↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Domain generalization (DG) aims to enable models to generalize to unseen target domains. Existing DG methods using Convolutional Neural Networks (CNNs) suffer from limited receptive fields and overfitting. Transformer-based methods have high computational costs. State Space Models (SSMs) offer a potential solution, but their input-dependent matrices can amplify domain-specific features.
This paper proposes START, a novel SSM-based architecture that uses a saliency-driven token-aware transformation to address this issue. START selectively perturbs domain-specific features in salient tokens within the input-dependent matrices of SSMs, significantly improving generalization performance. Extensive experiments show START outperforms existing methods on five benchmark datasets with efficient linear complexity, offering a competitive alternative to CNNs and Vision Transformers.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in domain generalization due to its novel approach using state space models, theoretical analysis of generalization error, and empirical validation on multiple benchmarks. It opens avenues for efficient and effective domain generalization methods, impacting various computer vision tasks.
Visual Insights#

This figure analyzes how domain discrepancy accumulates in the input-dependent matrices of State Space Models (SSMs). It shows that these matrices, A, B, and C, accumulate domain-specific features during the recurrent process, leading to a larger domain gap between the source and target domains. The experiment uses the PACS dataset with Sketch as the target domain, examining the representations from the final layer of a VMamba model. The bar charts illustrate the domain distances in the input sequence (x), the output sequence (y), and the input-dependent matrices (A, B, C) for both a baseline model and two proposed methods (START-M and START-X), demonstrating how START-M and START-X reduce the domain discrepancies.

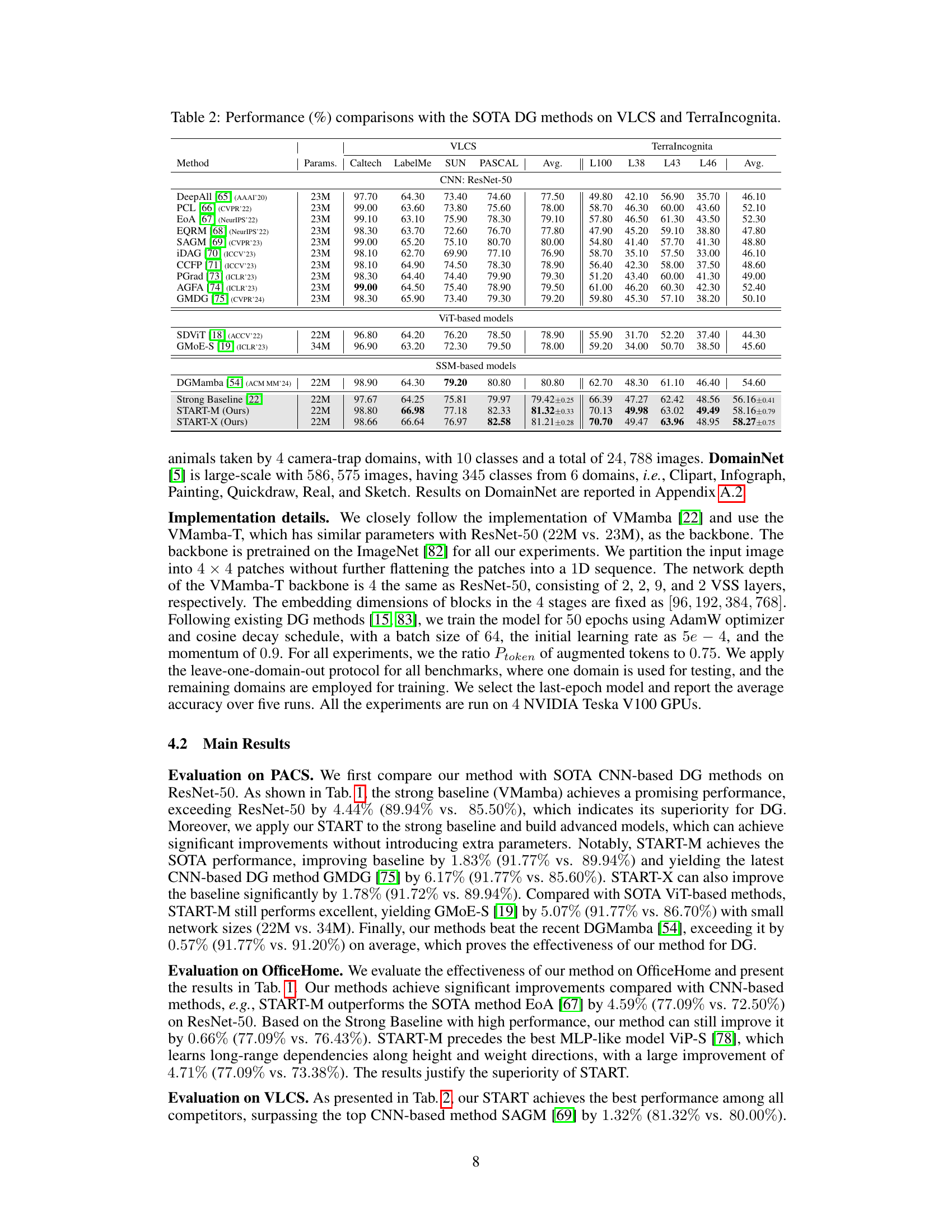
This table compares the performance of the proposed START model against state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. It shows the average performance across different domains within each dataset, allowing for a comparison of the methods’ ability to generalize to unseen target domains. The table includes the number of parameters for each model. It’s structured to facilitate comparison between different types of DG methods such as CNN-based, ViT-based, and SSM-based models.
In-depth insights#
SSM Generalization#
The core idea revolves around investigating the generalization capabilities of state space models (SSMs) in the context of domain generalization (DG). The authors explore how SSMs, known for their efficiency, might handle the challenges of unseen domains. A key finding is that the input-dependent matrices within SSMs can accumulate domain-specific information, hindering generalization. This accumulation effect is analyzed theoretically, revealing a potential amplification of domain biases. To overcome this limitation, a novel approach called START (Saliency-Driven Token-Aware Transformation) is introduced. START selectively perturbs and suppresses domain-specific features in salient tokens, thus improving the model’s robustness to domain shifts. The saliency-driven token selection is a crucial aspect, aiming to focus adjustments on the most relevant parts of the input. Experiments demonstrate that START achieves state-of-the-art performance on various DG benchmarks while maintaining linear computational complexity. The work highlights a trade-off between efficiency and generalization in SSMs and provides a compelling solution.
START Architecture#
The START architecture, a novel SSM-based model for domain generalization, tackles the limitations of CNNs and ViTs by introducing a saliency-driven token-aware transformation. It cleverly addresses the issue of input-dependent matrices accumulating domain-specific features in SSMs, which hinders generalization. By identifying salient tokens using either input-dependent matrices (START-M) or input sequences (START-X), START selectively perturbs and suppresses domain-specific information in those tokens. This targeted approach effectively reduces domain discrepancy and enhances the learning of domain-invariant representations, leading to improved generalization performance on unseen domains. The linear time complexity during training and fast inference capabilities of START make it a computationally efficient and competitive alternative to existing SOTA DG methods. The theoretical analysis provides a strong foundation for the design, validating the effectiveness of the proposed saliency-driven mechanism in mitigating the accumulation of domain-specific information. This results in a robust model that achieves state-of-the-art performance while maintaining efficiency.
Saliency-driven DG#
Saliency-driven domain generalization (DG) offers a novel approach to address the challenges of model overfitting to source domains in unseen target domains. By focusing on salient features, which are deemed more discriminative and less domain-specific, the method effectively mitigates the accumulation of domain-specific biases during training. This approach leverages the model’s inherent ability to identify and prioritize important visual information, reducing the reliance on less informative, domain-biased characteristics. This targeted approach promises to enhance generalization performance while maintaining computational efficiency, thus providing a valuable alternative to existing DG techniques. The core idea is to selectively perturb or suppress domain-specific features in these salient regions, thereby reducing discrepancies between source and target domains and thus improving the model’s generalization capability to unseen domains. The effectiveness of this approach hinges on the accuracy and reliability of the saliency detection method. The success of saliency-driven DG also depends on the careful selection of which saliency method is employed and the type of transformations applied to the selected features. A robust saliency map generation process is crucial for the success of this methodology.
Mamba Analysis#
A hypothetical ‘Mamba Analysis’ section in a research paper would likely delve into a state-space model’s (SSM) performance characteristics, particularly focusing on its generalization capabilities under domain shifts. The analysis would likely investigate how input-dependent matrices within the Mamba model accumulate and amplify domain-specific features, potentially hindering generalization. Key aspects would involve theoretical analysis of generalization error bounds, perhaps using techniques like Maximum Mean Discrepancy (MMD), to quantify the impact of domain-specific information. Empirical evaluations would showcase the model’s performance across multiple benchmark datasets with varying domain shifts. The analysis should also compare the computational complexity of Mamba against traditional CNNs and Transformers, highlighting its efficiency advantages. Finally, it might include ablation studies to dissect the model’s components, examining the contributions of specific modules like saliency-driven token-aware transformations to overall generalization performance.
Future of START#
The “Future of START” holds significant promise in domain generalization. Improved saliency models could refine token selection, enhancing the model’s ability to identify and suppress domain-specific features more effectively. Exploration of diverse architectures beyond state-space models, such as incorporating START’s principles into transformer-based models, could unlock further performance gains. Theoretical investigation into the optimal perturbation strategies and their impact on generalization error bounds is crucial. Applications to other challenging domains (e.g., medical imaging, time-series data analysis) and tasks (e.g., object detection, semantic segmentation) would demonstrate START’s wider applicability. Addressing limitations such as robust saliency calculations across diverse data distributions will be critical. Efficient implementations for resource-constrained scenarios would enhance START’s practicality. Ultimately, a focus on theoretical underpinnings alongside empirical validation will propel the advancement of START as a powerful tool in domain generalization.
More visual insights#
More on figures

The figure illustrates the overall architecture of the proposed START framework. The framework’s core is the Saliency-driven Token-Aware Transformation module, which uses a saliency-driven method to identify tokens in the input sequence that are heavily influenced by the model’s input-dependent matrices (A, B, C). Domain-specific style information within these identified tokens is then perturbed. Two variants are presented: START-M, which uses the input-dependent matrices themselves to calculate saliency, and START-X, which uses the input sequences directly. The process involves calculating saliency scores, selecting salient tokens based on these scores, and then replacing the selected tokens with style-perturbed versions via style interpolation. The final output is an augmented sequence that incorporates the style perturbations.
This figure illustrates the overall architecture of the START framework, focusing on the core component: Saliency-driven Token-Aware Transformation. This transformation uses a saliency-driven method to identify tokens within input-dependent matrices that are heavily influenced by domain-specific style information. These tokens are then selectively perturbed to encourage the model to learn more domain-invariant features. The figure highlights two variants: START-M, using the input-dependent matrices directly for saliency calculation, and START-X, which uses the input sequences for saliency estimation.
The figure illustrates the overall architecture of the proposed START framework for domain generalization. It highlights the core component, the Saliency-driven Token-Aware Transformation. This transformation identifies salient tokens within the input (using either input-dependent matrices – START-M – or the input sequence itself – START-X) and selectively perturbs these tokens to reduce domain-specific style information. This process aims to make the model more robust to domain shifts by focusing on domain-invariant features.
More on tables
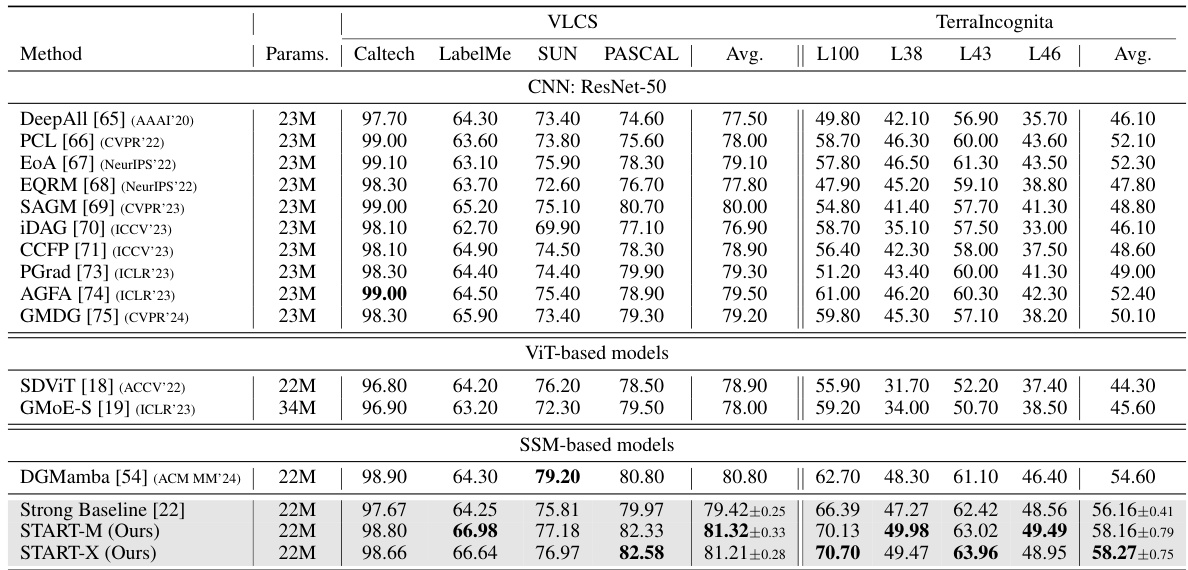
This table presents the performance comparison of the proposed START method with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the accuracy (%) achieved by each method on different domains within each dataset, providing a comprehensive evaluation of the model’s generalization ability across various visual domains. The results are crucial for demonstrating the superiority of START over existing methods.
This table compares the performance of the proposed START model with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the accuracy (%) achieved by each method on various subsets of each dataset. It allows for a comparison of different approaches, including those based on CNNs, ViTs, and SSMs. The performance is broken down by domain within each dataset, along with an average accuracy across all domains. The number of parameters used by each model is also included for reference.

This table compares the performance of the proposed START method with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the accuracy (%) achieved by each method on each of the sub-domains within each dataset, as well as an average accuracy across all sub-domains. It allows for a comparison of different approaches, including those based on Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and State Space Models (SSMs). The number of parameters for each model is also provided, allowing comparison of model complexity.
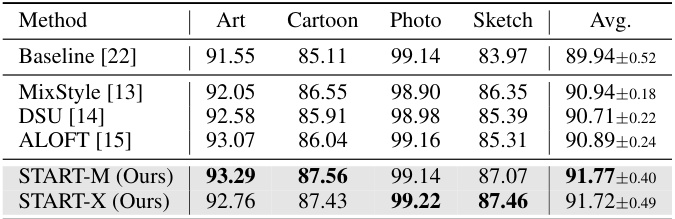
This table presents a comparison of the proposed START model’s performance against state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The results are shown in terms of accuracy percentages, broken down by individual domain and averaged across all domains. The table allows for a direct comparison of the proposed method against various existing approaches based on CNNs and ViTs, highlighting the relative strengths and weaknesses of each method in terms of accuracy and parameter count.

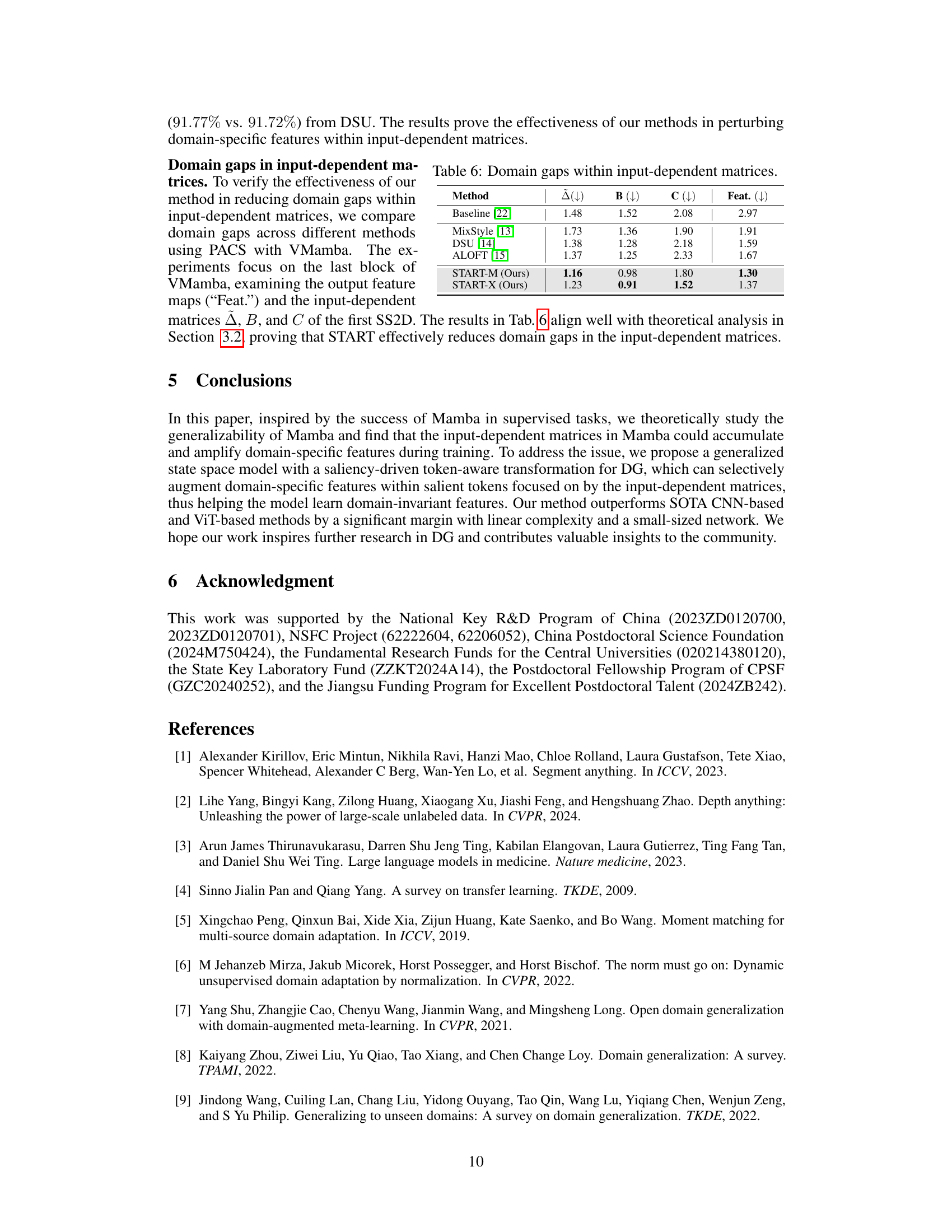
This table shows a comparison of domain gaps within input-dependent matrices (Δ, B, C) and feature maps (Feat.) across different methods. Lower values indicate smaller domain gaps, suggesting better generalization ability. The methods compared include a baseline and several state-of-the-art domain generalization techniques alongside the proposed START methods (START-M and START-X). The results demonstrate that START-M and START-X effectively reduce the domain discrepancy in input-dependent matrices, thus improving the model’s generalization performance.
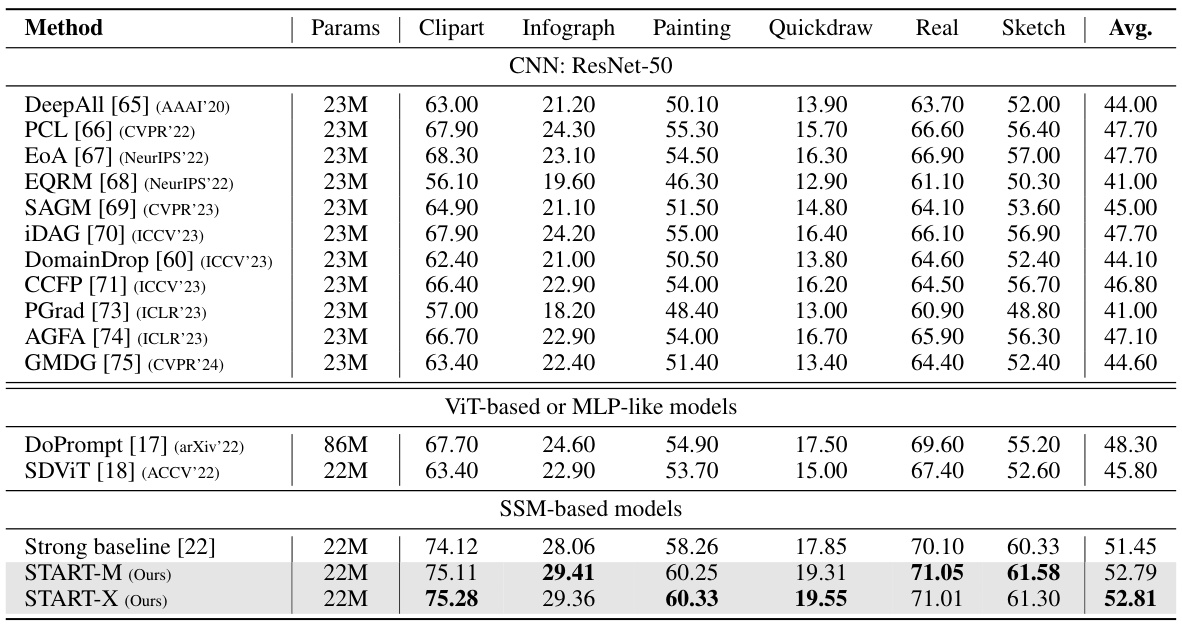
This table compares the performance of the proposed START model against state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the average accuracy (%) achieved by each method across different domains within each dataset. The comparison highlights START’s performance relative to other methods based on different architectures (CNNs, ViTs, and SSMs). Parameters (number of parameters in millions) are also provided for each model.
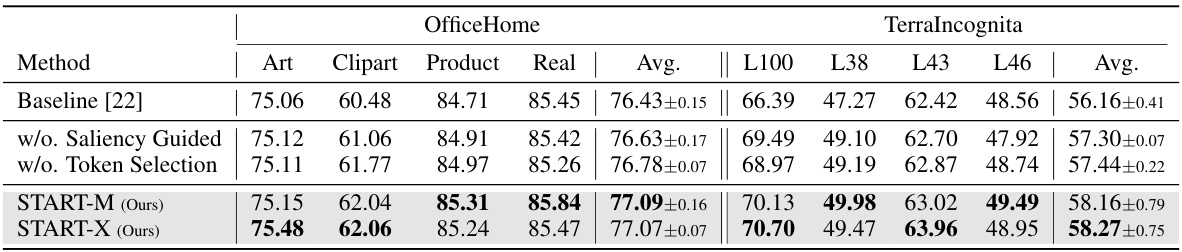
This table presents a comparison of the proposed START model’s performance against state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the average accuracy across different domains (Art, Cartoon, Photo, Sketch for PACS; Art, Clipart, Product, Real for OfficeHome) as well as the number of model parameters for each method. This allows for a comparison of both accuracy and computational efficiency between different approaches to domain generalization.

This table compares the performance of the proposed START method with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the accuracy (%) achieved by each method on different domains within each dataset. It also provides information on the number of parameters (Params) used by each model. The results demonstrate the effectiveness of START compared to existing CNN-based, ViT-based, and SSM-based methods.

This table compares the performance of the proposed START model with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the average accuracy achieved by each method across different domains within each dataset. Metrics include accuracy for individual domains (Art, Cartoon, Photo, Sketch for PACS; Art, Clipart, Product, Real for OfficeHome) and an average accuracy across all domains within each dataset.

This table compares the performance of the proposed START method against state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. It shows the accuracy (%) achieved by each method on different domains within each dataset. The table also includes the number of parameters (Params) for each method. The average accuracy across all domains is also reported (Avg.). The results demonstrate the superior performance of the START method compared to existing SOTA approaches.

This table compares the performance of the proposed START method with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the accuracy (%) achieved by each method on different subsets (Art, Cartoon, Photo, Sketch for PACS; Art, Clipart, Product, Real for OfficeHome) and the average accuracy across all subsets. The ‘Params’ column indicates the number of model parameters.

This table presents a comparison of the proposed START method’s performance with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. The table shows the average accuracy (%) achieved by each method across different domains within each dataset. The performance metrics include accuracy on individual domains as well as an average accuracy across all domains. This allows for a direct comparison of the effectiveness of the different DG approaches in handling domain shift and generalization to unseen domains. The table includes the number of parameters (Params) for each model, indicating model complexity.
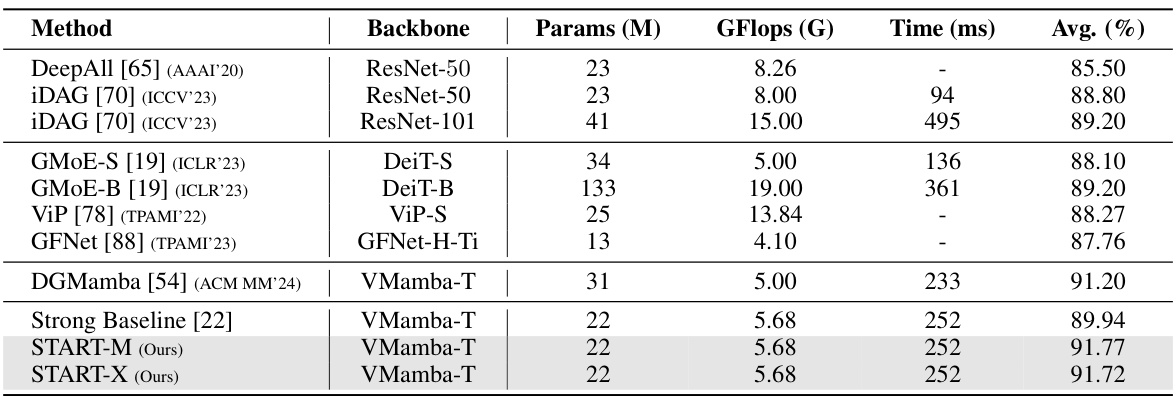
This table compares the performance of the proposed START method with state-of-the-art (SOTA) domain generalization (DG) methods on two benchmark datasets: PACS and OfficeHome. It shows the average accuracy across multiple domains for each method, along with the number of parameters used by each model. The table helps illustrate the effectiveness of START compared to other existing techniques in terms of accuracy and computational efficiency. The results are broken down by domain within each dataset to give a more detailed view of the model performance across diverse visual characteristics.
Full paper#