TL;DR#
Many image restoration techniques use deep learning models, but training these models is expensive and time-consuming. Existing diffusion probabilistic models (DPMs) provide good image quality but are also computationally expensive. Furthermore, these models tend to overfit to a specific task, meaning they cannot easily be adapted to other tasks.
This paper introduces a new framework called DP-IR that addresses these issues. DP-IR uses a modular approach, combining the strengths of pre-trained models with a much smaller, task-specific module. This makes it significantly cheaper and easier to adapt to various tasks. The paper also introduces an accelerated sampling method which further improves inference speed and efficiency. The authors extensively tested DP-IR on multiple benchmarks and achieved state-of-the-art performance, highlighting its practicality and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image restoration because it presents a modular and efficient diffusion-based framework (DP-IR) that significantly reduces computational costs while achieving state-of-the-art results. The modular design enables easy adaptation to various tasks, and the accelerated sampling strategy dramatically improves inference speed. This opens up exciting possibilities for deploying DPMs in real-world applications and motivates further research into efficient training and sampling techniques for diffusion models.
Visual Insights#
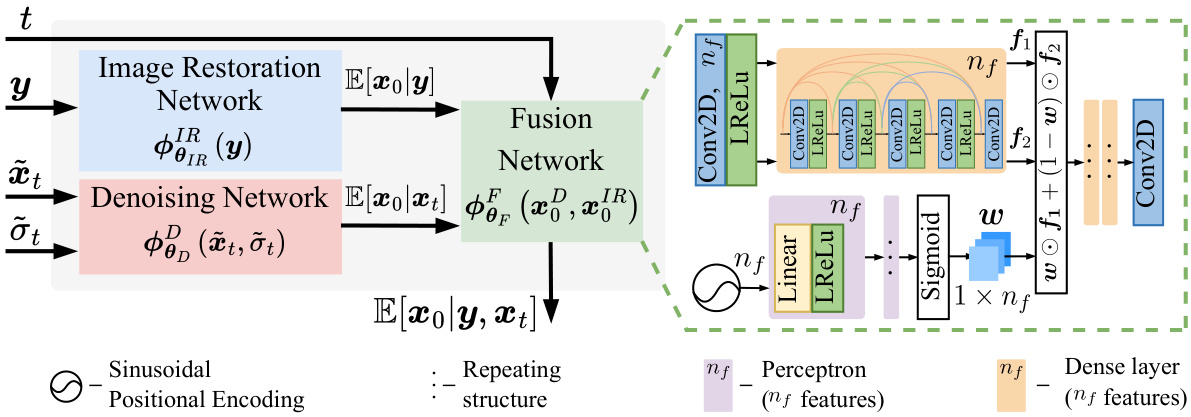
🔼 This figure shows the proposed modular architecture for conditional diffusion-based image reconstruction. It consists of three main parts: an Image Restoration Network (pre-trained model), a Denoising Network (MIRNet), and a Fusion Network (a small newly-trained module). The Image Restoration Network processes the low-quality input image (y). The Denoising Network takes a noisy version of the high-quality image (xt) as input and the Fusion network combines the outputs of these two networks to estimate the high-quality image (xo). The timestep (t) is also part of the process, influencing the noise level in the sampling.
read the caption
Figure 1: The proposed architecture consists of three modules: a Denoising Network də (xt, õt), an IR Network or (y) and a Fusion Network (x,x,t). A small version of MIRNet [81] is used as the Denoising Network, while a pre-trained SwinIR [42] or BSRT [50] or FFTFormer [34] is used as the IR Network, depending on the IR task. See section 3.3 for a detailed description.
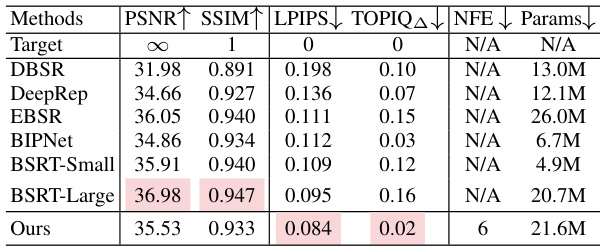
🔼 This table presents a performance comparison of different methods on the Burst Joint Demosaicking, Denoising and Super-Resolution (JDD-SR) task. Metrics include PSNR, SSIM, LPIPS, TOPIQ, and the number of neural function evaluations (NFEs) and model parameters. The table highlights the best performing method for each metric, offering a quantitative assessment of the models’ performance in terms of image quality and computational efficiency.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.
In-depth insights#
Modular Diffusion#
Modular diffusion models represent a significant advancement in generative modeling by breaking down complex diffusion processes into smaller, manageable modules. This approach offers several key advantages: increased flexibility, allowing researchers to combine pre-trained modules for various tasks and customize the overall model; enhanced efficiency, as smaller modules require less computational resources and data for training; and improved scalability, enabling the application of diffusion models to higher-resolution images and more complex problems. The modularity facilitates experimentation with different architectures and components, promoting faster development cycles and potentially leading to novel model designs. While the concept of modularity holds great promise, challenges remain in optimizing the interaction and communication between modules, effectively managing computational costs, and ensuring the generation of high-quality results. Further research should focus on establishing best practices for module design and integration, exploring efficient training strategies, and rigorously evaluating the performance of such modular architectures across diverse applications.
DP-IR Framework#
The DP-IR framework, a modular approach to image reconstruction using diffusion probabilistic models (DPMs), offers a compelling solution to the limitations of existing task-specific DPMs. Its modularity allows for the combination of pre-trained, high-performing image restoration (IR) networks with generative DPMs, significantly reducing the computational cost and data requirements associated with training from scratch. The framework necessitates training only a small, task-specific module, enabling adaptability to various IR tasks without extensive retraining. Furthermore, a novel sampling strategy accelerates inference by reducing neural function evaluations by at least four times, without compromising performance. This efficiency is further enhanced through compatibility with existing acceleration techniques like DDIM. The DP-IR framework’s modularity and efficiency are key advancements, addressing the scalability and accessibility issues inherent in previous DPM-based IR approaches, ultimately promoting wider adoption in diverse real-world applications.
Accelerated Sampling#
The concept of ‘Accelerated Sampling’ in the context of diffusion probabilistic models (DPMs) for image reconstruction is crucial for practical applications. Standard DPM sampling involves many iterations, making inference slow. Accelerated sampling techniques aim to reduce the number of iterations needed to generate a high-quality image without significantly sacrificing perceptual quality. This is achieved through methods that cleverly merge multiple sampling steps or skip less informative steps early in the sampling process. The paper likely details a novel accelerated sampling strategy tailored to their modular diffusion framework, improving upon existing methods like DDIM. This could involve a combination of techniques like intelligently skipping early sampling steps (based on theoretical analysis of information content), and merging later steps for efficiency. The key benefit is a significant reduction in computational cost, making the approach more suitable for real-world applications with limited resources. The success of this acceleration is likely experimentally validated on various image restoration tasks, demonstrating the speed and perceptual quality advantages of their approach.
Ablation Experiments#
Ablation studies systematically evaluate the impact of individual components within a complex model. By removing or modifying specific parts, researchers determine their relative contribution to the overall performance. In the context of a deep learning model for image reconstruction, an ablation study might involve removing or replacing specific modules (e.g., denoising, fusion, or upsampling networks) to understand the importance of each. The results highlight which aspects are most crucial and can guide future improvements by identifying areas for enhancement or simplification. A well-designed ablation study carefully controls for confounding variables, ensuring that observed changes in performance are directly attributable to the modifications made. This provides valuable insights into the model’s architecture and informs decisions about future development, potentially leading to more efficient and effective models.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of the proposed framework is crucial, especially for high-resolution images. This might involve exploring alternative network architectures, optimization techniques, or more efficient sampling methods. Investigating the impact of different IR networks and denoising models on the overall performance would provide further insights. Exploring the potential of the framework for other inverse problems, such as inpainting or colorization, is another valuable direction. A comprehensive study on the sensitivity and robustness of the model to various noise types and levels would be beneficial. Developing theoretical guarantees for the sampling process and its convergence properties is essential to increase the reliability of the method. Finally, a detailed analysis of the impact of different hyperparameters on the model’s performance would help in refining the design and improving its generalization capabilities.
More visual insights#
More on figures

🔼 This figure illustrates the forward and reverse diffusion processes used in the proposed conditional diffusion model. The forward process adds noise to the original image (x0) over many timesteps, until a completely noisy image (xT) is reached. The reverse process then aims to reconstruct the original image from this noisy version, but with the addition of a conditioning step at time τ that uses an IR network estimate to improve efficiency and quality. The figure highlights the accelerated sampling strategy using the closed-form cumulative transition probability (red arrow), which significantly reduces the number of steps required for image reconstruction.
read the caption
Figure 2: Forward and reverse diffusion process. Blue solid arrows: transitions at the forward pass with sampling distribution from eq. (1). Dashed arrow: cumulative transition probability from eq. (2). Black solid arrows: transitions at the backward pass with the sampling distribution from eq. (3). Red solid arrow: closed-form cumulative transition probability from eq. (8) representing our accelerated sampling.

🔼 This figure shows visual comparisons of different dynamic scene deblurring methods on the GoPro test set. Each output image is accompanied by its LPIPS (Learned Perceptual Image Patch Similarity) value, a metric quantifying the perceptual difference between the generated and ground truth images. Lower LPIPS values indicate higher perceptual similarity.
read the caption
Figure 3: Visual comparisons on the GoPro test set for the task of dynamic scene deblurring (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

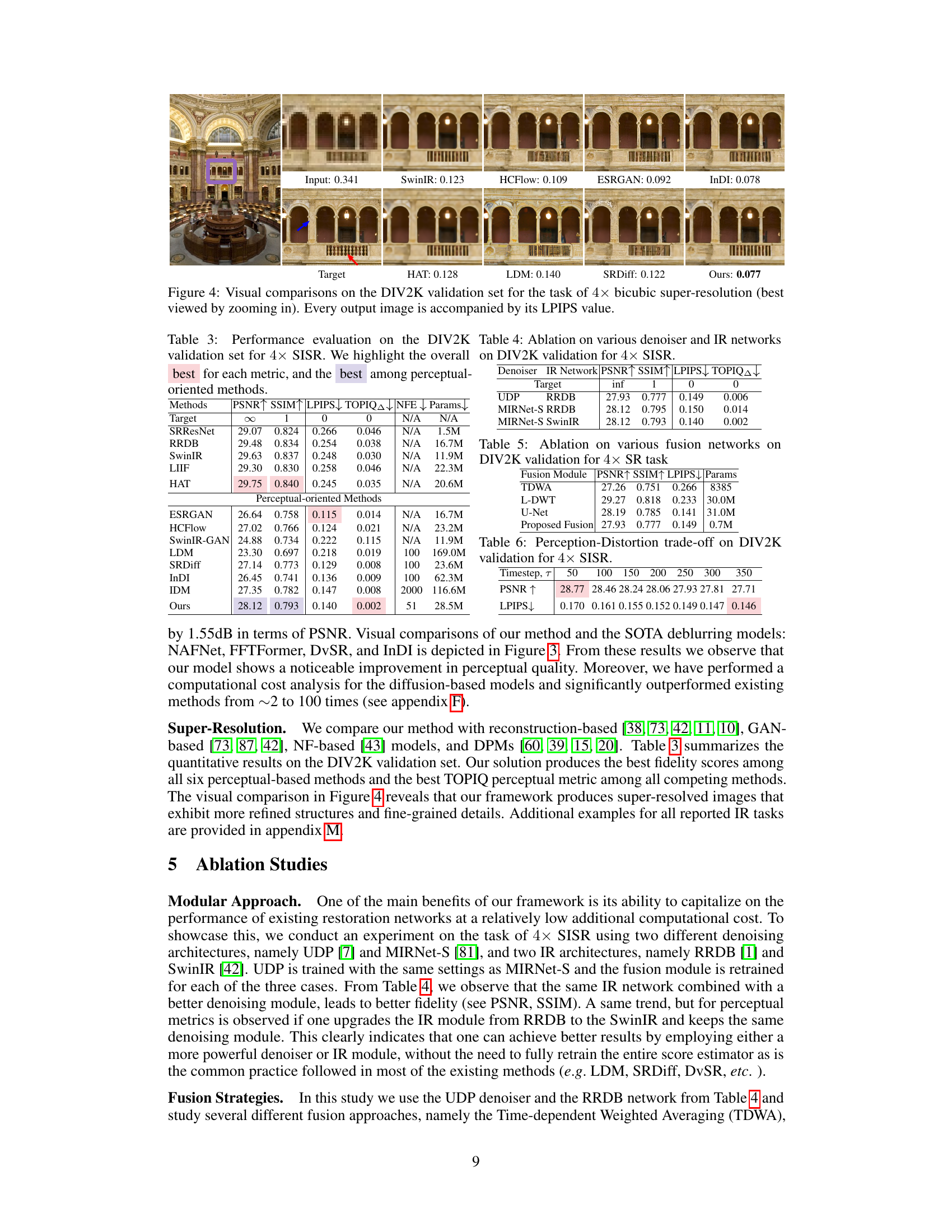
🔼 This figure compares visual results of different super-resolution (SR) methods on images from the DIV2K validation set. Each row shows the input low-resolution image, followed by the results from several SR methods (SwinIR, HCFlow, ESRGAN, InDI, HAT, LDM, SRDiff), and finally the ground truth high-resolution image. The LPIPS (Learned Perceptual Image Patch Similarity) score, a metric that measures perceptual similarity, is provided below each output image. The figure highlights the visual quality improvements achieved by the proposed method compared to existing methods.
read the caption
Figure 4: Visual comparisons on the DIV2K validation set for the task of 4× bicubic super-resolution (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure illustrates the modular architecture of the proposed conditional diffusion probabilistic image restoration framework (DP-IR). It shows three main components: 1. Denoising Network: Uses a smaller version of MIRNet to estimate E[x0|xt] (the expected original image given the noisy image at timestep t). 2. IR Network: Employs a pre-trained network (SwinIR, BSRT, or FFTformer depending on the specific image restoration task) to estimate E[x0|y] (the expected original image given the observed low-quality image y). 3. Fusion Network: Combines the outputs of the Denoising and IR Networks, along with the timestep t, to produce the final conditional expectation E[x0|y, xt] which is used for the image reconstruction process.
read the caption
Figure 1: The proposed architecture consists of three modules: a Denoising Network də (xt, õt), an IR Network or (y) and a Fusion Network (x,x,t). A small version of MIRNet [81] is used as the Denoising Network, while a pre-trained SwinIR [42] or BSRT [50] or FFTFormer [34] is used as the IR Network, depending on the IR task. See section 3.3 for a detailed description.

🔼 This figure compares the visual results of different super-resolution methods on a sample image from the Burst JDD-SR dataset. The leftmost image shows the ground truth (Target) and is followed by results from DBSR, DeepRep, BSRT-Small, BSRT-Large, BIPNet, EBSR, and finally the proposed method (Ours). Each result image is accompanied by its LPIPS (Learned Perceptual Image Patch Similarity) score which quantifies the perceptual difference between the reconstruction and the ground truth.
read the caption
Figure 6: Visual comparison of our approach against competing methods on the Burst JDD-SR task (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure compares the results of the proposed method against several state-of-the-art methods for Burst Joint Demosaicking and Super-Resolution (JDD-SR). It highlights perceptual differences by showing the LPIPS score of each reconstruction alongside a visual comparison of the reconstructed images against the ground truth. The lower LPIPS value indicates a higher perceptual similarity to the ground truth image.
read the caption
Figure 6: Visual comparison of our approach against competing methods on the Burst JDD-SR task (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure illustrates the modular architecture of the proposed conditional diffusion probabilistic image reconstruction framework (DP-IR). It shows three main components: a Denoising Network (a modified MIRNet), an Image Restoration Network (a pre-trained SwinIR, BSRT, or FFTFormer, depending on the task), and a Fusion Network that combines the outputs of the first two networks. The Fusion Network is a relatively small module (0.7M parameters) trained for a specific image reconstruction task. The figure details the structure of the networks, showing convolutional, ReLU, and dense layers.
read the caption
Figure 1: The proposed architecture consists of three modules: a Denoising Network ϕDθD(x˜t, σ˜t), an IR Network ϕIRθIR(y) and a Fusion Network ϕFθF(xIR0, xD0, t). A small version of MIRNet [81] is used as the Denoising Network, while a pre-trained SwinIR [42] or BSRT [50] or FFTFormer [34] is used as the IR Network, depending on the IR task. See section 3.3 for a detailed description.

🔼 This figure compares the visual quality of image reconstruction results produced by different methods on the Burst JDD-SR task. The leftmost image shows the input low-quality burst image with a highlighted region of interest. Subsequent images display the reconstruction results from DBSR, DeepRep, BSRT-Small, BSRT-Large, BIPNet, EBSR, and the proposed method. Each reconstructed image is accompanied by its Learned Perceptual Image Patch Similarity (LPIPS) score, a metric that measures perceptual similarity to the ground truth image. Lower LPIPS scores indicate better perceptual quality.
read the caption
Figure 6: Visual comparison of our approach against competing methods on the Burst JDD-SR task (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure shows a visual comparison of different dynamic scene deblurring methods on the GoPro test set. The input blurry image and ground truth are shown, along with results from several state-of-the-art methods (HINet, MPRNet, NAFNet, Restormer, DeblurGANv2, DvSR, InDI) and the proposed method (Ours). Each result image includes its LPIPS (Learned Perceptual Image Patch Similarity) score, which quantifies perceptual differences between the generated and ground truth images. Lower LPIPS scores indicate better perceptual quality.
read the caption
Figure 3: Visual comparisons on the GoPro test set for the task of dynamic scene deblurring (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure compares visual results of different dynamic scene deblurring methods on the GoPro test dataset. Each image shows a deblurred result alongside its LPIPS score (a perceptual metric measuring the difference between two images). The goal is to demonstrate the visual quality of the proposed method compared to existing state-of-the-art techniques. Lower LPIPS values indicate higher visual similarity to the ground truth.
read the caption
Figure 3: Visual comparisons on the GoPro test set for the task of dynamic scene deblurring (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure provides a visual comparison of different image deblurring methods on the GoPro dataset. The input image shows a blurry scene of a street, and the subsequent images show the results from different methods. Each result includes its LPIPS (Learned Perceptual Image Patch Similarity) score, a metric that quantifies perceptual differences between images. Lower LPIPS scores indicate a better visual quality compared to the ground truth image.
read the caption
Figure 3: Visual comparisons on the GoPro test set for the task of dynamic scene deblurring (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure shows visual comparison results of different dynamic scene deblurring methods on GoPro test dataset. Each result image includes LPIPS score to quantify the perceptual quality of the deblurred image.
read the caption
Figure 3: Visual comparisons on the GoPro test set for the task of dynamic scene deblurring (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure shows the architecture of the proposed modular conditional diffusion framework for image reconstruction. It consists of three main modules: a Denoising Network, an Image Restoration Network, and a Fusion Network. The Denoising Network is based on MIRNet and aims to estimate E[x0|xt]. The Image Restoration Network uses pre-trained models such as SwinIR, BSRT, or FFTformer to estimate E[x0|y]. The Fusion Network combines the outputs of the two previous modules to estimate E[x0|y,xt], which is then used to generate the final reconstructed image. The choice of pre-trained Image Restoration Network depends on the specific image reconstruction task.
read the caption
Figure 1: The proposed architecture consists of three modules: a Denoising Network də (xt, õt), an IR Network or (y) and a Fusion Network (x,x,t). A small version of MIRNet [81] is used as the Denoising Network, while a pre-trained SwinIR [42] or BSRT [50] or FFTFormer [34] is used as the IR Network, depending on the IR task. See section 3.3 for a detailed description.

🔼 This figure compares the visual results of different super-resolution methods on a sample image from the DIV2K validation set. The input is a low-resolution image, and the ‘Target’ shows the ground truth high-resolution image. The other images represent the output of various state-of-the-art super-resolution methods, including the authors’ proposed approach. Each output image is accompanied by its Learned Perceptual Image Patch Similarity (LPIPS) score, which quantifies perceptual differences between the output and the target. Lower LPIPS values indicate better perceptual quality.
read the caption
Figure 4: Visual comparisons on the DIV2K validation set for the task of 4× bicubic super-resolution (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure compares visual results of different super-resolution (SR) methods on images from the DIV2K validation set. Each column shows the input low-resolution image, outputs from several SR methods (SwinIR, HCFlow, ESRGAN, InDI, HAT, LDM, SRDiff), and the ground truth high-resolution image. The LPIPS (Learned Perceptual Image Patch Similarity) score, a perceptual quality metric, is provided for each output to quantify the visual similarity to the ground truth.
read the caption
Figure 4: Visual comparisons on the DIV2K validation set for the task of 4× bicubic super-resolution (best viewed by zooming in). Every output image is accompanied by its LPIPS value.

🔼 This figure compares the visual results of the proposed method against several state-of-the-art super-resolution methods on the DIV2K validation dataset. Each image is accompanied by its Learned Perceptual Image Patch Similarity (LPIPS) score, which measures perceptual similarity to the ground truth image. The LPIPS values indicate the visual quality of the reconstruction results.
read the caption
Figure 17: Visual comparison of our approach against competing methods on the DIV2K validation set for the task of 4× super-resolution (best viewed by zooming in). Every output image is accompanied by its LPIPS value.
More on tables
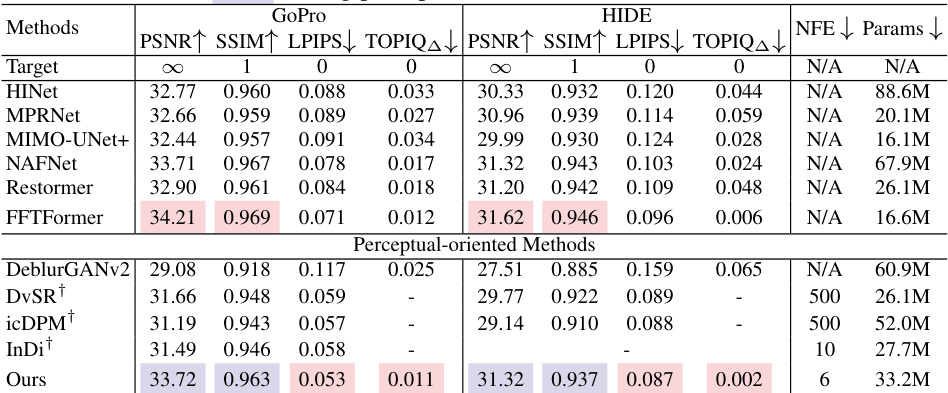
🔼 This table presents a quantitative comparison of different methods for dynamic scene deblurring on two benchmark datasets: GoPro and HIDE. The metrics used are PSNR, SSIM, LPIPS (lower is better), and TOPIQ△ (lower is better), reflecting both fidelity and perceptual quality. The number of neural function evaluations (NFEs) and the model’s number of parameters are also included for comparison. Note that some results marked with † are taken directly from the cited papers due to unavailability of their public implementations.
read the caption
Table 2: Performance evaluation on the GoPro and HIDE test sets for dynamic scene deblurring. † indicates that public implementation is unavailable and the scores are copied from the authors’ paper. We highlight the overall best for each metric, and the best among perceptual-oriented methods.
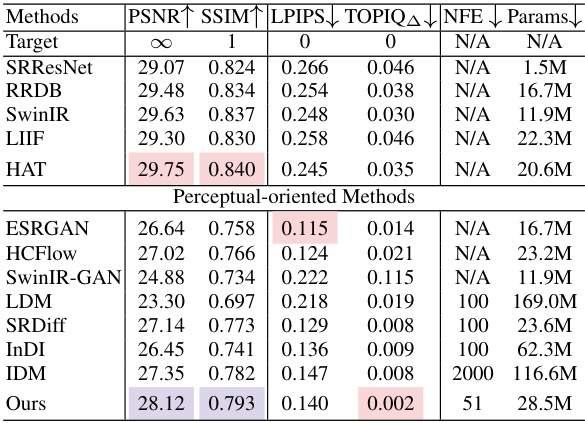
🔼 This table presents a comparison of different methods for Burst Joint Demosaicking and Super-Resolution (JDD-SR). The metrics used for evaluation include PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), TOPIQ (Task-Oriented Perceptual Image Quality), NFE (Number of Function Evaluations), and Params (number of parameters). The table highlights the best-performing method for each metric.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.
🔼 This table presents a performance comparison of different methods for the Burst Joint Demosaicking, Denoising and Super-Resolution (JDD-SR) task. Metrics used for evaluation include PSNR, SSIM, LPIPS, and TOPIQ. The number of neural function evaluations (NFEs) and the model’s number of parameters are also provided to show computational efficiency. The best performing method for each metric is highlighted.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.

🔼 This table compares the proposed method with other state-of-the-art Diffusion Probabilistic Models (DPMs) for single image super-resolution (SISR) in terms of training data and model parameters. It demonstrates that the proposed modular approach requires significantly less data and computational resources (smaller model) compared to existing DPMs while achieving competitive performance.
read the caption
Table 7: Comparison of the proposed approach against existing DPM methods for SISR task in terms of training dataset requirements and training parameters.

🔼 This table compares the proposed accelerated sampling strategy with those presented in papers [13] and [52] for the task of single image super-resolution (SISR). It shows the PSNR, SSIM, LPIPS, TOPIQΔ, and NFE values for both strategies. The comparison highlights the performance gains achieved by the proposed method while maintaining a similar number of neural function evaluations (NFEs).
read the caption
Table 8: Comparison of the proposed acceleration scheme and prior works [13, 52] for the SISR task.

🔼 This table compares the computational cost, measured in TFLOPs, of different diffusion-based methods for dynamic scene deblurring. The input image resolution is 720p (1280x720). The cost is broken down into two components: a base cost (the terms without NFE, representing operations performed once per image) and a per-NFE cost (the terms multiplied by NFE, representing operations whose number scales with the number of neural function evaluations). The table highlights that the proposed method achieves a significantly lower computational cost compared to other methods.
read the caption
Table 9: Computational cost of the proposed and existing diffusion-based methods for the Dynamic Scene Deblurring task with 720p input resolution.

🔼 This table compares the performance of the proposed one-step acceleration method with and without DDIM (Denoising Diffusion Implicit Models) acceleration technique for single image super-resolution (SISR) task. It shows the PSNR, SSIM, LPIPS, TOPIQ, and the number of neural function evaluations (NFEs) required for each method. The results indicate that the one-step acceleration technique significantly reduces the number of NFEs while maintaining comparable perceptual and fidelity metrics.
read the caption
Table 10: Results for the proposed one-step acceleration with/without DDIM technique tested on SISR task

🔼 This table presents the performance of different methods on the Burst Joint Demosaicking, Denoising and Super-Resolution (JDD-SR) task. It compares the proposed method against several state-of-the-art approaches, evaluating performance using PSNR, SSIM, LPIPS, and TOPIQ metrics. The number of neural function evaluations (NFEs) and model parameters are also included to show the computational efficiency of the different models.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.

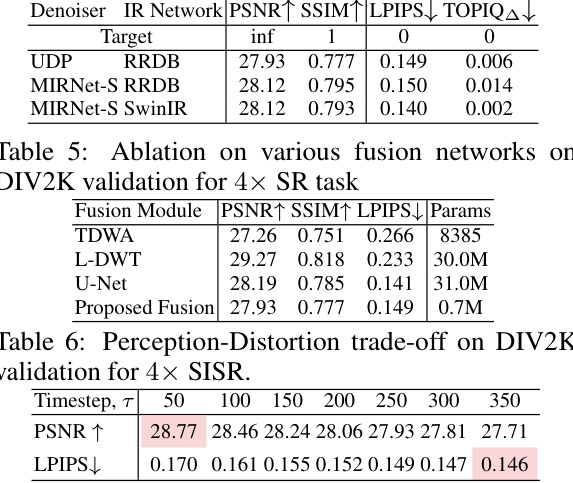
🔼 This table presents an ablation study evaluating the robustness of the proposed Fusion module. It shows the performance of the Fusion module, trained with a specific denoising and IR network pair (MIRNet-S + SwinIR), when tested with different combinations of denoising (MIRNet-S or UDP) and IR (SwinIR or RRDB) networks. The results are measured using PSNR, SSIM, LPIPS, and TOPIQA metrics. This demonstrates how well the Fusion module generalizes when using different network pairs.
read the caption
Table 12: The performance of Fusion module for different train/test pair scenarios for 4x SR task.

🔼 This table presents the performance comparison of different methods for the Burst Joint Demosaicking, Denoising, and Super-Resolution (JDD-SR) task. Metrics include PSNR, SSIM, LPIPS, and TOPIQ, which assess various aspects of image quality. The number of Neural Function Evaluations (NFEs) and model parameters are also included, reflecting computational cost and model size.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.

🔼 This table presents the performance of different methods on the Burst Joint Demosaicking, Denoising and Super-Resolution (JDD-SR) task. Metrics used for evaluation include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Task-Oriented Perceptual Image Quality (TOPIQ). The number of Neural Function Evaluations (NFEs) and the number of model parameters are also included for comparison. The table highlights the best-performing method for each metric.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.

🔼 This table presents a quantitative comparison of different methods for Burst Joint Demosaicking, Denoising, and Super-Resolution (JDD-SR). It shows the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Task-Oriented Perceptual Image Quality (TOPIQ) scores achieved by each method. The number of Neural Function Evaluations (NFEs) and model parameters are also included to indicate computational cost. The best performing method for each metric is highlighted.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.

🔼 This table presents the performance comparison of different methods on the Burst Joint Demosaicking, Denoising and Super-Resolution (JDD-SR) task. Metrics used include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Task-Oriented Perceptual Image Quality (TOPIQ). The number of Neural Function Evaluations (NFEs) and model parameters are also shown to assess computational cost.
read the caption
Table 1: Performance evaluation on the task of Burst JDD-SR. We highlight the overall best for each metric.
Full paper#