↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world machine learning applications face the challenge of adapting to constantly evolving data distributions. Traditional domain adaptation techniques often struggle when dealing with dynamic data streams and lack access to the original data sources. This makes it difficult to effectively transfer knowledge and maintain model performance over time. Existing multi-source approaches also suffer from issues of catastrophic forgetting, where the model loses its ability to perform well on previously-seen data distributions as it adapts to new ones.
The paper introduces CONTRAST, a novel method designed to address these challenges. CONTRAST intelligently combines multiple source models, each trained on a different data distribution, to optimally adapt to the incoming dynamic test data. It dynamically computes optimal combination weights and strategically updates only the most relevant model parameters for each test batch. This approach prevents catastrophic forgetting by avoiding unnecessary updates to less-relevant models. Experiments demonstrated that CONTRAST achieves performance comparable to the best source model and consistently maintains this performance even as the test distribution evolves.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on domain adaptation and continual learning, particularly in scenarios with dynamic data streams and limited access to source data. It provides a novel method (CONTRAST) that is both effective and robust, overcoming limitations of existing techniques and paving the way for more realistic and adaptable AI systems. The theoretical analysis further strengthens the method’s value, making it relevant to broader AI research on model ensembles and optimal weight combination for dynamic settings.
Visual Insights#
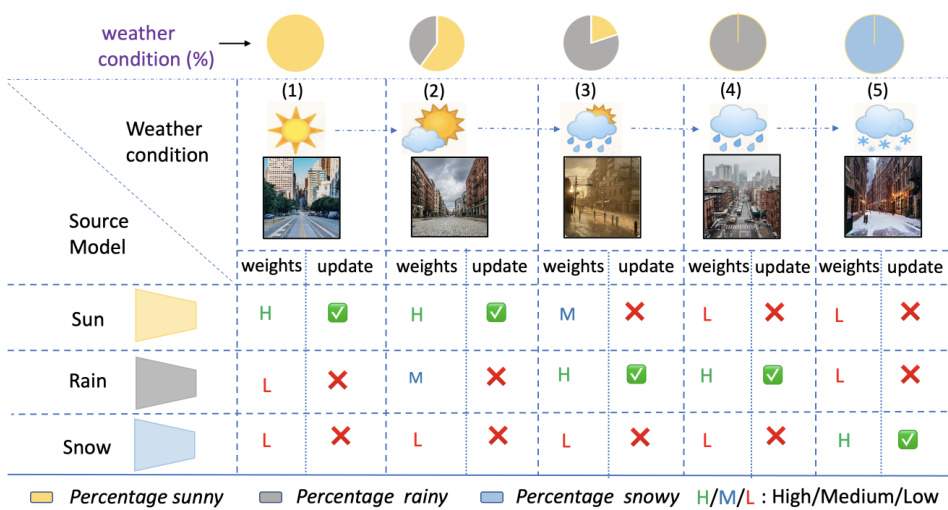
The figure illustrates a scenario where multiple source models, each trained on a specific weather condition (sunny, rainy, snowy), are used to make predictions on a test data set that has a dynamic mix of weather conditions. The pie charts at the top represent the proportions of different weather conditions in each test set. The goal is to automatically learn optimal combination weights for the source models and adapt only the models relevant to the current test data distribution.

The table compares the characteristics of different domain adaptation settings, including UDA, source-free UDA, and TTA. It highlights the unique aspects of the proposed CONTRAST approach, which addresses dynamic data distributions and the absence of source data, aspects not fully covered by existing methods. The comparison is based on the availability of source data for adaptation, whether adaptation happens during testing (on the fly), the presence of dynamic target distributions, and the use of multiple source models. CONTRAST is shown to be the only method that covers all these criteria.
In-depth insights#
Dynamic Adaptation#
Dynamic adaptation in machine learning focuses on algorithms’ ability to adjust to evolving data distributions. The core challenge lies in maintaining performance as the input data’s characteristics shift over time. This is crucial for real-world applications where data streams continuously and isn’t static. Effective dynamic adaptation strategies often involve online learning techniques, enabling models to update their parameters incrementally based on newly observed data. Ensemble methods which combine multiple models trained on different distributions can also be effective, as they provide robustness against sudden distribution changes. A key consideration is catastrophic forgetting, where the model loses performance on previously seen data distributions as it adapts to new ones. Approaches to mitigating this include regularization techniques and careful parameter updates, potentially focused only on parts of the model most relevant to the current data. The trade-off between adaptation speed and stability is a critical aspect of dynamic adaptation, as rapid adaptation may sacrifice accuracy or lead to instability, while slower adaptation might not respond adequately to fast-changing data.
Multi-Source Fusion#
Multi-source fusion, in the context of this research paper, is a crucial technique for handling dynamic data distributions. It allows the model to leverage the strengths of multiple pre-trained models, each with expertise in a different source domain, to enhance performance on a target domain. The approach is particularly beneficial when the target distribution is dynamic, evolving over time, and only accessible in small batches. CONTRAST, the proposed method, tackles this challenge by efficiently calculating optimal combination weights for integrating source models continuously, adapting to the incoming test data distribution. It also strategically updates only the most correlated model to the target data, mitigating the problem of catastrophic forgetting which is a major limitation in continual learning. This approach makes CONTRAST robust and efficient, performing on par with or even exceeding the best individual source model, highlighting its effectiveness in diverse settings. The theoretical insights presented add further credence to the practical findings. This method presents a significant advance in handling dynamic data streams when source data is unavailable or not accessible.
Catastrophic Forget.#
Catastrophic forgetting, a significant challenge in continual learning, describes the phenomenon where a model trained on new tasks forgets previously learned information. In the context of deep neural networks, this often manifests as a degradation in performance on older tasks as the model adapts to newer data distributions. This is especially problematic in scenarios like online adaptation where continuous learning is required and access to past data is limited or unavailable. Effective strategies to mitigate catastrophic forgetting often involve techniques that promote knowledge consolidation and preservation, such as regularization, memory replay, and carefully designed network architectures. Understanding and addressing catastrophic forgetting is crucial for developing robust and adaptable AI systems that can function effectively in dynamic environments and continue to improve their abilities over time without losing essential previously acquired skills. The core of the problem lies in the inherent plasticity of neural networks that can inadvertently overwrite previously established representations and weightings when learning new things. Addressing this requires innovative approaches that balance new learning with the retention of existing knowledge.
Theoretical Analysis#
A theoretical analysis section in a research paper would ideally delve into the mathematical underpinnings of the proposed method. It should rigorously justify the claims made and offer insights into why the method works, providing a deeper understanding beyond empirical results. A strong theoretical analysis would involve proofs of convergence, guarantees on performance bounds, and possibly a discussion of computational complexity. It might explore the method’s behavior under various conditions or assumptions, potentially comparing it to existing theoretical models. The analysis should highlight key assumptions and their limitations, clarifying the scope of the theoretical results. This section serves to strengthen the paper’s contributions, moving it beyond a purely empirical study and demonstrating a more profound understanding of the underlying principles. It increases the credibility and impact of the work by providing a firmer mathematical basis for the observed experimental results. Furthermore, it can provide guidance for future research directions by highlighting areas that require further investigation or suggest modifications or extensions to the method.
Broader Impact#
The broader impact of continual multi-source adaptation to dynamic distributions, as explored in the research paper, is multifaceted. On one hand, enhanced model robustness and adaptability across various domains and evolving data distributions offer significant potential benefits for numerous applications. These improvements might lead to safer and more reliable AI systems in autonomous vehicles or medical diagnoses, where the ability to handle unforeseen circumstances is crucial. Conversely, the potential for misuse should be carefully considered. The increased adaptability of the proposed model could inadvertently facilitate the creation of more sophisticated deepfakes or enhance adversarial attacks. Therefore, the development and deployment of such advanced AI systems requires a robust ethical framework to address potential misuse and promote responsible innovation. Transparency in model development and deployment is also crucial to foster public trust and facilitate oversight. Finally, access to necessary data and computational resources for training and evaluation is a significant factor influencing the feasibility and equitable distribution of benefits derived from this research.
More visual insights#
More on figures
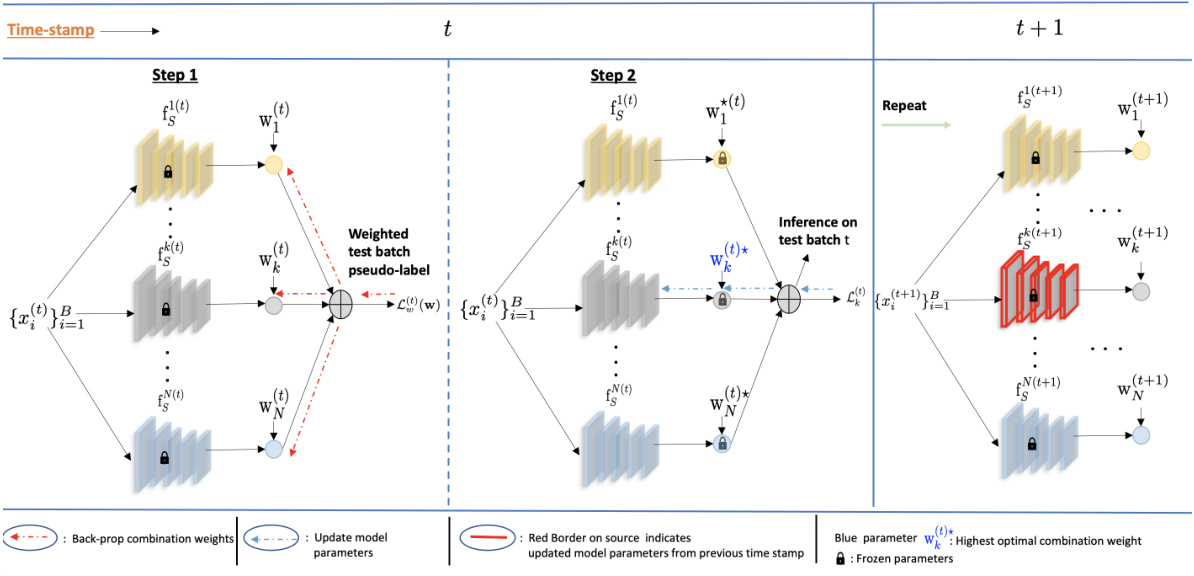
This figure illustrates the CONTRAST framework’s operation during the test phase. It involves two steps: first, calculating optimal combination weights for multiple source models based on the current test batch’s distribution; second, updating the parameters of the model most strongly correlated with the test distribution using existing test-time adaptation methods. The figure visually depicts these steps, highlighting the backpropagation of combination weights and model parameter updates. The use of a weighted pseudo-label aids in combining source model outputs.

This figure illustrates the CONTRAST framework’s two main steps for each test batch: 1) learning optimal combination weights for source models using weighted pseudo-labels and Shannon entropy minimization, and 2) updating parameters of the source model with the highest weight using a state-of-the-art TTA method. The figure visually depicts the flow of data, weight calculation, model updates and information between time steps, emphasizing the continuous adaptation process.
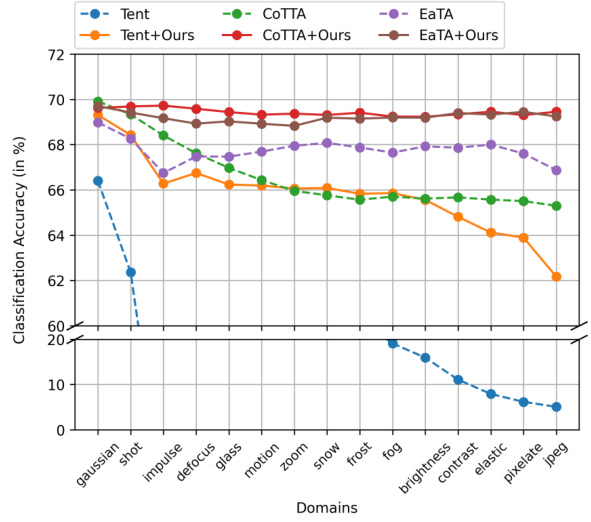
This figure compares the performance of CONTRAST against three baseline single-source test time adaptation methods (Tent, CoTTA, and EaTA) in terms of maintaining source knowledge during dynamic adaptation. The top panel shows the classification accuracy of each method across 15 noisy domains of CIFAR-100C. The bottom panel shows the loss of classification accuracy (forgetting) on the source test sets. The results demonstrate that CONTRAST effectively mitigates catastrophic forgetting, maintaining consistently high accuracy on source domains even after adapting to multiple target domains.

This figure compares the semantic segmentation results of CONTRAST with the baseline Tent method on the ACDC dataset. Four rows represent different weather conditions (rain, snow, fog, night) with the input image, ground truth mask, Tent-best results, and CONTRAST results. It visually demonstrates that CONTRAST provides better segmentation results than the baseline method, especially in challenging weather conditions.
More on tables

This table presents the results of experiments conducted on the CIFAR-100C dataset, which involves adapting four source models (trained on different weather conditions) to 15 sequential test domains with varying weather conditions. The table compares the performance of the proposed CONTRAST method against three baseline methods (Tent, EaTA, and COTTA), illustrating that CONTRAST consistently outperforms the best-performing single-source adaptation method (X-Best) across all test domains. The results highlight CONTRAST’s ability to optimally combine multiple source models and retain source knowledge effectively over time.
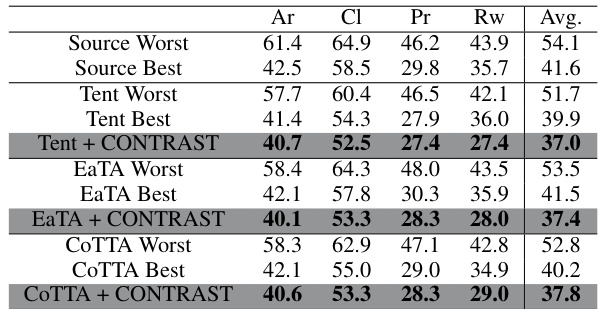
This table presents the results of the experiment conducted on the Office-Home dataset. The experiment is set up in a way that three source models are trained using three domains from the Office-Home dataset, and they are used for testing on the remaining domain. This is a test-time adaptation (TTA) setting. The table compares the performance of the proposed method (X+CONTRAST) with several baseline methods (X). The results show that the proposed method consistently outperforms all baselines in terms of error rate. The table highlights the effectiveness of the proposed method in adapting to the target domain even without access to the source data during the test-time adaptation.
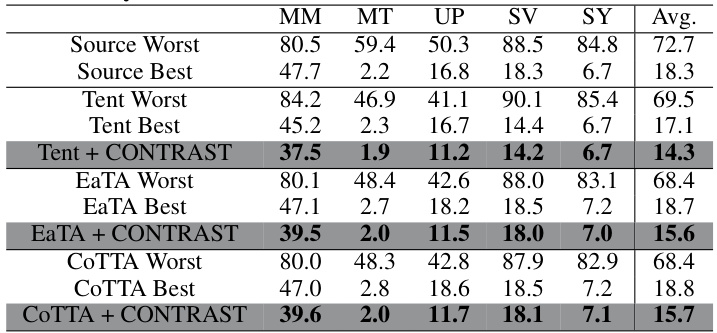
This table presents the results of the digit classification experiment. Four source models are trained on four different digit datasets (MNIST-M, MNIST, USPS, SVHN, and Synthetic Digits). Each column represents a target dataset (one of the five datasets is held out as a target for each test). The table shows that using the CONTRAST method with different test-time adaptation methods (Tent, EaTA, CoTTA) consistently outperforms the best individual source model for each adaptation setting. The table reports the error rate (percentage of misclassified samples) for each method and each dataset.

This table presents the results of applying CONTRAST and several baseline methods on the CIFAR-100C dataset. Four source models (trained on ‘Clear’, ‘Snow’, ‘Fog’, and ‘Frost’ conditions) are used for continual adaptation across 15 noisy test domains. The table shows error rates (%) for each method across the domains, demonstrating that CONTRAST consistently outperforms baseline single-source methods by effectively combining multiple source models while mitigating catastrophic forgetting.

This table presents the error rate results on the Office-Home dataset under the same experimental setting as Table 3 (Appendix) with Tent as the adaptation method, but with different initialization and learning rate choices for solving the optimization in (4). It is evident from the table that our chosen initialization and adaptive learning rate result in the highest accuracy gain.

This ablation study in Section D.1 of the paper compares the performance of CONTRAST using two different weight initialization methods: one based on entropy and another based on KL divergence. The results show that initializing weights based on KL divergence, which favors the most correlated source model, significantly outperforms entropy-based initialization, demonstrating the superiority of the proposed initialization strategy in achieving optimal performance.

This table presents an ablation study on the model update policy within the CONTRAST framework using CoTTA as the underlying single-source adaptation method. It compares the performance of four different strategies: updating all models, updating only the least correlated model, updating a subset of models based on weights, and updating only the most correlated model. The results, presented as error rates, show that updating only the most correlated model yields the best performance, highlighting the effectiveness of this approach in preventing catastrophic forgetting.

This table presents the ablation study on the model update policy of CONTRAST using CoTTA as the single-source adaptation method. It compares four different update strategies: updating all models, updating only the least correlated model, updating a subset of models, and updating only the most correlated model. The results, presented as error rates, show that updating only the most correlated model yields the best performance, highlighting the effectiveness of the proposed approach in mitigating catastrophic forgetting.

This table presents the results of applying CONTRAST and several baseline methods (Tent, COTTA, EaTA) on the CIFAR-100C dataset with 15 different noise types. Four source models (trained on clean images and three different noise types) are used for multi-source adaptation. The table shows the error rate for each method across all noise types, demonstrating the superiority of CONTRAST in achieving lower error rates while mitigating catastrophic forgetting. The ‘X-Best’ and ‘X+CONTRAST’ columns represent the best single-source performance and the performance when integrating each single-source method with CONTRAST, respectively.

This table compares the performance of CONTRAST+Tent against the DECISION method from a prior work on multi-source domain adaptation. The comparison highlights the superior performance of CONTRAST+Tent, particularly in online adaptation settings where data arrives in batches. The results are presented as error rates (percentage) across various noise conditions (GN to JPEG) in the CIFAR-100C dataset. The lower the error rate, the better the performance.

This table presents the results of applying the CONTRAST method and several baselines on the CIFAR-100C dataset. Four source models (trained on ‘Clear’, ‘Snow’, ‘Fog’, and ‘Frost’ conditions) are used, and their performance is evaluated across 15 different noisy test domains. The table compares the error rates (lower is better) of CONTRAST against several single-source adaptation methods (Tent, EaTA, COTTA), showing the best and worst performance achieved by each method across the 15 test domains. The results demonstrate that CONTRAST consistently outperforms even the best-performing single-source method in a dynamic setting, highlighting its effectiveness in combining source models and mitigating forgetting.

This table presents the results of semantic segmentation on the ACDC dataset using models trained on Cityscapes and its noisy variants. The experiment uses a static test distribution with various weather conditions. The table shows that the proposed CONTRAST method outperforms the baseline Tent method in terms of mean Intersection over Union (mIoU).

This table presents the results of the proposed CONTRAST method on the CIFAR-100C dataset, which involves 15 test domains with varying levels of noise (Snow, Fog, Frost). The table compares the performance of CONTRAST against several baseline methods (Tent, EaTA, and COTTA). Each baseline is tested both individually (X-Best and X-Worst) and integrated into CONTRAST (X+CONTRAST). The error rates (in %) are presented for each method, demonstrating that CONTRAST consistently outperforms the best individual baseline across all test domains.
Full paper#