TL;DR#
Transformer-based diffusion models are powerful but computationally expensive, hindering widespread use. This paper addresses this issue. Existing methods struggle with balancing computation and performance, and often face challenges in learning complex relationships between object parts within images. This limits their practical applications.
The proposed Efficient Diffusion Transformer (EDT) framework introduces a lightweight architecture and training-free components inspired by human sketching. EDT incorporates an Attention Modulation Matrix to improve image quality and a novel masking training strategy to augment its relation learning capability. The results demonstrate that EDT achieves significant speed-ups and surpasses existing transformer-based diffusion models in image synthesis, indicating a significant advancement in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and machine learning due to its significant advancements in diffusion models. It offers a novel framework that enhances both the speed and performance of image generation, addressing a key limitation of transformer-based models. The introduction of the Attention Modulation Matrix and relation-enhanced masking strategies provides new avenues for optimizing computational efficiency and improving the quality of generated images, thus opening up several directions for future research in diffusion models and other transformer-based applications. The improved efficiency also makes these models more accessible to researchers with limited computational resources.
Visual Insights#

🔼 This figure illustrates the process of sketching a tree in a landscape. The process starts with a global view of the scene and a rough outline of the tree. Then, the focus shifts to local details, such as the branches and leaves of the tree. After refining the local details, the focus shifts back to the global view, where the tree is evaluated in the context of the whole scene. This process repeats until the sketch is complete. The figure is intended to illustrate how human-like sketching incorporates both local and global attention, which inspired the Attention Modulation Matrix (AMM) in the EDT framework.
read the caption
Figure 1: Illustration of the alternation process of local and global attention during sketching.

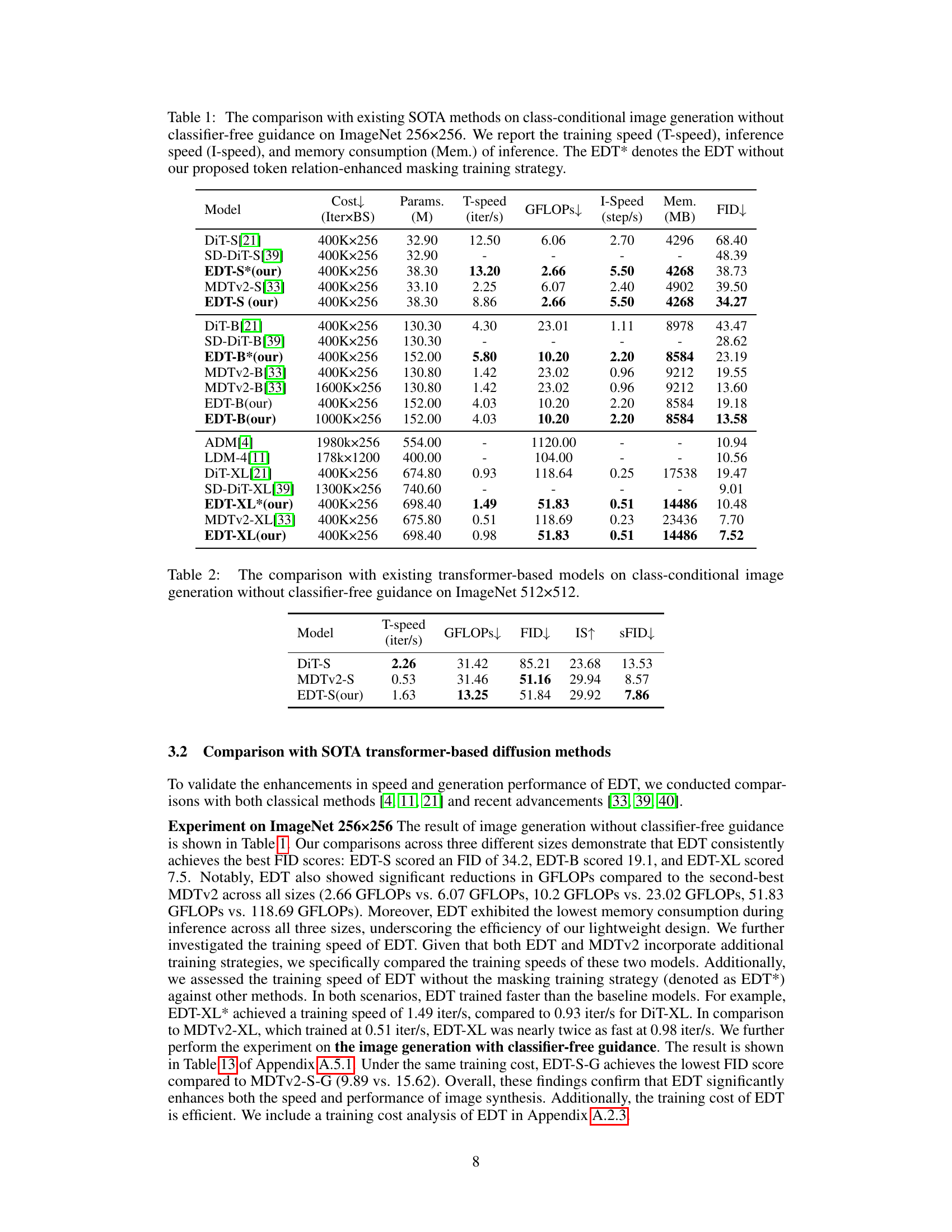
🔼 This table compares the performance of the proposed EDT model with other state-of-the-art (SOTA) methods for class-conditional image generation on the ImageNet dataset (256x256 resolution) without using classifier-free guidance. The metrics shown include training speed, inference speed, memory usage during inference, and the Fréchet Inception Distance (FID), a common metric to assess the quality of generated images. A version of EDT without the proposed masking training strategy is included for comparison.
read the caption
Table 1: The comparison with existing SOTA methods on class-conditional image generation without classifier-free guidance on ImageNet 256x256. We report the training speed (T-speed), inference speed (I-speed), and memory consumption (Mem.) of inference. The EDT* denotes the EDT without our proposed token relation-enhanced masking training strategy.
In-depth insights#
Diffusion Model Boost#
A hypothetical ‘Diffusion Model Boost’ section in a research paper would likely explore advanced techniques to enhance the performance and capabilities of diffusion models. This could involve investigations into novel architectures, such as hybrid models combining diffusion processes with other generative methods, or exploring more efficient training strategies to reduce computational costs and improve scalability. The section might also delve into improved sampling methods to generate higher-quality samples faster and potentially analyze different loss functions optimized for specific tasks or data types. Furthermore, research could focus on developing techniques to address mode collapse, improve sample diversity, or enable finer control over the generation process, perhaps through the use of conditional inputs or guidance mechanisms. Finally, the section might also discuss applications of boosted diffusion models, highlighting their advantages over traditional methods in specific domains.
Lightweight Transformer#
Designing lightweight transformers is crucial for deploying large language models and other computationally intensive AI applications on resource-constrained devices. Efficiency is achieved through various techniques, including reducing the number of parameters, employing more efficient attention mechanisms (like linear attention), using quantization and pruning methods, and exploring novel architectures. The trade-off between model size and performance is a key consideration. A smaller model might be faster but less accurate, necessitating careful balancing depending on the specific application requirements. Research efforts focus on maintaining accuracy while drastically reducing the model’s footprint, leading to optimized models for mobile devices, embedded systems, and edge computing. Furthermore, techniques to improve training efficiency of lightweight models are also crucial; this reduces the overall development time and cost. Ultimately, the goal is to enable powerful AI capabilities on a wider range of hardware platforms, expanding access and utility.
Sketch-Inspired AMM#
The heading ‘Sketch-Inspired AMM’ suggests a novel approach to attention mechanisms in deep learning models, drawing inspiration from the human sketching process. The core idea likely involves mimicking the human’s iterative refinement strategy, starting with a coarse overview and progressively focusing on finer details. This is achieved using an Attention Modulation Matrix (AMM), a component that dynamically adjusts attention weights based on the current stage of processing and the overall context. The AMM’s sketch-inspired design is crucial, as it suggests a more efficient and effective way to handle attention compared to traditional methods. Instead of attending to all elements uniformly, it prioritizes specific regions or features, thus reducing computational costs and improving accuracy. This approach likely provides a more human-like understanding of images, focusing on essential features before delving into the details. The AMM’s alternation of local and global attention could also lead to enhanced model performance in tasks requiring both fine-grained detail and holistic understanding. The effectiveness of this method would likely be demonstrated by improved performance in image generation or other visual tasks compared to existing attention mechanisms.
Masking Training Plus#
The concept of “Masking Training Plus” suggests an enhancement to standard masking training techniques used in diffusion models. It likely involves a more sophisticated masking strategy than simple random masking, perhaps incorporating elements of structured masking, adaptive masking, or masking guided by learned features. This could lead to improvements in several areas, such as enhanced generation of details, better object relationships, and reduced training time. A key consideration is how the “Plus” element differs from previous methods. It could mean the addition of a novel loss function, incorporating attention mechanisms during the masking process, or a different approach to training sample selection. Ultimately, a successful “Masking Training Plus” method would likely achieve superior image generation quality and efficiency compared to existing techniques by addressing the limitations of random masking, a common problem in diffusion models which often leads to artifact generation and instability.
EDT Limitations#
The heading ‘EDT Limitations’ prompts a thoughtful exploration of the Efficient Diffusion Transformer’s shortcomings. While EDT boasts significant improvements in speed and image quality, limitations inherent in its design and training methodology require attention. The reliance on a lightweight architecture, while boosting efficiency, may compromise the detailed fidelity of generated images in some instances. Furthermore, the plug-in nature of the Attention Modulation Matrix (AMM), though effective, lacks a universal applicability; optimal placement and parameter tuning require careful experimentation for each model, impacting usability. The masking training strategy, while enhancing token relations, might still suffer from potential information loss during down-sampling. Therefore, future work should focus on addressing these limitations to further refine EDT’s performance and robustness across diverse scenarios and model sizes.
More visual insights#
More on figures
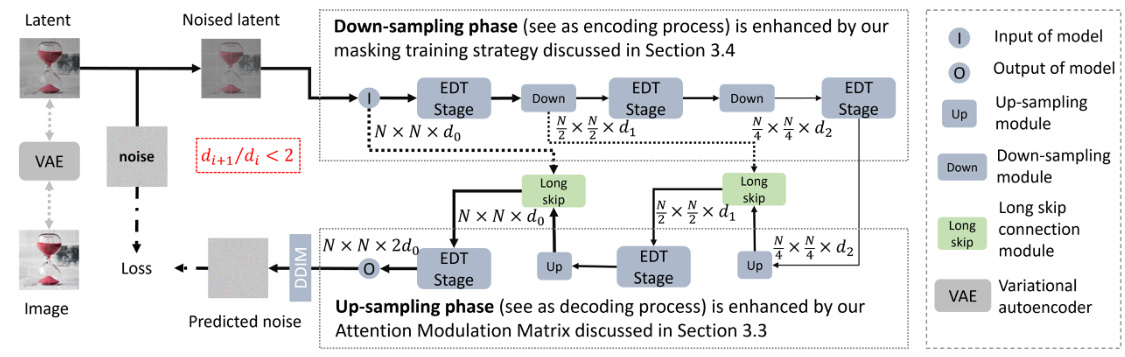
🔼 This figure illustrates the architecture of the lightweight-design diffusion transformer. It shows the process of the model, starting with a latent image which is then noised. The model then uses a series of EDT (Efficient Diffusion Transformer) stages, alternating between downsampling and upsampling. Downsampling is described as an encoding process, while upsampling is a decoding process. The downsampling phases use masking training, and the upsampling phase leverages an Attention Modulation Matrix. Long skip connections are employed between the stages. Finally, the model output is a denoised latent that is then decoded back into an image using a VAE (Variational Autoencoder).
read the caption
Figure 2: The architecture of lightweight-design diffusion transformer.

🔼 This figure shows the detailed architecture of the down-sampling, long skip connection, and up-sampling modules in EDT. The down-sampling module reduces the number of tokens while enhancing key features using AdaLN and positional encoding. The long skip connection module concatenates information from earlier stages. The up-sampling module increases the number of tokens and incorporates positional encoding. These modules are designed to balance computational efficiency and information preservation in the EDT framework.
read the caption
Figure 3: The design of down-sampling, long skip connection and up-sampling modules.
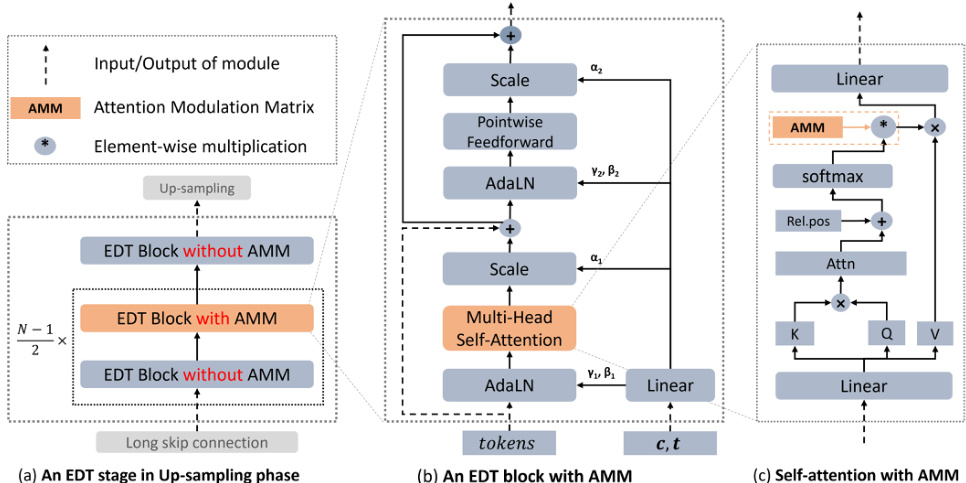
🔼 This figure shows how the Attention Modulation Matrix (AMM) is integrated into an EDT stage during the up-sampling phase. It illustrates the alternation between global and local attention, mimicking the human-like sketching process. Specifically, it depicts an EDT stage with AMM integrated into the self-attention module of some EDT blocks, while others remain without AMM. This alternation allows for a coarse-to-fine refinement of image details, starting with a general framework from global attention and then refining local details with local attention provided by the AMM.
read the caption
Figure 4: The position of Attention Modulation Matrix (local attention) in an EDT stage in the up-sampling phase.

🔼 This figure compares two masking training strategies: MDT and EDT. MDT masks tokens randomly at the beginning of the training process, which may lead to loss of token information and an unbalanced focus on reconstructing masked regions. The EDT strategy, however, feeds full tokens into the shallow EDT blocks before introducing the masking operation in the down-sampling modules. This approach allows the model to learn relationships between tokens before masking, thereby enhancing the training process and reducing information loss. The masking operation itself is postponed to the down-sampling phase, making the training process more balanced.
read the caption
Figure 5: Token relation-enhanced masking training strategy. MDT is fed the remained tokens after token masking into models. EDT is fed full tokens into shallow EDT blocks, and the operation of token masking is performed in down-sampling modules.

🔼 This figure shows a comparison of images generated by EDT-XL with and without the Attention Modulation Matrix (AMM). The images on the left are generated without AMM, while those on the right are generated with AMM. The red boxes highlight areas where the images generated without AMM show unrealistic or unnatural visual details. The images generated with AMM show improved realism in those areas, highlighting the effectiveness of AMM in improving image quality without negatively impacting overall realism.
read the caption
Figure 6: EDT-XL with AMM achieves more realistic visual effects. Area A: There are some blue stains on the panda's arm. Area B: An unreasonable gray area. Area C: Black smoke in the red fog. Area D: Unrealistic eyes of the fox. Area E: Fish with an odd shape. The parrot image generated by EDT-XL without AMM is realistic. And the parrot image generated by EDT-XL with AMM remains equally realistic. The add of AMM does not negatively affect the original quality.

🔼 This figure illustrates the architecture of the lightweight diffusion transformer used in the Efficient Diffusion Transformer (EDT) framework. The model employs a down-sampling phase (encoding) with three EDT stages, progressively compressing tokens. This is followed by an up-sampling phase (decoding) with two EDT stages, gradually reconstructing tokens. These five stages are interconnected via down-sampling, up-sampling, and long skip connection modules. Each EDT stage consists of multiple consecutive transformer blocks. The figure visually explains the process and flow of information within the EDT model architecture, highlighting the key components and their roles in achieving efficient image synthesis.
read the caption
Figure 2: The architecture of lightweight-design diffusion transformer.

🔼 The figure illustrates the step-by-step process of how the Attention Modulation Matrix (AMM) modulates the attention score matrix. It begins with the calculation of Euclidean distances between all pairs of tokens, resulting in a token distance matrix. A modulation matrix is then generated based on these distances, and this matrix is expanded to match the dimensions of the attention score matrix. Finally, a Hadamard product is performed between the expanded modulation matrix and the attention score matrix, resulting in a modulated attention score matrix. The figure clearly shows the shapes and dimensions of the tensors at each stage of the process.
read the caption
Figure 8: The process of modulating the attention score matrix and the changes in tensor shape.
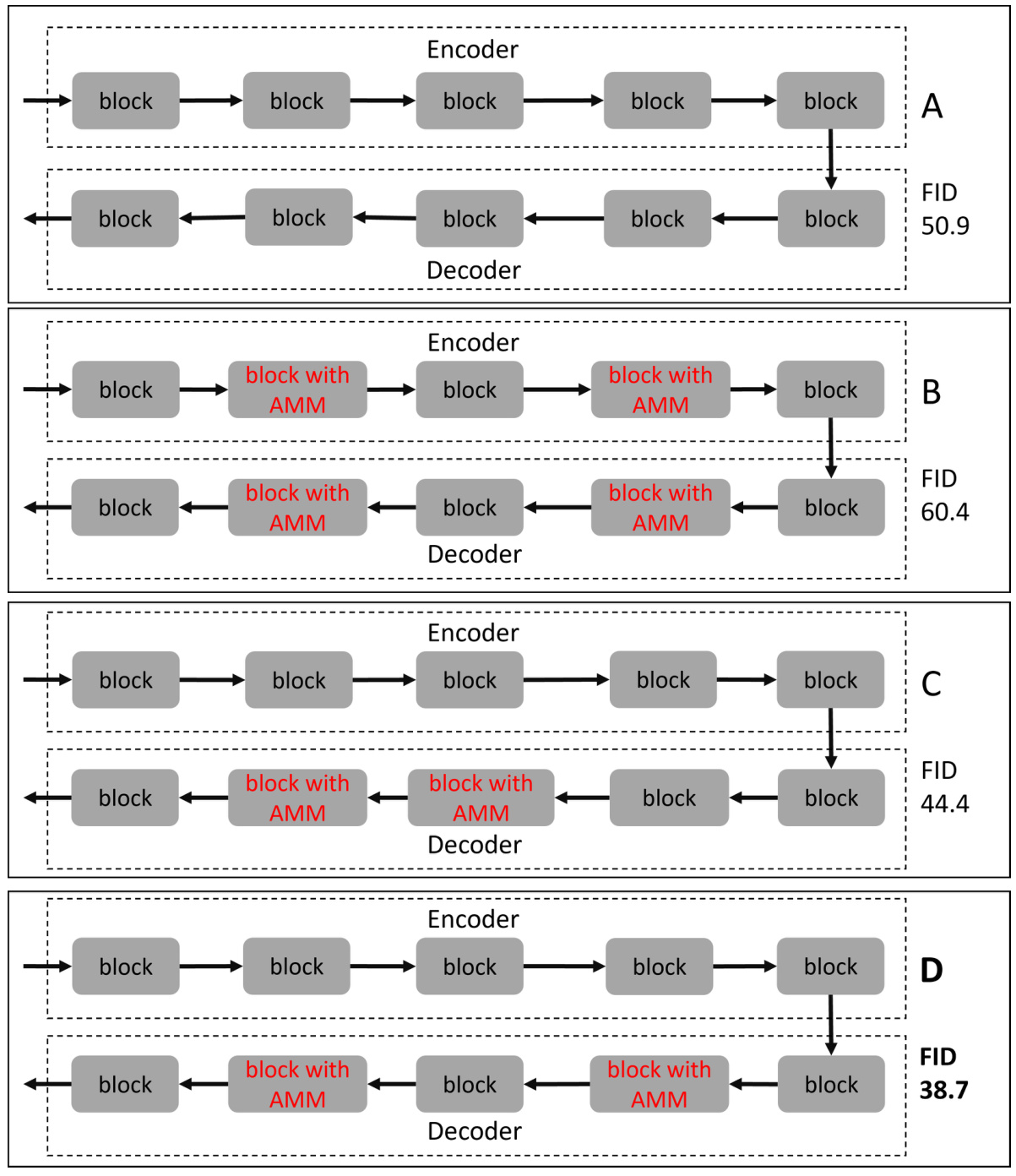
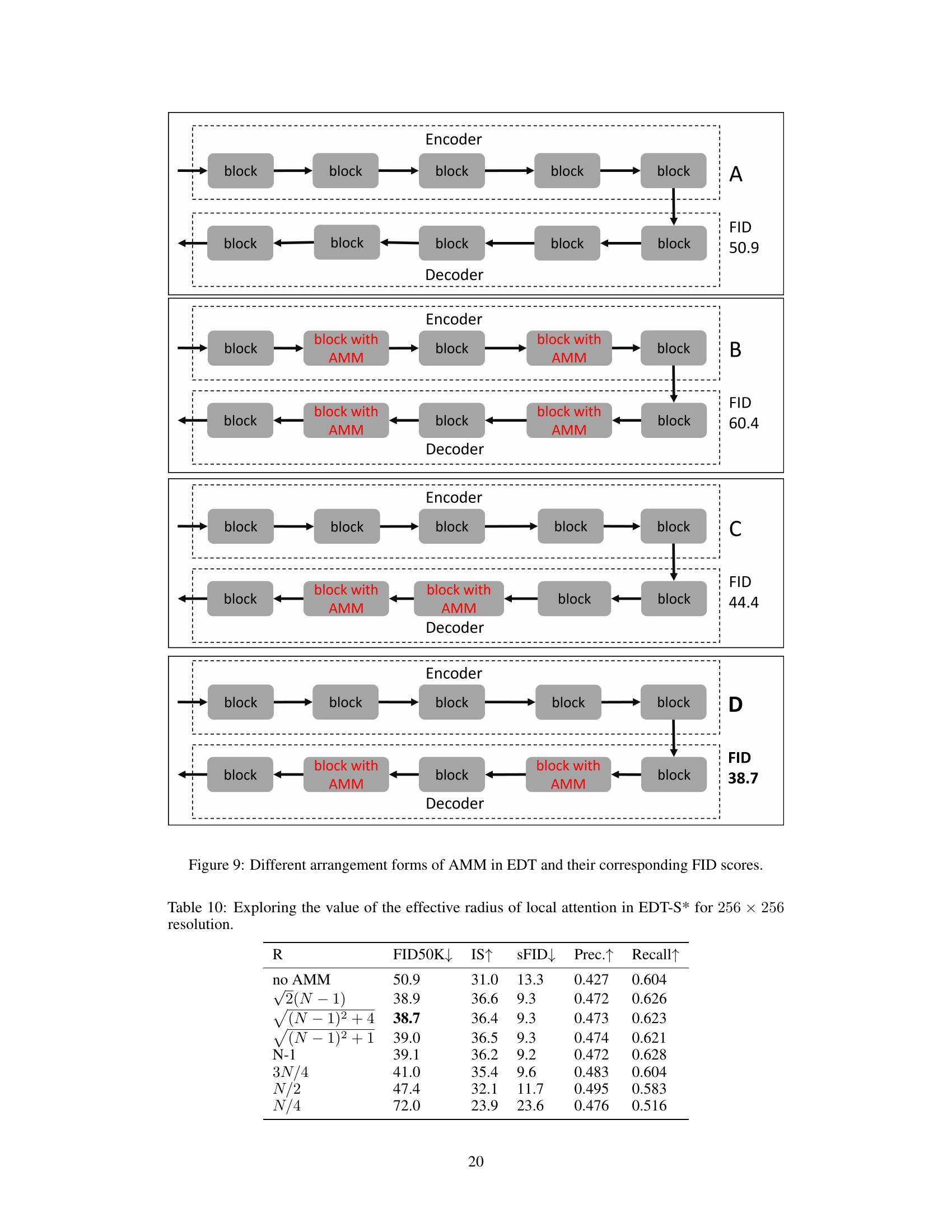
🔼 This figure shows four different ways of integrating the Attention Modulation Matrix (AMM) into the Efficient Diffusion Transformer (EDT) architecture and their resulting FID (Frechet Inception Distance) scores. The variations involve placing AMM in different positions within the encoder and decoder blocks of the EDT. The FID scores, a measure of image generation quality, demonstrate that the arrangement of AMM significantly impacts performance.
read the caption
Figure 9: Different arrangement forms of AMM in EDT and their corresponding FID scores.

🔼 This figure compares the loss curves for the masking training strategies of MDT and EDT. The top two subfigures show the loss changes for MDT across two different training stages (300k-305k and 300k-400k iterations). It highlights a conflict between the masked input loss (red line) and full input loss (green line) for MDT. When one loss decreases, the other increases, indicating conflicting training objectives. The bottom two subfigures show the corresponding loss changes for EDT. The loss curves are more synchronized, with both loss values decreasing during the training stages, demonstrating a more consistent and harmonious training process compared to MDT.
read the caption
Figure 10: Comparing the loss changes of different masking training strategies.

🔼 This figure compares image generation results of EDT-XL model with and without Attention Modulation Matrix (AMM). It highlights how AMM improves the realism of generated images by addressing artifacts like unnatural colors, shapes, or missing details, while maintaining the overall quality of realistic images. The red boxes pinpoint specific areas where AMM made improvements.
read the caption
Figure 6: EDT-XL with AMM achieves more realistic visual effects. Area A: There are some blue stains on the panda's arm. Area B: An unreasonable gray area. Area C: Black smoke in the red fog. Area D: Unrealistic eyes of the fox. Area E: Fish with an odd shape. The parrot image generated by EDT-XL without AMM is realistic. And the parrot image generated by EDT-XL with AMM remains equally realistic. The add of AMM does not negatively affect the original quality.

🔼 This figure shows the architecture of the lightweight diffusion transformer. The model includes three EDT stages in the down-sampling phase, viewed as an encoding process where tokens are progressively compressed, and two EDT stages in the up-sampling phase, viewed as a decoding process where tokens are gradually reconstructed. These five EDT stages are interconnected through down-sampling, up-sampling, and long skip connection modules.
read the caption
Figure 2: The architecture of lightweight-design diffusion transformer.
More on tables

🔼 This table compares the performance of EDT-S, DiT-S, and MDTv2-S models on ImageNet 512x512 dataset. The metrics used for comparison include training speed (iterations per second), GFLOPs (a measure of computational cost), FID (Frechet Inception Distance, a measure of image quality), Inception Score (IS, another measure of image quality), and sFID (a variant of FID). Lower FID and sFID scores, and higher IS scores indicate better performance. The results show that EDT-S achieves a better balance between speed and quality, compared to the other models.
read the caption
Table 2: The comparison with existing transformer-based models on class-conditional image generation without classifier-free guidance on ImageNet 512x512.
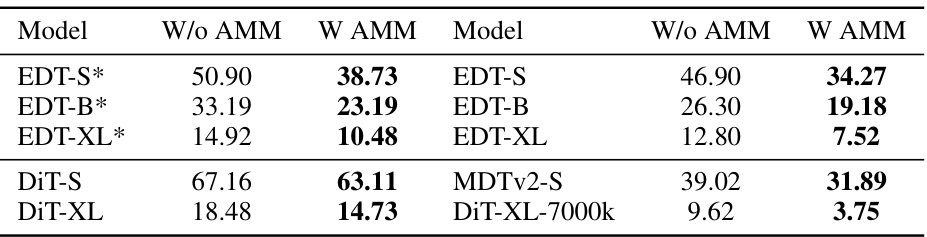
🔼 This table presents the FID scores for various models, comparing their performance with and without the Attention Modulation Matrix (AMM). The models were all trained for 400,000 iterations. Lower FID scores indicate better image generation quality.
read the caption
Table 3: Results on various models with (w) AMM and without (w/o) AMM. These models are trained for 400k iterations by default. We evaluate models using FID scores.

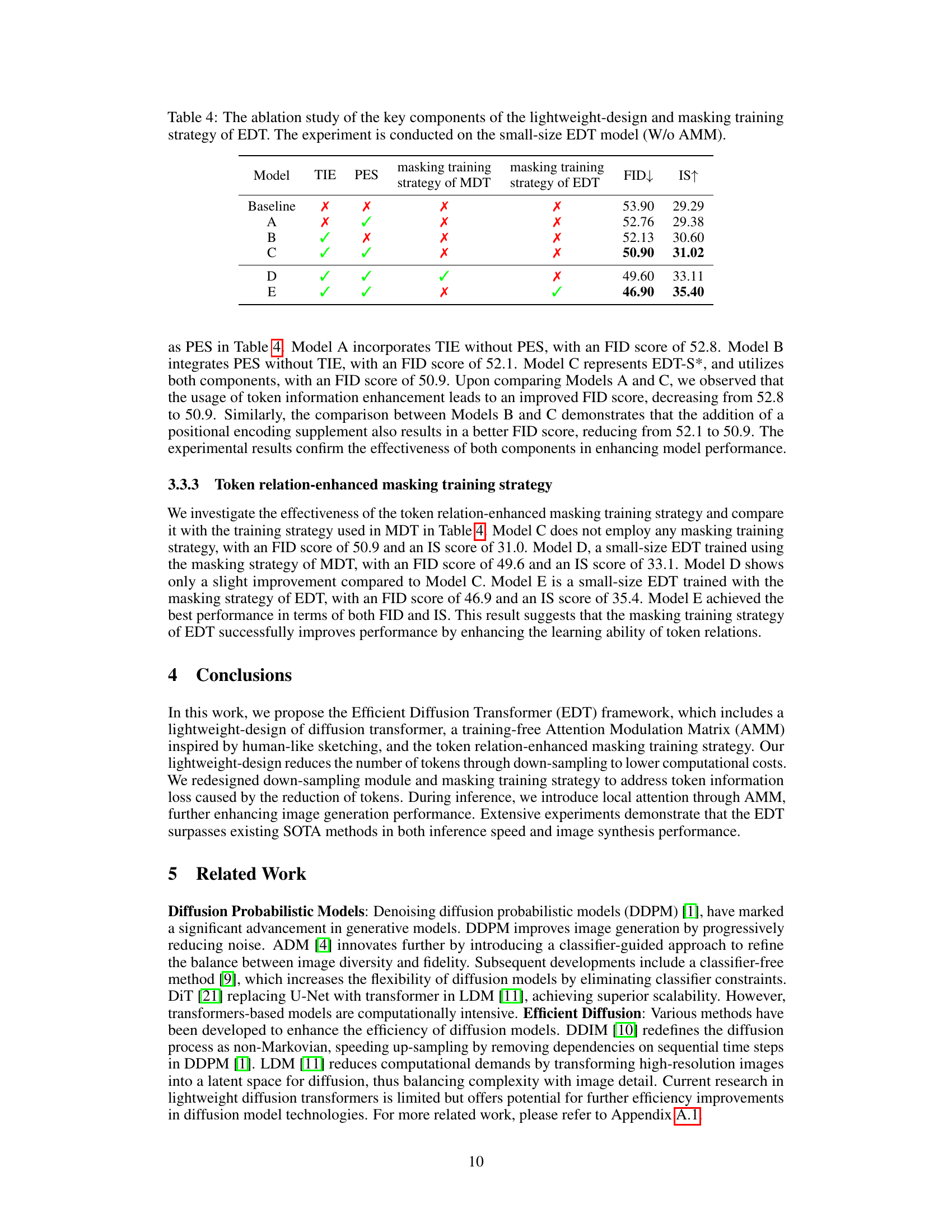
🔼 This table presents the ablation study results focusing on the key components of the lightweight-design and masking training strategy within the Efficient Diffusion Transformer (EDT) framework. The study uses a small-size EDT model without the Attention Modulation Matrix (AMM). It assesses the impact of token information enhancement (TIE), positional encoding supplement (PES), and two different masking training strategies (MDT and EDT) on the model’s performance, measured by FID and IS scores. Each row represents a different model configuration, indicating the presence or absence of these components with checkmarks (✓) and crosses (✗). The results showcase how these components individually and collectively affect the model’s image generation quality.
read the caption
Table 4: The ablation study of the key components of the lightweight-design and masking training strategy of EDT. The experiment is conducted on the small-size EDT model (W/o AMM).

🔼 This table presents the architecture details for three different sizes of the Efficient Diffusion Transformer (EDT) model: small (EDT-S), base (EDT-B), and extra-large (EDT-XL). For each model size, the table shows the total number of parameters (Params.), the total number of blocks, the number of blocks in each of the five stages (Down-sampling phase has three stages, Up-sampling phase has two stages), the dimensions of the feature maps at each stage, and the number of attention heads used at each stage. This information provides a detailed comparison of the model’s complexity and capacity across different sizes.
read the caption
Table 5: The model details of EDT across three different sizes.

🔼 This table details the computational cost (FLOPs) and the number of parameters for each operation within a DiT (Diffusion Transformer) block. It breaks down the calculations for AdaLN (Adaptive Layer Normalization), Attention (including key, query, value, and attention operations), and FFN (Feed-Forward Network) layers. The table provides a granular view of the computational complexity at each stage of the DiT block architecture.
read the caption
Table 6: FLOPs in a DiT block
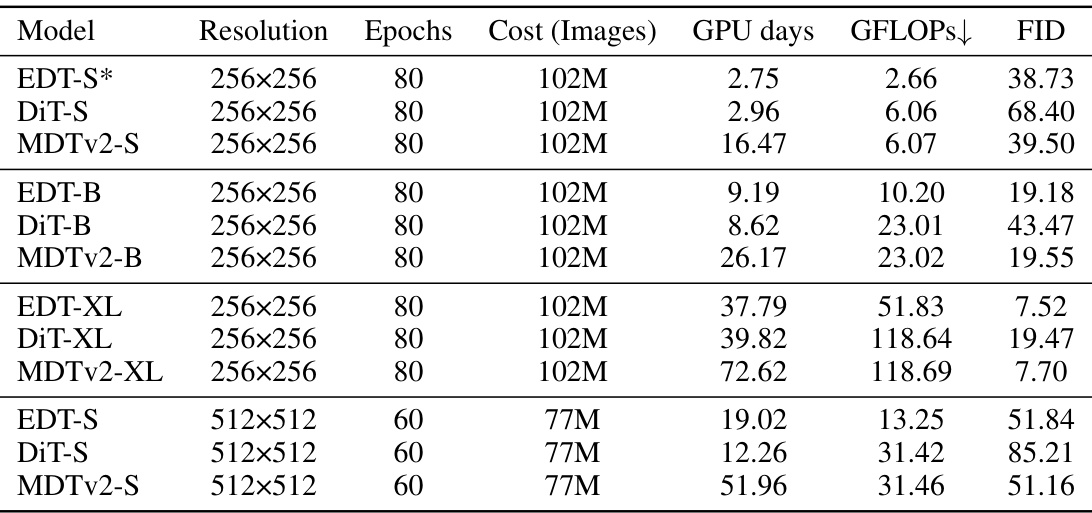
🔼 This table compares the training costs of three different models (EDT, MDTv2, and DiT) on the ImageNet dataset. The comparison is done for three different sizes of each model (small, base, and extra-large) and two resolutions (256x256 and 512x512). The metrics presented are the number of epochs, the total cost (measured in number of images), the GPU days used for training, the number of GFLOPs, and the final FID (Frechet Inception Distance) score. The table showcases EDT’s efficiency by showing significantly lower training costs and faster training times (fewer GPU days) compared to DiT and MDTv2 while achieving comparable or better FID scores.
read the caption
Table 7: Training cost of EDT, MDTv2, and DiT on ImageNet

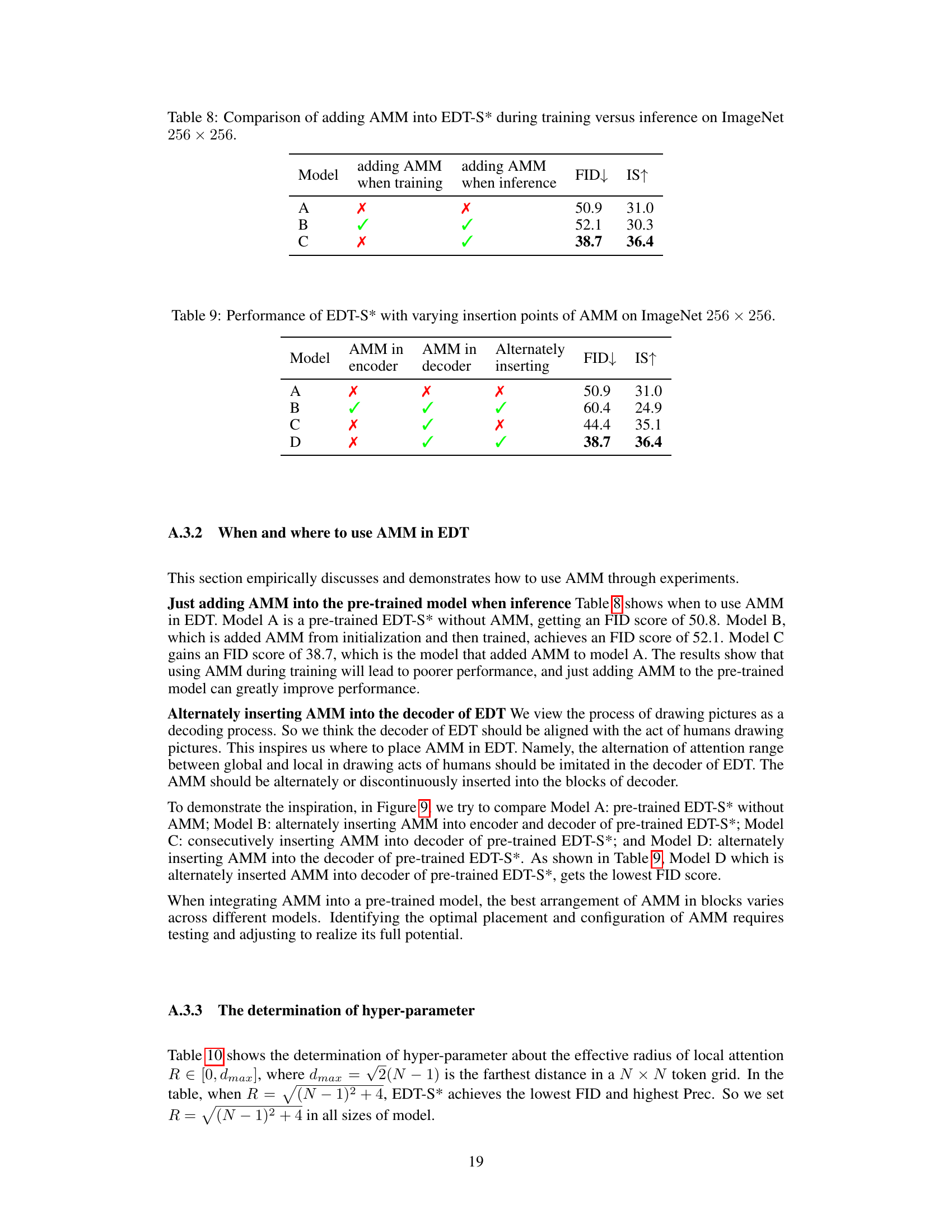
🔼 This table compares the FID and IS scores of EDT-S* model with three different training and inference settings: - Model A: No AMM is used in training or inference. - Model B: AMM is used in both training and inference. - Model C: AMM is only used during inference. The results show that adding AMM only during inference significantly improves the performance of EDT-S* model.
read the caption
Table 8: Comparison of adding AMM into EDT-S* during training versus inference on ImageNet 256 × 256.

🔼 This table presents the results of an ablation study on the EDT-S* model, investigating the impact of different placement strategies for the Attention Modulation Matrix (AMM) on image generation performance. It compares FID and IS scores across four model variations (A, B, C, D), each differing in where AMM is integrated (encoder, decoder, or alternately in both) during the up-sampling process. This experiment explores how the alternation of global and local attention influences the quality of generated images.
read the caption
Table 9: Performance of EDT-S* with varying insertion points of AMM on ImageNet 256 × 256.
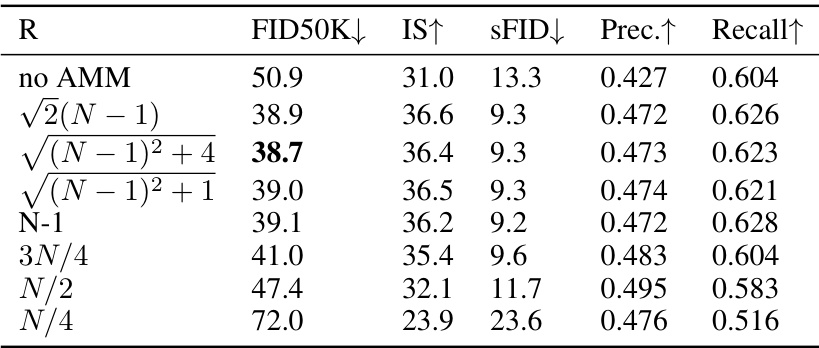
🔼 This table presents the results of an experiment to determine the optimal value for the hyperparameter ’effective radius of local attention (R)’ in the Attention Modulation Matrix (AMM) of the EDT-S* model. Different values of R were tested, and the table shows the resulting FID50K, IS, sFID, Precision, and Recall scores. The results indicate that a value of R = √(N-1)²+4 provides the best balance among these metrics.
read the caption
Table 10: Exploring the value of the effective radius of local attention in EDT-S* for 256 × 256 resolution.
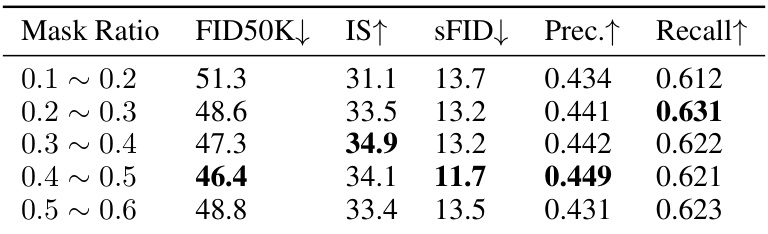
🔼 This table presents the results of experiments conducted to determine the optimal mask ratio for the first down-sampling module in the EDT model. Different mask ratios (0.1-0.2, 0.2-0.3, 0.3-0.4, 0.4-0.5, and 0.5-0.6) were tested and evaluated based on FID50k, Inception Score (IS), sFID, Precision, and Recall. The results suggest that a mask ratio of 0.3-0.4 yields the best performance, with the lowest FID50k and sFID scores and high IS, Precision, and Recall.
read the caption
Table 11: Mask Ratio in the first down-sampling module.

🔼 This table shows the results of experiments to determine the optimal mask ratio for the second down-sampling module in the EDT model. The experiments were conducted using different mask ratios (0.1
0.2, 0.20.3, 0.30.4, 0.40.5), and the results are evaluated based on FID50K, IS, sFID, Precision, and Recall. The mask ratio of the first down-sampling module was fixed at 0.4 ~ 0.5 based on previous experiments.read the caption
Table 12: Mask Ratio in the second down-sampling module. (Based on the 0.4 ~ 0.5 mask ratio in the first down-sampling module)
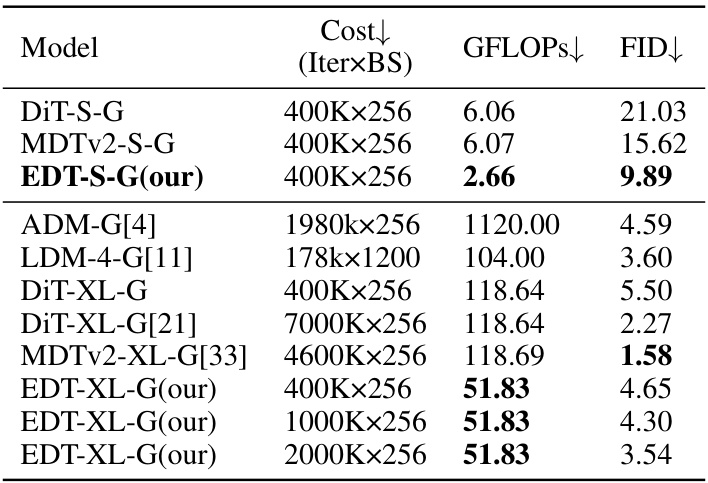
🔼 This table compares the performance of EDT against other state-of-the-art (SOTA) methods for class-conditional image generation using classifier-free guidance. It shows that EDT achieves a good balance between training cost, inference speed (GFLOPs), and image generation performance (FID). The comparison includes various model sizes and training iteration counts. The classifier-free guidance setting is noted for each model.
read the caption
Table 13: The comparison with existing SOTA methods on class-conditional image generation with classifier-free guidance on ImageNet 256x256 (CFG=2 in EDT; according to DiT and MDTv2, their optimal CFG settings are 1.5 and 3.8, respectively).
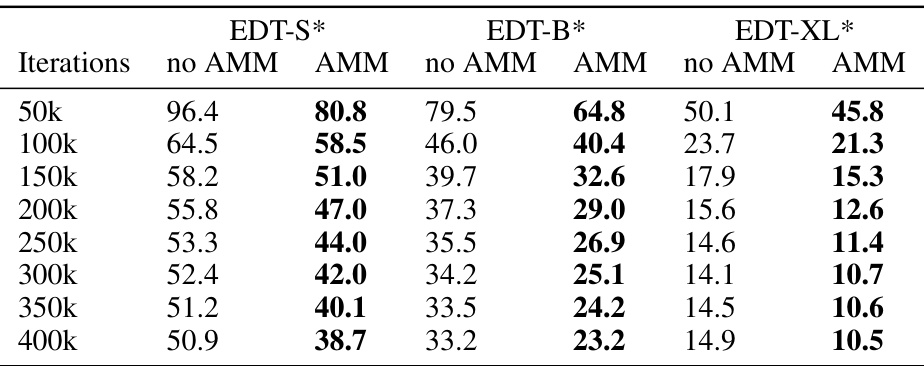
🔼 This table shows the FID (Frechet Inception Distance) scores for three different sizes of the EDT model (EDT-S*, EDT-B*, EDT-XL*) with and without the Attention Modulation Matrix (AMM) at different training iterations (50k, 100k, …, 400k). It demonstrates how the FID score improves with the addition of AMM as the training progresses for all three model sizes.
read the caption
Table 14: FID of EDTs* under different iterations on Imagenet 256 × 256.

🔼 This table compares the performance of the proposed EDT model with several state-of-the-art (SOTA) models on ImageNet 256x256 dataset for class-conditional image generation without classifier-free guidance. Key metrics include FID (lower is better), training speed, inference speed, and memory usage. The table highlights EDT’s superior performance and efficiency compared to existing methods, particularly showing significant speed improvements in both training and inference.
read the caption
Table 1: The comparison with existing SOTA methods on class-conditional image generation without classifier-free guidance on ImageNet 256x256. We report the training speed (T-speed), inference speed (I-speed), and memory consumption (Mem.) of inference. The EDT* denotes the EDT without our proposed token relation-enhanced masking training strategy.
Full paper#