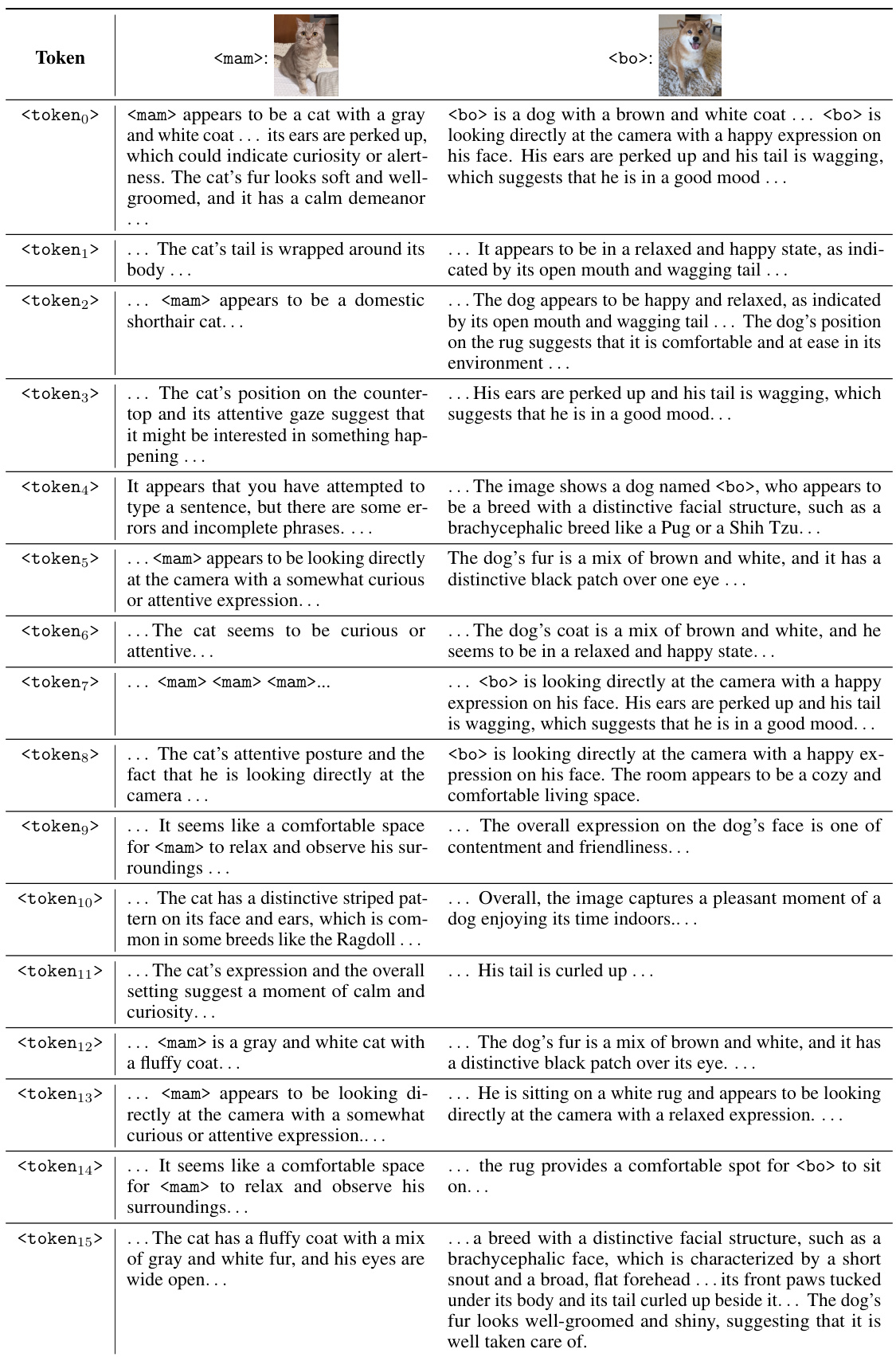
↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Existing Large Multimodal Models (LMMs) struggle with personalized information, lacking the ability to engage in conversations about specific, user-defined subjects. This paper addresses this limitation by introducing the novel task of personalizing LMMs.
Yo’LLaVA, the proposed method, effectively personalizes LMMs using a novel framework embedding personalized concepts into latent tokens. It leverages hard negative mining to improve subject recognition. This approach is efficient, requires few tokens, and outperforms strong baselines, setting a new benchmark in personalized LMMs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to personalize large multimodal models (LMMs). Personalizing LLMs is a crucial step towards creating more user-friendly and effective AI systems, and this work makes significant contributions to this emerging area of research by proposing Yo’LLaVA. The efficient framework, using fewer tokens and hard negative mining, offers a practical solution for personalizing LLMs, and the open-source nature of the work further promotes reproducibility and collaboration within the research community.
Visual Insights#

This figure demonstrates the personalization capability of Yo’LLaVA. Given only a few images of a novel subject (in this case, a dog), Yo’LLaVA can engage in both text-based and visual conversations about that specific subject. It contrasts its responses with those of a standard LLM (LLaVA), highlighting Yo’LLaVA’s ability to handle personalized queries and visual recognition tasks beyond the capabilities of generic LLMs.
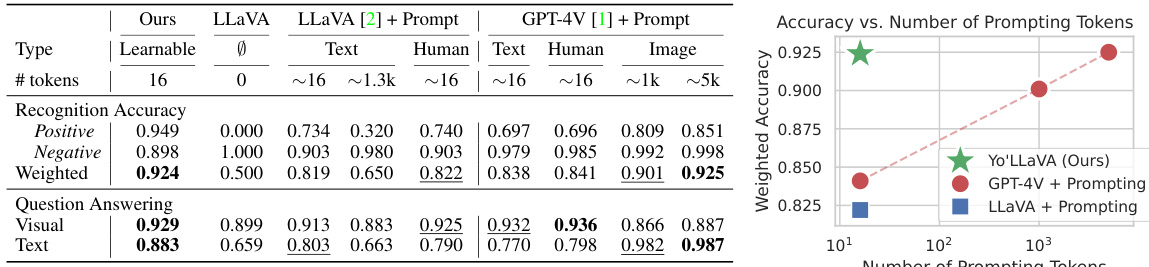
This table compares the performance of Yo’LLaVA against two baselines: Vanilla LLaVA and LLaVA with human-written or LLaVA-generated descriptions, and GPT-4V with text or image prompting. It shows the recognition accuracy (positive, negative, and weighted average) and question-answering accuracy (visual and text) for each method. The number of tokens used for prompting is also included, highlighting the efficiency of Yo’LLaVA’s learnable prompt approach.
In-depth insights#
Personalized LLM#
The concept of a “Personalized LLM” represents a significant advancement in the field of large language models. It moves beyond the limitations of generic LLMs by tailoring the model’s knowledge and responses to a specific individual or entity. This personalization is achieved through various techniques, including fine-tuning on a user’s data or by incorporating personal information into the model’s prompt. The key advantage lies in creating a more relevant and useful experience by generating context-aware and individualized outputs. Privacy is a major concern with personalized LLMs, however, as they require access to personal information. This makes data security and user consent crucial aspects that must be carefully addressed. While the potential benefits are substantial, including more effective virtual assistants, personalized education tools, and improved healthcare systems, the ethical considerations surrounding data usage and potential biases must be carefully evaluated and mitigated to ensure responsible development and deployment.
Learnable Prompt#
The concept of a “learnable prompt” presents a compelling alternative to traditional prompting methods in large multimodal models (LMMs). Instead of relying on fixed, handcrafted prompts, a learnable prompt is dynamically adjusted and optimized during the training process. This approach allows the LMM to learn a more nuanced and precise representation of a personalized concept (e.g., a specific person or pet). The approach is particularly powerful when dealing with subjects that are difficult or impossible to describe effectively using natural language. The use of learnable tokens within the prompt enables the model to embed visual details which provide a richer, more efficient representation than any textual prompt possibly could. This leads to improved performance in tasks such as visual recognition and personalized question answering. The efficiency gains are significant, especially when limited training data is available for the personalized concept, thus demonstrating the practical advantages of this approach. However, it’s crucial to consider that potential limitations may include difficulty in capturing very fine-grained visual details and the risk of overfitting, especially with small training sets.
Hard Negative Mining#
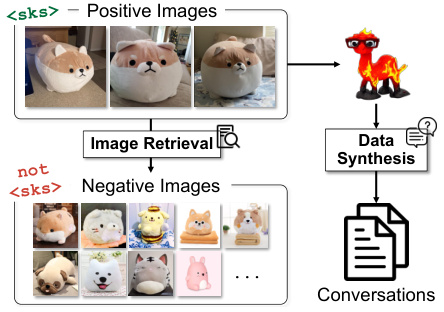
Hard negative mining is a crucial technique used to enhance the performance of machine learning models, particularly in scenarios involving visual recognition. The core idea is to augment the training data with examples that are visually similar to the target class but do not actually belong to it. These ‘hard negatives’ pose a significant challenge to the model, forcing it to learn more discriminative features and preventing overgeneralization. By carefully selecting these hard negatives, often through techniques like nearest neighbor search in embedding space, and incorporating them into the training process, the model learns to distinguish subtle differences and improves its accuracy and robustness. The difficulty of identifying truly challenging hard negatives is a key factor affecting the effectiveness of this strategy; if the negatives are too easy or too difficult, the model may not benefit substantially. Careful selection and balance between positive and hard negative examples are therefore essential for success. A key benefit is the significant improvement in generalization ability; the model learns more robust features that transfer well to unseen data.
Ablation Study#
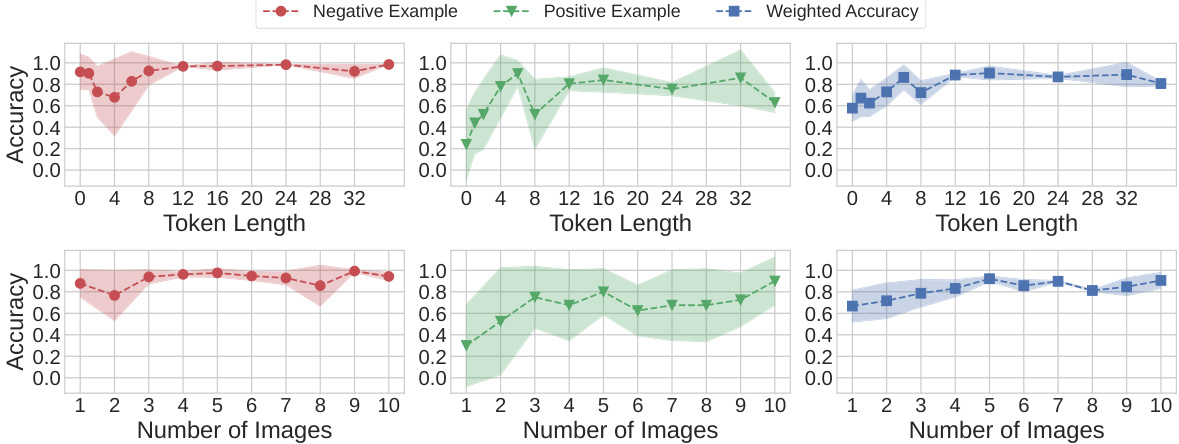
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a personalized language and vision assistant, an ablation study might explore the impact of removing different elements, such as the number of training images, the quantity of learnable tokens, or the inclusion of hard negative mining. By observing the changes in performance metrics (e.g., recognition accuracy, conversational fluency) after each removal, researchers can determine the relative importance of each component. This process is crucial for understanding the model’s inner workings, identifying critical features, and potentially simplifying the model while maintaining performance. A well-designed ablation study is essential for validating the model’s design choices and justifying the inclusion of specific features. Moreover, it helps to rule out any unintended shortcuts in model training and ensures the findings are robust and reliable. The results may guide future improvements, indicating which components are most crucial and highlighting areas for optimization. Finally, such studies contribute to a deeper understanding of personalized LLM models, providing valuable insights into the effectiveness of specific design decisions and informing future model development in this rapidly evolving field.
Future Directions#
Future research directions for personalized large multimodal models (LMMs) like YoLLaVA should prioritize several key areas. Improving the handling of fine-grained visual details is crucial, enabling more nuanced understanding of personalized subjects. This involves exploring advanced techniques in visual feature extraction and representation, potentially leveraging attention mechanisms or other methods to capture subtle differences. Addressing the limitations of current methods in recognizing personalized subjects in complex scenes or with occlusions is also important. This might involve incorporating robust object detection and tracking algorithms or developing more advanced methods for handling uncertainty. Investigating the use of multi-modal data beyond images and text (e.g., audio, sensor data) would significantly expand the capabilities of personalized LMMs, allowing for richer interactions and a more comprehensive understanding of personalized concepts. Finally, thorough exploration of ethical considerations and bias mitigation techniques is absolutely necessary, especially considering that personalized models can be susceptible to amplifying existing biases present in the training data. The development of methods to prevent and mitigate biases, along with transparent and responsible deployment strategies, should be a central focus.
More visual insights#
More on figures
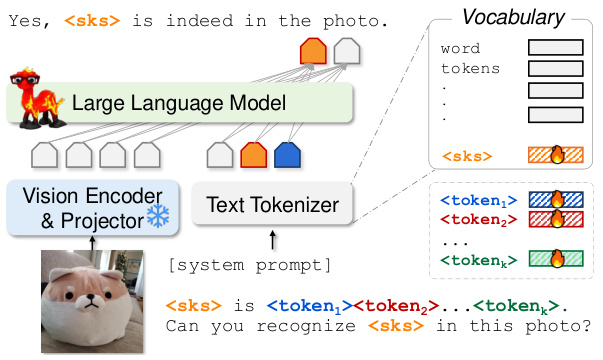
This figure illustrates the core concept of Yo’LLaVA. Given only a small number of images of a specific object or person (in this case, a dog named ‘
’), Yo’LLaVA is able to engage in both text-based and image-based conversations about that specific subject. The figure shows examples of both types of conversations, demonstrating Yo’LLaVA’s ability to personalize its responses based on the provided images. This contrasts with traditional LLMs which lack this ability to handle personalized subjects.

This figure shows an overview of Yo’LLaVA’s capabilities. Given only a few images of a new subject (in this example, a dog named ‘
’), the system learns to engage in both text-based and image-based conversations about that specific subject. It highlights the contrast with existing Large Multimodal Models (LMMs), which struggle with personalized scenarios, showing how Yo’LLaVA surpasses them in understanding and responding to questions about this novel subject. The text conversation example demonstrates understanding of the subject’s characteristics, while the visual conversation example shows object recognition within an image.
This figure illustrates the core idea of the YoLLaVA model. It shows how, given only a few images of a new subject (in this example, a dog), the model learns to understand and respond to both text and image-based questions about that specific subject. The example shows personalized text conversations, where the model answers questions about the dog’s birthday, as well as personalized visual conversations, where it identifies the dog in a picture and describes what the dog is doing. This highlights YoLLaVA’s ability to go beyond generic object recognition and engage in personalized interactions.

This figure demonstrates the core functionality of Yo’LLaVA. Given only a small number of images of a novel subject (in this case, a dog), Yo’LLaVA can engage in both text and image-based conversations about that subject. It shows how Yo’LLaVA personalizes the interaction by understanding the specific subject, unlike general LMMs which would only offer generic responses. The figure contrasts the responses of Yo’LLaVA with those from a standard LLM (LLaVA), highlighting the improvement in personalization.
This figure shows how Yo’LLaVA, given a small number of images of a novel subject (in this case, a dog), is able to hold both text and visual conversations about that subject. The example shows text conversations where questions about the dog’s birthday present are answered, and visual conversations where the model is asked if the dog is in a picture and describes what the dog is doing in the picture. This illustrates the key concept of personalization for LMMs.

This figure shows examples of how Yo’LLaVA, a personalized language and vision assistant, can engage in both textual and visual conversations about a novel subject given only a few images. The left side demonstrates a text-based conversation about buying a birthday gift for the subject, while the right side shows a visual conversation identifying the subject within a photograph and describing their actions. The figure highlights Yo’LLaVA’s ability to handle personalized subjects, unlike generic LMMs.

The figure shows how Yo’LLaVA, a personalized language and vision assistant, can engage in both textual and visual conversations about a specific subject given only a few images. The example shown involves a dog named ‘
’. The left side displays the personalized concepts, training images used to personalize the model for , and the textual conversation about . The right side depicts a visual conversation where the model correctly identifies in an image and answers a question about its activity.

This figure demonstrates the capabilities of Yo’LLaVA. Given only a small number of images of a new subject (in this case, a dog), Yo’LLaVA is able to engage in both text-based and visual conversations about that subject. The left side shows text-based conversations where Yo’LLaVA provides personalized answers to questions about the subject, while the right side illustrates visual conversations where Yo’LLaVA correctly identifies and comments on the subject within an image. This highlights Yo’LLaVA’s ability to learn and apply knowledge about specific, personalized subjects.

This figure shows the overall functionality of Yo’LLaVA. Given only a few images of an object (like a dog), Yo’LLaVA can learn to answer questions about it through both text and image-based conversation. The example shows both a text-based conversation (asking for birthday gift recommendations) and a visual conversation (identifying the dog in an image). This demonstrates Yo’LLaVA’s ability to personalize its responses around a specific subject rather than giving generic answers.

This figure shows examples of how Yo’LLaVA, a personalized language and vision assistant, can engage in both text-based and visual conversations about a novel subject, given only a few images of that subject. The example uses a dog named ‘
’ as the subject. The figure demonstrates that Yo’LLaVA can not only identify the subject in images but also answer questions and generate relevant text about the subject, demonstrating an ability to personalize LMM knowledge beyond generic object recognition.

This figure demonstrates Yo’LLaVA’s ability to personalize conversations using only a few images of a new subject. The top part shows the input of personalized concepts and training images. The middle part shows how Yo’LLaVA handles personalized text conversations and how it answers questions about the subject. The bottom part shows how it performs personalized visual conversations, using the input image and answering the questions more effectively than baselines like LLaVA.

This figure shows three example conversations using Yo’LLaVA. The first conversation involves asking a question about the subject (a dog named
) using text. The second is asking whether the subject appears in a photo, also using text. The third conversation involves the same question as the second but uses an image as input to Yo’LLaVA. Each conversation includes a comparison between Yo’LLaVA and the original LLaVA model. The key takeaway is that Yo’LLaVA, given a few images of a novel subject, can handle personalized queries and provide answers grounded in the visual attributes of the subject, unlike the generic responses from the original LLaVA.

The figure shows how Yo’LLaVA, a personalized language and vision assistant, uses a few images of a novel subject to learn and engage in both textual and visual conversations about that subject. The example given is a dog named ‘
’. The left side depicts personalized concept training (images of the dog), the middle shows a text-based conversation about buying a gift for the dog, and the right side shows a visual conversation involving an image of the dog, where Yo’LLaVA correctly identifies the dog in the photo and even provides a descriptive caption. This demonstrates Yo’LLaVA’s ability to personalize its knowledge and conversation skills.

This figure shows how Yo’LLaVA, a personalized language and vision assistant, can be used to have conversations about a specific subject, even with just a few images of that subject. The example shows a personalized text conversation and a personalized visual conversation, both centered around a dog named ‘
’. It highlights Yo’LLaVA’s ability to answer questions about ‘ ’s’ appearance, activities, and preferences, contrasting with the generic responses of a non-personalized language and vision model (LLaVA).

The figure shows how Yo’LLaVA, given only a few images of a novel subject (in this case, a dog), can successfully engage in both text-based and image-based conversations about that specific subject. It highlights Yo’LLaVA’s ability to move beyond generic LLM capabilities and personalize responses based on the provided images. The figure showcases examples of personalized text conversations (where the model gives relevant advice considering the dog’s identity) and image-based conversations (where the model correctly identifies the dog in a photo).

This figure shows how Yo’LLaVA, a personalized language and vision assistant, can engage in conversations about a novel subject (in this case, a dog) using only a few images of that subject. The figure illustrates that Yo’LLaVA can handle both textual and visual conversations, understanding the context and providing personalized responses. It compares Yo’LLaVA’s responses to those of a general LLM (LLaVA), highlighting the improvements achieved by personalization.

This figure demonstrates the core functionality of Yo’LLaVA. Given only a few images of a new subject (in this case, a dog named ‘
’), Yo’LLaVA is able to understand and respond to both textual and visual questions about that subject. The example shows how Yo’LLaVA is able to answer questions like ‘What do you recommend?’ regarding a birthday gift, and correctly identify the subject in images.

The figure shows a visual example of Yo’LLaVA’s capability. Using only a few images of a novel subject (a dog named
), Yo’LLaVA can perform both text and visual conversations related to that subject. It demonstrates the system’s ability to personalize the interaction by recognizing the subject in new images and generating relevant responses to questions about it.

The figure illustrates the core functionality of Yo’LLaVA. Given only a small number of images of a novel subject (in this case, a dog), Yo’LLaVA is able to engage in both textual and visual conversations about that subject. The example shows how Yo’LLaVA can answer questions about the dog’s appearance, activities, and even suggest birthday gifts, showcasing its ability to personalize interactions beyond simple object recognition.

The figure shows examples of how Yo’LLaVA, a personalized language and vision assistant, can engage in conversations about a novel subject given only a few images of that subject. The left side demonstrates a textual conversation where the user asks about buying a gift for their dog and Yo’LLaVA provides relevant suggestions. The right side shows a visual conversation where the user asks if their dog is in a photo, and Yo’LLaVA correctly identifies and describes the dog’s presence in the image. These examples highlight Yo’LLaVA’s ability to learn and utilize personalized information about a specific subject, unlike generic LMMs that only handle general concepts.

This figure illustrates the core functionality of Yo’LLaVA. Given a small set of images of a new subject (in this case, a dog named
), the system learns to understand and respond to both text-based and image-based questions about that subject. The example shows how Yo’LLaVA can answer questions about the dog’s appearance, activities, and even suggest birthday gifts, demonstrating its ability to personalize conversations beyond generic knowledge.

This figure demonstrates Yo’LLaVA’s ability to personalize conversations using only a few images of a novel subject. It shows examples of both text and visual conversations, highlighting how Yo’LLaVA is able to answer questions and engage in conversations about the specific subject, which is a dog in this case, far beyond the capabilities of standard LLMs. The figure showcases the personalization of the LLM with regards to a specific subject and contrasts it with the generic approach of existing LLMs.

This figure shows examples of how Yo’LLaVA, a personalized language and vision assistant, can engage in both textual and visual conversations about a specific subject given only a few images of that subject. The left side shows personalized text conversations where the model responds appropriately to questions about a dog’s birthday gift, demonstrating an understanding of the dog’s identity and characteristics. The right side illustrates personalized visual conversations where the model correctly identifies the subject in an image and answers questions about its actions and appearance. This illustrates Yo’LLaVA’s ability to handle personalized subjects compared to generic LLM models.

This figure demonstrates the personalization capabilities of Yo’LLaVA. Given only a small number of images of a new subject (in this case, a dog), Yo’LLaVA can engage in both text-based and visual conversations about that subject. The examples show how Yo’LLaVA correctly identifies the subject in images and answers questions related to the subject’s appearance, activities, and other attributes, going beyond the capabilities of generic large multimodal models.

This figure demonstrates the core functionality of Yo’LLaVA. Given only a small number of images of a novel subject (in this case, a dog), Yo’LLaVA is able to personalize its responses to questions about the subject. The figure shows examples of both text-based conversations and image-based conversations, highlighting the model’s ability to understand and respond appropriately in both modalities.

This figure illustrates the personalization capability of Yo’LLaVA. Given only a small number of images of a new subject (in this case, a dog), the model is able to understand and engage in both text-based and image-based conversations about that specific subject. This demonstrates a move beyond the generic knowledge found in standard Large Multimodal Models (LMMs) toward a personalized understanding of individual entities. The example shows that Yo’LLaVA can answer questions about the dog’s birthday gift ideas or whether the dog is present in a given image, demonstrating its enhanced understanding and personalized response capability.

This figure shows examples of how Yo’LLaVA, a personalized language and vision assistant, can engage in conversations about a specific subject using only a few images of that subject. It highlights the personalization aspect by contrasting Yo’LLaVA’s responses to those of a generic LLM (LLaVA) on questions related to the subject. Yo’LLaVA accurately identifies the subject in images and answers questions about the subject’s characteristics and activities, demonstrating its capacity to go beyond generic knowledge.

This figure demonstrates Yo’LLaVA’s ability to conduct personalized conversations using both text and images. Given only a small number of images of a specific subject (in this case, a dog), Yo’LLaVA learns to recognize that subject in new images and answer questions about it. The top half shows text-based conversation examples, where the model successfully answers questions about the dog’s birthday gift. The bottom half shows image-based conversation examples, where the model successfully identifies the dog within a picture.

This figure shows an overview of Yo’LLaVA’s capabilities. Given only a few images of a novel subject (in this case, a dog), Yo’LLaVA can engage in both text-based and visual conversations about that subject. The text-based conversation demonstrates Yo’LLaVA’s ability to provide personalized recommendations (e.g., suggesting a birthday gift for the dog). The visual conversation showcases Yo’LLaVA’s capacity to identify and provide details about the subject within an image.

This figure illustrates the core concept of Yo’LLaVA. Using only a few images of a new subject (in this case, a dog named
), Yo’LLaVA learns to engage in both text-based and image-based conversations about that specific subject. The figure shows examples of personalized text conversations (e.g., recommending a birthday gift for ), and personalized visual conversations (e.g., identifying in a photograph). This demonstrates Yo’LLaVA’s ability to move beyond generic knowledge and understand and interact with user-specific concepts.
More on tables

This table compares the performance of YoLLaVA and MyVLM on a visual recognition task. It shows that YoLLaVA achieves higher accuracy and recall than MyVLM, while not requiring external recognition modules. The comparison uses the same experimental setup as described in MyVLM’s paper ([34]). The table highlights the advantages of YoLLaVA’s integrated approach.

This table shows the results of an ablation study on the dataset creation process for the Yo’LLaVA model. The study evaluates the model’s ability to answer detailed descriptive questions about a subject. It shows the impact of different training data components (recognition data, conversation data, and retrieval negative examples) on the model’s performance. The qualitative example demonstrates how the fully trained model answers a detailed question about the subject.

This table presents the results of an ablation study evaluating catastrophic forgetting in Yo’LLaVA, a personalized large multimodal model. The study compares the performance of Yo’LLaVA against the original LLaVA model across three benchmarks: POPE, MMBench, and LLaVA-Wild. The results demonstrate that Yo’LLaVA maintains nearly identical performance to the original LLaVA model, indicating that the model retains its pre-trained knowledge effectively while learning personalized information. Despite nearly identical performance, Yo’LLaVA offers the capability to perform personalized conversations, demonstrating its efficacy in this new task.

This table compares the performance of Yo’LLaVA against two baselines (LLaVA and GPT-4V) across two tasks: recognition and question answering. It shows the accuracy results for each model and prompt type (human-written, LLaVA-generated, and GPT-4V-generated) in both positive and negative image recognition. It also presents question answering accuracy for visual and text conversations, highlighting Yo’LLaVA’s superiority in both tasks, particularly with fewer tokens.

This table compares the performance of Yo’LLaVA against two baselines: Vanilla LLaVA and LLaVA with human-written or automatically generated descriptions. It evaluates performance on two tasks: recognition accuracy (identifying the personalized subject in images) and question answering (answering questions about the subject in visual and text-only settings). The table shows that Yo’LLaVA significantly outperforms the baselines, demonstrating its effectiveness in personalizing LLMs. Additionally, it includes results for GPT-4V using both textual and image prompts, showing that Yo’LLaVA’s performance is competitive even compared to a more powerful and resource-intensive model.

This table compares the performance of Yo’LLaVA against two baselines: Vanilla LLaVA and LLaVA with human-written descriptions. It also includes results using GPT-4V with both text and image prompting. The table presents recognition accuracy (positive, negative, and weighted average) and question answering accuracy (visual and text) for different methods. The number of tokens used in each method is also indicated, highlighting the efficiency of Yo’LLaVA in achieving high accuracy with fewer tokens compared to other methods.

This table lists 30 example questions and their corresponding answers used for the positive recognition task in the training dataset. The questions all focus on whether a specific subject is present in an image. This helps the model to learn to accurately identify the presence of the target subject, rather than just making guesses.

This table provides 30 example questions and their corresponding answers for negative recognition tasks. These examples demonstrate the model’s ability to correctly identify when a subject is NOT present in an image. The questions are phrased in various ways to test the robustness of the model’s understanding and to avoid biases. Each question has a ‘No’, indicating that the specified subject is not in the picture.

This table presents personalized descriptions of various subjects generated by GPT-4V. These descriptions are used as input prompts to personalize the LLM (Large Language Model) in the Yo’LLaVA framework. Each subject is given a detailed textual description intended to capture its visual characteristics for the model’s training and recognition purposes.
This table compares the performance of Yo’LLaVA against two baselines: Vanilla LLaVA and LLaVA with human-written or automatically generated descriptions. It evaluates performance on two tasks: recognition accuracy (identifying a personalized subject in an image) and question answering (both visual and text-based). The table shows that Yo’LLaVA significantly outperforms both baselines, especially in recognition, demonstrating the efficacy of its learnable prompt approach in encoding personalized visual knowledge.
Full paper#



















