↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Language models (LMs) typically underperform on domain-specific tasks due to their inability to effectively learn “long-tail” domain knowledge (rarely occurring data). This necessitates costly and time-consuming domain-specific pretraining. This paper addresses this issue by exploring the limitations of existing pretrained LMs in handling long-tail knowledge, particularly the challenge of gradient conflicts between long-tail data and common data.
To solve the issues, this paper proposes a Cluster-guided Sparse Expert (CSE) layer that actively learns long-tail knowledge. CSE efficiently groups similar data into clusters, assigning long-tail data to designated experts. The results show that incorporating CSE significantly improves LM performance on downstream tasks without additional domain-specific pretraining, indicating that domain-specific pretraining might be unnecessary. The proposed CSE approach is computationally efficient and easily integrable, offering a valuable tool for improving language model performance.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional wisdom in natural language processing by demonstrating that domain-specific pretraining might be unnecessary. It introduces a novel method to improve the performance of language models on long-tail domain knowledge, opening new avenues for research and potentially reducing the cost and time associated with pretraining.
Visual Insights#
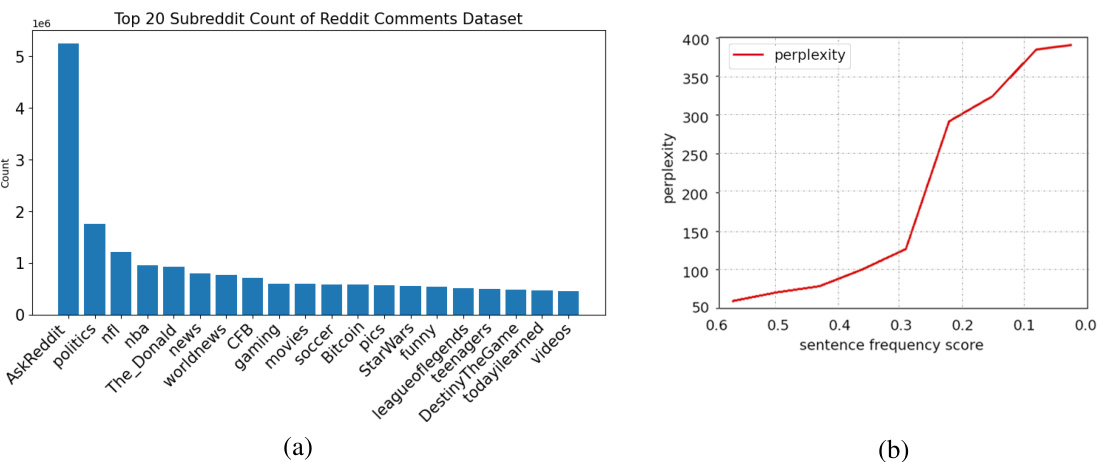
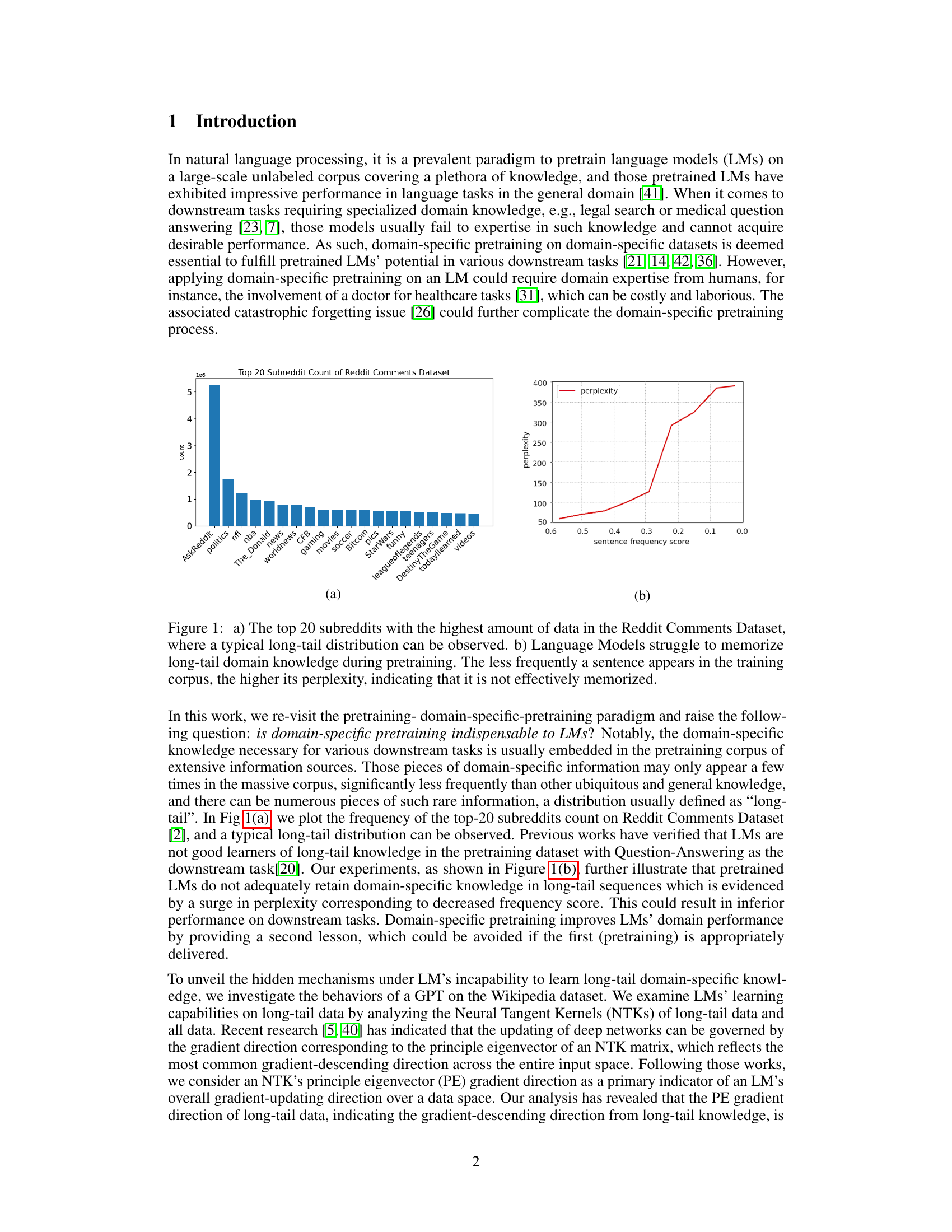
This figure shows two subfigures. Subfigure (a) is a bar chart illustrating the top 20 subreddits in the Reddit Comments Dataset, demonstrating a long-tail distribution where a few subreddits have a significantly higher number of comments than the vast majority. Subfigure (b) is a line graph showing the relationship between sentence frequency and perplexity in language models. It indicates that as the frequency of a sentence in the training corpus decreases (long-tail data), its perplexity (a measure of how well the model predicts the sentence) increases, illustrating the difficulty language models have in memorizing less frequent domain-specific knowledge.

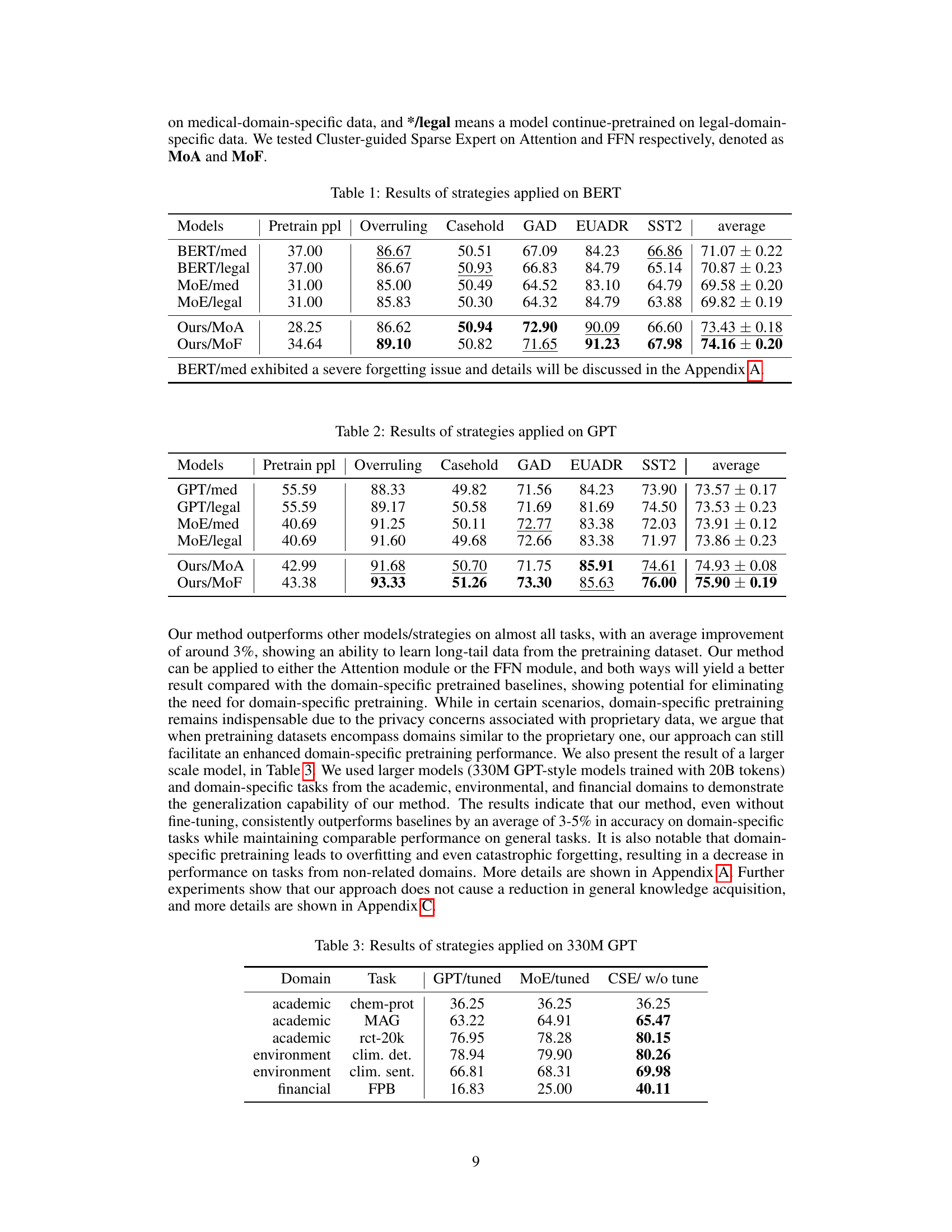
This table presents the results of different strategies applied to the BERT model. It compares the performance of a BERT model that underwent additional medical and legal domain-specific pretraining with a BERT model incorporating the Cluster-guided Sparse Expert (CSE) layer (Ours/MoA and Ours/MoF). The performance metrics include overall perplexity, as well as the accuracy scores across several downstream tasks: Overruling, Casehold, GAD, EUADR, and SST2. The average accuracy across all five tasks is also provided for each model variant.
In-depth insights#
Long-Tail Learning#
Long-tail learning tackles the challenge of imbalanced data distributions where a few classes dominate, while many others have scarce samples. This is particularly relevant in natural language processing where vocabulary and concepts exhibit long-tail distributions. Traditional machine learning models often struggle with such data, failing to generalize well to the less-frequent classes. The core of the problem lies in the model’s bias towards frequently-occurring instances, leading to suboptimal performance on the long tail. Addressing this involves techniques like data augmentation, re-weighting of samples, cost-sensitive learning, and specialized architectures such as mixture-of-experts. These methods aim to either balance the class distribution, increase the representation of infrequent classes, or design models capable of efficiently handling diverse data densities. The choice of approach depends heavily on the specific application and data characteristics. Successfully tackling long-tail challenges in NLP is crucial for enhancing model robustness and overall capability, opening possibilities for improved performance in real-world scenarios with naturally skewed data.
CSE Layer Design#
The Cluster-guided Sparse Expert (CSE) layer is a novel architecture designed to enhance the learning of long-tail knowledge in language models. Its core innovation lies in efficiently clustering semantically similar data points in the embedding space and assigning them to dedicated sparse experts. This approach directly addresses the challenge of gradient conflicts between long-tail and frequent data during pretraining, which prevents effective learning of less common, domain-specific information. The design is computationally efficient, requiring only the addition of a lightweight structure to existing layers. Furthermore, the dynamic clustering mechanism adapts to shifts in the embedding space during training, maintaining the effectiveness of the layer throughout the learning process. The overall strategy promotes improved learning of long-tail knowledge without requiring costly domain-specific pretraining. By actively organizing and channeling this knowledge to specialized experts, the CSE layer enables language models to achieve better performance on downstream tasks requiring specialized domain expertise.
Gradient Analysis#
Gradient analysis, in the context of this research paper, likely involves investigating the gradient flow during the training of language models. This could include analyzing how gradients from different data subsets, particularly long-tail data, behave during optimization. The goal would be to understand why language models struggle to effectively memorize domain-specific knowledge embedded in the general corpus with rare occurrences, often exhibiting inferior downstream performance. The analysis may use techniques like Neural Tangent Kernel (NTK) analysis to quantify the effect of long-tail data on the gradient updates. This involves assessing the alignment of gradient directions, which could be represented by metrics like Gradient Consistency (GC). A low GC for long-tail data suggests that their semantic information is poorly integrated into the model’s overall representation. This analysis would thus form a crucial part of the justification for introducing the Cluster-guided Sparse Expert (CSE) layer. NTK analysis potentially reveals that long-tail data have weak influence on gradient updates, explaining their inadequate memorization. Overall, gradient analysis provides a quantitative and qualitative understanding of the challenges in learning from long-tail data, thereby informing the design of new learning strategies.
Dynamic Clustering#
Dynamic clustering in the context of language model training involves analyzing how data clusters evolve during the learning process. This is crucial for understanding how models handle long-tail knowledge, which is often poorly represented in standard language models. The emergence of distinct clusters, particularly long-tail data clusters, can indicate successful model adaptation to nuanced domain-specific information. The observation of isolated, outlier clusters in the embedding space is particularly insightful, as it suggests that a model has successfully separated less frequent, but semantically coherent, data from more common information. The interaction between cluster dynamics and model depth is also of key interest. Analyzing this dynamic helps to understand how semantic understanding refines over layers, potentially revealing how models transition from general to more specific representations. A crucial aspect is analyzing how these cluster dynamics impact downstream task performance; consistent clustering of domain-specific knowledge should correlate with superior results.
Future of Pretraining#
The “Future of Pretraining” in language models points towards a paradigm shift away from massive, general-purpose pretraining towards more targeted and efficient approaches. This involves leveraging techniques such as cluster-guided sparse experts to focus learning on specific, long-tail domain knowledge often neglected by generic pre-training. Future research will likely concentrate on improving the efficiency of knowledge acquisition, potentially reducing reliance on massive datasets and computational resources. Methods focusing on aligning gradient updates with long-tail data will be further developed. The goal is to create models capable of effectively leveraging domain-specific knowledge without extensive, costly pretraining. Furthermore, a key challenge will be balancing the benefits of specialized pretraining against maintaining generalizable performance, finding an optimal trade-off that maximizes both domain expertise and general understanding.
More visual insights#
More on figures

Figure 2(a) shows the negative correlation between the frequency of a sentence and its gradient consistency in the baseline model. Sentences that appear infrequently in the dataset show low gradient consistency, indicating that the model struggles to capture their learning dynamics effectively. Figure 2(b) illustrates the embedding space of a model with the Cluster-guided Sparse Expert (CSE) layer. The figure highlights four distinct long-tail clusters along with a more central cluster of common data. Each long-tail cluster contains semantically similar sentences from a specific domain.
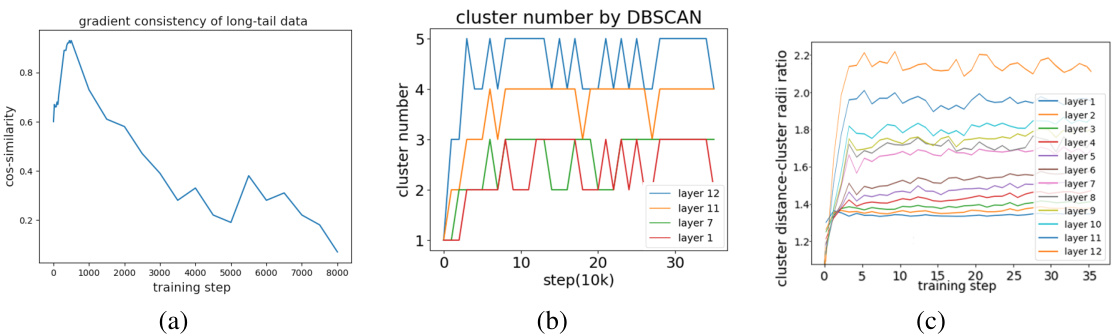
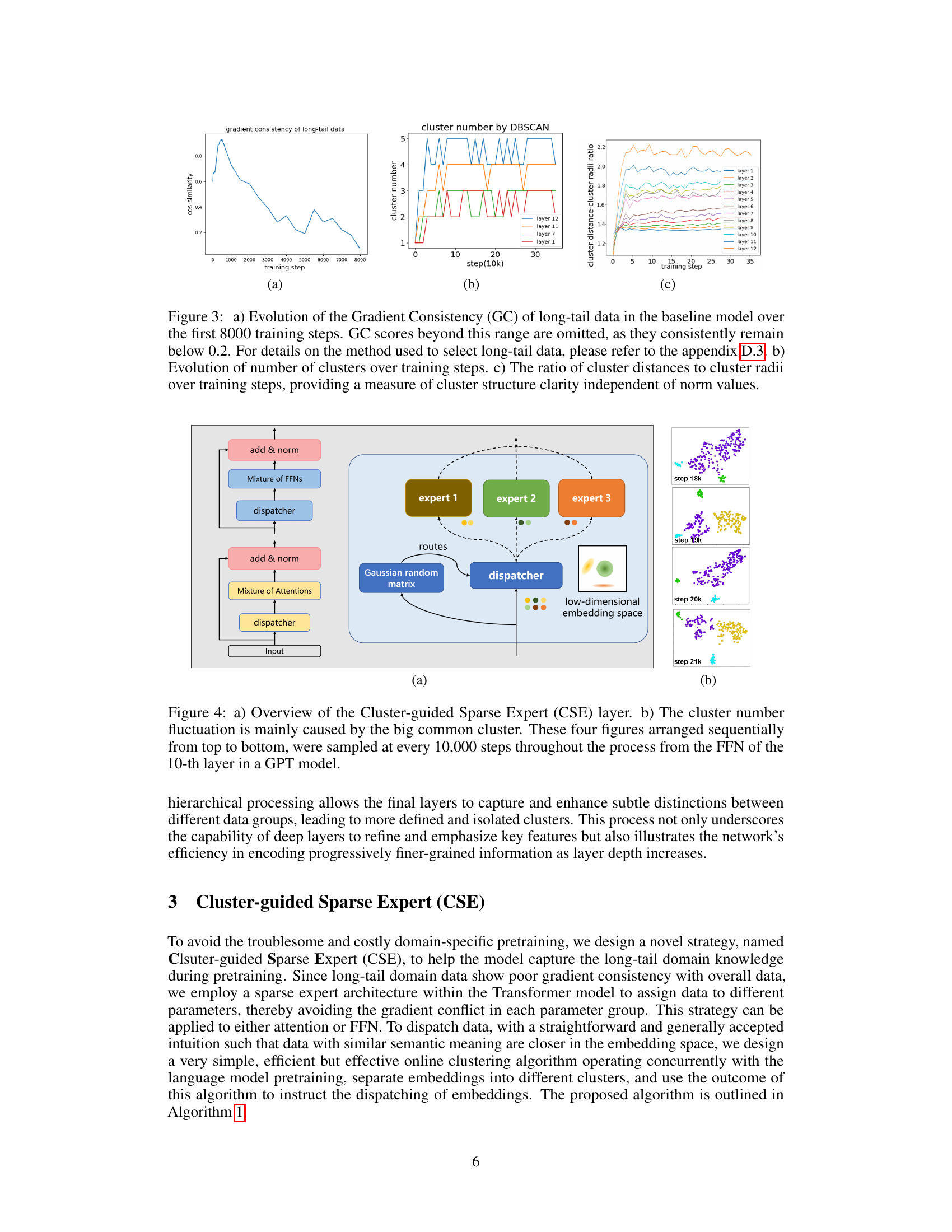
This figure shows the evolution of gradient consistency (GC) of long-tail data, the number of clusters, and the ratio of cluster distances to cluster radii over training steps in a baseline model. Panel (a) demonstrates the decreasing GC of long-tail data over time. Panels (b) and (c) illustrate the dynamic evolution of cluster formation and structure throughout training. The number of clusters changes, and their relative compactness shifts over time. The changes in cluster structure clarity independent of norm values suggest an evolution in how the model learns and groups the long-tail data over the course of training.

This figure illustrates the Cluster-guided Sparse Expert (CSE) layer architecture. Subfigure (a) shows the overall CSE layer structure, highlighting the dispatcher mechanism that routes input embeddings to different sparse experts. Subfigure (b) visualizes the cluster evolution in the embedding space during the training process, showing how clusters form and evolve across different training steps (sampled every 10,000 steps from the 10th layer’s FFN in a GPT model). The evolution showcases the dynamic nature of clustering, with the formation and merging of clusters, particularly driven by a large common cluster.
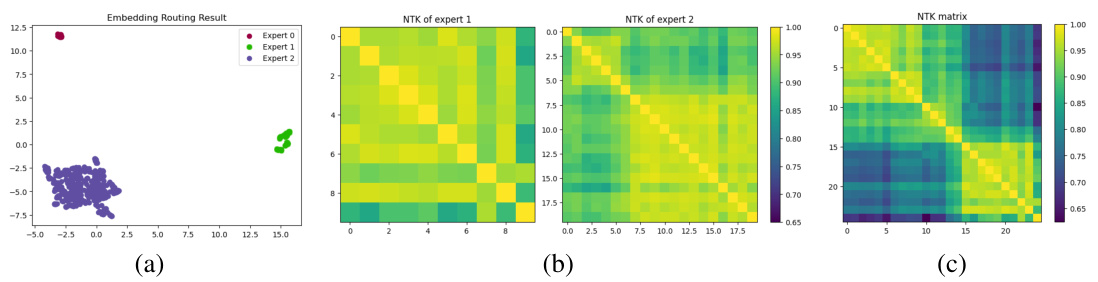
This figure visualizes the embedding space and neural tangent kernel (NTK) analysis of the proposed Cluster-guided Sparse Expert (CSE) model. Panel (a) shows the embedding space, illustrating how the CSE layer effectively clusters and routes long-tail data to designated experts. Panels (b) and (c) present NTK matrices for the CSE model (experts 1 and 2) and the baseline model, respectively, demonstrating that the CSE model achieves more consistent NTK within each expert, unlike the baseline.

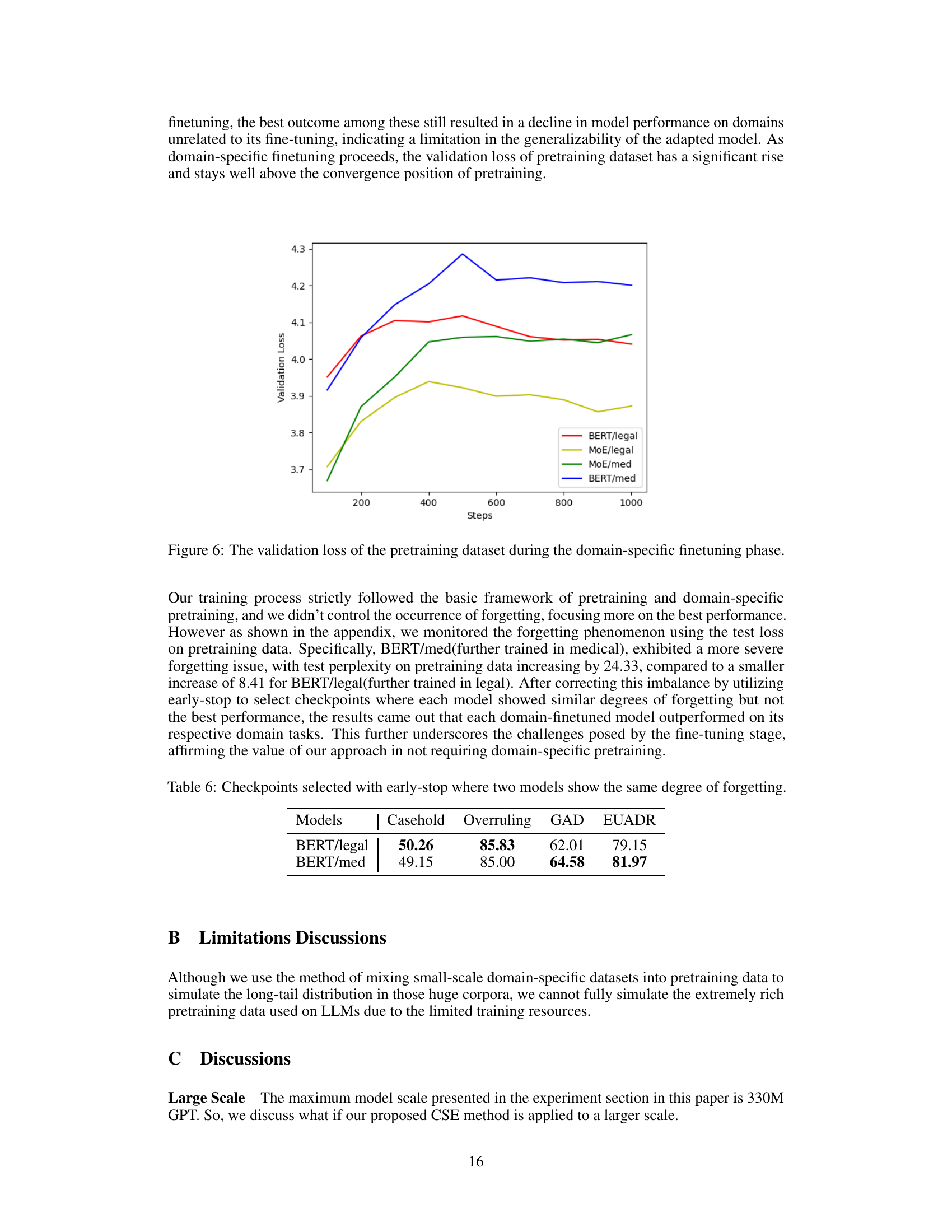
This figure shows the validation loss of the pretraining dataset during the domain-specific finetuning phase for four different models: BERT/legal, MoE/legal, MoE/med, and BERT/med. The x-axis represents the training steps, and the y-axis represents the validation loss. The plot illustrates the phenomenon of catastrophic forgetting, where the model’s performance on the pretraining dataset degrades significantly as it is further fine-tuned on the domain-specific tasks. Notice that the models fine-tuned on medical data show a greater increase in validation loss than those fine-tuned on legal data. This highlights the challenges posed by domain-specific finetuning on pretrained language models.
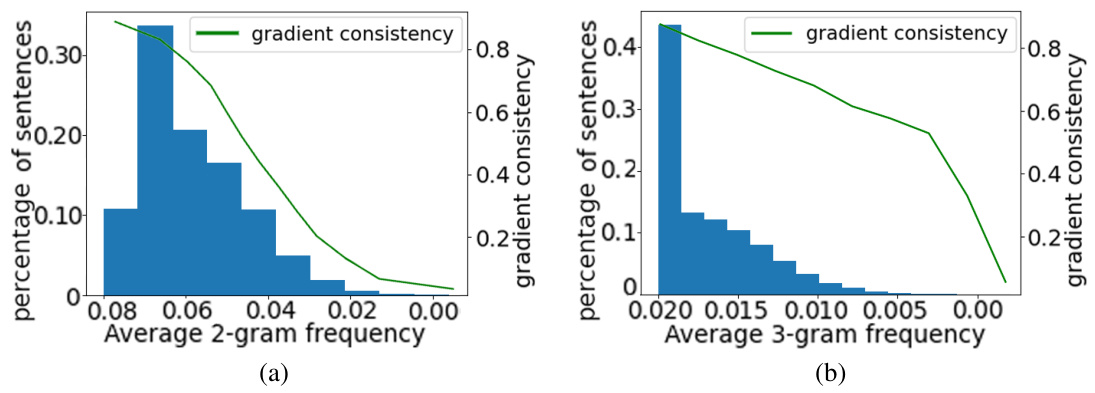
The figure shows the frequency distribution of sentences based on their 2-gram and 3-gram patterns, respectively. The distributions are shown as histograms, with the x-axis representing the average frequency and the y-axis representing the percentage of sentences. A second line graph shows the gradient consistency for each frequency range. The results confirm that the 1-gram method used earlier is robust, as the gradient consistency aligns with the frequency trends across 2-gram and 3-gram analysis.
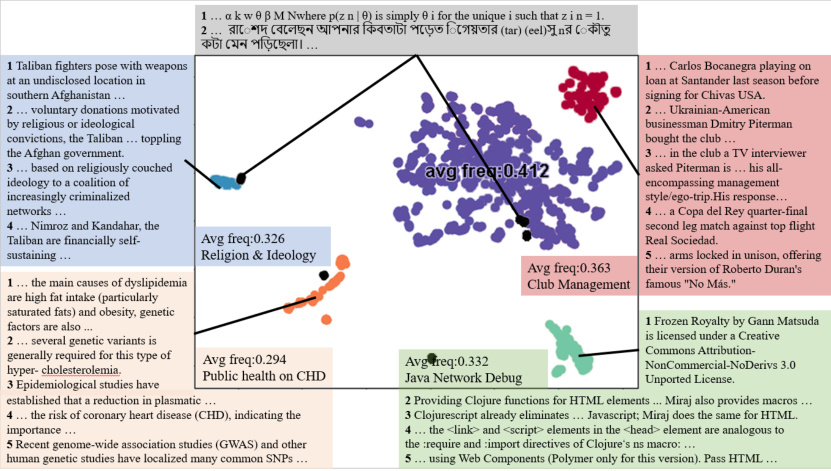
This figure visualizes the content of sentences within different clusters identified by the CSE layer. It demonstrates that sentences within the same cluster share semantic similarity, indicating the effectiveness of the clustering approach. The figure also highlights the presence of low-frequency, irregular sentences that are scattered across clusters, lacking clear semantic coherence. This observation supports the paper’s argument that CSE effectively groups semantically similar sentences, even those with low frequency, improving the language model’s ability to learn long-tail knowledge.
More on tables
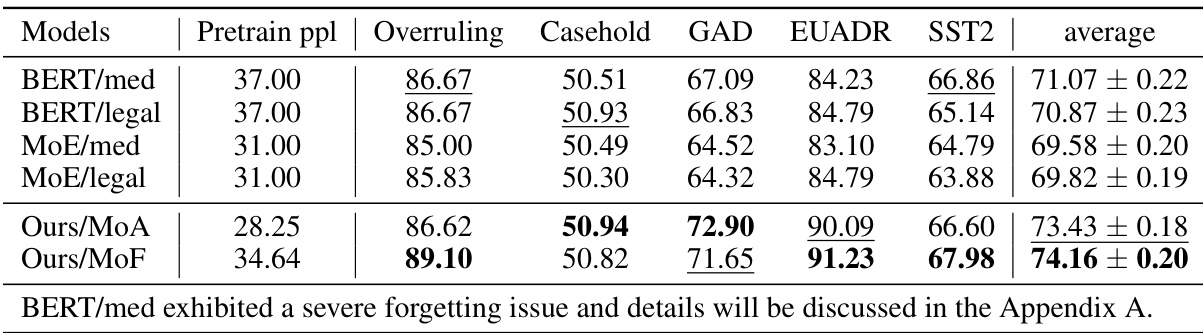
This table presents the results of different strategies applied to the BERT model. The strategies include continuing pretraining on medical and legal domain-specific data (BERT/med and BERT/legal), using a Mixture of Experts (MoE) approach (MoE/med and MoE/legal), and applying the proposed Cluster-guided Sparse Expert (CSE) method (Ours/MoA and Ours/MoF). The table shows the pretraining perplexity (Pretrain ppl), and the performance on several downstream tasks (Overruling, Casehold, GAD, EUADR, SST2), along with average performance across tasks. Note that BERT/med shows a significant forgetting issue, which is discussed in the Appendix. The results highlight the effectiveness of the CSE approach in improving performance on downstream tasks compared to other methods.

This table presents the results of different strategies applied to the GPT model. The strategies include using a GPT model fine-tuned on medical data (GPT/med), a GPT model fine-tuned on legal data (GPT/legal), a MoE (Mixture of Experts) model fine-tuned on medical data (MoE/med), a MoE model fine-tuned on legal data (MoE/legal), and the proposed CSE (Cluster-guided Sparse Expert) method applied to the attention mechanism (Ours/MoA) and the feed-forward network (Ours/MoF). The table shows the average performance across several downstream tasks, including the perplexity scores, and the performance on the Overruling, Casehold, GAD, EUADR, and SST2 datasets. The results highlight the performance improvement using the CSE approach.
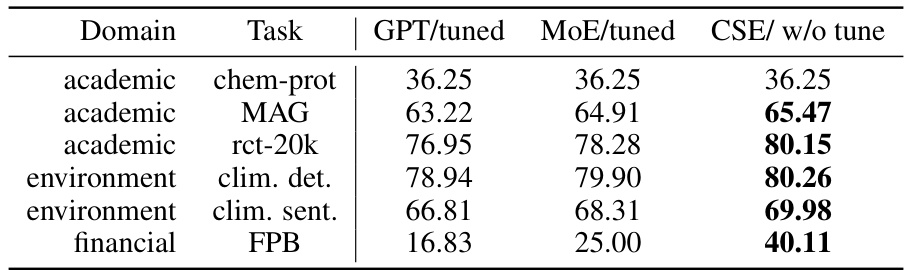
This table presents the performance comparison of different methods (GPT/tuned, MoE/tuned, and CSE/w/o tune) on various downstream tasks using a larger 330M GPT model. It shows the accuracy achieved on multiple tasks across three domains: academic, environment, and financial. Notably, CSE/w/o tune showcases performance on par or exceeding the other methods without requiring any domain-specific fine-tuning. This highlights its ability to learn from long-tail data efficiently during pretraining alone.
This table presents the results of different strategies applied to the BERT model. It compares the performance of the baseline BERT model (with and without further training on medical and legal datasets) against a model using the proposed Cluster-guided Sparse Expert (CSE) approach. The performance is measured across several downstream tasks, including Overruling, Casehold, GAD, EUADR, and SST2, with the average performance across all these tasks also included.
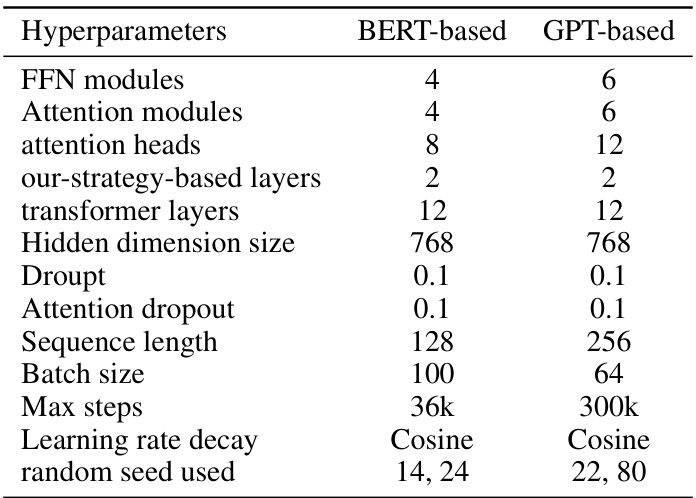
This table lists the hyperparameters used for both BERT-based and GPT-based models in the experiments. It details the settings for various aspects of the model architecture and training process, including the number of FFN and attention modules, attention heads, transformer layers, hidden dimension size, dropout rates, sequence length, batch size, maximum training steps, learning rate decay strategy, and the random seed used. These hyperparameters were crucial in configuring and training the models for the experimental results presented in the paper.

This table displays the results of the Casehold, Overruling, GAD, and EUADR tasks using checkpoints selected by an early-stopping method that controls for catastrophic forgetting. The early stopping ensures that both BERT/legal and BERT/med models exhibit a similar level of forgetting on the pretraining data, enabling a more fair comparison of their performance on the downstream tasks.
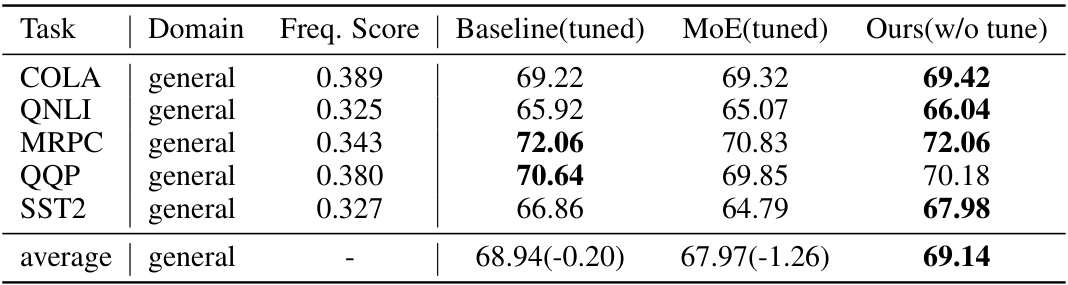
This table presents the results of several general knowledge tasks using BERT models. It compares the performance of a baseline BERT model (fine-tuned), a MoE (Mixture of Experts) version of BERT (fine-tuned), and the proposed CSE (Cluster-guided Sparse Expert) method without fine-tuning. The comparison is based on accuracy scores, frequency scores for the tasks, and the average performance across all the tasks. This table aims to demonstrate that even without fine-tuning, the CSE method can achieve comparable or better performance on general tasks, highlighting its effectiveness in learning long-tail domain knowledge while retaining general capabilities.
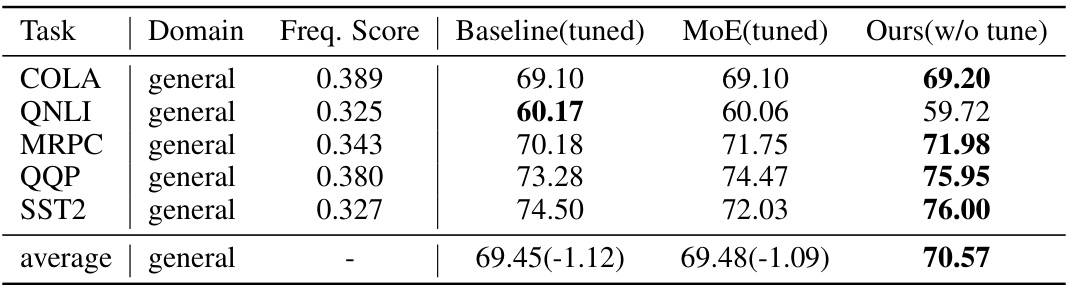
This table presents the results of general knowledge tasks evaluated on a larger GPT model (330M parameters) trained with 20 billion tokens. It compares the performance of a baseline model, a Mixture of Experts (MoE) model, and the proposed Cluster-guided Sparse Expert (CSE) model without any fine-tuning. The table shows the accuracy scores for each task (COLA, QNLI, MRPC, QQP, SST2), along with the average frequency score of the sentences used in those tasks and the overall average accuracy of each method.

This table presents the results of different strategies applied to a pre-trained 110M model. The strategies include continuing pretraining on medical data (/med), continuing pretraining on legal data (/legal), using a Mixture of Experts (MoE) architecture, and the proposed Cluster-guided Sparse Expert (CSE) approach (Ours/MoA and Ours/MoF). The table shows the performance of each strategy across various downstream tasks (Overruling, Casehold, GAD, EUADR, SST2), along with the average performance. It highlights the improvement achieved by the CSE approach compared to the baseline methods and MoE.

This table presents the results of different strategies applied to the BERT model. The strategies include using a BERT model fine-tuned on medical data (BERT/med), a BERT model fine-tuned on legal data (BERT/legal), a MoE (Mixture of Experts) model fine-tuned on medical data (MoE/med), a MoE model fine-tuned on legal data (MoE/legal), the proposed Cluster-guided Sparse Expert (CSE) model applied to the attention mechanism (Ours/MoA), and the proposed CSE model applied to the feed-forward network (Ours/MoF). The table shows the pretraining perplexity (Pretrain ppl) and the performance on several downstream tasks: Overruling, Casehold, GAD, EUADR, and SST2. The average performance across all tasks is also included for comparison.
Full paper#