TL;DR#
Existing methods for integrating Large Language Models (LLMs) and Graph Neural Networks (GNNs) often struggle with complex real-world textual graphs. These methods either focus on simpler graph tasks or deal poorly with graphs exceeding the LLM’s context window size. Furthermore, LLMs are susceptible to hallucinations, generating incorrect information.
To address these limitations, the paper proposes G-Retriever, a retrieval-augmented generation (RAG) method specifically designed for textual graphs. G-Retriever employs a Prize-Collecting Steiner Tree optimization problem to efficiently retrieve relevant subgraphs, enabling the handling of large graphs. The method also leverages soft prompting to enhance LLM performance and mitigate hallucination. The paper introduces a comprehensive benchmark, GraphQA, to evaluate the performance of various models on real-world tasks. Experiments show that G-Retriever significantly outperforms existing baselines on multiple datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with textual graph data and LLMs. It introduces a novel benchmark and a retrieval-augmented generation (RAG) method, G-Retriever, that significantly improves efficiency and mitigates hallucination in graph question answering. This opens new avenues for research in graph-based LLMs and their applications in various domains.
Visual Insights#

🔼 This figure showcases the model’s ability to answer complex and creative questions about three different types of textual graphs: explanation graphs, scene graphs, and knowledge graphs. The unified conversational interface allows users to interact with the graphs using natural language. The examples demonstrate the model’s versatility across multiple graph-related applications.
read the caption
Figure 1: We develop a flexible question-answering framework targeting real-world textual graph applications via a unified conversational interface. Presented here are examples showcasing the model's adeptness in handling generative and creative queries in practical graph-related tasks: common sense reasoning, scene understanding, and knowledge graph reasoning, respectively.

🔼 This table demonstrates the issue of hallucination in graph LLMs (Large Language Models) using a baseline method adapted from MiniGPT-4. The baseline uses a frozen LLM with a trainable GNN (Graph Neural Network). The table shows an example question about a graph, and compares the incorrect response with hallucinated nodes and edges given by the baseline LLM, with the correct response generated by the proposed G-Retriever method, along with references to support the answer. The comparison highlights how G-Retriever effectively mitigates hallucination by accurately recalling and utilizing information directly from the graph, unlike the baseline LLM.
read the caption
Table 1: Observation and mitigation of hallucination in graph LLMs.
In-depth insights#
GraphRAG Pioneering#
GraphRAG, a novel approach, integrates retrieval-augmented generation (RAG) with graph neural networks (GNNs). This pioneering technique directly addresses the limitations of existing methods that struggle with large-scale textual graphs and LLM context limitations. By formulating subgraph retrieval as a Prize-Collecting Steiner Tree problem, GraphRAG efficiently identifies the most relevant parts of a graph, mitigating hallucination and enhancing scalability. This method is especially significant because it provides a unified framework for diverse applications like knowledge graph reasoning and common sense reasoning, improving both efficiency and explainability in graph-based question answering.
Hallucination Mitigation#
Hallucination, a significant issue in large language models (LLMs), is especially problematic when LLMs are applied to graph data. The paper investigates this issue by introducing a retrieval-augmented generation (RAG) approach called G-Retriever to mitigate hallucinations. G-Retriever tackles hallucination by directly retrieving relevant subgraphs from the graph data instead of relying solely on the LLM’s generated embeddings. This direct retrieval method prevents the model from fabricating information not present in the input graph. The effectiveness of this approach is demonstrated in empirical evaluations, where G-Retriever significantly outperforms baseline methods in accuracy and substantially reduces hallucination across multiple datasets. Key to G-Retriever’s success is its formulation of subgraph retrieval as a Prize-Collecting Steiner Tree (PCST) optimization problem. This allows for efficient and scalable retrieval of relevant information, even in large graphs that exceed the typical context window size of LLMs. The results highlight the importance of addressing hallucination in graph-based LLMs and demonstrate the efficacy of the proposed RAG-based approach.
GraphQA Benchmark#
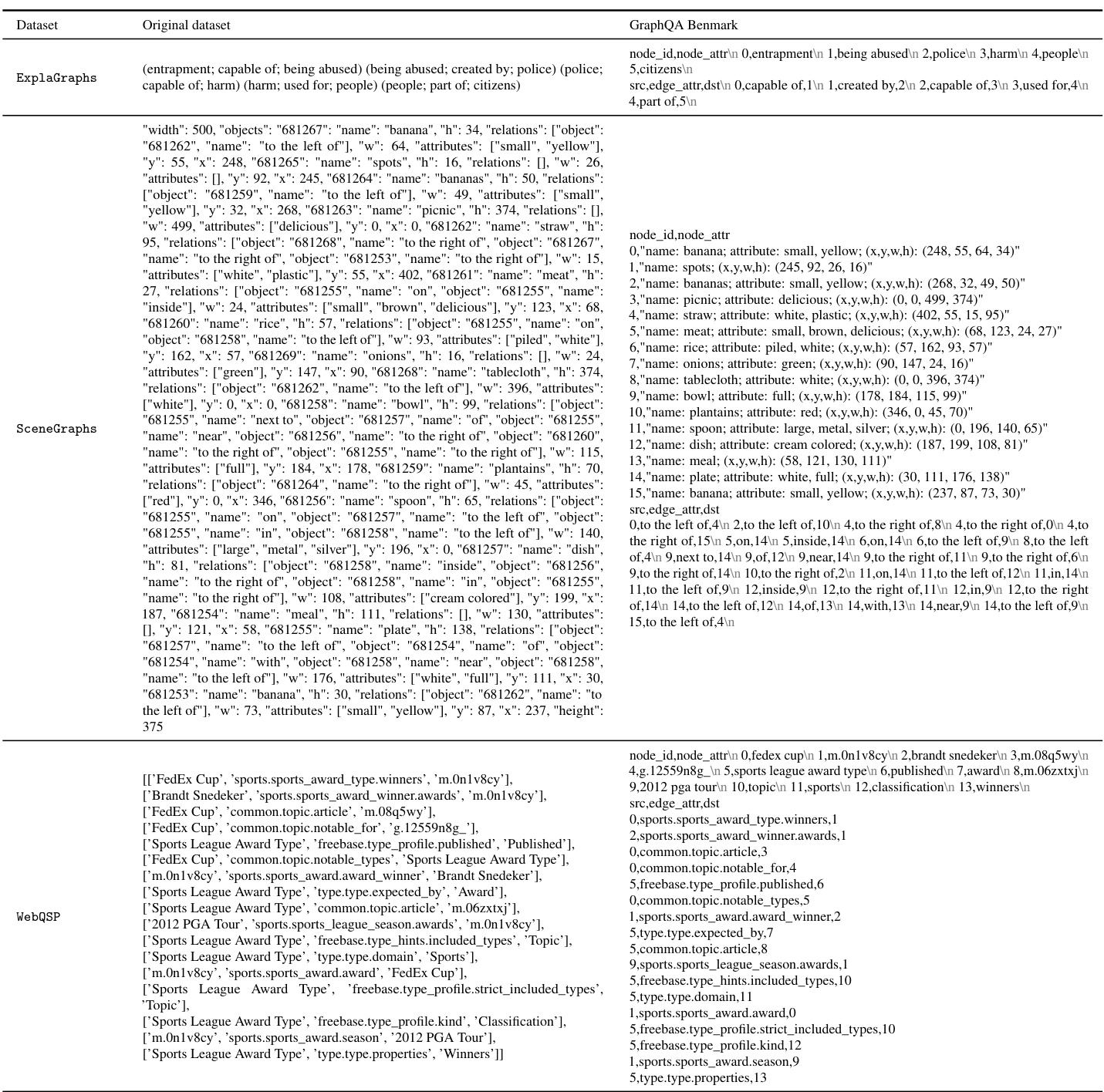
The proposed GraphQA benchmark is a crucial contribution, addressing the need for a comprehensive evaluation framework specifically tailored to textual graph question answering. Its strength lies in unifying diverse real-world datasets (ExplaGraphs, SceneGraphs, WebQSP) under a standardized format, enabling robust model comparison across various complexities. This multi-domain approach moves beyond simplistic graph tasks, fostering progress towards more sophisticated graph reasoning capabilities. The benchmark’s focus on realistic graph structures and complex questions facilitates assessment of models’ ability to handle multi-hop reasoning and mitigate hallucination, a critical aspect often overlooked in existing benchmarks. The unified format simplifies the evaluation process for researchers, fostering broader participation and accelerating advancement in the field of graph-based question answering.
PCST Subgraph Retrieval#
The proposed PCST (Prize-Collecting Steiner Tree) Subgraph Retrieval method offers a novel approach to enhance efficiency and mitigate hallucinations in graph-based question answering. Instead of processing the entire graph, which can exceed LLM context window limits, PCST intelligently selects a relevant subgraph. This is achieved by formulating subgraph retrieval as a PCST optimization problem, assigning higher prize values to nodes/edges more relevant to the query, and minimizing subgraph size. This approach balances maximizing the relevance of the retrieved information with maintaining computational feasibility. The resulting subgraph, rich in contextually important information, is then fed to the LLM, resulting in improved accuracy and reduced hallucination. PCST’s ability to manage subgraph size is crucial for scaling to large graphs, overcoming the limitations of methods converting entire graphs into text for LLM processing. Furthermore, the selection of a connected subgraph improves explainability by providing a transparent and easily interpretable subset of the original graph data.
Future Enhancements#
Future enhancements for the G-Retriever model could focus on several key areas. Improving the retrieval mechanism beyond the current Prize-Collecting Steiner Tree approach is crucial; exploring more sophisticated methods that better account for the nuances of textual graph structure would significantly boost performance and scalability. Integrating a trainable retrieval component instead of a static one would also enhance adaptability and allow the system to learn optimal retrieval strategies for various graph types and query styles. Additionally, enhancing the explainability of the model’s responses is vital; this could involve visualizing the retrieved subgraph more effectively or providing more detailed explanations of the reasoning process. Finally, exploring alternative architectures or incorporating other advanced techniques, such as larger LLMs or more sophisticated graph neural networks, may lead to additional improvements in accuracy, efficiency, and robustness.
More visual insights#
More on figures

🔼 This figure shows three example questions from the GraphQA benchmark dataset. The first example shows a commonsense reasoning task, where an explanation graph is given and the model is asked to determine if two arguments support or counter each other. The second example is a scene graph question-answering task where the question asks about the presence of a woman in a particular location relative to other objects. The third example is a knowledge-based question-answering task, where the question asks for the name of a sibling.
read the caption
Figure 2: Illustrative examples from the GraphQA benchmark datasets.
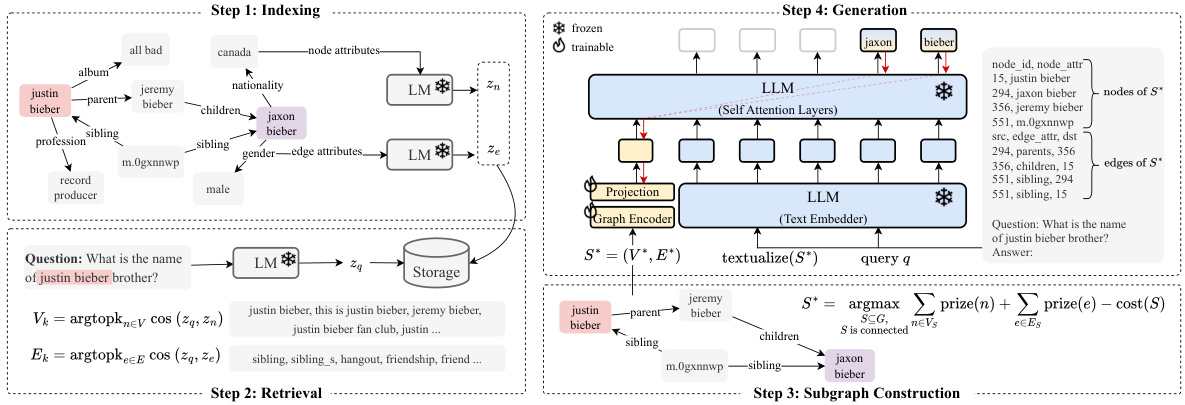
🔼 This figure illustrates the four main steps of the G-Retriever model for graph question answering. First, the graph is indexed to allow for efficient query processing. Second, the most relevant nodes and edges are retrieved based on the input query. Third, a connected subgraph containing many of these relevant nodes and edges is constructed, while keeping the size manageable for the LLM. Finally, an answer is generated using a textual representation of the subgraph as a prompt, along with the original query.
read the caption
Figure 3: Overview of the proposed G-Retriever: 1) Indexing: Graphs are indexed for efficient query processing; 2) Retrieval: The most semantically relevant nodes and edges are retrieved, conditioned on the query; 3) Subgraph Construction: A connected subgraph is extracted, covering as many relevant nodes and edges as possible while maintaining a manageable graph size; 4) Generation: An answer is generated using a 'graph prompt', a textualized graph, and the query.

🔼 This figure illustrates the four main steps of the G-Retriever model: indexing the graph for efficient query processing, retrieving the most relevant nodes and edges based on the query, constructing a manageable connected subgraph from the retrieved elements, and generating the final answer using the query and a textual representation of the subgraph.
read the caption
Figure 3: Overview of the proposed G-Retriever: 1) Indexing: Graphs are indexed for efficient query processing; 2) Retrieval: The most semantically relevant nodes and edges are retrieved, conditioned on the query; 3) Subgraph Construction: A connected subgraph is extracted, covering as many relevant nodes and edges as possible while maintaining a manageable graph size; 4) Generation: An answer is generated using a 'graph prompt', a textualized graph, and the query.

🔼 This figure illustrates the four main steps of the G-Retriever model. First, the graph is indexed to allow for efficient searching. Second, nodes and edges relevant to the query are retrieved. Third, a subgraph is constructed from the retrieved elements to optimize size and relevance. Finally, an answer is generated using the textualized subgraph and the original query as input to the language model.
read the caption
Figure 3: Overview of the proposed G-Retriever: 1) Indexing: Graphs are indexed for efficient query processing; 2) Retrieval: The most semantically relevant nodes and edges are retrieved, conditioned on the query; 3) Subgraph Construction: A connected subgraph is extracted, covering as many relevant nodes and edges as possible while maintaining a manageable graph size; 4) Generation: An answer is generated using a 'graph prompt', a textualized graph, and the query.

🔼 This figure shows the four main steps of the G-Retriever model for graph question answering. First, the graph is indexed to allow efficient retrieval of relevant parts. Second, the most relevant nodes and edges are retrieved based on semantic similarity to the query. Third, a connected subgraph is constructed using the prize-collecting Steiner tree optimization, balancing subgraph size and relevance. Finally, the textualized subgraph and the query are fed to an LLM to generate the answer.
read the caption
Figure 3: Overview of the proposed G-Retriever: 1) Indexing: Graphs are indexed for efficient query processing; 2) Retrieval: The most semantically relevant nodes and edges are retrieved, conditioned on the query; 3) Subgraph Construction: A connected subgraph is extracted, covering as many relevant nodes and edges as possible while maintaining a manageable graph size; 4) Generation: An answer is generated using a 'graph prompt', a textualized graph, and the query.

🔼 This figure illustrates the four main steps of the G-Retriever model: indexing the graph for efficient query processing, retrieving the most relevant nodes and edges based on the query, constructing a connected subgraph containing those relevant elements, and finally generating the answer using the subgraph, textualized graph, and the query as input to the LLM. The figure visually represents each step with diagrams and text descriptions for clarity.
read the caption
Figure 3: Overview of the proposed G-Retriever: 1) Indexing: Graphs are indexed for efficient query processing; 2) Retrieval: The most semantically relevant nodes and edges are retrieved, conditioned on the query; 3) Subgraph Construction: A connected subgraph is extracted, covering as many relevant nodes and edges as possible while maintaining a manageable graph size; 4) Generation: An answer is generated using a 'graph prompt', a textualized graph, and the query.

🔼 This figure shows examples of how the G-Retriever model answers complex and creative questions using a conversational interface with different types of textual graphs (explanation graph, scene graph, and knowledge graph). It highlights the model’s ability to handle various question types and provide accurate and relevant answers by highlighting the relevant parts of the input graph.
read the caption
Figure 1: We develop a flexible question-answering framework targeting real-world textual graph applications via a unified conversational interface. Presented here are examples showcasing the model's adeptness in handling generative and creative queries in practical graph-related tasks: common sense reasoning, scene understanding, and knowledge graph reasoning, respectively.
More on tables

🔼 This table presents a comparison of the performance of different model configurations on three datasets: ExplaGraphs, SceneGraphs, and WebQSP. The configurations tested include using a frozen LLM for inference only, a frozen LLM with prompt tuning (PT), and a tuned LLM. The performance is measured by mean scores and standard deviations, with the best and second-best results highlighted for each dataset and task.
read the caption
Table 3: Performance comparison across ExplaGraphs, SceneGraphs, and WebQSP datasets for different configurations, including Inference-only, Frozen LLM with prompt tuning (PT), and Tuned LLM settings. Mean scores and standard deviations (mean ± std) are presented. The first best result for each task is highlighted in bold and the second best result is highlighted with an underline.

🔼 This table shows that using retrieval on graphs significantly improves the efficiency of the model. The number of tokens required to represent graphs, the number of nodes in the graph, and the training time (minutes per epoch) are all substantially reduced after implementing retrieval. For the SceneGraphs dataset, tokens decreased by 83%, nodes by 74%, and training time by 29%. For the WebQSP dataset, tokens decreased by 99%, nodes by 99%, and training time by 67%. This highlights the method’s efficiency for handling large-scale graph data.
read the caption
Table 4: Retrieval on graphs significantly improves efficiency.

🔼 This table shows a comparison of hallucination mitigation between a baseline method (LLM w/ Graph Prompt Tuning) and the proposed G-Retriever method. The baseline shows significant hallucination in answering questions about a graph, as evidenced by a low percentage of correctly identified nodes and edges. In contrast, G-Retriever significantly reduces hallucination by retrieving information directly from the graph.
read the caption
Table 1: Observation and mitigation of hallucination in graph LLMs.
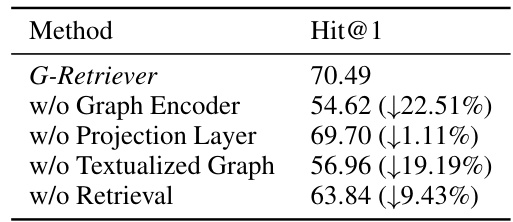
🔼 This table presents the results of an ablation study conducted on the WebQSP dataset to evaluate the impact of each component of the G-Retriever model. It shows the Hit@1 (a metric for evaluating the accuracy of top-ranked answers) achieved by removing each of four key components: Graph Encoder, Projection Layer, Textualized Graph, and Retrieval. The results quantify the decrease in performance when each component is removed, demonstrating their relative importance to the overall effectiveness of the G-Retriever model.
read the caption
Table 6: Ablation study on the WebQSP dataset showing performance drops (Hit@1) when each component is removed.

🔼 This table compares the performance of three different graph encoders (GCN, GAT, and Graph Transformer) on two different datasets (WebQSP and ExplaGraphs). The results show that the Graph Transformer generally performs best, but the performance differences are small on the WebQSP dataset.
read the caption
Table 7: Performance of different graph encoders on the WebQSP and ExplaGraphs datasets.

🔼 This table presents a comparison of the performance achieved by two different Large Language Models (LLMs), Llama2-7b and Llama2-13b, on the WebQSP dataset. The performance metric used is Hit@1, representing the accuracy of retrieving the correct answer in the top result.
read the caption
Table 8: Performance of different LLMs on the WebQSP dataset.
🔼 This table presents the performance comparison of different model configurations on three datasets: ExplaGraphs, SceneGraphs, and WebQSP. The configurations tested are Inference-only (using a frozen LLM), Frozen LLM with Prompt Tuning (PT), and Tuned LLM. The table shows the mean and standard deviation of the scores for each dataset and configuration. The best performing configuration for each task is highlighted.
read the caption
Table 3: Performance comparison across ExplaGraphs, SceneGraphs, and WebQSP datasets for different configurations, including Inference-only, Frozen LLM with prompt tuning (PT), and Tuned LLM settings. Mean scores and standard deviations (mean ± std) are presented. The first best result for each task is highlighted in bold and the second best result is highlighted with an underline.

🔼 This table compares the performance of four different graph retrieval methods on the WebQSP dataset, using Hit@1 as the evaluation metric. The methods compared are PCST retrieval (the proposed method), top-k triples retrieval (KAPING), top-k nodes plus its neighbors, and shortest path retrieval. The results show that the PCST retrieval method outperforms all the baseline methods.
read the caption
Table 10: Comparison of retrieval methods on the WebQSP dataset.

🔼 This table presents the results of an experiment evaluating the effect of different values of the hyperparameter k on the performance of the G-Retriever model on the WebQSP dataset. The hyperparameter k controls the number of top-k nodes/edges retrieved during the retrieval phase of the method. The table shows that performance (measured by Hit@1, a metric indicating the accuracy of retrieving the correct answer in the top-ranked result), initially increases with k, peaks at k=10 and then starts decreasing for higher values of k. This suggests an optimal value for k exists that balances recall (finding relevant information) and precision (avoiding irrelevant information).
read the caption
Table 11: The impact of k on the webqsp dataset.

🔼 This table compares the performance of different model configurations on three graph question-answering datasets: ExplaGraphs, SceneGraphs, and WebQSP. The configurations include an Inference-only model, a Frozen LLM with prompt tuning, and a Tuned LLM. The table shows mean scores and standard deviations for each dataset and configuration, highlighting the best and second-best performing models for each task.
read the caption
Table 3: Performance comparison across ExplaGraphs, SceneGraphs, and WebQSP datasets for different configurations, including Inference-only, Frozen LLM with prompt tuning (PT), and Tuned LLM settings. Mean scores and standard deviations (mean ± std) are presented. The first best result for each task is highlighted in bold and the second best result is highlighted with an underline.

🔼 This table compares the performance of three different model configurations (Inference-only, Frozen LLM with prompt tuning, and Tuned LLM) across three different datasets (ExplaGraphs, SceneGraphs, and WebQSP) for graph question answering. The results are presented as mean scores and standard deviations. The best and second best performing methods for each dataset are highlighted.
read the caption
Table 3: Performance comparison across ExplaGraphs, SceneGraphs, and WebQSP datasets for different configurations, including Inference-only, Frozen LLM with prompt tuning (PT), and Tuned LLM settings. Mean scores and standard deviations (mean ± std) are presented. The first best result for each task is highlighted in bold and the second best result is highlighted with an underline.

🔼 This table showcases the results of an experiment designed to observe and mitigate hallucination in graph LLMs (Large Language Models). The experiment compared a baseline method (LLM w/ Graph Prompt Tuning) with the proposed G-Retriever method. The comparison focuses on answering questions and identifying the nodes or edges that support the answers. The table presents a sample question and highlights the difference in response quality, demonstrating that G-Retriever successfully mitigates hallucination by providing accurate responses and references to nodes and edges, in contrast to the baseline method which frequently produces incorrect answers and hallucinated references.
read the caption
Table 1: Observation and mitigation of hallucination in graph LLMs.

🔼 This table showcases the presence of hallucination in graph Large Language Models (LLMs) and how the proposed G-Retriever method mitigates this issue. It compares the performance of a baseline method (LLM with Graph Prompt Tuning) with G-Retriever in answering questions about a graph. The comparison highlights the accuracy of the responses and the correctness of the nodes and edges referenced in the answers. G-Retriever’s retrieval mechanism helps reduce hallucination by ensuring accurate information retrieval from the graph.
read the caption
Table 1: Observation and mitigation of hallucination in graph LLMs.

🔼 This table showcases an example of a question-answering task applied to a graph. The first row demonstrates the incorrect response with hallucinated nodes and edges from a baseline method (LLM w/ Graph Prompt Tuning). The second row shows that the proposed method (G-Retriever) correctly answers the question with accurate nodes and edge references, mitigating the hallucination problem.
read the caption
Table 1: Observation and mitigation of hallucination in graph LLMs.

🔼 This table presents a comparison of the performance of three different model configurations (Inference-only, Frozen LLM with prompt tuning, and Tuned LLM) across three different datasets (ExplaGraphs, SceneGraphs, and WebQSP). The results show the mean scores and standard deviations for each model configuration and dataset. The best-performing model for each dataset is highlighted.
read the caption
Table 3: Performance comparison across ExplaGraphs, SceneGraphs, and WebQSP datasets for different configurations, including Inference-only, Frozen LLM with prompt tuning (PT), and Tuned LLM settings. Mean scores and standard deviations (mean ± std) are presented. The first best result for each task is highlighted in bold and the second best result is highlighted with an underline.
Full paper#



















