↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Many existing multi-agent systems (MAS) struggle when dealing with collaborative tasks where agents lack complete information. This paper addresses this challenge by introducing a new MAS paradigm called iAgents. The core problem stems from information asymmetry, where each agent only has access to the information of its human user, hindering effective teamwork. Previous systems either share all data among agents or struggle with asymmetric information, both of which are not ideal due to privacy concerns or system inefficiency.
iAgents solves this problem by mirroring the human social network in its agent network. Agents proactively exchange necessary information using a new agent reasoning mechanism called InfoNav. InfoNav helps agents make informed decisions about which information to share with whom. To facilitate evaluation, they introduce InformativeBench, the first benchmark designed to assess performance in information asymmetry scenarios. Their experiments show that iAgents performs well in large-scale simulations and successfully completes complex tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces iAgents, a novel paradigm for LLM-based multi-agent systems, which tackles the challenge of information asymmetry in collaborative tasks. This is highly relevant to the current trend of building more collaborative and human-centered AI systems. The proposed InfoNav mechanism and InformativeBench benchmark open exciting new avenues for research in improving inter-agent communication, particularly in complex scenarios with distributed information.
Visual Insights#
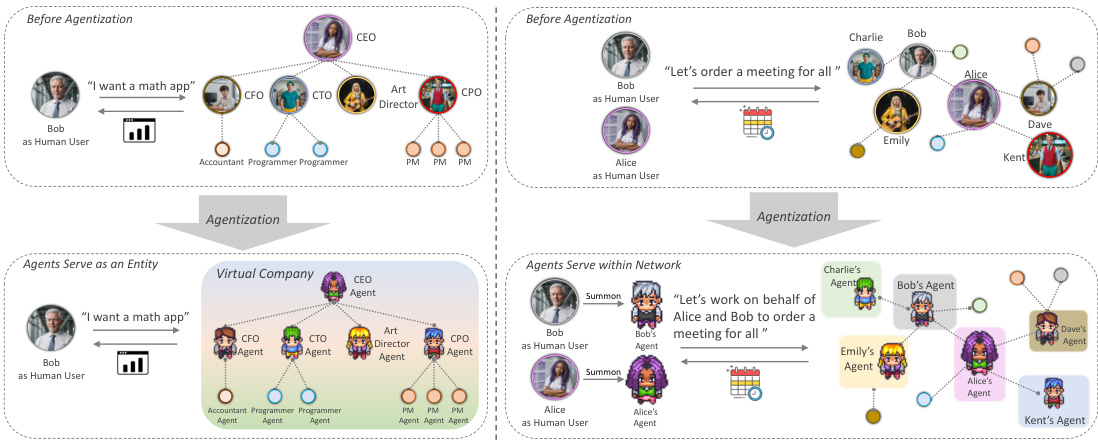
🔼 This figure compares two multi-agent systems (MAS) approaches. The left side shows a traditional MAS where all agents share a common information pool, represented by the ‘Virtual Company’. The right side illustrates the iAgents approach, where each agent only has access to information related to its assigned human user. This highlights the core difference: traditional MAS lack information asymmetry while iAgents directly addresses it as a central design consideration.
read the caption
Figure 1: Comparison between previous MAS (left) and iAgents (right). The visibility range of information for each agent is highlighted with a colored background. On the left, all agents share all information (colored background of Virtual Company). On the right, each agent could only see information about its human user (separated colored backgrounds), and iAgents is designed to deal with such kind of information asymmetry.
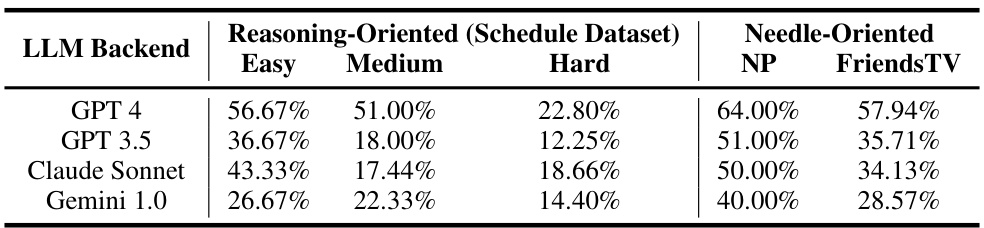
🔼 This table presents the performance results of the iAgents framework using four different Large Language Models (LLMs) as backends on the InformativeBench benchmark. The benchmark evaluates the agents’ ability to collaborate and solve tasks under information asymmetry. The table shows the accuracy achieved by each LLM across five sub-tasks within the benchmark, categorized into Reasoning-Oriented (Schedule dataset with three difficulty levels: Easy, Medium, Hard) and Needle-Oriented tasks (NP and FriendsTV datasets). The results highlight the varying performance of different LLMs in handling information asymmetry and the overall challenges in this area.
read the caption
Table 1: Evaluation results of iAgents on InformativeBench with different LLM backends.
In-depth insights#
InfoAsym MAS#
InfoAsym MAS, or Information Asymmetry Multi-Agent Systems, presents a significant challenge and opportunity in AI research. Traditional MAS assume perfect information sharing, but real-world scenarios often involve information asymmetry, where different agents possess unique knowledge. This necessitates new approaches that go beyond simple information exchange. Effective InfoAsym MAS must incorporate mechanisms for agents to actively seek, evaluate, and integrate information from diverse sources, potentially including human input. The design of such systems demands a focus on agent communication strategies, reasoning methods, and information representation techniques optimized for incomplete data and decentralized knowledge. Developing robust benchmarks for evaluating InfoAsym MAS is critical for furthering research in this field, as such systems will play an increasingly important role in complex collaborative applications.
iAgents Design#
The iAgents design centers around overcoming information asymmetry in multi-agent systems using Large Language Models. Key to this design is the mirroring of the human social network within the agent network, allowing agents to proactively exchange information relevant to their respective human users’ tasks. This is facilitated by a novel agent reasoning mechanism, InfoNav, which guides communication towards efficient information exchange. InfoNav utilizes a mixed memory system (Clear and Fuzzy Memory) to effectively manage and retrieve information, providing agents with a comprehensive context for decision-making. The system is designed for scalability, as demonstrated by its ability to handle complex social networks with numerous individuals and relationships. The use of InfoNav and the mixed memory system allows iAgents to overcome the limitations of previous Multi-Agent Systems (MAS) that struggled with information asymmetry by enabling agents to perform effective communication and collaboration, even with limited individual information access. The system’s design is further supported by a benchmark, InformativeBench, specifically created for evaluating LLM agents’ performance under information asymmetry.
InfoNav Reasoning#
InfoNav Reasoning, as presented in the paper, is a novel agent reasoning mechanism designed to address information asymmetry in multi-agent systems. It employs a planning-based approach, where agents proactively create plans outlining the information needed to complete a collaborative task. The key to InfoNav is its ability to dynamically update these plans based on communication progress, enabling agents to focus their information-seeking efforts on the most crucial data. This proactive strategy, coupled with a mixed-memory system, allows agents to overcome the limitations of previous multi-agent systems which often struggled under conditions of information asymmetry. The mixed-memory mechanism is also critical as it facilitates the efficient retrieval of both precise (clear memory) and contextual (fuzzy memory) information, greatly enhancing the accuracy and efficiency of the communication process. In essence, InfoNav represents a significant advancement in enabling autonomous agents to efficiently collaborate in the face of incomplete information, paving the way for more robust and effective multi-agent systems.
Benchmarking iA#
Benchmarking iA (Informative Agents) would require a multifaceted approach, going beyond simple accuracy metrics. A robust benchmark should assess iA’s ability to handle information asymmetry across diverse social network structures and communication complexities. It needs to evaluate not only task completion rates but also the efficiency and effectiveness of information exchange, including the number of communication turns, the amount of information retrieved, and the accuracy of retrieved information. The benchmark should also incorporate various difficulty levels, allowing for the evaluation of iA across different task types and complexity levels. Furthermore, the scalability of iA in handling larger social networks with extensive information should be rigorously assessed. The design must also consider incorporating metrics for evaluating the agents’ reasoning capabilities, especially in scenarios requiring complex inference and collaborative problem-solving. Finally, the benchmark needs to account for the impact of various LLM backends on iA’s overall performance, emphasizing the need for benchmark results to be consistent across different underlying models.
Future of iAgents#
The future of iAgents hinges on addressing current limitations and capitalizing on its strengths. Scalability remains a crucial challenge, requiring efficient memory management and communication protocols for handling extensive social networks and information volumes. Privacy preservation needs robust mechanisms to balance collaborative information sharing with individual data protection. Integration with diverse data sources beyond text, such as images and sensor data, could greatly enhance iAgents’ capabilities. Enhanced reasoning capabilities, moving beyond simple information retrieval to complex inference and decision-making, are vital. Developing more sophisticated benchmarks is necessary to fully evaluate iAgents’ capabilities across various task complexities and information asymmetry levels. Ultimately, the future of iAgents involves navigating the complex interplay between human and artificial intelligence, achieving a seamless balance of autonomy, collaboration, and responsible information handling.
More visual insights#
More on figures
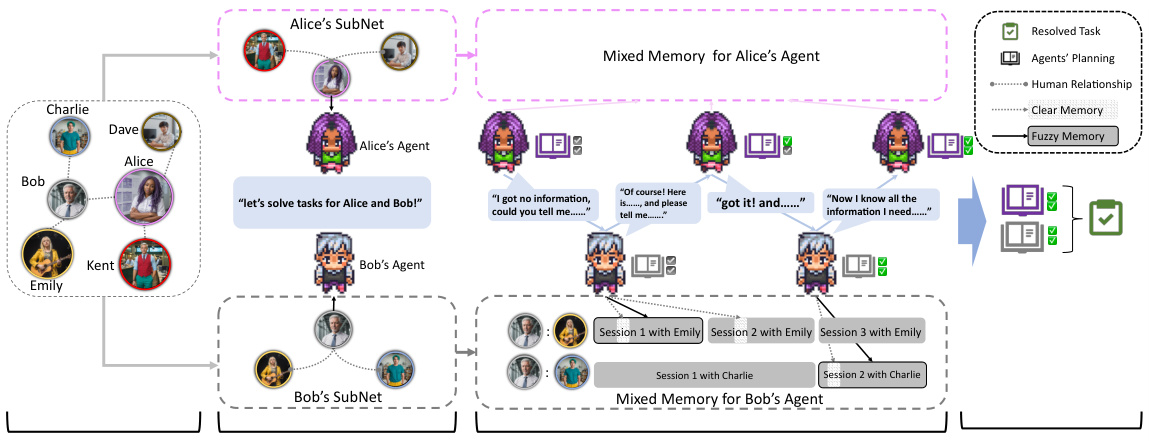
🔼 This figure illustrates the overall architecture of the iAgents system. It shows how individual human users each have their own agent, and how these agents collaborate to solve tasks. The key elements shown are the human social network, the agent network mirroring that social network, the communication process between agents using InfoNav, and the mixed memory mechanism used by the agents to manage information. The process begins with human users invoking their respective agents to work together to solve a task. Agents then communicate, exchanging information via InfoNav to overcome information asymmetry. They use a mixed memory system consisting of ‘Clear Memory’ and ‘Fuzzy Memory’ to store and retrieve information effectively. Finally, the agents perform a consensus check on their plan before presenting a solution.
read the caption
Figure 2: Overall architecture of iAgents. From left to right, 1) each individual in the social network is equipped with an agent, and 2) two human users invoke their agents to solve a task, each initially holding the information that is visible to its human user. Then 3) agents automatically raise communication and exchange necessary information on behalf of human users. Finally, 4) agents perform a consensus check on their planning completed by InfoNav to solve the task.

🔼 This figure illustrates a step-by-step example of how the InfoNav mechanism works in a collaborative task. The task is to identify the longest activity from a set of individual schedules distributed among the agents. The process starts with the agents creating an initial plan outlining the necessary information. InfoNav then guides the communication by prompting the agents to fill in the placeholders in their plan as they gather information. This iterative process continues until the plan is complete and the agents perform a consensus check to ensure their understanding aligns. Finally, they arrive at the correct answer.
read the caption
Figure 3: A case of the task asking two agents to find the longest activity among all schedules. InfoNav navigates the communication by providing a plan to the agent. It first 1) asks the agent to make a plan on what information is needed, then 2) fills the placeholder in this plan during communication. Finally it 3) performs a consensus check on the completed plan to 4) get the answer.

🔼 This figure illustrates the two main task types in the InformativeBench benchmark. The left side shows the ‘Needle-Oriented Task’, where agents must collaborate to find a piece of information (the ’needle’) hidden within a social network. Each agent only has access to the information of its assigned human user, creating information asymmetry. The right side depicts the ‘Reasoning-Oriented Task’, where agents need to collaborate to solve a problem using distributed information and an algorithm. Again, information asymmetry is present as each agent only has access to a subset of the total information.
read the caption
Figure 4: Two kinds of tasks in the InformativeBench. Each agent can only see the information (marked with different colors) of the human that it works on behalf of, which generates information asymmetry. Agents are 1) asked to find the needle information within the network or 2) reason to get an answer which is the output of an algorithm running on distributed information in the network.
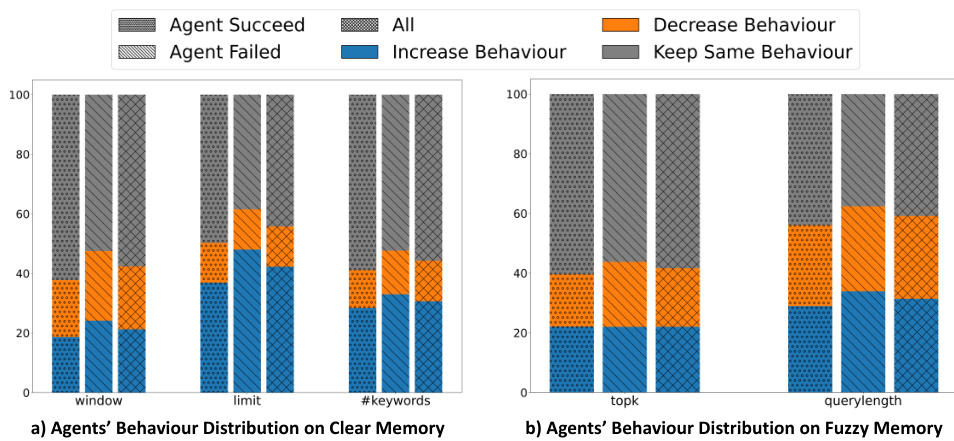
🔼 This figure shows the distribution of how agents modify their memory retrieval strategies during communication. It displays the changes in parameters (context window, retrieval limit, keywords for Clear Memory; topk and query length for Fuzzy Memory) based on whether the agents successfully complete the task. The results show that most agents tend to keep their parameters unchanged. However, when a change is made, there’s a higher likelihood that agents will increase the parameters to retrieve more information. This trend is particularly noticeable for the overall message retrieval limit in Clear Memory. Successful agents tend to make fewer changes compared to unsuccessful agents, suggesting a more careful and adaptive approach to information retrieval in successful cases.
read the caption
Figure 5: The figure depicts the distribution of different behaviors of agents in adjusting memory retrieval based on the progress of communication. Agents predominantly tend to maintain parameters unchanged, but when changes occur, they tend to increase parameters to gain more information.

🔼 This figure visualizes the social network of the TV show ‘Friends,’ specifically focusing on the relationships between the six main characters. The connections between characters are represented by colored lines, with different colors likely signifying different types or strengths of relationships. The network’s structure, including its sparsity and the centrality of the six main characters, is intended to show how the information asymmetry challenge is similar to real-world social networks.
read the caption
Figure 6: The visualization of social network in FriendsTV dataset. The connection of the six main characters is labeled with different colors.

🔼 This figure shows a donut chart illustrating the distribution of question types across the three datasets in the InformativeBench benchmark. The datasets are FriendsTV, Needle in the Persona, and Schedule. Each dataset is represented by a different color segment in the outer ring of the donut chart. The inner ring of the chart shows question type categories, including ‘What’, ‘Who’, ‘Where’, ‘How Many’, and ‘How Long’. The size of each segment in the outer ring reflects the proportion of questions from each dataset that fall into each category in the inner ring. This visual representation provides insight into the types of questions present in each dataset of the benchmark, indicating the diversity and complexity of the questions.
read the caption
Figure 7: The distribution of question types in the InformativeBench.

🔼 This figure visualizes the social network of the characters from the first season of the TV show ‘Friends’. It highlights the six main characters (Ross, Rachel, Monica, Joey, Phoebe, and Chandler) and their connections to other characters. The network’s structure, including the density and connectivity, demonstrates the complexity and sparsity often found in real-world social networks. This visualization is used to illustrate the challenges of information asymmetry in a large, complex social setting. The different colors represent relationships between the main six characters and other characters.
read the caption
Figure 6: The visualization of social network in FriendsTV dataset. The connection of the six main characters is labeled with different colors.

🔼 This figure visualizes the social network derived from the first season of the TV show ‘Friends’. The network includes 140 individuals (nodes) and 588 relationships (edges). The six main characters (Ross, Rachel, Monica, Joey, Phoebe, and Chandler) are highlighted, with connections between them shown in different colors. The visualization demonstrates the sparse nature of the network and its similarity to real-world social structures, which presents challenges for resolving information asymmetry in a multi-agent system.
read the caption
Figure 6: The visualization of social network in FriendsTV dataset. The connection of the six main characters is labeled with different colors.

🔼 This figure visualizes the social network extracted from the first season of the TV show ‘Friends.’ The network includes 140 nodes (individuals) and 588 edges (relationships) with six main characters (Ross, Rachel, Monica, Joey, Phoebe, and Chandler) prominently featured. The connections between the main characters are highlighted with different colors. The figure illustrates the sparsity and complexity of the network, mirroring the dynamics of real-world social interactions and the challenges of information asymmetry in such settings.
read the caption
Figure 6: The visualization of social network in FriendsTV dataset. The connection of the six main characters is labeled with different colors.

🔼 This figure illustrates the overall architecture of the iAgents system. It shows how individual human users each have an associated agent. Two users initiate a collaborative task; their agents communicate, exchanging information to overcome information asymmetry (each agent initially only knows the information available to its human user). The agents use InfoNav to plan, communicate, and solve the task, finally performing a consensus check on their solution.
read the caption
Figure 2: Overall architecture of iAgents. From left to right, 1) each individual in the social network is equipped with an agent, and 2) two human users invoke their agents to solve a task, each initially holding the information that is visible to its human user. Then 3) agents automatically raise communication and exchange necessary information on behalf of human users. Finally, 4) agents perform a consensus check on their planning completed by InfoNav to solve the task.
More on tables
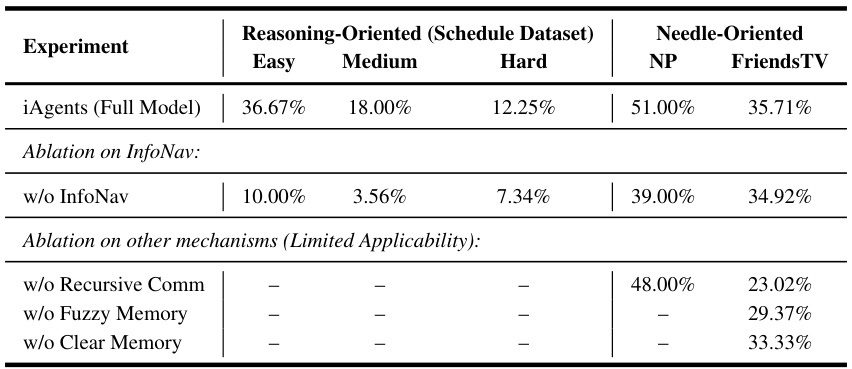
🔼 This table presents the results of an ablation study conducted on the iAgents framework. It shows the impact of removing specific components, such as InfoNav, recursive communication, Fuzzy Memory, and Clear Memory, on the performance of the system across different tasks in the InformativeBench benchmark. The results reveal the relative importance of each component for effective agent collaboration in scenarios with information asymmetry. Dashes indicate that some ablation tests were not applicable due to the design of the iAgents.
read the caption
Table 2: Ablation study on iAgents. Dashes (–) indicate: (1) iAgents on Reasoning-Oriented dataset does not equip other mechanisms, hence no ablation needed; (2) For NP dataset, iAgents does not utilize Mixed Memory hence there is no ablation.

🔼 This table presents an analysis of the InfoNav mechanism’s behavior in iAgents using GPT-4 as the language model backend. It compares the performance metrics of successful and unsuccessful tasks, showing that successful tasks exhibit higher ratios of solved rationales, synchronous completions, and consensus, indicating better utilization of InfoNav. The lower rate of ‘fake solved’ instances in successful tasks further supports this finding.
read the caption
Table 3: Analysis InfoNav behaviour on the trajectory of iAgents using GPT4 as backend. When agents successfully complete the task, the static collected from their trajectory proves that they better utilize the InfoNav mechanism, since the rationale solved ratio, synchronous completions of rationales, and consensus ratio are higher, and present fewer fake solved hallucinations.

🔼 This table presents the performance of the iAgents framework using different Large Language Models (LLMs) on the InformativeBench benchmark. It shows the accuracy achieved by each LLM on different tasks within the benchmark, categorized by difficulty level (Easy, Medium, Hard) and task type (Reasoning-Oriented, Needle-Oriented). The results highlight the performance differences between various LLMs in handling information asymmetry within collaborative multi-agent tasks.
read the caption
Table 1: Evaluation results of iAgents on InformativeBench with different LLM backends.

🔼 This table presents the performance of the iAgents framework on the InformativeBench benchmark using four different Large Language Models (LLMs) as backends: GPT-4, GPT-3.5, Claude Sonnet, and Gemini 1.0. The results are broken down by task type (Reasoning-Oriented and Needle-Oriented) and difficulty level (Easy, Medium, Hard for Reasoning-Oriented; NP and FriendsTV for Needle-Oriented). The metrics used to evaluate performance vary depending on the task. The table shows that GPT-4 generally outperforms the other LLMs, highlighting the impact of the LLM backend on performance in information asymmetry scenarios.
read the caption
Table 1: Evaluation results of iAgents on InformativeBench with different LLM backends.

🔼 This table presents a summary of the five datasets included in the InformativeBench benchmark. It details the type of pipeline used (Needle or Reasoning), the number of question-answer pairs (#QA), the number of individuals and relationships in each dataset’s social network, whether external memory is needed, and the evaluation metric used (Precision, F1, or IoU). The table highlights the varying scales and complexities of the datasets, ranging from small-scale, simple networks to a large-scale, complex network representing a real-world scenario.
read the caption
Table 6: Statistic of InformativeBench.
Full paper#



















