TL;DR#
Fine-grained visual classification (FGVC) struggles with limited and homogenous datasets, hindering model training. Traditional data augmentation methods are insufficient to address this challenge. Generative models offer new possibilities but often compromise class fidelity or diversity, creating a trade-off between accuracy and representativeness.
SaSPA (Structure and Subject Preserving Augmentation) tackles this head-on. It leverages text-to-image diffusion models conditioned on edge maps and subject representations to create diverse, class-consistent synthetic images. SaSPA significantly outperforms existing methods in various FGVC scenarios, including full dataset training, few-shot learning, and mitigating contextual biases. The method’s flexibility and improved diversity are key contributors to its success. The results highlight the potential of leveraging synthetic data effectively for FGVC and provide valuable insights into the optimal balance of real and synthetic data in model training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in fine-grained visual classification (FGVC). It introduces a novel data augmentation technique, significantly improving model performance, particularly with limited data. This addresses a major bottleneck in FGVC and opens new avenues for research in synthetic data generation and its effective use in training robust models. The findings on the relationship between real and synthetic data are also valuable.
Visual Insights#

🔼 This figure shows a comparison of different image augmentation techniques applied to an airplane image. It highlights the trade-off between image fidelity (how realistic the augmented image is) and diversity (how different the augmented image is from the original). Text-to-image methods often lack fidelity. Img2Img methods with low strength improve fidelity but lack diversity; while high strength increases diversity but loses fidelity. The authors’ method, SaSPA, achieves high fidelity and diversity.
read the caption
Figure 1: Various generative augmentation methods applied on Aircraft [30]. Text-to-image often compromises class fidelity, visible by the unrealistic aircraft design (i.e., tail at both ends). Img2Img trades off fidelity and diversity: lower strength (e.g., 0.5) introduces minimal semantic changes, resulting in higher fidelity but limited diversity, whereas higher strength (e.g., 0.75) introduces diversity but also inaccuracies such as the incorrectly added engine. In contrast, SaSPA achieves high fidelity and diversity, critical for Fine-Grained Visual Classification tasks. D - Diversity. F - Fidelity
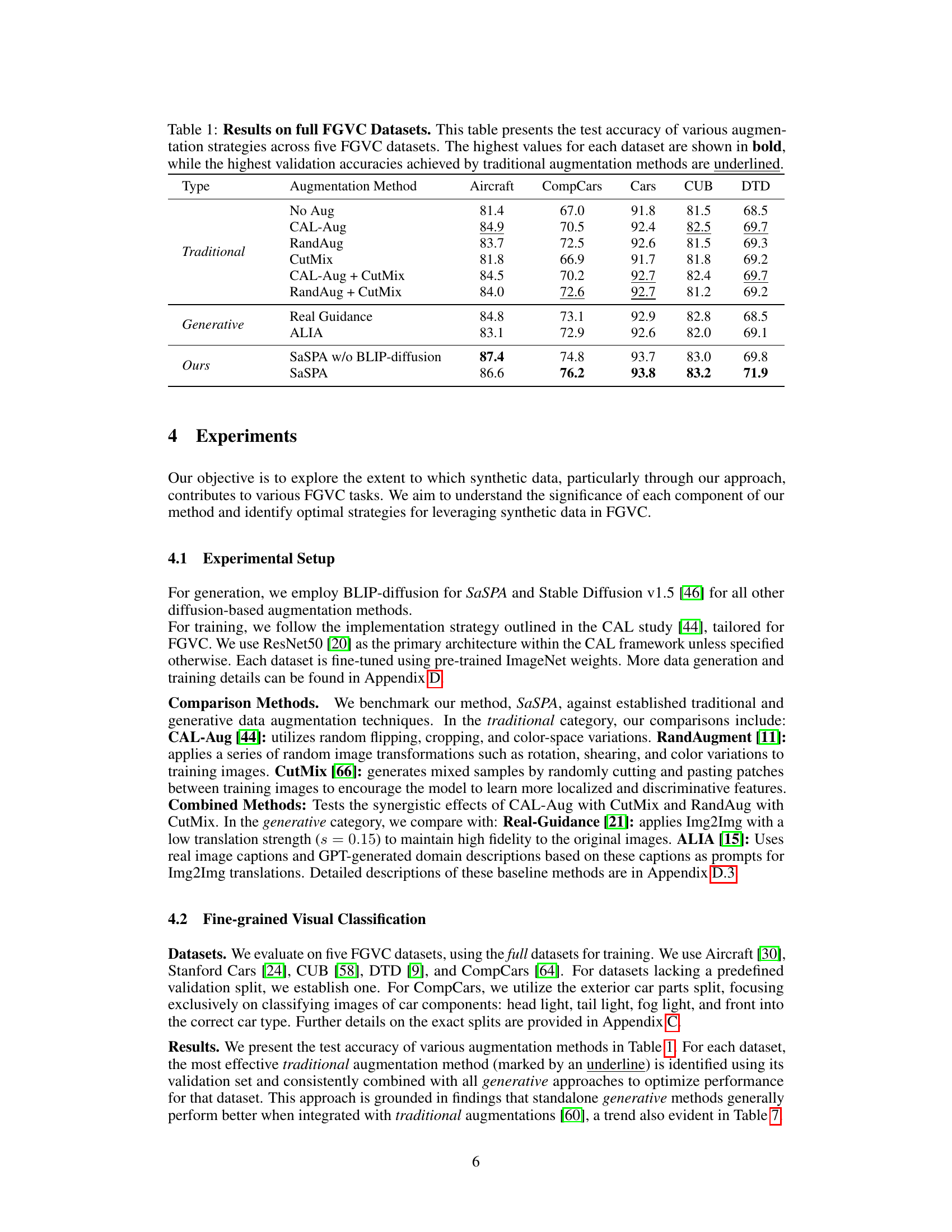
🔼 This table compares the performance of various data augmentation methods on five fine-grained visual classification (FGVC) datasets. The methods are categorized as traditional (e.g., CAL-Aug, RandAug, CutMix) and generative (e.g., Real Guidance, ALIA, SaSPA). The table shows the test accuracy for each method on each dataset. The highest accuracy for each dataset is highlighted in bold, and the highest validation accuracy achieved by traditional methods is underlined. SaSPA, the authors’ proposed method, generally outperforms the other augmentation methods.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.
In-depth insights#
FGVC Augmentation#
Fine-grained visual classification (FGVC) augmentation presents unique challenges due to the subtle inter-class differences and high intra-class variance. Traditional methods often fall short. Generative models, particularly diffusion models, offer significant potential. However, directly applying them can compromise class fidelity or diversity. The key lies in carefully controlling the generation process. Methods employing real images as guidance, while maintaining fidelity, often limit diversity. Structure and subject-preserving augmentation techniques aim to address this by conditioning generation on abstract representations like image edges and subject characteristics. This allows for greater diversity without sacrificing accuracy. Successful approaches often involve filtering generated samples to eliminate low-quality or irrelevant augmentations. The optimal balance between real and synthetic data, and the ideal augmentation strategy, are dataset-dependent. Future research should explore more sophisticated conditioning mechanisms and better filtering techniques to unlock the full potential of generative models for FGVC.
SaSPA’s Mechanism#
SaSPA’s mechanism ingeniously tackles the challenge of fine-grained visual classification (FGVC) data augmentation by prioritizing diversity without sacrificing fidelity. Instead of using real images as direct guidance (a limitation of previous approaches), it leverages abstract conditioning on edge maps, which capture the object’s structure, and subject representation, maintaining sub-class characteristics. This strategy allows the generation of diverse variations without being overly reliant on any single source image. GPT-4 generates prompts ensuring class consistency and relevance, while a robust filtering mechanism maintains quality. This multifaceted approach effectively balances the competing demands of diversity and fidelity, critical for FGVC where subtle inter-class differences are key. The system’s architecture uses ControlNet and BLIP-2 diffusion models, demonstrating the potential of integrating large language models and image synthesis for data augmentation tasks.
Synthetic Data Use#
The research paper explores the use of synthetic data, specifically focusing on its application in fine-grained visual classification (FGVC). The core idea is to augment existing, limited datasets with synthetically generated images to improve model performance. The paper argues that standard augmentation techniques are insufficient for FGVC due to the subtle differences between closely related sub-classes. While acknowledging that previous works have employed generative models for data augmentation, the authors highlight limitations in achieving both high fidelity (accurate class representation) and high diversity (sufficient variations within the class). The proposed methodology, SaSPA, addresses this by generating synthetic images conditioned on edge maps and subject representations extracted from real images, effectively preserving structural information and fine-grained details. The research evaluates the efficacy of this approach through extensive experiments and comparisons with established baselines, demonstrating improvements across various FGVC datasets and settings. A key contribution is highlighting the relationship between the amount of real data available and the optimal proportion of synthetic data to utilize, suggesting that a higher synthetic data ratio can be beneficial in scenarios with limited real data.
Bias Mitigation#
The provided text focuses on mitigating biases in fine-grained visual classification (FGVC) using synthetic data augmentation. SaSPA, the proposed method, tackles the challenge of subtle inter-class differences and limited data in FGVC datasets by generating diverse, class-consistent images. The approach cleverly avoids using real images as direct guidance for augmentation, unlike previous methods, thus promoting greater diversity while preserving class fidelity. Instead, it conditions image generation on edge maps and subject representation, effectively capturing object structure and class-specific characteristics. The strategy shows promising results in reducing bias, especially in a challenging contextual bias scenario where visual similarity between subclasses is high (e.g., differentiating Airbus and Boeing airplanes based on background). The use of synthetic data, created with less reliance on real image guidance, likely contributes to improved generalization and bias mitigation by reducing overfitting to the idiosyncrasies of the training set. The effectiveness of SaSPA is demonstrated across multiple FGVC datasets and experimental settings, highlighting its versatility and robustness in handling bias-prone scenarios.
Future of SaSPA#
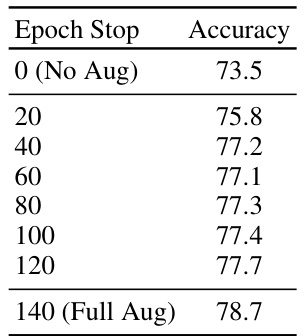
The future of SaSPA (Structure and Subject Preserving Augmentation) looks promising, building upon its success in fine-grained visual classification (FGVC). Expanding its application to other challenging tasks like object detection and semantic segmentation is a key area of development. Further research should explore ways to improve its efficiency and scalability, potentially by optimizing the prompt generation process or leveraging more efficient diffusion models. Addressing limitations, such as the LLM’s dependence on adequate meta-class knowledge and higher resolution image challenges, is critical. Integrating advanced conditioning techniques, such as temporal consistency for video data, will broaden its applicability and impact. Finally, exploring different base diffusion models and investigating the optimal balance between real and synthetic data across various datasets warrants investigation to improve the robustness and performance of SaSPA.
More visual insights#
More on figures
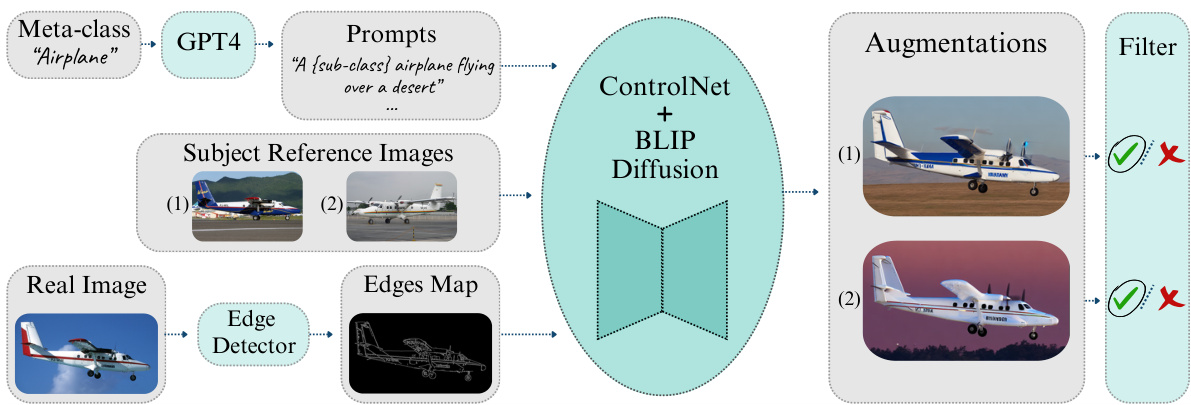
🔼 This figure illustrates the SaSPA pipeline. It starts with generating prompts from GPT-4 based on the meta-class of the dataset. Then, real images undergo edge detection to capture structural information. These edges, along with different prompts and subject reference images from the same sub-class, are fed into ControlNet with BLIP-Diffusion. The generated images are finally filtered for relevance and quality using a dataset-trained model and CLIP.
read the caption
Figure 2: SaSPA Pipeline: For a given FGVC dataset, we generate prompts via GPT-4 based on the meta-class. Each real image undergoes edge detection to provide structural outlines. These edges are used M times, each time with a different prompt and a different subject reference image from the same sub-class, as inputs to a ControlNet with BLIP-Diffusion as the base model. The generated images are then filtered using a dataset-trained model and CLIP to ensure relevance and quality.

🔼 This figure compares different image augmentation methods applied to aircraft images from the Aircraft dataset. It shows how text-to-image methods can create unrealistic results (low fidelity), while image-to-image methods struggle to balance fidelity and diversity. The authors’ method, SaSPA, is highlighted for its ability to achieve both high fidelity and high diversity in generated images, which is crucial for fine-grained visual classification.
read the caption
Figure 1: Various generative augmentation methods applied on Aircraft [30]. Text-to-image often compromises class fidelity, visible by the unrealistic aircraft design (i.e., tail at both ends). Img2Img trades off fidelity and diversity: lower strength (e.g., 0.5) introduces minimal semantic changes, resulting in higher fidelity but limited diversity, whereas higher strength (e.g., 0.75) introduces diversity but also inaccuracies such as the incorrectly added engine. In contrast, SaSPA achieves high fidelity and diversity, critical for Fine-Grained Visual Classification tasks. D - Diversity. F - Fidelity
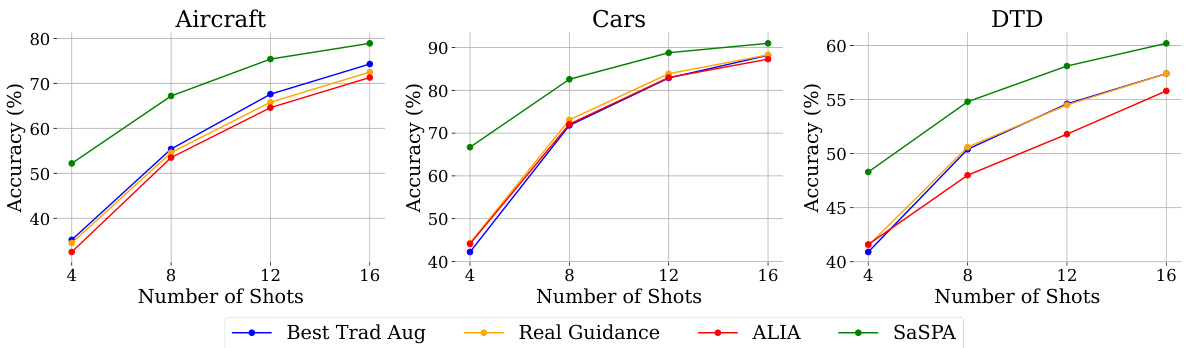
🔼 This figure compares the performance of various data augmentation methods in a few-shot learning setting on three fine-grained visual classification (FGVC) datasets: Aircraft, Cars, and DTD. The x-axis represents the number of training examples (shots) used, while the y-axis shows the test accuracy achieved. Different lines represent different augmentation techniques: Best Trad Aug (best traditional augmentation method), Real Guidance, ALIA, and SaSPA (the proposed method). The figure clearly demonstrates that SaSPA consistently outperforms all other methods across all datasets and different numbers of shots.
read the caption
Figure 4: Few-shot test accuracy across three FGVC datasets: Aircraft, Cars, and DTD, using different augmentation methods. The number of few-shots tested includes 4, 8, 12, and 16. We can see that for all datasets and shots, SaSPA outperforms all other augmentation methods.

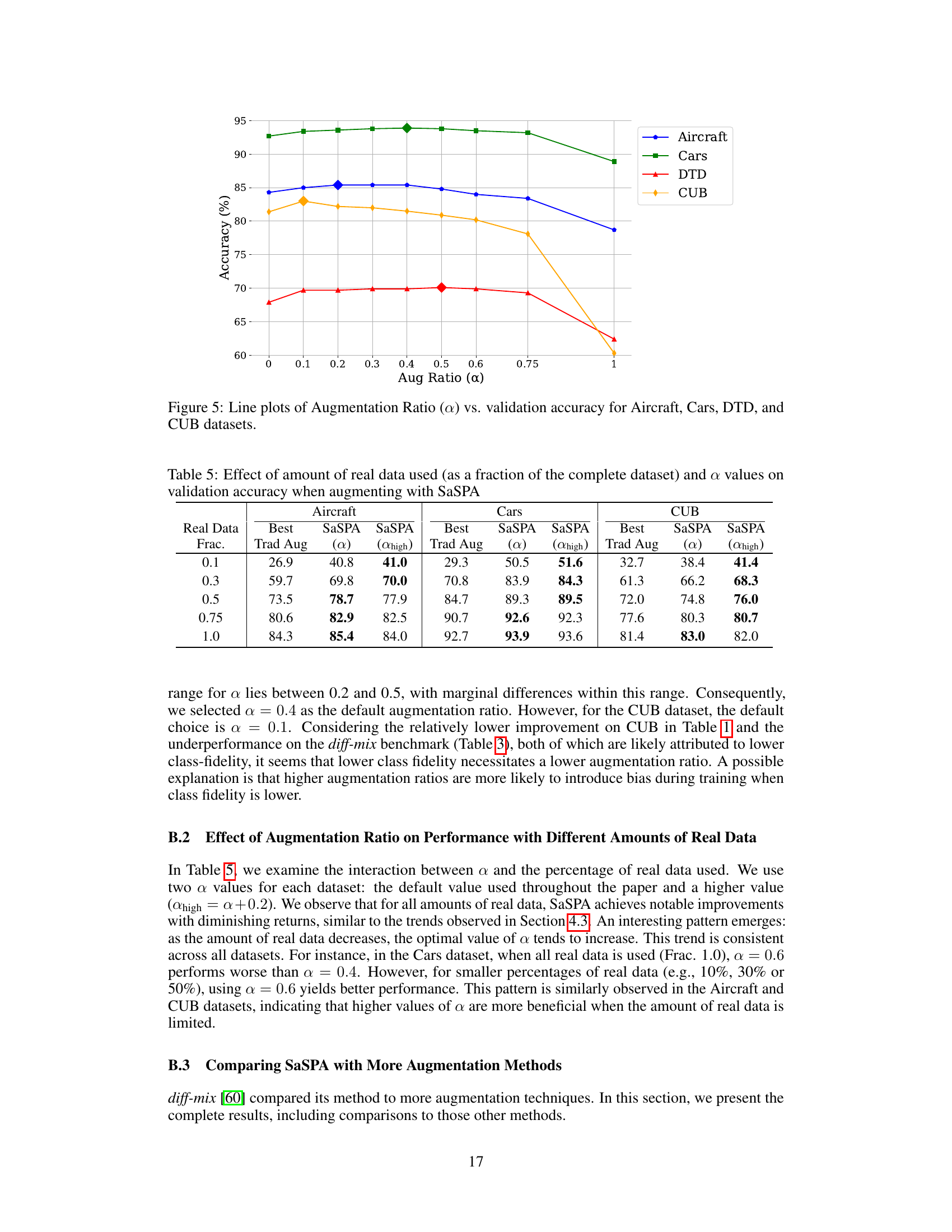
🔼 This figure shows the relationship between the augmentation ratio (α) and the validation accuracy for four fine-grained visual classification (FGVC) datasets: Aircraft, Cars, DTD, and CUB. The augmentation ratio represents the probability that a real training sample will be replaced with a synthetic sample during each epoch. The plot reveals how the optimal augmentation ratio varies across different datasets, indicating that there’s no single optimal ratio for all FGVC tasks. Some datasets show an optimal ratio between 0.2 and 0.5, while others, such as CUB, exhibit a different trend.
read the caption
Figure 5: Line plots of Augmentation Ratio (α) vs. validation accuracy for Aircraft, Cars, DTD, and CUB datasets.
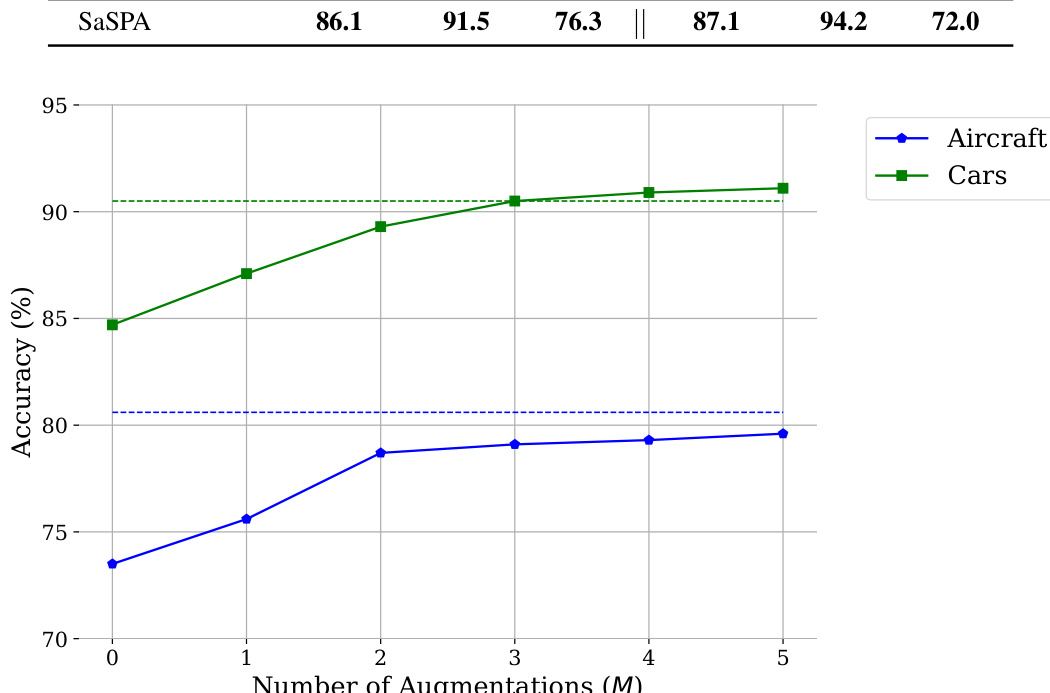
🔼 This figure displays the results of a few-shot learning experiment on three fine-grained visual classification (FGVC) datasets (Aircraft, Cars, and DTD) using various data augmentation methods. The x-axis represents the number of ‘shots’ (training examples per class), and the y-axis represents the test accuracy. The figure shows that SaSPA (Structure and Subject Preserving Augmentation), consistently outperforms other augmentation methods across all three datasets and across different numbers of shots.
read the caption
Figure 4: Few-shot test accuracy across three FGVC datasets: Aircraft, Cars, and DTD, using different augmentation methods. The number of few-shots tested includes 4, 8, 12, and 16. We can see that for all datasets and shots, SaSPA outperforms all other augmentation methods.

🔼 This figure shows a qualitative comparison of three different generative augmentation methods (Real Guidance, ALIA, and SaSPA) on their ability to augment images from five fine-grained visual classification (FGVC) datasets. The results highlight that SaSPA generates more diverse and visually distinct augmentations compared to the other two methods. Real Guidance produces minimal changes, ALIA produces noticeable but less diverse changes, and SaSPA creates substantial diversity in augmentations while maintaining visual quality.
read the caption
Figure 7: Qualitative results of different generative augmentation methods: Real-Guidance, ALIA, and SaSPA on five FGVC datasets. Real Guidance produces very subtle variations from the original image due to the low translation strength they used. ALIA generates visible variations, but they are considerably less diverse compared to the augmentations produced by SaSPA.

🔼 This figure shows examples of augmentations generated by SaSPA for three different datasets (Aircraft, CompCars, and CUB). It visually demonstrates the effectiveness of the filtering process used in the SaSPA pipeline. The top row displays augmentations that passed the filtering, meaning they were deemed to be of sufficient quality and relevant to their respective classes. The bottom row shows augmentations that were filtered out, indicating that they either did not adequately represent their class or were of insufficient quality for use in training. The images help to illustrate the criteria used in the filtering process and showcase the types of augmentations that are deemed suitable for inclusion in the dataset versus those that are discarded.
read the caption
Figure 8: Randomly selected augmentations of SaSPA that were and were not filtered for Aircraft, CompCars, and CUB.
More on tables

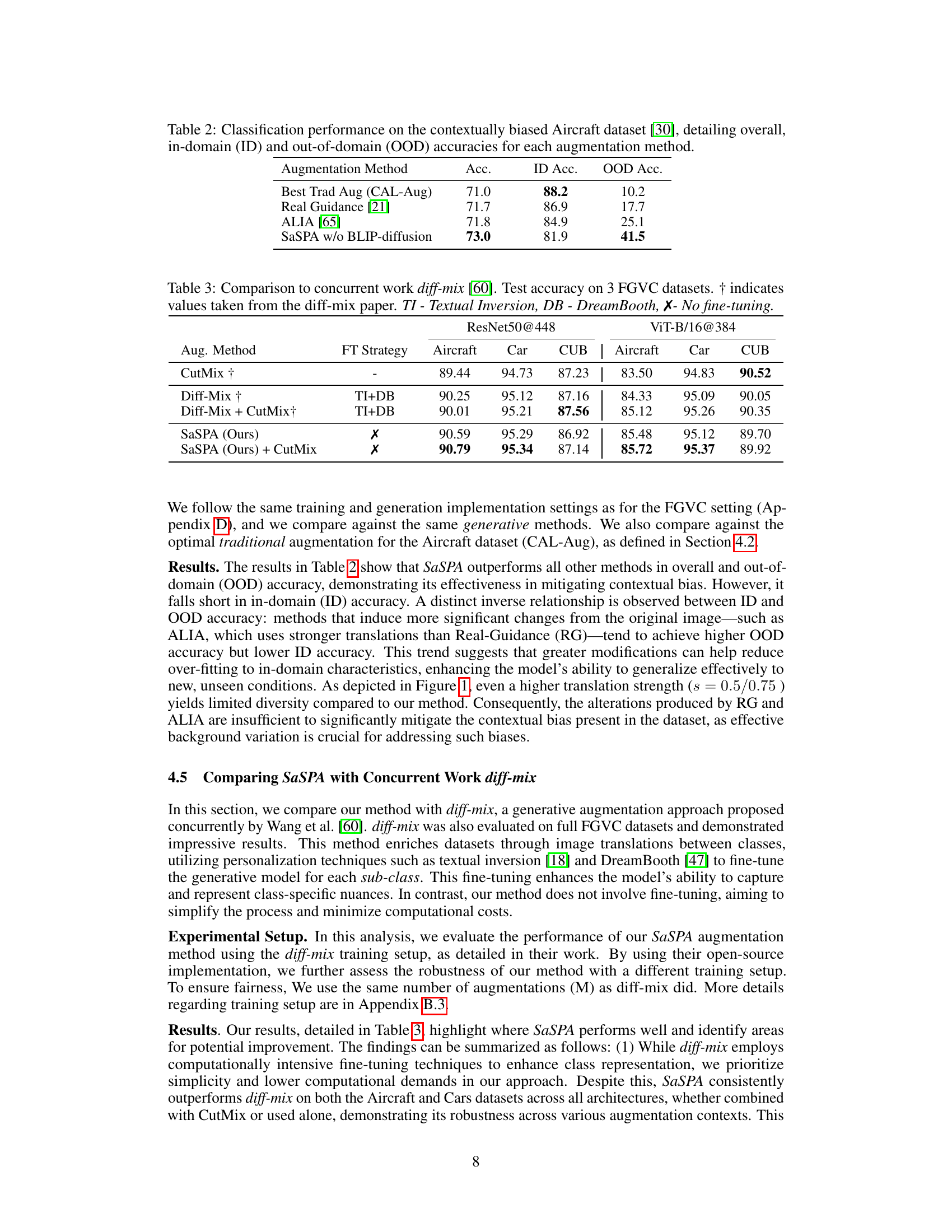
🔼 This table presents the classification performance results on the contextually biased Aircraft dataset. It compares different data augmentation methods, showing their overall accuracy, in-domain accuracy (ID Acc.), and out-of-domain accuracy (OOD Acc.). In-domain accuracy refers to performance on data similar to the training data, while out-of-domain accuracy assesses generalization to unseen data. The table helps to illustrate the effectiveness of various augmentation techniques in mitigating bias and improving generalization.
read the caption
Table 2: Classification performance on the contextually biased Aircraft dataset [30], detailing overall, in-domain (ID) and out-of-domain (OOD) accuracies for each augmentation method.
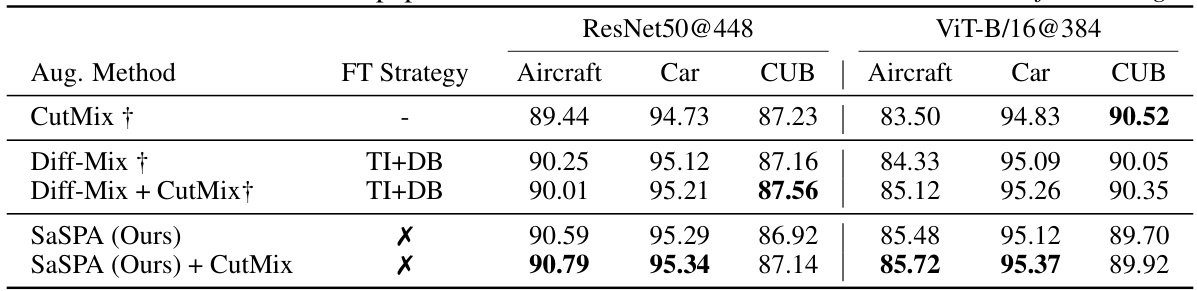
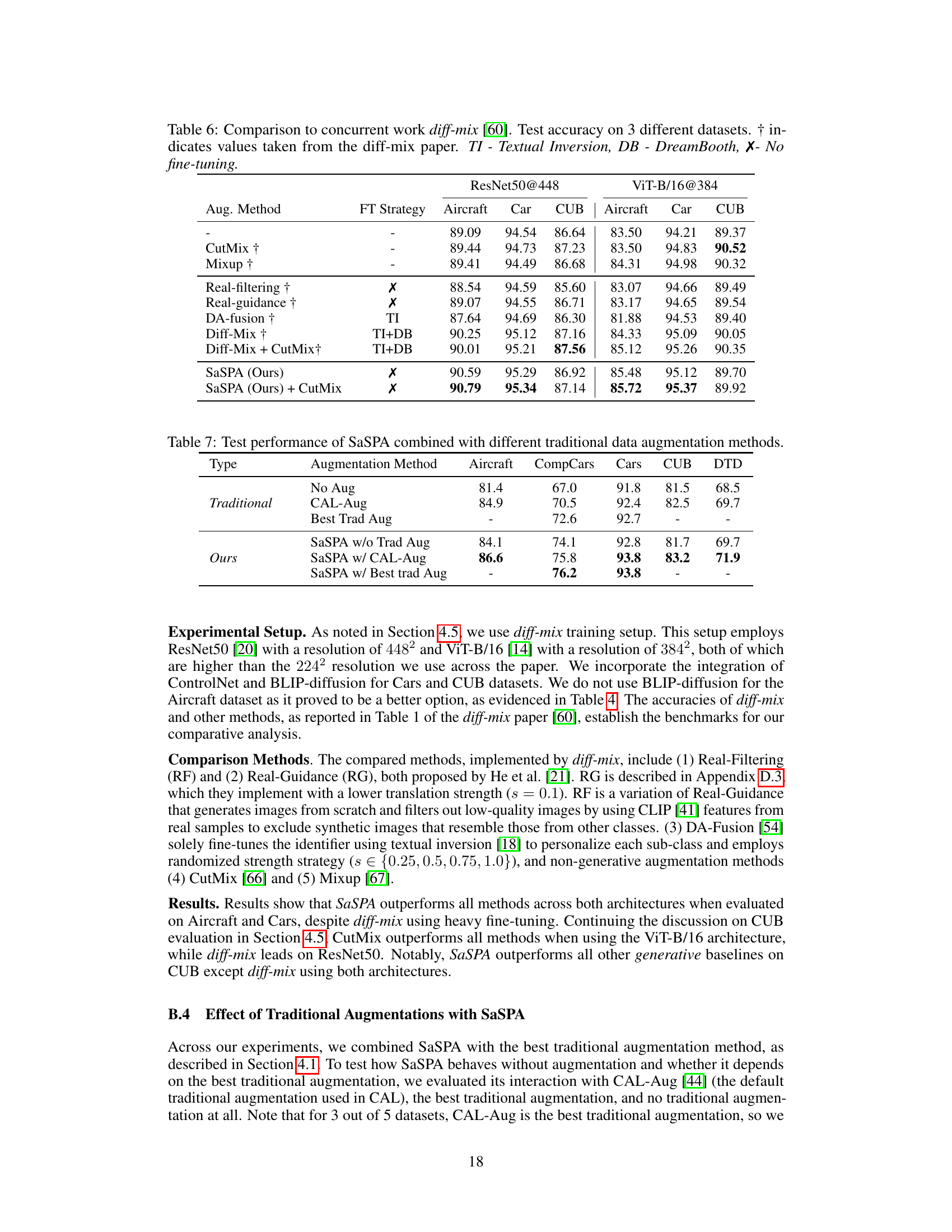
🔼 This table compares the proposed SaSPA method to the diff-mix method [60] across three fine-grained visual classification (FGVC) datasets. It shows the test accuracy achieved by both methods, with and without using additional augmentation techniques like CutMix and fine-tuning strategies such as Textual Inversion and DreamBooth. The table highlights the performance of SaSPA, showing its competitive results even without using any fine-tuning.
read the caption
Table 3: Comparison to concurrent work diff-mix [60]. Test accuracy on 3 FGVC datasets. † indicates values taken from the diff-mix paper. TI - Textual Inversion, DB - DreamBooth, X- No fine-tuning.

🔼 This table presents an ablation study evaluating the impact of different components of the SaSPA method on the performance of fine-grained visual classification (FGVC) tasks across multiple datasets. It examines the individual and combined effects of edge guidance, Img2Img generation, subject representation, artistic prompt styles, and the relationship between the edge map and subject images. The results highlight the optimal combination of components for achieving high accuracy in FGVC.
read the caption
Table 4: Ablation Study: Effects of different generation strategies on various FGVC Datasets. ‘Subj.’ means subject representation is used. ‘Edges=Subj.’ indicates that the real image used to extract the edges is the same as the subject reference image. ‘Art.’ indicates that half the prompts are appended with artistic styles. For each dataset, bold indicates the highest validation accuracy, and underline indicates the second highest. Ticks under each column mean the component is used.

🔼 This table shows the validation accuracy achieved by SaSPA under different augmentation ratios (α) and varying amounts of real training data. The results demonstrate the interaction between α and the amount of real data, highlighting the diminishing returns of augmentation and the optimal α values under different real data proportions.
read the caption
Table 5: Effect of amount of real data used (as a fraction of the complete dataset) and α values on validation accuracy when augmenting with SaSPA
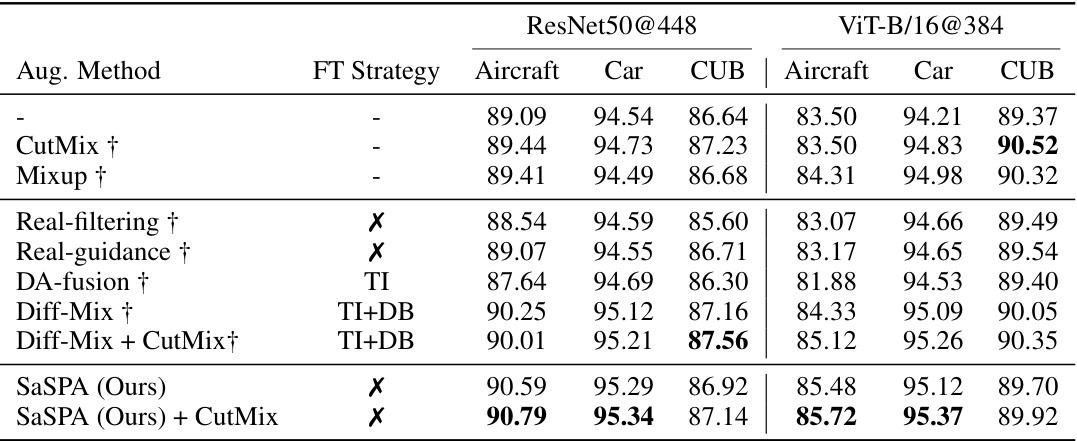
🔼 This table compares the performance of various data augmentation methods on five fine-grained visual classification (FGVC) datasets. The methods include traditional augmentation techniques (e.g., CAL-Aug, RandAug, CutMix), generative methods using real image guidance, and the proposed SaSPA method. The table highlights the test accuracy for each method on each dataset, with the best result for each dataset shown in bold and the best result achieved by a traditional method underlined. This allows for a direct comparison of the performance gains achieved by different augmentation approaches on full FGVC datasets.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.
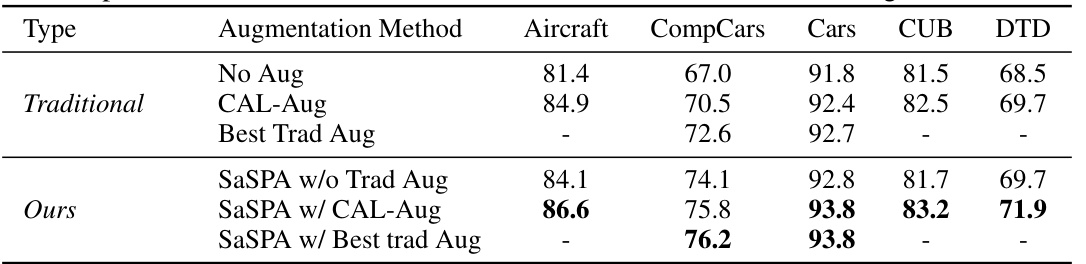
🔼 This table compares the performance of various data augmentation methods on five fine-grained visual classification (FGVC) datasets. The methods are categorized as traditional (e.g., CAL-Aug, RandAug, CutMix) and generative (e.g., SaSPA, ALIA, Real Guidance). For each dataset, the highest test accuracy is highlighted in bold, and the best validation accuracy achieved by traditional methods is underlined. The table allows readers to assess the effectiveness of the different augmentation strategies for improving the performance of FGVC models.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.
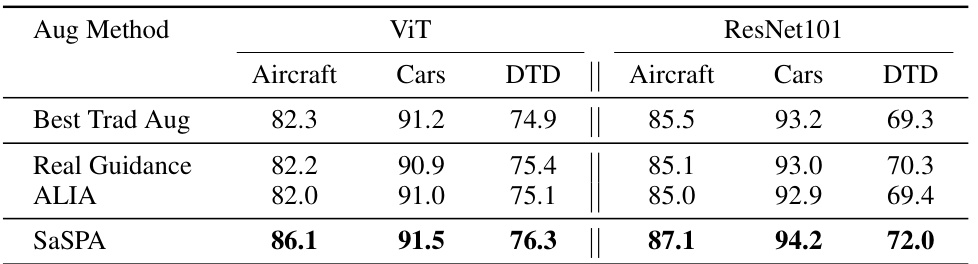
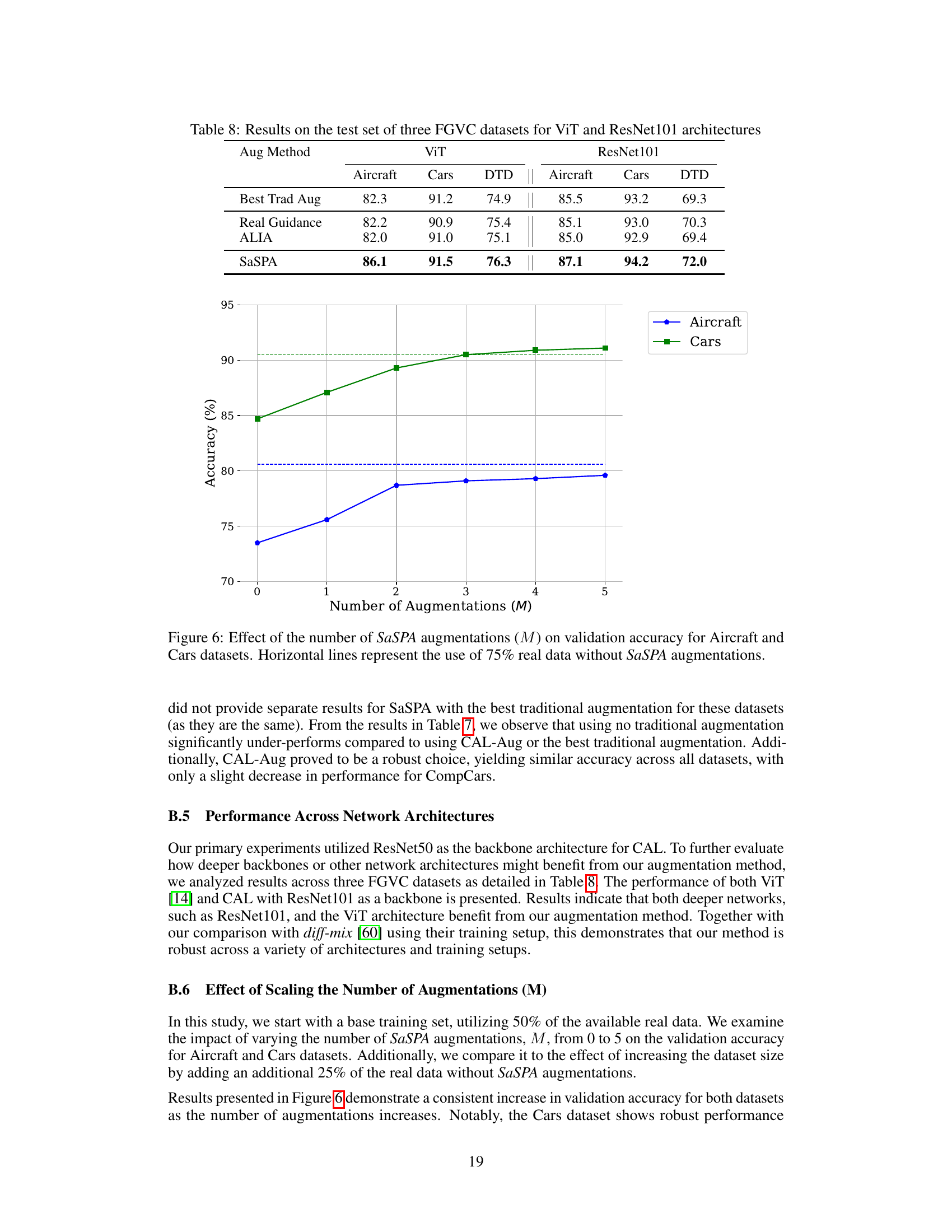
🔼 This table compares the performance of different augmentation methods (Best Trad Aug, Real Guidance, ALIA, and SaSPA) on three fine-grained visual classification (FGVC) datasets using two different network architectures: ViT and ResNet101. The results show the test accuracy for each method on each dataset and architecture, highlighting the effectiveness of SaSPA in improving the performance across different FGVC datasets and architectures.
read the caption
Table 8: Results on the test set of three FGVC datasets for ViT and ResNet101 architectures
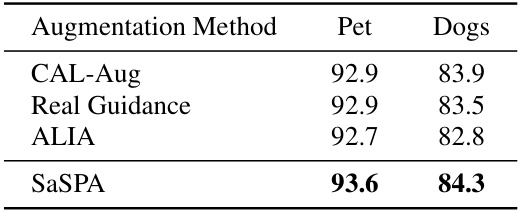
🔼 This table presents the test accuracy achieved by various augmentation methods (CAL-Aug, Real Guidance, ALIA, and SaSPA) on two additional fine-grained visual classification (FGVC) datasets: Stanford Dogs and Oxford-IIIT Pet. The highest accuracy for each dataset is highlighted in bold, demonstrating the relative performance of each method on these datasets.
read the caption
Table 9: Additional datasets. We report test accuracy on two additional FGVC datasets: Stanford Dogs and The Oxford-IIIT Pet Dataset. The highest values for each dataset are shown in bold.

🔼 This table compares the performance of different prompt generation strategies (Captions, LE, ALIA (GPT), Ours (GPT), Ours (GPT) + Art) on two FGVC datasets (Aircraft and Cars). The results show that the proposed method (Ours (GPT) and Ours (GPT) + Art) outperforms other strategies.
read the caption
Table 10: Comparison of prompt strategies across two FGVC datasets. The highest values are highlighted in bold, while the second highest are underlined.

🔼 This table shows the validation accuracy achieved on the Aircraft dataset using two different numbers of prompts (100 and 200) generated by the SaSPA method. The results indicate whether using more prompts significantly improves the accuracy of the method.
read the caption
Table 11: Validation accuracy on the Aircraft dataset using 100 and 200 prompts generated by our method.

🔼 This table shows the Fréchet Inception Distance (FID) and accuracy scores for various generative augmentation methods across four fine-grained visual classification (FGVC) datasets. FID measures the similarity between the distribution of generated images and real images. The table compares Real Guidance, ALIA, and SaSPA, highlighting the trade-off between FID (image realism) and accuracy. Lower FID values indicate higher similarity to real data, while higher accuracy indicates better performance on the classification task.
read the caption
Table 12: Combined FID and accuracy results for various generative augmentation methods across four FGVC datasets.

🔼 This table presents a comparison of different generative augmentation methods across five fine-grained visual classification (FGVC) datasets. It shows both the diversity score (using LPIPS to measure perceptual differences between original and augmented images) and the resulting accuracy achieved by each method. The higher the diversity score, the more varied the augmentations produced. The accuracy reflects the performance of a downstream classification model trained using the augmented datasets.
read the caption
Table 13: Combined diversity score and accuracy results for various generative augmentation methods across five FGVC datasets.
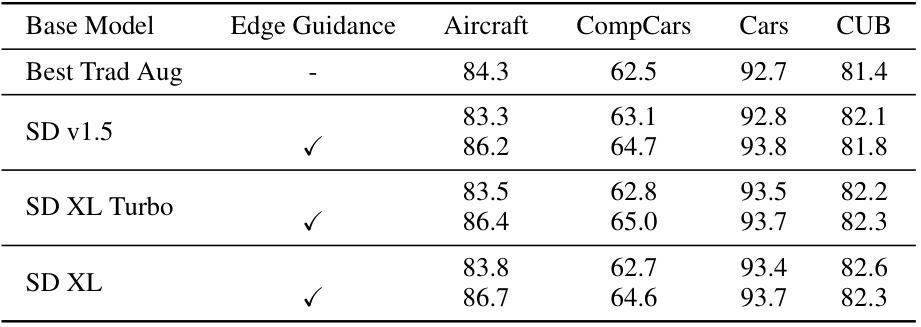
🔼 This table presents the validation accuracy results of the SaSPA method using different base diffusion models (Stable Diffusion v1.5, SD XL Turbo, SD XL) with and without edge guidance. It helps to analyze the impact of different base models and edge guidance on the overall performance of SaSPA.
read the caption
Table 14: Validation accuracy of our method with different base models. Generations do not include BLIP-diffusion.
🔼 This table compares the performance of different data augmentation methods on five fine-grained visual classification (FGVC) datasets. It shows the test accuracy for each method, highlighting the best-performing method for each dataset in bold. The table is divided into traditional augmentation methods and generative augmentation methods. The highest validation accuracy achieved by traditional methods is also underlined for comparison.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.

🔼 This table shows the results of experiments conducted using images with higher resolution (448x448) compared to other parts of the paper. It compares the performance of SaSPA with the best-performing traditional augmentation method for each of the datasets used in the study, providing a comparison of test accuracy scores. The table helps assess the impact of higher resolution on the effectiveness of SaSPA and traditional augmentation methods.
read the caption
Table 16: Higher resolution results. Comparison of our method (SaSPA) with the best augmentation method per dataset. All results are using 448x448 resolution, and reported on the test set of each dataset.

🔼 This table shows the validation accuracy achieved on the Aircraft dataset when using different edge detection methods (Canny and HED) for conditioning the ControlNet model during image generation. The results compare the performance of using Canny edges versus HED edges as the conditioning input for the ControlNet model.
read the caption
Table 17: Validation accuracy on the Aircraft dataset using different conditioning types of ControlNet.
🔼 This table compares the test accuracy of different data augmentation methods across five fine-grained visual classification (FGVC) datasets. The methods include traditional augmentation techniques (no augmentation, CAL-Aug, RandAug, CutMix, combinations thereof), generative methods leveraging real images (Real Guidance, ALIA), and the proposed SaSPA method. The highest accuracy for each dataset is highlighted in bold, and the highest validation accuracy achieved by traditional methods is underlined to provide context for the performance of the generative methods.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.

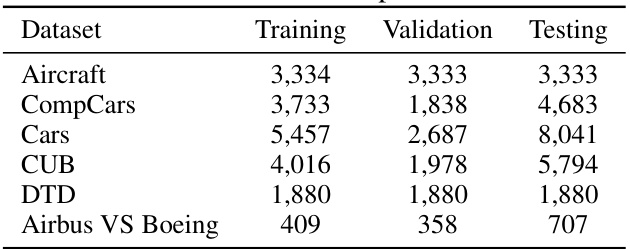
🔼 This table shows the number of training, validation, and testing samples for Airbus and Boeing planes, categorized by their background (sky, grass, road). It’s used to illustrate the class imbalance and contextual bias present in the dataset when evaluating the model’s performance on mitigating contextual biases.
read the caption
Table 19: Dataset Statistics for Contextually Biased Planes
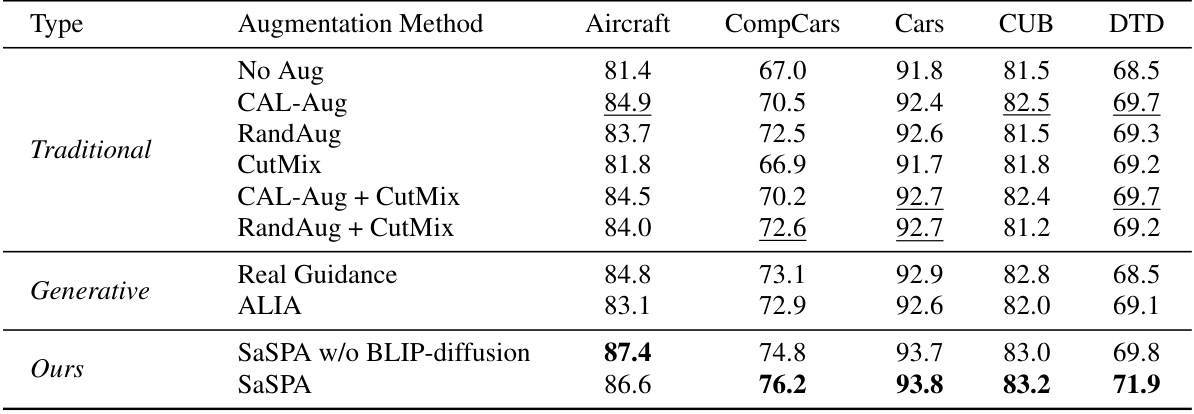
🔼 This table compares the test accuracy of different data augmentation methods across five fine-grained visual classification (FGVC) datasets. It contrasts traditional methods (no augmentation, CAL-Aug, RandAug, CutMix, combinations thereof) with generative methods (real guidance, ALIA, SaSPA with and without BLIP-diffusion). The best performing method for each dataset is highlighted in bold, while the best performing traditional method is underlined.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.

🔼 This table compares the performance of various data augmentation techniques on five fine-grained visual classification (FGVC) datasets. It shows the test accuracy achieved by different methods, including traditional augmentation techniques (no augmentation, CAL-Aug, RandAug, CutMix, and combinations), generative methods (using real images as guidance, ALIA, SaSPA w/o BLIP diffusion), and the proposed SaSPA method. The highest test accuracy for each dataset is highlighted in bold, and the best validation accuracy achieved by a traditional method is underlined, providing a basis for comparison.
read the caption
Table 1: Results on full FGVC Datasets. This table presents the test accuracy of various augmentation strategies across five FGVC datasets. The highest values for each dataset are shown in bold, while the highest validation accuracies achieved by traditional augmentation methods are underlined.
Full paper#