↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing 3D Gaussian splatting methods struggle with generalization and free-view synthesis due to their complex backbones and limitations in accurately localizing 3D Gaussians, especially from long image sequences. They are often confined to narrow-range interpolations between stereo images, lacking the ability to accurately reconstruct global 3D scenes and support free-view synthesis across a wider view range. This restricts their use in real-world applications with long-sequence input.
FreeSplat tackles these issues by introducing novel techniques for efficient feature aggregation across multiple views and reducing 3D Gaussian redundancy. It uses a Low-cost Cross-View Aggregation method that constructs adaptive cost volumes, along with Pixel-wise Triplet Fusion to eliminate redundant Gaussians. A novel free-view training strategy further enhances robustness and effectiveness. Experimental results demonstrate significant improvements in novel view synthesis performance compared to previous methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FreeSplat, a novel framework that significantly improves the generalization ability and efficiency of 3D Gaussian splatting for free-view synthesis of indoor scenes. This addresses a key limitation of existing methods and opens new avenues for research in efficient and robust 3D scene reconstruction from sparse input views. The proposed approach is highly relevant to current trends in view synthesis and has the potential to impact applications such as augmented reality, virtual reality, and robotics.
Visual Insights#

This figure compares the performance of FreeSplat against two existing methods, pixelSplat and MVSplat, in reconstructing 3D scenes from multiple views. It highlights that pixelSplat and MVSplat struggle to create consistent 3D Gaussian representations, especially when dealing with longer sequences of images. In contrast, FreeSplat accurately localizes the 3D Gaussians and enables free-view synthesis. The figure shows input reference views, the depth predictions, the resulting 3D Gaussian splatting, and the rendered novel views for each method. The red boxes highlight specific regions to visually compare the results.
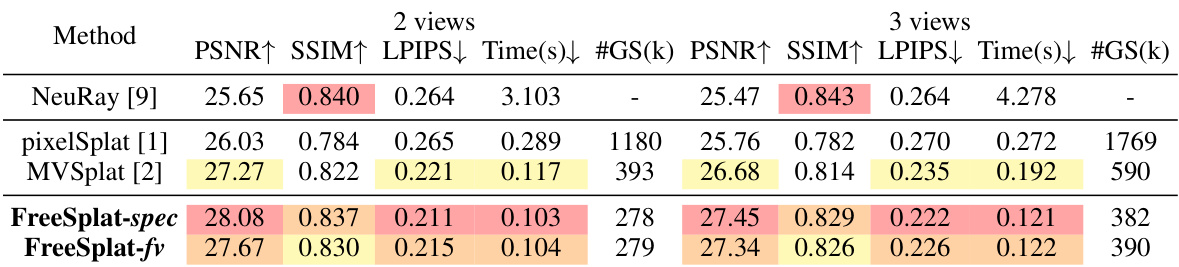
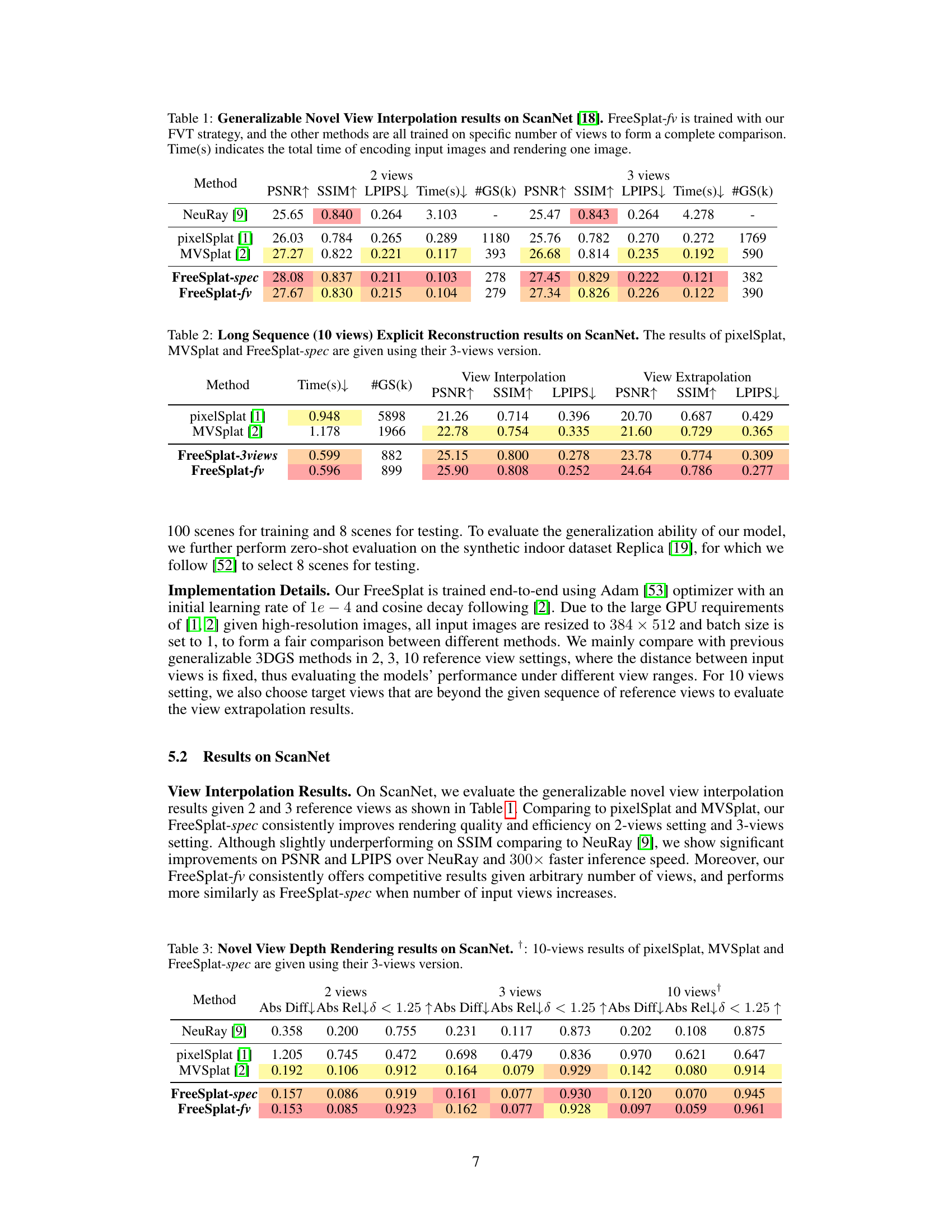
This table compares the performance of FreeSplat with other generalizable novel view synthesis methods on the ScanNet dataset for novel view interpolation tasks. It shows the PSNR, SSIM, LPIPS, rendering time, and number of Gaussian primitives (#GS) for both 2-view and 3-view settings. FreeSplat-spec represents FreeSplat trained on a specific number of views, while FreeSplat-fv uses the Free-View Training (FVT) strategy.
In-depth insights#
3D Gaussian Splatting#
3D Gaussian splatting is a novel technique for representing 3D scenes using a collection of 3D Gaussian primitives. Each Gaussian is characterized by its mean (position), covariance (shape and size), and color. This explicit representation offers several advantages over implicit methods like Neural Radiance Fields (NeRFs). It avoids the computationally expensive ray-marching process inherent to NeRFs, leading to significantly faster rendering times, making real-time applications feasible. The Gaussian splatting technique excels at representing surfaces with fine details and textured regions, as the Gaussians can be densely packed in these areas, while sparsely populating uniform or less-detailed regions. This adaptive density control results in efficient memory usage. Although vanilla Gaussian splatting methods often require per-scene optimization, recent research has focused on developing generalizable approaches capable of handling various scenes without scene-specific training. However, limitations remain, especially concerning accurate localization of Gaussians from long input sequences and robust free-view synthesis across a wide range of viewpoints. Active research aims to address these challenges, improving the efficiency, accuracy, and generalizability of 3D Gaussian splatting for broader applications in 3D scene reconstruction and novel view synthesis.
FreeSplat Framework#
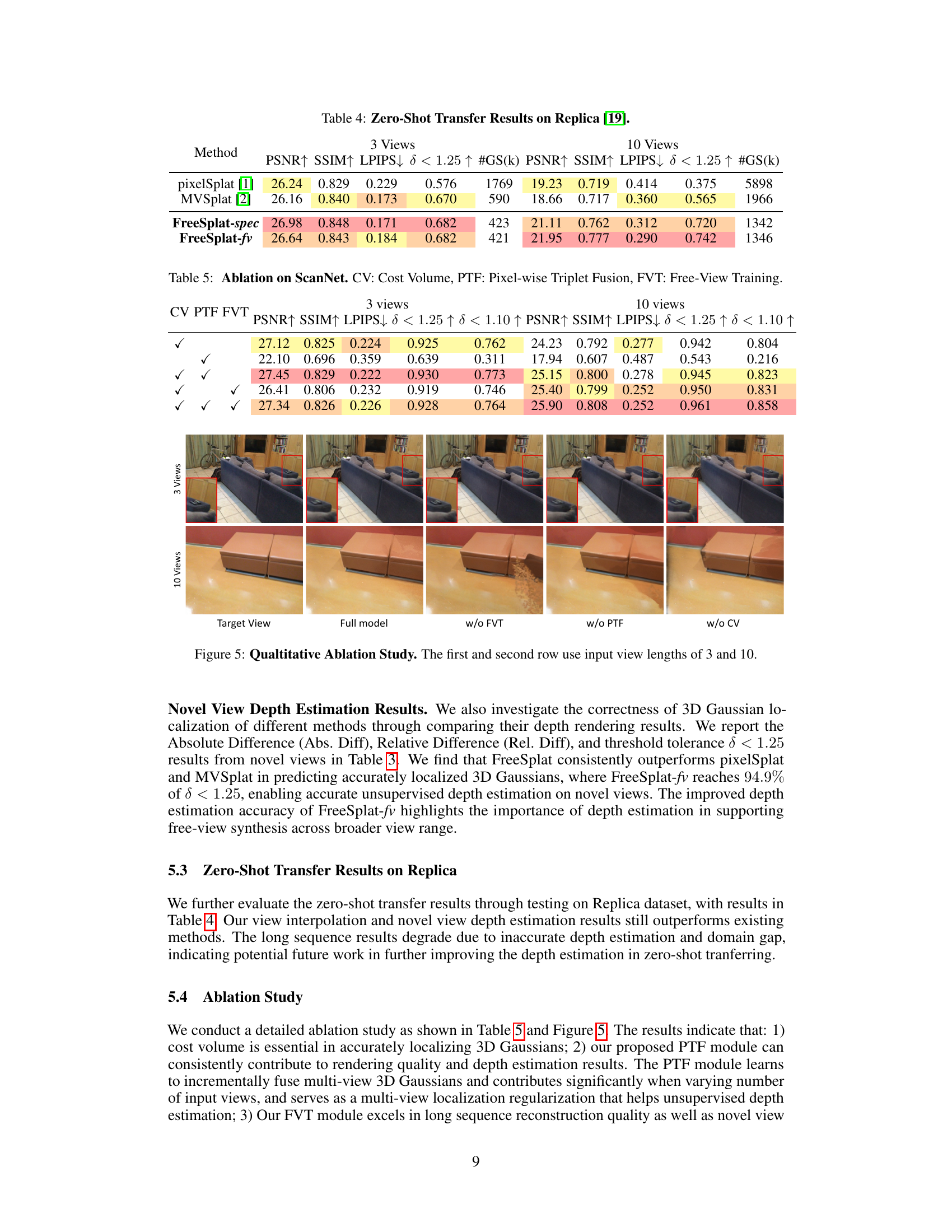
The FreeSplat framework is a novel approach for generalizable 3D Gaussian splatting targeting free-view synthesis of indoor scenes. It addresses limitations of previous methods by enabling accurate 3D Gaussian localization from long image sequences and effectively handling wide view ranges. Low-cost cross-view aggregation and pixel-wise triplet fusion are key components, optimizing feature extraction and 3D Gaussian fusion. The framework’s efficiency allows for free-view training, enhancing its robustness. This results in state-of-the-art novel view synthesis quality, particularly in color map and depth map accuracy. A key strength is its ability to effectively reduce redundant Gaussians, leading to efficient inference and the potential for real-time large-scale scene reconstruction without depth priors.
Cross-View Fusion#
Cross-view fusion in 3D scene reconstruction aims to combine information from multiple viewpoints to create a more complete and accurate representation. Effective fusion strategies are crucial because individual views often suffer from occlusions, noise, and limited field of view. A successful approach must address several key challenges: robust feature matching across views, despite variations in viewpoint and lighting; efficient aggregation of multi-view features, to avoid redundancy and computational complexity; and handling inconsistencies between views, such as discrepancies in depth or geometry. Different techniques, like cost volume methods or neural networks, are employed, each with trade-offs in accuracy, efficiency, and robustness. The choice of fusion method significantly impacts the final 3D model’s quality and completeness. Key considerations include the type of features used (e.g., raw pixels, deep features), the fusion strategy (e.g., summation, weighted averaging, learned fusion), and the handling of occlusions. Ultimately, the effectiveness of cross-view fusion determines the accuracy and fidelity of the reconstructed 3D scene.
Free-View Training#
Free-View Training (FVT) is a novel training strategy designed to enhance the generalizability of 3D Gaussian Splatting (3DGS) models. Standard 3DGS methods often struggle with scenes containing a wide range of viewpoints, as they usually rely on narrow-range interpolation. FVT addresses this limitation by training the model on long sequences of input views, thus encouraging it to learn more robust and consistent 3D Gaussian representations that work even beyond the views presented during training. This broader training approach results in superior novel view synthesis capabilities and increased depth estimation accuracy. The strategy effectively disentangles the generalizable aspects of the 3DGS representation from the specific viewpoints of the input sequence, leading to improved generalization and less reliance on a dense set of views. By exposing the model to more diverse viewing angles and contexts, FVT enables the generation of high-quality images and depth maps from novel viewpoints, significantly surpassing the capabilities of traditional 3DGS training methods.
Limitations & Future#
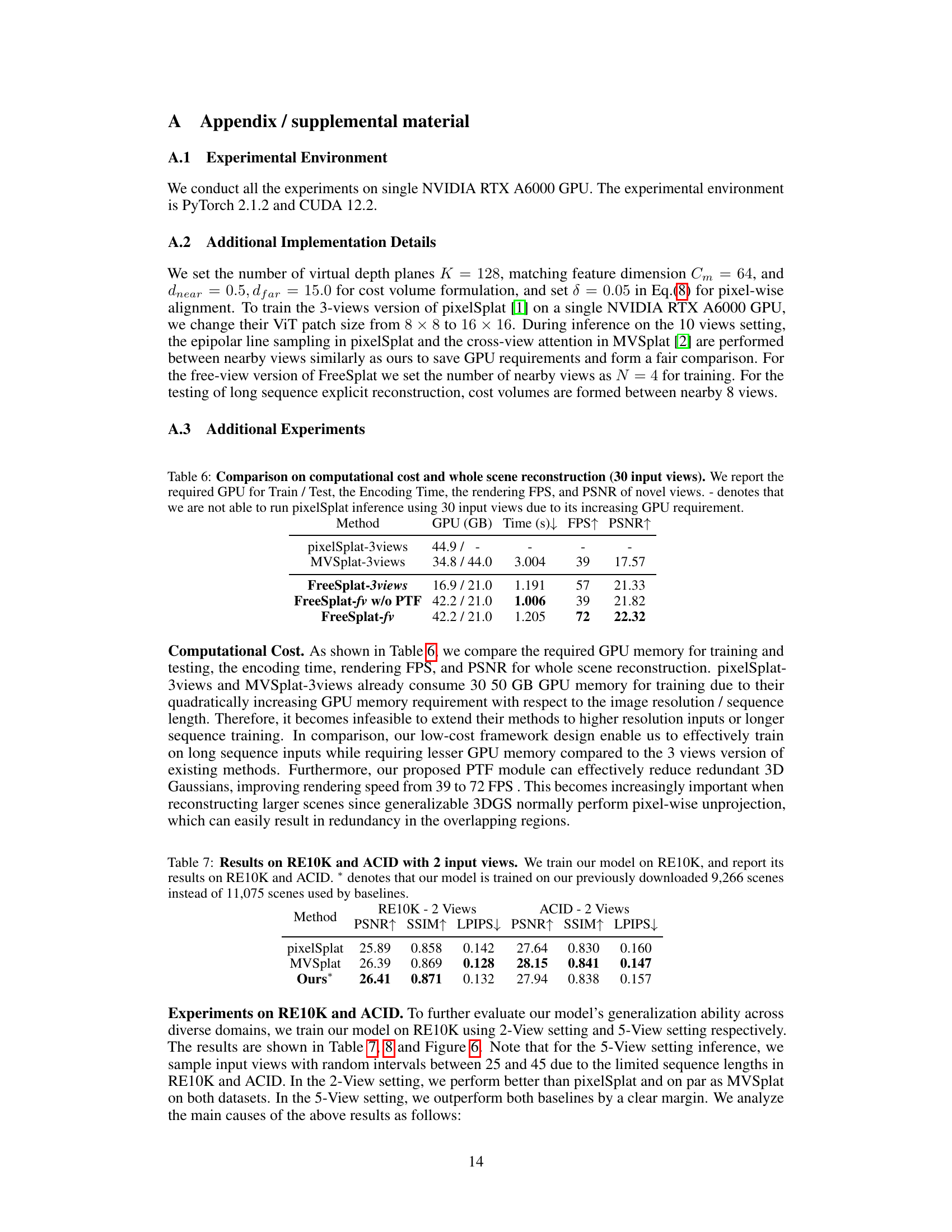
The research paper’s limitations section should thoroughly address the computational cost associated with processing long image sequences, especially concerning GPU memory constraints. It should also acknowledge the inaccuracy in depth estimation for textureless and specular regions, potentially impacting the overall reconstruction quality. Future work could explore techniques to mitigate the computational burden and improve depth prediction accuracy, perhaps through more efficient feature extraction or advanced depth estimation methods. Furthermore, exploring the generalizability of the model to scenes beyond the dataset it was trained on is crucial. This could involve testing on diverse datasets and addressing potential domain adaptation issues. Finally, investigating the effects of input sequence length on overall performance and exploring the applicability of the model to real-time applications would be valuable future directions.
More visual insights#
More on figures
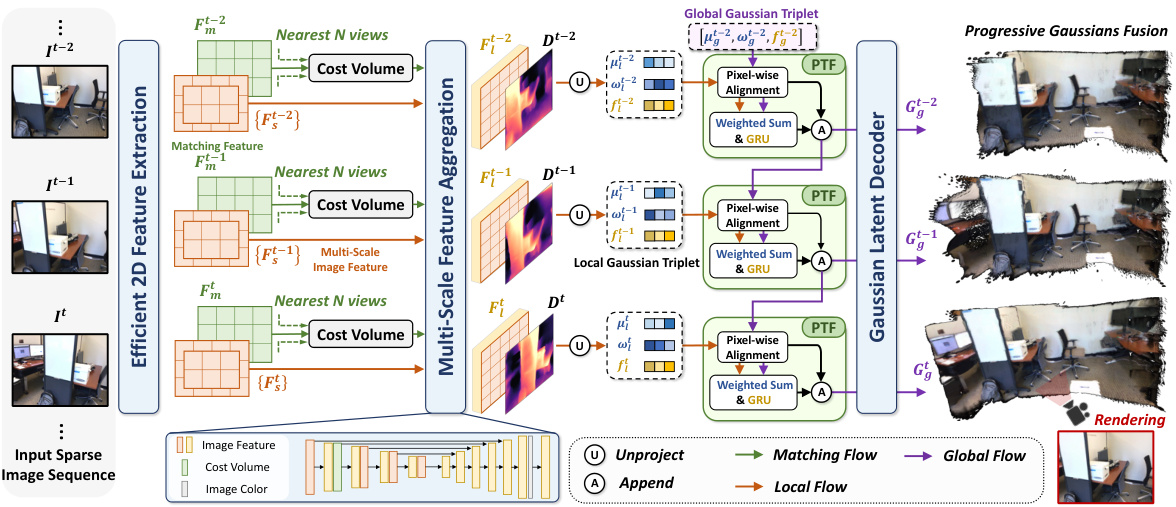
This figure illustrates the framework of FreeSplat. It begins with an input sparse sequence of RGB images. These images are processed to construct cost volumes between nearby views, generating depth maps and feature maps. These are then unprojected to create 3D Gaussian triplets with 3D position information. The Pixel-aligned Triplet Fusion (PTF) module progressively aggregates and updates these local and global triplets using pixel-wise alignment. Finally, these global Gaussian triplets are decoded into Gaussian parameters, which can then be used for rendering.

This figure illustrates the Pixel-wise Triplet Fusion (PTF) module. The left side shows the pixel-wise alignment step: global Gaussians are projected onto the current view and compared to local Gaussians. Only nearby Gaussians (within a threshold) are selected for fusion. The right side depicts the Gaussian latent fusion: geometrically weighted sums and a GRU network fuse these selected local and global Gaussian triplets.

This figure displays qualitative results of long sequence explicit reconstruction using the FreeSplat method. Each sequence shows two view interpolation results (top two rows) and two view extrapolation results (bottom two rows), demonstrating the model’s ability to reconstruct consistent 3D scenes from long sequences of input images and generate novel views both within and beyond the input range. The comparison visually highlights FreeSplat’s superior performance in accurately localizing 3D Gaussians and maintaining fine-grained details compared to existing methods. The results emphasize the method’s robustness and accuracy in handling longer image sequences and more challenging camera trajectories.

This figure illustrates the FreeSplat framework. It begins by taking a sparse sequence of RGB images as input. Cost volumes are created between nearby views, and depth and feature maps are predicted. These maps are then unprojected into 3D Gaussian triplets. A Pixel-aligned Triplet Fusion (PTF) module is then used to progressively aggregate and update these triplets, resulting in a set of global Gaussian triplets. Finally, these triplets are decoded into Gaussian parameters for rendering.

This figure shows qualitative results of long sequence explicit reconstruction. It demonstrates FreeSplat’s ability to generate novel views from long sequences of input images. The top two rows for each scene represent view interpolation (generating views within the range of the input views). The bottom two rows show view extrapolation (generating views outside the range of the input views). The results are compared to those of MVSplat and pixelSplat, highlighting FreeSplat’s superior performance in terms of image quality and accurate depth estimation.

This figure compares the results of FreeSplat-fv and SurfelNeRF on the same test sequences. It visually demonstrates the superior rendering quality and efficiency of FreeSplat-fv compared to SurfelNeRF. FreeSplat-fv produces sharper, more detailed images with better reconstruction of fine-grained details, while SurfelNeRF shows blurry, less detailed reconstructions.

This figure shows a qualitative comparison of the proposed FreeSplat method against the baselines, pixelSplat and MVSplat. The top row displays rendered color images, and the bottom row shows corresponding depth maps. The results are shown for both 2-view and 3-view input scenarios, demonstrating the ability of FreeSplat to generate more accurate and detailed results compared to the baselines, particularly in terms of depth estimation.

This figure displays qualitative results for long-sequence explicit reconstruction using FreeSplat. Each sequence is shown across four rows. The first two rows demonstrate view interpolation results—reconstructing views between existing input views in the sequence. The final two rows illustrate view extrapolation results, showcasing the reconstruction of views beyond the provided input sequence. Visual comparisons are made between the reference image, FreeSplat’s results, and results from MVSplat and pixelSplat methods. The image pairs show both rendered color and depth maps to give a comprehensive qualitative comparison of the methods’ performance for long sequences.

This figure shows a qualitative comparison of the results of whole scene reconstruction. The leftmost column displays the 3D Gaussian distribution learned by the FreeSplat model. The central column displays the rendered images (color and depth) produced by the FreeSplat model. The rightmost column shows the corresponding target views for comparison. The results demonstrate the model’s ability to perform whole-scene reconstruction and render high-quality images from novel viewpoints.
More on tables

This table presents the results of reconstructing 3D scenes from long sequences (10 views) of images using different methods, including pixelSplat, MVSplat, and FreeSplat. It compares the performance in terms of time taken for processing, the number of Gaussian primitives used, and the quality of the reconstructed views in terms of PSNR, SSIM, and LPIPS, both for view interpolation and extrapolation. The results for pixelSplat and MVSplat are based on their 3-view versions for fair comparison.
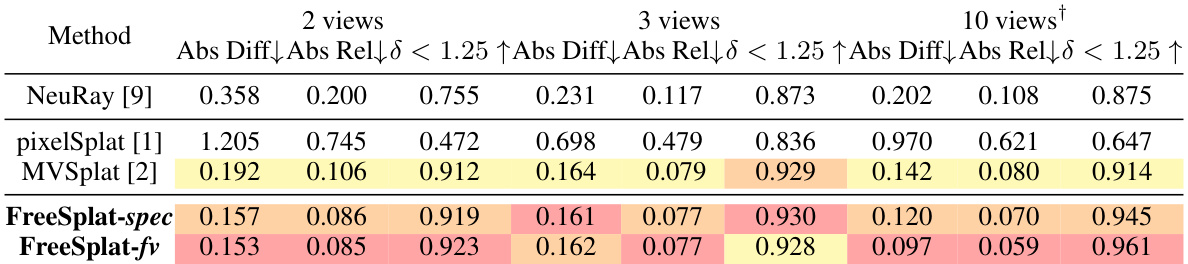
This table presents a comparison of novel view depth rendering results on the ScanNet dataset for different methods (NeuRay, pixelSplat, MVSplat, FreeSplat-spec, and FreeSplat-fv) and varying numbers of input views (2, 3, and 10). The metrics used to evaluate performance are Absolute Difference (Abs Diff), Absolute Relative Difference (Abs Rel), and the percentage of points with depth error less than 1.25 (δ < 1.25). The results show FreeSplat-fv consistently outperforms other methods in depth accuracy, particularly with 10 views.

This table compares the performance of FreeSplat with other generalizable novel view synthesis methods on the ScanNet dataset. The comparison is done for scenarios with 2 and 3 input views. Metrics include PSNR, SSIM, LPIPS, rendering time, and the number of Gaussians used. FreeSplat-fv denotes the version trained with the Free-View Training strategy, showing its ability to generalize across different numbers of input views.
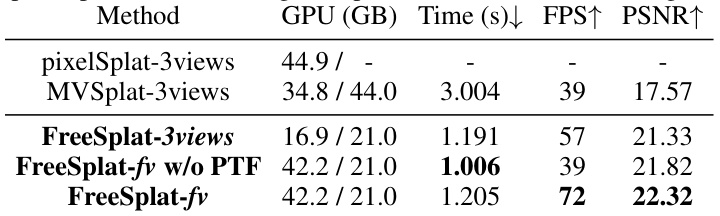
This table compares the computational cost and performance of different methods for whole scene reconstruction using 30 input views. It shows the GPU memory required for training and testing, encoding time, rendering FPS (frames per second), and PSNR (peak signal-to-noise ratio) for novel views. Note that pixelSplat could not be run with 30 views due to high GPU memory requirements.
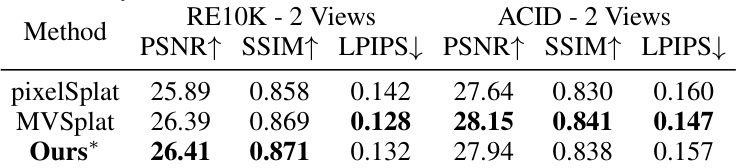
This table presents a comparison of the performance of different methods on the RE10K and ACID datasets using only 2 input views. The PSNR, SSIM, and LPIPS metrics are used to evaluate the quality of novel view synthesis. The asterisk (*) indicates that the authors’ model was trained on a slightly smaller subset of the RE10K dataset (9,266 scenes) compared to the baselines (11,075 scenes).
Full paper#