TL;DR#
Object detection in low-light conditions is challenging due to poor image quality and reduced visibility, leading to inaccurate results from traditional methods that focus on image enhancement. Existing approaches often rely heavily on synthetic datasets or task-specific loss functions, which limit their real-world applicability.
This paper introduces YOLA, a novel framework that tackles low-light object detection by learning illumination-invariant features using a novel Illumination-Invariant Module (IIM). The IIM effectively extracts these features by leveraging the Lambertian image formation model and employing a zero-mean constraint on task-driven learnable kernels. YOLA demonstrates significant improvements in low-light object detection, surpassing state-of-the-art methods on benchmark datasets. The code’s availability promotes further research and real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in low-light object detection because it introduces a novel framework that significantly improves detection accuracy by learning illumination-invariant features. It offers a new approach beyond traditional image enhancement methods, paving the way for more robust and accurate low-light vision systems and opening up new avenues of research in illumination-invariant feature learning. The readily available code further enhances its impact on the research community.
Visual Insights#

🔼 This figure shows the effectiveness of the proposed Illumination-Invariant Module (IIM) in object detection under low-light conditions. (a) shows a baseline detector failing to recognize objects in a low-light image. (b) demonstrates that using the IIM with a simple edge feature allows the detector to identify an object. Finally, (d) and (e) illustrate that using the full IIM with a learned kernel produces richer, more robust illumination-invariant features leading to improved object recognition, surpassing the performance of the simpler edge-based approach.
read the caption
Figure 1: (a): The base detector failed to recognize objects. (b, c) However, when IIM is employed with a simple edge feature, the object is identified. (d, e) Furthermore, the full IIM utilizes a task-driven learnable kernel to extract illumination-invariant features that are richer and more suitable for the detection task than simple edge features.
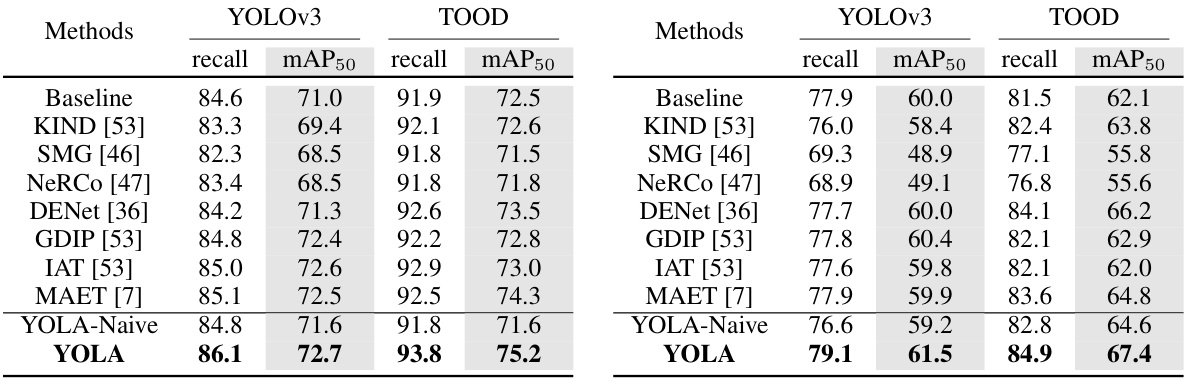
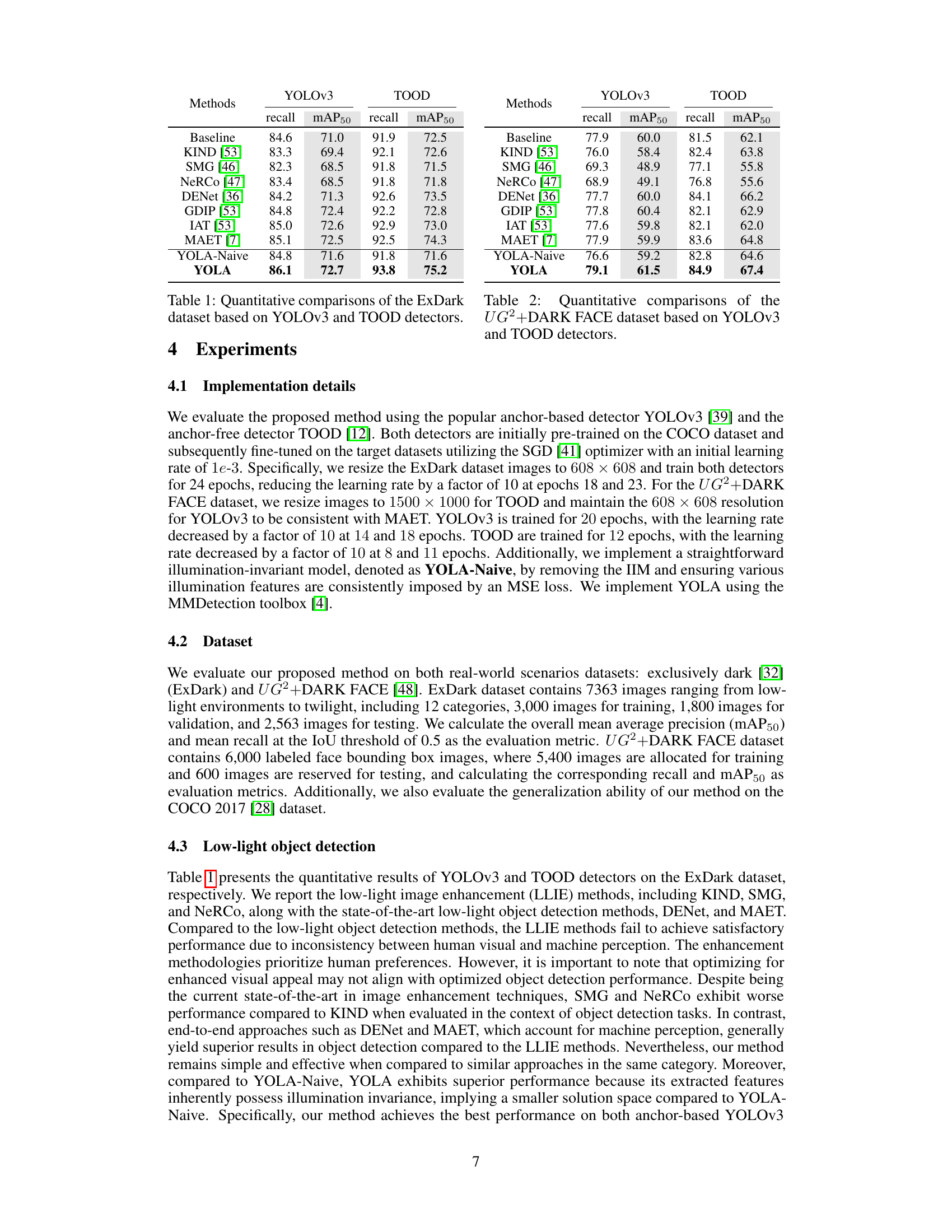
🔼 This table presents a quantitative comparison of the performance of YOLOv3 and TOOD object detectors on the ExDark dataset. It shows the recall and mean Average Precision (mAP) at an IoU threshold of 0.5 for various methods, including baselines (KIND, SMG, NeRCo, DENet, GDIP, IAT, MAET), a naive version of the proposed YOLA method, and the full YOLA method. The results demonstrate the improvement achieved by YOLA compared to other methods on this low-light image dataset.
read the caption
Table 1: Quantitative comparisons of the ExDark dataset based on YOLOv3 and TOOD detectors.
In-depth insights#
Illuminant Invariant#
The concept of illuminant invariance is crucial for robust computer vision, especially in challenging conditions like low-light scenarios. The core idea revolves around extracting features that are insensitive to variations in lighting. This is important because changes in illumination drastically affect image pixel values, potentially leading to inaccurate object detection and recognition. Traditional methods often try to pre-process images to normalize lighting, but this can be computationally expensive and may introduce artifacts. Learning illumination-invariant features directly from raw image data offers a more efficient and robust solution, enabling the system to adapt to a wider range of lighting conditions without explicit pre-processing steps. This approach aligns with the principle of learning task-relevant features rather than relying solely on image enhancement. Algorithms leveraging the Lambertian assumption, which models the relationship between surface properties and light reflection, provide a theoretical framework for designing such features. The success of this approach hinges on the ability of the model to effectively disentangle intrinsic object features from lighting effects, a challenge often addressed by employing constraints or carefully designing network architectures.
YOLA Framework#
The YOLA framework, as presented, offers a novel approach to low-light object detection by focusing on learning illumination-invariant features. This departs from traditional methods that primarily rely on image enhancement techniques. YOLA leverages the Lambertian image formation model, observing that illumination-invariant features can be approximated by exploiting relationships between neighboring color channels and pixels. A key innovation is the Illumination Invariant Module (IIM), which extracts these features using learnable convolutional kernels, trained in a detection-driven manner. The zero-mean constraint imposed on these kernels ensures both illumination invariance and richer task-specific patterns. YOLA’s modular design allows easy integration into existing object detection frameworks, improving performance in low-light, well-lit, and over-lit scenarios. The framework demonstrates promising results on benchmark datasets, showcasing significant improvements over existing methods, and its efficiency is highlighted by the relatively small number of parameters required. However, further research could explore its limitations in extremely challenging low-light conditions or with more diverse object categories.
IIM Module#
The Illumination Invariant Module (IIM) is a crucial component of the proposed YOLA framework, designed to extract illumination-invariant features from low-light images. Its core functionality revolves around learning convolutional kernels that characterize the interrelationships between neighboring color channels and spatially adjacent pixels. This approach is grounded in the Lambertian image formation model, which posits that under this model, illumination-invariant features can be approximated by exploiting these relationships. The innovative aspect of the IIM lies in its ability to learn these kernels in a detection-driven manner within a network. This adaptive learning contrasts with previous methods relying on fixed formulations, improving flexibility and compatibility with diverse downstream tasks. A key improvement introduced is the zero-mean constraint imposed on these learnable kernels. This constraint serves a dual purpose: it ensures illumination invariance by eliminating the influence of illumination-dependent terms while simultaneously facilitating the discovery of richer, task-specific patterns. The effectiveness of the IIM is empirically validated through significant improvements in low-light object detection, highlighting its potential as a versatile module readily integrable into existing object detection architectures.
Ablation Studies#
Ablation studies systematically evaluate the contribution of individual components within a machine learning model. In this context, the authors likely removed or deactivated different modules (such as the Illumination Invariant Module) to observe the impact on the overall performance. This would reveal the importance of the module in enhancing low-light object detection accuracy. Key insights might focus on comparing results with and without the module, quantifying improvement, and potentially investigating the effectiveness of variations within the module, like exploring different kernel sizes or the influence of zero-mean constraints on performance. A strong ablation study would provide quantitative results demonstrating the significance of the proposed techniques. It helps confirm that the improvements observed are not merely coincidental, rather, are direct outcomes of the innovative design choices made.
Future Works#
Future work could explore extending YOLA’s illumination invariance to other challenging visual conditions beyond low-light scenarios such as adverse weather conditions (fog, rain, snow). Improving the robustness of the IIM to handle a wider range of illumination variations would be beneficial. Investigating the applicability of YOLA to different object detection architectures (e.g., transformer-based detectors) would be valuable. A more comprehensive ablation study evaluating the impact of each component of the IIM could provide deeper insights. Furthermore, exploring the effectiveness of YOLA in real-time object detection is important for practical applications. Finally, developing a more robust and efficient method for extracting and integrating illumination-invariant features is crucial for improving the performance of object detection in challenging scenarios. Exploring the transferability of the learned illumination-invariant features to other related tasks, such as image segmentation or instance recognition would be interesting to study. Additionally, extending the research to other datasets and benchmarking against a wider range of state-of-the-art methods could be beneficial.
More visual insights#
More on figures
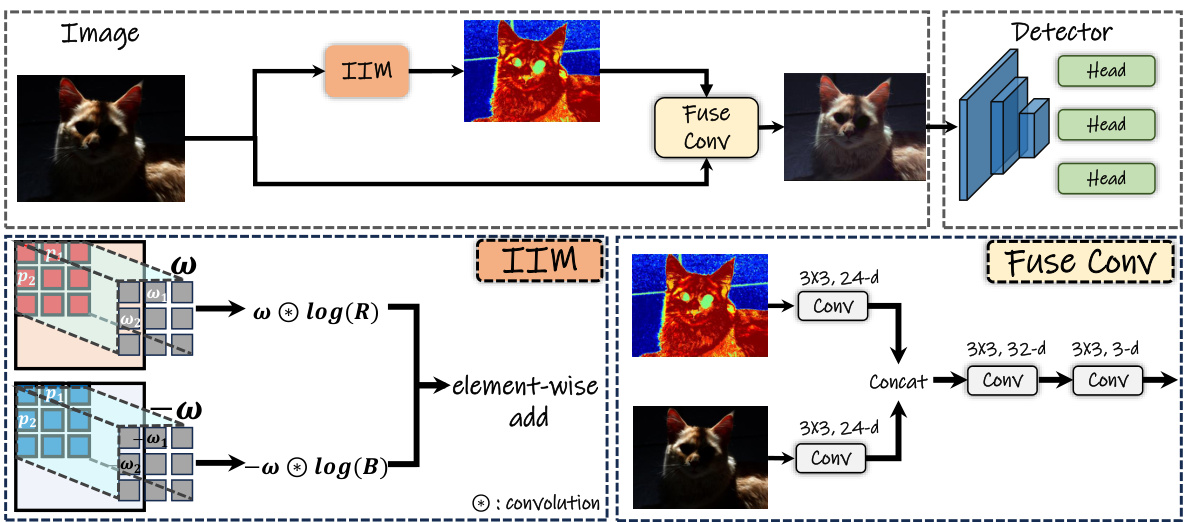
🔼 This figure illustrates the architecture of the YOLA object detection framework. It shows how illumination-invariant features are extracted using the Illumination Invariant Module (IIM). These features are then fused with the original image using a fusion convolution block before being fed into the detector head for final object detection. The IIM processes the image to generate illumination-invariant feature maps using learnable kernels. The bottom half of the figure shows a detailed view of the IIM process, highlighting the use of convolutional kernels and element-wise addition.
read the caption
Figure 2: The overall pipeline of YOLA.YOLA extracts illumination-invariant features via IIM and integrates them with original images by leveraging a fuse convolution block for the subsequent detector.

🔼 This figure shows a qualitative comparison of the TOOD object detector’s performance on the ExDark and UG2+DARK FACE datasets. The top two rows display results on ExDark, while the bottom two rows show results on UG2+DARK FACE. Each image shows the ground truth (GT) bounding boxes along with results from several different methods (baseline, DENet, MAET, KIND, SMG, NERCO) and the proposed YOLA method. Red dashed boxes highlight cases where objects were missed or poorly detected by the various methods.
read the caption
Figure 3: Qualitative comparisons of TOOD detector on both ExDark and UG2+DARK FACE dataset, where the top 2 rows visualize the detection results from ExDark, and the bottom 2 rows show the results from UG2+DARK FACE. The images are being replaced with enhanced images generated by LLIE or low-light object methods. Red dash boxes highlight the inconspicuous cases. Zoom in red dash boxes for the best view.

🔼 This figure demonstrates the effectiveness of the Illumination-Invariant Module (IIM) in object detection under low-light conditions. It shows that using the IIM, even with a simple edge feature (b, c), improves object recognition compared to a baseline detector that fails entirely (a). The full IIM, employing a learned kernel, extracts richer, more effective features, further enhancing detection performance (d, e).
read the caption
Figure 1: (a): The base detector failed to recognize objects. (b, c) However, when IIM is employed with a simple edge feature, the object is identified. (d, e) Furthermore, the full IIM utilizes a task-driven learnable kernel to extract illumination-invariant features that are richer and more suitable for the detection task than simple edge features.

🔼 This figure shows a qualitative comparison of the TOOD object detector’s performance on the ExDark and UG2+DARK FACE datasets. The top two rows display results on ExDark, while the bottom two rows show results on UG2+DARK FACE. The images used are enhanced using various low-light image enhancement (LLIE) techniques or low-light object detection methods. Red boxes highlight areas where the detectors had difficulty, particularly with inconspicuous objects.
read the caption
Figure 3: Qualitative comparisons of TOOD detector on both ExDark and UG2+DARK FACE dataset, where the top 2 rows visualize the detection results from ExDark, and the bottom 2 rows show the results from UG2+DARK FACE. The images are being replaced with enhanced images generated by LLIE or low-light object methods. Red dash boxes highlight the inconspicuous cases. Zoom in red dash boxes for the best view.

🔼 This figure presents a qualitative comparison of the TOOD object detector’s performance on the ExDark and UG2+DARK FACE datasets. The top two rows show results on ExDark, and the bottom two rows show results on UG2+DARK FACE. Each image shows the ground truth (GT) bounding boxes and results from different methods, including the baseline, DENet, MAET, KIND, SMG, NeRCo, and the proposed YOLA method. Red boxes highlight areas where the detectors had difficulty.
read the caption
Figure 3: Qualitative comparisons of TOOD detector on both ExDark and UG2+DARK FACE dataset, where the top 2 rows visualize the detection results from ExDark, and the bottom 2 rows show the results from UG2+DARK FACE. The images are being replaced with enhanced images generated by LLIE or low-light object methods. Red dash boxes highlight the inconspicuous cases. Zoom in red dash boxes for the best view.

🔼 This figure shows qualitative results comparing the TOOD object detector’s performance on the ExDark and UG2+DARK FACE datasets with and without the proposed YOLA method. The top two rows display ExDark results, and the bottom two rows display UG2+DARK FACE results. Red boxes highlight areas where the baseline detector failed but YOLA succeeded. This demonstrates YOLA’s improved object detection in low-light conditions.
read the caption
Figure 3: Qualitative comparisons of TOOD detector on both ExDark and UG2+DARK FACE dataset, where the top 2 rows visualize the detection results from ExDark, and the bottom 2 rows show the results from UG2+DARK FACE. The images are being replaced with enhanced images generated by LLIE or low-light object methods. Red dash boxes highlight the inconspicuous cases. Zoom in red dash boxes for the best view.
More on tables
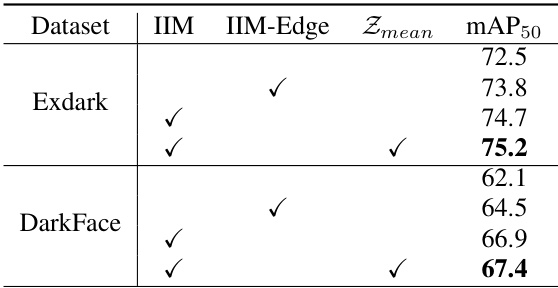
🔼 This table presents ablation study results on the TOOD detector to evaluate the impact of different components of the proposed Illumination Invariant Module (IIM). It shows the mAP50 (mean Average Precision at IoU threshold of 0.5) for the ExDark and DarkFace datasets using different configurations of the IIM: with only IIM-Edge (simple edge feature), with IIM (including learnable kernels), and with IIM and zero-mean constraint. The baseline results (no IIM) are also included for comparison. The table demonstrates the contribution of each component towards improving the overall object detection performance.
read the caption
Table 3: The effectiveness of IIM, IIM-Edge and the zero mean constraint Zmean based on TOOD. The blank line denotes the baseline.
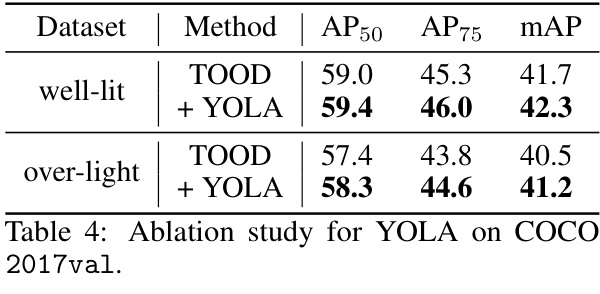
🔼 This table presents the ablation study results for the proposed YOLA framework. It shows the performance of the TOOD detector with and without YOLA on a well-lit and over-lit version of the COCO 2017 validation set. The metrics used for evaluation are AP50, AP75 and mAP.
read the caption
Table 4: Ablation study for YOLA on COCO 2017val.
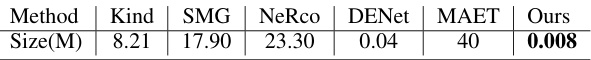
🔼 This table compares the model sizes (in millions of parameters) of various methods used for low-light object detection, including the proposed YOLA method and several state-of-the-art methods. The table highlights the significantly smaller model size of YOLA compared to others.
read the caption
Table 5: Model size of different methods.
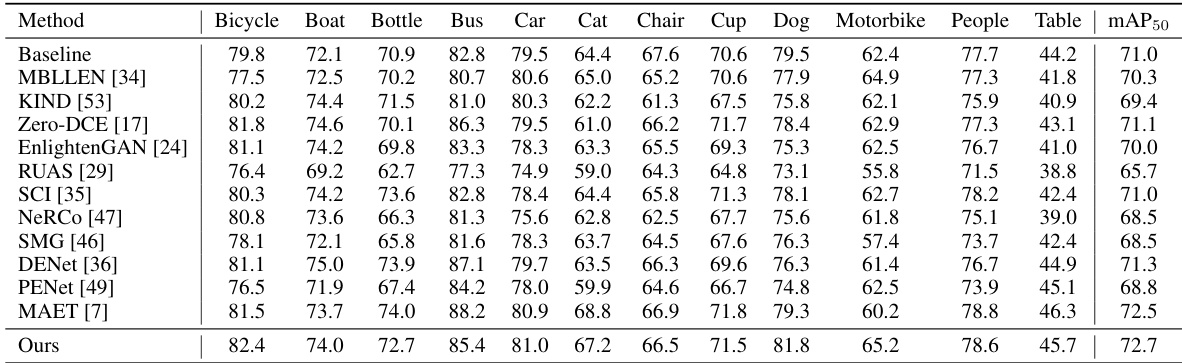
🔼 This table presents a quantitative comparison of different object detection methods on the ExDark dataset using the YOLOv3 detector. It shows the mean Average Precision (mAP50) and the average precision (AP) for each object category (Bicycle, Boat, Bottle, Bus, Car, Cat, Chair, Cup, Dog, Motorbike, People, Table) for various methods including baselines and state-of-the-art methods. The ‘Ours’ row represents the performance of the proposed YOLA method.
read the caption
Table 6: Quantitative comparisons of the ExDark dataset based on YOLOv3 detector.
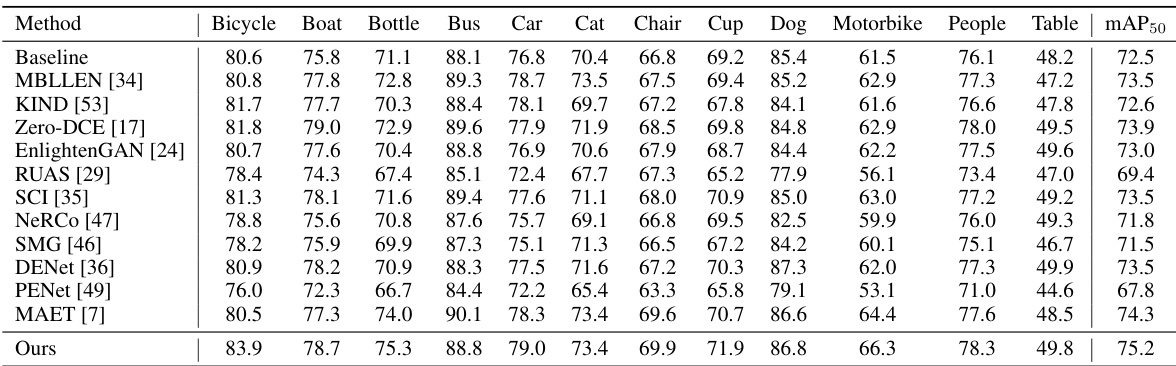
🔼 This table presents a quantitative comparison of different object detection methods on the ExDark dataset using the YOLOv3 detector. It shows the mean Average Precision (mAP50) and the average precision (AP) for each object category in the dataset. The methods compared include various low-light image enhancement techniques integrated with YOLOv3, along with the proposed YOLA method. The results show the performance improvement achieved by YOLA compared to existing techniques.
read the caption
Table 6: Quantitative comparisons of the ExDark dataset based on YOLOv3 detector.
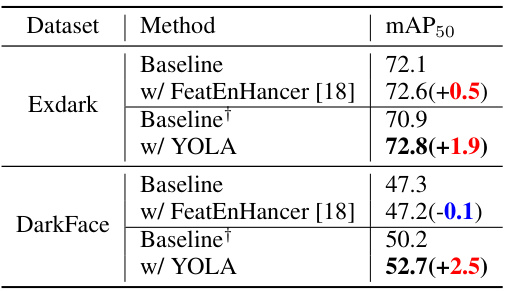
🔼 This table presents a quantitative comparison of the performance of YOLA and FeatEnhancer on the ExDark and UG2+DARK FACE datasets. The results are based on the RetinaNet object detection model. The table shows the mAP50 (mean Average Precision at IoU threshold of 0.5) for each method, along with the change in mAP50 compared to the baseline. Positive values indicate improvements, and negative values show performance degradation. The baseline results are shown for both standard and the authors’ alternate baseline implementation (indicated by †).
read the caption
Table 8: Quantitative comparisons (YOLA vs. FeatEnHancer) of ExDark and UG2+DARK FACE datasets based on RetinaNet. Red and blue colors represent improvement and degradation of performance, respectively, compared to the baseline. † indicates our implemented baseline.
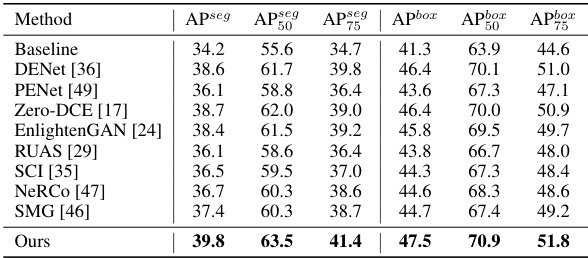
🔼 This table presents a quantitative comparison of different methods for low-light instance segmentation on the LIS dataset using Mask R-CNN. It shows the average precision (AP) for segmentation (APseg) and detection (Apbox) at different IoU thresholds (0.5, 0.75). The results demonstrate the superior performance of YOLA compared to other state-of-the-art methods, especially in terms of overall segmentation performance.
read the caption
Table 9: Quantitative comparisons of the LIS dataset based on Mask R-CNN, where APseg and Apbox indicate the average precision of segmentation and detection, respectively.
Full paper#