TL;DR#
Training Concept Activation Vectors (CAVs) usually needs many high-quality images, limiting their use. Existing methods struggle with this data scarcity problem, hindering their ability to provide insightful interpretations of model predictions. This makes it difficult to analyze and improve complex models effectively.
The proposed Language-Guided CAV (LG-CAV) method uses vision-language models to overcome this challenge. LG-CAV trains CAVs guided by concept descriptions, eliminating the need for extensive labeled data. It incorporates additional modules for improved accuracy. Furthermore, LG-CAV enables a novel model correction technique, boosting performance. Experiments show significant improvement over existing methods, offering a superior approach to understanding and improving models.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly advances the interpretability of black-box models. It introduces a novel method, LG-CAV, to train concept activation vectors (CAVs) without requiring large labeled datasets. This addresses a major limitation of existing CAV methods, opening doors for broader application in explainable AI and related fields. The proposed model correction technique further enhances the practical value of LG-CAV, offering a potential paradigm shift in how we understand and improve model performance.
Visual Insights#

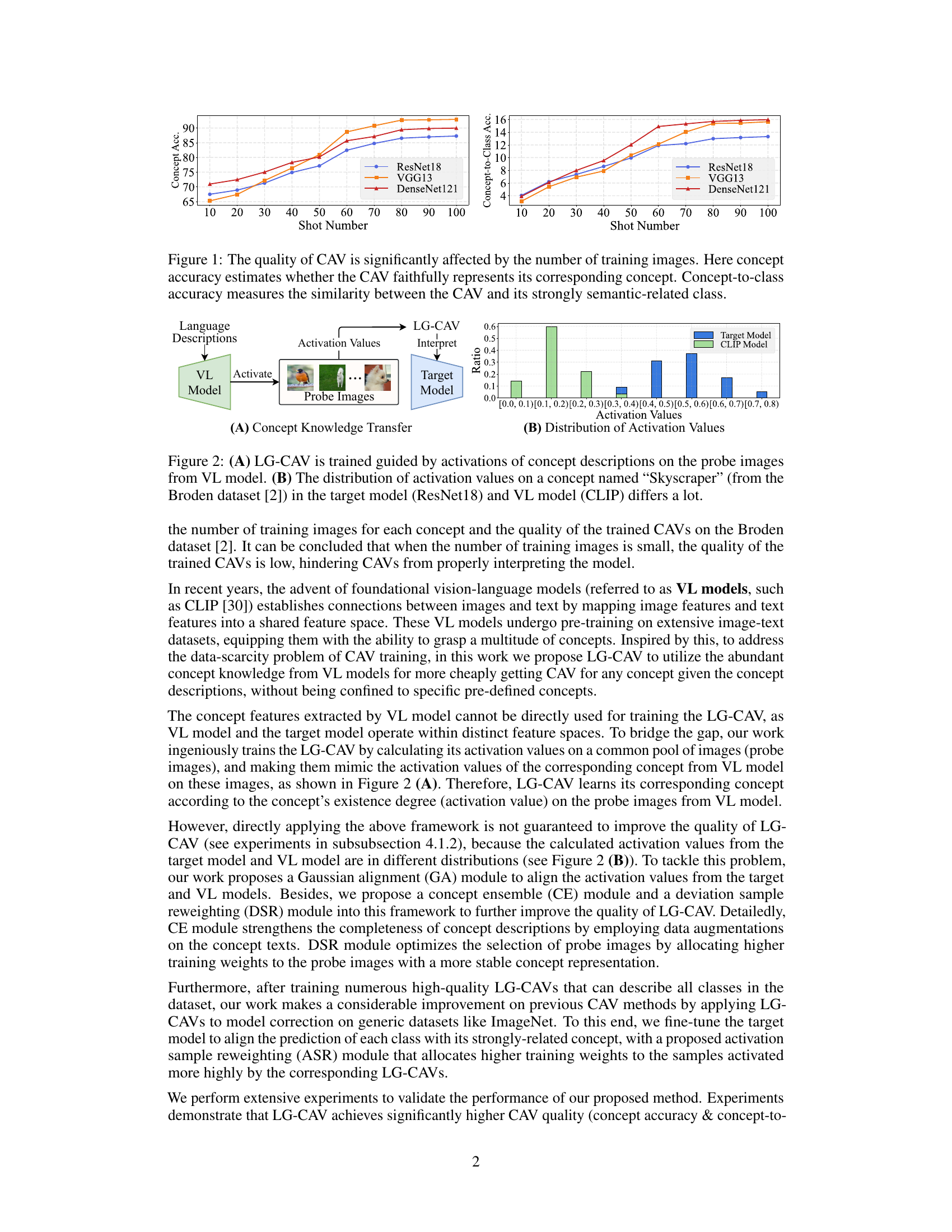
🔼 This figure shows that the quality of Concept Activation Vectors (CAVs) is highly dependent on the number of training images used. Two metrics are plotted against shot number (number of training images): concept accuracy (how well the CAV represents the concept) and concept-to-class accuracy (how similar the CAV is to its semantically related class). The plots reveal a strong positive correlation between the number of training images and the accuracy of the CAVs, highlighting the challenge of training high-quality CAVs for many concepts when training data is scarce.
read the caption
Figure 1: The quality of CAV is significantly affected by the number of training images. Here concept accuracy estimates whether the CAV faithfully represents its corresponding concept. Concept-to-class accuracy measures the similarity between the CAV and its strongly semantic-related class.
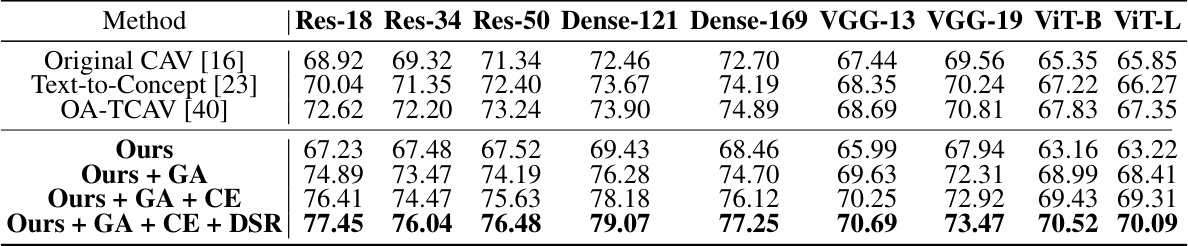
🔼 This table presents a comprehensive comparison of concept accuracy scores for various CAV methods on the Broden dataset. The evaluation is performed across nine different neural network architectures (ResNet-18, ResNet-34, ResNet-50, DenseNet-121, DenseNet-169, VGG-13, VGG-19, ViT-B, ViT-L), each pre-trained on ImageNet. The results are averaged over four independent runs with different random seeds to ensure reliability. The highest accuracy for each architecture is highlighted in bold.
read the caption
Table 1: The comprehensive evaluation of concept accuracy (%) for different CAVs on the Broden dataset. The results are on nine backbones pre-trained on ImageNet (Note that Res denotes ResNet, Dense denotes DenseNet) averaged over 4 runs with different seeds. Bold font denotes the best result.
In-depth insights#
LG-CAV: Concept Training#
LG-CAV, a novel method for training concept activation vectors (CAVs), offers a significant advancement in explainable AI. Its core innovation lies in leveraging pre-trained vision-language models (VLMs), like CLIP, to bypass the need for large, meticulously labeled image datasets typically required for CAV training. Instead of relying on manually curated datasets, LG-CAV uses concept descriptions as guidance. This allows for CAV training on any concept imaginable, making the approach highly versatile. The framework involves calculating activation values from the VLM on a common set of images and training LG-CAV to mimic these activations. The introduction of Gaussian alignment, concept ensemble, and deviation sample reweighting modules further enhances the quality of the resulting CAVs, leading to improved interpretability and model correction capabilities. The LG-CAV approach shows significant improvement over existing methods in terms of both concept accuracy and concept-to-class accuracy, and its application to model correction demonstrates state-of-the-art performance.
VL Model Transfer#
The concept of ‘VL Model Transfer’ in the context of a research paper likely revolves around leveraging pre-trained vision-language (VL) models to enhance a downstream task, such as training concept activation vectors (CAVs). This approach is particularly valuable when labeled data is scarce for the target task. The core idea is to transfer knowledge embedded within the VL model’s rich feature representations to the CAV training process. This transfer could involve several steps such as extracting relevant features from the VL model for a given concept description and then using these features as guidance or supervision signals for training the CAVs on a separate, possibly smaller and less well curated dataset. Careful consideration of the inherent differences between the VL model’s feature space and that of the target model is crucial. This difference necessitates a mechanism to effectively bridge these disparate spaces. Techniques such as alignment or adaptation layers might be employed to ensure compatibility and facilitate the transfer of knowledge. A successful VL Model Transfer would not only improve efficiency but also enhance the quality and generalizability of CAVs by effectively leveraging the wealth of information contained in large-scale VL models trained on diverse image-text datasets. This method thus addresses the key limitation of CAV training, which often requires extensive labeled data. The effectiveness of this transfer is likely to be evaluated by measuring CAV quality, generalization, and perhaps impact on the downstream application.
Model Correction#
The paper introduces a novel method for model correction using Language-Guided Concept Activation Vectors (LG-CAVs). Instead of solely interpreting models, LG-CAVs are leveraged to improve model accuracy by addressing spurious correlations. By training high-quality LG-CAVs representing all classes, the method fine-tunes the target model, aligning class predictions with strongly-related concepts. This is achieved through activation sample reweighting (ASR), which allocates higher training weights to samples highly activated by their corresponding LG-CAVs. This approach differs from prior methods by not being limited to small datasets or specific tasks. The superior performance achieved on various datasets and architectures highlights the effectiveness of using LG-CAVs for model correction, demonstrating the potential of combining concept-based interpretation with model improvement.
Ablation Experiments#
Ablation experiments systematically investigate the contribution of individual components within a model. In the context of the LG-CAV paper, ablation studies likely assessed the impact of each module (Gaussian Alignment, Concept Ensemble, Deviation Sample Reweighting) on the overall performance. By removing a module and measuring the resulting change in concept accuracy and concept-to-class accuracy, the researchers could quantify the effectiveness of each component. The results of these experiments would highlight which modules are essential for LG-CAV’s success and which ones are less critical. Furthermore, the effects of varying the number and selection method of probe images are likely examined. This would help determine the optimal strategy for leveraging vision-language models effectively. Overall, ablation experiments provide crucial evidence to support the paper’s claims and enhance the understanding of LG-CAV’s inner workings, guiding future improvements.
Future of LG-CAV#
The future of LG-CAV (Language-Guided Concept Activation Vector) is bright, given its demonstrated ability to train high-quality CAVs without labeled data. Future research could focus on improving the alignment between vision-language models and target models, perhaps through more sophisticated alignment techniques or by training vision-language models specifically for CAV generation. Exploring alternative methods for generating concept descriptions beyond simple textual descriptions could significantly enhance the diversity and nuance of LG-CAVs. For example, leveraging knowledge graphs or multimodal inputs could yield more robust and comprehensive concept representations. Further investigation into the application of LG-CAVs to other domains such as 3D shape generation, recommender systems, and beyond, is also warranted. Additionally, developing more robust methods for model correction that go beyond simple fine-tuning, potentially by integrating LG-CAVs with other model explanation techniques, would be highly valuable. Finally, addressing the potential biases present in vision-language models and their impact on the quality and fairness of LG-CAVs is crucial for responsible development and deployment.
More visual insights#
More on figures

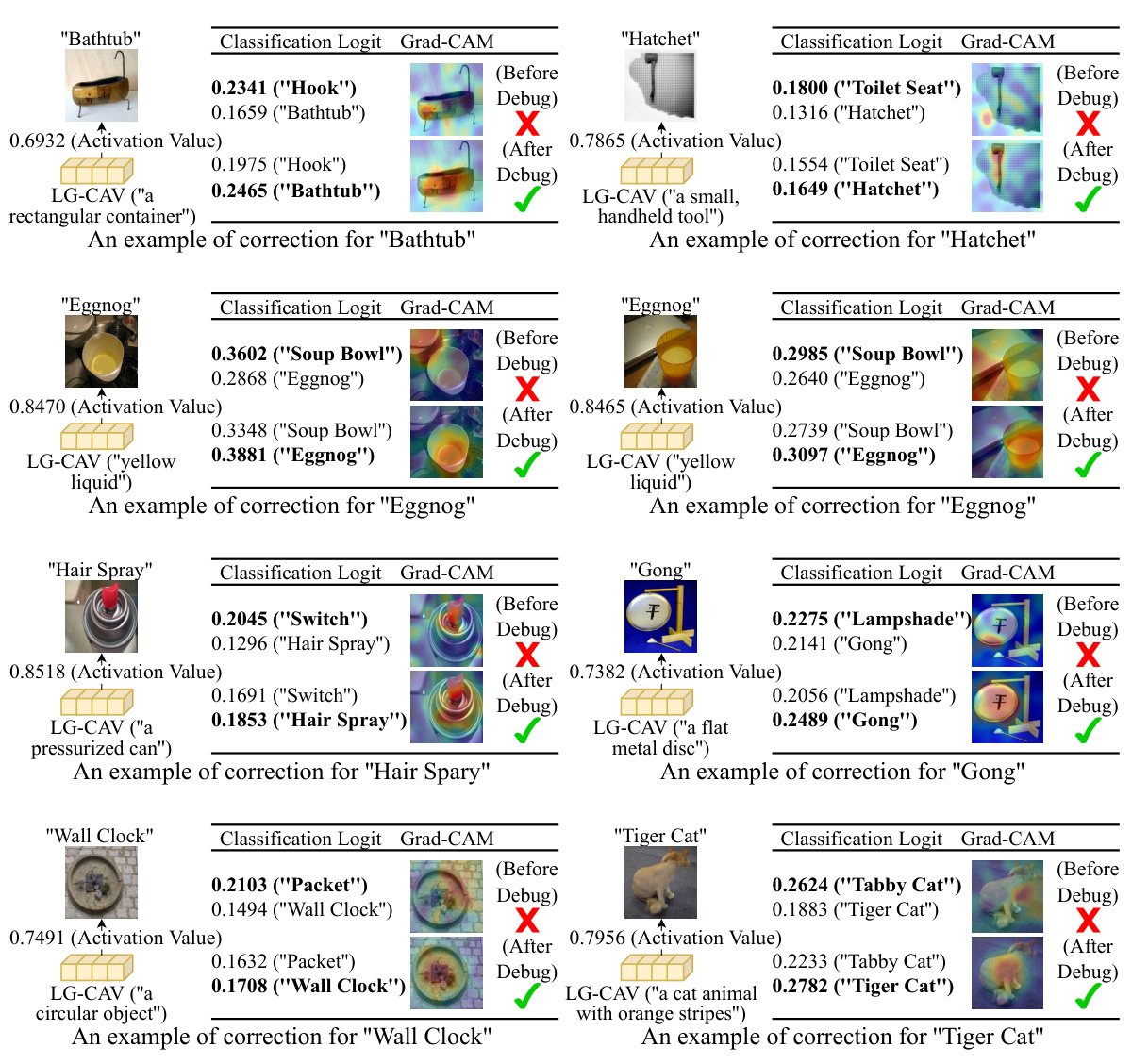
🔼 The figure demonstrates the LG-CAV training framework and the differences in activation value distributions between the vision-language model (VL model) and the target model. (A) shows how LG-CAV leverages activations from the VL model on probe images to train the LG-CAV for a target model. (B) highlights the significant distributional difference between the two models’ activation values for the concept ‘Skyscraper’, emphasizing the need for a mechanism to bridge this gap during LG-CAV training.
read the caption
Figure 2: (A) LG-CAV is trained guided by activations of concept descriptions on the probe images from VL model. (B) The distribution of activation values on a concept named 'Skyscraper' (from the Broden dataset [2]) in the target model (ResNet18) and VL model (CLIP) differs a lot.

🔼 This figure illustrates the architecture of the proposed LG-CAV method and compares it with the original CAV method. The top half shows the original CAV training process, using positive and negative image features to train a binary classifier. The bottom half depicts the LG-CAV, which utilizes activations from a vision-language (VL) model and incorporates three modules (Gaussian Alignment (GA), Concept Ensemble (CE), and Deviation Sample Reweighting (DSR)) to improve training and accuracy. The figure highlights the key differences and improvements of the LG-CAV over the traditional CAV approach.
read the caption
Figure 3: Top: The original CAV is defined as the weight vector for its represented concept in the binary linear classifier. Bottom: The LG-CAV is learned by mimicking the activation values of its represented concept on the probe images R using VL model. Besides, three modules (GA module, CE module, and DSR module) are proposed to enhance the quality of LG-CAV.
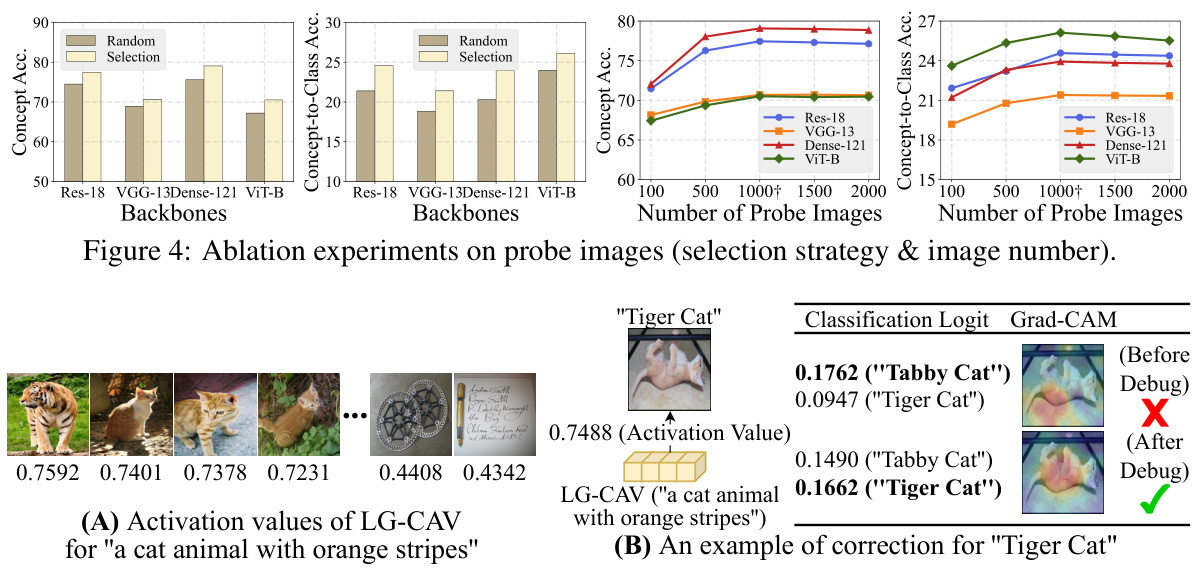
🔼 This figure presents the ablation studies conducted on the selection strategy and number of probe images used in the LG-CAV model. The left two subfigures show the comparison of concept accuracy and concept-to-class accuracy between random probe image selection and the proposed strategy (selecting the most and least activated images). The right two subfigures illustrate how the number of probe images affects the model performance in terms of concept accuracy and concept-to-class accuracy. The results demonstrate that the proposed selection strategy and a sufficient number of probe images are crucial for achieving high-quality LG-CAVs.
read the caption
Figure 4: Ablation experiments on probe images (selection strategy & image number).

🔼 This figure shows the results of ablation experiments conducted to analyze the impact of probe image selection strategy and the number of probe images on the performance of LG-CAV. The left panel displays concept accuracy, while the right panel shows concept-to-class accuracy. Both accuracy metrics are plotted against the number of probe images used for training, showing results for four different backbones (ResNet-18, VGG-13, DenseNet-121, and ViT-B) and comparing a random selection strategy to a more focused selection method. The results illustrate the optimal configuration for probe image selection and the number of images required to achieve superior performance.
read the caption
Figure 4: Ablation experiments on probe images (selection strategy & image number).

🔼 This figure illustrates the architecture of the proposed LG-CAV method in comparison to the original CAV method. The original CAV is shown on the top, while the LG-CAV is shown on the bottom, with added Gaussian Alignment Module (GA), Concept Ensemble Module (CE), and Deviation Sample Reweighting Module (DSR) to improve the LG-CAV quality. The LG-CAV learns by mimicking VL model’s activation values on probe images, bridging the gap between VL model and the target model.
read the caption
Figure 3: Top: The original CAV is defined as the weight vector for its represented concept in the binary linear classifier. Bottom: The LG-CAV is learned by mimicking the activation values of its represented concept on the probe images R using VL model. Besides, three modules (GA module, CE module, and DSR module) are proposed to enhance the quality of LG-CAV.
🔼 This figure illustrates the architecture of the proposed LG-CAV method, comparing it to the original CAV method. The top half shows the original CAV approach, training a binary classifier on positive and negative image features to obtain a concept activation vector. The bottom half details the LG-CAV which uses a vision-language model (VL) and incorporates three additional modules (Gaussian Alignment, Concept Ensemble, and Deviation Sample Reweighting) to improve the quality of the resulting concept activation vector.
read the caption
Figure 3: Top: The original CAV is defined as the weight vector for its represented concept in the binary linear classifier. Bottom: The LG-CAV is learned by mimicking the activation values of its represented concept on the probe images R using VL model. Besides, three modules (GA module, CE module, and DSR module) are proposed to enhance the quality of LG-CAV.
More on tables
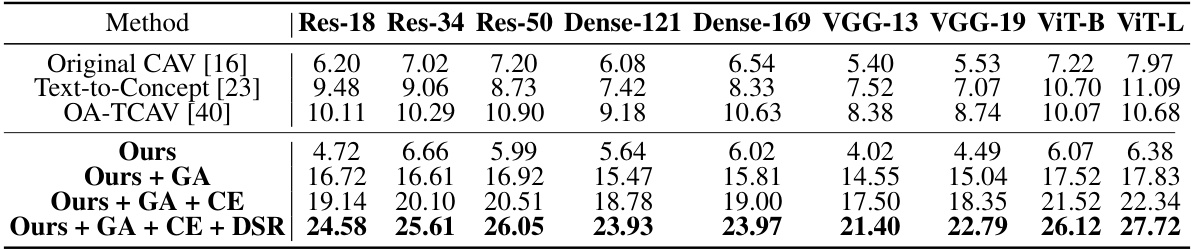
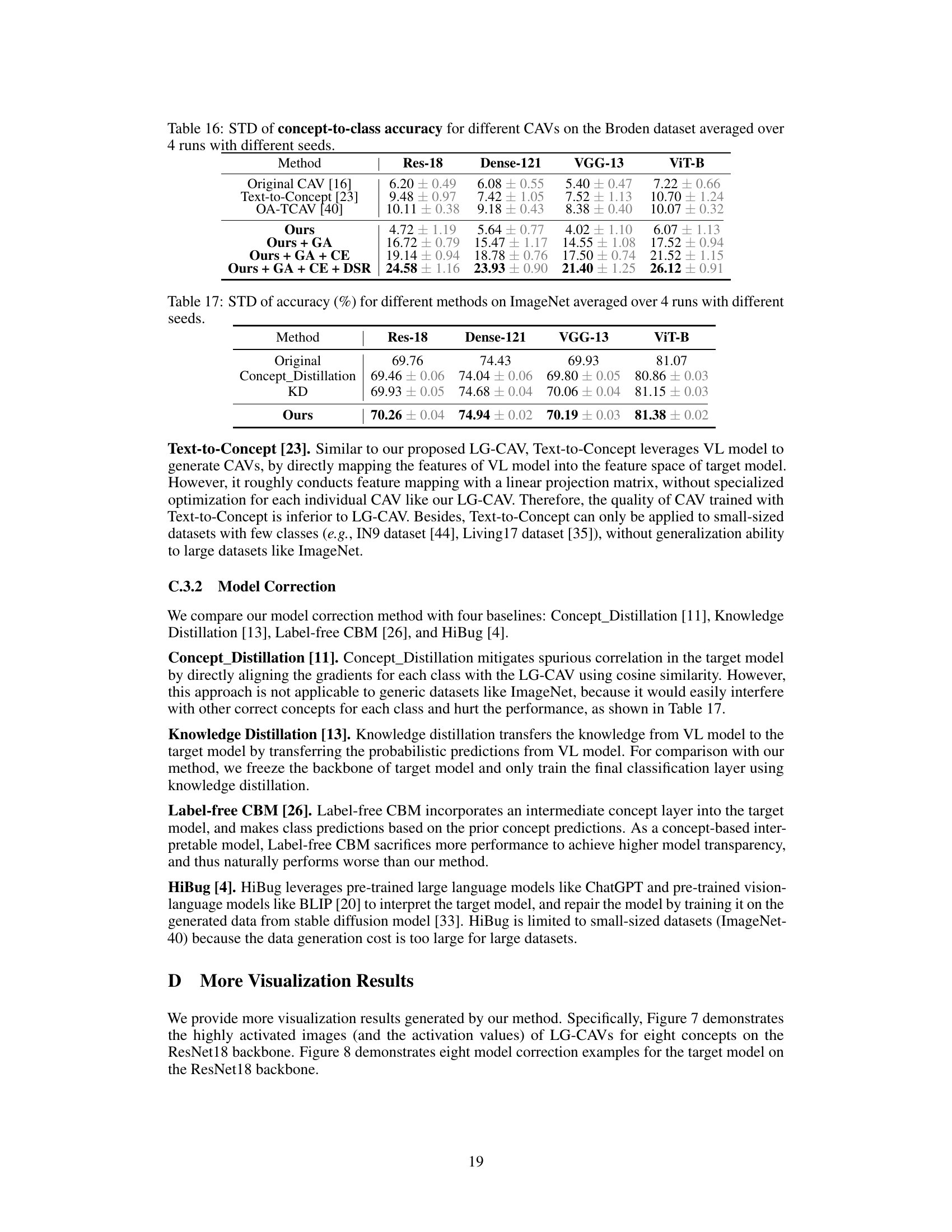
🔼 This table presents the concept-to-class accuracy results for various CAV methods on the Broden dataset. Concept-to-class accuracy measures how well the CAV aligns with its semantically related class. The table shows the performance of different CAV methods (Original CAV, Text-to-Concept, OA-TCAV, and the proposed LG-CAV with different modules added). Results are averaged over four runs with different random seeds for each of nine different network architectures (ResNet-18, ResNet-34, ResNet-50, DenseNet-121, DenseNet-169, VGG-13, VGG-19, ViT-B, ViT-L). Higher scores indicate better performance.
read the caption
Table 2: The comprehensive evaluation of concept-to-class accuracy for different CAVs on the Broden dataset averaged over 4 runs with different seeds.

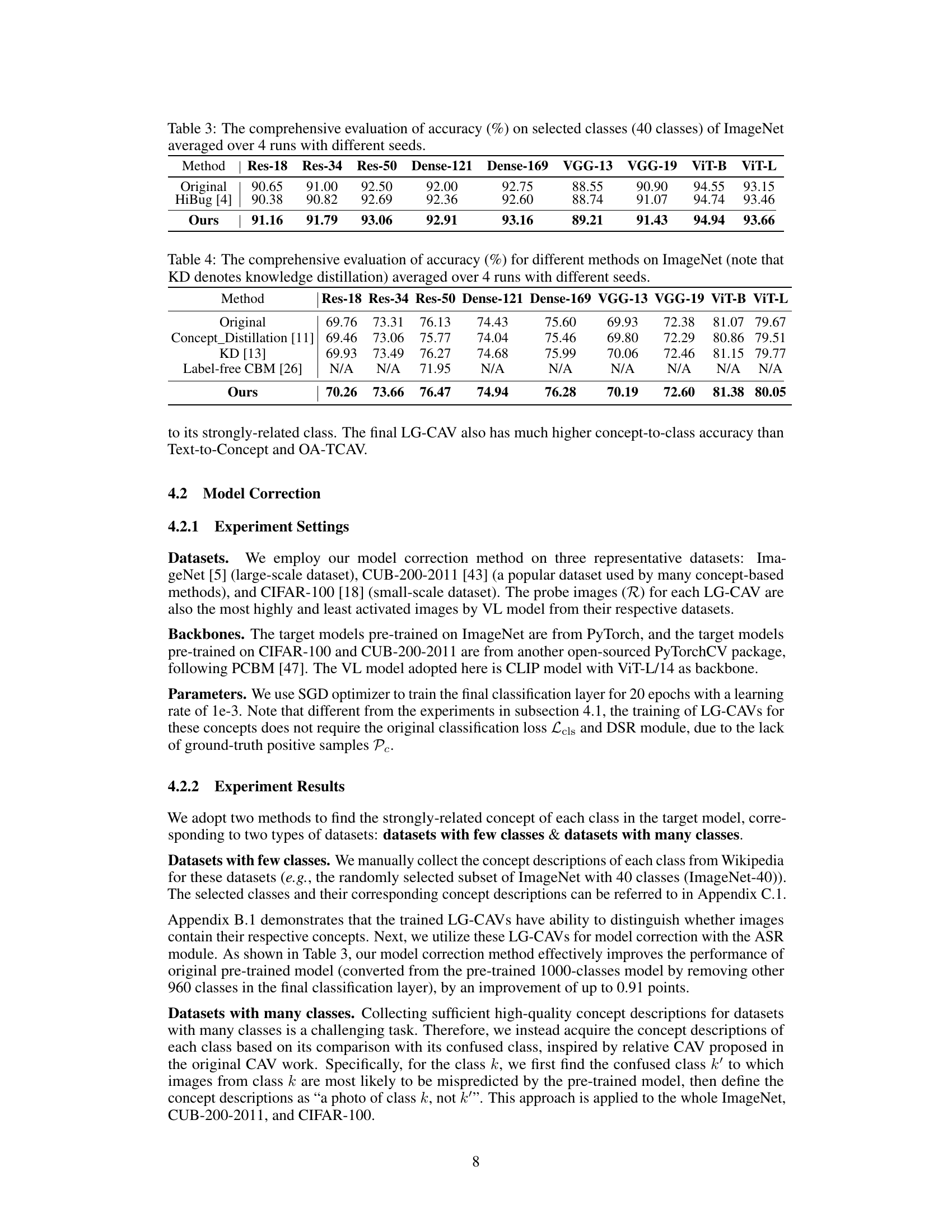
🔼 This table presents the accuracy results of different methods on a subset of 40 classes from the ImageNet dataset. The methods compared include the original model, HiBug, and the proposed LG-CAV method. The accuracy is averaged over four runs, each with a different random seed to assess the robustness and reliability of the results. The table shows the performance of these methods across nine different model architectures (ResNet-18, ResNet-34, ResNet-50, DenseNet-121, DenseNet-169, VGG-13, VGG-19, ViT-B, and ViT-L).
read the caption
Table 3: The comprehensive evaluation of accuracy (%) on selected classes (40 classes) of ImageNet averaged over 4 runs with different seeds.

🔼 This table compares the accuracy of different model correction methods on the ImageNet dataset. It shows the accuracy for ResNet-18, ResNet-34, ResNet-50, DenseNet-121, DenseNet-169, VGG-13, VGG-19, ViT-B, and ViT-L. The methods compared include the original model, Concept Distillation, Knowledge Distillation, Label-free CBM, and the proposed LG-CAV method. The results are averaged over four runs with different random seeds to show the robustness and reliability of the results.
read the caption
Table 4: The comprehensive evaluation of accuracy (%) for different methods on ImageNet (note that KD denotes knowledge distillation) averaged over 4 runs with different seeds.

🔼 This table presents the Recall@100 for different CAV methods on the ImageNet-40 dataset. Recall@100 measures how well a CAV can identify the top 100 images most relevant to its concept from a set of test images. The results are shown for nine different network architectures (ResNets, DenseNets, VGGs, and Vision Transformers). A randomly initialized CAV serves as a baseline. Bold type indicates the best result for each architecture.
read the caption
Table 5: The averaged Recall@100 (%) of LG-CAVs on ImageNet-40. Random CAV denotes the randomly initialized CAV. Bold font denotes the best result.
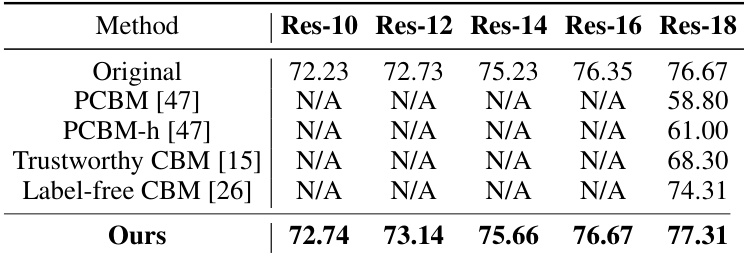
🔼 This table compares the performance of different concept-based methods (including the proposed LG-CAV) on the CUB-200-2011 dataset. The accuracy is measured across five different ResNet backbones (Res-10, Res-12, Res-14, Res-16, Res-18). Results for PCBM, PCBM-h, and Trustworthy CBM are taken from the original papers, allowing for a direct comparison with the LG-CAV’s performance.
read the caption
Table 6: The evaluation of accuracy (%) for different concept-based methods on the CUB-200-2011 dataset over five backbones. The results of PCBM & Trustworthy CBM & Label-free CBM are from their original paper.

🔼 This table presents the accuracy results achieved by the proposed LG-CAV method and compares it with the original CAV method’s performance. The results are averaged over four independent runs with different random seeds to ensure robustness. The accuracy is evaluated across 40 selected classes from the ImageNet dataset, and the performance is measured across nine different backbone architectures (ResNet-18, ResNet-34, ResNet-50, DenseNet-121, DenseNet-169, VGG-13, VGG-19, ViT-B, and ViT-L).
read the caption
Table 7: The comprehensive evaluation of accuracy (%) on selected classes (40 classes) of ImageNet averaged over 4 runs with different seeds.

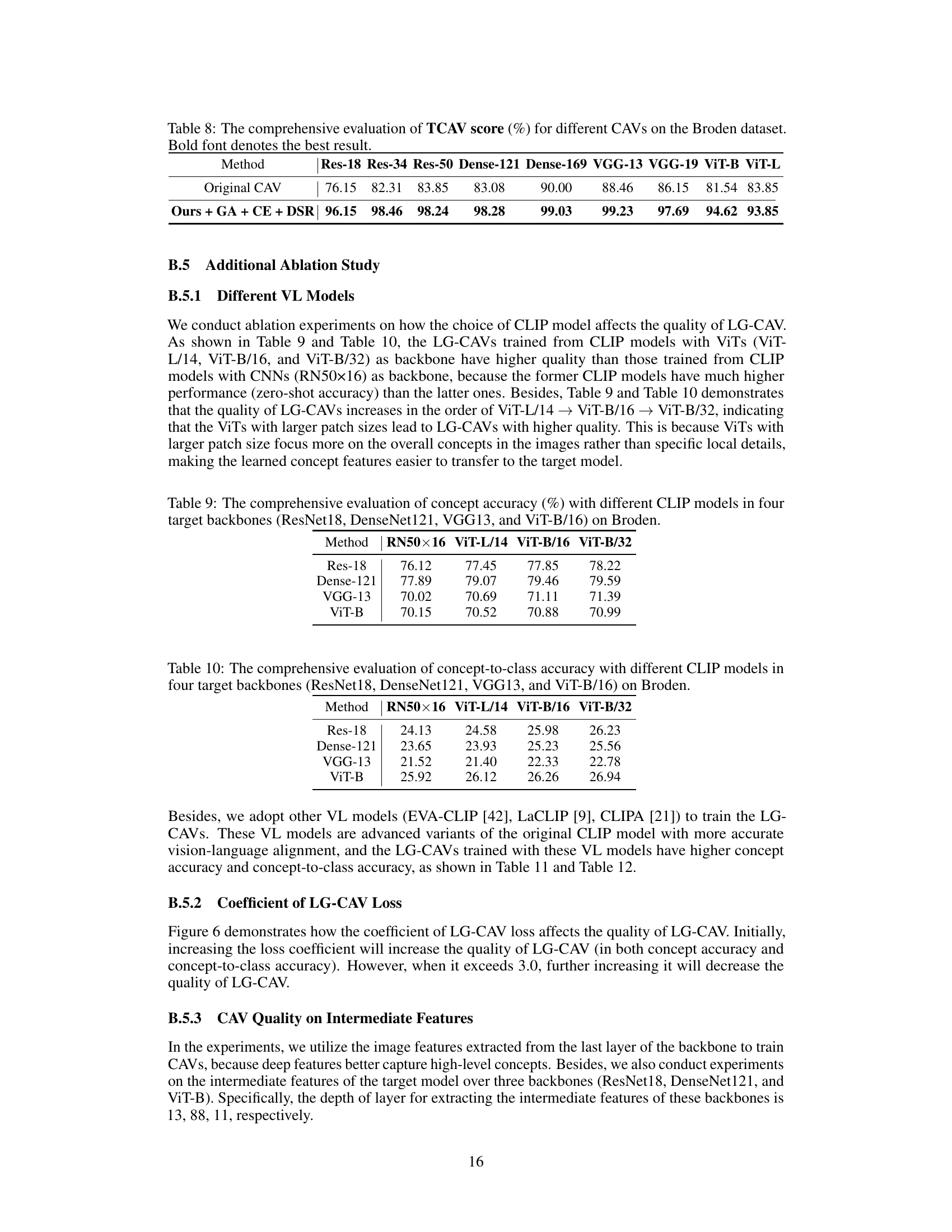
🔼 This table presents a comparison of TCAV scores for various CAV methods on the Broden dataset. TCAV (Testing with Concept Activation Vectors) score measures how well a CAV represents its associated concept. The table shows the performance of the original CAV method and the improved LG-CAV method (with Gaussian alignment (GA), concept ensemble (CE), and deviation sample reweighting (DSR) modules) across nine different neural network backbones (ResNet-18, ResNet-34, ResNet-50, Dense-121, Dense-169, VGG-13, VGG-19, ViT-B, ViT-L). Higher scores indicate better concept representation.
read the caption
Table 8: The comprehensive evaluation of TCAV score (%) for different CAVs on the Broden dataset. Bold font denotes the best result.
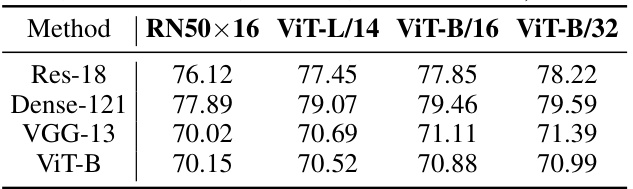
🔼 This table shows the concept accuracy results of LG-CAV using different CLIP models (RN50x16, ViT-L/14, ViT-B/16, and ViT-B/32) as backbones. The accuracy is measured across four different target models (ResNet18, DenseNet121, VGG13, and ViT-B/16) using the Broden dataset. The results demonstrate the impact of the choice of CLIP model on the performance of LG-CAV.
read the caption
Table 9: The comprehensive evaluation of concept accuracy (%) with different CLIP models in four target backbones (ResNet18, DenseNet121, VGG13, and ViT-B/16) on Broden.
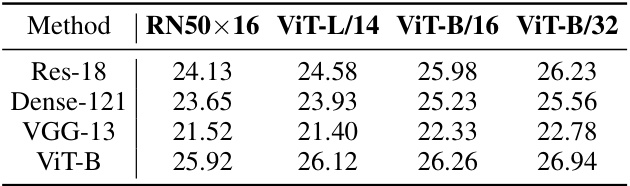
🔼 This table shows the concept-to-class accuracy results for different CLIP models (RN50x16, ViT-L/14, ViT-B/16, and ViT-B/32) across four different backbones (ResNet18, DenseNet121, VGG13, and ViT-B/16) on the Broden dataset. The concept-to-class accuracy metric assesses how well the CAV’s align with the strongly semantic-related class. Higher values indicate better alignment and therefore higher quality CAVs.
read the caption
Table 10: The comprehensive evaluation of concept-to-class accuracy with different CLIP models in four target backbones (ResNet18, DenseNet121, VGG13, and ViT-B/16) on Broden.

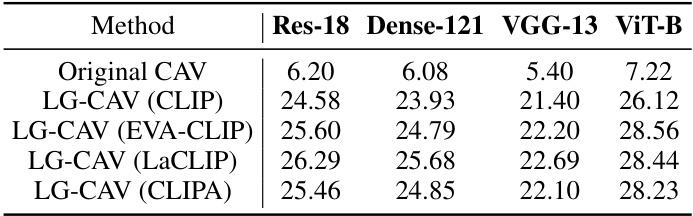
🔼 This table shows the concept accuracy results for different vision-language models (VLMs) used in training LG-CAV. The accuracy is evaluated across four different backbones (ResNet18, DenseNet121, VGG-13, and ViT-B/16) on the Broden dataset. Each row represents a different VLM used (CLIP, EVA-CLIP, LaCLIP, and CLIPA). The original CAV results are also included for comparison.
read the caption
Table 11: The comprehensive evaluation of concept accuracy (%) with different VL models in four target backbones (ResNet18, DenseNet121, VGG13, and ViT-B/16) on Broden. These VL models all adopt ViT-L/14 as backbones.
🔼 This table presents the concept-to-class accuracy results for various CAV methods on the Broden dataset. Different CLIP models (RN50x16, ViT-L/14, ViT-B/16, ViT-B/32) were used, and the results are broken down by four different backbones (ResNet18, DenseNet121, VGG13, ViT-B/16). The concept-to-class accuracy metric evaluates how well the CAV correlates with its strongly related class, assessing the quality of the CAV in identifying semantically similar classes.
read the caption
Table 10: The comprehensive evaluation of concept-to-class accuracy (%) with different CLIP models in four target backbones (ResNet18, DenseNet121, VGG13, and ViT-B/16) on Broden.

🔼 This table presents the concept accuracy results for different configurations of the LG-CAV model. The concept accuracy is evaluated on the Broden dataset using three different backbones: ResNet18, DenseNet121, and ViT-B/16. The table compares the performance of the original CAV method against several variations of the LG-CAV method, each incorporating additional modules (GA, CE, DSR). Higher values indicate better performance. The bold values indicate the best-performing configuration for each backbone.
read the caption
Table 13: The comprehensive evaluation of concept accuracy (%) for intermediate features in three backbones (ResNet18, DenseNet121, and ViT-B/16) of the target model on the Broden dataset. Bold font denotes the best result.

🔼 This table presents the concept-to-class accuracy results for different CAV methods on the Broden dataset, specifically focusing on the performance using intermediate features from three different backbones (ResNet18, DenseNet121, and ViT-B/16). The table compares the performance of the original CAV method against the LG-CAV method with different modules (GA, CE, and DSR). The bold font highlights the best-performing method for each backbone.
read the caption
Table 14: The comprehensive evaluation of concept-to-class accuracy for intermediate features in three backbones (ResNet18, DenseNet121, and ViT-B/16) on Broden. Bold font denotes the best result.
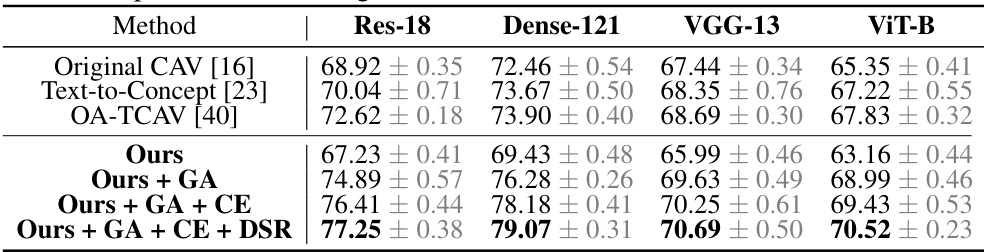
🔼 This table presents the concept accuracy results for different CAV methods on the Broden dataset. Concept accuracy measures how well a CAV represents its corresponding concept. The results are broken down by nine different ImageNet pre-trained backbones (ResNet-18, ResNet-34, ResNet-50, DenseNet-121, DenseNet-169, VGG-13, VGG-19, ViT-B, ViT-L), with the best result for each backbone highlighted in bold. The experiment was run four times with different random seeds, and the average is reported.
read the caption
Table 1: The comprehensive evaluation of concept accuracy (%) for different CAVs on the Broden dataset. The results are on nine backbones pre-trained on ImageNet (Note that Res denotes ResNet, Dense denotes DenseNet) averaged over 4 runs with different seeds. Bold font denotes the best result.
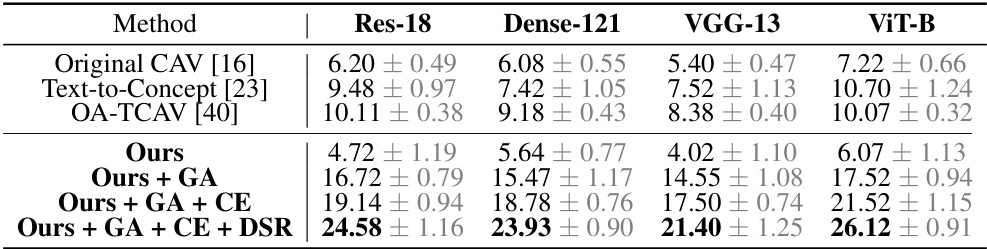
🔼 This table presents a comparison of concept-to-class accuracy across various CAV (Concept Activation Vector) methods on the Broden dataset. The results are averaged over four independent runs with different random seeds to ensure statistical robustness. Concept-to-class accuracy measures how well a CAV’s representation of a concept aligns with its strongly semantically related class, offering a measure of the CAV’s quality. The table shows that the proposed LG-CAV method significantly outperforms existing CAV methods across multiple different neural network architectures.
read the caption
Table 2: The comprehensive evaluation of concept-to-class accuracy for different CAVs on the Broden dataset averaged over 4 runs with different seeds.
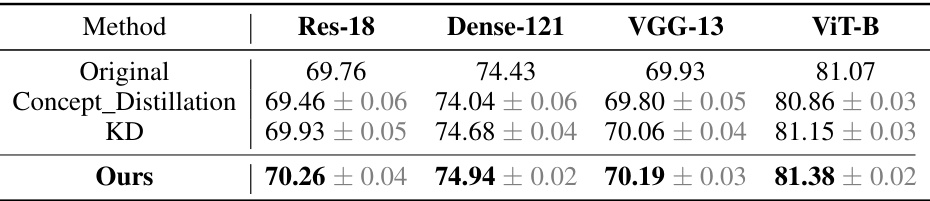
🔼 This table presents a comprehensive evaluation of the accuracy achieved by different methods on the ImageNet dataset. The methods compared include the original model, Concept Distillation, Knowledge Distillation, Label-free CBM, and the proposed LG-CAV method. The results are averaged over four runs using different random seeds, providing a measure of robustness and reliability. The table highlights the performance improvements obtained by the LG-CAV approach compared to existing state-of-the-art methods.
read the caption
Table 4: The comprehensive evaluation of accuracy (%) for different methods on ImageNet (note that KD denotes knowledge distillation) averaged over 4 runs with different seeds.

🔼 This table presents a comprehensive comparison of concept accuracy across various CAV (Concept Activation Vector) methods on the Broden dataset. The evaluation considers nine different pre-trained ImageNet backbones (ResNet, DenseNet, VGG, ViT). Results are averaged over four runs with varying random seeds to ensure reliability, with the best performing method highlighted in bold font.
read the caption
Table 1: The comprehensive evaluation of concept accuracy (%) for different CAVs on the Broden dataset. The results are on nine backbones pre-trained on ImageNet (Note that Res denotes ResNet, Dense denotes DenseNet) averaged over 4 runs with different seeds. Bold font denotes the best result.

🔼 This table presents a comparison of concept accuracy scores for different CAV (Concept Activation Vector) methods on the Broden dataset. The evaluation was performed across nine different neural network architectures (ResNet18, ResNet34, ResNet50, DenseNet121, DenseNet169, VGG13, VGG19, ViT-B, ViT-L) pre-trained on ImageNet. The results are averaged across four independent runs to ensure robustness. The best performing method for each architecture is highlighted in bold.
read the caption
Table 1: The comprehensive evaluation of concept accuracy (%) for different CAVs on the Broden dataset. The results are on nine backbones pre-trained on ImageNet (Note that Res denotes ResNet, Dense denotes DenseNet) averaged over 4 runs with different seeds. Bold font denotes the best result.
Full paper#