↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Long-tailed object detection struggles with data imbalance and simplicity bias, hindering accurate detection of under-represented classes. Existing pre-training methods often fall short in addressing these issues.
This paper proposes a novel pre-training framework, 2DRCL, to tackle these challenges. 2DRCL uses Holistic-Local Contrastive Learning to align pre-training with object detection, a dynamic rebalancing strategy to adjust for data imbalance, and dual reconstruction to reduce simplicity bias. Experiments show significant improvements in the mean average precision (mAP) and average precision (AP) for all classes, especially for those with limited training examples. This demonstrates the effectiveness of 2DRCL for improving object detection performance in real-world scenarios where data might be imbalanced.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in object detection due to its novel approach to pre-training, especially for long-tailed distributions. It introduces a dynamic rebalancing strategy and dual reconstruction, effectively addressing simplicity bias and data imbalance. The improved performance on benchmark datasets highlights the potential for advancements in real-world applications, particularly for scenarios with limited data. This work provides a significant improvement over traditional methods and opens avenues for further research into addressing long-tailed scenarios in computer vision.
Visual Insights#
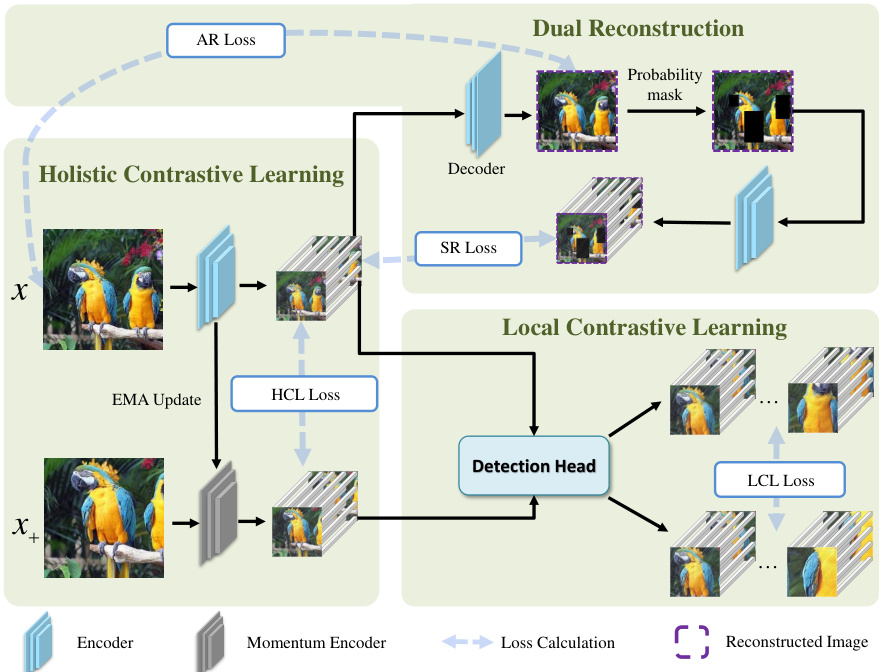
This figure illustrates the 2DRCL framework, showing its three main components: Holistic Contrastive Learning (HCL), Local Contrastive Learning (LCL), and Dual Reconstruction (DRC). HCL learns global image-level representations, LCL learns local object-level representations, and DRC mitigates simplicity bias through appearance and semantic reconstruction. The entire network is trained end-to-end.
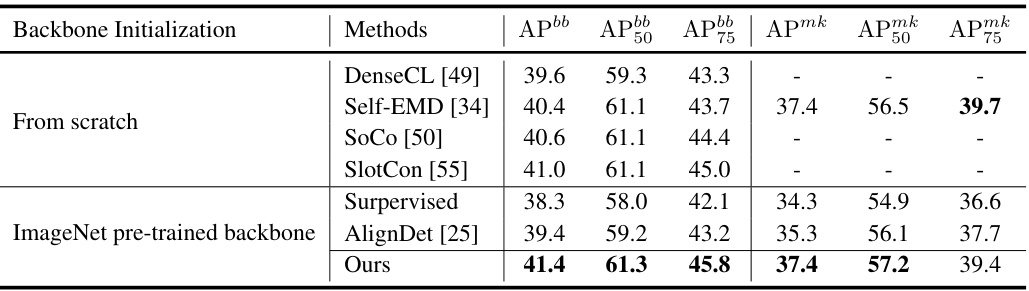
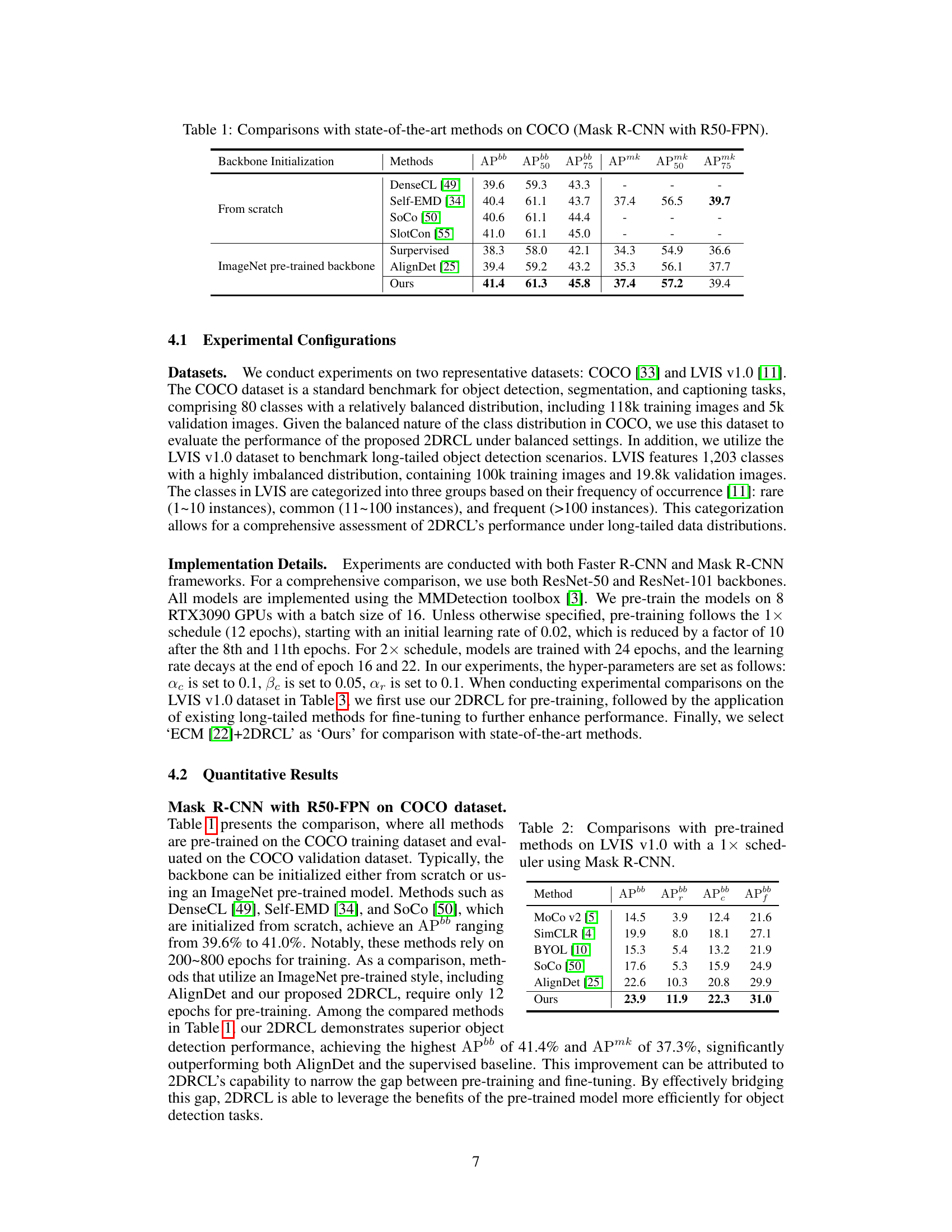
This table compares the performance of different object detection methods on the COCO dataset using Mask R-CNN with a ResNet-50 Feature Pyramid Network (FPN) backbone. The methods are categorized by their backbone initialization (from scratch or ImageNet pre-trained) and their performance is measured using several metrics: AP (average precision), AP50 (AP at an IoU threshold of 50%), AP75 (AP at an IoU threshold of 75%), APmk (average precision for masks), APmk50, and APmk75. The table highlights the superior performance of the proposed method, particularly in improving mAP.
In-depth insights#
Long-Tail Detection#
Long-tail detection in object detection addresses the challenge of imbalanced class distributions, where some classes have significantly fewer training examples than others. This imbalance leads to biased models that perform poorly on under-represented classes, also known as the tail. Effective long-tail detection strategies strive to improve the accuracy and performance on these tail classes without sacrificing the accuracy on head classes. Common approaches involve data augmentation techniques to synthesize more tail examples, careful data sampling (e.g., re-weighting or oversampling) during training, and the design of specialized loss functions that penalize misclassifications of tail classes less harshly than head classes. Some methods also focus on feature representation learning to capture more discriminative features for the underrepresented classes, or employ techniques such as class-balanced sampling or curriculum learning to address the imbalance progressively. A key focus is to balance generalization ability across all classes while avoiding overfitting to head classes. Ultimately, the effectiveness of any long-tail detection method is evaluated based on its ability to enhance the performance on the tail classes while maintaining a competitive overall performance.
Contrastive Learning#
Contrastive learning, a self-supervised learning approach, plays a crucial role in the paper by enabling the model to learn effective feature representations without relying on labeled data. The core idea revolves around learning by comparing and contrasting different data points. Holistic Contrastive Learning (HCL) focuses on capturing global contextual semantics, while Local Contrastive Learning (LCL) concentrates on detailed local patterns. This dual approach allows the model to learn both general visual representations and fine-grained object-level features, crucial for object detection tasks. The combination of HCL and LCL forms the foundation of the Holistic-Local Contrastive Learning (HLCL) paradigm. HLCL is particularly effective in aligning pre-training with object detection, leading to better performance. The paper further enhances contrastive learning by addressing the challenges of long-tailed distributions and simplicity bias through dynamic rebalancing and dual reconstruction techniques. This innovative approach ensures that the model is robust and capable of handling complex visual patterns, leading to improved accuracy in object detection, especially for under-represented classes.
Dual Reconstruction#
The proposed “Dual Reconstruction” method cleverly tackles the inherent “simplicity bias” in deep learning models, particularly relevant for long-tailed object detection. It uses two reconstruction tasks to encourage the model to learn both complex and subtle features. The first, “Appearance Reconstruction,” focuses on precise pixel-level reconstruction, forcing the model to capture fine-grained visual details. The second, “Semantic Reconstruction,” uses a masked image, forcing the model to learn semantic relationships rather than just relying on superficial visual cues. By combining these two complementary approaches, Dual Reconstruction helps the model overcome the tendency to favor simple solutions at the expense of complex ones, particularly benefiting under-represented classes in long-tailed datasets. This is a significant contribution because it addresses a critical limitation of many existing models, leading to improved accuracy and generalization, especially for those rare, under-represented classes which are typically overlooked by simpler models.
Dynamic Rebalancing#
Dynamic rebalancing, in the context of long-tailed object detection pre-training, addresses the inherent class imbalance problem. Traditional resampling techniques often fall short, focusing primarily on balancing class representation at the image level. This approach fails to adequately address the imbalance at the instance level (i.e., the uneven distribution of object proposals for different classes). Dynamic rebalancing goes further by introducing a more sophisticated, adaptive strategy. This strategy dynamically adjusts the sampling rate of different classes throughout the pre-training process, giving increased emphasis to under-represented classes. The adaptive nature of this method is crucial; it ensures that tail classes, which are often most affected by the class imbalance problem, receive the attention they need to improve model performance and avoid the ‘simplicity bias’ where simpler, common patterns are overemphasized. By dynamically re-weighting samples and adjusting sampling frequencies throughout training, this method aims to create a more robust and balanced representation of all classes for improved model generalization and accuracy.
Pre-train Framework#
A robust pre-training framework for object detection, especially tackling long-tailed distributions, is crucial for improved performance. Dynamic Rebalancing Contrastive Learning with Dual Reconstruction (2DRCL) is proposed as such a framework, addressing inherent data imbalance and simplicity bias. The framework leverages a Holistic-Local Contrastive Learning (HLCL) mechanism to capture both global context and detailed local patterns, effectively aligning pre-training with object detection tasks. A key innovation is the dynamic rebalancing strategy, which adjusts sampling to prioritize underrepresented classes, improving the representation of tail classes throughout the process. Furthermore, Dual Reconstruction helps mitigate the simplicity bias by enforcing a reconstruction task aligned with the self-consistency principle. This dual approach ensures that the model learns both complex patterns and subtle details, leading to better performance on challenging long-tailed datasets. The effectiveness of 2DRCL is demonstrated through experiments on COCO and LVIS v1.0, showing significant improvements in mAP/AP scores, particularly for tail classes. The holistic and local contrastive learning approach, in addition to the dual reconstruction and dynamic rebalancing aspects, appear to provide a more robust and effective pre-training solution for improving the accuracy and reliability of object detection across various data distributions.
More visual insights#
More on figures
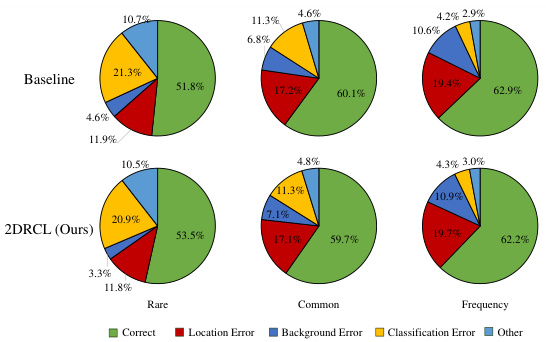
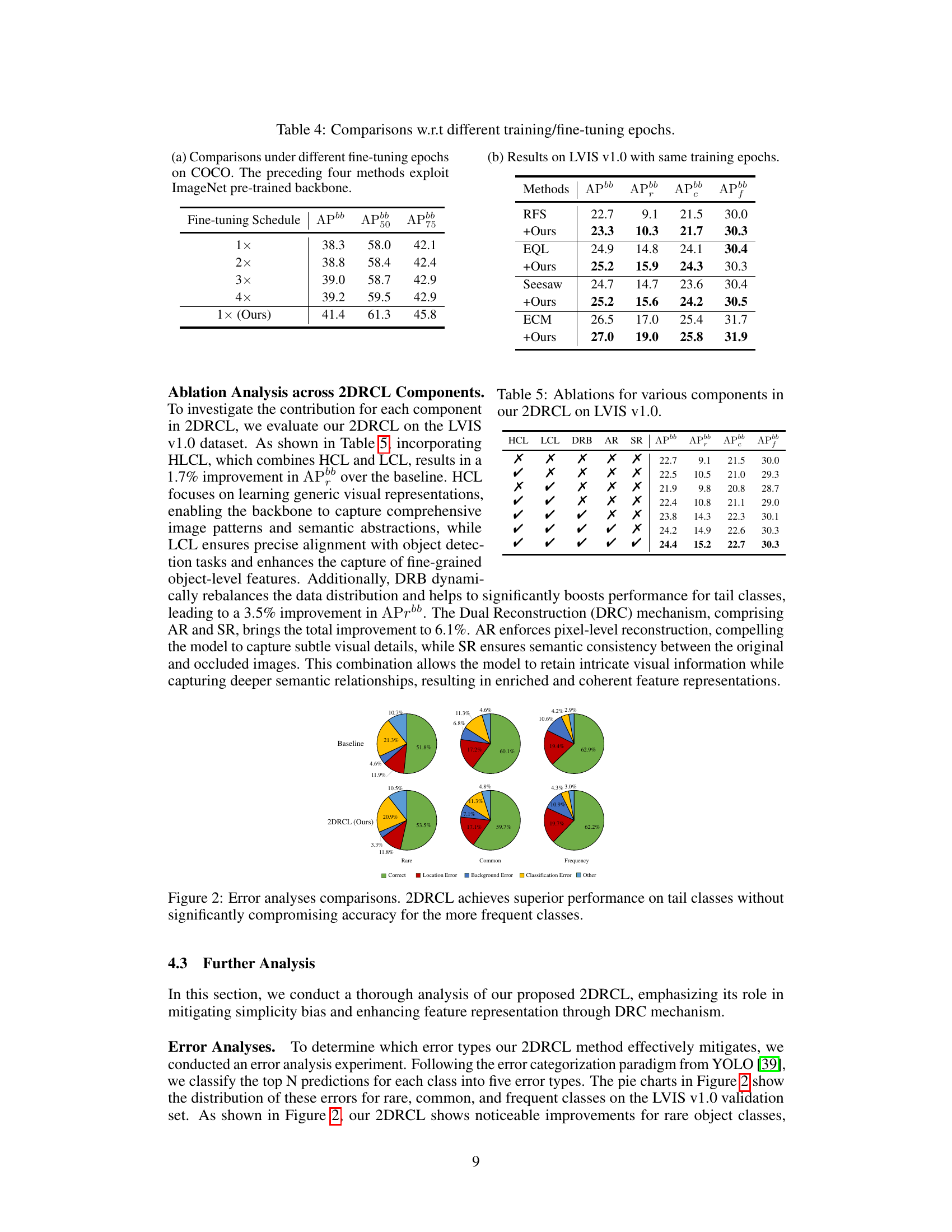
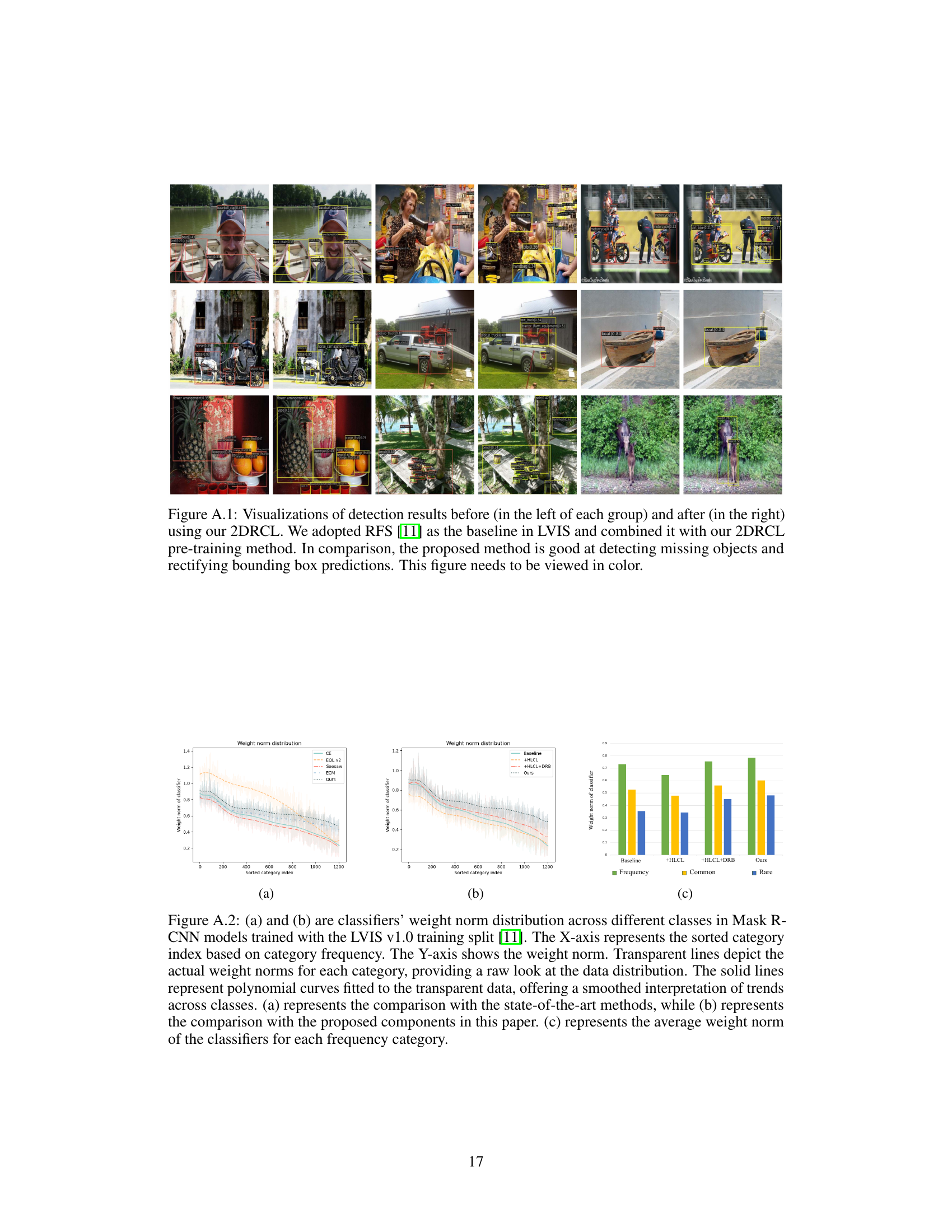
This figure presents a comparison of error analysis between the baseline method and the proposed 2DRCL method. The error types are categorized into five types: Correct, Location Error, Background Error, Classification Error, and Other. The pie charts show the distribution of these errors for three frequency categories of classes (Rare, Common, and Frequent) in the LVIS v1.0 validation set. The results demonstrate that 2DRCL significantly improves the performance on tail classes (rare classes) without a substantial decrease in accuracy for more frequent classes.

This figure compares attention maps from four different methods (Baseline, ECM, 2DRCL without Dual Reconstruction, and 2DRCL) on the LVIS dataset. Each row shows the attention map for a specific image and method. The top row shows the class of the corresponding image. Red color indicates high attention. It demonstrates that 2DRCL effectively mitigates simplicity bias by learning more comprehensive patterns that encompass informative regions, particularly for images belonging to tail classes.

This figure illustrates the architecture of the proposed Dynamic Rebalancing Contrastive Learning with Dual Reconstruction (2DRCL) method. It shows the three main components: Holistic Contrastive Learning (HCL), Local Contrastive Learning (LCL), and Dual Reconstruction. HCL focuses on global image-level understanding, LCL focuses on detailed local object patterns, and Dual Reconstruction aims to mitigate simplicity bias. The entire network is trained end-to-end.

This figure illustrates the architecture of the Dynamic Rebalancing Contrastive Learning with Dual Reconstruction (2DRCL) method. It shows the three main components of the method: Holistic Contrastive Learning (HCL), Local Contrastive Learning (LCL), and Dual Reconstruction. The HCL component focuses on learning general visual representations, while the LCL component focuses on learning object-level representations. The Dual Reconstruction component aims to mitigate simplicity bias by enforcing both pixel-level and semantic consistency. The figure shows how these three components are integrated into a single network that can be trained in an end-to-end manner.
More on tables

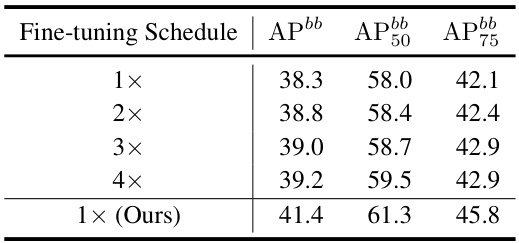
This table compares the performance of the proposed 2DRCL method against several pre-trained methods on the LVIS v1.0 dataset using the Mask R-CNN framework with a 1x scheduler. It shows the Average Precision (APbb) for different categories of objects (rare, common, frequent) and the overall APbb score. The results demonstrate the superiority of 2DRCL in handling long-tailed distributions in object detection, significantly outperforming other pre-trained models, particularly in detecting rare objects.

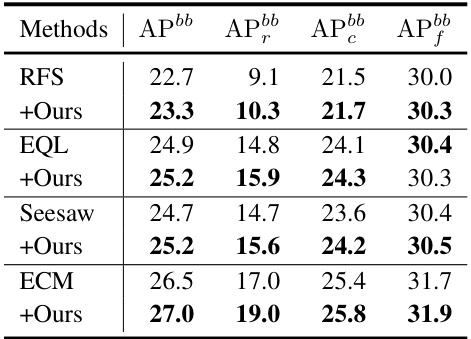
This table compares the proposed 2DRCL method with other state-of-the-art methods on the LVIS v1.0 dataset using two different backbones (ResNet-50 and ResNet-101) and two different detectors (Faster R-CNN and Mask R-CNN) with 2x training schedule. The results show the Average Precision (AP) scores for the overall dataset (APbb), rare classes (APbb r), common classes (APbb c), and frequent classes (APbb f) for each method. This table demonstrates the effectiveness of 2DRCL, particularly on tail classes.
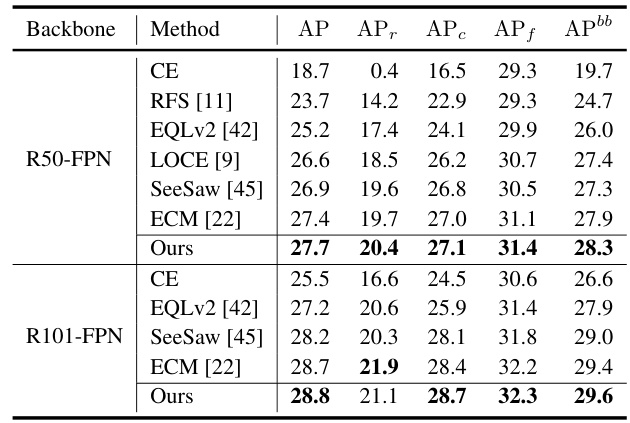
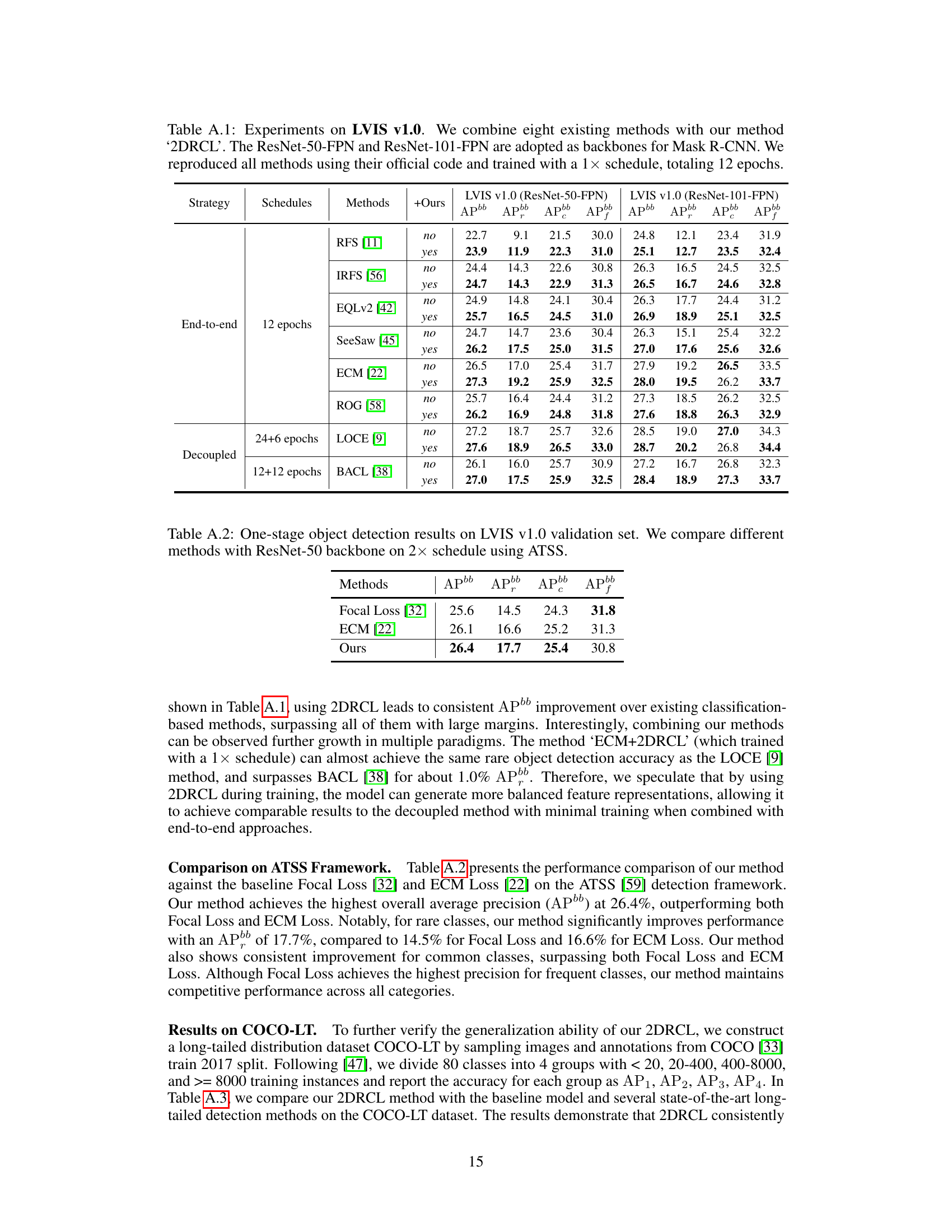
This table presents a comparison of the proposed 2DRCL method with several state-of-the-art methods on the LVIS v1.0 dataset using Faster R-CNN and Mask R-CNN with ResNet-50 and ResNet-101 backbones. The results show the AP, APr, APc, APf, and APbb scores for each method, illustrating the effectiveness of 2DRCL, particularly in improving the performance on tail classes.
This table compares the performance of the proposed method with other state-of-the-art methods on the COCO dataset using Mask R-CNN with a ResNet50-FPN backbone. It shows the Average Precision (AP) for bounding boxes (APbb) at different Intersection over Union (IoU) thresholds (50 and 75) and for masks (APmk). The comparison is broken down into methods initialized from scratch and those using an ImageNet pre-trained backbone. The table highlights the superior performance of the proposed method.
This table compares the performance of the proposed Dynamic Rebalancing Contrastive Learning with Dual Reconstruction (2DRCL) method against several state-of-the-art pre-trained methods on the LVIS v1.0 dataset. The comparison uses the Mask R-CNN framework and a 1× scheduler. The table highlights the performance on different classes (rare, common, frequent) as measured by Average Precision (APbb) scores. It shows how 2DRCL improves upon existing pre-training methods, particularly for tail classes (rare classes).
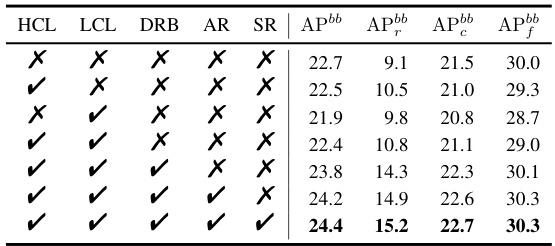
This ablation study analyzes the impact of each component of the proposed 2DRCL model on the LVIS v1.0 dataset. It shows the effect of using Holistic Contrastive Learning (HCL), Local Contrastive Learning (LCL), Dynamic Rebalancing (DRB), Appearance Reconstruction (AR), and Semantic Reconstruction (SR), both individually and in combination, on the object detection performance, specifically measuring Average Precision (AP) for different object frequency categories (rare, common, and frequent).
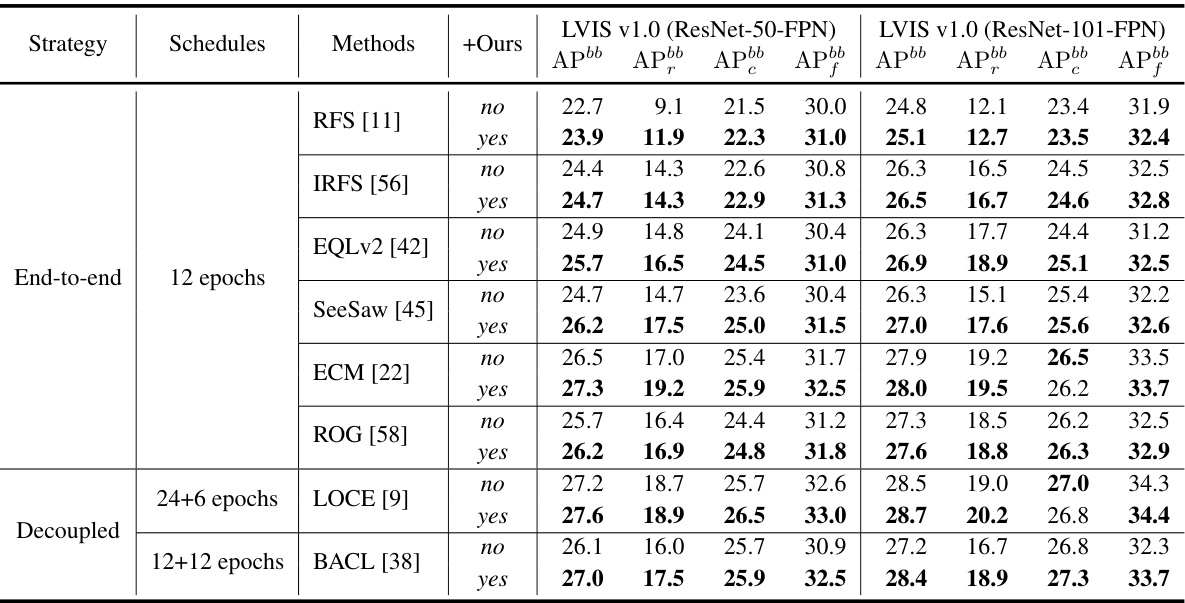
This table presents a comparison of the proposed 2DRCL method with other state-of-the-art methods on the LVIS v1.0 dataset using Faster R-CNN and Mask R-CNN with ResNet-50/101 backbones. It shows the performance using a 2x training schedule (24 epochs) and the results are broken down by AP scores for rare, common, and frequent classes, as well as overall APbb and AP scores.
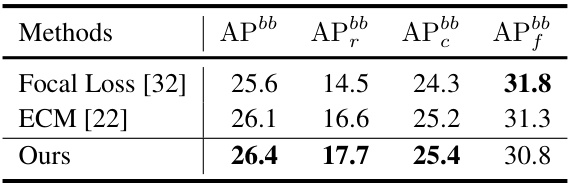
This table presents a comparison of one-stage object detection methods (using the ATSS framework) on the LVIS v1.0 validation set. The comparison is limited to methods using the ResNet-50 backbone and trained with a 2x schedule. The table shows the average precision (AP) and average precision for different categories of objects (rare, common, and frequent). It highlights the performance improvements achieved by the proposed 2DRCL method compared to baseline approaches such as Focal Loss and ECM Loss.
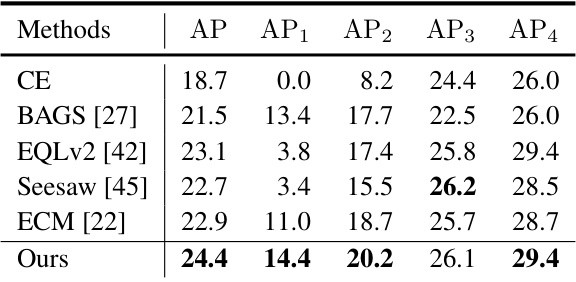
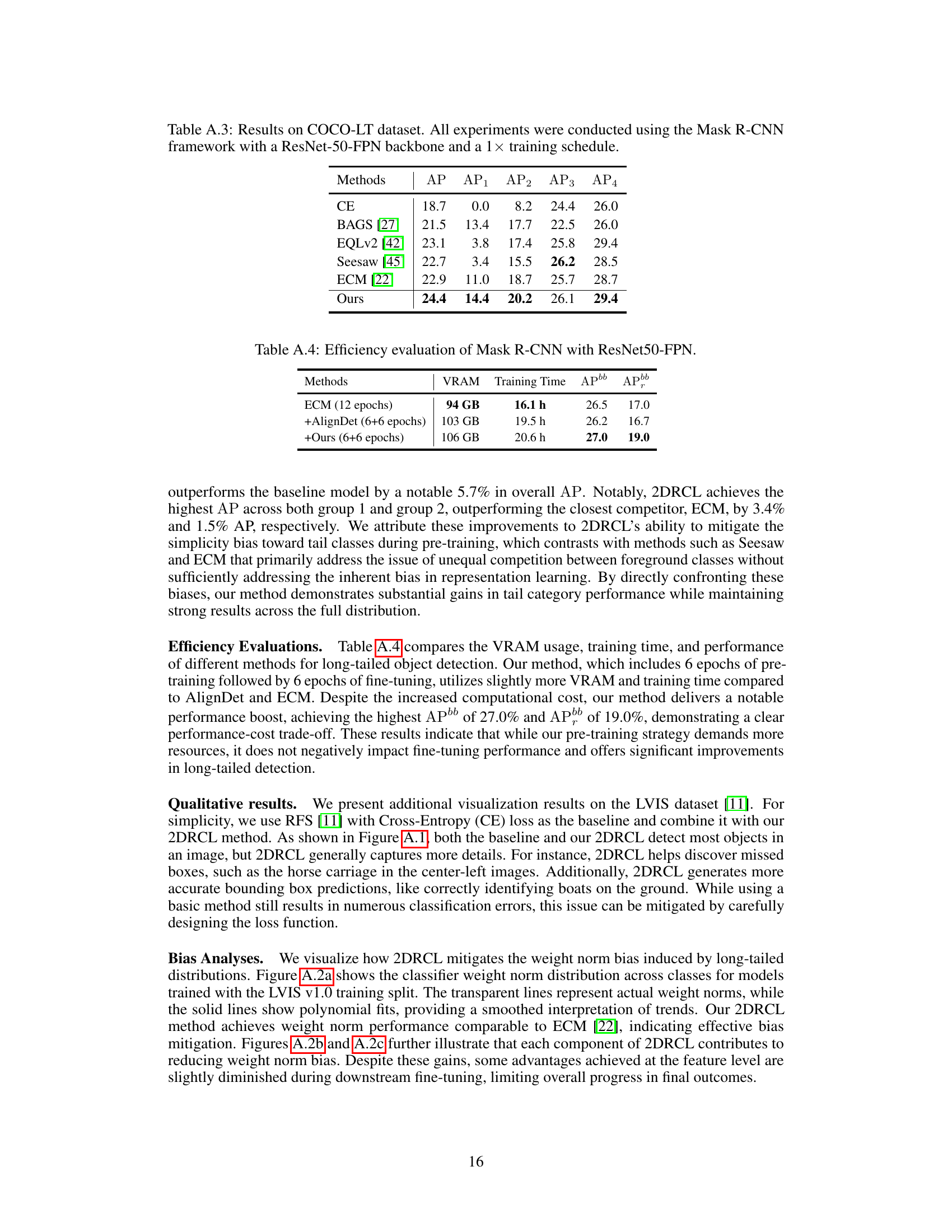
This table presents a comparison of different long-tailed object detection methods on the COCO-LT dataset. The methods are evaluated based on their average precision (AP) across all classes and across four different class frequency groups (AP1, AP2, AP3, and AP4). The groups represent classes with increasing numbers of training instances, allowing assessment of how well the methods perform on classes with varying levels of data imbalance. The table showcases how the proposed 2DRCL method performs against other state-of-the-art methods for long-tailed object detection.

This table compares the VRAM usage, training time, and the performance of different methods for long-tailed object detection. The results show a trade-off between resource usage and performance gains. The method combining 2DRCL with AlignDet achieves the highest AP and APbb, but requires more VRAM and training time compared to other approaches.
Full paper#