TL;DR#
Indoor radar perception, while beneficial for privacy and reliability in challenging conditions, suffers from limitations in existing pipelines, which often fail to exploit the unique characteristics of multi-view radar data. These pipelines often rely on hand-crafted components for object detection and segmentation, limiting their accuracy and efficiency.
The proposed Radar dEtection TRansformer (RETR) addresses these issues by extending the DETR architecture. RETR leverages carefully designed modifications, including depth-prioritized feature similarity, a tri-plane loss function, and learnable radar-to-camera transformations. Evaluated on two indoor datasets, RETR demonstrates significant improvements over state-of-the-art methods, achieving a substantial margin of improvement in both object detection and instance segmentation accuracy.
Key Takeaways#
Why does it matter?#
This paper is significant because it tackles the limitations of existing radar perception pipelines for indoor environments. By proposing RETR, a novel multi-view radar detection transformer, it offers a significant performance boost in object detection and segmentation, paving the way for more reliable and efficient indoor perception systems. This is particularly relevant in scenarios where traditional vision-based systems fall short (low-light, adverse weather). The work also opens up new avenues for research in multi-sensor fusion and transformer-based object recognition, potentially impacting applications such as elderly care, indoor navigation, and building energy management.
Visual Insights#
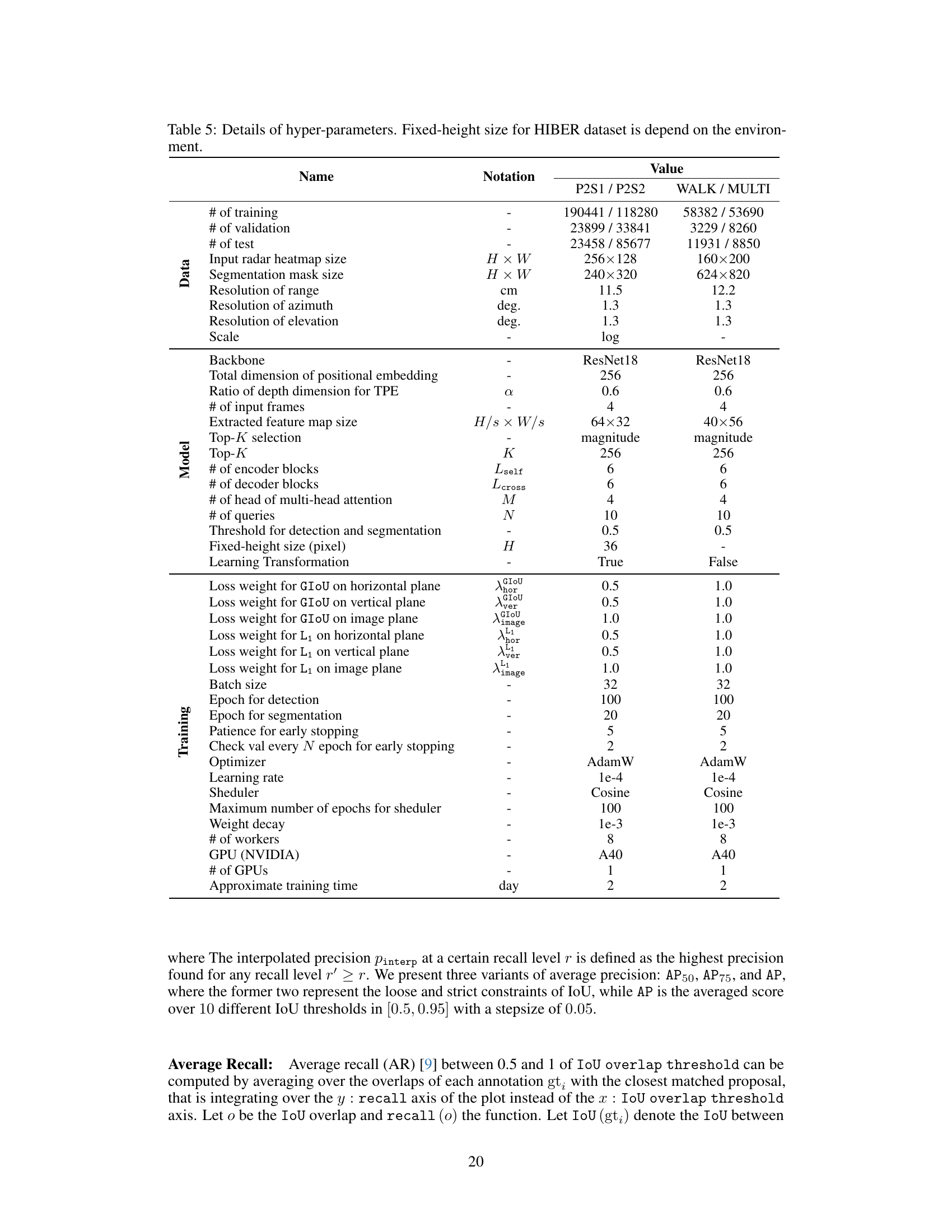
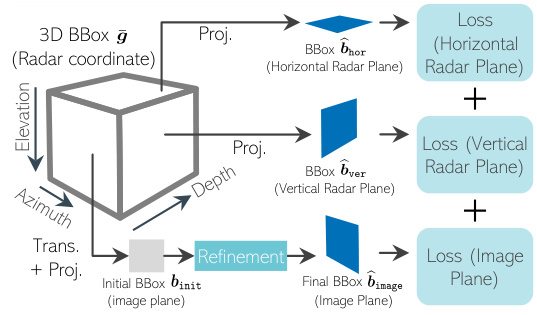
🔼 This figure illustrates the overall architecture of the RETR model. It shows how horizontal and vertical radar heatmaps are fed into the model, which then uses a depth-prioritizing positional encoding to process the data within transformer encoder-decoder modules. The output is a set of 3D-embedding object queries that enable both image-plane object detection and segmentation. This process involves a coordinate transformation between radar and camera perspectives, and finally a projection from 3D to 2D using a pinhole camera model.
read the caption
Figure 1: By taking horizontal-view and vertical-view radar heatmaps as inputs, RETR introduces a depth-prioritizing positional encoding (exploit the shared depth between the two radar views) into transformer self-attention and cross-attention modules and outputs a set of 3D-embedding object queries to support image-plane object detection and segmentation via a calibrated or learnable radar-to-camera coordinate transformation and 3D-to-2D pinhole camera projection.

🔼 This table presents a comparison of object detection performance in the image plane using the MMVR dataset’s P2S1 protocol. It compares several models: RFMask, DETR, DETR with Top-K feature selection, RETR (with TPE only in the decoder), and the full RETR model. The performance metrics shown are Average Precision (AP), AP at 50% IoU (AP50), AP at 75% IoU (AP75), Average Recall at 1 detection (AR1), and Average Recall at 10 detections (AR10). The table highlights the superior performance of the proposed RETR model compared to existing state-of-the-art methods.
read the caption
Table 1: Main results of object detection in the image plane under 'P2S1' of MMVR. The top section shows results from conventional models, while the bottom section presents RETR results.
In-depth insights#
Multi-view Radar#
The concept of “Multi-view Radar” in the context of indoor perception signifies a significant advancement in radar technology’s capabilities. The use of multiple radar views, whether horizontal and vertical or from different spatial locations, allows for a far richer and more complete understanding of the environment. This multi-perspective approach overcomes the inherent limitations of single-view radar systems, particularly concerning occlusion and the limited semantic information typically extracted from radar signals. By fusing information from these various viewpoints, a more robust and accurate 3D representation of the scene is made possible. This enhancement is crucial for accurate object detection, pose estimation, and instance segmentation tasks, which are all extremely challenging using single-view data alone. Multi-view radar addresses the ambiguity inherent in single-view radar data, resulting in a more reliable and precise indoor perception system. Furthermore, such a system presents a powerful solution for scenarios where visual sensors are limited (e.g., low-light conditions, smoke, or adverse weather), allowing the reliable acquisition of rich environmental information.
DETR Extension#
The heading ‘DETR Extension’ suggests a research paper focusing on improving or adapting the Detection Transformer (DETR) architecture. A thoughtful analysis would explore the specific modifications introduced. This likely involves enhancements to the encoder and decoder, perhaps incorporating novel attention mechanisms or positional encodings better suited to the task. The paper likely benchmarks its extended DETR model against the original DETR and other state-of-the-art methods on a relevant dataset. Key improvements might involve addressing DETR’s slower training convergence or its inherent difficulties with handling complex scenes or occlusions. The ’extension’ may be tailored for a specific application, such as object detection in challenging environments, like low-light conditions or cluttered scenes. Understanding the specific datasets and evaluation metrics would provide further insights into the overall contribution. The research may also delve into the computational cost and complexity of the enhanced architecture, showing its efficiency or discussing potential trade-offs for improved performance. Ultimately, a deep dive would assess how this DETR variant solves existing limitations and contributes new capabilities.
Tri-plane Loss#
The tri-plane loss function, a key contribution of the RETR model, represents a significant advancement in multi-view radar object detection and segmentation. Instead of relying solely on 2D projections, RETR leverages information from three coordinate systems: the horizontal radar plane, the vertical radar plane, and the 2D image plane. By calculating a loss function across all three planes, RETR effectively enforces consistency between the predicted 3D bounding boxes in radar space and their corresponding 2D projections in the image plane. This holistic approach significantly improves the accuracy of object detection and instance segmentation, leading to superior performance compared to methods relying solely on 2D information. The tri-plane loss is a powerful technique that effectively integrates the depth information inherent in multi-view radar data, thereby addressing a crucial limitation of prior radar-based perception systems. The careful design and combination of losses across these planes directly addresses the challenges of multi-view radar data fusion and significantly enhances the accuracy and robustness of object detection in complex indoor environments.
Tunable Encoding#
The concept of “Tunable Positional Encoding” presents a novel approach to enhancing feature association in multi-view radar data. Instead of fixed positional embeddings, it introduces a learnable parameter that adjusts the relative importance of depth versus angular information in the attention mechanism. This dynamic weighting allows the model to prioritize features with similar depths, even across different radar views, thereby improving the association of corresponding object features. This tunable aspect is crucial because it addresses the unique characteristics of multi-view radar data, where depth often provides a stronger cue for object correspondence than angular information alone. The tunable nature allows the model to adapt to various radar configurations and environmental conditions. By learning optimal depth-angular weighting, the network improves its ability to fuse multi-view radar information efficiently and accurately, leading to superior performance in object detection and segmentation tasks. This approach stands in contrast to traditional methods with fixed positional embeddings, demonstrating a significant advancement in the field of multi-view radar perception.
Future Work#
The ‘Future Work’ section of a radar perception research paper could explore several promising avenues. Extending RETR to handle more complex scenarios such as outdoor environments or those with significant clutter and occlusion is crucial. This would require addressing the challenges of increased noise and interference in radar signals. Improving the model’s robustness to various types of radar hardware and signal processing techniques is another key area; current performance relies heavily on the specific type of radar used. Additionally, exploring more sophisticated 3D representation learning techniques could lead to significant improvements in object detection and segmentation accuracy, potentially using graph neural networks or more advanced attention mechanisms. Investigating the integration of RETR with other sensor modalities such as cameras and LiDAR is also warranted. This multi-sensor fusion could enhance object understanding and improve the overall system’s reliability and accuracy, especially in difficult conditions. Finally, applications to different areas such as activity recognition, anomaly detection, and scene understanding should be tested, expanding the potential impact of RETR in diverse fields. Addressing these points will move the technology significantly closer to real-world applications.
More visual insights#
More on figures

🔼 This figure illustrates the three main steps of the indoor radar perception pipeline. First, multi-view radar data is used to estimate 3D bounding boxes (BBoxes) in the radar coordinate system. Second, a transformation is applied to convert these 3D BBoxes from the radar coordinate system to the 3D camera coordinate system. Finally, these 3D BBoxes are projected onto the 2D image plane for object detection. The figure also highlights the difference between the proposed RETR method and the existing RFMask method in terms of how they handle the height of objects in the radar views.
read the caption
Figure 2: Indoor radar perception pipeline: (a) multi-radar views are utilized to estimate 3D BBoxes in the radar coordinate system; (b) the 3D BBoxes are then transformed into the 3D camera coordinate system by a radar-to-camera transformation; and (c) the transformed 3D BBoxes are projected onto the image plane for final object detection. Blue line denotes a fixed-height regional proposal in RFMask, while Magenta line denotes an object query with learnble height in RETR.
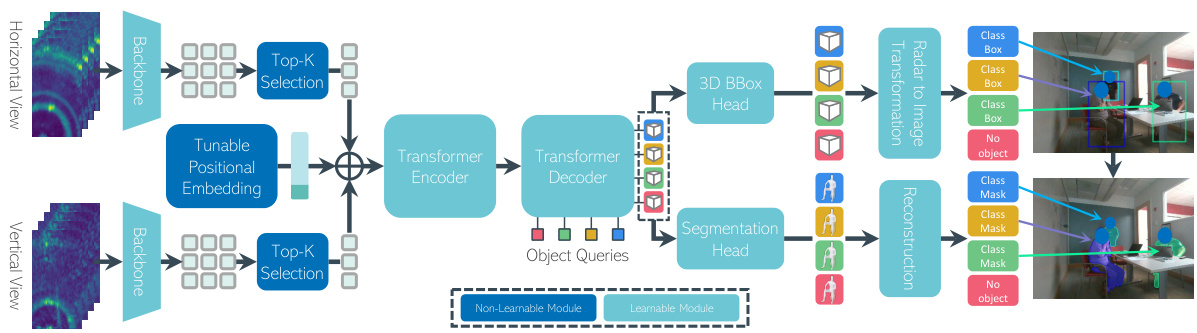
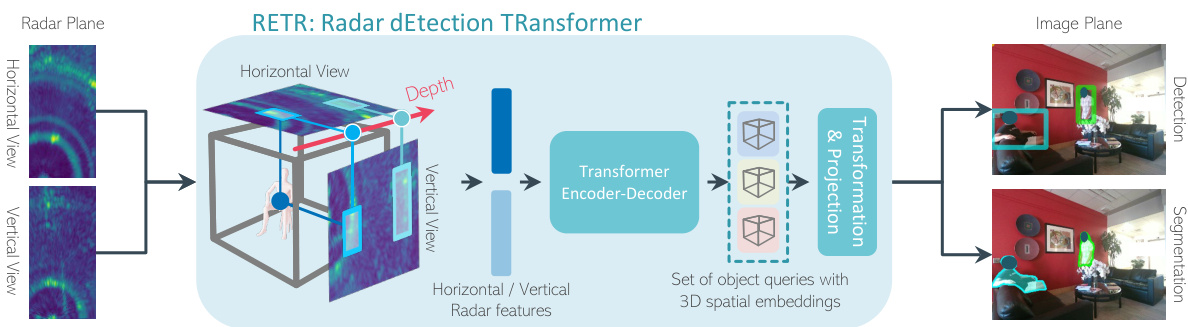
🔼 The figure shows the architecture of the proposed Radar dEtection TRansformer (RETR) model. The model consists of an encoder that processes multi-view radar data using top-K feature selection and a tunable positional embedding to improve feature association. The decoder then associates object queries with these features to predict 3D bounding boxes in the radar coordinate system. A transformation projects these 3D boxes to the image plane for object detection, while another head uses the queries to predict instance segmentation masks. The diagram illustrates the flow of data and the different modules within the RETR architecture.
read the caption
Figure 3: The RETR architecture: 1) Encoder: Top-K features selection and tunable positional encoding to assist feature association across the two radar views; 2) Decoder: TPE is also used to assist the association between object queries and multi-view radar features; 3) 3D BBox Head: Object queries are enforced to estimate 3D objects in the radar coordinate and projected to 3 planes for supervision via a coordinate transformation; 4) Segmentation Head: The same queries are used to predict binary pixels within each predicted BBox in the image plane.
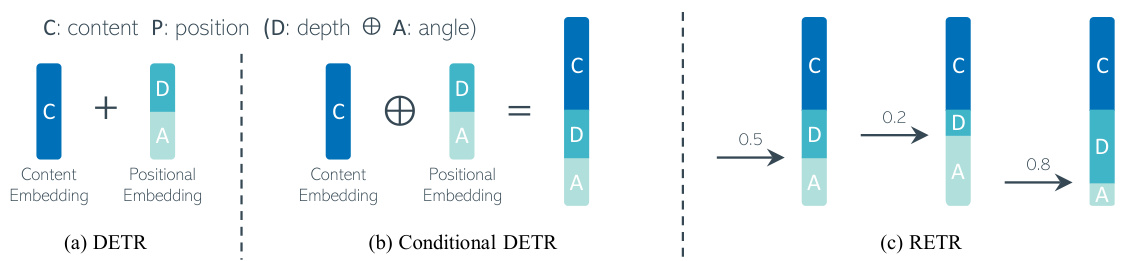
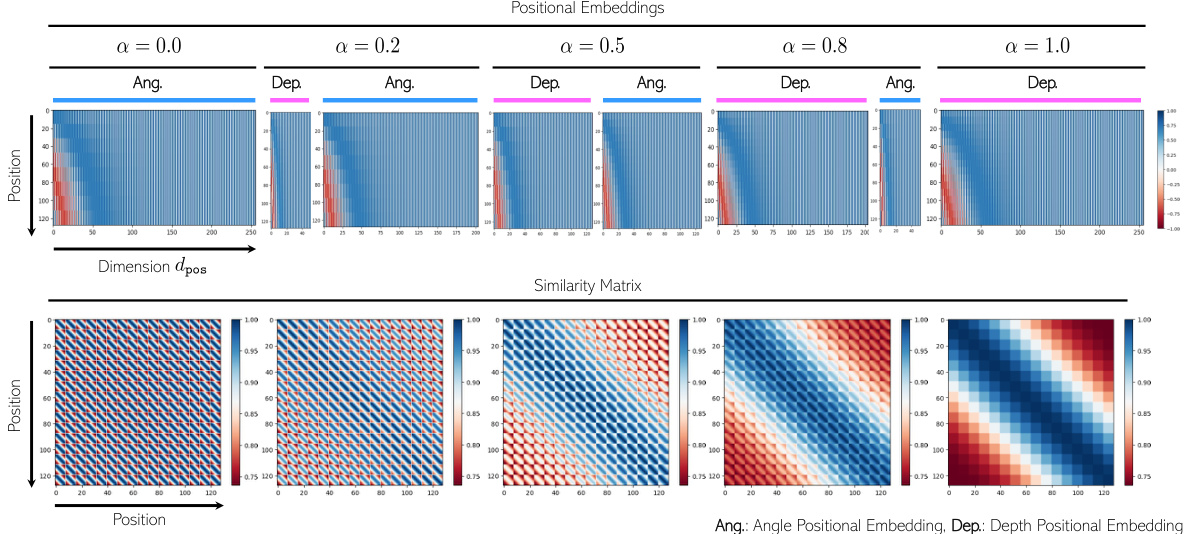
🔼 This figure illustrates different positional encoding schemes used in various transformer architectures. (a) shows the simple sum operation of DETR, (b) shows the concatenation in Conditional DETR, and (c) shows the tunable positional encoding (TPE) in RETR. TPE allows for adjusting the balance between depth and angular dimensions in positional embeddings, which helps to prioritize similarity between keys and queries that share similar depth information.
read the caption
Figure 4: Schemes of positional encoding: (a) the sum operation in the original DETR; (b) the concatenation in Conditional DETR; and (c) TPE in RETR that allows for adjustable dimensions between depth and angular embeddings and promotes higher similarity scores for keys and queries with similar depth embeddings than those far apart in depth.
🔼 This figure illustrates the three main stages of the indoor radar perception pipeline. First, multiple radar views are used to estimate 3D bounding boxes (BBoxes) in the radar coordinate system. These 3D BBoxes are then transformed into the 3D camera coordinate system using a radar-to-camera transformation (calibrated or learned). Finally, these transformed 3D BBoxes are projected onto the 2D image plane for object detection, completing the perception pipeline. The figure also highlights the difference between the proposed RETR method (magenta line) and the existing RFMask method (blue line) in terms of how they handle height estimation in the bounding boxes.
read the caption
Figure 2: Indoor radar perception pipeline: (a) multi-radar views are utilized to estimate 3D BBoxes in the radar coordinate system; (b) the 3D BBoxes are then transformed into the 3D camera coordinate system by a radar-to-camera transformation; and (c) the transformed 3D BBoxes are projected onto the image plane for final object detection. Blue line denotes a fixed-height regional proposal in RFMask, while Magenta line denotes an object query with learnble height in RETR.
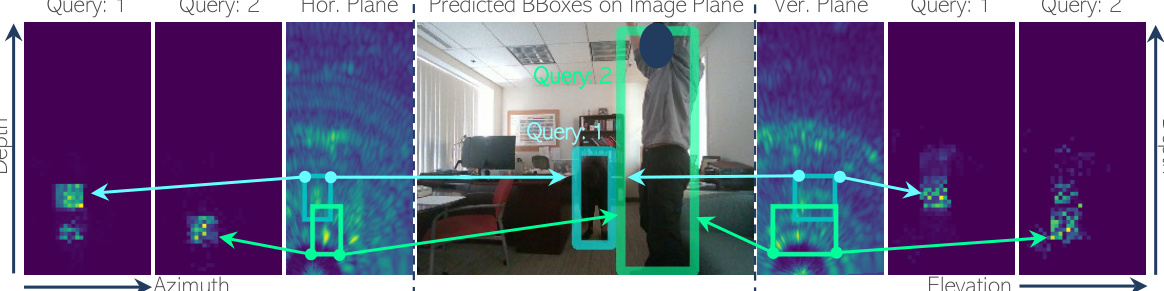
🔼 This figure visualizes the cross-attention mechanism in RETR, illustrating how predicted bounding boxes (BBoxes) are associated with features from both horizontal and vertical radar views. The image shows the cross-attention map generated during the decoder’s last layer. Each color corresponds to a unique subject, helping to understand how the model associates radar features with the respective object across different views (horizontal, vertical). The visualization is particularly effective in highlighting the depth-based feature association within the two radar planes and their projection onto the image plane.
read the caption
Figure 6: Visualization of cross-attention map between predicted BBoxes and multi-view radar features. BBoxes with the same color correspond to the same subject.

🔼 This figure illustrates the architecture of the proposed Radar dEtection TRansformer (RETR) model for multi-view radar perception. It highlights the four main components: the encoder, which processes the horizontal and vertical radar views using top-K feature selection and tunable positional encoding (TPE) for efficient feature association; the decoder, which associates object queries with multi-view radar features via cross-attention; the 3D bounding box (BBox) head, which estimates 3D object BBoxes in the radar coordinate system and projects them onto 3 planes for supervision; and the segmentation head, which predicts binary masks (segmentation) for objects detected in the image plane using the same object queries from the decoder. The learnable and non-learnable components of the model are clearly indicated.
read the caption
Figure 3: The RETR architecture: 1) Encoder: Top-K features selection and tunable positional encoding to assist feature association across the two radar views; 2) Decoder: TPE is also used to assist the association between object queries and multi-view radar features; 3) 3D BBox Head: Object queries are enforced to estimate 3D objects in the radar coordinate and projected to 3 planes for supervision via a coordinate transformation; 4) Segmentation Head: The same queries are used to predict binary pixels within each predicted BBox in the image plane.

🔼 This figure shows the architecture of the segmentation head in the RETR model. The segmentation head takes decoder embeddings as input and uses cross-attention with FPN-style CNN features to generate low-resolution attention heatmaps for each object. An FPN and light U-Net architecture further refines these masks to a higher resolution. A transformation and projection module converts bounding box predictions from the radar coordinate system to the image plane. The learnable and fixed parameter modules represent the learnable and fixed parts of the transformation respectively.
read the caption
Figure 8: Illustration of segmentation head.

🔼 This figure visualizes the segmentation results of RETR and compares them to the ground truth (GT). It shows RGB images, ground truth segmentation masks, and RETR’s segmentation results for various scenes. The results demonstrate the model’s ability to accurately segment people in different indoor settings, capturing their shapes and positions effectively, but also highlighting some instances where the model struggles with accurate segmentation.
read the caption
Figure 9: Visualization of segmentation results.
🔼 This figure illustrates the overall architecture of the Radar dEtection TRansformer (RETR) model. It shows how horizontal and vertical radar heatmaps are processed. The depth-prioritizing positional encoding is highlighted, showing how it leverages shared depth information between the two views to improve feature association within the transformer modules. The process culminates in the generation of 3D object queries that are then used for image-plane object detection and segmentation. A crucial step involves transforming radar coordinates to camera coordinates, followed by 3D-to-2D projection to obtain final results in the image plane.
read the caption
Figure 1: By taking horizontal-view and vertical-view radar heatmaps as inputs, RETR introduces a depth-prioritizing positional encoding (exploit the shared depth between the two radar views) into transformer self-attention and cross-attention modules and outputs a set of 3D-embedding object queries to support image-plane object detection and segmentation via a calibrated or learnable radar-to-camera coordinate transformation and 3D-to-2D pinhole camera projection.
🔼 The figure illustrates the architecture of the proposed Radar dEtection TRansformer (RETR) for multi-view radar perception. It shows how horizontal and vertical radar heatmaps are processed using depth-prioritized positional encoding within transformer modules. The output is a set of 3D object queries that enable image-plane object detection and segmentation through a radar-to-camera transformation and 3D-to-2D projection.
read the caption
Figure 1: By taking horizontal-view and vertical-view radar heatmaps as inputs, RETR introduces a depth-prioritizing positional encoding (exploit the shared depth between the two radar views) into transformer self-attention and cross-attention modules and outputs a set of 3D-embedding object queries to support image-plane object detection and segmentation via a calibrated or learnable radar-to-camera coordinate transformation and 3D-to-2D pinhole camera projection.

🔼 This figure presents a visual comparison of the object detection and instance segmentation results obtained using RETR and RFMask on the MMVR dataset. Each row showcases results for a specific segment from the P2S1 test set, allowing for a direct comparison of the performance of the two methods in detecting and segmenting people within indoor scenes. The comparison highlights the strengths of RETR in accurately identifying and segmenting individuals, even in complex scenes with multiple people.
read the caption
Figure 14: Visualization and comparison between RETR and RFMask. Each row indicates the segment name used from the “P2S1” test dataset.
🔼 This figure illustrates the overall architecture of the proposed RETR model. It shows how horizontal and vertical radar heatmaps are processed. The model uses a depth-prioritized positional encoding to leverage the shared depth information between the two views, improving feature association. The transformer encoder and decoder modules process these features to produce 3D object queries that are then used to perform both object detection and segmentation in the image plane. This involves a coordinate transformation between the radar and camera coordinate systems, followed by a 3D-to-2D projection.
read the caption
Figure 1: By taking horizontal-view and vertical-view radar heatmaps as inputs, RETR introduces a depth-prioritizing positional encoding (exploit the shared depth between the two radar views) into transformer self-attention and cross-attention modules and outputs a set of 3D-embedding object queries to support image-plane object detection and segmentation via a calibrated or learnable radar-to-camera coordinate transformation and 3D-to-2D pinhole camera projection.
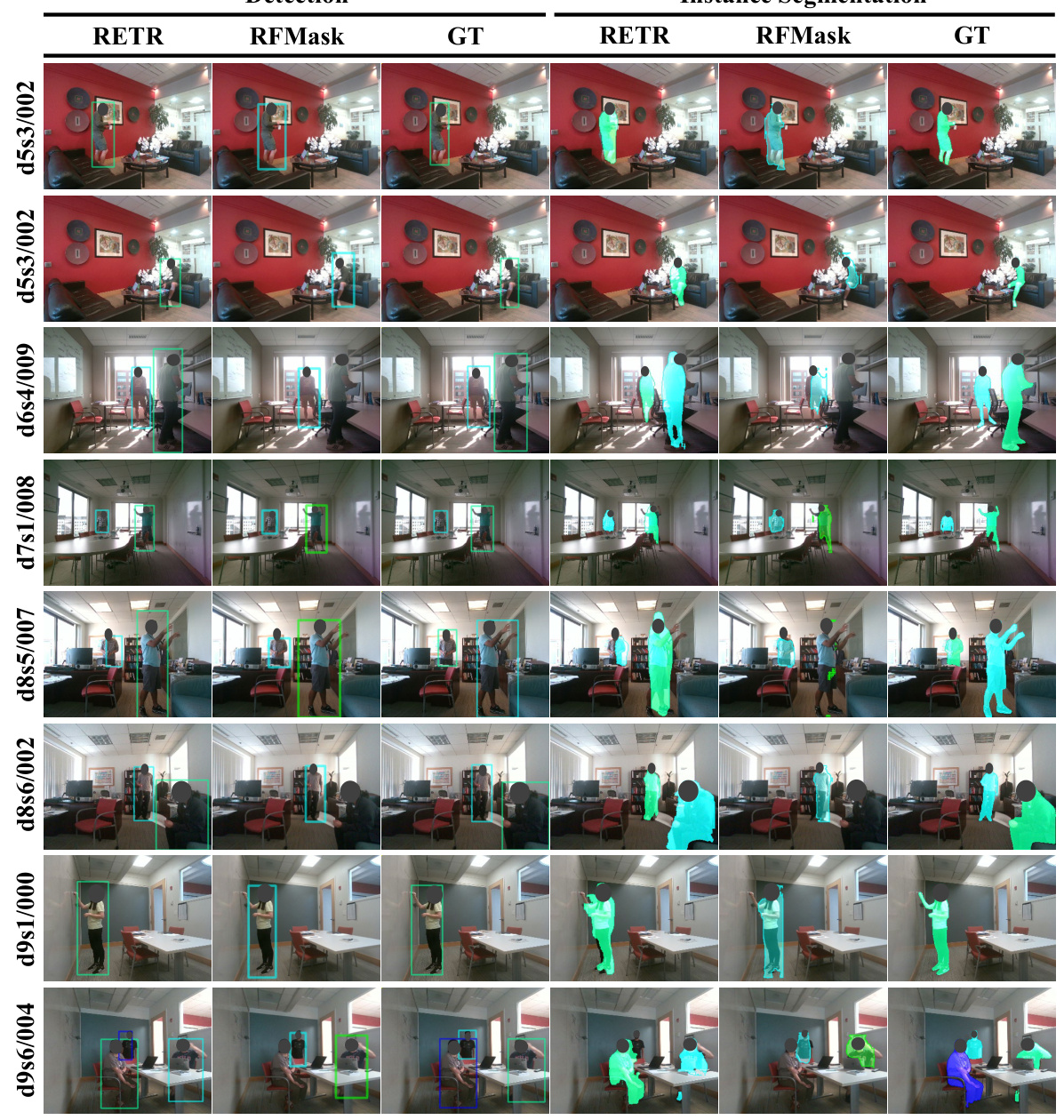
🔼 This figure provides a visual comparison of the object detection and instance segmentation results produced by RETR and RFMask on the MMVR dataset. Each row displays the results for a specific segment from the P2S1 test set, showing the RGB image, the ground truth (GT) bounding boxes and masks, and the predictions of RETR and RFMask. The comparison allows for a direct visual assessment of the performance differences between the two methods.
read the caption
Figure 14: Visualization and comparison between RETR and RFMask. Each row indicates the segment name used from the “P2S1” test dataset.

🔼 This figure shows a comparison of the object detection and instance segmentation results of RETR and RFMask on the MMVR dataset. Each row presents results for a specific data segment from the test set, illustrating the performance of each method in identifying and segmenting objects within indoor scenes. The green bounding boxes indicate ground truth annotations. The results highlight RETR’s superior ability to accurately detect and segment multiple objects, especially in challenging scenarios with multiple subjects or occlusions, where RFMask struggles.
read the caption
Figure 14: Visualization and comparison between RETR and RFMask. Each row indicates the segment name used from the “P2S1” test dataset.
More on tables

🔼 This table presents the main results of object detection in the image plane using the HIBER dataset’s ‘WALK’ subset. It compares the performance of different models (RFMask, DETR, DETR with Top-K feature selection, RETR with TPE only in the decoder, and the full RETR model) across various metrics including average precision (AP), AP at 50% IoU (AP50), AP at 75% IoU (AP75), average recall with 1 detection (AR1), and average recall with 10 detections (AR10). The input features used by each model (horizontal radar view only (H), both horizontal and vertical radar views (H, V), and the combination of radar and image views (H+I, H+V+I)) and the specific loss function employed are also indicated. The table’s format is consistent with Table 1.
read the caption
Table 2: Main results of object detection in the image plane under “WALK” of HIBER. The notation follows the same format as Table 1.

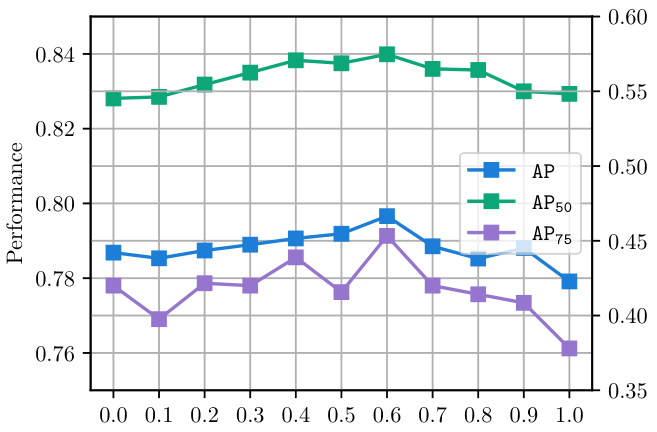
🔼 This table presents the ablation study results performed on the MMVR dataset using the P2S1 protocol. It shows the impact of different factors on the model’s performance, including the tunable dimension ratio (α) in the tunable positional encoding (TPE), the inclusion of the learnable transformation (LT), and the type of loss function used (bi-plane or tri-plane). The results are reported in terms of Average Precision (AP) and Average Recall (AR1). The highlighted cells indicate the best performing model configurations.
read the caption
Table 3: Ablation studies under 'P2S1' on MMVR.
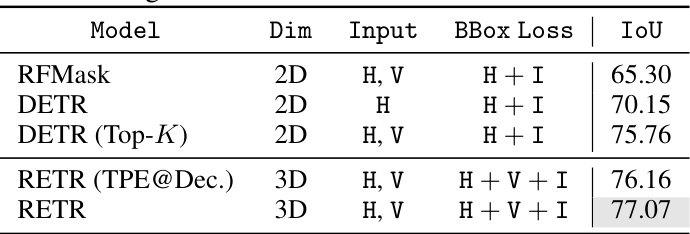
🔼 This table presents the results of instance segmentation on the MMVR dataset’s P2S1 protocol. It compares the performance of RFMask, DETR, DETR (Top-K), RETR (TPE@Dec.), and RETR, showing the IoU (Intersection over Union) achieved by each model. The table highlights the superior performance of RETR, demonstrating the effectiveness of its proposed modifications for instance segmentation.
read the caption
Table 4: Segmentation results under 'P2S1' on MMVR.
🔼 This table presents a comparison of object detection performance in the image plane using the MMVR dataset’s ‘P2S1’ protocol. It contrasts the performance of several state-of-the-art models (RFMask and DETR variants) with the proposed RETR model. Key metrics include Average Precision (AP) at different Intersection over Union (IoU) thresholds, AP50, AP75, Average Recall (AR) at 1 and 10 detections, and the type of loss function used. The table highlights RETR’s superior performance across all metrics.
read the caption
Table 1: Main results of object detection in the image plane under 'P2S1' of MMVR. The top section shows results from conventional models, while the bottom section presents RETR results.

🔼 This table presents the results of object detection experiments conducted on the HIBER dataset using the “MULTI” data split. The table compares the performance of different models (DETR, DETR with Top-K feature selection, RETR with TPE only at the decoder, and the full RETR model) across various metrics: AP, AP50, AP75, AR1, and AR10. The models are evaluated using two different dimensionality settings: 2D and 3D. The ‘Input’ column indicates whether the model uses horizontal (H), vertical (V), or both (H, V) radar views. The ‘BBox Loss’ column specifies the loss function used for bounding box regression.
read the caption
Table 6: Results under “MULTI” on HIBER dataset.

🔼 This table presents the main results of object detection in the image plane under the ‘P2S2’ protocol of the MMVR dataset. It compares the performance of different models (RFMask, DETR (Top-K), and RETR) with varying dimensionality (2D vs. 3D) and input sources (horizontal and vertical radar views). The metrics used are Average Precision (AP), AP at IoU thresholds of 0.5 and 0.75 (AP50, AP75), and Average Recall at 1 and 10 detections (AR1, AR10). This allows for a comprehensive comparison of the different model’s ability to detect objects in complex indoor environments.
read the caption
Table 7: Results under “P2S2” on MMVR dataset.

🔼 This table compares the object detection performance of RETR models with and without the learnable transformation. The results show that using a learnable transformation leads to improved performance across all metrics, including AP, AP50, AP75, AR1, and AR10, indicating its effectiveness in radar-to-camera coordinate transformation.
read the caption
Table 8: Impact of Learnable Transformation (LT) with additional precision and recall metrics.

🔼 This table presents a comparison of the object detection performance using two different BBox loss functions: one using only horizontal and image plane data (H+I) and another using horizontal, vertical, and image plane data (H+V+I). The results show that incorporating vertical radar data significantly improves the performance across all metrics (AP, AP50, AP75, AR1, AR10, and IoU). The improvement highlights the benefit of leveraging multi-view radar data in object detection.
read the caption
Table 9: Full table: Tri-plane loss can improve the performance.

🔼 This table shows the effect of varying the number of selected features (K) in the Top-K feature selection method on object detection performance. It presents the average precision (AP), along with AP at 50% and 75% IoU thresholds (AP50, AP75), and average recall (AR) at 1 and 10 detections (AR1, AR10). The results demonstrate how increasing K initially improves the performance, then plateaus, indicating a point of diminishing returns with further increases beyond a certain threshold.
read the caption
Table 10: Impact of the value of K on object detection
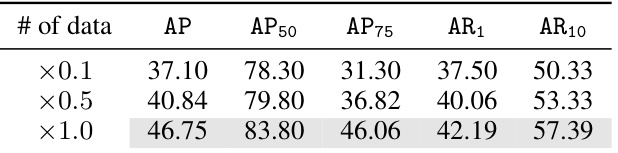
🔼 This table presents the main results of object detection experiments conducted on the MMVR dataset, specifically using the ‘P2S1’ protocol. It compares the performance of the proposed RETR model against several conventional object detection models. The table shows Average Precision (AP) and Average Recall (AR) at different IoU thresholds (AP50, AP75), along with overall AP and AR10. The results are broken down by input (horizontal only, horizontal and vertical) and loss function used in each model.
read the caption
Table 1: Main results of object detection in the image plane under 'P2S1' of MMVR. The top section shows results from conventional models, while the bottom section presents RETR results.

🔼 This table presents a quantitative comparison of the inference time and frames per second (FPS) between RFMask and RETR. It shows the time taken in milliseconds (ms) for processing each frame and the corresponding FPS. The results provide insight into the computational efficiency of each model and their suitability for real-time applications.
read the caption
Table 12: Inference time and frame rate (FPS) of RFMask and RETR.
Full paper#