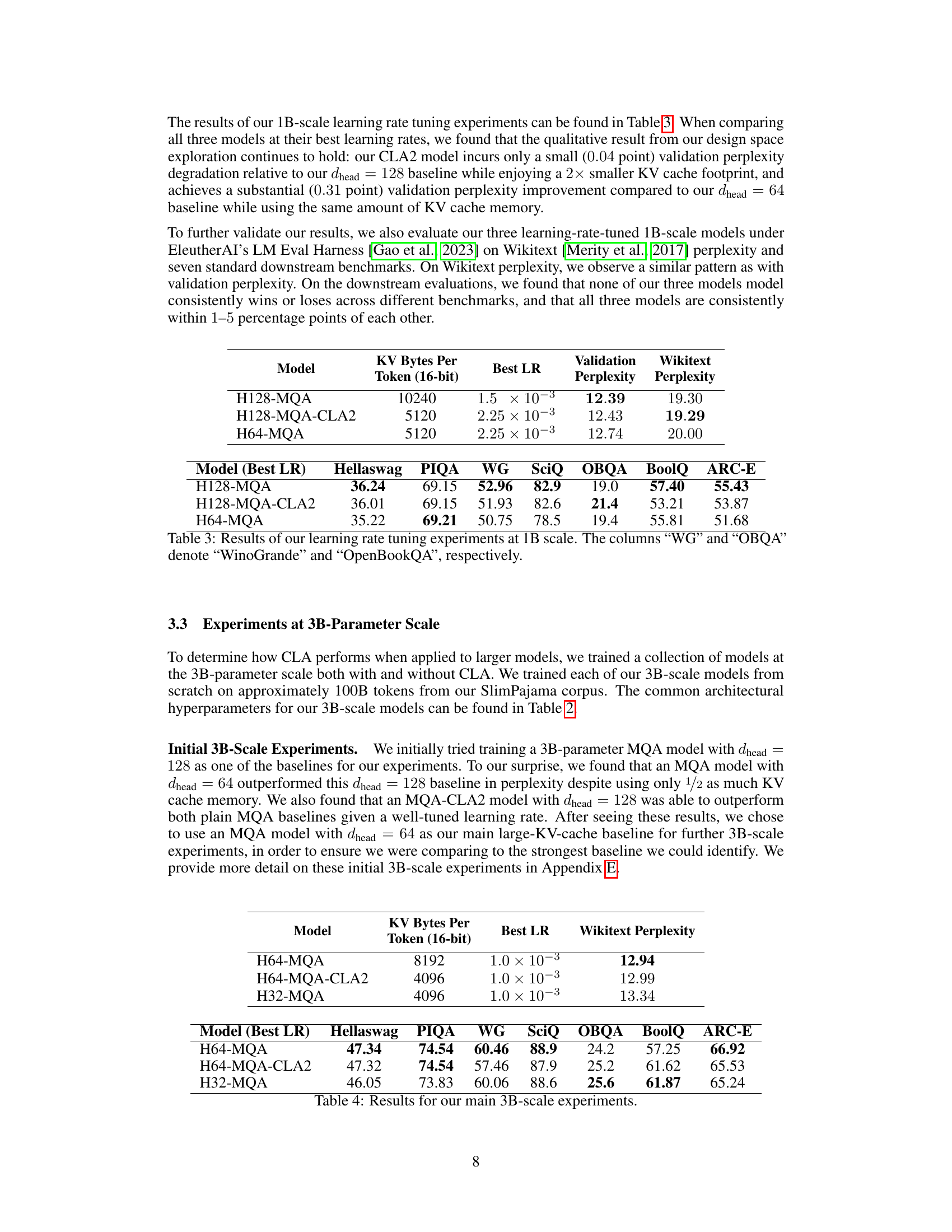
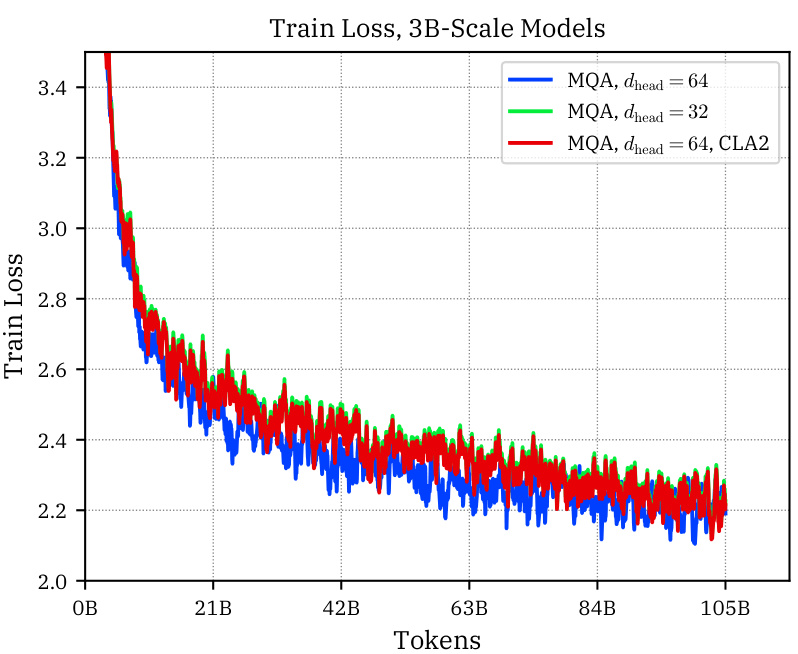
This table presents the results of the main 3B-parameter experiments. It compares three models: H64-MQA, H64-MQA-CLA2, and H32-MQA. The table shows the KV cache size per token (in 16-bit precision), the best learning rate found for each model, the Wikitext perplexity, and scores on several downstream benchmarks (Hellaswag, PIQA, WG, SciQ, OBQA, BoolQ, ARC-E). The results demonstrate the accuracy/memory tradeoffs achieved by CLA, showing that it maintains accuracy while reducing memory usage.

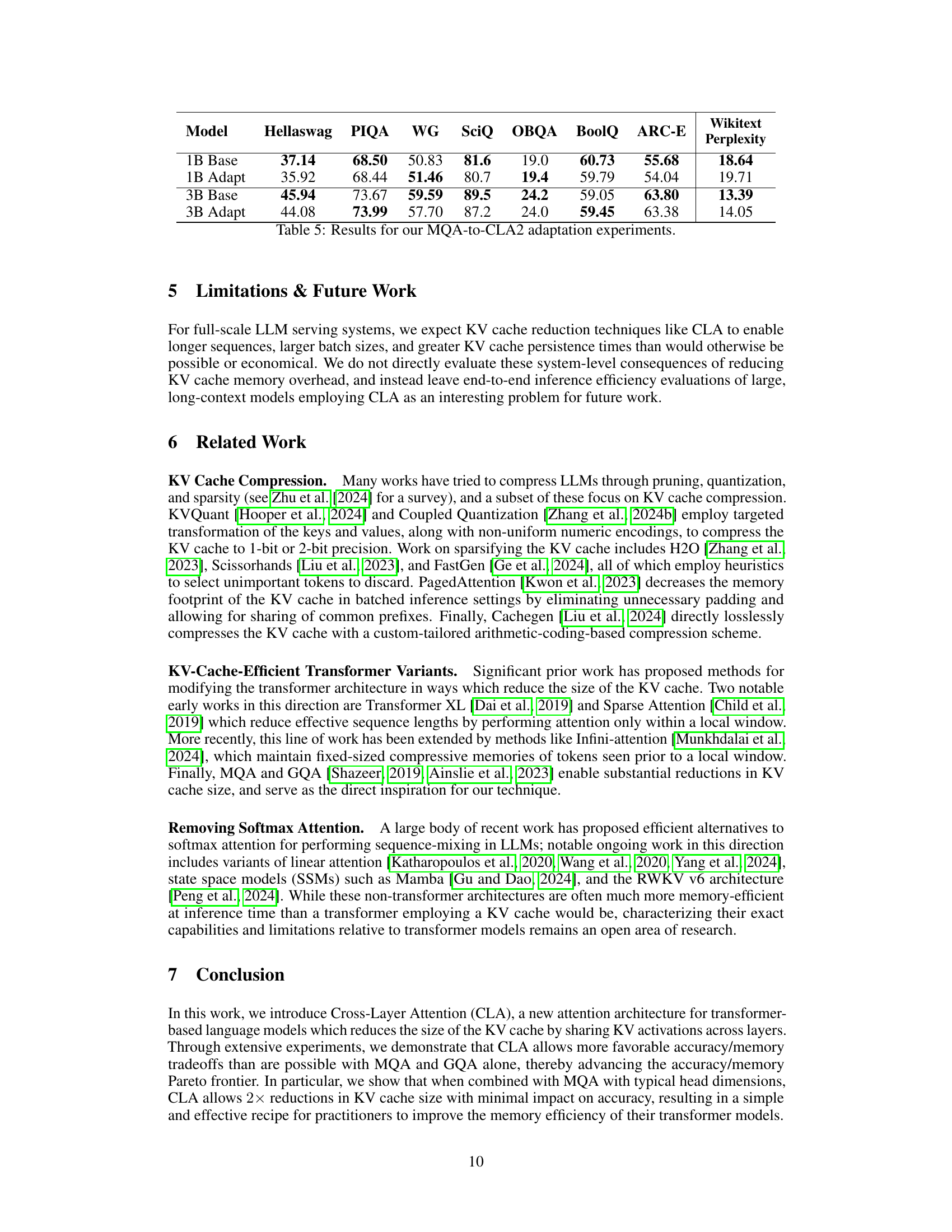
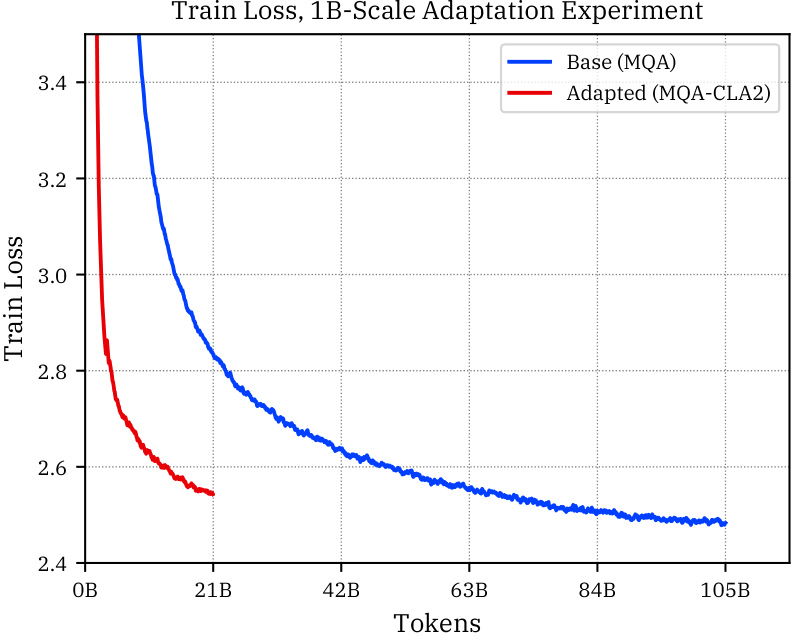
This table presents the results of adaptation experiments where models initially trained without Cross-Layer Attention (CLA) were subsequently adapted to utilize CLA. The table shows the performance of models before and after adaptation on various downstream benchmarks, including HellaSwag, PIQA, WinoGrande, SciTail, OpenBookQA, BoolQ, and ARC-E, as well as Wikitext perplexity. This helps assess the effectiveness of adapting pre-trained models to incorporate CLA.

This table presents the results of a design space exploration conducted at the 1 billion parameter scale. It shows the validation perplexity achieved by various transformer models with different architectures and hyperparameters. Specifically, it compares models with different head dimensions (dhead), query heads, key-value heads, layers, and KV cache sizes. It also includes models using Multi-Query Attention (MQA), Grouped-Query Attention (GQA), and Cross-Layer Attention (CLA) techniques, showcasing their respective accuracy/memory tradeoffs. Ablation studies are detailed in Appendix B.
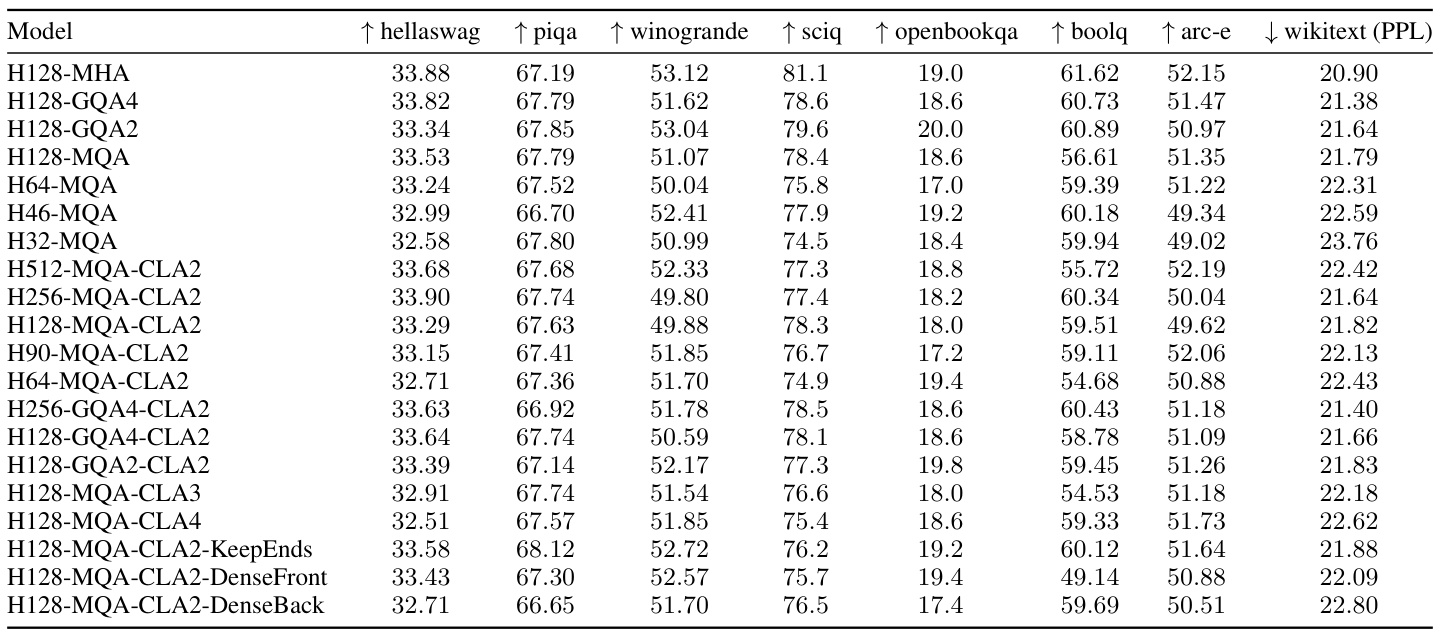
This table presents the results of the design space exploration conducted for 1B parameter models. It shows various model configurations, including different head dimensions (dhead), number of query heads, key/value heads, number of layers, KV bytes per token, and validation perplexity. The models explore different attention mechanisms like MHA, GQA, MQA, and combinations of MQA with CLA2. Appendix B contains more detailed ablation studies.

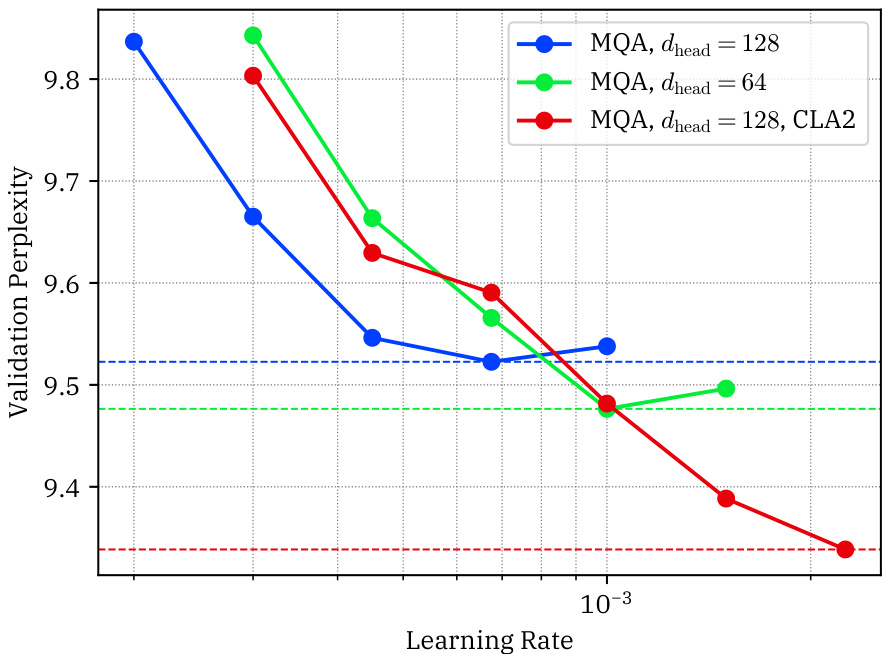
This table shows the results of initial experiments conducted at the 3B parameter scale. Three models were compared: a standard MQA model with 128 heads, an MQA model with CLA2 and 128 heads, and an MQA model with 64 heads. For each model, the table lists the optimal learning rate found, as well as the resulting validation and Wikitext perplexities. This table highlights the initial findings that informed the subsequent, more extensive 3B-scale experiments.

This table presents the results of the design space exploration performed for 1B parameter models. It compares various configurations of Multi-Query Attention (MQA) with and without Cross-Layer Attention (CLA). The models are evaluated based on validation perplexity and the KV cache size per token. Appendix B provides a more comprehensive analysis of the ablations.

This table compares the performance of the original TinyLlama-1.1B-105B model with a version of the same model trained from scratch using Cross-Layer Attention (CLA2). The comparison is based on several downstream benchmark tasks (Hellaswag, PIQA, WG, SciQ, OBQA, BoolQ, ARC-E) and Wikitext perplexity. The results show that CLA2 model achieves comparable or better performance on all the tasks compared to the original model.

This table presents the results from the design space exploration of 1B parameter models. It compares various configurations of attention mechanisms (MHA, GQA, MQA) and includes models using Cross-Layer Attention (CLA). The table shows the hyperparameters used (dhead, query heads, key-value heads, layers), KV cache size, and validation perplexity for each model. The full results, including ablation studies, can be found in Appendix B of the paper.
This table presents the results of the design space exploration performed on 1B parameter models. It shows different model configurations (varying head dimension, using MQA, GQA, MHA, and CLA2), the resulting KV cache size per token, and the achieved validation perplexity. The table helps to illustrate the accuracy/memory trade-offs achieved by different attention mechanisms and the impact of CLA2 on reducing KV cache size. Appendix B provides more detailed ablation studies.
Full paper#