TL;DR#
Large Language Models (LLMs) currently struggle with logical reasoning tasks, hindering their broader applicability in AI. This is primarily because existing training datasets lack sufficient high-quality reasoning samples. The paper addresses this critical gap by emphasizing the importance of high-quality, synthetic training data.
To tackle this, the researchers introduce a new approach called Additional Logic Training (ALT), which utilizes a newly constructed synthetic corpus called Formal Logic Deduction Diverse (FLD×2). FLD×2 is meticulously designed based on established principles of symbolic logic, ensuring that the training data reflects the true essence of logical reasoning. Experimental results demonstrate that ALT using FLD×2 substantially improves the reasoning capabilities of state-of-the-art LLMs. These improvements were observed across various benchmarks, highlighting the effectiveness of this novel training approach. The researchers also highlight the crucial role of preventing knowledge forgetting during the training process and discuss the broader implications of this method.
Key Takeaways#
Why does it matter?#
This paper is crucial because it directly tackles the critical challenge of enhancing Large Language Models’ (LLMs) reasoning capabilities, a significant limitation in current AI. The proposed method, using a novel synthetic logic corpus (FLD×2) for training, offers a significant advancement with the potential to improve various reasoning tasks, including logic, math, and coding. Its impact is further amplified by the release of the corpus, code and model, encouraging reproducibility and fostering further research in the field.
Visual Insights#

🔼 This figure displays the performance improvement achieved by incorporating Additional Logic Training (ALT) using the Formal Logic Deduction Diverse (FLD×2) corpus into the LLaMA-3.1-70B large language model. The improvements are shown across various benchmark sets categorized as Logic, Math, Code, NLI (Natural Language Inference), and Others. Each category includes several individual benchmarks (detailed in Tables 2 and 4 of the paper). The bar chart illustrates the performance gains in terms of percentage points compared to the original LLaMA model before ALT training. The results show substantial improvements across multiple domains.
read the caption
Figure 1: The performance gains to LLaMA-3.1-70B by Additional Logic Training (ALT) on the proposed synthetic corpus, FLD×2 (Formal Logic Deduction Diverse). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain. Tables 2, 4 shows the details.
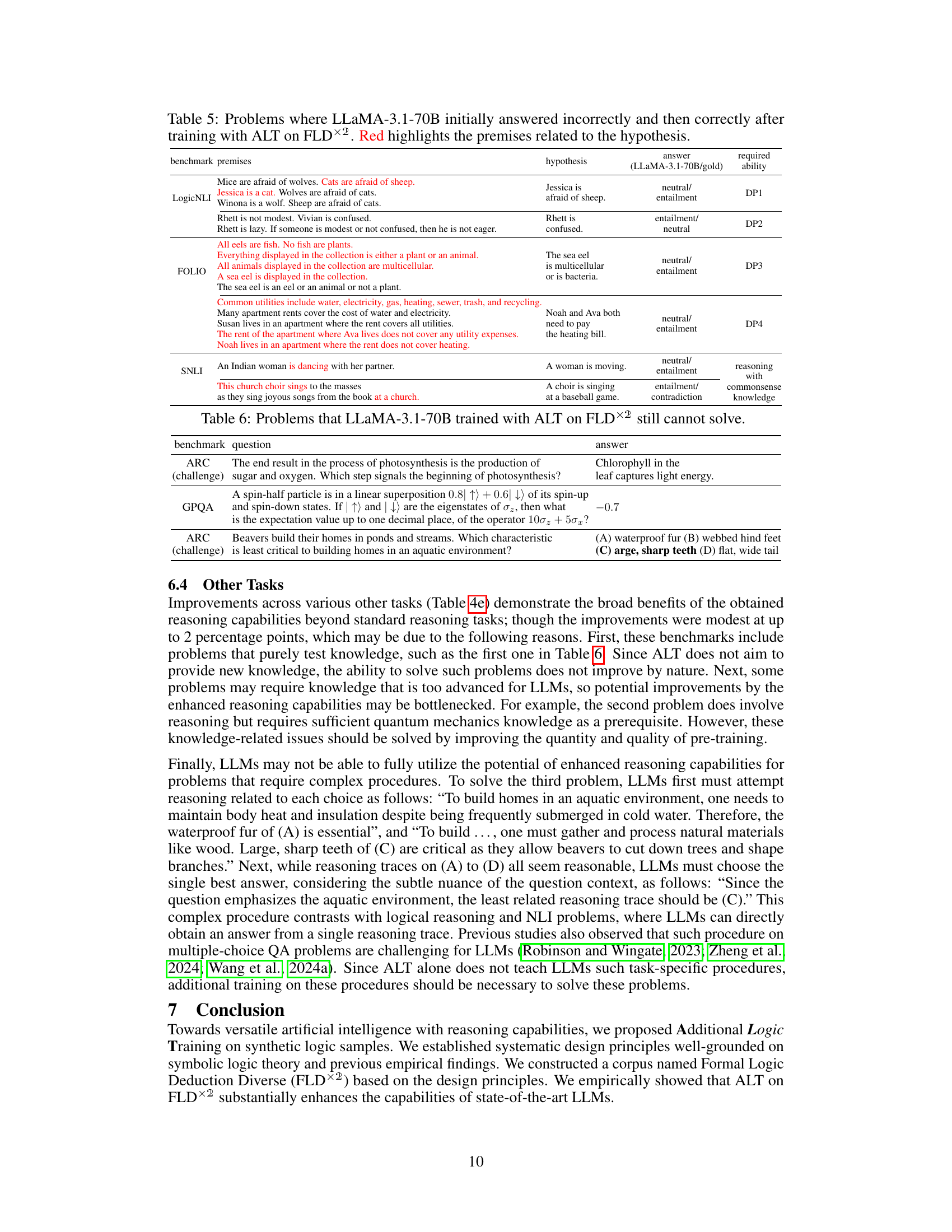
🔼 This table compares several synthetic logic corpora used in the study, including the proposed FLDx2 and existing ones like RuleTaker and PARARULE-Plus. Each corpus is evaluated based on four design principles (DP): 1. Inclusion of unknown facts (DP1), 2. Inclusion of negative facts (DP2), 3. Diversity of reasoning rules and number of steps (DP3), and 4. Diversity of linguistic expressions (DP4). The table shows the characteristics of each corpus according to these principles, such as vocabulary size, presence of distractors, types of deduction rules, number of logical steps, and the number of expressions per formula. The ablation corpora are variations of FLDx2, where each principle is removed to test its impact on the overall performance.
read the caption
Table 1: Synthetic logic corpora compared in this study, with their features categorized according to our proposed design principles (DP). Note that the last row of the ablation corpora lists variations of FLD×2, each of which differs from the original regarding one of the design principles.
In-depth insights#
LLM Reasoning Boost#
The concept of “LLM Reasoning Boost” points to the exciting advancements in improving the logical reasoning capabilities of Large Language Models (LLMs). Current LLMs, while proficient in many tasks, often struggle with complex reasoning tasks. This limitation stems from several factors, including the nature of their training data and their reliance on pattern matching rather than true logical deduction. Strategies to enhance LLM reasoning often involve fine-tuning with high-quality datasets specifically designed for logical reasoning, addressing issues such as handling unknown facts and diverse linguistic expressions. Synthetic datasets, created using principles of formal logic, have proven particularly effective, allowing for the generation of numerous samples covering a wide range of logical structures and difficulty levels. The success of these methods demonstrates the potential for significantly improving LLM capabilities beyond pattern recognition towards true logical understanding and reasoning. However, challenges still exist, including the generalization of learned reasoning skills to novel tasks and the prevention of overfitting on synthetic data. Future research will focus on more effective data creation, evaluation metrics, and investigating the relationship between reasoning and other cognitive abilities within LLMs. The ultimate goal is to develop LLMs capable of flexible, robust, and explainable reasoning across various domains, leading to more versatile and reliable AI systems.
Synthetic Logic Design#
Synthetic logic design in LLMs focuses on creating high-quality, programmatically generated datasets for training. The core idea is to overcome LLMs’ limitations in reasoning by providing them with numerous examples of logical deductions, encompassing various complexities and linguistic styles. Key design principles include incorporating unknown facts, diverse reasoning rules, and varied linguistic expressions. A crucial element is the inclusion of both logical and illogical examples to facilitate proper distinction. High-quality synthetic data thus addresses the bias towards memorized knowledge and enhances the ability of LLMs to generalize reasoning skills to novel problems. This approach contrasts with methods relying solely on pre-trained knowledge and offers a way to systematically improve LLMs’ logical reasoning capabilities. The effectiveness relies on the careful consideration of these design principles to ensure the resulting corpus is both comprehensive and representative of real-world reasoning challenges. Evaluating the success of this approach requires rigorous benchmarking across a range of tasks to ascertain whether the improvement is generalizable or confined to a specific type of problem.
ALT Training Effects#
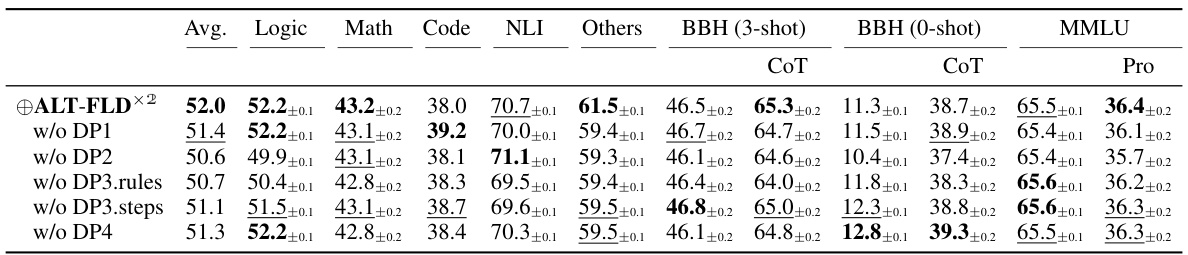
Analyzing the effects of Additional Logic Training (ALT) reveals significant improvements in LLMs’ reasoning capabilities. FLD×2, the synthetic corpus used, proved highly effective, demonstrating the importance of its design principles (incorporating unknown facts, negative examples, diverse rules, and linguistic expressions). ALT on FLD×2 yielded substantial gains across diverse benchmarks, including logical reasoning, math, coding, and natural language inference. The results highlight the critical role of high-quality reasoning samples in enhancing LLMs. Knowledge-forgetting prevention is crucial, as training on unknown facts can displace existing knowledge. However, limitations remain, suggesting that further research is necessary to improve performance on tasks requiring complex procedures or advanced knowledge integration.
Abductive Reasoning#
Abductive reasoning, a crucial aspect of human intelligence, involves forming explanatory hypotheses. It’s distinct from deductive (deriving conclusions from premises) and inductive (generalizing from observations) reasoning. In AI, replicating abductive reasoning is challenging because it requires generating creative explanations, often involving incomplete information and uncertainty. The paper likely explores how advancements in Large Language Models (LLMs) might address this. LLMs demonstrate promise in handling incomplete data, which is central to abduction. However, evaluating an LLM’s abductive capabilities rigorously is difficult. Standard benchmark datasets might not adequately capture the nuances of abductive inference. The study may offer new metrics or a novel benchmark for evaluating LLMs’ progress in abductive reasoning, or it might present a new methodology for training LLMs to enhance their abilities in this area. The research likely contributes to closing the gap between current AI capabilities and human-level reasoning by exploring the potential of LLMs for creative and explanatory reasoning tasks.
Future Research#
Future research directions stemming from this paper on enhancing LLMs’ reasoning capabilities could explore several promising avenues. Extending ALT to encompass abductive and inductive reasoning beyond deductive reasoning is crucial for building more versatile AI systems. Investigating reasoning within different logical systems (e.g., modal and linear logic) instead of solely focusing on first-order predicate logic would allow for a more nuanced understanding of reasoning and enhance the breadth of application. Further research should explore knowledge-forgetting prevention techniques to avoid the displacement of existing knowledge during training. Finally, a key focus should be on integrating both synthetic logic corpora training with methods that leverage larger language models to distill reasoning traces. This combined approach could lead to more effective application of enhanced reasoning capabilities in solving complex, real-world problems.
More visual insights#
More on figures

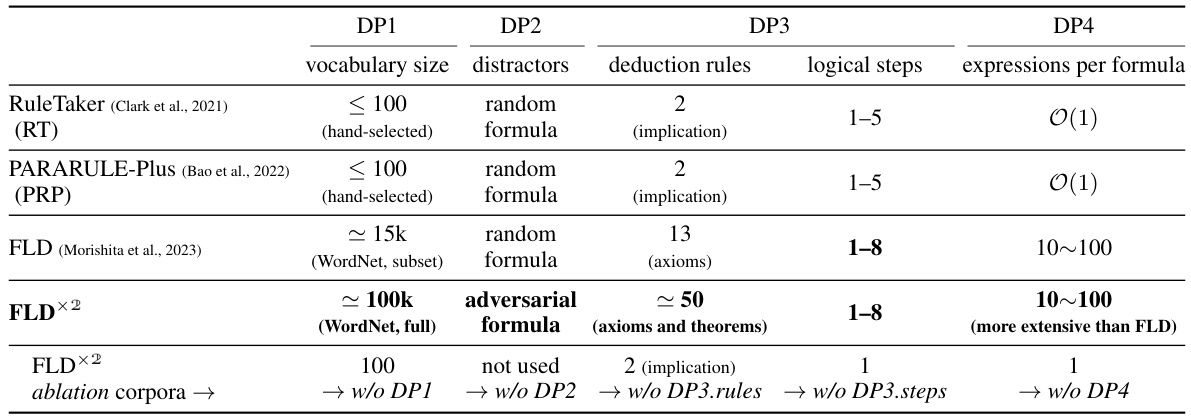
🔼 This figure illustrates the process of Additional Logic Training (ALT). The left side shows a sample generator that creates multi-step deductive reasoning samples using symbolic logic. This generator follows design principles to ensure high-quality samples (e.g., including unknown facts, diverse rules, etc.). The right side demonstrates how these samples are presented to LLMs. LLMs receive facts and a hypothesis and must generate a series of logical steps to prove or disprove the hypothesis. The figure highlights the overall ALT approach and the structure of the synthetic logic samples.
read the caption
Figure 2: Our proposed Additional Logic Training (ALT) aims to enhance LLMs' reasoning capabilities through training on many synthetically generated logical reasoning samples. Our sample generator (left) first generates a sample of multi-step deductive reasoning and then converts it into a deduction sample written in English (right). LLMs must generate logical steps to derive a given hypothesis from provided facts. The sample generator adheres to theoretically and empirically grounded design principles discussed in Section 2. Refer to Figure D.3 for a real sample.

🔼 This figure shows the performance improvement achieved by using Additional Logic Training (ALT) with the synthetic logic corpus FLDx2 on the LLaMA-3.1-70B large language model. The improvements are presented across various benchmark categories (Logic, Math, Code, NLI, and Others) and are visually represented using bar charts. The figure highlights the substantial gains obtained through ALT on FLDx2 compared to the baseline performance of LLaMA-3.1-70B.
read the caption
Figure 1: The performance gains to LLaMA-3.1-70B by Additional Logic Training (ALT) on the proposed synthetic corpus, FLD×2 (Formal Logic Deduction Diverse). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain. Tables 2, 4 shows the details.
🔼 This figure illustrates the Additional Logic Training (ALT) method proposed in the paper. ALT aims to improve LLMs’ reasoning by training them on synthetically generated logical reasoning samples. The figure’s left side shows how a sample generator creates a multi-step deductive reasoning sample using logical formulas. This sample is then converted into an English-language deduction sample (right side). The sample, presented to an LLM, requires the model to derive a given hypothesis from provided facts by generating the necessary logical steps. The generator follows design principles discussed earlier in the paper to ensure high-quality samples.
read the caption
Figure 2: Our proposed Additional Logic Training (ALT) aims to enhance LLMs' reasoning capabilities through training on many synthetically generated logical reasoning samples. Our sample generator (left) first generates a sample of multi-step deductive reasoning and then converts it into a deduction sample written in English (right). LLMs must generate logical steps to derive a given hypothesis from provided facts. The sample generator adheres to theoretically and empirically grounded design principles discussed in Section 2. Refer to Figure D.3 for a real sample.
More on tables

🔼 This table presents the performance of different LLMs (Large Language Models) on various reasoning tasks, before and after undergoing Additional Logic Training (ALT). The LLMs are tested on a variety of benchmark sets, including logic, math, code, and others. The table shows the average performance across all benchmarks, as well as the performance within each individual benchmark set. The color-coding helps to visually compare the relative performance of each LLM on each task.
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.

🔼 This table presents the 5-shot performance of different LLMs (Large Language Models) before and after applying Additional Logic Training (ALT) using various synthetic logic corpora. The performance is measured across several benchmark sets, including Logic, Math, Code, NLI (Natural Language Inference), and others. The ‘Avg.’ column shows the micro-average performance across all benchmarks. The color-coding helps to easily compare the relative performance of each model on each task. ALT-x indicates that the LLM was trained with ALT using the synthetic logic corpus x (as defined in Table 1).
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.
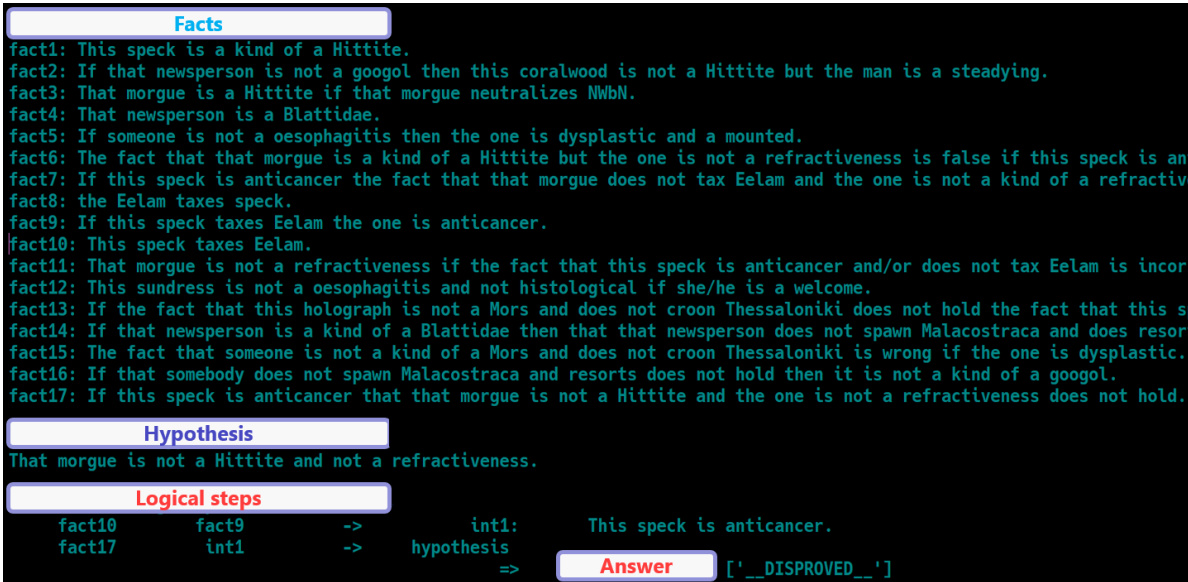
🔼 This table presents the results of training the LLaMA-3.1-8B language model on several variations of the FLDx2 corpus. Each variation removes one of the four design principles (DP1-DP4) to understand their individual contributions to the model’s performance. The table shows performance metrics across various benchmarks, allowing for a comparison of the effects of each design principle on the model’s ability to generalize across different reasoning tasks.
read the caption
Table 3: LLaMA-3.1-8B trained on the ablation corpora.

🔼 This table presents the results of the experiment comparing the performance of the LLaMA-3.1-70B language model before and after undergoing Additional Logic Training (ALT) on the FLDx2 dataset. It shows the performance gains across various benchmark sets which include Logic, Math, Code, Natural Language Inference (NLI), and Other tasks. The results are presented as 5-shot performance with error bars indicating variability. A reference to a supplementary table with results for the LLaMA-3.1-8B model is included and there is also a reference for the detailed breakdown of the individual benchmarks in Table E.7.
read the caption
Table 4: Benchmark-wise 5-shot performance of LLaMA-3.1-70B before and after ALT on FLD×2. Refer to Table F.9 for LLaMA-3.1-8B results. Table E.7 details each benchmark.

🔼 This table presents the results of the experiments conducted to evaluate the impact of Additional Logic Training (ALT) on the performance of the LLaMA-3.1-70B language model. It shows the 5-shot performance (meaning the model was provided 5 examples before being asked to perform the task) on various benchmarks across different categories: Logic, Math, Code, Natural Language Inference (NLI), and Others. For each benchmark, the table shows the performance of the LLaMA-3.1-70B model before ALT and after ALT using the FLDx2 corpus. The difference in performance highlights the impact of ALT on improving the model’s reasoning abilities across diverse tasks.
read the caption
Table 4: Benchmark-wise 5-shot performance of LLaMA-3.1-70B before and after ALT on FLD×2. Refer to Table F.9 for LLaMA-3.1-8B results. Table E.7 details each benchmark.
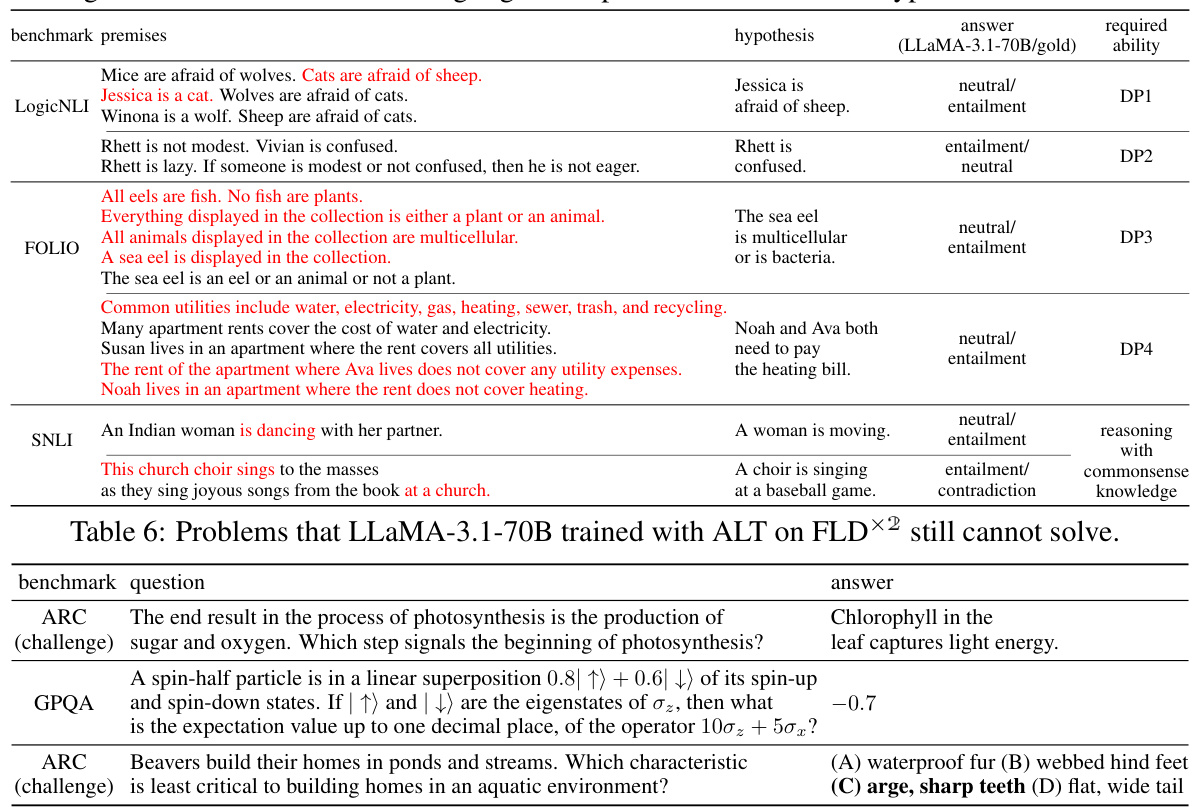
🔼 This table presents the results of experiments comparing the performance of Large Language Models (LLMs) before and after undergoing Additional Logic Training (ALT). The LLMs were trained using different synthetic logic corpora, identified by ‘ALT-x’, where ‘x’ represents the specific corpus used (as detailed in Table 1). Performance is measured across several benchmark sets, including logic, math, code, and others, with each set encompassing multiple individual benchmarks. The table displays the average scores across all benchmarks, providing a comparative analysis of the LLMs’ performance before and after ALT. The ranking of each LLM’s performance in each category is visually represented by color-coding (darker color indicates better performance).
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.

🔼 This table presents the 5-shot performance of Large Language Models (LLMs) before and after undergoing Additional Logic Training (ALT) using different synthetic logic corpora. It compares the performance across various benchmarks categorized into Logic, Math, Code, and Others. The color-coding helps visualize the ranking of each LLM’s performance within each benchmark category. The ‘Avg.’ column shows the average performance across all benchmarks.
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.

🔼 This table presents the 5-shot performance results of several Large Language Models (LLMs) before and after undergoing Additional Logic Training (ALT). The LLMs were trained using different synthetic logic corpora (ALT-x, where x represents the corpus used). The table shows performance across various benchmark sets, including Logic, Math, Code, Natural Language Inference (NLI), and others. The average performance across all benchmarks is also provided. Darker shades in the table indicate better performance.
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.

🔼 This table presents the performance of different LLMs (Large Language Models) on various benchmark tasks, both before and after undergoing Additional Logic Training (ALT) with different synthetic logic corpora. The results show the average scores across multiple runs, with color-coding to visually represent the ranking of each LLM on each benchmark. The table highlights the impact of ALT and the choice of training corpus on the model’s overall performance.
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.

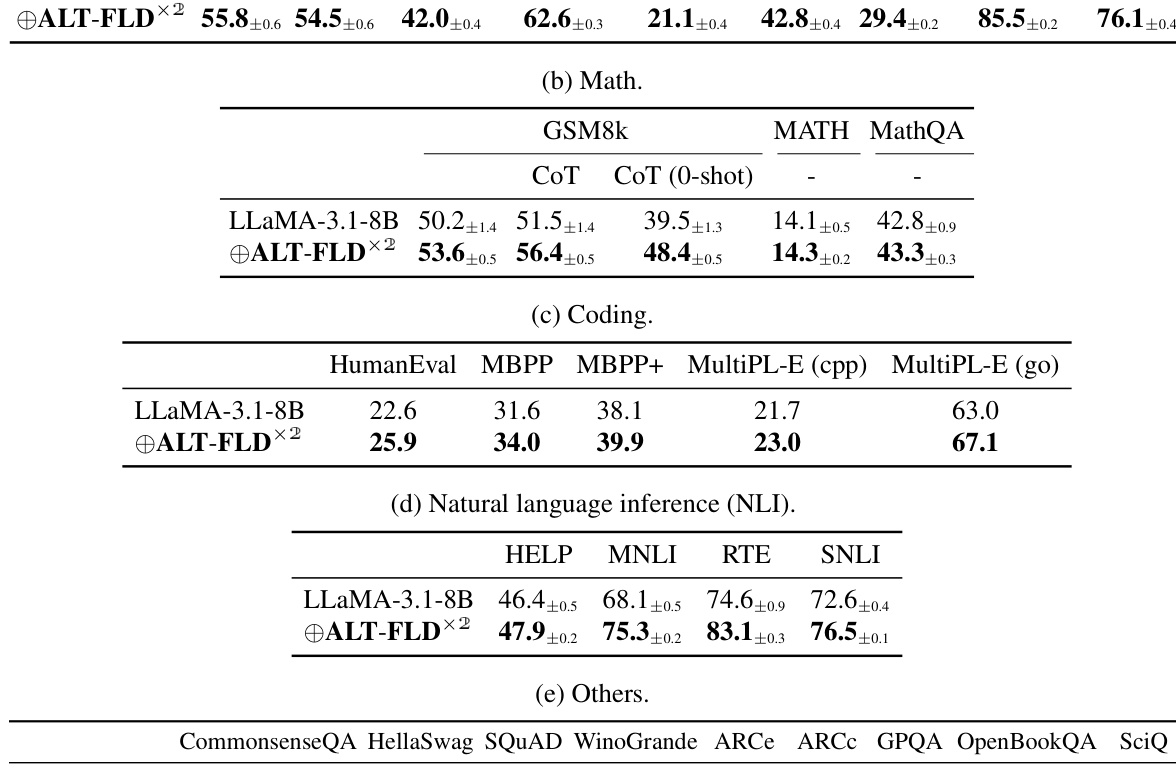
🔼 This table presents the 5-shot performance results of the LLaMA-3.1-70B language model on various benchmark tasks, before and after undergoing Additional Logic Training (ALT) using the Formal Logic Deduction Diverse (FLD×2) corpus. The results are broken down into categories (Logic, Math, Code, NLI, Others) showcasing improvements across a range of reasoning tasks after applying ALT. The table also includes references to other tables providing further details on specific benchmarks and model performance on different model sizes.
read the caption
Table 4: Benchmark-wise 5-shot performance of LLaMA-3.1-70B before and after ALT on FLD×2. Refer to Table F.9 for LLaMA-3.1-8B results. Table E.7 details each benchmark.
🔼 This table presents the performance of different LLMs (Large Language Models) before and after applying Additional Logic Training (ALT). It compares the performance across various benchmark sets (Logic, Math, Code, NLI, Others) using a 5-shot in-context learning approach. The results highlight the impact of ALT on improving the reasoning capabilities of LLMs.
read the caption
Table 2: 5-shot performance of LLMs before and after ALT. ALT-x denotes the LLM trained with ALT on the synthetic logic corpus x from Table 1. The color shows the rank in each column (darker is better). Each benchmark set, such as 'Logic' and 'Math', comprises various benchmarks in that domain (see Table E.7). 'Avg.' represents the micro-average of all the benchmarks.

🔼 This table presents the results of the 5-shot performance evaluation of the LLaMA-3.1-70B language model on various benchmarks before and after undergoing Additional Logic Training (ALT) using the Formal Logic Deduction Diverse (FLD×2) corpus. The table is divided into five sections representing different benchmark categories: Logic, Math, Code, Natural Language Inference (NLI), and Others. For each category, it shows the average performance and standard deviation (e.g., 83.8±1.2) of the model before ALT and the improvement after ALT (e.g., from 83.8±1.2 to 83.5±0.5 for Logic). The table highlights the significant performance gains across various reasoning tasks following the ALT training, illustrating the effectiveness of the method.
read the caption
Table 4: Benchmark-wise 5-shot performance of LLaMA-3.1-70B before and after ALT on FLD×2. Refer to Table F.9 for LLaMA-3.1-8B results. Table E.7 details each benchmark.
Full paper#