TL;DR#
Deep neural networks (DNNs) are vulnerable to backdoor attacks, where attackers manipulate the training data to make the model misbehave when it sees specific trigger patterns. Existing defenses often struggle to completely remove backdoor effects without impacting the accuracy on clean data. This paper focuses on a new approach to solving this issue.
The researchers propose a two-stage defense method. First, they use clean unlearning data to identify and reinitialize the backdoor-related neurons. This stage leverages observations about the relationship between weight changes during clean and poisoned unlearning and the different activity levels of neurons in clean versus backdoored models. The second stage involves a fine-tuning process with gradient norm regulation to further prevent backdoor reactivation. The experimental results demonstrate that this new approach significantly outperforms existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on backdoor attacks and defenses in deep learning. It introduces a novel two-stage defense method that outperforms current state-of-the-art techniques and provides valuable insights into the behavior of clean unlearning and backdoor activeness, opening new avenues for more effective and robust defenses against malicious attacks on deep neural networks.
Visual Insights#

🔼 This figure illustrates two key observations about backdoored models. Observation 1 shows a positive correlation between neuron weight changes during clean and poison unlearning, suggesting that neurons significantly impacted by clean unlearning are also strongly associated with backdoor mechanisms. Observation 2 highlights that neurons in backdoored models are more active (exhibiting larger changes in gradient norm) than those in clean models during clean unlearning. These observations provide the basis for the proposed two-stage backdoor defense method.
read the caption
Figure 1: Illustration of two observations. Figures for Observation 1 show distributions of neuron weight changes during clean unlearning and poison unlearning. Figures for Observation 2 compare the average gradient norm for each neuron on the backdoored model and clean model, which are calculated with one-epoch clean unlearning. More active means a larger change in the gradient norm. Experiments are conducted on PreAct-ResNet18 [12] on CIFAR-10 [13] for the clean model and additional attacks with 10% poisoning ratio for the backdoored model. The last convolutional layers are chosen for illustration.
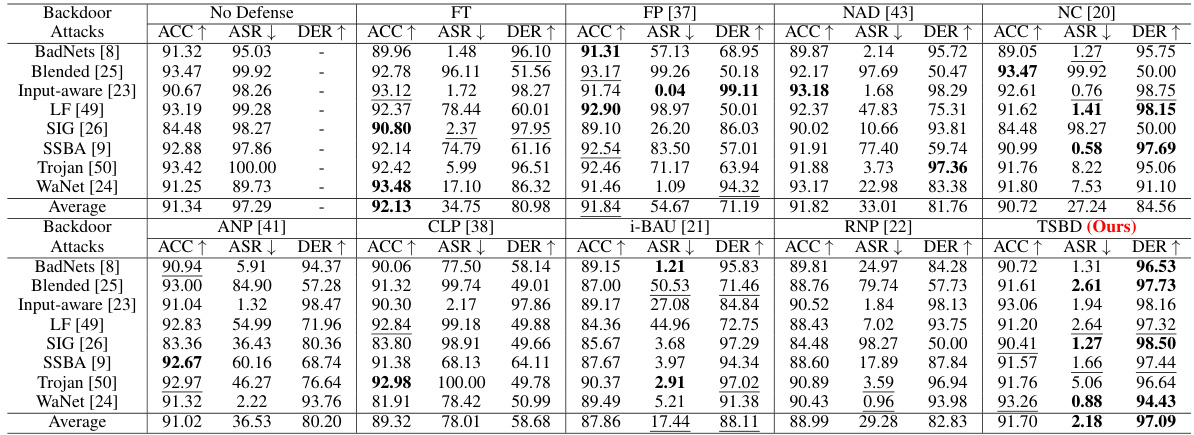
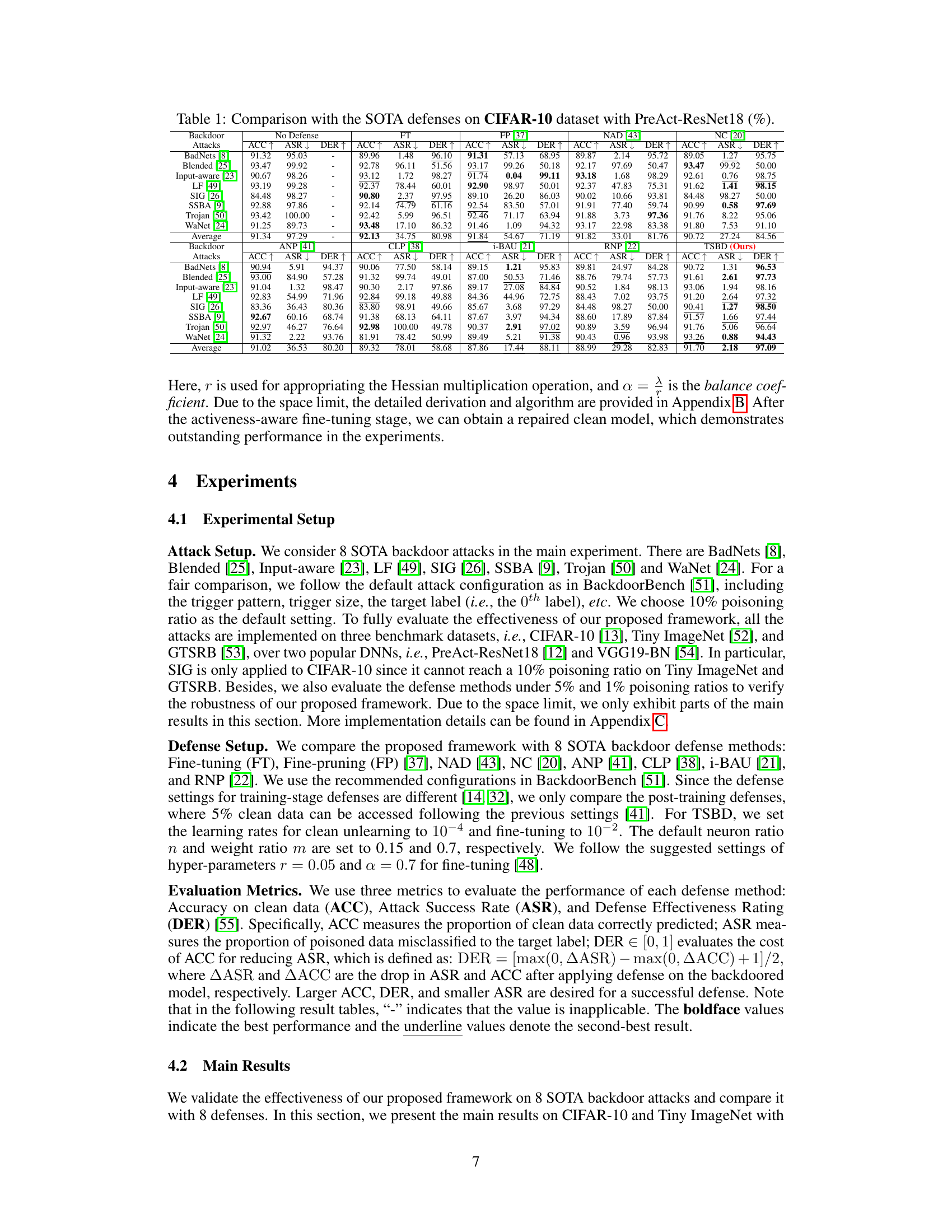
🔼 This table compares the proposed Two-Stage Backdoor Defense (TSBD) method with eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. It evaluates the performance of each method against eight different backdoor attacks using three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). Higher ACC and DER values, along with lower ASR, indicate better defense performance. The table provides a quantitative comparison of the effectiveness of TSBD against other SOTA methods.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).
In-depth insights#
Backdoor Unlearning#
Backdoor unlearning, a crucial aspect of backdoor defense in neural networks, focuses on mitigating the malicious behavior injected during the training phase. The core idea is to selectively remove or neutralize the backdoor’s influence without significantly harming the model’s performance on legitimate data. This is challenging because backdoors often subtly alter the network’s weight parameters, making them difficult to identify and remove. Effective backdoor unlearning techniques often involve analyzing the network’s weights, activations, and gradients to isolate the backdoor-related components. This may involve identifying neurons or pathways that are disproportionately activated by the trigger input. Methods like neuron weight change analysis and gradient norm regularization are used to refine and retrain the model, suppressing the backdoor’s activation while preserving its overall accuracy. However, the success of backdoor unlearning heavily depends on the sophistication of the attack and the quality of the available clean data. The process is particularly complex when there is limited or no poisoned data available for analysis.
Neuron Weight Changes#
Analyzing neuron weight changes in the context of backdoor attacks unveils crucial insights into model vulnerabilities. Clean unlearning, a process of removing clean data’s influence, reveals a positive correlation with weight changes observed during poison-based unlearning. This correlation highlights the possibility of identifying backdoor-related neurons without access to poisoned data. The concept of neuron activeness, measured by gradient norm changes, demonstrates that backdoored neurons exhibit higher activity. This observation points to the need for methods to suppress backdoored neuron activation during fine-tuning, preventing the backdoor effect’s reemergence. These findings are instrumental in developing effective defense mechanisms, enabling the targeted mitigation of backdoor vulnerabilities by combining weight re-initialization and activeness-aware fine-tuning.
Activeness-Aware Tuning#
Activeness-Aware Fine-tuning is a crucial stage in the proposed Two-Stage Backdoor Defense (TSBD) method. It directly addresses the observation that backdoored models exhibit higher neuron activeness during the learning process than clean models. This heightened activeness, measured by the average gradient norm, indicates a greater susceptibility to backdoor reactivation during standard fine-tuning. Activeness-Aware Fine-tuning mitigates this by incorporating gradient-norm regulation into the loss function, effectively suppressing the activity of these susceptible neurons. This approach prevents the unintentional reinstatement of the backdoor effect while recovering clean accuracy. The method’s superior performance highlights the importance of considering neuron activeness in backdoor defense strategies. The use of gradient-norm regulation is a key innovation, offering a more effective alternative to standard fine-tuning.
Two-Stage Defense#
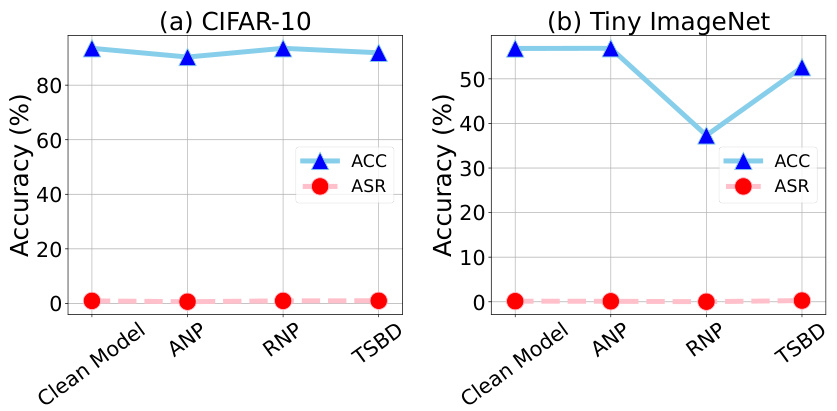
A two-stage defense mechanism is proposed to effectively mitigate backdoor vulnerabilities in deep neural networks. Stage 1 focuses on backdoor re-initialization, leveraging the correlation between weight changes during clean and poisoned unlearning to identify and neutralize backdoor-related neurons without needing poisoned data. This is achieved by efficiently reinitializing a calculated subset of the most significantly altered neuron weights to zero. Stage 2 involves activeness-aware fine-tuning, addressing the issue of backdoor reactivation during the standard fine-tuning process. By regulating gradient norms during fine-tuning, the method effectively suppresses excessive neuron activations associated with the backdoor, enhancing clean accuracy recovery. This two-pronged approach, combining targeted backdoor neuron elimination with controlled fine-tuning, is shown to significantly improve backdoor defense performance compared to existing state-of-the-art methods across several benchmark datasets and attack types.
Future Work#
Future research directions stemming from this backdoor defense work could explore several promising avenues. Improving the efficiency of the two-stage defense is crucial, potentially through more efficient neuron selection methods or alternative reinitialization strategies. Investigating the generalizability of the proposed approach across diverse model architectures and datasets beyond the benchmarks tested is essential to validate its robustness. A deeper exploration into the interaction between backdoor attacks and various defense mechanisms is needed. This includes understanding the limitations of the defense, particularly against advanced, adaptive attack techniques. Finally, exploring data-free or minimal-data backdoor defenses is a critical future direction, to address scenarios with limited or no access to clean data for training.
More visual insights#
More on figures

🔼 The figure shows a flowchart of the proposed two-stage backdoor defense framework. The first stage is Neuron Weight Change-based Backdoor Reinitialization, which involves clean unlearning, neuron weight change calculation, and zero reinitialization. The second stage is Activeness-aware Fine-tuning, which involves fine-tuning with gradient-norm regulation. The framework aims to mitigate the backdoor effect while maintaining the performance on clean data.
read the caption
Figure 2: Overview of the proposed Two-Stage Backdoor Defense framework.

🔼 This figure shows the distributions of clean and poisoned neuron activations on original clean and backdoored models. The subfigures (a) and (b) show the distributions of activations for each neuron from the last convolutional layer of the clean model and backdoored model respectively. Subfigure (c) shows the changes of activations during the clean and poisoned unlearning for the neurons of the backdoored model.
read the caption
Figure 3: Illustration of clean and poison activations of each neuron. (a) and (b) represent the activations on the original clean and backdoored model, respectively. (c) shows the activation changes during the clean and poison unlearning on backdoored model. Activations are captured from the last convolutional layer with an additional Relu activation function on PreAct-ResNet18 [12].
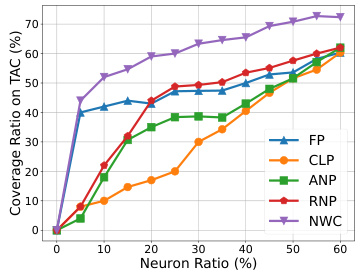
🔼 The figure shows the comparison of neuron coverage ratio on TAC (Trigger-activated Change) under different neuron ratios for five different methods: FP (Fine-pruning), CLP (Channel Lipschitz), ANP (Adversarial Neuron Pruning), RNP (Reconstructive Neuron Pruning), and NWC (Neuron Weight Change). The x-axis represents the neuron ratio (percentage of neurons selected for reinitialization or pruning), and the y-axis represents the coverage ratio on TAC (percentage of overlapping neurons between the selected neurons and the TAC metric). The graph illustrates the effectiveness of each method in identifying backdoor-related neurons. NWC shows consistently higher coverage ratio compared to other methods, indicating its superior ability in pinpointing backdoor-related neurons using clean unlearning.
read the caption
Figure 4: Comparison of neuron coverage ratio on TAC under different neuron ratios.

🔼 This figure shows the distributions of neuron activations during clean and poison unlearning and poison unlearning for backdoored models. The plots illustrate two key observations: 1) the positive correlation between weight changes in clean and poison unlearning, suggesting the possibility of identifying backdoor-related neurons without poisoned data; 2) the higher activation levels (larger gradient norm changes) in backdoored models compared to clean models, indicating a need to suppress gradient norms during fine-tuning to mitigate the backdoor effect.
read the caption
Figure 3: Illustration of clean and poison activations of each neuron. (a) and (b) represent the activations on the original clean and backdoored model, respectively. (c) shows the activation changes during the clean and poison unlearning on backdoored model. Activations are captured from the last convolutional layer with an additional Relu activation function on PreAct-ResNet18 [12].

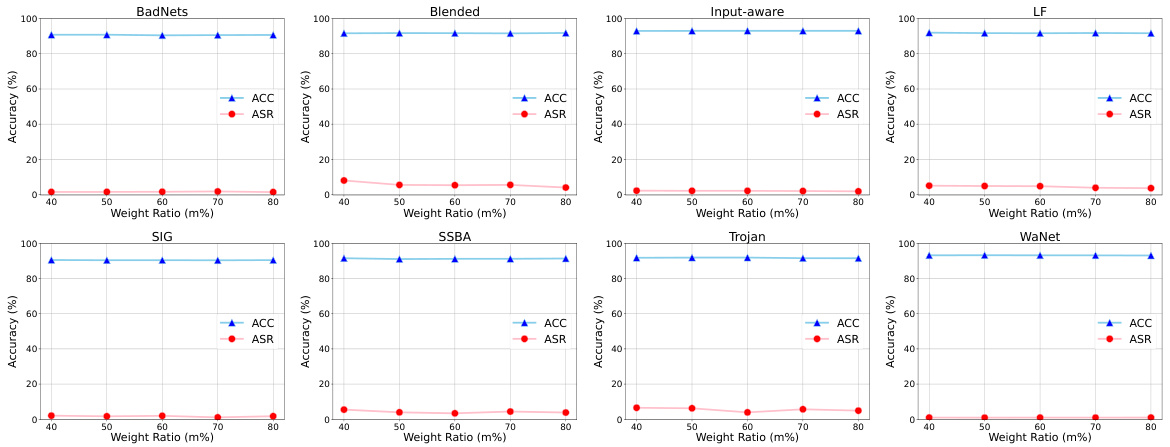
🔼 This figure shows the accuracy (ACC) and attack success rate (ASR) under different poisoning ratios (10%, 5%, and 1%) for various backdoor attacks. It illustrates how the performance of the TSBD defense method changes with varying attack strengths. Generally, higher poisoning rates lead to lower accuracy and higher attack success rates, but the TSBD method shows a relatively consistent defense performance.
read the caption
Figure 6: ACC and ASR on different poisoning ratios.
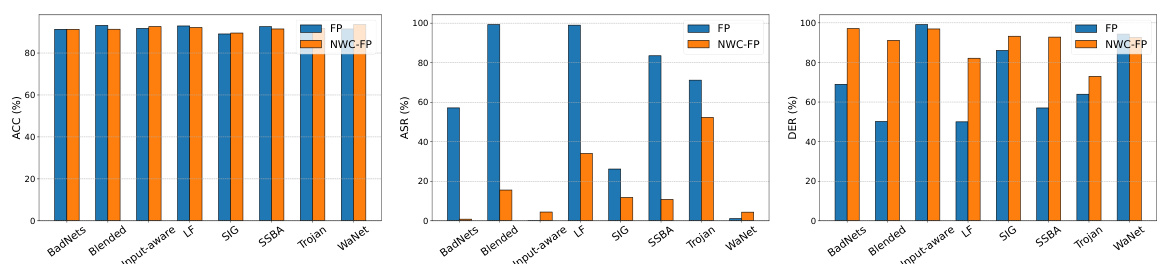
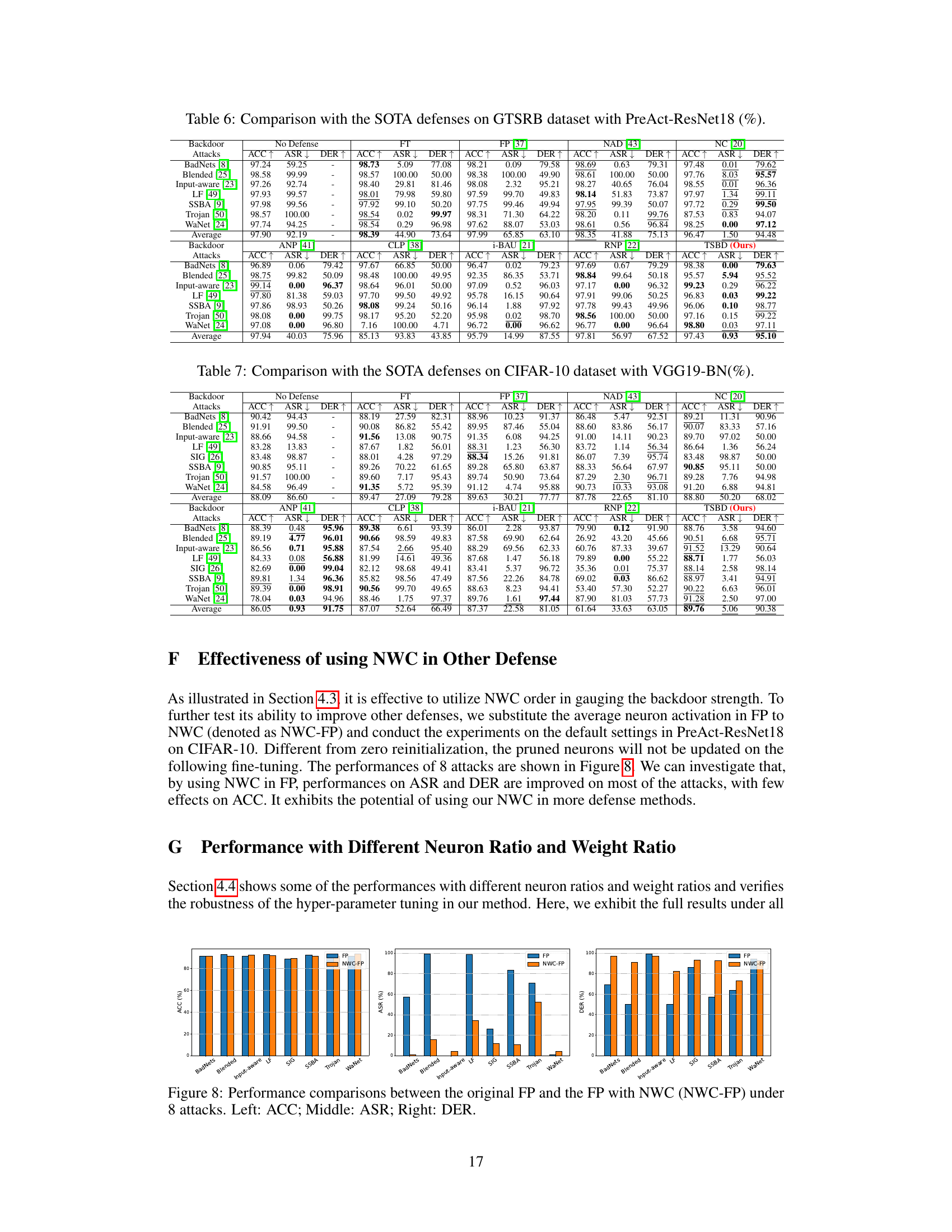
🔼 This figure compares the performance of the original Fine-Pruning (FP) method with a modified version using the Neuron Weight Change (NWC) order (NWC-FP) for backdoor defense. The performance is evaluated across eight different backdoor attacks (BadNets, Blended, Input-aware, LF, SIG, SSBA, Trojan, and WaNet) using three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). The bar chart visually represents the differences in performance between the two methods for each of the attacks, allowing for a direct comparison of their effectiveness in mitigating backdoor vulnerabilities.
read the caption
Figure 8: Performance comparisons between the original FP and the FP with NWC (NWC-FP) under 8 attacks. Left: ACC; Middle: ASR; Right: DER.

🔼 This figure shows the neuron activations for clean and poisoned data in the original clean model, original backdoored model and after clean and poison unlearning on the backdoored model. It helps to visualize observations 1 and 2 mentioned in the paper. Specifically, it illustrates that the weight changes between poison and clean unlearning are positively correlated, and that neurons in the backdoored model are more active than those in the clean model.
read the caption
Figure 3: Illustration of clean and poison activations of each neuron. (a) and (b) represent the activations on the original clean and backdoored model, respectively. (c) shows the activation changes during the clean and poison unlearning on backdoored model. Activations are captured from the last convolutional layer with an additional Relu activation function on PreAct-ResNet18 [12].
🔼 This figure shows three subfigures illustrating the clean and poison activations of each neuron in a model. Subfigure (a) displays activations for a clean model, subfigure (b) for a backdoored model, and subfigure (c) compares activation changes during clean versus poison unlearning in the backdoored model. The activations are captured from the last convolutional layer of a PreAct-ResNet18 model, after passing through a ReLU activation function. The figure visually supports the paper’s observations about the differing activity of neurons in clean versus backdoored models and how these activities change during unlearning processes.
read the caption
Figure 3: Illustration of clean and poison activations of each neuron. (a) and (b) represent the activations on the original clean and backdoored model, respectively. (c) shows the activation changes during the clean and poison unlearning on backdoored model. Activations are captured from the last convolutional layer with an additional Relu activation function on PreAct-ResNet18 [12].
🔼 This figure shows two key observations about backdoored models. Observation 1 demonstrates a positive correlation between weight changes during clean and poison unlearning. Observation 2 shows that neurons in backdoored models are more active (higher gradient norm changes) during clean unlearning compared to clean models. These observations are illustrated using data from PreAct-ResNet18 trained on CIFAR-10, with 10% poisoned data.
read the caption
Figure 1: Illustration of two observations. Figures for Observation 1 show distributions of neuron weight changes during clean unlearning and poison unlearning. Figures for Observation 2 compare the average gradient norm for each neuron on the backdoored model and clean model, which are calculated with one-epoch clean unlearning. More active means a larger change in the gradient norm. Experiments are conducted on PreAct-ResNet18 [12] on CIFAR-10 [13] for the clean model and additional attacks with 10% poisoning ratio for the backdoored model. The last convolutional layers are chosen for illustration.
More on tables
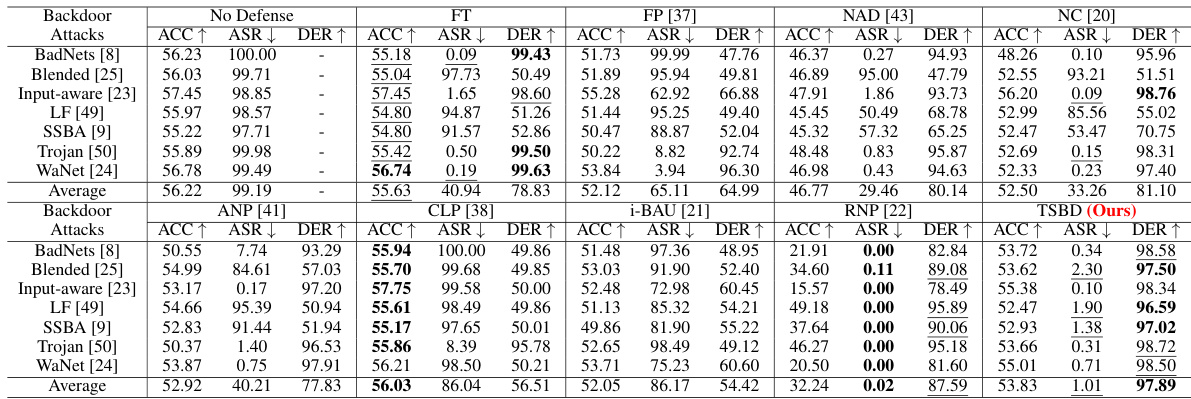
🔼 This table compares the performance of the proposed Two-Stage Backdoor Defense (TSBD) method against eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. The comparison is based on three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). Eight different backdoor attacks are evaluated.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).
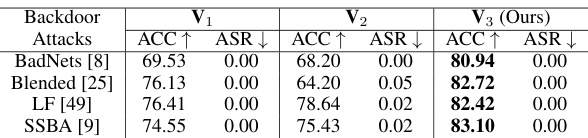
🔼 This table compares three different reinitialization schemes (V1, V2, and V3 - TSBD’s method) on CIFAR-10 using PreAct-ResNet18. It evaluates the effectiveness of these schemes against four different backdoor attacks (BadNets, Blended, LF, and SSBA). For each scheme, it shows the Accuracy (ACC↑) and Attack Success Rate (ASR↓). The results demonstrate that TSBD’s reinitialization strategy (V3) achieves significantly higher accuracy while maintaining a near-zero ASR compared to other methods. This highlights the superior performance of the proposed two-stage defense method.
read the caption
Table 3: Comparison of different reinitialization schemes on CIFAR-10 with PreAct-ResNet18 (%)
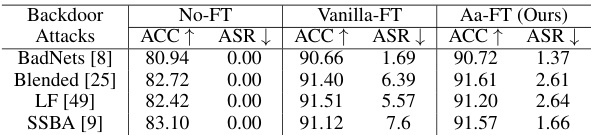
🔼 This table compares the performance of three different fine-tuning approaches on the CIFAR-10 dataset using the PreAct-ResNet18 model. The three approaches are: No fine-tuning (No-FT), vanilla fine-tuning (Vanilla-FT), and the proposed activeness-aware fine-tuning (Aa-FT). The table shows the accuracy (ACC↑) and attack success rate (ASR↓) for each method across four different backdoor attacks. The results demonstrate the effectiveness of the proposed Aa-FT in improving both accuracy and reducing the attack success rate compared to the other methods.
read the caption
Table 4: Comparison of different fine-tuning schemes on CIFAR-10 with PreAct-ResNet18 (%).

🔼 This table compares the performance of the proposed Two-Stage Backdoor Defense (TSBD) method against eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. The comparison is based on three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). The table shows the performance of each method under eight different backdoor attacks, highlighting the superior performance of TSBD in terms of achieving high ACC and DER while maintaining a low ASR.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).

🔼 This table compares the proposed Two-Stage Backdoor Defense (TSBD) method with eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. It evaluates the performance of each method across eight different backdoor attacks. The table presents the accuracy on clean data (ACC), attack success rate (ASR), and defense effectiveness rating (DER) for each method and attack. Higher ACC and DER, and lower ASR indicate better defense performance.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).

🔼 This table compares the proposed Two-Stage Backdoor Defense (TSBD) method with eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. It evaluates the performance of each method across eight different backdoor attacks using three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). Higher ACC and DER values, along with lower ASR values, indicate better defense performance. The table allows for a quantitative comparison of TSBD against existing methods.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).

🔼 This table compares the performance of the proposed Two-Stage Backdoor Defense (TSBD) method against eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. The comparison is based on three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). Each row represents a different backdoor attack, and each column represents a different defense method or the baseline (no defense). Higher ACC and DER values, and lower ASR values indicate better defense performance.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).

🔼 This table compares the performance of the proposed Two-Stage Backdoor Defense (TSBD) method against eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. The comparison is based on three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). Each row represents a different backdoor attack, and the columns show the performance of each defense method on that attack. Higher ACC and DER values and lower ASR values indicate better defense performance.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).

🔼 This table compares the performance of different defense methods on the CIFAR-10 dataset using the ViT-b-16 model. The table shows the accuracy (ACC↑) and attack success rate (ASR↓) for different attacks (Input-aware and WaNet). It demonstrates the effectiveness of the proposed TSBD method compared to other state-of-the-art defenses (CLP, ANP).
read the caption
Table 10: Performance on CIFAR-10 with ViT-b-16 (%).

🔼 This table compares the performance of the proposed Two-Stage Backdoor Defense (TSBD) method against other state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. The table presents results for eight different backdoor attacks. For each attack and defense method, the table shows the accuracy on clean data (ACC), attack success rate (ASR), and defense effectiveness rating (DER). Higher ACC and DER values, and lower ASR values, indicate better performance.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).

🔼 This table compares the performance of the proposed Two-Stage Backdoor Defense (TSBD) method against eight state-of-the-art (SOTA) backdoor defense methods on the CIFAR-10 dataset using the PreAct-ResNet18 model. The comparison is based on three metrics: Accuracy on clean data (ACC), Attack Success Rate (ASR), and Defense Effectiveness Rating (DER). Eight different backdoor attacks are evaluated. Higher ACC and DER, and lower ASR, indicate better defense performance. The table helps demonstrate the superior performance of TSBD compared to other SOTA methods.
read the caption
Table 1: Comparison with the SOTA defenses on CIFAR-10 dataset with PreAct-ResNet18 (%).
Full paper#