↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training object detectors is computationally expensive and requires massive datasets. Current dataset condensation methods primarily focus on image classification, leaving object detection relatively unexplored. This is due to the complexities of object detection (simultaneous localization and classification) and the high-resolution nature of detection datasets, which existing methods struggle to handle.
The authors propose DCOD, a two-stage framework addressing these challenges. The first stage, “Fetch,” trains a detector on the original dataset, storing crucial information in the model’s parameters. The second stage, “Forge,” uses model inversion to generate synthetic images guided by the trained detector, employing Foreground Background Decoupling and Incremental PatchExpand to enhance diversity. Experiments demonstrate DCOD’s significant performance gains on VOC and COCO datasets even with extreme compression.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the significant challenge of training deep learning models for object detection, which typically requires large, high-resolution datasets. By introducing an efficient dataset condensation method, it reduces training time and data storage needs, making object detection accessible to researchers with limited resources.
Visual Insights#

This figure compares three different dataset condensation frameworks. (a) shows the meta-learning framework, where the synthetic dataset is updated by minimizing the performance risk on the original dataset’s validation set. (b) shows the data-matching framework, which aligns gradients, feature distributions, or training trajectories to simulate the original data’s impact. (c) introduces the proposed DCOD framework, which decouples the bi-level optimization of the previous methods into two stages: Fetch and Forge. The Fetch stage stores key information from the original dataset within the detector. The Forge stage synthesizes images from the trained detector using model inversion. DCOD is specifically designed for object detection tasks, addressing the challenges of multitasking and high-resolution data.
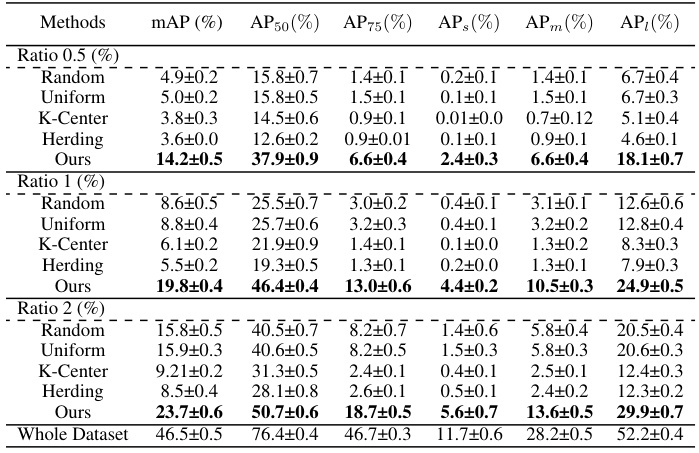
This table presents the performance comparison of different dataset condensation methods on the Pascal VOC dataset. The methods are compared using various metrics (mAP, AP50, AP75, APs, APm, APl) at three different compression ratios (0.5%, 1%, and 2%). The baseline model used is YOLOv3-SPP. The results show the effectiveness of the proposed DCOD method compared to other methods like Random, Uniform, K-Center, and Herding.
In-depth insights#
DCOD Framework#
The DCOD framework, a novel approach to dataset condensation for object detection, is presented as a two-stage process: Fetch and Forge. The Fetch stage leverages a pre-trained object detector to implicitly capture crucial localization and classification information from the original dataset within its model parameters. This eliminates the complex bi-level optimization typically found in traditional dataset condensation methods. The Forge stage uses model inversion to synthesize new images, guided by the learned model parameters from the Fetch stage. Foreground Background Decoupling and Incremental PatchExpand are introduced to enhance the diversity and realism of the generated synthetic images, particularly addressing the challenges of multi-object scenes. The effectiveness of DCOD is showcased through rigorous experimentation on standard benchmark datasets, achieving significant performance gains even at very low compression rates. This framework offers a more efficient and scalable alternative to existing methods, paving the way for more effective training of object detectors using reduced datasets.
Fetch & Forge Stages#
The ‘Fetch & Forge’ stages represent a novel two-stage approach to dataset condensation for object detection. The ‘Fetch’ stage leverages a pre-trained object detector to implicitly capture key information (localization and classification) from the original dataset, storing this knowledge within the detector’s parameters. This bypasses the computationally expensive bi-level optimization often used in traditional dataset condensation methods. The ‘Forge’ stage cleverly employs model inversion, using the trained detector to synthesize new images. This synthesis process is enhanced by techniques like Foreground-Background Decoupling (isolating and focusing improvements on foreground objects) and Incremental PatchExpand (increasing image diversity by creating multiple patches from single images). The entire process is guided by the detector’s loss function, ensuring the quality of synthesized images and their alignment with the original dataset’s characteristics. This innovative approach offers a significant improvement in efficiency and scalability compared to traditional methods, successfully handling the complexities of object detection datasets.
Multi-Object Handling#
Effective multi-object handling is crucial for object detection models. Challenges include disentangling individual objects within complex scenes, managing occlusions, and handling varying object scales and aspect ratios. A robust approach often involves a two-stage process: First, identifying individual objects using region proposal networks or similar techniques. Second, refining the localization and classification of each object using sophisticated feature extraction and classification layers. Foreground-background separation, a key technique in many successful approaches, improves object identification by isolating foreground elements from background clutter. Furthermore, attention mechanisms can be strategically implemented to selectively focus the model’s processing power on the most relevant features for each object, enhancing accuracy and efficiency. Strategies to address scale and aspect ratio variability often include feature pyramids or multi-scale feature extraction, providing a wider range of features for detection and recognition. Finally, non-maximum suppression is essential for removing duplicate detections of the same object, producing a more refined and accurate final output.
Ablation Experiments#
Ablation experiments systematically remove components of a model or system to assess their individual contributions. In a research paper, this section would show the impact of removing features, modules, or data augmentation techniques on the overall performance. The goal is to demonstrate the importance of each component and isolate the effects of specific design choices. A well-designed ablation study should involve removing one element at a time, while keeping other elements constant, providing a controlled comparison of model variants. The results would reveal which components are crucial for good performance and which are less important or even detrimental. A strong ablation study strengthens the validity of the paper’s claims by showing that the positive results are not due to any single part of the proposed method but rather the combined effect of carefully chosen components. Ideally, the study includes error bars or other statistical indicators to show the significance of the observed differences. Results often reveal unexpected interactions and highlight areas for future improvements.
Future of DCOD#
The future of DCOD (Dataset Condensation for Object Detection) holds significant promise. Improving the quality and diversity of synthetic images is crucial; current methods sometimes struggle with generating realistic multi-object scenes. Future work could explore advanced generative models like GANs or diffusion models to produce higher-fidelity synthetic data. Addressing computational costs remains vital, particularly for large-scale datasets. Exploring more efficient model inversion techniques or alternative optimization strategies would be beneficial. Extending DCOD to different object detection architectures and exploring its applicability in domains beyond standard benchmarks (e.g., medical imaging, autonomous driving) would expand its impact. Finally, investigating the theoretical limitations of DCOD and developing robust methods for evaluating the quality of condensed datasets are important next steps to solidify its place in the field.
More visual insights#
More on figures

This figure visualizes the synthetic images generated by the DCOD method. (a) shows examples of images with only a single object in the foreground. (b) shows examples of images with multiple objects in the foreground, demonstrating the method’s ability to generate diverse and complex scenes.

This figure illustrates the two-stage process of the DCOD framework. Stage-I: Fetch trains a detector on the original images to capture key information. Stage-II: Forge uses this trained detector to create synthetic images. The process involves randomly initializing synthetic images, applying Foreground Background Decoupling and Incremental PatchExpand for enhancement, and optimizing these images using the detector’s loss function. Regularization ensures the quality of the generated images.
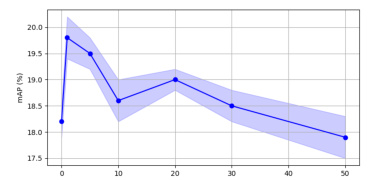
This figure shows the performance of the Random baseline method and the DCOD method as the compression ratio increases. The performance of the full dataset serves as the theoretical upper bound. When the ratio is below 5%, DCOD shows a significant advantage over the random method, while as the ratio exceeds 20%, the performance of both methods converge.

This figure visualizes the iterative process of synthesizing images using the DCOD method. The leftmost column shows the ground truth images with bounding boxes. Subsequent columns depict the synthetic image generation process at different iterations (0, 500, 1000, 2000, and 3000). Each synthetic image has a score indicating the quality of the synthesis, calculated based on the Intersection over Union (IOU) at 0.5 threshold using a trained YOLOv3-SPP model. The figure demonstrates how the model progressively refines the synthetic images over iterations, improving the accuracy of object detection.

This figure shows example images generated by the DCOD model. The top row (a) demonstrates that the model can generate images with a single object in the foreground. The bottom row (b) illustrates the model’s ability to generate images containing multiple objects of different classes, sizes, and shapes, all within a single image.

This figure shows a comparison of the performance of the Random baseline method and the DCOD method as the compression ratio increases. The performance of the full dataset, marked by a gray line, serves as the theoretical upper bound. When the ratio is below 5%, DCOD shows a significant advantage over the random method, while as the ratio exceeds 20%, the performance of both methods converge. The figure includes two subplots: one for mAP and one for AP@50, both plotted against the compression ratio. The x-axis represents the compression ratio (%), and the y-axis represents the mAP and AP@50, respectively. The performance of the full dataset is shown as a dashed horizontal line for comparison.
More on tables

This table presents the performance comparison of different dataset condensation methods (Random, Uniform, K-Center, Herding, and the proposed DCOD method) on the MS COCO dataset. The comparison is done at three different compression ratios (0.25%, 0.5%, and 1%), using the YOLOv3-SPP model for both condensation and evaluation. The metrics used are mAP, AP50, and AP75. The table demonstrates the effectiveness of the DCOD approach compared to other methods across different compression levels, showcasing its ability to maintain relatively high performance even at extremely low compression rates.
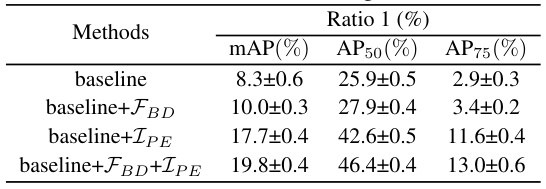
This table presents the results of an ablation study conducted on the Pascal VOC dataset using the YOLOv3-SPP model at a compression rate of 1%. The study evaluates the effectiveness of three components of the Forge stage: Foreground Background Decoupling (FBD), Incremental PatchExpand (IPE), and the combination of both. The results are reported in terms of mAP, AP50, and AP75.
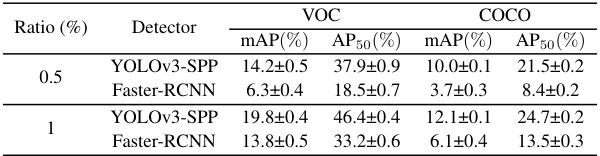
This table presents the performance of the DCOD method on Pascal VOC and MS COCO datasets using two different object detectors: YOLOv3-SPP (one-stage detector) and Faster R-CNN (two-stage detector). The results are shown for different compression ratios (0.5% and 1%). It demonstrates the generalizability of DCOD across different detector architectures.
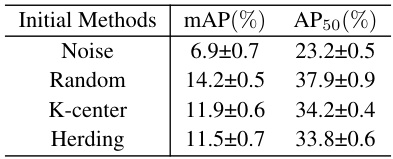
This table compares the performance of different initialization methods (Noise, Random, K-center, Herding) for dataset condensation on the Pascal VOC dataset using the YOLOv3-SPP model. The compression ratio is set to 0.5%. The results show the mAP and AP50 achieved by each initialization method, highlighting the impact of different initialization strategies on the model’s performance.
Full paper#

















