TL;DR#
Autonomous driving heavily relies on accurate motion forecasting, which is significantly enhanced by integrating data from other vehicles and infrastructure (V2X). Current methods primarily focus on single-frame cooperative perception, under-utilizing motion and interaction contexts. This paper tackles this issue.
The proposed V2X-Graph framework uses a graph-based approach for cooperative trajectory feature fusion. It encodes motion and interaction features from multiple perspectives, creating an interpretable graph that guides the fusion process. Evaluated on V2X-Seq and the new V2X-Traj dataset (the first real-world V2X dataset), V2X-Graph demonstrates superior performance compared to state-of-the-art methods, improving the accuracy and interpretability of cooperative motion forecasting. This work significantly advances the field of cooperative motion forecasting by providing both a novel approach and a valuable new dataset.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing cooperative motion forecasting methods by proposing a novel framework, V2X-Graph, that leverages motion and interaction features from cooperative information more effectively. It also introduces a new real-world dataset, V2X-Traj, which will advance research in this field. The improved accuracy and interpretability offered by V2X-Graph will be highly valuable for autonomous driving development and other applications of cooperative perception. This work opens new avenues for investigating more sophisticated methods for trajectory prediction in complex scenarios.
Visual Insights#

🔼 This figure compares two approaches to cooperative motion forecasting. (a) shows existing methods that use cooperative perception information frame-by-frame, which limits the use of motion and interaction contexts. (b) presents the proposed V2X-Graph, which uses a forecasting-oriented approach with interpretable trajectory feature fusion to improve historical representation of agents and enhance forecasting accuracy.
read the caption
Figure 1: Scheme Comparison. (a) Existing methods utilize cooperative perception information at each frame individually then performs forecasting. (b) Our V2X-Graph considers this information from a typical forecasting perspective and employs interpretable trajectory feature fusion in an end-to-end manner, to enhance the historical representation of agents for cooperative motion forecasting.

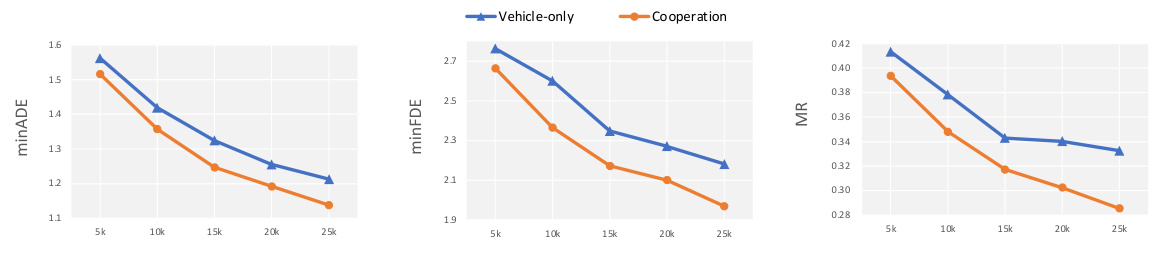
🔼 This table compares the performance of three different methods on the V2X-Seq dataset: DenseTNT, HiVT, and V2X-Graph. Each method is evaluated under three conditions: using only vehicle data, using vehicle data with perception information from infrastructure added using PP-VIC, and using V2X-Graph’s feature fusion. The metrics used for comparison are minADE, minFDE, and MR.
read the caption
Table 1: Cooperative method comparison on V2X-Seq.
In-depth insights#
Coop Forecasting#
Cooperative forecasting, or “Coop Forecasting,” in autonomous driving leverages data from multiple sources to enhance prediction accuracy. This approach goes beyond single-vehicle perception by incorporating information from Vehicle-to-Everything (V2X) communication, infrastructure sensors, and other vehicles. The key advantage lies in the ability to compensate for individual vehicle limitations. A single autonomous vehicle might have occluded views or limited sensing range, but cooperative forecasting can integrate diverse perspectives to build a more robust understanding of the traffic environment. Successful Coop Forecasting demands efficient data fusion techniques capable of handling the heterogeneous nature of V2X data (sensor types, data rates, and latency). Interpretable methods, where the contributions of different data sources are transparent, are highly valuable for debugging, validation and building trust in autonomous systems. Furthermore, the creation and use of high-quality cooperative datasets are critical for training and evaluating these models. Real-world datasets should capture complex interactions and various traffic scenarios to prepare autonomous vehicles for unpredictable situations. Ultimately, effective Coop Forecasting is essential for achieving safe and efficient autonomous driving in dynamic environments.
V2X-Graph Design#
The design of V2X-Graph centers around creating an interpretable and end-to-end framework for cooperative motion forecasting. This involves representing the cooperative driving scenario as a graph, where nodes encode information from various sources (ego vehicle, other vehicles, infrastructure) and edges capture relationships between them. The graph structure facilitates heterogeneous feature fusion, integrating motion and interaction features in a principled manner. This fusion is guided by an interpretable association mechanism establishing links between observations of the same agent across different viewpoints, resolving inconsistencies arising from differing sensor perspectives. Key to its effectiveness is the use of graph neural networks for feature propagation and fusion across different node types. The framework’s design emphasizes an interpretable and forecasting-oriented approach, prioritizing accuracy and explainability in trajectory prediction over simple perception enhancement. This design choice distinguishes it from existing methods and allows for effective context utilization in a cooperative multi-agent setting.
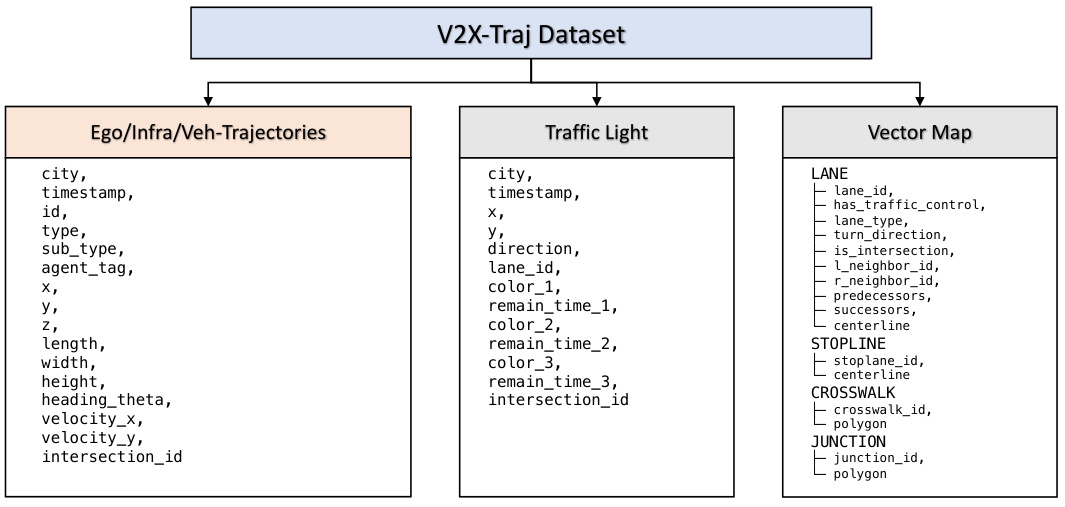
V2X-Traj Dataset#
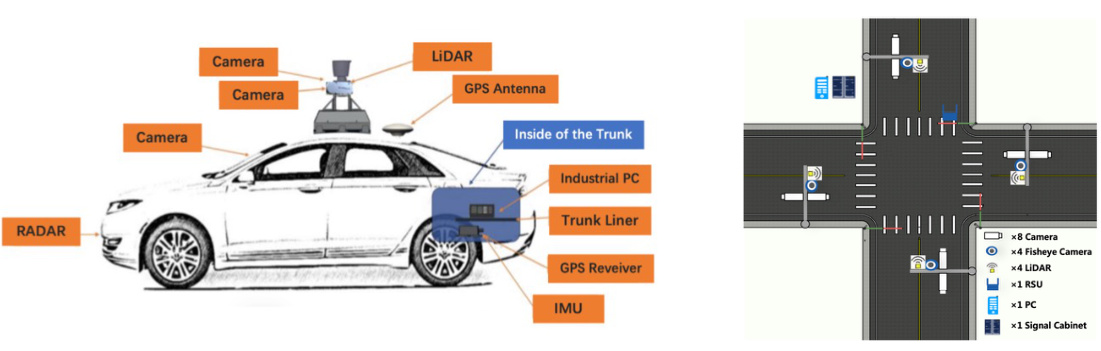
The creation of the V2X-Traj dataset is a significant contribution to the field of autonomous driving research. Its unique focus on real-world vehicle-to-everything (V2X) scenarios, including both vehicle-to-infrastructure (V2I) and vehicle-to-vehicle (V2V) interactions, addresses a critical gap in existing datasets. Most public datasets concentrate solely on single-vehicle perception or limited V2I scenarios. V2X-Traj offers a more comprehensive and realistic representation of cooperative driving environments, making it ideal for evaluating the performance of cooperative motion forecasting algorithms. The dataset’s inclusion of diverse traffic participants and infrastructure components further enhances its value for training robust and generalizable models. The availability of vector maps and real-time traffic signals adds context, providing crucial information for improving the accuracy of forecasting models. Overall, V2X-Traj represents a valuable resource for advancing the research and development of next-generation autonomous driving systems. Its open-source nature encourages collaboration and will likely accelerate progress in this important area.
Interpretable Fusion#
Interpretable fusion in the context of multi-agent trajectory forecasting signifies a method that not only combines data from various sources (e.g., different sensors, vehicles) but also does so in a transparent and understandable manner. Transparency is key; the fusion process should reveal how individual data streams contribute to the final prediction, enhancing trust and debugging capabilities. This is in contrast to “black box” methods where the fusion logic is opaque. Interpretability facilitates identifying and correcting errors in individual data sources, improving robustness. Effective interpretable fusion should leverage the unique strengths of each data source, potentially employing graph-based methods to represent relationships between agents and sensors for more sophisticated analysis. This approach is vital in safety-critical applications, such as autonomous driving, where understanding the reasoning behind predictions is paramount. By making the fusion process clear, it allows for verification and validation, contributing to safer and more reliable systems. Careful design of feature representations is crucial to ensure that the fused information remains meaningful and avoids information loss.
Future Research#
Future research directions stemming from this cooperative motion forecasting work could explore several promising avenues. Improving the robustness of the model to noisy or incomplete data from various sensors is crucial, potentially through advanced data fusion techniques or more sophisticated handling of missing data. Investigating more complex traffic scenarios, beyond simple intersections, would require incorporating richer contextual information, like driver behavior models and different types of interactions. Another key area is scaling the approach to larger and more diverse datasets, which might involve decentralized computation or efficient representation learning to handle massive data. Finally, developing a deeper understanding of the interpretability of the learned graph representations would be invaluable for debugging, improving model accuracy, and possibly enabling more explainable AI for autonomous driving. The creation of new, more comprehensive V2X datasets would significantly benefit the field. These datasets should include a wider variety of traffic conditions, environmental factors, and sensor configurations. Overall, continued research should push the boundaries of accuracy, robustness, and scalability while focusing on both technical and ethical implications.
More visual insights#
More on figures
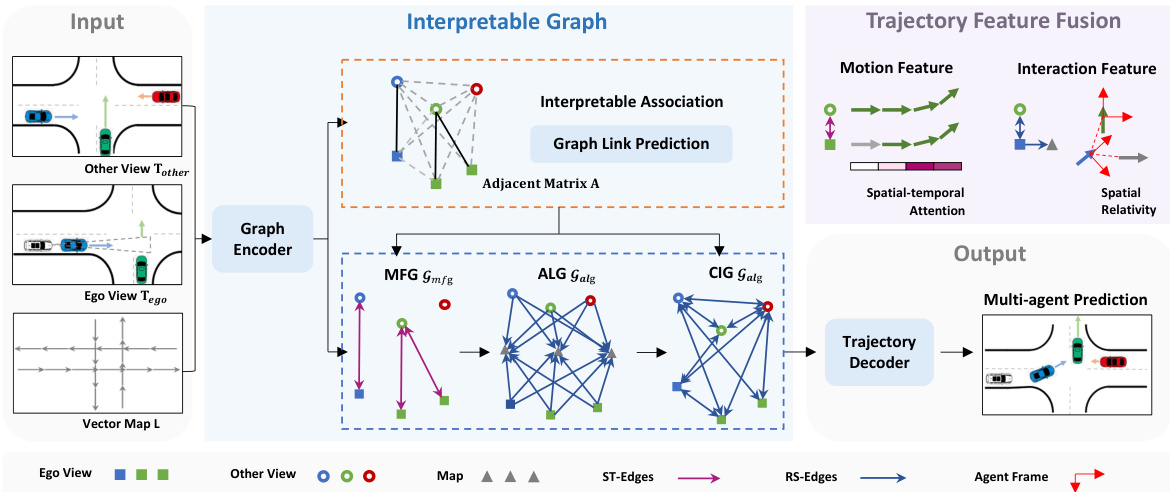
🔼 This figure illustrates the V2X-Graph architecture, which is a novel framework for cooperative motion forecasting that leverages information from the ego vehicle, other vehicles, and infrastructure. It uses a graph-based approach where nodes represent trajectories and lane segments, and edges represent spatial and temporal relationships between them. The graph is designed to be interpretable, facilitating fusion of motion and interaction features for enhanced forecasting accuracy. The figure highlights the key components: graph encoding, interpretable association, and trajectory feature fusion, all working together to generate a multi-agent prediction.
read the caption
Figure 2: V2X-Graph overview. Trajectories from the ego-view and other views, along with vector map information, are encoded as nodes and edges for graph construction to represent a cooperative scenario. The novel interpretable graph provides guidance for forecasting-oriented trajectory feature fusion, including motion and interaction features. In this figure, solid rectangles represent encodings of ego-view trajectories, hollow circles represent encodings of cooperative trajectories, distinguished by distinct colors. Specifically, within the same view, the use of the same color indicates interruptions caused by occlusion. Triangles represent encodings of lane segments. In trajectory feature fusion, grey arrow indicates an missing frame in motion case, a lane segment vector in interaction case.

🔼 This figure shows statistics and visualizations of the V2X-Traj dataset, a new dataset created for the research. Panel (a) presents a bar chart summarizing the number and average length of trajectories for eight different agent classes (e.g., cars, pedestrians, buses). Panel (b) displays example scenarios from the dataset, illustrating multiple views (ego, infrastructure, vehicle) and the agents included. Orange boxes represent autonomous vehicles, blue represents other traffic participants, and green boxes indicate the target agent being predicted.
read the caption
Figure 3: V2X-Traj dataset. (a) Statistics of the total number and average length for the 8 classes of agents. (b) Visualizations. Orange boxes represent autonomous vehicles, blue elements denote other traffic participants and the green box denotes the target agent needs to be predicted.

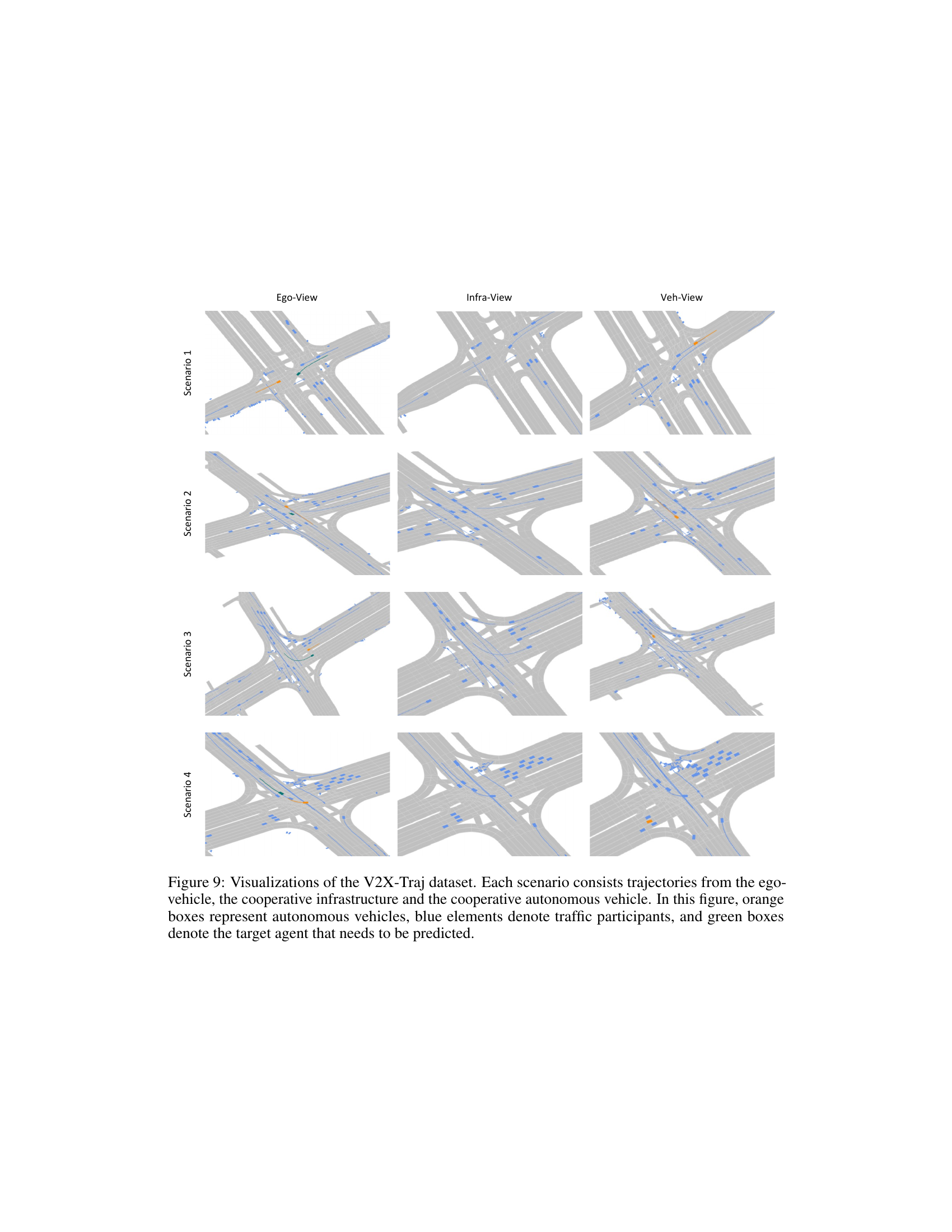
🔼 This figure shows four examples from the V2X-Traj dataset, illustrating scenarios with trajectories from ego-vehicle, infrastructure, and other vehicles. Each scenario shows multiple agents with their predicted trajectories. Orange boxes represent autonomous vehicles, blue indicates other traffic participants, and green denotes the target agent whose future trajectory is being predicted. The figure visually demonstrates the multi-agent, multi-view nature of the dataset and the complexity of the scenarios.
read the caption
Figure 9: Visualizations of the V2X-Traj dataset. Each scenario consists trajectories from the ego-vehicle, the cooperative infrastructure and the cooperative autonomous vehicle. In this figure, orange boxes represent autonomous vehicles, blue elements denote traffic participants, and green boxes denote the target agent that needs to be predicted.
🔼 This figure illustrates the V2X-Graph architecture, a novel framework for cooperative motion forecasting. It shows how trajectories from ego and other views, along with vector map data, are encoded as nodes and edges in an interpretable graph. This graph guides the fusion of motion and interaction features to improve forecasting accuracy. The use of color-coding and shapes helps to visually distinguish the different types of trajectory data and their relationships.
read the caption
Figure 2: V2X-Graph overview. Trajectories from the ego-view and other views, along with vector map information, are encoded as nodes and edges for graph construction to represent a cooperative scenario. The novel interpretable graph provides guidance for forecasting-oriented trajectory feature fusion, including motion and interaction features. In this figure, solid rectangles represent encodings of ego-view trajectories, hollow circles represent encodings of cooperative trajectories, distinguished by distinct colors. Specifically, within the same view, the use of the same color indicates interruptions caused by occlusion. Triangles represent encodings of lane segments. In trajectory feature fusion, grey arrow indicates an missing frame in motion case, a lane segment vector in interaction case.
🔼 This figure shows the architecture of the V2X-Graph model. It details how trajectories from different viewpoints (ego-vehicle and other vehicles/infrastructure) are integrated via a graph-based approach. The graph uses nodes to represent trajectories and lane segments, and edges represent relationships (spatial and temporal) between them. The figure emphasizes the fusion of motion and interaction features, illustrating the model’s design to leverage cooperative perception data for motion forecasting.
read the caption
Figure 2: V2X-Graph overview. Trajectories from the ego-view and other views, along with vector map information, are encoded as nodes and edges for graph construction to represent a cooperative scenario. The novel interpretable graph provides guidance for forecasting-oriented trajectory feature fusion, including motion and interaction features. In this figure, solid rectangles represent encodings of ego-view trajectories, hollow circles represent encodings of cooperative trajectories, distinguished by distinct colors. Specifically, within the same view, the use of the same color indicates interruptions caused by occlusion. Triangles represent encodings of lane segments. In trajectory feature fusion, grey arrow indicates an missing frame in motion case, a lane segment vector in interaction case.
🔼 This figure shows statistics and visualizations of the V2X-Traj dataset, a new dataset created for the research. (a) presents a bar chart showing the number and average length of trajectories for eight different agent classes (e.g., cars, pedestrians, buses). (b) provides example visualizations of scenes from the dataset; orange boxes represent autonomous vehicles, blue boxes show other traffic participants, and green boxes highlight the target vehicle whose movement needs to be predicted.
read the caption
Figure 3: V2X-Traj dataset. (a) Statistics of the total number and average length for the 8 classes of agents. (b) Visualizations. Orange boxes represent autonomous vehicles, blue elements denote other traffic participants and the green box denotes the target agent needs to be predicted.
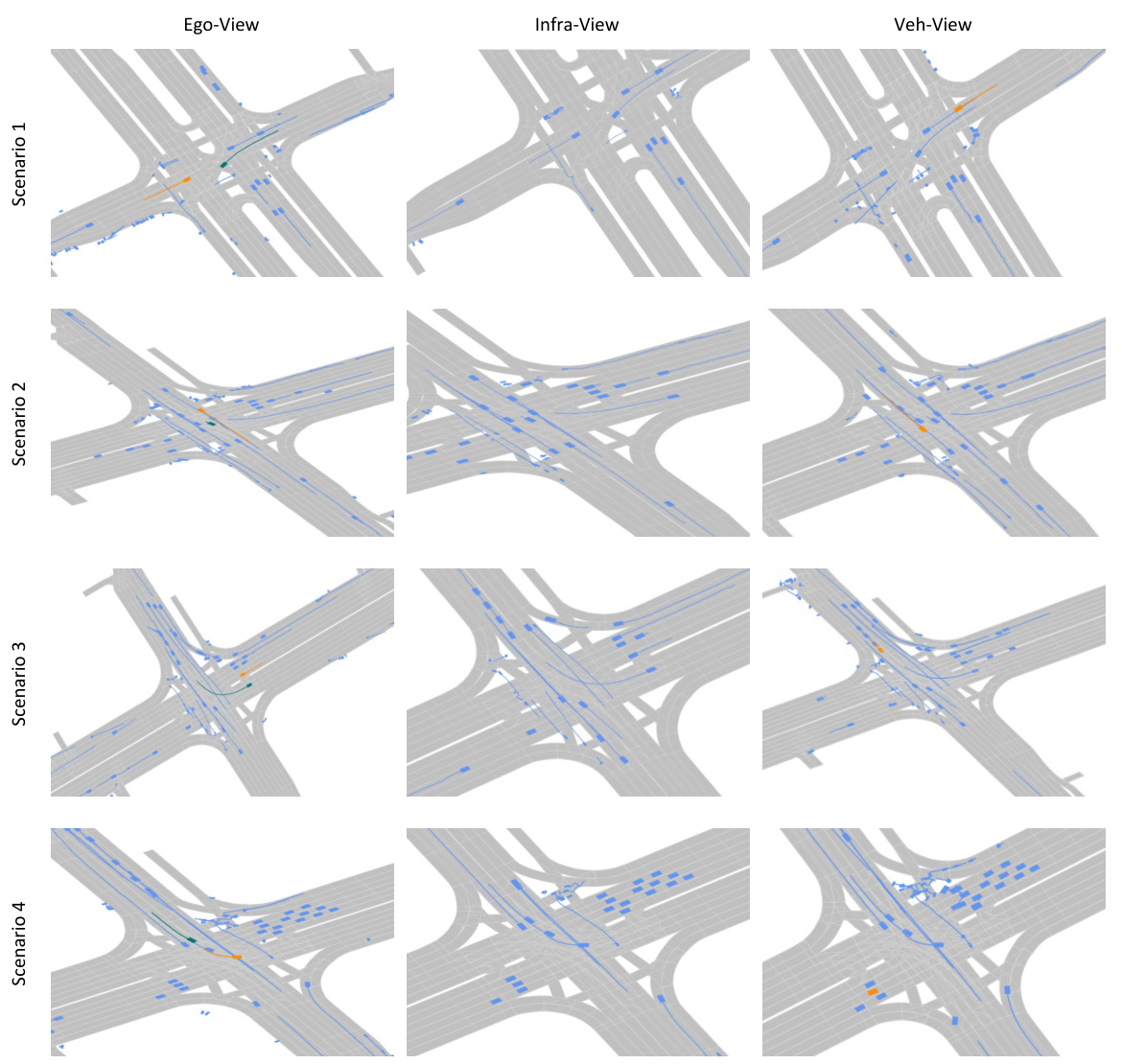
🔼 This figure visualizes four scenarios from the V2X-Traj dataset. Each scenario shows trajectories from three perspectives: the ego-vehicle, the infrastructure, and another vehicle. The visualization uses color-coding to distinguish different types of agents: orange for autonomous vehicles, blue for other traffic participants, and green for the target agent whose motion needs to be predicted. The figure demonstrates how the dataset includes multiple perspectives for cooperative motion forecasting.
read the caption
Figure 9: Visualizations of the V2X-Traj dataset. Each scenario consists trajectories from the ego-vehicle, the cooperative infrastructure and the cooperative autonomous vehicle. In this figure, orange boxes represent autonomous vehicles, blue elements denote traffic participants, and green boxes denote the target agent that needs to be predicted.
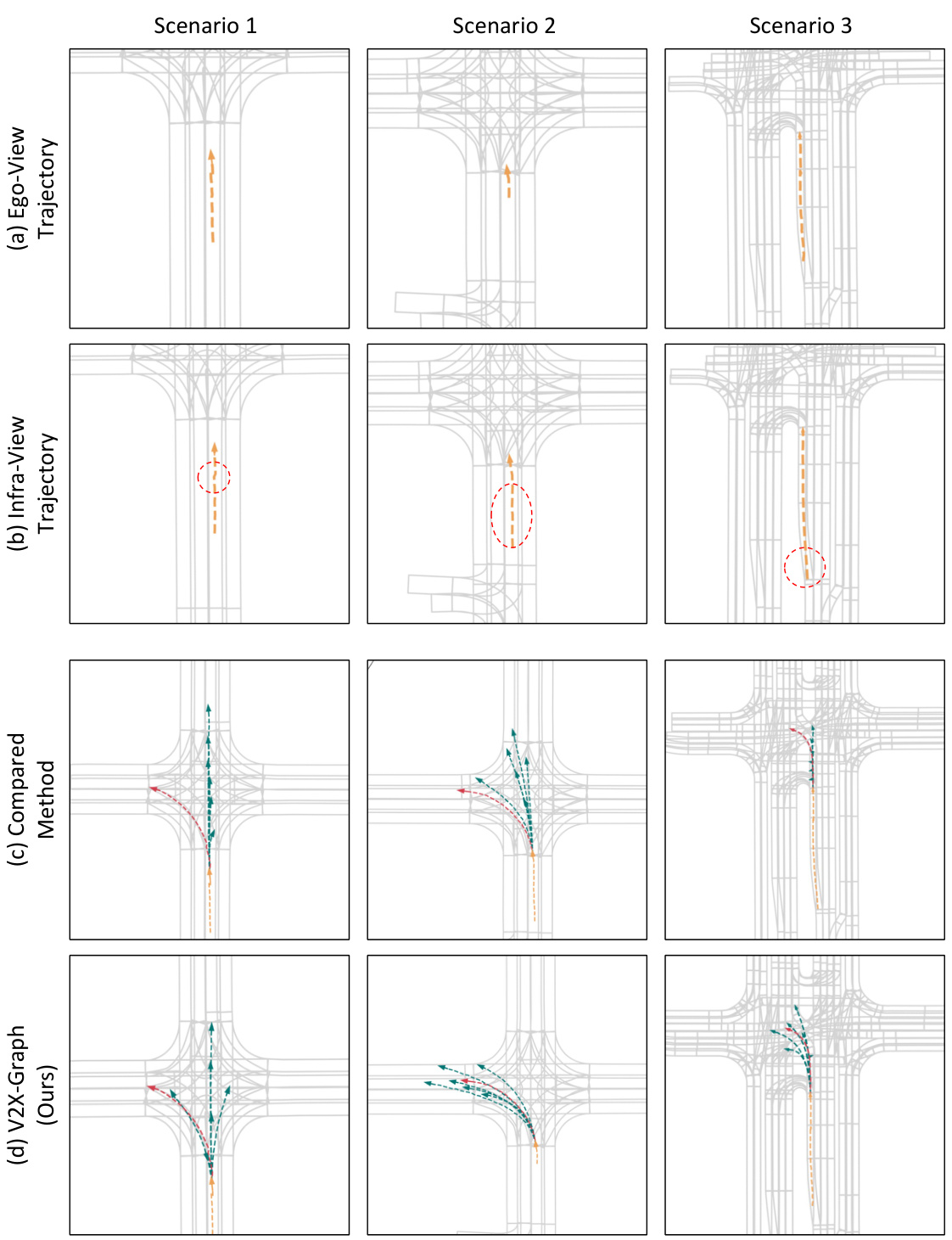
🔼 This figure presents a qualitative comparison of motion forecasting results on three challenging scenarios from the V2X-Seq dataset. It highlights the performance of the proposed V2X-Graph method against a comparison method. The visualization shows the historical trajectories, ground truth trajectories and predicted trajectories. Red dashed circles emphasize the additional information integrated from the infrastructure view, showcasing the benefit of cooperative information in improving prediction accuracy.
read the caption
Figure 10: Qualitative results on three challenge scenarios over V2X-Seq. The historical trajectories of the target agent are shown in yellow. The red dashed circles indicate a part of the enhanced information from the infrastructure view. The ground-truth trajectories are shown in red, and the predicted trajectories are shown in green.
More on tables

🔼 This table presents the comparison results of V2X-Graph with other graph-based methods on the V2X-Traj dataset. It shows the performance (minADE, minFDE, and MR) of each method under different scenarios: vehicle-only, V2V (vehicle-to-vehicle), V2I (vehicle-to-infrastructure), and V2V&I (vehicle-to-everything). This allows for a comprehensive evaluation of V2X-Graph’s performance in various cooperative settings.
read the caption
Table 2: Graph-based methods comparison on V2X-Traj.

🔼 This table presents the ablation study results on the effectiveness of each major component of the proposed V2X-Graph model. By selectively removing one component (MFG, ALG, or CIG) at a time, the impact on the model’s performance is evaluated using three metrics: minADE, minFDE, and MR. The results show the individual contribution of each component to the overall performance, highlighting their importance in achieving the best results when all components are included.
read the caption
Table 3: Effect of major components.

🔼 This table presents the ablation study results on the effectiveness of cooperative representations in the V2X-Graph model. By selectively disabling components (MFG, ALG, CIG) of the model, the impact on the cooperative motion forecasting performance (minADE, minFDE, MR) is evaluated. The results highlight the contributions of each component in improving accuracy.
read the caption
Table 4: Effect of cooperative representations.

🔼 This table presents the ablation study results on the effectiveness of feature fusion with interpretable graph. It compares different fusion strategies: no fusion, full fusion (all features combined), and interpretable fusion (features aggregated based on cross-view trajectory associations). The results are measured using minADE, minFDE, and MR metrics, showing the impact of each fusion method on the model’s forecasting accuracy.
read the caption
Table 5: Effectiveness of feature fusion with interpretable graph. 'Fusion Count' represents statistics average fusion counts of features per scenario. 'Interpretable Fusion' indicates the aggregation of motion and interaction features through associations.
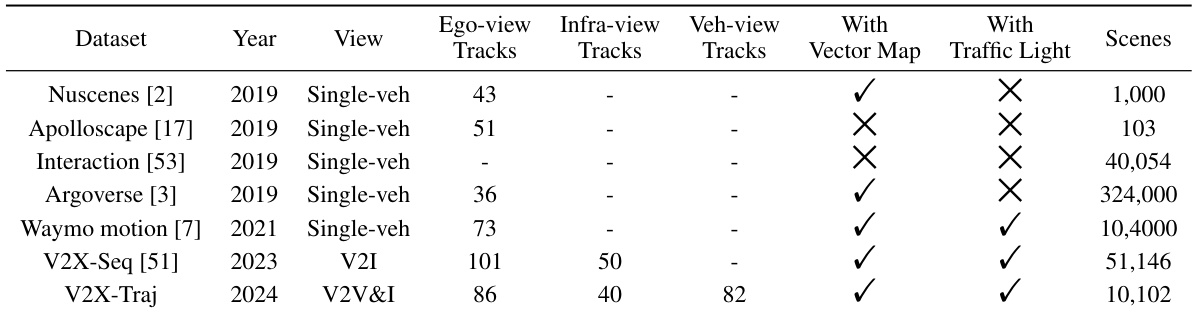
🔼 This table compares V2X-Traj with other public motion forecasting datasets, highlighting the unique aspects of V2X-Traj such as its support for V2V and V2I scenarios, the inclusion of vector maps and traffic light information, and the larger number of scenes.
read the caption
Table 6: Comparison with the public motion forecasting dataset. '-' denotes that the information is not provided or not available. V2X-Traj is the first cooperative dataset that supports research on V2V and broader V2V&I cooperative motion forecasting. The dataset contains abundant real-world cooperative trajectories from infrastructure and cooperative vehicles, as well as information about vector maps and real-time traffic lights.

🔼 This table presents a detailed breakdown of the number and average length of trajectories for each of the eight agent classes within the V2X-Traj dataset. The agent classes include Van, Car, Cyclist, Motorcyclist, Pedestrian, Bus, Tricyclist, and Truck. The data provides valuable context for understanding the composition of the dataset and the characteristics of the various agent types.
read the caption
Table 7: Detailed statistics on the total number and length of trajectories per class.

🔼 This table presents the ablation study results on the V2X-Seq dataset to demonstrate the contribution of each key component to the cooperative motion forecasting performance. It shows the minADE, minFDE, and MR metrics when removing one component (MFG, ALG, or CIG) at a time from the interpretable graph. The results indicate the importance of each component for achieving improved performance.
read the caption
Table 8: Effect of major components.
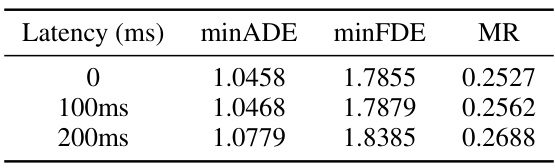
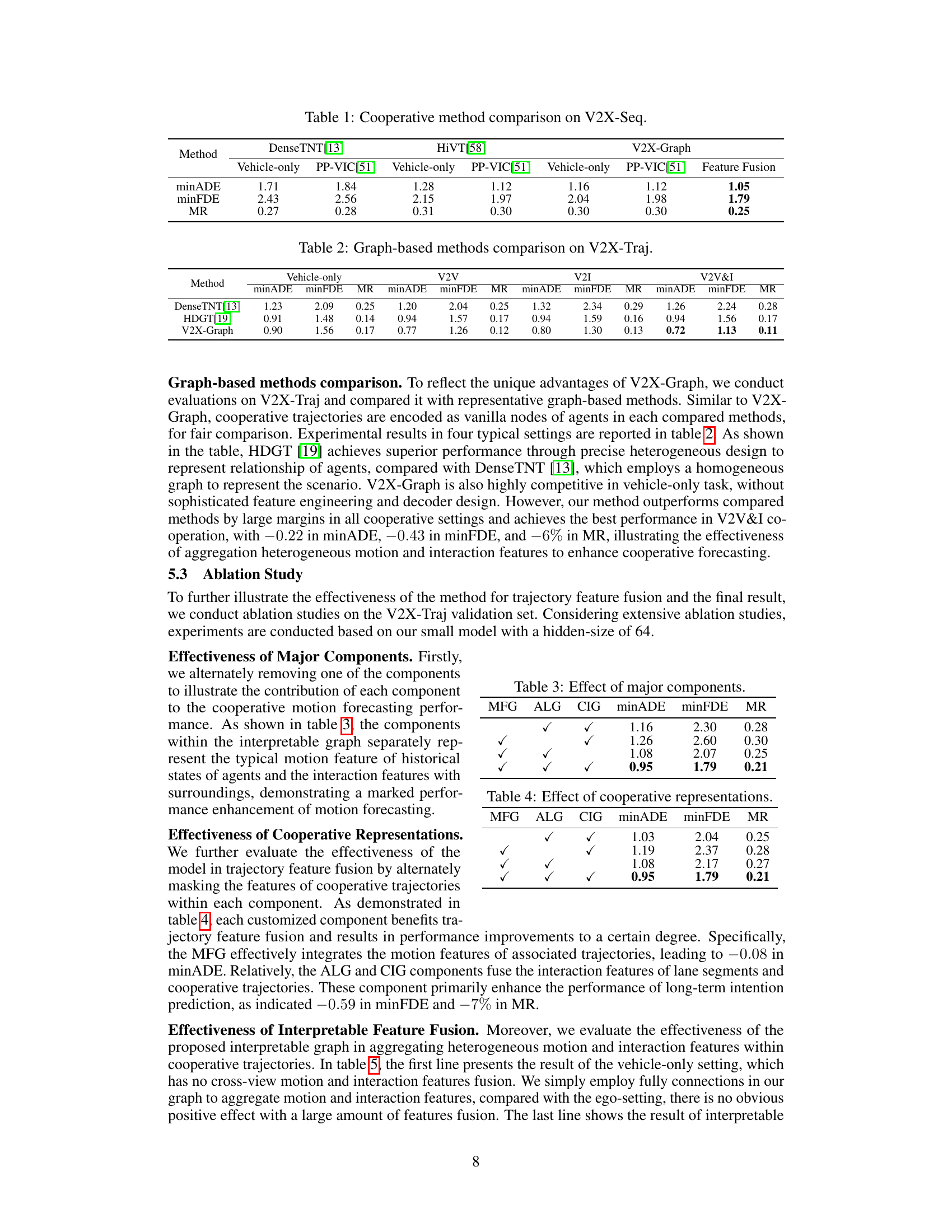
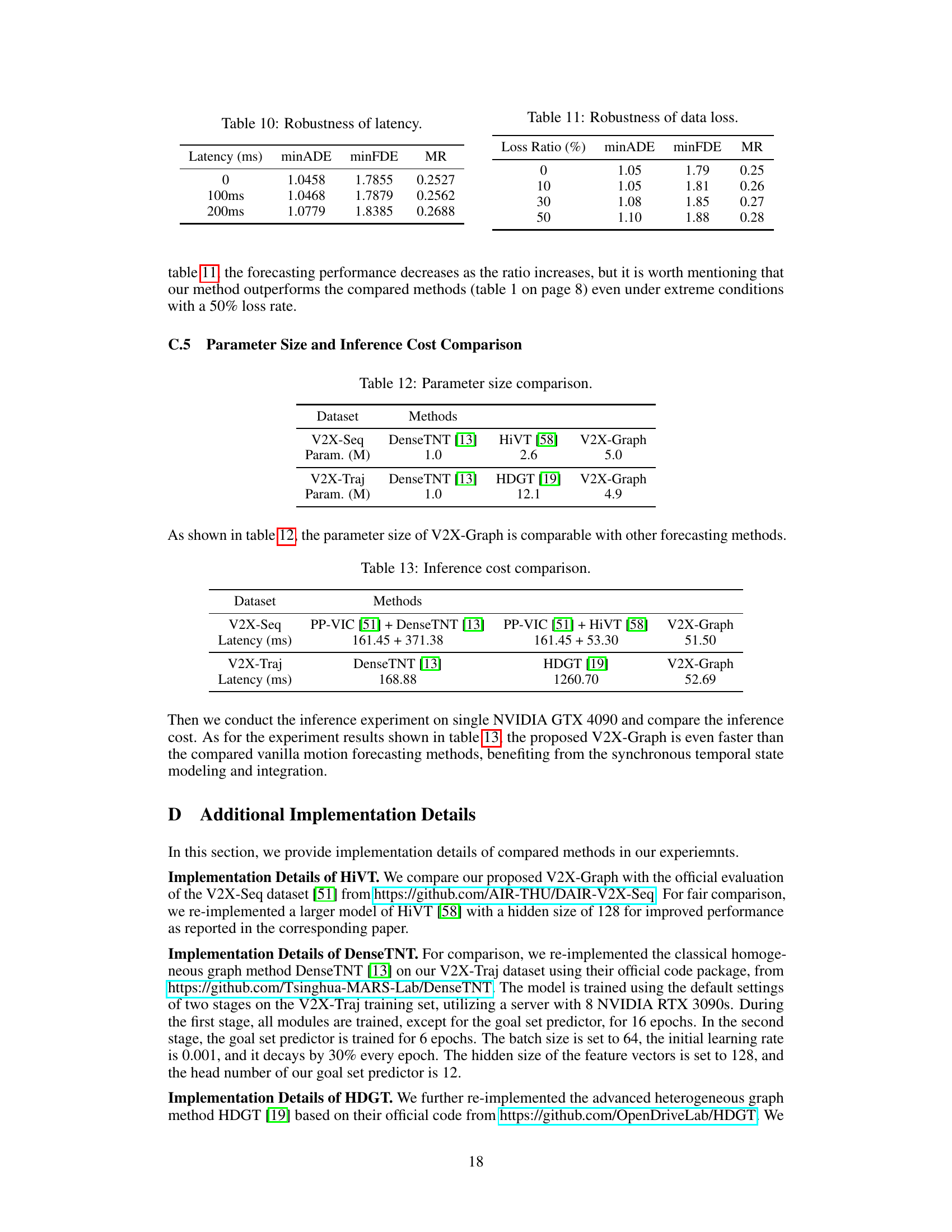
🔼 This table presents the robustness results of the proposed model against communication latency. The results show the model’s performance (minADE, minFDE, MR) under different latency conditions (0ms, 100ms, 200ms). The minADE, minFDE, and MR metrics measure the average displacement error, final displacement error, and miss rate, respectively, all indicating the accuracy of the model’s prediction. The experiment simulates latency by dropping the latest one or two frames of infra-view data during transmission and uses interpolation to obtain synchronized trajectory data. The minimal change in performance shows the model’s resilience to latency.
read the caption
Table 10: Robustness of latency.

🔼 This table shows the robustness of the proposed V2X-Graph model against data loss in the infrastructure view. The minADE, minFDE, and MR metrics are reported for different data loss ratios (0%, 10%, 30%, and 50%). The results demonstrate the model’s resilience to varying levels of missing data.
read the caption
Table 11: Robustness of data loss.

🔼 This table compares the performance of different graph-based methods for cooperative motion forecasting on the V2X-Traj dataset. It shows the results for three different scenarios: vehicle-only, vehicle-to-vehicle (V2V), and vehicle-to-infrastructure (V2I). The metrics used for comparison are mean average displacement error (minADE), mean final displacement error (minFDE), and miss rate (MR).
read the caption
Table 2: Graph-based methods comparison on V2X-Traj.

🔼 This table compares the performance of three different methods on the V2X-Seq dataset: DenseTNT, HiVT, and V2X-Graph. It shows the results with and without cooperative perception information (PP-VIC), highlighting the impact of cooperative information fusion on motion forecasting accuracy, measured by minimum average displacement error (minADE), minimum final displacement error (minFDE), and miss rate (MR).
read the caption
Table 1: Cooperative method comparison on V2X-Seq.
Full paper#