↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing GNN reuse methods rely on knowledge distillation or amalgamation, necessitating retraining and labeled data, which is resource-intensive. This is particularly challenging with large models and datasets. The non-Euclidean nature of graph data further complicates the process. This paper introduces Deep Graph Mating (GRAMA) to address these issues.
GRAMA introduces a novel learning-free approach, Dual-Message Coordination and Calibration (DuMCC), that facilitates training-free knowledge transfer. DuMCC optimizes permutation matrices for parameter interpolation by coordinating aggregated messages from parent GNNs and calibrates message statistics in the child GNN to mitigate over-smoothing. Extensive experiments show that GRAMA, utilizing DuMCC, achieves performance on par with pre-trained models in various tasks and domains without any training or labeled data.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Deep Graph Mating (GRAMA), the first learning-free model reuse method for graph neural networks (GNNs). This addresses the limitations of existing GNN reuse techniques that require resource-intensive re-training, opening new avenues for efficient GNN development and deployment in various resource-constrained applications.
Visual Insights#
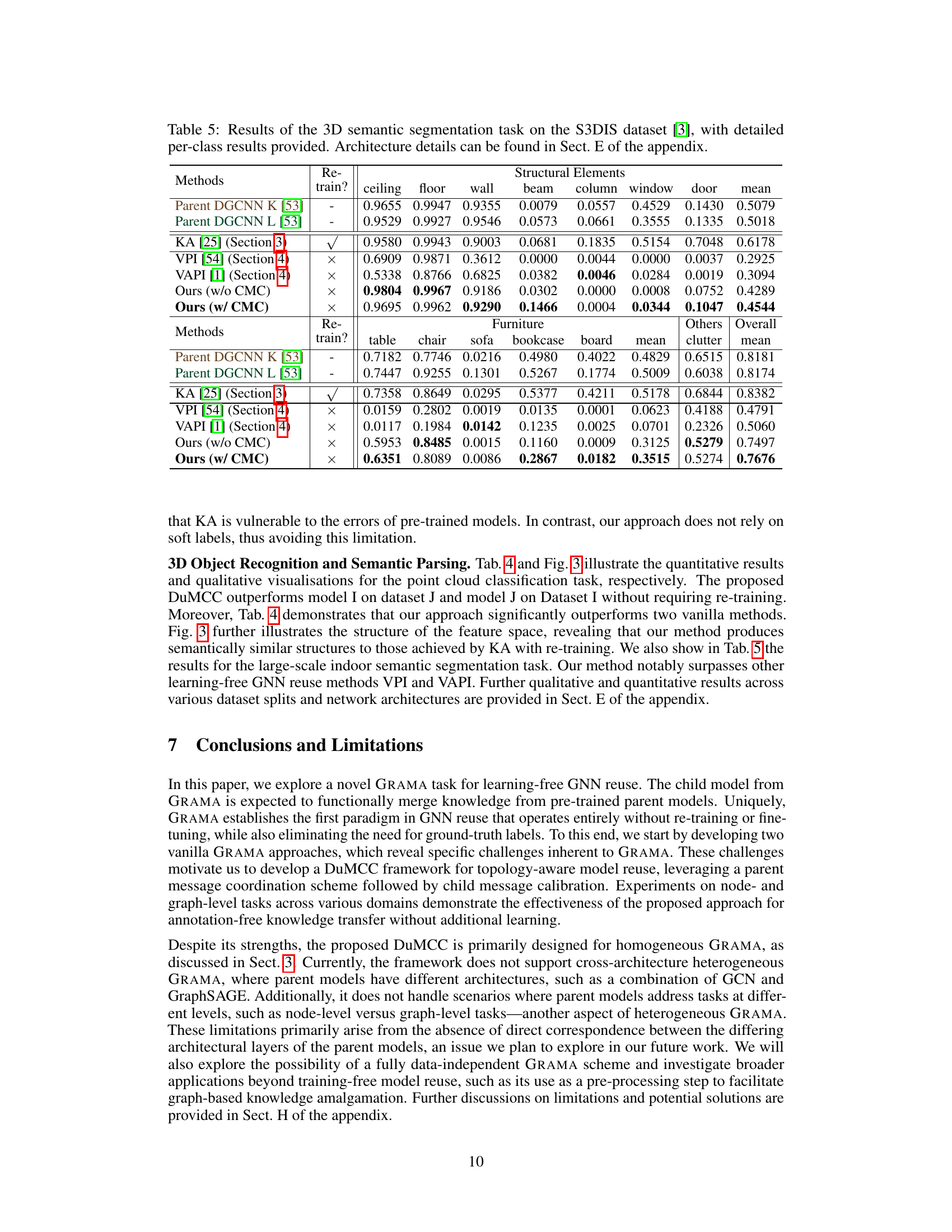
This figure shows the Dirichlet energy of pre-trained parent GNNs (A and B) and the child GNN produced by the Parent Message Coordination (PMC) scheme. Each point represents a pair of parent GNNs trained on different data splits. The x-axis represents the Dirichlet energy of parent GNN A, the y-axis represents the Dirichlet energy of parent GNN B, and the color represents the Dirichlet energy of the child GNN produced by PMC. The figure demonstrates the over-smoothing effect of PMC, where the child GNN’s Dirichlet energy is lower than those of the parents, indicating a loss of node feature variance.

This table compares different graph neural network (GNN) model reuse techniques in the non-Euclidean domain. It contrasts Knowledge Distillation, Knowledge Amalgamation, and the novel Deep Graph Mating (GRAMA) approach introduced in the paper. The columns indicate whether each method supports multi-model reuse, operates without annotations, and is training-free/fine-tuning-free.
In-depth insights#
GNN Mating: A New Task#
GNN mating introduces a novel paradigm in graph neural network (GNN) research, focusing on training-free knowledge transfer. Unlike traditional knowledge distillation or amalgamation, it aims to combine the strengths of multiple pre-trained GNNs without retraining or using labeled data. This is achieved by developing innovative methods to effectively merge parameters and align topologies of parent GNNs, resulting in a child GNN inheriting the combined expertise. The training-free nature is a significant advantage for resource-efficient GNN reuse, particularly important when dealing with large models and datasets. However, the task introduces unique challenges such as sensitivity to parameter misalignment and inherent topological complexities. Addressing these challenges forms a crucial part of the proposed methodology, which must effectively coordinate and calibrate messages from parent GNNs to prevent over-smoothing in the child GNN, ensuring knowledge transfer without significant loss of information. The success of this approach opens up new possibilities for the efficient and responsible reuse of pre-trained GNNs across diverse applications.
Vanilla Methods’ Failure#
The failure of the vanilla methods, Vanilla Parameter Interpolation (VPI) and Vanilla Alignment Prior to Interpolation (VAPI), in the Deep Graph Mating (GRAMA) task highlights the unique challenges of applying model reuse techniques to the non-Euclidean domain of graphs. VPI’s simplistic averaging of parameters failed because it didn’t account for the topology-dependent nature of GNNs and the potential for misalignment between parameters of differently trained models. VAPI, while attempting to address parameter misalignment, still lacked a mechanism to effectively handle the inherent complexities of graph structures. Its failure underscores the critical need for topology-aware methods. The theoretical analysis revealing GNNs’ amplified sensitivity to parameter misalignment compared to Euclidean models further supports the inadequacy of these vanilla approaches. Ultimately, the limitations of these approaches demonstrate why a more sophisticated methodology, like the proposed Dual-Message Coordination and Calibration (DuMCC), is crucial for effective learning-free knowledge transfer in the context of graph neural networks.
DuMCC: Topology-Aware#
The proposed DuMCC methodology represents a significant advancement in addressing the inherent limitations of training-free knowledge transfer in graph neural networks. By explicitly incorporating topological information through its two core components, Parent Message Coordination (PMC) and Child Message Calibration (CMC), DuMCC effectively mitigates the challenges of parameter misalignment and over-smoothing. The topology-aware nature of DuMCC allows for a more nuanced understanding of how to leverage pre-trained models without necessitating re-training or annotated labels, thus showcasing its potential to revolutionize resource-efficient model reuse within the non-Euclidean domain. DuMCC’s effectiveness is not only theoretically supported but empirically demonstrated across various tasks and datasets, highlighting its robustness and generalizability. The design of DuMCC, with its learning-free components, showcases a paradigm shift towards more practical and computationally-efficient model deployment.
Over-smoothing Mitigation#
Over-smoothing, a critical challenge in graph neural networks (GNNs), hinders their ability to effectively capture and utilize intricate graph structures. Mitigation strategies are crucial for achieving optimal performance. One common approach involves modifying the message-passing mechanism to reduce the homogeneity of node representations. This might include incorporating attention mechanisms to prioritize informative neighbors or employing residual connections to preserve fine-grained details during propagation. Another strategy focuses on the architecture itself, utilizing techniques like layer normalization or specialized activation functions to improve the expressiveness of the network. Regularization methods, such as graph-based dropout or adding noise to the input features, can also enhance robustness and mitigate over-smoothing. Finally, data augmentation strategies that enrich graph representations before input can prevent overly simplistic node embeddings, thereby improving overall model accuracy and providing valuable insights.
Future of GRAMA#
The future of Deep Graph Mating (GRAMA) holds significant potential. Extending GRAMA to heterogeneous scenarios, where parent GNNs have different architectures or target diverse tasks, is crucial. This would unlock a wider range of applications and require sophisticated alignment strategies beyond simple weight interpolation. Addressing the inherent complexity of topology-dependent parameter misalignment remains a challenge, calling for advanced optimization techniques and potentially novel loss functions. Investigating the interplay between over-smoothing and the efficacy of the Child Message Calibration (CMC) scheme will pave the way for improved robustness and performance. Furthermore, exploring novel applications of GRAMA in diverse domains, such as drug discovery, social network analysis, and materials science, is promising. Finally, enhancing the theoretical understanding of GRAMA’s limitations and developing more sophisticated methods for addressing topology-dependent challenges and cross-architecture alignment will be critical. These future directions will contribute to a more robust, versatile, and impactful model reuse paradigm.
More visual insights#
More on figures

This figure compares the feature space visualizations generated by different methods for node classification on the ogbn-arxiv dataset. t-SNE is used to reduce the dimensionality of the feature vectors to 2D for visualization. Each point represents a node, and its color represents its class label. The figure shows that the proposed DuMCC method, with and without child message calibration (CMC), achieves better separation of classes compared to other baselines, such as Knowledge Amalgamation (KA), Vanilla Parameter Interpolation (VPI), and Vanilla Alignment Prior to Interpolation (VAPI).

This figure shows t-SNE visualizations of feature space structures for different methods (KA, VPI, VAPI, and the proposed method) on the ModelNet40 dataset. The color gradient represents the distance from a reference point (red dot) to other points, illustrating how different methods group similar features and the overall structure of the learned feature space. The visualization helps demonstrate the impact of different approaches on the organization and discriminative power of node features.
More on tables
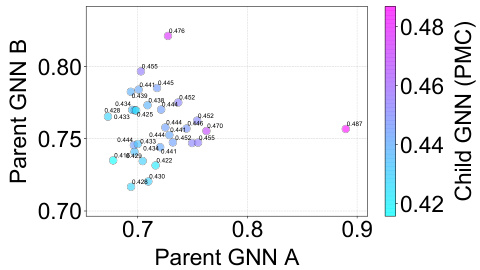
This table presents the results of a multi-class node classification task using two parent GNNs pre-trained on disjoint partitions of the ogbn-arxiv and ogbn-products datasets. It compares the performance of several methods, including Knowledge Amalgamation (KA), Vanilla Parameter Interpolation (VPI), Vanilla Alignment Prior to Interpolation (VAPI), and the proposed Dual-Message Coordination and Calibration (DuMCC) approach (with and without Child Message Calibration). The table shows the accuracy achieved by each method on the test sets for both datasets. The ‘Re-train?’ column indicates whether the method required retraining.
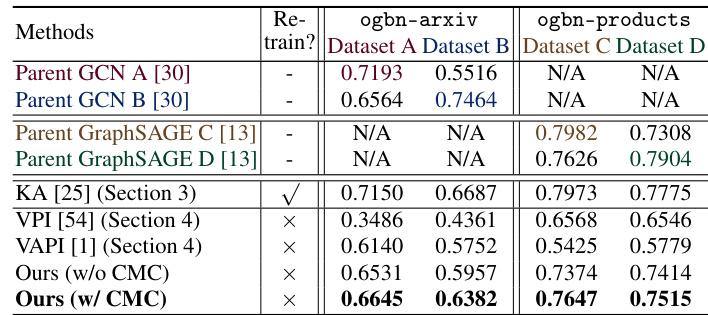
This table presents the results of a point cloud classification task using the DGCNN architecture on the ModelNet40 dataset. Two parent DGCNN models were pre-trained on disjoint partitions of the dataset. The table compares the performance of the Knowledge Amalgamation (KA) method, two vanilla methods (VPI and VAPI), and the proposed DuMCC approach (with and without Child Message Calibration) on this task. The results show the accuracy achieved by each method on two different dataset partitions (Dataset I and Dataset J).

This table presents the results of multi-label node classification and graph classification tasks using GIN and GAT architectures respectively. It compares the performance of the proposed DuMCC method with existing methods (KA, VPI, and VAPI) and pre-trained parent models. The results show that DuMCC exhibits comparable performance to KA while avoiding the drawbacks of relying on soft labels generated by pre-trained teacher models, which are susceptible to misclassification errors.
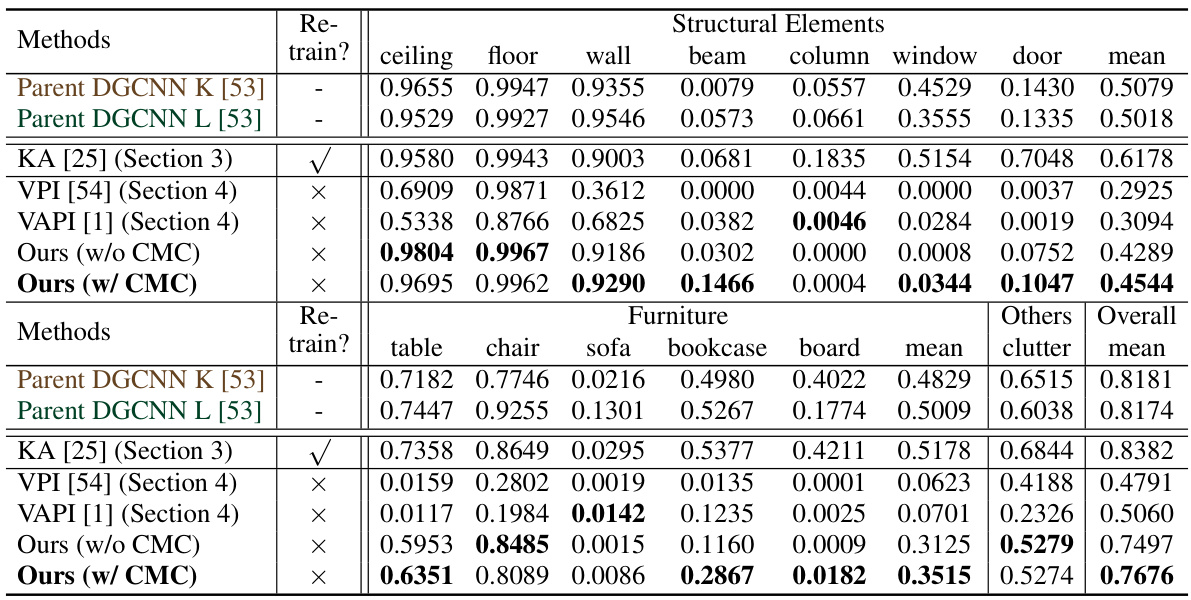
This table presents the results of a multi-class molecule property prediction task. It compares the performance of several methods, including the proposed DuMCC approach, on two datasets (ogbn-arxiv and ogbn-products). The methods compared include training-free methods (VPI, VAPI, DuMCC with and without CMC), and a training-based method (KA). The table shows the accuracy achieved by each method on each dataset, highlighting the effectiveness of the proposed DuMCC approach, particularly when CMC is included, in achieving competitive results without requiring any retraining.
Full paper#