↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-3D models struggle with generating high-quality meshes, realistic materials and lighting, often producing artifacts and slow generation times. Existing methods frequently utilize “baked” shading, which limits realistic relighting in various environments and restricts practical applications. This approach also has ambiguity in assigning materials to surfaces.
This paper introduces Meta 3D AssetGen, a two-stage approach that addresses these issues. The first stage uses a text-to-image model to generate multiple views of the object with separate albedo and shaded channels. The second stage employs a novel image-to-3D reconstruction network that predicts physically-based rendering (PBR) materials (albedo, metalness, and roughness) and reconstructs the 3D mesh. A texture refinement transformer further enhances texture quality. The results show significant improvements in mesh quality and realism, exceeding existing methods and achieving high user preference.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D computer graphics and AI. It significantly advances text-to-3D generation, producing high-quality meshes with realistic materials and lighting. This work directly addresses the limitations of existing methods, paving the way for more realistic and versatile applications in gaming, animation, and virtual reality. By introducing physically-based rendering (PBR) materials, the researchers overcome the limitations of baked shading, enabling more realistic relighting. The novel reconstruction method and texture refinement transformer substantially improve mesh quality, outperforming existing approaches. The high human preference rate suggests significant practical impact.
Visual Insights#

This figure showcases the capabilities of Meta 3D AssetGen. The top row demonstrates text-to-3D and image-to-3D generation, highlighting the model’s ability to create detailed 3D meshes from text prompts or input images. The bottom row focuses on material decomposition, showing how AssetGen separates materials into albedo, metalness, and roughness components, allowing for realistic relighting in various environments.

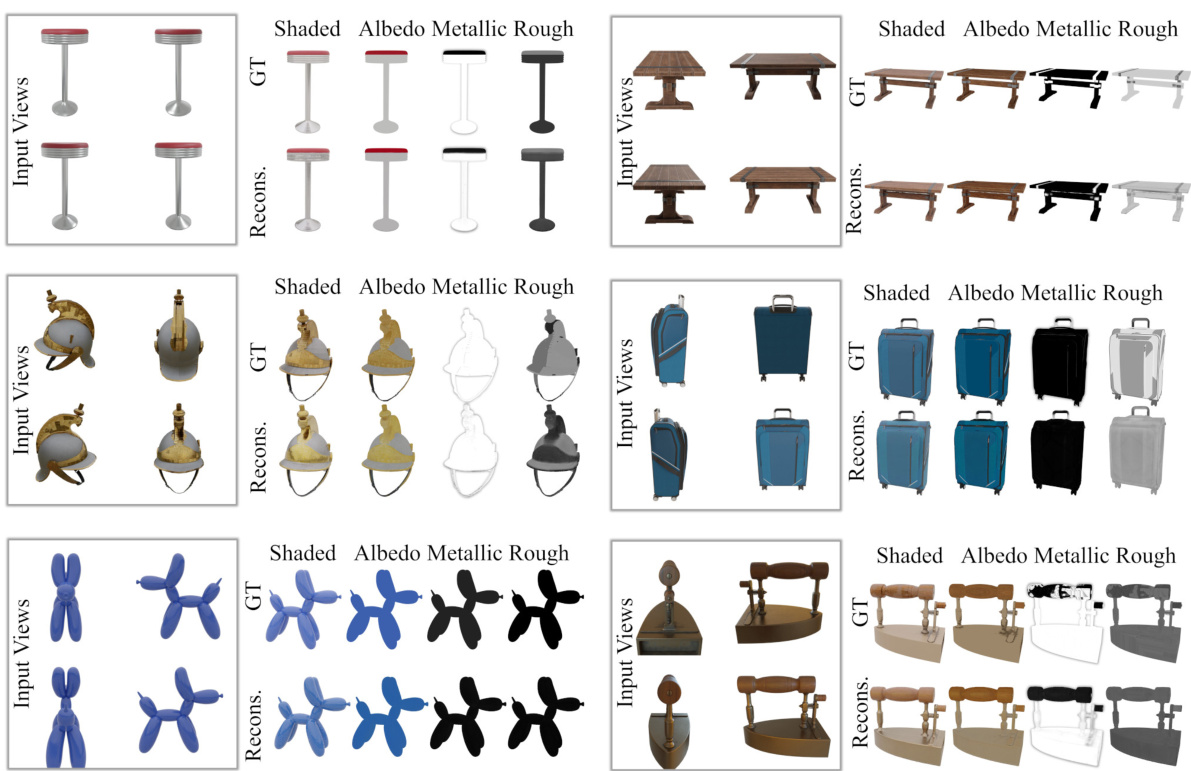
This table presents the results of a four-view reconstruction experiment evaluating the accuracy of physically-based rendering (PBR) material prediction. It compares different model variations of MetalLRM, assessing the performance of albedo, metalness, and roughness prediction using LPIPS (lower is better) and PSNR (higher is better) metrics. The table shows the impact of adding material prediction, deferred shading loss, and texture refinement to the baseline model (LightplaneLRM with SDF). The top section uses models trained with shaded images, while the bottom section uses models trained with both shaded and albedo images.
In-depth insights#
PBR Materials in 3D#
Physically-Based Rendering (PBR) is crucial for realistic 3D graphics, as it accurately simulates the interaction of light with materials. PBR in 3D necessitates modeling albedo (base color), metalness (metallic reflection), and roughness (surface texture) to achieve photorealism. This decomposition of materials is a significant advancement over older methods that “baked” shading into the model, limiting relighting capabilities and creating unrealistic appearances. Accurate PBR materials enhance the realism and versatility of 3D assets, particularly in applications demanding real-world lighting simulation, like video games and virtual reality. Challenges in PBR for 3D generation include accurately predicting material properties from limited input data (e.g., images or text) and efficiently representing this information in a 3D model. Successful methods utilize efficient loss functions, learning models, and texture refinement techniques to overcome these obstacles, resulting in high-quality 3D models with realistic material appearances and interactive lighting behavior. The focus on PBR in 3D asset generation represents a substantial step toward creating visually compelling and realistic virtual worlds.
Two-Stage Generation#
A two-stage generation approach in 3D asset generation typically involves a text-to-image stage followed by an image-to-3D stage. The initial stage leverages pre-trained text-to-image models to generate multiple views of the target object from different viewpoints. This approach addresses the challenge of generating realistic and consistent 3D assets directly from text by breaking the problem into two more manageable steps. The text-to-image model handles ambiguity and stochasticity well; however, predicting PBR parameters directly from the images is difficult in the second stage because the task is deterministic and ambiguous. Therefore, generating shaded and albedo images in the first stage and deferring PBR prediction to the second stage offers an advantage. The second stage then processes these images to reconstruct the final 3D mesh, employing techniques such as signed distance functions (SDFs) for improved mesh quality and texture refinement for enhanced detail. This decomposition of the generation process into multiple stages allows for better handling of material properties and improved efficiency, ultimately creating high-quality 3D meshes with physically-based rendering (PBR) materials which is superior compared to single-stage methods.
MetaILRM Model#
The MetaILRM model, a core component of Meta 3D AssetGen, represents a substantial advancement in image-to-3D reconstruction. Its novelty lies in its integrated approach to predicting physically-based rendering (PBR) materials alongside 3D geometry, directly addressing a significant limitation of previous methods. Instead of relying on separate predictions, MetaILRM uses a unified network to generate both albedo, metalness, and roughness maps simultaneously with a signed distance function (SDF) representation of the 3D shape. This unified architecture allows for more coherent and realistic material rendering and improves mesh quality. The use of SDFs over opacity fields significantly enhances the accuracy of shape representation, making it more reliable for mesh extraction and improving texture quality. Furthermore, MetaILRM’s memory efficiency, achieved through the use of fused kernels and VolSDF formulation, allows for processing higher-resolution renders and larger batch sizes, leading to significant performance gains and improved detail in reconstructed meshes. The integration of a texture refinement transformer further augments the quality, enhancing sharpness and details from the initially generated textures.
Texture Refinement#
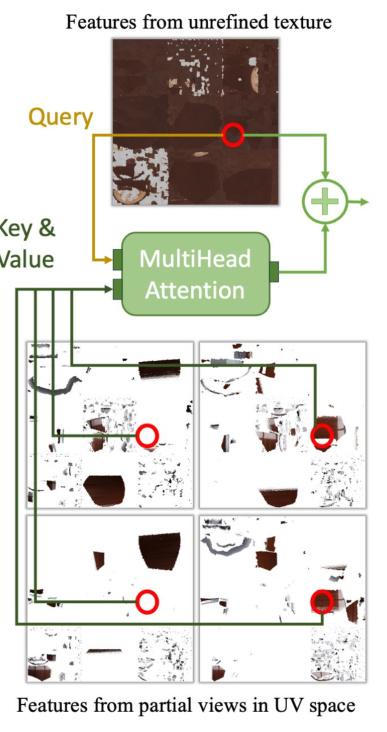
The texture refinement process in the research paper is crucial for enhancing the quality of generated 3D meshes. It addresses the limitations of directly sampling PBR fields from the reconstruction model, which often leads to blurry textures due to limited resolution. The process leverages information from multiple input views of the object, resolving potential conflicts to create sharper and more detailed textures. This refinement is implemented using fused kernels for memory efficiency and operates in UV space, maximizing its effectiveness. The technique significantly boosts the final asset’s quality, demonstrating a substantial improvement in perceptual metrics like LPIPS. The innovation lies in its ability to fuse information from various views, resolving conflicts, and producing high-fidelity textures without overly complex procedures. This is important because texture quality significantly impacts the visual appeal and realism of the final 3D asset. The choice of UV space further highlights the efficiency and effectiveness of the method. This combination of efficient implementation and superior results underscores the importance of texture refinement in high-quality 3D asset generation.
Future Work: Scalability#
Future scalability of text-to-3D generation models like Meta 3D AssetGen hinges on addressing several key limitations. Improving memory efficiency is crucial; current methods struggle with high-resolution outputs due to memory constraints. Exploring alternative 3D representations, such as octrees or sparse voxel grids, could significantly enhance scalability by reducing the computational cost of representing empty space. Directly supervising a multi-resolution SDF, rather than relying on the current inefficient autograd implementation, will also improve efficiency. Furthermore, the model’s current reliance on 4 canonical viewpoints is a bottleneck; research into handling a flexible number of views, or even single-view reconstruction, would greatly boost scalability and make the model more practical. Finally, extending the approach to handle scene-scale generation, rather than just object-level modeling, presents a significant challenge for future work. Addressing these points would make text-to-3D technology much more widely applicable.
More visual insights#
More on figures

This figure illustrates the overall architecture of the Meta 3D AssetGen pipeline, which consists of two main stages: text-to-image and image-to-3D. The text-to-image stage uses a multiview multichannel diffusion model to generate four views of the object with shaded and albedo channels. The image-to-3D stage takes these images as input and uses a novel reconstruction model (MetaILRM) to produce a mesh with physically-based rendering (PBR) materials. A texture refinement step further enhances the quality of the generated textures. The figure highlights the data flow and the different components of the pipeline, including the use of triplanes, signed distance functions (SDFs), and differentiable rendering.

This figure shows the pipeline of the AssetGen model. The model takes a text prompt as input and generates a 3D mesh with physically-based rendering (PBR) materials in two stages. The first stage is a text-to-image stage that predicts a 6-channel image containing four views of the object. The second stage is an image-to-3D stage that reconstructs the 3D shape, appearance, and materials from the views. This stage includes a texture refiner that enhances the quality of the materials.
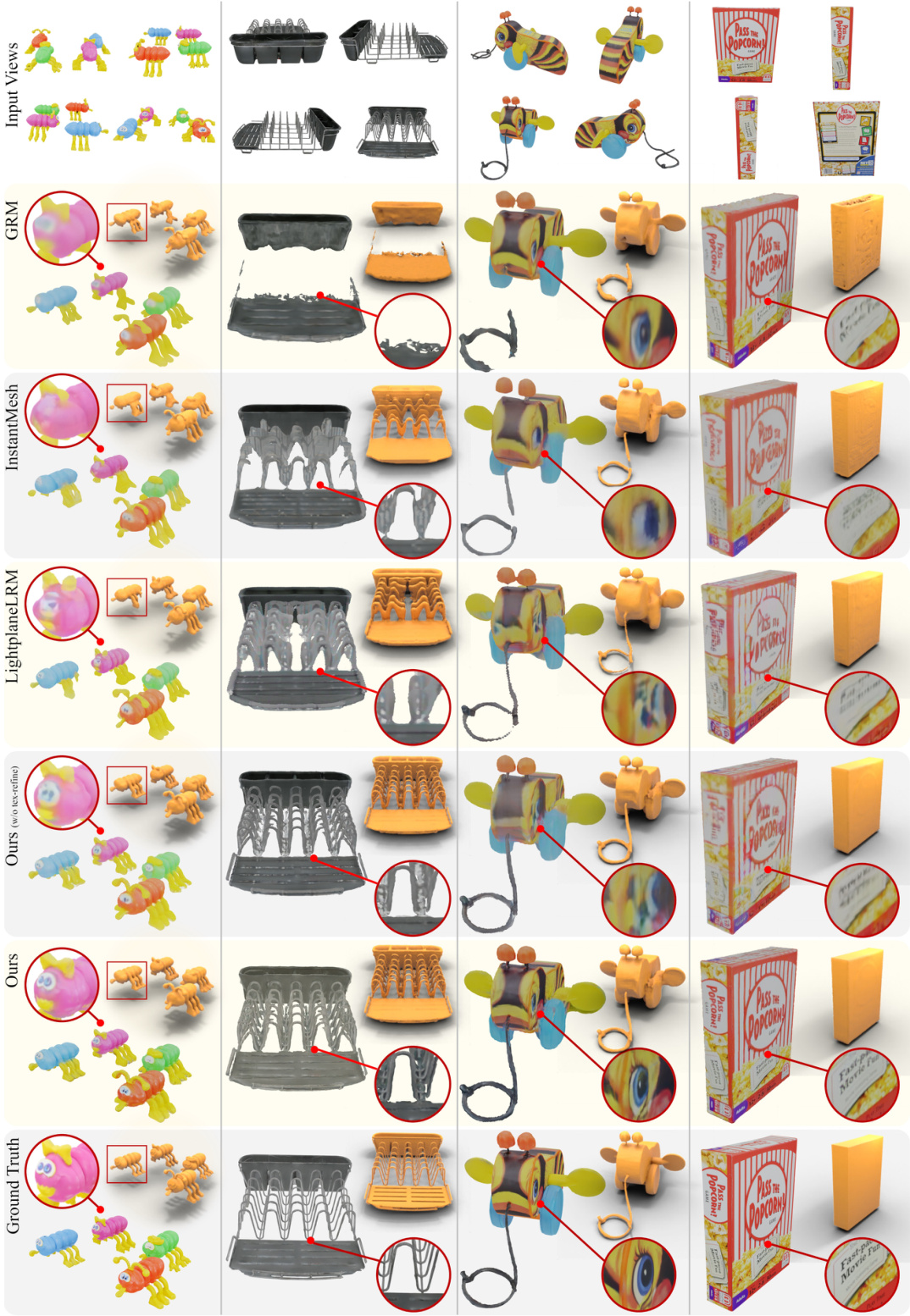
This figure compares the results of sparse-view reconstruction using AssetGen against other state-of-the-art methods. It shows that AssetGen produces better geometry and higher-fidelity textures. The use of SDF representation and direct SDF loss leads to improved geometry compared to LightplaneLRM, which uses occupancy. Additionally, AssetGen’s texture refiner significantly enhances texture quality.

This figure compares the results of text-to-3D generation using Meta 3D AssetGen and several state-of-the-art baselines. The comparison highlights the superior quality of materials produced by Meta 3D AssetGen, showing better-defined metalness, roughness, and more accurate separation of lighting effects from albedo (base color).

This figure shows the overall architecture of the Meta 3D AssetGen pipeline. It’s a two-stage process: The first stage uses a text-to-image model to generate a multi-channel image containing four views of the target object. The second stage uses a novel reconstruction model, MetaILRM, to create a 3D mesh with Physically Based Rendering (PBR) materials. The output of this model is then refined by a texture refiner for improved detail and quality. The figure highlights the different components and their interactions within the overall system.
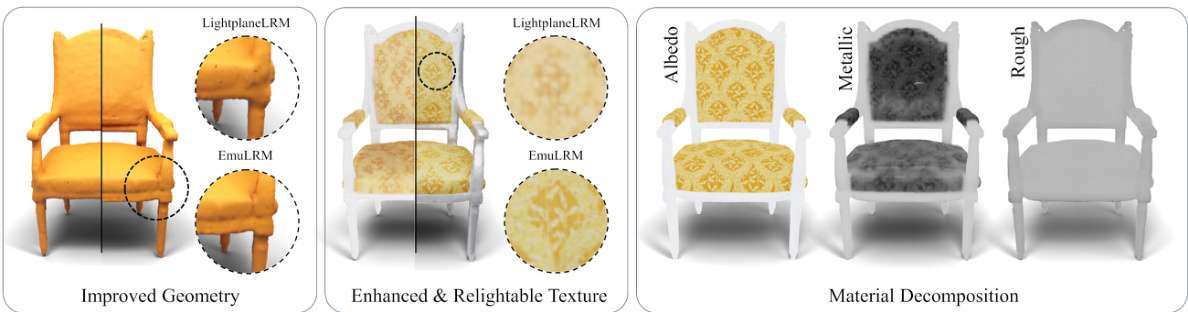
This figure shows the architecture of MetaILRM and its improvements over LightplaneLRM. The improvements include better geometry due to the use of SDF, enhanced and reliable textures due to the UV space texture refiner, and more accurate material decomposition due to novel deferred shading loss. It visually demonstrates how these improvements work together to produce higher quality 3D models.
This figure shows the pipeline of the AssetGen model. It takes a text prompt as input and outputs a 3D mesh with physically based rendering (PBR) materials. The process is divided into two stages: text-to-image and image-to-3D. The text-to-image stage uses a multiview multichannel diffusion model to generate a 6-channel image containing 4 views of the object (albedo and shaded). The image-to-3D stage uses a PBR-based large reconstruction model and a texture refiner to reconstruct the 3D mesh from the images, adding PBR materials and refining textures.

This figure compares the results of sparse-view reconstruction using AssetGen against other state-of-the-art methods. AssetGen’s superior performance in geometry and texture detail is highlighted, particularly when compared to methods using occupancy fields instead of SDFs.

This figure shows the architecture of the Meta 3D AssetGen pipeline. It consists of two main stages: a text-to-image stage and an image-to-3D stage. The text-to-image stage takes a text prompt as input and outputs a multi-channel image containing multiple views of the object, with both shaded and albedo colors. The image-to-3D stage takes this image as input and performs 3D reconstruction, material prediction, and texture refinement to generate the final 3D model with high-quality geometry, texture and PBR materials.
This figure shows the overall architecture of the Meta 3D AssetGen pipeline, which consists of two main stages: a text-to-image stage and an image-to-3D stage. The text-to-image stage uses a multiview multichannel diffusion model to generate four views of the object, including both shaded and albedo information. The image-to-3D stage then takes these views and uses a physically-based rendering (PBR) reconstruction model (MetaILRM) to create a 3D mesh with PBR materials, followed by a texture refinement step to improve detail.

This figure demonstrates the capabilities of Meta 3D AssetGen. The top row shows examples of 3D models generated from text and image prompts, highlighting the high quality of geometry and textures. The bottom left shows the material decomposition into albedo, metalness, and roughness, which are essential for physically based rendering (PBR). The bottom right demonstrates how these PBR materials allow for realistic relighting of the objects in different environments.
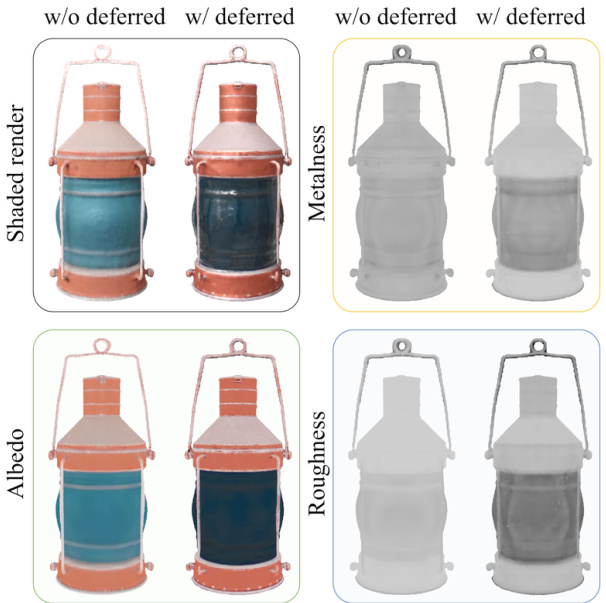
This figure demonstrates the effect of using a deferred shading loss in enhancing the quality of Physically Based Rendering (PBR) materials. By comparing the results with and without the loss, it highlights improved definition in metalness and roughness. Specifically, the lantern’s metal parts exhibit increased metalness, while the glass shows improved roughness.
This figure shows the overall architecture of the Meta 3D AssetGen model. It is a two-stage pipeline. The first stage uses a multiview multichannel diffusion model to generate four views of the object with shaded and albedo channels from text prompt. The second stage uses a PBR-based reconstruction model to generate a mesh from these views, with a texture refiner to enhance texture quality.

This figure shows the cross-view attention mechanism and deferred shading loss calculation in the Meta 3D AssetGen model. (a) illustrates how cross-view attention blends predicted texture features with UV-projected input views using a multi-headed attention mechanism. (b) demonstrates how deferred shading computes pixel shading using albedo, metalness, roughness, normals, object position, and light source position, comparing ground truth and predicted channels and weighting the error by normal similarity.
More on tables

This table presents the results of a user study comparing the performance of Meta 3D AssetGen against other state-of-the-art text-to-3D generation methods. The study evaluates two key aspects: visual quality and the alignment of the generated 3D models with the text prompts used to generate them. The results show that Meta 3D AssetGen significantly outperforms other methods in both visual quality and text fidelity, achieving a win-rate of over 70% against the best competitors within a 30-second time limit.
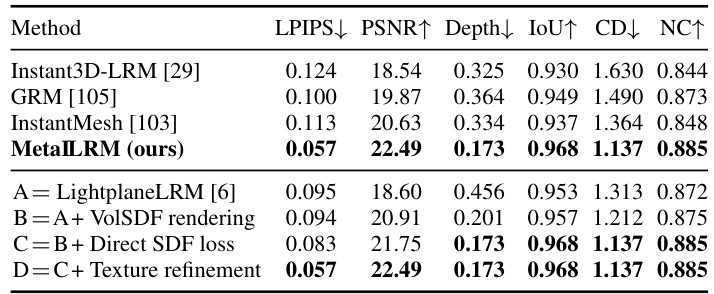
This table presents a comparison of different methods for four-view reconstruction on the Google Scanned Objects dataset (GSO). The methods compared are Instant3D-LRM, GRM, InstantMesh, and MetaILRM, along with several ablations of MetaILRM. The metrics used for comparison are LPIPS, PSNR, depth error, IoU, Chamfer Distance (CD), and Normal Correctness (NC). MetaILRM demonstrates state-of-the-art performance across all metrics, highlighting the contributions of its core components.

This table presents the results of a user study comparing Meta 3D AssetGen to other state-of-the-art text-to-3D generation methods. The study evaluated both the visual quality of the generated 3D models and how well the models matched the text prompts used to generate them. The results show that AssetGen outperforms all other methods, achieving a high win rate (percentage of times preferred) within a 30-second time constraint on an A100 GPU.
Full paper#



















