TL;DR#
This research investigates how large language models (LLMs), specifically ChatGPT, perpetuate and amplify social biases in job application materials. Existing bias detection methods often rely on manual word counts or simple similarity measures, failing to capture the nuances of language and context. These methods also often do not use validated inventories of social cues. This study shows a need for more sophisticated approaches that can effectively capture the complex interplay of words and context in assessing AI bias.
The researchers propose a novel bias evaluation framework called PRISM (Probability Ranking bias Score via Masked Language Model). PRISM leverages the power of masked language models to assess bias within texts, incorporating validated word lists from social science research to provide contextual sensitivity. Using PRISM, the study analyzes ChatGPT-generated job applications in response to real job advertisements. The results demonstrate a correlation between biases in job postings and the language generated by ChatGPT, highlighting how AI systems can reproduce and even amplify existing gender biases. The findings underscore the urgent need for mitigation strategies to prevent AI from exacerbating societal inequalities in the labor market.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers studying AI bias, particularly in NLP and social sciences. It introduces a novel bias evaluation framework (PRISM) that addresses limitations of existing methods, offering a more nuanced and efficient way to quantify bias in text. The findings on gender bias in ChatGPT-generated job applications highlight the potential for AI to exacerbate existing societal inequalities, prompting critical discussions and urging researchers to develop mitigation strategies. The study paves the way for further research into the broader societal impact of AI bias and the development of more equitable AI applications.
Visual Insights#
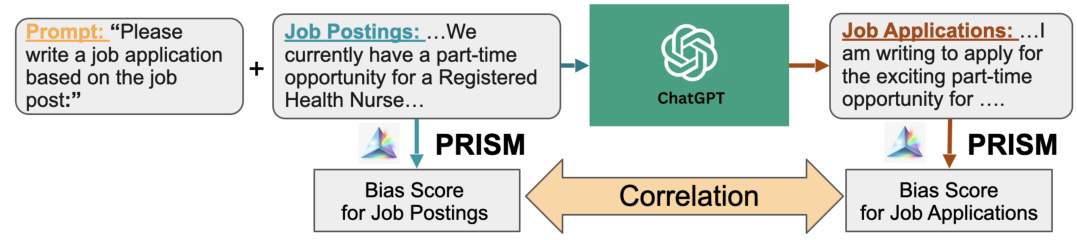
🔼 This figure illustrates the experimental design used in the study to investigate social bias in ChatGPT-generated job applications. Real job postings are fed into ChatGPT, which then generates job applications. Both the original job postings and the generated applications are analyzed using the PRISM algorithm to measure bias scores. Finally, the correlation between bias scores of the job postings and the generated applications is calculated to determine if and how biases are reproduced or amplified by the model.
read the caption
Figure 1: Overview of the paradigm for bias probing experimental design.

🔼 This table summarizes the statistical significance tests performed to analyze how ChatGPT influences bias reproduction in job applications. It shows whether the mean bias score shifts towards masculine or feminine language, whether the magnitude of the bias increases or decreases, and whether the variance of bias scores changes from job postings to job applications, across four different dimensions of gender bias. Detailed statistical results are available in supplementary tables.
read the caption
Table 1: Statistical testing results for each dimension. The mean result indicates whether the overall bias score is shifting toward the masculine (↑) or feminine (↓) direction. The magnitude result reveals whether the bias is moving toward zero (↓) or away from zero (↑). The variance assesses whether job application bias scores exhibit greater (↑) or lesser (↓) variance compared to the job postings. Please refer to Table 2, 3, 4 and 5 in Appendix for detail statistics.
In-depth insights#
Bias Detection#
The paper tackles the crucial problem of bias detection in the context of large language models (LLMs), specifically focusing on how these models perpetuate social biases, especially gender bias, in the generation of job application materials. The core of the bias detection strategy is PRISM, a novel algorithm that leverages Masked Language Models (MLMs) and pre-defined word lists from social science research to quantitatively assess bias in text. PRISM’s strengths lie in its efficiency, computational flexibility, and robustness; it avoids costly human-labeled data and model training, offering a scalable and adaptable method. The study evaluates PRISM through rigorous validation, demonstrating high accuracy in identifying biases, and then applies it to analyze both job postings and AI-generated applications to reveal how LLMs can amplify existing biases. This systematic approach, combined with insightful statistical analysis, delivers valuable conclusions about bias propagation and mitigation strategies for this emerging technology.
PRISM Algorithm#
The PRISM algorithm, as described, presents a novel approach to bias detection in text by leveraging masked language models (MLMs). Its key innovation lies in combining the power of MLMs with validated word lists from social science research. This framework moves beyond simple keyword counting, offering contextual sensitivity by assessing bias based on the probability of masked words being replaced with gendered terms. The algorithm’s strength lies in its efficiency, not requiring costly human-annotated training data. This makes it particularly scalable and flexible, enabling researchers to adapt it to various bias dimensions by simply changing the word lists. Furthermore, PRISM’s reliance on ranking, rather than raw probability scores, enhances robustness and minimizes the influence of outliers. This method also provides a systematic and quantitative measure of bias, allowing researchers to better understand the presence and direction of gender bias in text and potentially other forms of bias as well. However, its performance might be influenced by the choice of MLM and potential biases inherent in pre-trained models. Future research could explore these limitations.
ChatGPT Bias#
The concept of “ChatGPT Bias” encapsulates the systematic biases present within the ChatGPT model, stemming from its training data and inherent architectural limitations. Bias manifests in various forms, including gender bias (favoring masculine language), racial bias, and socioeconomic bias, impacting the quality and fairness of the model’s output. The research paper likely explores how these biases affect different applications, particularly focusing on job applications. It might demonstrate how a biased training dataset leads to biased outputs, reinforcing existing societal inequalities. The study likely proposes methods to quantify and mitigate these biases, potentially using novel algorithms or existing frameworks adapted for this specific task. A crucial aspect is analyzing the impact of this bias on the labor market, where it could disproportionately affect job seekers from certain demographics and perpetuate discriminatory hiring practices. Addressing ChatGPT bias is essential for ensuring fairness and equity in AI applications.
Future Work#
Future research directions stemming from this work on social bias in AI-generated job applications are multifaceted. Extending the PRISM algorithm to encompass a wider array of biases beyond gender, such as racial or socioeconomic bias, is crucial. This involves developing robust and validated word lists for these biases and ensuring the algorithm’s effectiveness across diverse linguistic contexts. Investigating the impact of different prompting strategies on bias propagation in ChatGPT-generated texts is another key area. Exploring how varying degrees of prompt specificity or the incorporation of counter-stereotypical cues might affect bias could offer valuable insights. Examining the downstream effects of bias in AI-generated job applications on hiring practices and subsequent labor market outcomes warrants further investigation. A longitudinal study tracking the career trajectories of individuals whose applications were generated by AI could reveal important long-term consequences. Cross-cultural comparisons are necessary to determine whether the observed biases are specific to certain cultures or reflect broader societal issues. Finally, developing effective mitigation strategies that address the biases identified in this research is vital. This might involve training data augmentation, algorithmic debiasing techniques, or user-friendly interfaces that help users identify and correct biases in their applications. This comprehensive approach will lead to more impactful advancements.
Method Limits#
A critical examination of a research paper’s methodology necessitates a dedicated section on method limits. This would involve identifying potential weaknesses, biases, and constraints inherent in the approach. Specific limitations could include sample size (too small to draw robust conclusions), data quality (affecting the reliability of findings), generalizability (results might not apply to other contexts), or the chosen analytical methods (potentially overlooking crucial factors). For instance, limitations stemming from the use of a specific algorithm or model, such as its inherent biases or limitations in handling certain types of data, would need thorough discussion. It is vital to acknowledge the influence of uncontrolled variables that could confound results and discuss the implications of these limitations on the interpretation of findings. A comprehensive analysis of method limits must be accompanied by a frank and transparent assessment of the study’s strengths and weaknesses to ensure responsible research practices. Addressing potential confounding factors and alternative interpretations is essential to promoting robust and reliable research. Overall, a robust discussion of the method’s limitations enhances the credibility of the research and aids in responsible interpretation of the findings. It is important to outline how these limitations might impact the broader implications of the research to provide a balanced analysis of the entire research process.
More visual insights#
More on figures

🔼 This figure illustrates the PRISM algorithm’s workflow. It starts with a text input which is then processed by masking each word sequentially. A Masked Language Model (MLM), such as BERT, predicts the probability of different words replacing the masked word. The probabilities for masculine and feminine words from predefined lists are extracted. These probabilities are merged, ranked, and then used to calculate a bias score. A positive score indicates masculine bias, while a negative score indicates feminine bias.
read the caption
Figure 2: An illustration of the paradigm for PRISM that uses word lists for directional cues with MLM to compute bias score for text.
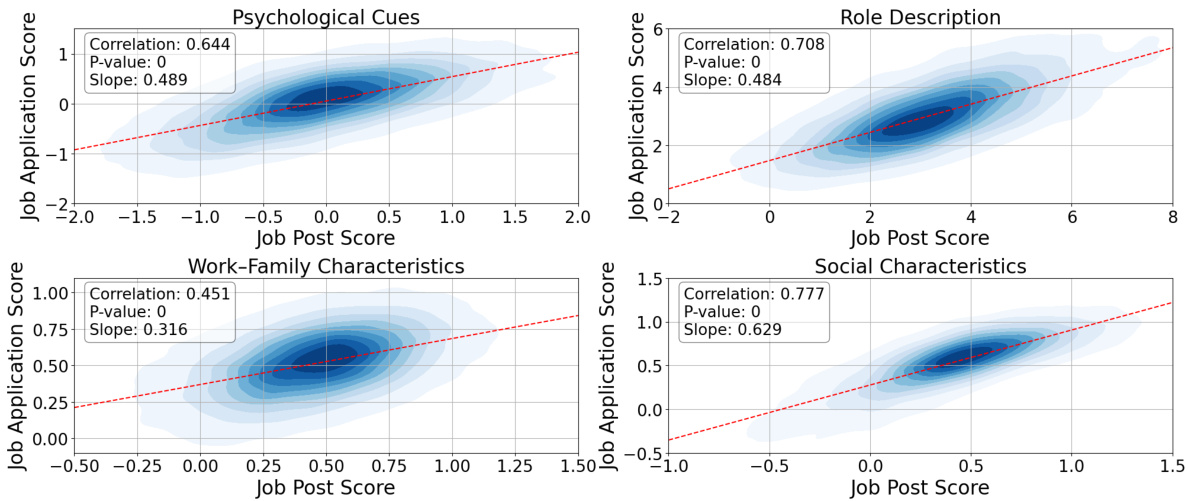
🔼 This figure shows the correlation between bias scores in job postings and the corresponding job applications generated by ChatGPT. Each subplot represents one of four dimensions of gender bias (Psychological Cues, Role Description, Work-Family Characteristics, Social Characteristics). The x-axis represents the bias score of the job posting, and the y-axis represents the bias score of the generated application. The density of points illustrates the strength of the correlation, with darker areas indicating more data points and thus a stronger correlation. A red line represents the linear regression fit; its slope indicates the degree to which bias in the posting is reproduced in the application. The correlation coefficient and p-value are provided for each dimension.
read the caption
Figure 3: Result scatter density plot, for each of the bias dimensions where the x-axis is the job posting bias score and the y-axis is the job applications bias score. Where the darker color means there are more dots. The p-value is the significance of the correlation coefficient.

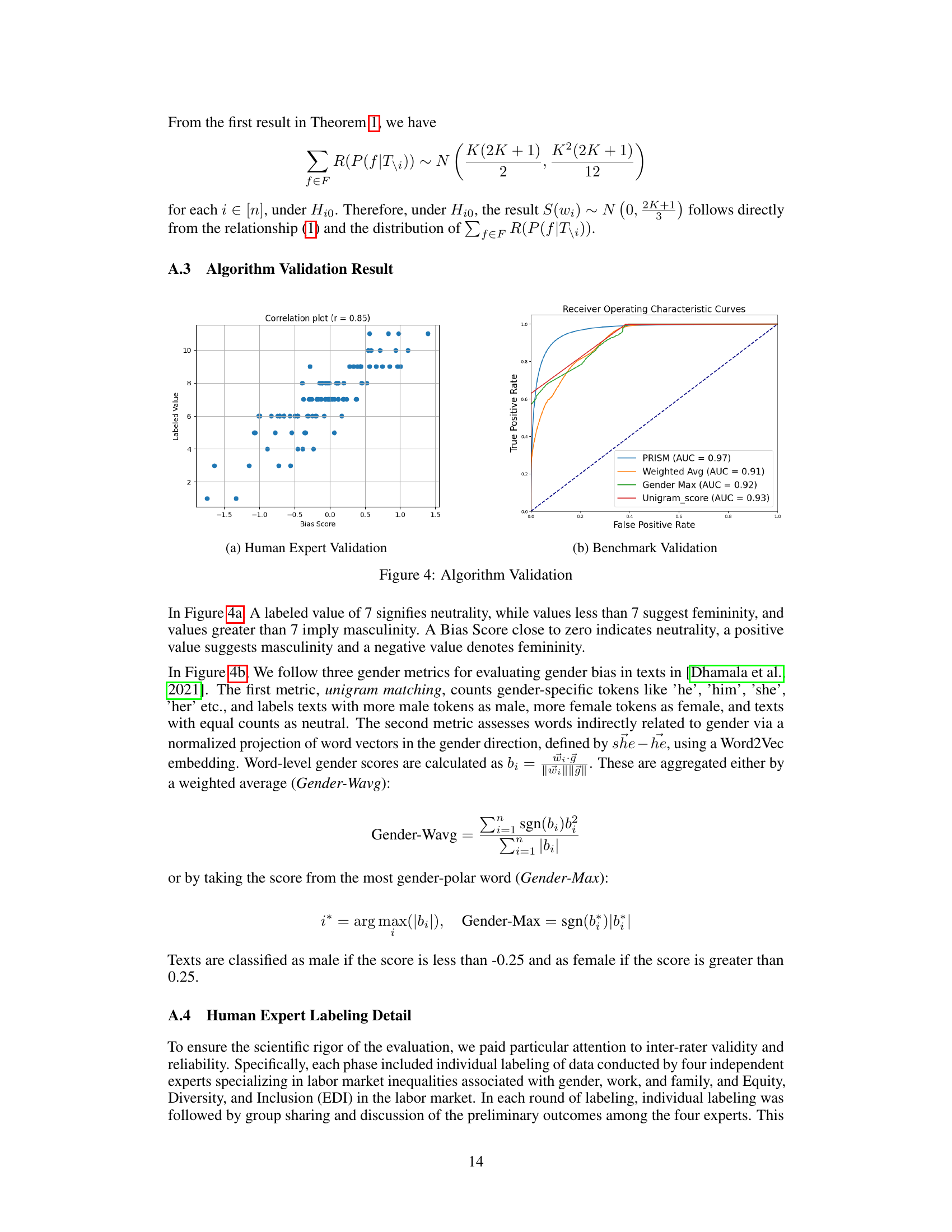
🔼 This figure shows the results of algorithm validation using two different methods: human expert validation and benchmark validation. The left panel (a) displays the correlation between human expert ratings and algorithm scores, showing a strong positive correlation (r = 0.85). The right panel (b) presents the receiver operating characteristic (ROC) curves comparing the algorithm’s performance against three baseline methods for classifying gender bias in text. The algorithm (PRISM) significantly outperforms the baselines, with an area under the curve (AUC) of 0.97, while the baselines range from 0.91 to 0.93.
read the caption
Figure 4: Algorithm Validation
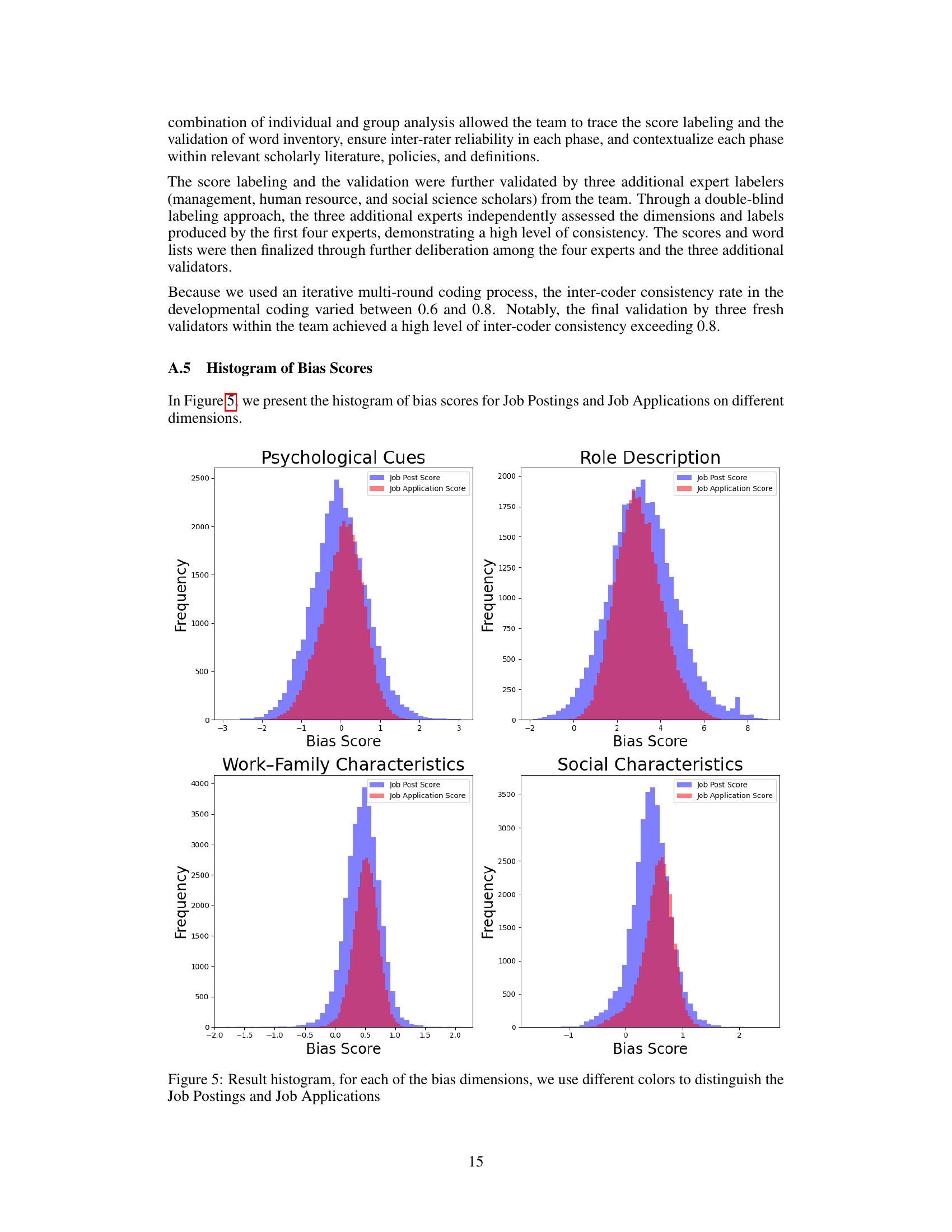
🔼 This figure shows the correlation between bias scores in job postings and corresponding job applications generated by ChatGPT across four dimensions of gender bias (Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics). Each scatter plot visualizes the relationship, with the x-axis representing the bias score of the job posting and the y-axis representing the bias score of the generated job application. The density of points indicates the concentration of data points in specific regions, while the correlation coefficient and its p-value (significance level) quantify the strength and statistical significance of the linear relationship between the two sets of bias scores for each dimension. The plots illustrate whether the biases present in job postings are mirrored or amplified in the AI-generated applications.
read the caption
Figure 3: Result scatter density plot, for each of the bias dimensions where the x-axis is the job posting bias score and the y-axis is the job applications bias score. Where the darker color means there are more dots. The p-value is the significance of the correlation coefficient.
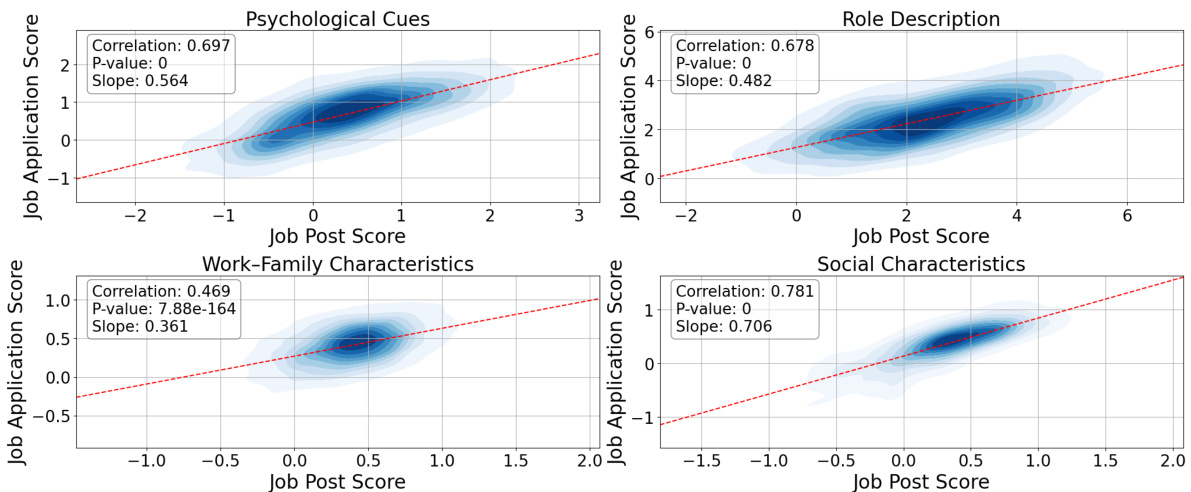
🔼 This figure shows the correlation between bias scores in job postings and the corresponding job applications generated by ChatGPT, for four different dimensions of gender bias: Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics. Each scatter plot displays the relationship between the bias scores of the job postings (x-axis) and the job applications (y-axis). The density of points is represented by color intensity, with darker shades indicating a higher concentration of data points. A regression line is fitted to each scatter plot, showing the correlation strength. The p-value for each correlation is also provided, indicating the statistical significance of the relationship.
read the caption
Figure 3: Result scatter density plot, for each of the bias dimensions where the x-axis is the job posting bias score and the y-axis is the job applications bias score. Where the darker color means there are more dots. The p-value is the significance of the correlation coefficient.
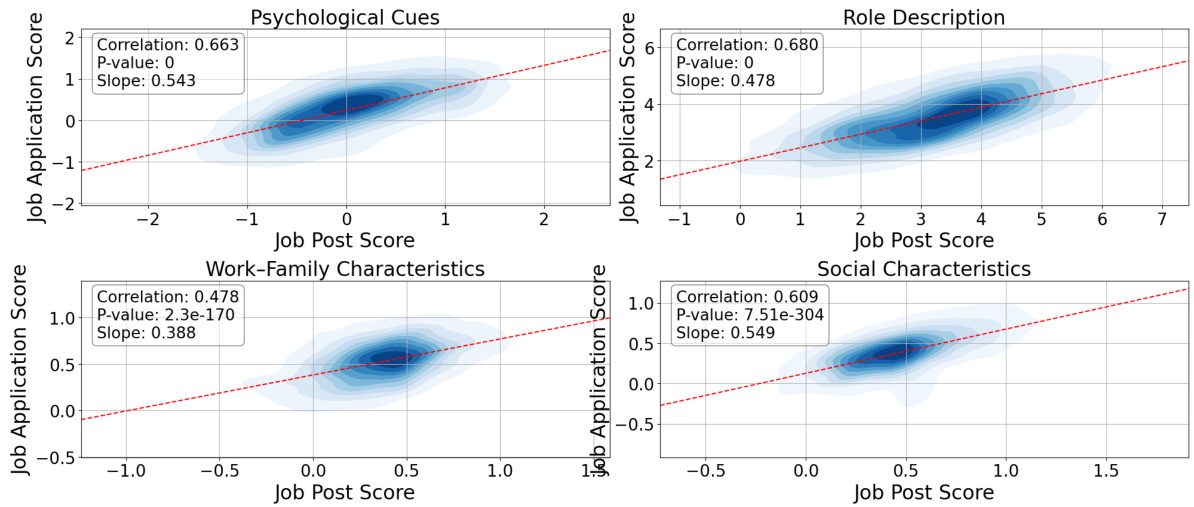
🔼 This figure shows scatter plots illustrating the correlation between bias scores in job postings and those in ChatGPT-generated job applications for four different dimensions of gender bias (Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics). Each plot visualizes the relationship between the bias scores of job postings (x-axis) and the corresponding job applications (y-axis). Darker colors indicate a higher density of points. The correlation coefficient and p-value for each dimension are displayed on the plot, indicating the strength and statistical significance of the correlation. The slope of the fitted line shows how strongly the job posting bias predicts the bias in the job applications.
read the caption
Figure 3: Result scatter density plot, for each of the bias dimensions where the x-axis is the job posting bias score and the y-axis is the job applications bias score. Where the darker color means there are more dots. The p-value is the significance of the correlation coefficient.

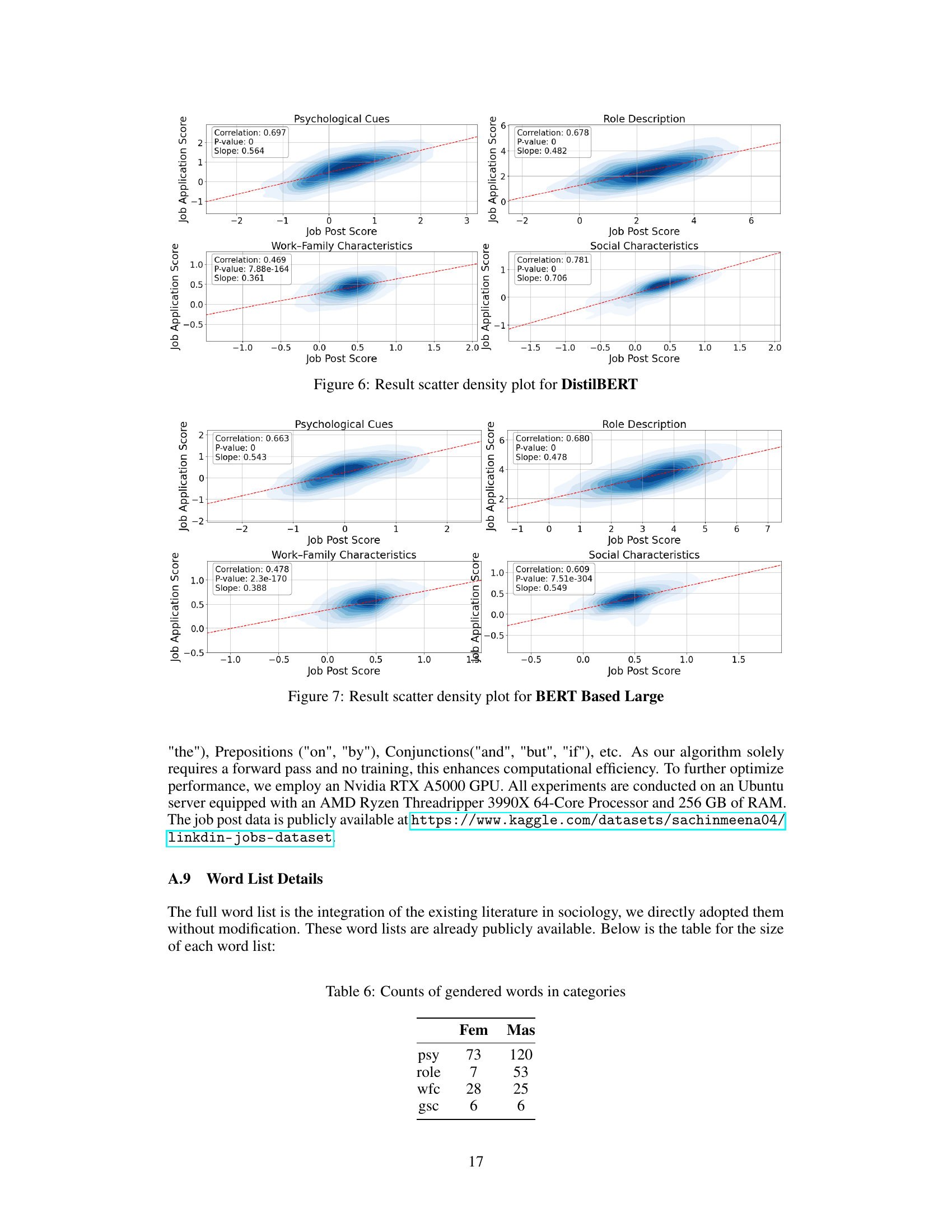
🔼 This figure shows the correlation between human expert labels and the bias scores generated by the algorithm for two different language models: distilBERT and BERT-large. The scatter plots visually represent the agreement between human judgment of gender bias in texts and the algorithm’s assessment. The correlation coefficient (r) is provided for each model, indicating the strength of the relationship. Higher correlation indicates better agreement between human assessment and the algorithm.
read the caption
Figure 8: Human Label Evaluation Correlation
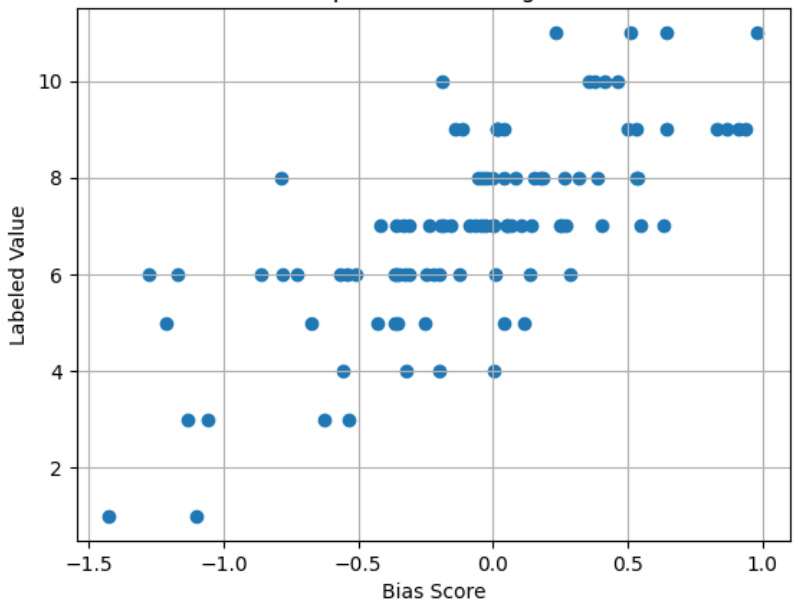
🔼 This figure shows the results of two algorithm validation tasks. Figure 4(a) displays a scatter plot illustrating the strong positive correlation (r=0.85) between human expert bias scores and the PRISM algorithm’s bias scores on a randomly selected subset of job advertisements. This demonstrates that PRISM effectively captures human perception of bias. Figure 4(b) presents the receiver operating characteristic (ROC) curve for the algorithm’s performance on the BIOS dataset, achieving an AUC of 0.97, exceeding the performance of three baseline methods (weighted average, gender max, and unigram score). This validates PRISM’s effectiveness in identifying gender bias in text.
read the caption
Figure 4: Algorithm Validation
More on tables
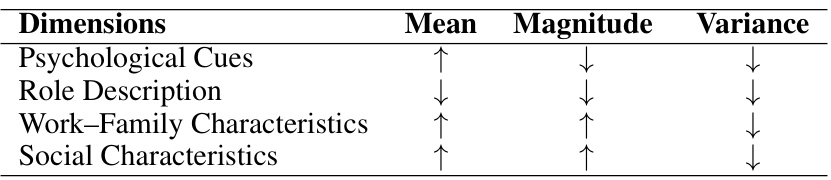
🔼 This table summarizes the statistical significance tests performed to analyze the shift in mean, magnitude, and variance of gender bias scores between job postings and ChatGPT-generated job applications across four dimensions: Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics. The arrows (↑ or ↓) indicate the direction of the change (increase or decrease).
read the caption
Table 1: Statistical testing results for each dimension. The mean result indicates whether the overall bias score is shifting toward the masculine (↑) or feminine (↓) direction. The magnitude result reveals whether the bias is moving toward zero (↓) or away from zero (↑). The variance assesses whether job application bias scores exhibit greater (↑) or lesser (↓) variance compared to the job postings. Please refer to Table 2, 3, 4 and 5 in Appendix for detail statistics.

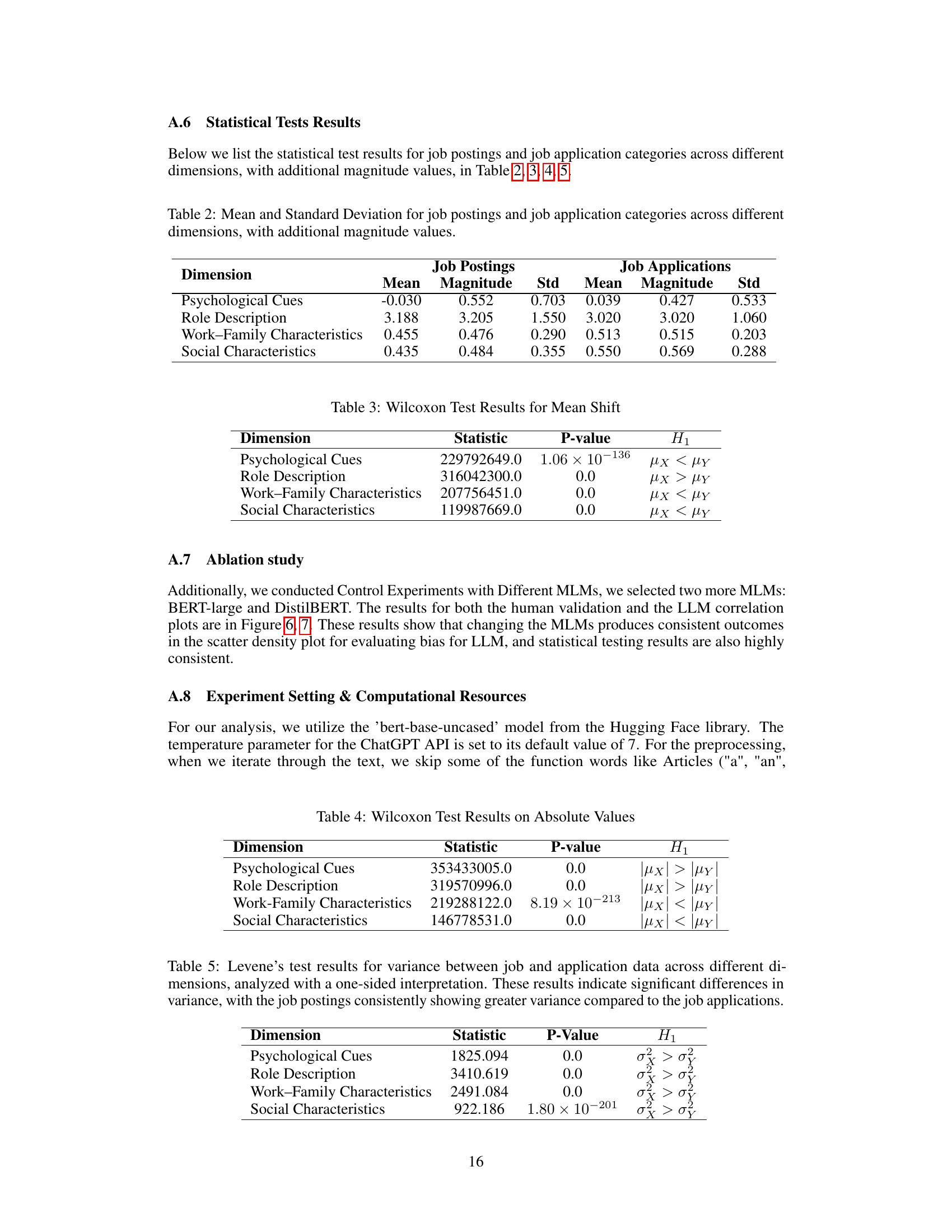
🔼 This table presents a statistical summary of bias scores for job postings and their corresponding AI-generated job applications, categorized across four dimensions: Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics. For each dimension and category (postings vs. applications), the mean bias score, the magnitude of the bias, and the standard deviation are provided. The magnitude represents the absolute value of the mean bias score, offering a measure of bias intensity regardless of direction.
read the caption
Table 2: Mean and Standard Deviation for job postings and job application categories across different dimensions, with additional magnitude values.

🔼 This table presents the results of Wilcoxon signed-rank tests, assessing whether there is a significant shift in the mean bias score from job postings to AI-generated job applications across four dimensions of gender bias (Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics). The ‘Statistic’ column displays the test statistic, ‘P-value’ indicates the statistical significance level, and ‘H1’ specifies the alternative hypothesis being tested (whether there is a shift to more masculine or feminine language).
read the caption
Table 3: Wilcoxon Test Results for Mean Shift

🔼 This table presents the results of Wilcoxon signed-rank tests performed to assess shifts in the magnitude of bias from job postings to ChatGPT-generated job applications across four dimensions. The Wilcoxon test assesses whether there’s a significant difference in the absolute values of the bias scores (regardless of direction, focusing on the overall intensity of bias). The table shows the test statistic, p-value, and the alternative hypothesis (H1) for each dimension. A low p-value indicates a statistically significant difference in bias magnitude. ‘μχ’ represents the mean bias score of job postings, and ‘μγ’ represents the mean bias score of job applications.
read the caption
Table 4: Wilcoxon Test Results on Absolute Values

🔼 This table presents the results of Levene’s test, which assesses the equality of variances between job postings and the corresponding ChatGPT-generated job applications across four dimensions of gender bias. A significant difference (p<0.05) indicates that the variance of the bias scores differs between job postings and applications for each dimension. The consistently higher variance in job postings suggests a wider range of bias expression in original job postings compared to the more homogenous bias expression generated by ChatGPT.
read the caption
Table 5: Levene's test results for variance between job and application data across different dimensions, analyzed with a one-sided interpretation. These results indicate significant differences in variance, with the job postings consistently showing greater variance compared to the job applications.

🔼 This table presents the counts of words categorized as feminine and masculine for four different dimensions: psychological cues (psy), role descriptions (role), work-family characteristics (wfc), and social characteristics (gsc). These word counts are used as part of the PRISM algorithm for bias evaluation. A higher number indicates a greater association with the specific gender.
read the caption
Table 6: Counts of gendered words in categories

🔼 This table summarizes statistical test results across four dimensions of gender bias: Psychological Cues, Role Description, Work-Family Characteristics, and Social Characteristics. For each dimension, it shows whether the average bias score shifted towards masculine or feminine language, whether the magnitude of the bias increased or decreased, and whether the variance (spread) of the bias scores changed in job applications compared to the original job postings. Detailed statistics are available in the appendix.
read the caption
Table 1: Statistical testing results for each dimension. The mean result indicates whether the overall bias score is shifting toward the masculine (↑) or feminine (↓) direction. The magnitude result reveals whether the bias is moving toward zero (↓) or away from zero (↑). The variance assesses whether job application bias scores exhibit greater (↑) or lesser (↓) variance compared to the job postings. Please refer to Table 2, 3, 4 and 5 in Appendix for detail statistics.
Full paper#