TL;DR#
Estimating body pose from egocentric videos is crucial for immersive AR/VR, but current methods often rely on dense sensor data. This limits their applicability in scenarios with limited sensor visibility. This paper addresses this limitation by focusing on doubly sparse data (sparse in time and space) which is more common in practical applications. It examines how even sparse observations, like occasional hand poses captured during natural movement, are valuable in estimating overall body motion.
The paper proposes DSPoser, a two-stage approach. First, it uses masked autoencoders to impute missing hand pose data by leveraging temporal and spatial correlations with the available head pose data. This stage also provides uncertainty estimates for the imputed data. Second, conditional diffusion models are employed to generate the complete body pose. Uncertainty information from the first stage guides the diffusion process, leading to more plausible and accurate full-body pose predictions. The comprehensive evaluation on two large datasets showcases that DSPoser’s performance surpasses existing methods, especially when dealing with doubly sparse input data, and is robust in diverse AR/VR conditions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to estimating ego-body pose from limited sensor data, a crucial challenge in augmented reality. The method’s robustness and adaptability to various AR/VR setups could significantly advance human-computer interaction and immersive experiences. Its innovative use of masked autoencoders and conditional diffusion models opens new avenues for research in human pose estimation, and the incorporation of uncertainty quantification improves robustness.
Visual Insights#

🔼 This figure shows the overall pipeline of the proposed method, DSPoser. It illustrates the process of estimating ego-body pose using egocentric video and head tracking data, even with temporally sparse hand observations. The method involves (a) input egocentric video and head tracking, (b) hand pose prediction, (c) hand pose imputation (filling in missing hand poses) with uncertainty estimation, and (d) using the imputed hand poses and head pose to predict the full 3D body pose.
read the caption
Figure 1: Overview of DSPoser. Our goal is to estimate ego-body pose without dependency on hand controllers in an HMD environment. (a) Given the egocentric video and head tracking signals as input, (b) our approach first predicts the hand pose in the frames where hands are visible (dark blue). It then estimates the hand poses in frames with invisible hands (light blue) using imputation, and (c) estimates uncertainty associated with the hand poses where the hands are invisible, (d) The predicted and imputed hand pose is then used with head pose to predict the 3D full body pose.

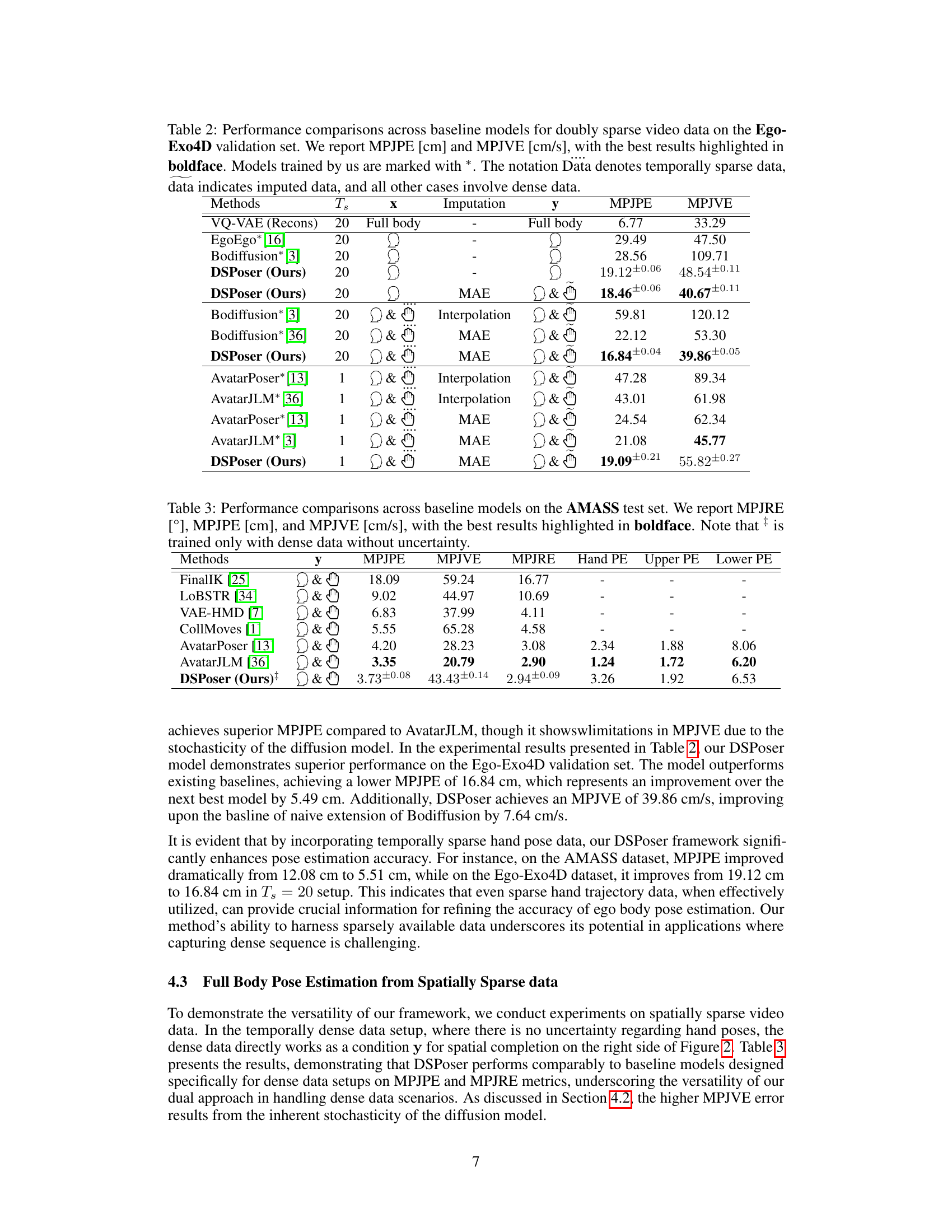
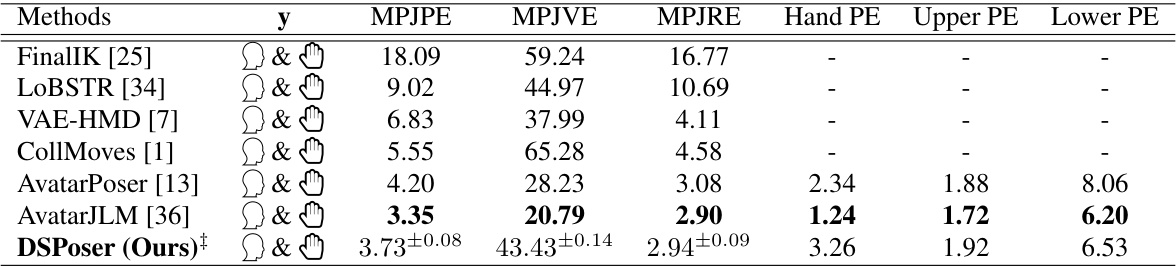
🔼 This table compares the performance of different methods for estimating human body pose from doubly sparse egocentric video data on the AMASS test set. The metrics used are Mean Per Joint Position Error (MPJPE), Mean Per Joint Velocity Error (MPJVE), and Mean Per Joint Rotation Error (MPJRE). The table shows the performance with different types of input data (dense, temporally sparse, imputed) and different imputation methods (interpolation, MAE). The results highlight the effectiveness of the proposed method (DSPoser) compared to baselines.
read the caption
Table 1: Performance comparisons across baseline models for doubly sparse video data on the AMASS test set. We report MPJRE [°], MPJPE [cm], and MPJVE [cm/s], with the best results highlighted in boldface. Models trained by us are marked with *. The notation data denotes temporally sparse data, data indicates imputed data, and all other cases involve dense data. Ts indicates the sliding window, x indicates the input of our whole pipeline, and y indicates the input of denoising Transformer.
In-depth insights#
Sparse Pose Estimation#
Sparse pose estimation tackles the challenge of reconstructing full body pose from limited, spatially sparse input, such as data from a few body markers or intermittently available sensor readings. This contrasts with dense pose estimation which relies on a large number of data points covering the entire body. The core difficulty lies in effectively interpolating and extrapolating the missing information, often leveraging temporal dynamics or learned relationships between observed and unobserved parts. Robustness to noise and missing data is crucial, requiring sophisticated techniques to handle uncertainty and maintain accuracy. Common approaches involve using sophisticated models like diffusion models to generate plausible pose sequences and integrating temporal context through methods like recurrent neural networks or transformers. The success of sparse pose estimation is particularly critical in applications like augmented reality where sensors may have limited coverage or are subject to occlusion. Successful algorithms need to strike a balance between computational efficiency and the accuracy of the reconstructed pose.
Two-Stage Approach#
The paper proposes a two-stage approach to tackle the challenge of ego-body pose estimation from doubly sparse egocentric video data. This approach cleverly addresses the inherent sparsity of the data by dividing the problem into two manageable steps: temporal completion and spatial completion. The first stage focuses on intelligently imputing missing hand poses by leveraging correlations between the intermittent hand poses, head pose sequence and uncertainty estimates from masked autoencoders. This stage effectively addresses the temporal sparsity of the data by generating plausible and temporally consistent hand trajectories. Next, the second stage leverages a conditional diffusion model that incorporates uncertainty estimates from the first stage, to generate full-body poses by combining the completed hand trajectories with head tracking signals. This two-stage method demonstrates significant advantages over single-stage methods by providing a more robust and accurate approach for ego-body pose estimation in scenarios with limited body part visibility, even with temporal sparsity. This decomposition is key to accurately generating full-body poses.
Uncertainty Handling#
The paper’s approach to uncertainty handling is a key strength, demonstrated through a two-stage process. First, a probabilistic masked autoencoder imputes missing hand poses, cleverly providing uncertainty estimates alongside the predictions. This uncertainty quantification isn’t simply a byproduct but is actively incorporated into the second stage. A conditional diffusion model then generates full-body poses, using the uncertainty information to guide the generation process, leading to more robust and reliable results. This two-stage method elegantly addresses the inherent uncertainties in temporally and spatially sparse egocentric data. The combination of imputation and generation makes the overall approach more resilient to noisy or incomplete data. The experiments highlight the importance of uncertainty handling for improved performance. The paper’s meticulous attention to incorporating and managing uncertainty in its methodology is a significant contribution.
HMD Versatility#
The concept of “HMD Versatility” in the context of egocentric body pose estimation highlights the adaptability of the system to diverse hardware configurations and usage scenarios. A truly versatile system wouldn’t be restricted by specific HMD models or the presence of hand controllers, instead leveraging readily available sensor data like head tracking signals. This adaptability is key to broader AR/VR applications beyond those with controlled environments, allowing seamless integration into scenarios like sports training or outdoor experiences. The paper’s proposed method directly addresses this need by decoupling pose estimation from the reliance on hand controllers. Instead, it prioritizes the use of consistently available head tracking data, combined with sparsely sampled hand poses obtained through egocentric video. This dual-sparse approach is robust and generalizable, minimizing reliance on specific hardware and ultimately expanding the scope of potential applications of the technology.
Future Research#
Future research directions stemming from this doubly sparse egocentric body pose estimation work could explore several promising avenues. Improving robustness to noisy or incomplete data is crucial, perhaps through incorporating more sophisticated uncertainty modeling techniques or exploring alternative imputation methods beyond masked autoencoders. Expanding the approach to handle more diverse body morphologies and activities would enhance generalizability, requiring a larger and more varied dataset. Investigating the potential of incorporating additional sensor modalities, such as depth sensors or more sophisticated IMU data, to further refine pose estimation accuracy would be highly valuable. Finally, exploring real-time applications and efficient hardware implementation is essential for practical deployment in augmented reality systems. This would necessitate algorithm optimization and possibly the exploration of specialized hardware architectures.
More visual insights#
More on figures

🔼 This figure illustrates the overall architecture of the proposed method, DSPoser, which consists of two main stages: Temporal Completion and Spatial Completion. The Temporal Completion stage uses a Masked Autoencoder (MAE) to impute missing hand pose data by leveraging correlations between head pose and intermittently visible hand poses. This stage also estimates uncertainty for the imputed hand poses. The Spatial Completion stage employs a conditional diffusion model (VQ-Diffusion) which utilizes the temporally completed hand poses, head tracking data, and uncertainty estimates to generate full-body pose sequences.
read the caption
Figure 2: Overall pipeline of our proposed work DSPoser, composed of Temporal Completion stage and Spatial Completion stage to tackle pose estimation problem from doubly sparse data.
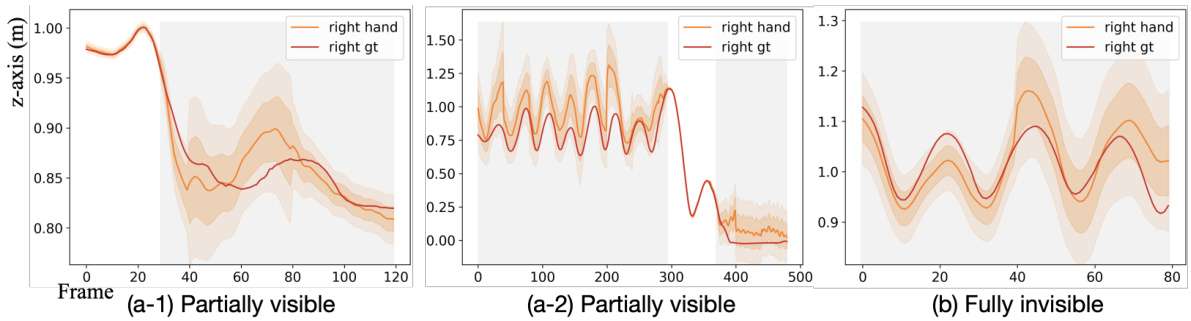
🔼 This figure visualizes the uncertainty in right-hand pose estimation by the masked autoencoder (MAE). Three scenarios are shown: partially visible hands (a-1, a-2) and fully invisible hands (b). Gray shading indicates frames where the hand is not visible. The plots show the estimated hand pose (orange) against the ground truth (red), with shaded areas representing uncertainty intervals of ±10 and ±20 around the estimated mean. The plots show that the uncertainty increases as the hand visibility decreases.
read the caption
Figure 3: Uncertainty visualization of the right hand pose captured by the MAE. Gray areas represent frames where the hand is invisible, and white areas denote visible frames. We depict aleatoric uncertainty within ranges of ±10 and ±20 from the estimated μ.

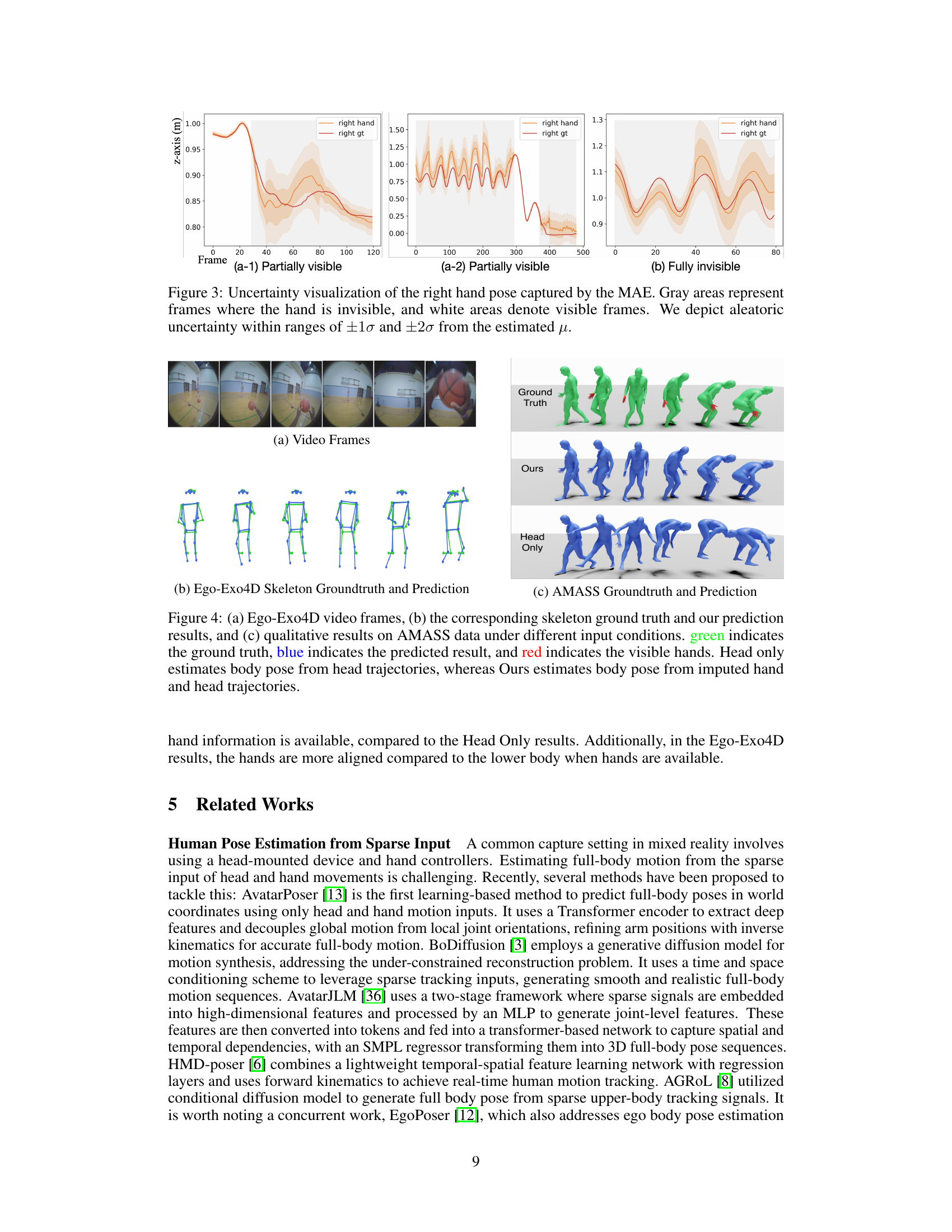
🔼 This figure shows a comparison of the ground truth and predicted human poses using the proposed method on the Ego-Exo4D and AMASS datasets. The Ego-Exo4D section (b) displays the video frames and a comparison of ground truth skeleton pose with the results obtained by the model. The AMASS section (c) provides a similar comparison. The model’s ability to accurately reconstruct the body pose is visually demonstrated and compared against a baseline (‘Head Only’) that relies solely on head trajectory estimation, highlighting the benefits of incorporating imputed hand pose information for more complete body pose prediction.
read the caption
Figure 4: (a) Ego-Exo4D video frames, (b) the corresponding skeleton ground truth and our prediction results, and (c) qualitative results on AMASS data under different input conditions. green indicates the ground truth, blue indicates the predicted result, and red indicates the visible hands. Head only estimates body pose from head trajectories, whereas Ours estimates body pose from imputed hand and head trajectories.
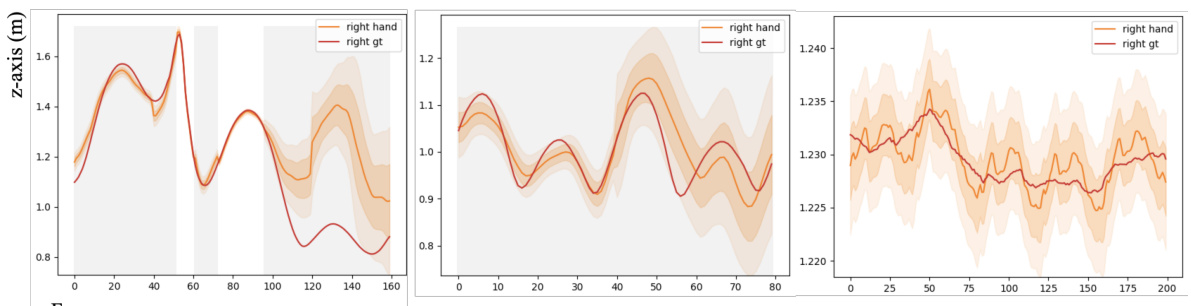
🔼 This figure visualizes the uncertainty in right-hand pose estimation from a masked autoencoder (MAE). The gray shaded areas represent frames where the hand is not visible in the video. The orange lines represent the predicted hand pose from MAE. The red lines show the ground truth pose. The shaded areas around the predictions represent uncertainty calculated by MAE, showing that the uncertainty is larger when the hand is not visible (gray areas) and smaller when it is visible. The visualization demonstrates the MAE’s ability to estimate uncertainty, which is important because it guides the subsequent step of generating full body pose.
read the caption
Figure 3: Uncertainty visualization of the right hand pose captured by the MAE. Gray areas represent frames where the hand is invisible, and white areas denote visible frames. We depict aleatoric uncertainty within ranges of ±10 and ±20 from the estimated μ.
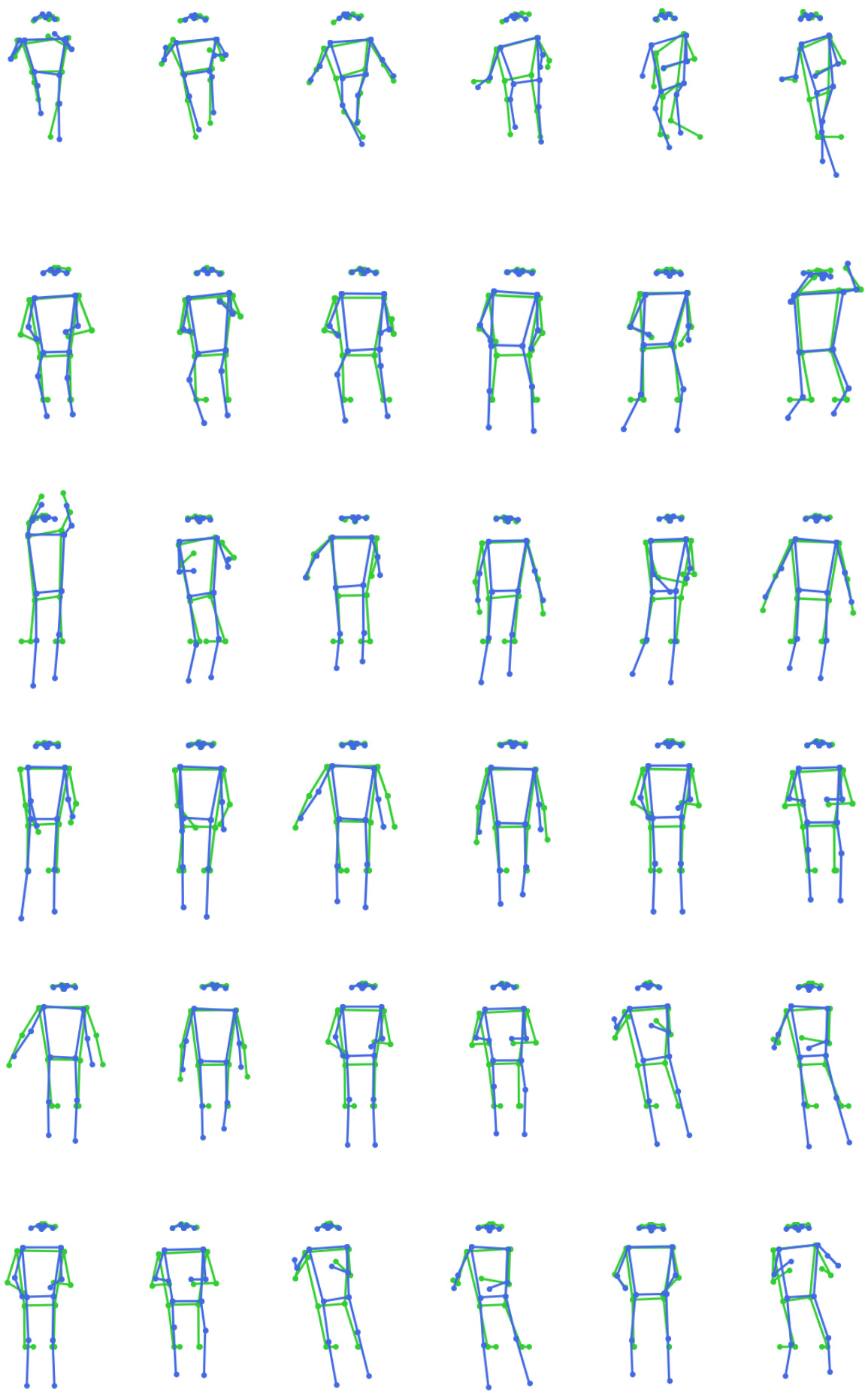
🔼 This figure presents a qualitative comparison of the proposed method’s performance on the Ego-Exo4D dataset. It shows several sequences of human poses, with each sequence consisting of multiple frames. For each frame, the ground truth pose (obtained through manual annotation or other high-fidelity methods) is shown in green, while the pose estimated by the proposed method (DSPoser) is presented in blue. This visual comparison allows for an assessment of the accuracy and fidelity of DSPoser’s estimations across a variety of body movements and viewpoints, providing a clear representation of how well the model captures the nuances of human motion.
read the caption
Figure 6: Qualitative results showing the groundtruth in green and predicted human pose in blue using our method on Ego-Exo4D dataset.
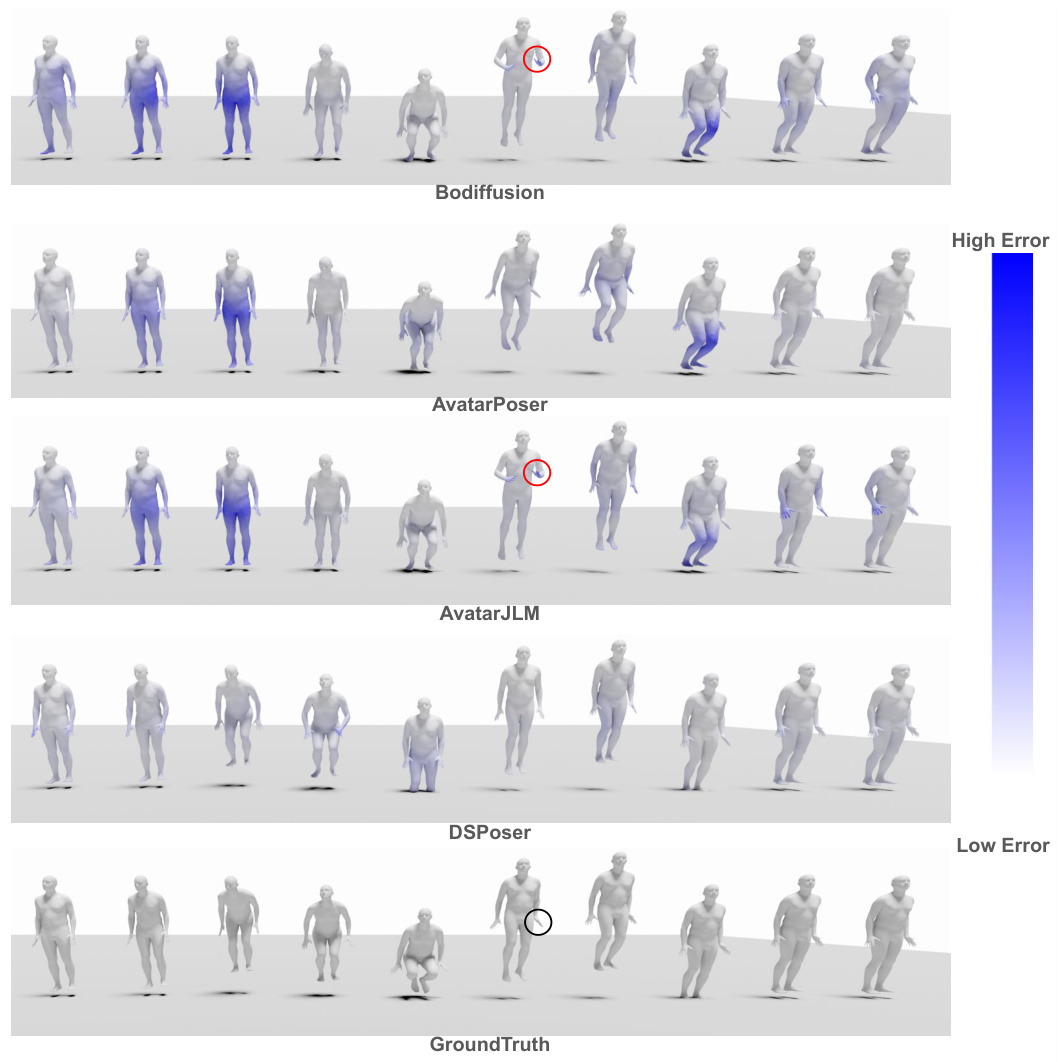
🔼 This figure compares the qualitative results of different methods (Bodiffusion, AvatarPoser, AvatarJLM, and DSPoser) on the AMASS dataset. It shows the estimated 3D human poses as a sequence. The color gradient represents the error, with blue indicating low error and lighter shades of blue/white indicating higher errors. Red circles highlight areas of higher error for comparison methods where the hand is occluded in the ground truth, indicating that the proposed method (DSPoser) is robust even when the hand is invisible for a short period. The ground truth poses are also shown for reference.
read the caption
Figure 7: Qualitative results on AMASS dataset comparing DSPoser (Ours) against the baselines. Color gradient indicates an absolute positional error, with a higher error corresponding to higher blue intensity. Results demonstrate that motions generated by DSPoser exhibit greater similarity to the ground truth. Furthermore, it highlights higher errors (indicated with red circles) for baselines when the hand is occluded in the ground truth pose (indicated with a black circle).

🔼 This figure shows qualitative results comparing the ground truth and predicted human poses using the proposed method (DSPoser) on two datasets: Ego-Exo4D and AMASS. The Ego-Exo4D results (b) illustrate the model’s ability to accurately predict full-body poses from temporally and spatially sparse hand and head data. The AMASS results (c) demonstrate the method’s performance on different input conditions, comparing the use of only head trajectories versus the use of head and imputed hand trajectories.
read the caption
Figure 4: (a) Ego-Exo4D video frames, (b) the corresponding skeleton ground truth and our prediction results, and (c) qualitative results on AMASS data under different input conditions. green indicates the ground truth, blue indicates the predicted result, and red indicates the visible hands. Head only estimates body pose from head trajectories, whereas Ours estimates body pose from imputed hand and head trajectories.
More on tables

🔼 This table presents a comparison of the performance of different methods for estimating human body pose from doubly sparse egocentric video data on the Ego-Exo4D validation dataset. The methods are evaluated using two metrics: Mean Per Joint Position Error (MPJPE) and Mean Per Joint Velocity Error (MPJVE). The table shows results for various methods using different data types (full body, head and hands, imputed hands using interpolation or MAE) and different sliding window sizes. The best results are highlighted in boldface, and models trained by the authors are marked with an asterisk.
read the caption
Table 2: Performance comparisons across baseline models for doubly sparse video data on the Ego-Exo4D validation set. We report MPJPE [cm] and MPJVE [cm/s], with the best results highlighted in boldface. Models trained by us are marked with *. The notation Data denotes temporally sparse data, data indicates imputed data, and all other cases involve dense data.
🔼 This table presents a comparison of the performance of different methods for human pose estimation on the AMASS test dataset. The metrics used are Mean Per Joint Position Error (MPJPE), Mean Per Joint Velocity Error (MPJVE), and Mean Per Joint Rotation Error (MPJRE). The table highlights the best-performing method for each metric and shows that the proposed DSPoser method outperforms the baselines across the board, even when baselines are trained with dense data (no uncertainty).
read the caption
Table 3: Performance comparisons across baseline models on the AMASS test set. We report MPJRE [°], MPJPE [cm], and MPJVE [cm/s], with the best results highlighted in boldface. Note that + is trained only with dense data without uncertainty.
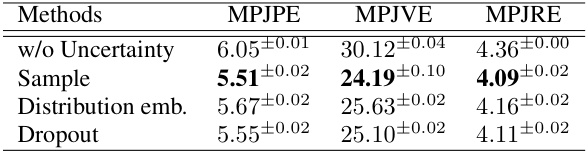
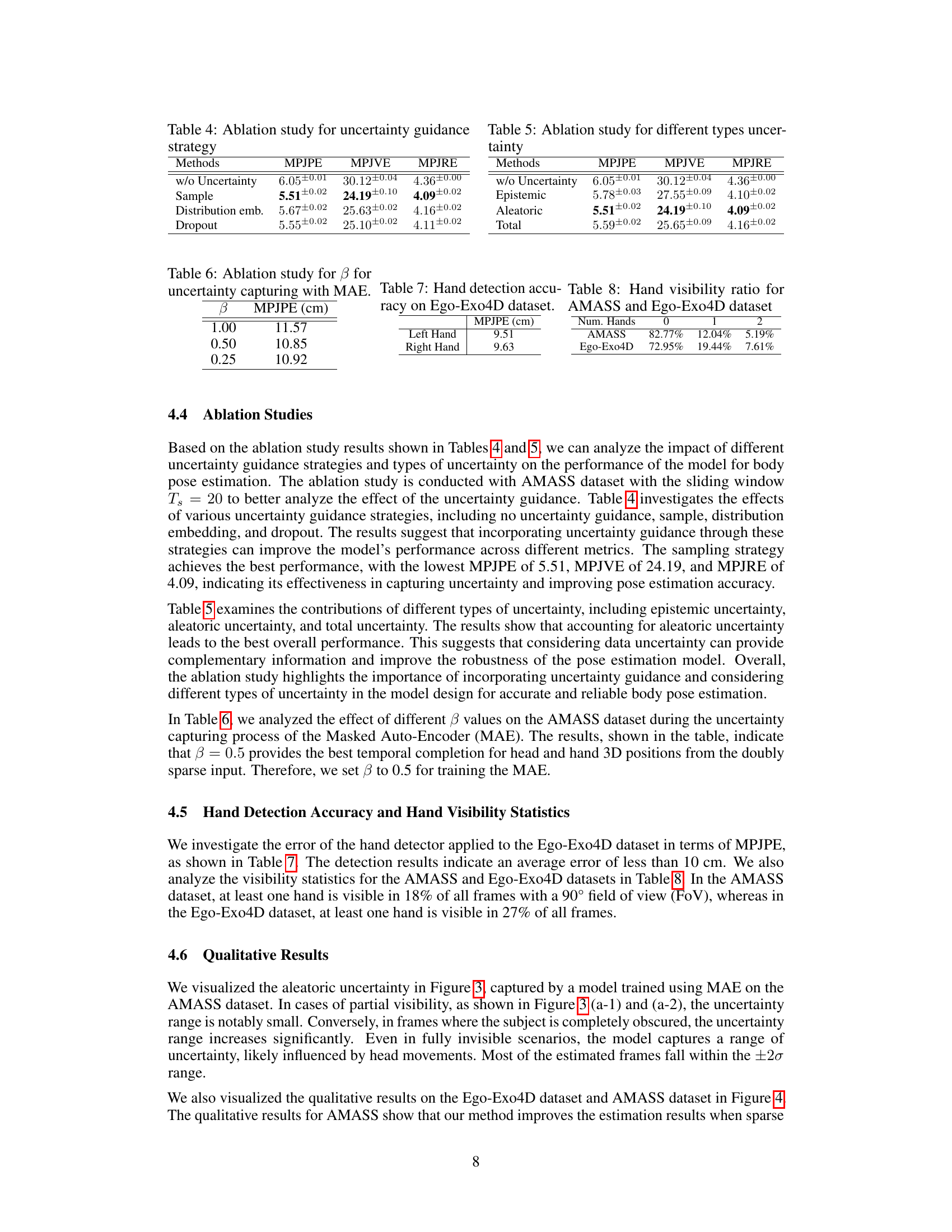
🔼 This table presents the ablation study for different uncertainty guidance strategies, including no uncertainty guidance, sample, distribution embedding, and dropout, on the AMASS dataset with a sliding window of 20. The results show the impact of each strategy on the MPJPE, MPJVE, and MPJRE metrics. The sampling strategy shows the best performance in terms of all three metrics.
read the caption
Table 4: Ablation study for uncertainty guidance strategy
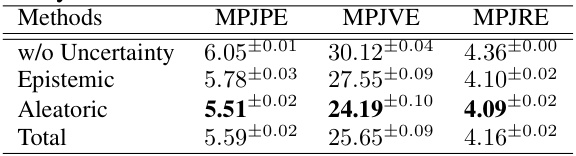
🔼 This table presents the ablation study of different uncertainty guidance strategies on the AMASS dataset using a sliding window of T=20. It compares the model’s performance (MPJPE, MPJVE, MPJRE) when using no uncertainty guidance, sampling, distribution embedding, and dropout. The results show that incorporating uncertainty guidance significantly improves pose estimation accuracy, with the sampling strategy providing the best results.
read the caption
Table 4: Ablation study for uncertainty guidance strategy
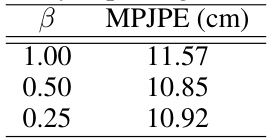
🔼 This table presents the ablation study result for the hyperparameter β used in the uncertainty-aware Masked Autoencoder (MAE). It shows the effect of different β values on the performance of the MAE in terms of Mean Per Joint Position Error (MPJPE) on the AMASS dataset. The results suggest that β = 0.5 provides the best temporal completion for head and hand 3D positions from the doubly sparse input.
read the caption
Table 6: Ablation study for β for uncertainty capturing with MAE.
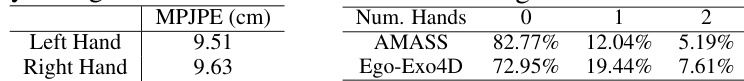
🔼 This table presents the accuracy of hand detection on the Ego-Exo4D dataset. It shows the mean per-joint position error (MPJPE) for left and right hands separately, which are 9.51 cm and 9.63 cm respectively. This indicates the average error in hand pose estimation. The lower the MPJPE, the higher the accuracy of hand pose detection.
read the caption
Table 7: Hand detection accuracy on Ego-Exo4D dataset.

🔼 This table compares the performance of the proposed DSPoser method against several baseline methods for ego-body pose estimation using doubly sparse video data on the AMASS dataset. It shows the Mean Per Joint Position Error (MPJPE), Mean Per Joint Velocity Error (MPJVE), and Mean Per Joint Rotation Error (MPJRE) for different methods, varying the input data (dense or sparse) and imputation techniques (Interpolation or MAE). The best results for each metric are highlighted in bold. The table also indicates which models were trained by the authors and the sliding window size (Ts) used for the temporal context.
read the caption
Table 1: Performance comparisons across baseline models for doubly sparse video data on the AMASS test set. We report MPJRE [°], MPJPE [cm], and MPJVE [cm/s], with the best results highlighted in boldface. Models trained by us are marked with *. The notation data denotes temporally sparse data, data indicates imputed data, and all other cases involve dense data. Ts indicates the sliding window, x indicates the input of our whole pipeline, and y indicates the input of denoising Transformer.
Full paper#