TL;DR#
Domain generalization (DG) remains a challenge in machine learning, where models struggle to generalize to unseen data distributions. Large pre-trained vision-language models like CLIP show promise but often underperform in DG scenarios due to domain shifts between training and testing data. Existing methods haven’t effectively addressed the inherent limitations of CLIP in handling these shifts.
CLIPCEIL tackles this issue by using a two-pronged approach: 1) channel refinement to remove domain-specific information from CLIP’s visual features, and 2) image-text alignment to maintain CLIP’s original alignment despite the feature refinement. Extensive experiments demonstrate that CLIPCEIL surpasses existing DG methods, particularly showcasing improvements on several benchmark datasets. This suggests that explicitly considering domain invariance and maintaining image-text alignment is key to enhancing CLIP’s performance in domain generalization tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on domain generalization, a vital area in machine learning. It presents a novel approach to improve the generalizability of vision-language models (VLMs), particularly CLIP, by explicitly addressing the issue of domain shift. The proposed method, CLIPCEIL, outperforms state-of-the-art techniques, making it valuable for various downstream applications and opening new avenues for research on VLM adaptation and robustness.
Visual Insights#
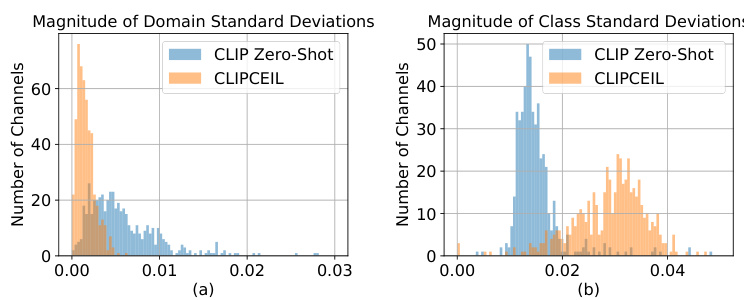
🔼 This figure shows the sensitivity of CLIP’s visual feature channels to domain and class shifts. Histograms display the standard deviations of channel activations across different domains (a) and classes (b). The OfficeHome dataset and ViT-B/16 backbone are used for analysis. CLIPCEIL’s impact on reducing domain sensitivity and increasing class sensitivity is illustrated by comparison with the standard CLIP zero-shot approach.
read the caption
Figure 1: The feature channel sensitivity to domain and class shifts are quantified through employing the histogram of their standard deviations across different domains and classes. We analyze CLIP’s image embeddings using the ViT-B/16 backbone on OfficeHome [52] dataset. For each channel, the average outputs are computed across all samples from each domain/class, and the standard deviations are calculated on domain/class dimension.

🔼 This table presents a comparison of the performance of CLIP with all its features versus CLIP using only the top 400 channels selected based on minimizing inter-domain variance and maximizing inter-class variance, evaluated on the OfficeHome dataset using a zero-shot approach. The results show that a simple feature selection technique can improve the performance of the CLIP zero-shot model.
read the caption
Table 1: Comparison of channel selection (Q = 400) with the CLIP zero-shot on Office Home benchmark
In-depth insights#
CLIP Adaptation#
CLIP Adaptation methods modify the pre-trained CLIP model to enhance its performance on specific tasks or datasets. The core idea is to leverage CLIP’s powerful vision-language understanding while mitigating its limitations, such as sensitivity to domain shifts and a lack of task-specific knowledge. Approaches might include fine-tuning, prompt engineering, or adapter modules. Fine-tuning adjusts CLIP’s weights, but can lead to overfitting. Prompt engineering alters the input text to guide CLIP’s attention, offering flexibility. Adapter modules introduce lightweight modifications, preserving CLIP’s original weights while adding task-specific capabilities. The choice of method depends on factors like the dataset size, desired performance gains, and computational constraints. Effective CLIP adaptation often involves a careful balance between retaining CLIP’s generalizability and specializing it for the target task. Successfully adapting CLIP for downstream tasks hinges on addressing the trade-offs between accuracy and robustness, and selecting the right adaptation strategy for optimal performance.
Channel Refinement#
The concept of ‘Channel Refinement’ in the context of a vision-language model like CLIP for domain generalization is a novel approach to enhance model robustness. It tackles the issue of domain-specific and class-irrelevant features within CLIP’s visual channels by selectively refining feature channels. The core idea is to identify and retain channels containing domain-invariant and class-relevant information, effectively minimizing inter-domain variance while maximizing inter-class variance. This process ensures the model learns features that generalize well across various domains, rather than overfitting to the specifics of the training data. This is critical for improving the performance of the model when faced with unseen or out-of-distribution data, a common challenge in domain generalization tasks. The effectiveness of this technique likely hinges on the ability to accurately identify and separate these feature types, which may require sophisticated techniques or substantial computational resources. The success of ‘Channel Refinement’ therefore greatly relies on the quality and appropriateness of the chosen criteria and metrics used for feature selection.
Image-Text Alignment#
Image-text alignment is crucial for effective vision-language models. The goal is to learn a shared representation space where image and text embeddings of the same concept are close together, while those of different concepts are far apart. The paper’s approach to image-text alignment is noteworthy because it addresses the challenge of domain shift. Standard methods often fail when images from unseen domains differ significantly from those in training data. The described method uses a lightweight adapter to refine visual features, making them domain-invariant, followed by an alignment step. This ensures that the refined image embeddings better correspond to textual descriptions, enhancing generalization to unseen data. The success of this method is likely due to its focus on aligning semantic relationships between images and texts, rather than just raw pixel-level features. The multi-scale feature fusion further improves performance by leveraging richer visual information. This combined approach of refined visual features and semantic alignment is an innovative and effective way to improve the robustness of vision-language models and tackle the problem of domain generalization.
DG Benchmark Results#
A thorough analysis of DG benchmark results would require a detailed look at the specific datasets used, the metrics employed to evaluate performance, and the comparison against existing state-of-the-art (SOTA) methods. Crucially, understanding the characteristics of each dataset—the variability in data distributions, the diversity of classes, and the presence of confounding factors—is vital. The choice of evaluation metrics (e.g., accuracy, F1-score, AUC) also significantly impacts the interpretation. A simple accuracy comparison might not tell the whole story; a more nuanced assessment is required. The summary should describe how the proposed approach compares to existing SOTA methods, preferably visualizing the performance differences through tables or charts. Important considerations include the statistical significance of the results (e.g., confidence intervals, p-values) and any potential biases or limitations in the datasets or evaluation methodologies. A key question is whether the improvements are consistent across different datasets or primarily localized to a few. The ultimate value lies in examining whether the proposed model demonstrates robustness and generalizability that transcends the limitations of the benchmark data, and in drawing conclusions about its real-world applicability.
Future of CLIP-DG#
The future of CLIP-based domain generalization (CLIP-DG) appears bright, particularly given CLIP’s impressive zero-shot capabilities. Further research should focus on enhancing CLIP’s robustness to distribution shifts, perhaps through more sophisticated data augmentation techniques or by developing more effective domain-invariant feature extraction methods. Addressing the limitations of existing methods, such as computational cost and the need for large datasets, is crucial for wider adoption. Exploring novel architectures specifically designed for CLIP-DG, potentially incorporating self-supervised learning, is another promising avenue. Investigating the interplay between CLIP’s inherent biases and its performance on diverse domains is also important for creating more fair and equitable CLIP-DG models. Finally, applying CLIP-DG to real-world problems in areas such as medical imaging and autonomous driving will be essential to demonstrate the true value of this promising technology.
More visual insights#
More on figures
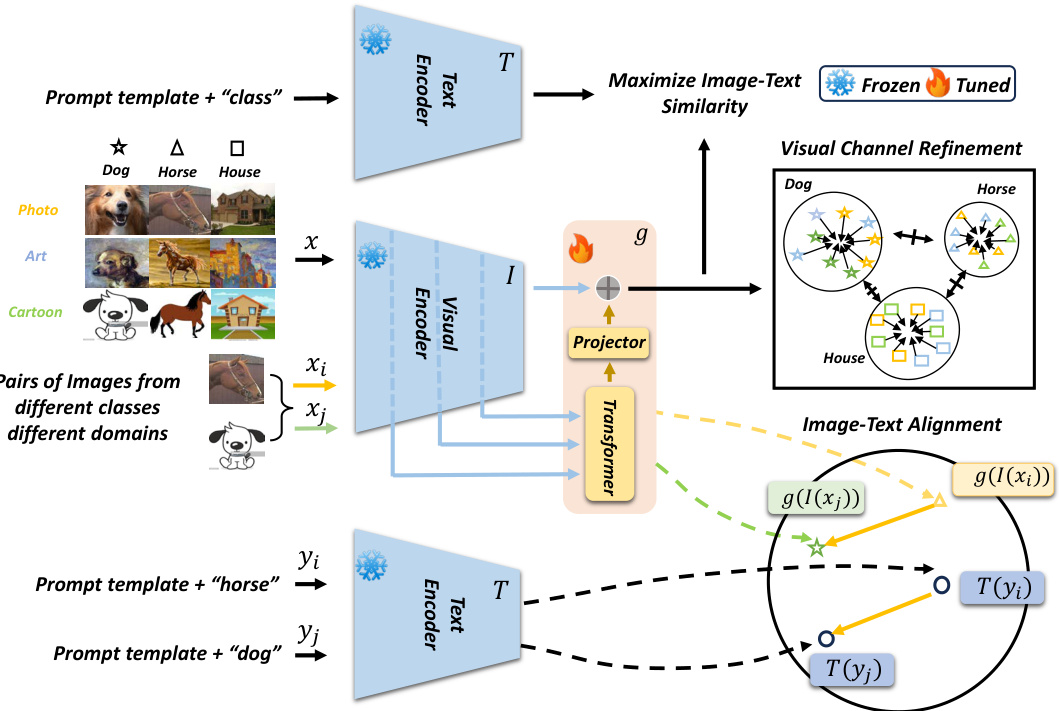
🔼 This figure illustrates the CLIPCEIL framework, which consists of three main components: a lightweight adapter that integrates multi-scale CLIP features, visual channel refinement to ensure domain-invariant and class-relevant visual features, and image-text alignment to maintain consistency between image and text embeddings. The adapter processes multi-scale visual features from the CLIP visual encoder, minimizing inter-domain variance and maximizing inter-class variance. Image-text alignment is achieved by maximizing similarity and minimizing directional loss between image and text embeddings. The text encoder is fixed, and only the adapter is trained during training.
read the caption
Figure 2: An overview of the proposed framework. We fixed the CLIP visual encoder I and text encoder T and trained a lightweight adapter g during the training. The channel refinement ensures each feature channel contains domain-invariant (minimizing domain variance) and class-relevant (maximizing class variance) information. To further align the image and text, we maximize the image-text similarity and minimize direction loss with the help of text class descriptions based on data pairs from different classes and domains.

🔼 The figure shows the architecture of the adapter g, a lightweight component in the CLIPCEIL model. It consists of a Transformer layer followed by a Multi-Layer Perceptron (MLP) projector. The Transformer layer integrates multi-scale visual features (from different layers of CLIP’s visual encoder) and maps them into a latent feature space. The MLP projector then further refines the feature representations. The adapter’s role is crucial for improving the model’s generalizability by learning domain-invariant and class-relevant features. In short, it processes multiple CLIP visual features to make them more robust against domain shift and improve classification.
read the caption
Figure 3: The architecture of the adapter g.
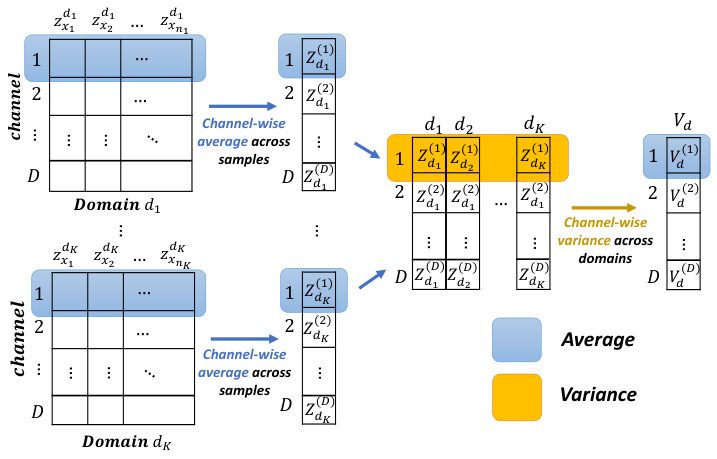
🔼 This figure illustrates the calculation of channel domain sensitivity. It starts with feature vectors from multiple domains. For each channel, it calculates the average value across all samples in each domain. Then, it computes the variance of these average values across the domains. This variance represents the sensitivity of that channel to domain shifts. Channels with low variance are considered domain-invariant. The visualization shows how the calculation proceeds step-by-step from individual samples to channel-wise averages, and finally to inter-domain variance for each channel.
read the caption
Figure 4: Diagram of calculating the channel domain sensitivity across different domains.
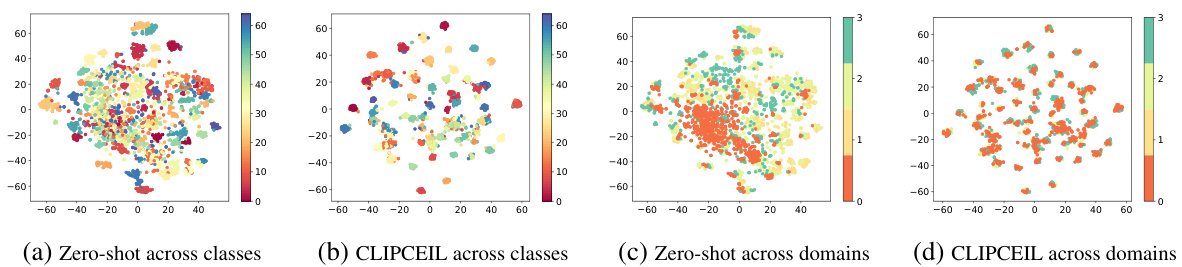
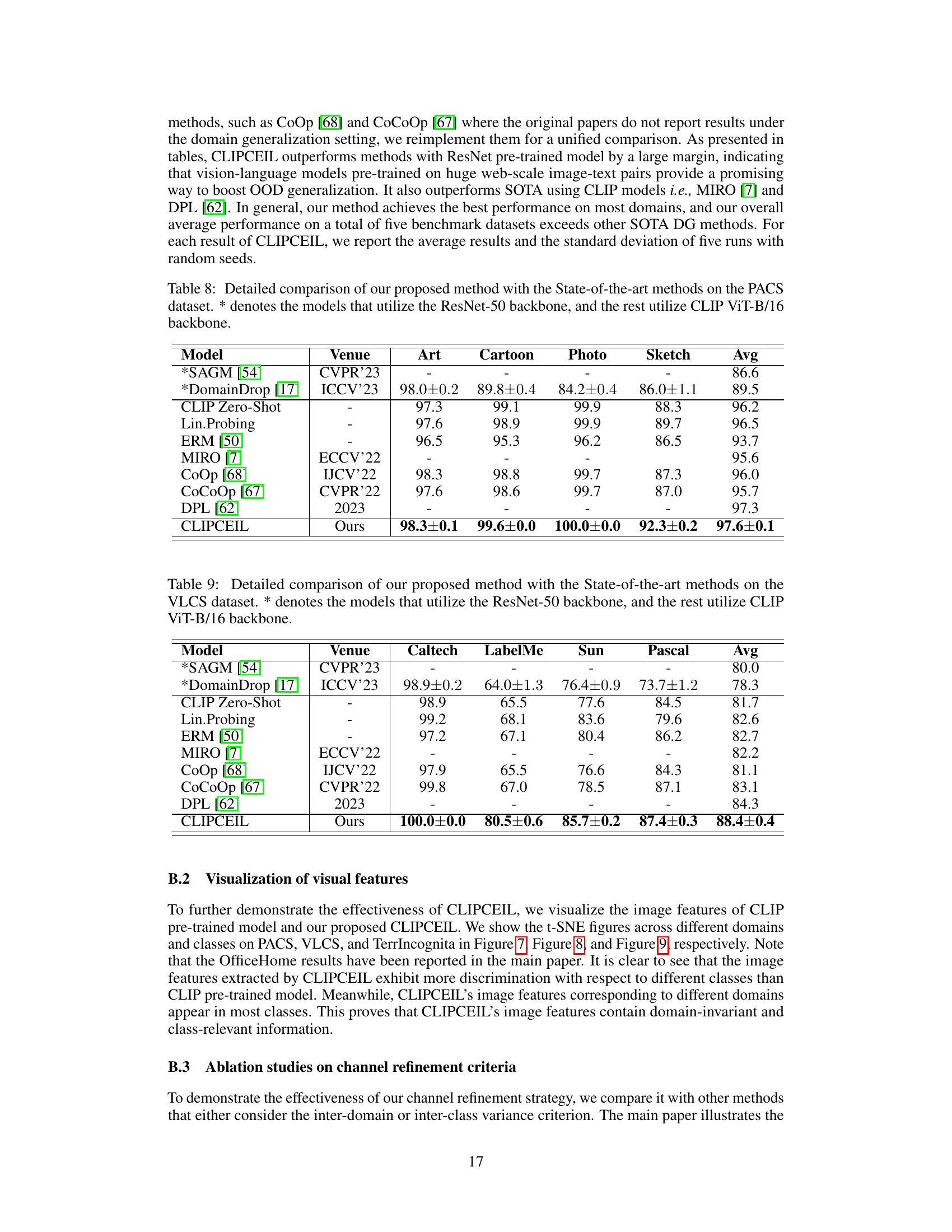
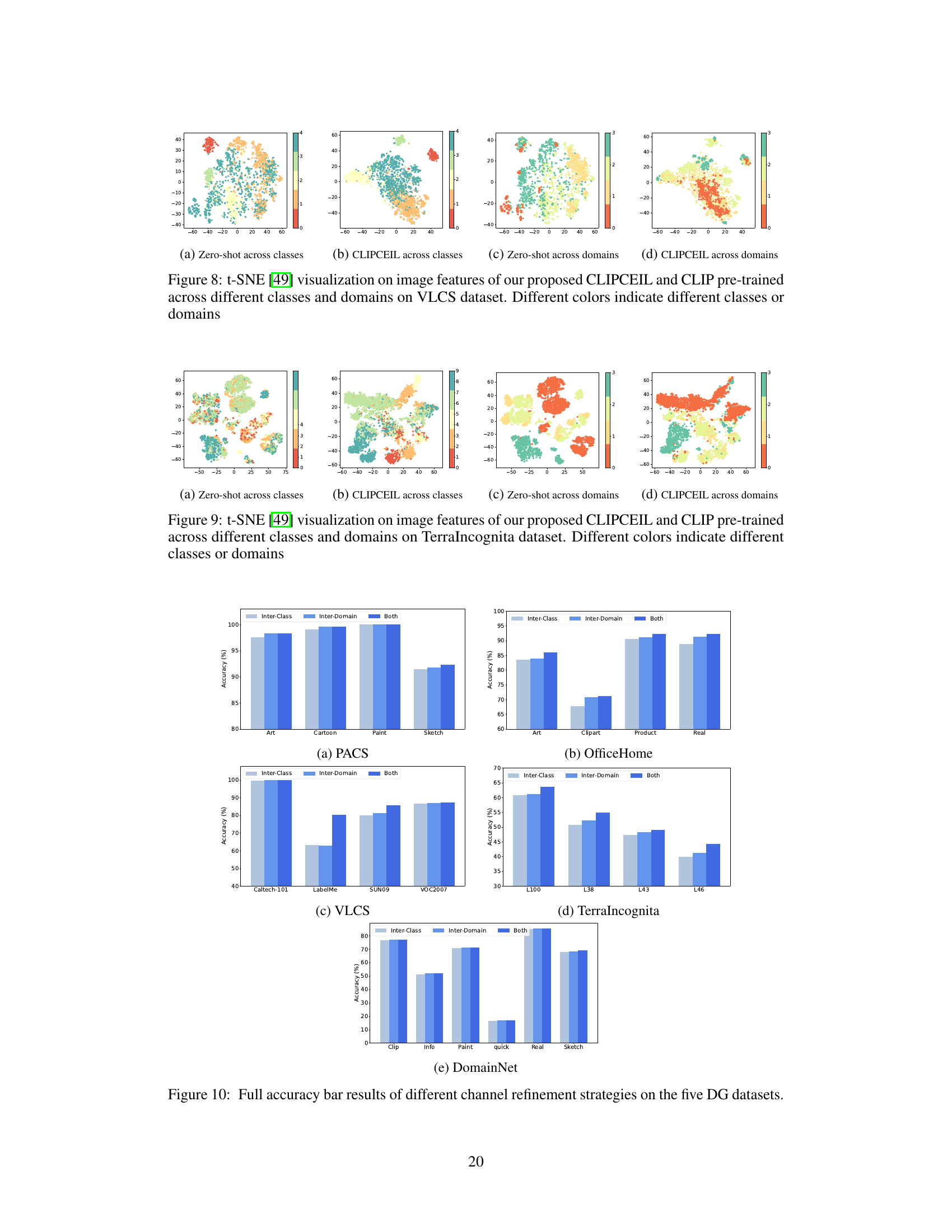
🔼 This figure shows the results of t-SNE dimensionality reduction applied to image features extracted by both CLIPCEIL and the original CLIP model. The plots visualize how the features cluster across different classes and domains. Panel (a) shows CLIP zero-shot across classes, panel (b) CLIPCEIL across classes, panel (c) CLIP zero-shot across domains, and panel (d) CLIPCEIL across domains. The goal is to illustrate that CLIPCEIL produces features that are more discriminative between classes while showing less sensitivity to domain shifts.
read the caption
Figure 5: t-SNE [49] visualization on image features of CLIPCEIL and CLIP pre-trained models across different classes and domains. Different colors indicate different classes or domains

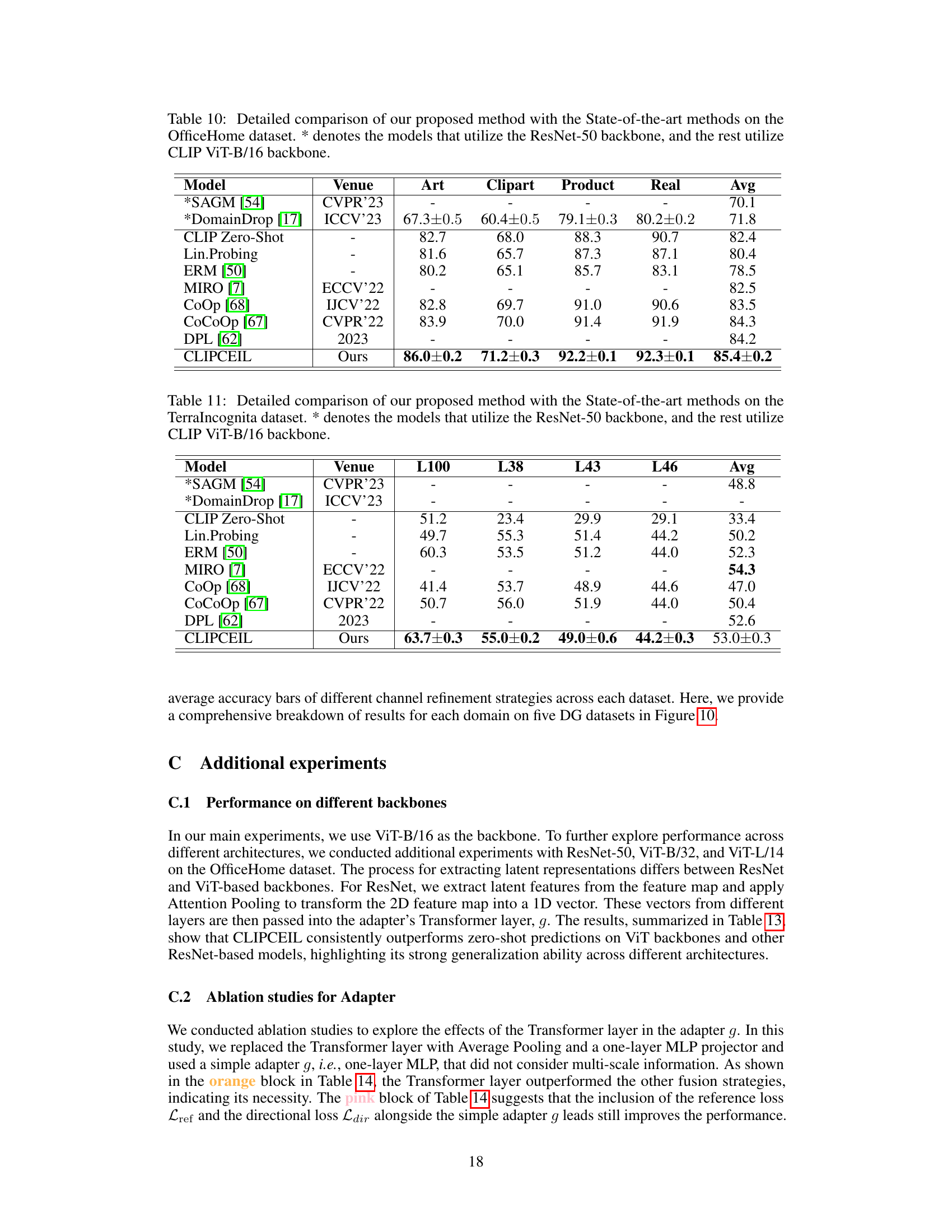
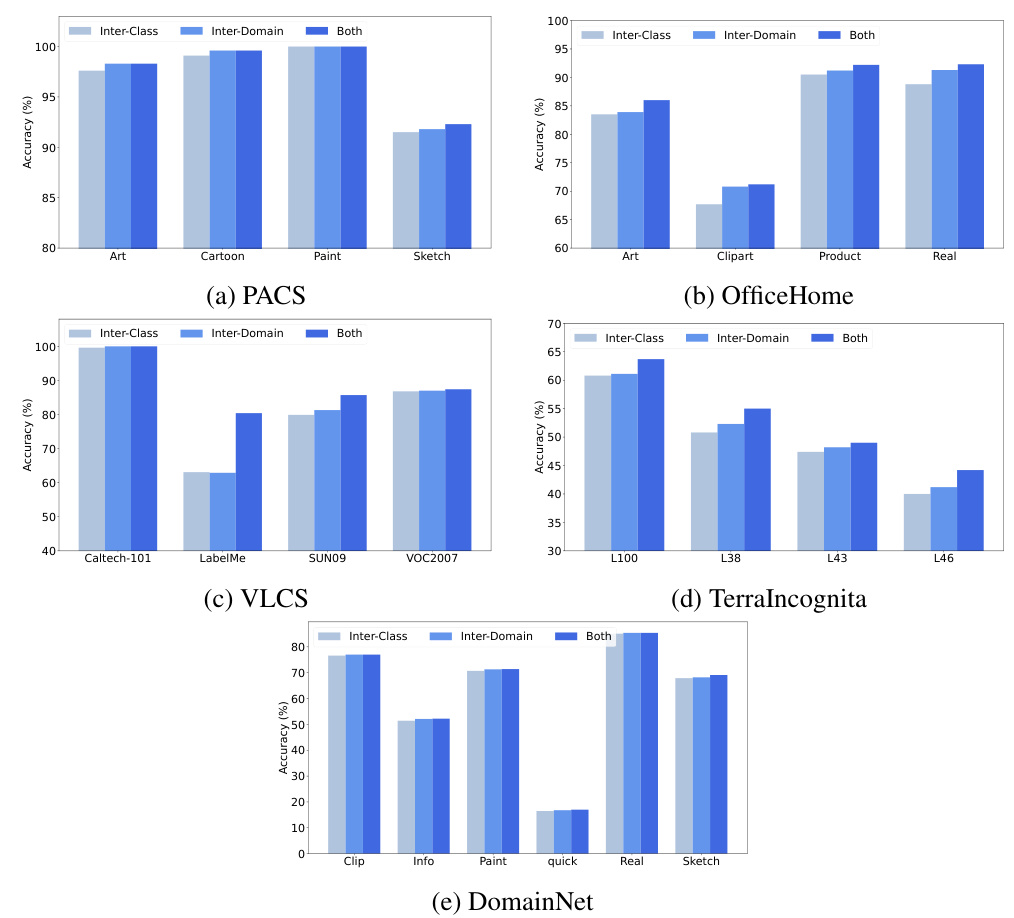
🔼 This figure presents a bar chart comparing the average accuracy achieved by three different channel refinement strategies across five domain generalization (DG) benchmark datasets. The strategies are: using only inter-class variance, only inter-domain variance, and using both. The datasets are PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet. The chart visually demonstrates the relative performance of each strategy on each dataset, highlighting the effectiveness of combining both inter-class and inter-domain variance for improved accuracy across various domains.
read the caption
Figure 10: Full accuracy bar results of different channel refinement strategies on the five DG datasets.

🔼 This figure shows the results of t-SNE dimensionality reduction applied to image features extracted by both CLIPCEIL and a standard CLIP model. The visualizations help to understand how well each model separates image features by class and domain. Distinct clusters indicate good separation, while overlapping clusters suggest difficulty in distinguishing between classes or domains. The differences in clustering patterns between CLIPCEIL and CLIP highlight CLIPCEIL’s improved ability to generate domain-invariant features while preserving class-relevant information.
read the caption
Figure 5: t-SNE [49] visualization on image features of CLIPCEIL and CLIP pre-trained models across different classes and domains. Different colors indicate different classes or domains
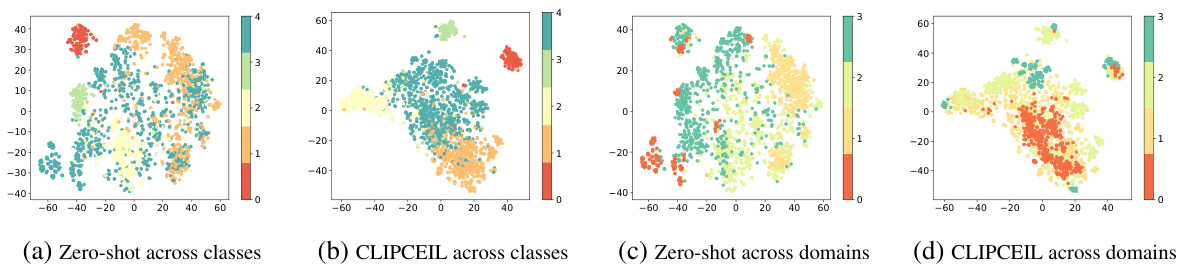
🔼 This figure shows the results of t-SNE dimensionality reduction applied to image features extracted by both CLIPCEIL and the original CLIP model. The visualizations help understand the impact of CLIPCEIL on feature representation by comparing how features from different classes and domains are clustered. The goal is to show that CLIPCEIL generates features that are more discriminative between classes while being less sensitive to domain shifts than features from the original CLIP.
read the caption
Figure 5: t-SNE [49] visualization on image features of CLIPCEIL and CLIP pre-trained models across different classes and domains. Different colors indicate different classes or domains

🔼 This figure visualizes the image features extracted by both CLIPCEIL and the original CLIP model using t-SNE. It shows the distribution of features across different classes and domains. The purpose is to illustrate that CLIPCEIL better separates features by class, indicating improved class discrimination, and that the features from different domains are more intermixed, showcasing the model’s enhanced domain invariance compared to the original CLIP.
read the caption
Figure 5: t-SNE [49] visualization on image features of CLIPCEIL and CLIP pre-trained models across different classes and domains. Different colors indicate different classes or domains
🔼 This figure shows the t-SNE visualization of image features from both the CLIPCEIL model and the pre-trained CLIP model. The visualization is performed separately for different classes and domains. Different colors represent different classes or domains. The purpose is to show how CLIPCEIL improves the separation of classes compared to the pre-trained CLIP model, especially across domains. This illustrates CLIPCEIL’s ability to learn domain-invariant and class-relevant features.
read the caption
Figure 5: t-SNE [49] visualization on image features of CLIPCEIL and CLIP pre-trained models across different classes and domains. Different colors indicate different classes or domains
More on tables

🔼 This table compares the performance of the proposed CLIPCEIL model with several state-of-the-art domain generalization methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). It shows the average accuracy for each method on each dataset, highlighting the superior performance of CLIPCEIL and its variant, CLIPCEIL++, which fine-tunes the entire CLIP model. Different model architectures (ResNet-50 and CLIP ViT-B/16) are included for a comprehensive comparison. The table distinguishes between methods that freeze the CLIP encoder and those that fine-tune it, and further differentiates between methods using inference-time fine-tuning.
read the caption
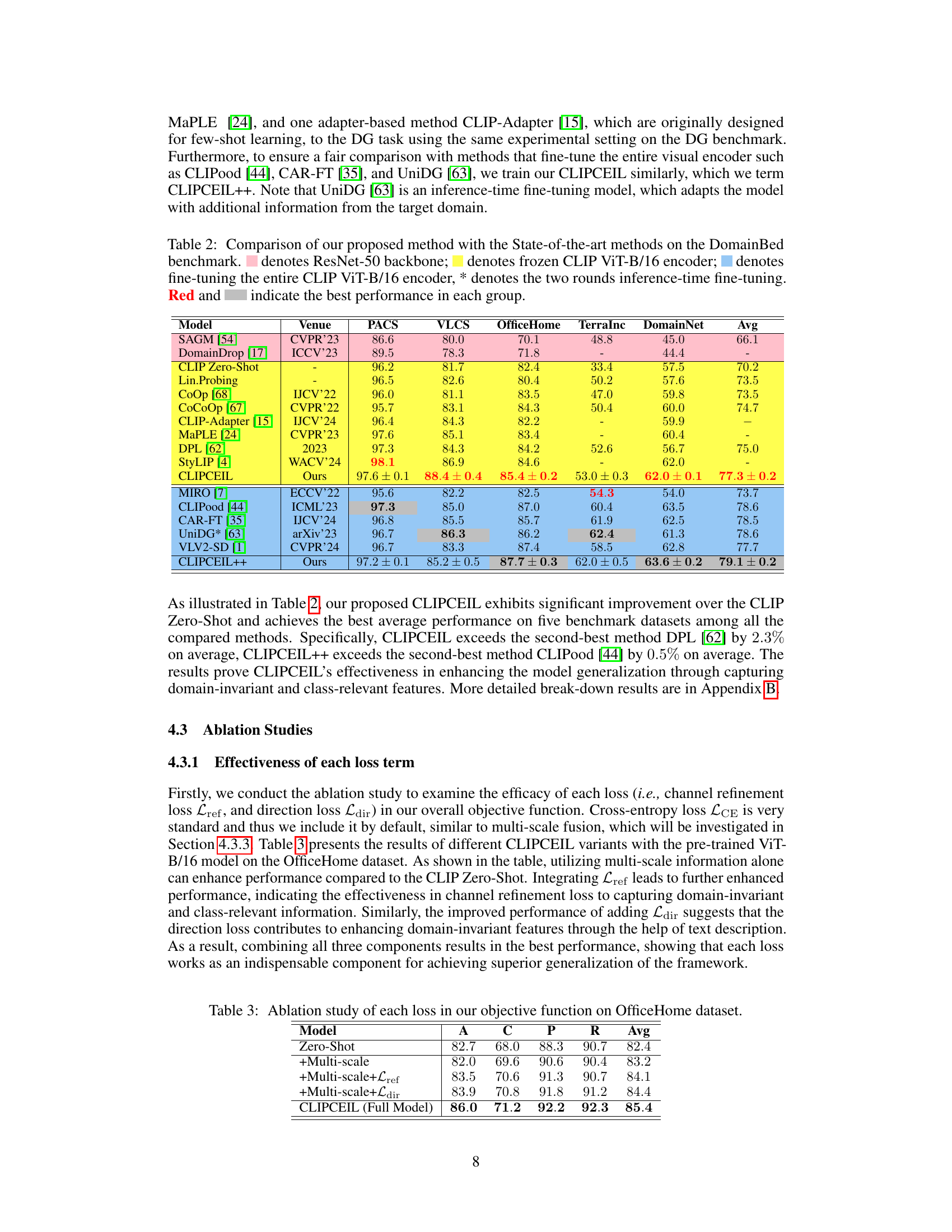
Table 2: Comparison of our proposed method with the State-of-the-art methods on the DomainBed benchmark. denotes ResNet-50 backbone; denotes frozen CLIP ViT-B/16 encoder; denotes fine-tuning the entire CLIP ViT-B/16 encoder, * denotes the two rounds inference-time fine-tuning. Red and indicate the best performance in each group.
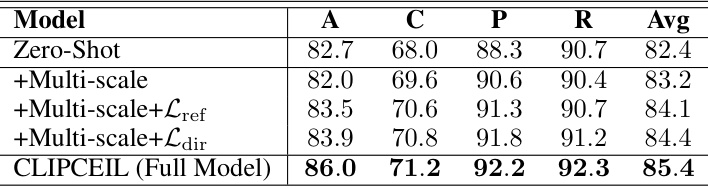
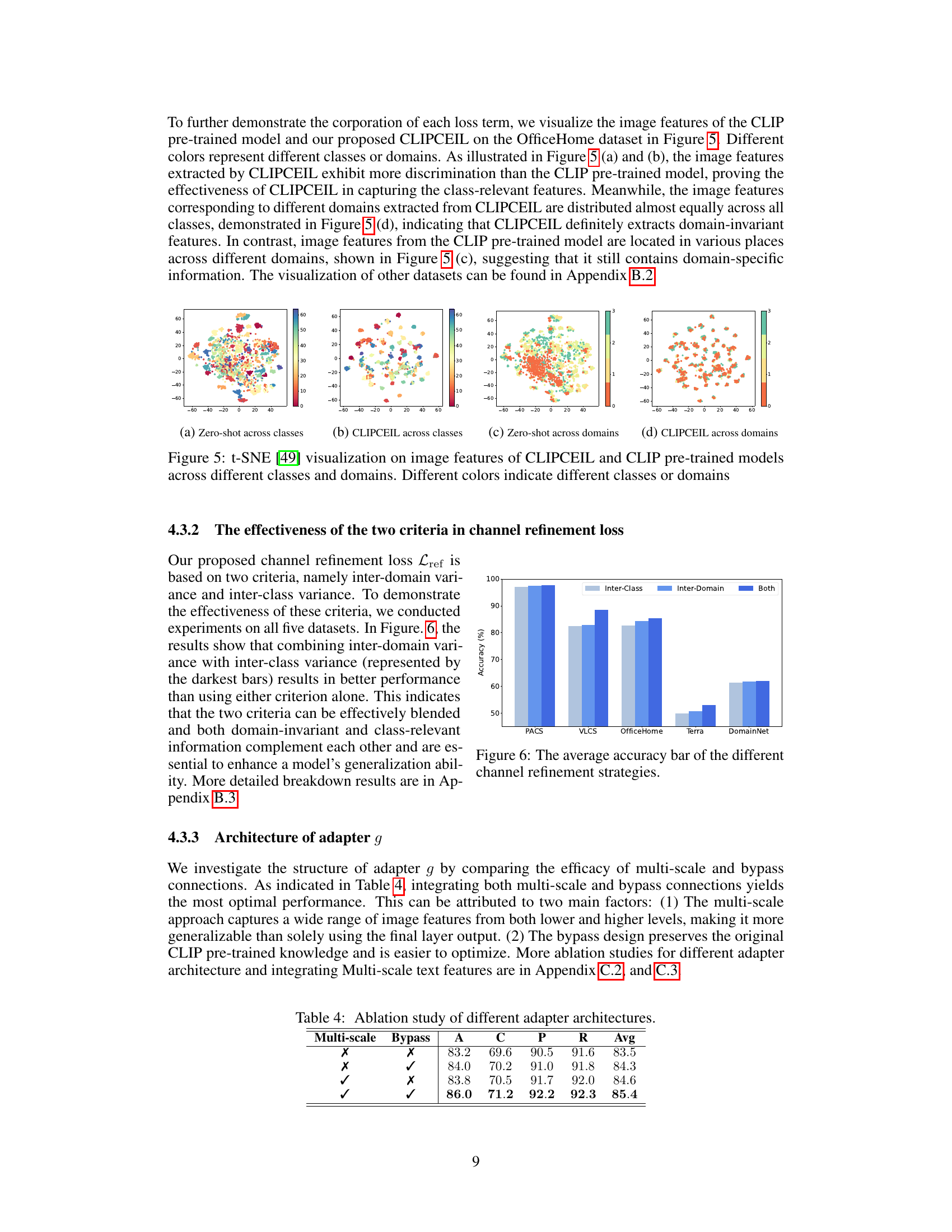
🔼 This table presents the ablation study results on the OfficeHome dataset, evaluating the impact of different loss components on the model’s performance. It compares the performance of the model using only the cross-entropy loss, adding multi-scale feature fusion, incorporating the channel refinement loss (Lref), adding the direction loss (Ldir), and finally, the full model with all components combined. The results show the contribution of each component in improving the model’s generalization ability.
read the caption
Table 3: Ablation study of each loss in our objective function on OfficeHome dataset.
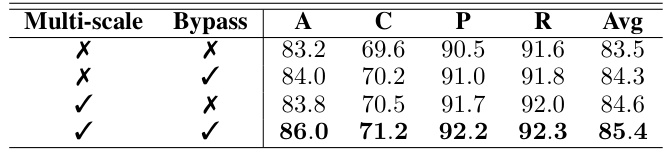
🔼 This ablation study investigates the individual and combined effects of the three loss terms in the CLIPCEIL model (Channel Refinement loss, Direction loss, and Cross-Entropy loss) on the OfficeHome dataset. It compares the performance of CLIPCEIL with different combinations of these losses against the baseline zero-shot performance. The results show how each loss term contributes to the model’s improved performance and the synergistic effect when they are combined.
read the caption
Table 3: Ablation study of each loss in our objective function on OfficeHome dataset.

🔼 This table compares the performance of the proposed CLIPCEIL model against several state-of-the-art domain generalization methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). It shows the average accuracy for each method on each dataset, highlighting the best-performing methods in each category. The table also distinguishes between methods using ResNet-50 and CLIP ViT-B/16 backbones, and those that use fine-tuning versus frozen CLIP encoders. The results demonstrate the superior performance of CLIPCEIL compared to other methods.
read the caption
Table 2: Comparison of our proposed method with the State-of-the-art methods on the DomainBed benchmark. denotes ResNet-50 backbone; denotes frozen CLIP ViT-B/16 encoder; denotes fine-tuning the entire CLIP ViT-B/16 encoder, * denotes the two rounds inference-time fine-tuning. Red and indicate the best performance in each group.

🔼 This table compares the performance of the proposed CLIPCEIL model against several state-of-the-art (SOTA) domain generalization methods. It shows the average accuracy across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). Different model variations are presented (ResNet-50, frozen CLIP ViT-B/16 encoder, fine-tuned CLIP ViT-B/16 encoder), highlighting the superior performance of CLIPCEIL.
read the caption
Table 2: Comparison of our proposed method with the State-of-the-art methods on the DomainBed benchmark. denotes ResNet-50 backbone; denotes frozen CLIP ViT-B/16 encoder; denotes fine-tuning the entire CLIP ViT-B/16 encoder, * denotes the two rounds inference-time fine-tuning. Red and indicate the best performance in each group.

🔼 This table compares the performance of the proposed CLIPCEIL model against several state-of-the-art (SOTA) domain generalization methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). It shows the average accuracy of each method on each dataset, highlighting the superior performance of CLIPCEIL and its variants (CLIPCEIL++) compared to other approaches that use either ResNet-50 or CLIP as the base model. The table also indicates whether methods fine-tune the whole model, only a part, or use inference-time fine-tuning.
read the caption
Table 2: Comparison of our proposed method with the State-of-the-art methods on the DomainBed benchmark. denotes ResNet-50 backbone; denotes frozen CLIP ViT-B/16 encoder; denotes fine-tuning the entire CLIP ViT-B/16 encoder, * denotes the two rounds inference-time fine-tuning. Red and indicate the best performance in each group.

🔼 This table compares the performance of the proposed CLIPCEIL model against several state-of-the-art (SOTA) domain generalization methods. It shows the average accuracy across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). Different model variations are included, such as those using ResNet-50 and CLIP ViT-B/16 backbones, and those that fine-tune the entire CLIP model or employ inference-time fine-tuning. The table highlights CLIPCEIL’s superior performance.
read the caption
Table 2: Comparison of our proposed method with the State-of-the-art methods on the DomainBed benchmark. denotes ResNet-50 backbone; denotes frozen CLIP ViT-B/16 encoder; denotes fine-tuning the entire CLIP ViT-B/16 encoder, * denotes the two rounds inference-time fine-tuning. Red and indicate the best performance in each group.

🔼 This table compares the performance of the proposed CLIPCEIL model with several state-of-the-art domain generalization (DG) methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). It shows the average accuracy for each method on each dataset and highlights the best-performing methods in each group, considering different model architectures (ResNet-50, frozen CLIP ViT-B/16, fine-tuned CLIP ViT-B/16) and inference-time fine-tuning.
read the caption
Table 2: Comparison of our proposed method with the State-of-the-art methods on the DomainBed benchmark. denotes ResNet-50 backbone; denotes frozen CLIP ViT-B/16 encoder; denotes fine-tuning the entire CLIP ViT-B/16 encoder, * denotes the two rounds inference-time fine-tuning. Red and indicate the best performance in each group.

🔼 This table compares the performance of the proposed CLIPCEIL model with several state-of-the-art domain generalization methods on the VLCS benchmark dataset. The comparison includes ResNet-50 based models and CLIP-based models. CLIPCEIL demonstrates superior performance compared to other methods on this dataset. The table shows the average accuracy across different domains for each model.
read the caption
Table 9: Detailed comparison of our proposed method with the State-of-the-art methods on the VLCS dataset. * denotes the models that utilize the ResNet-50 backbone, and the rest utilize CLIP ViT-B/16 backbone.
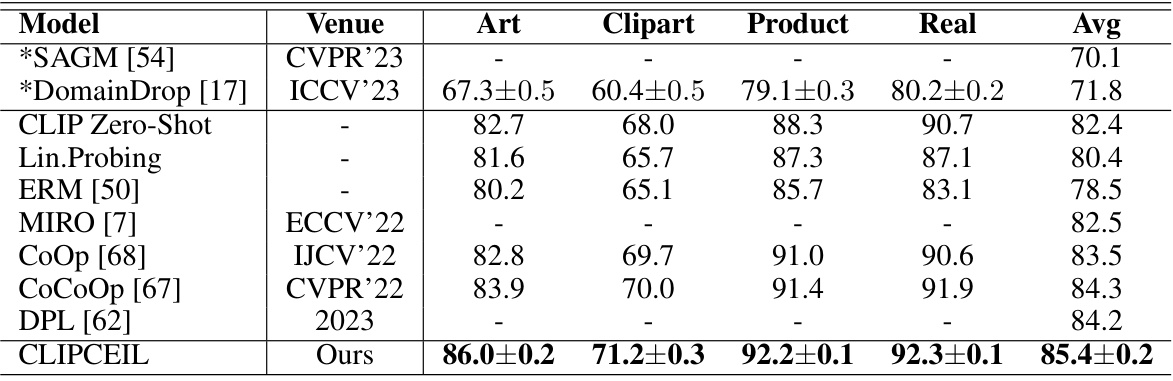
🔼 This table presents a detailed comparison of the proposed CLIPCEIL method with several state-of-the-art domain generalization methods on the OfficeHome benchmark dataset. It compares the average accuracy across four different domains (Art, Clipart, Product, Real) and overall average accuracy. The models compared use either ResNet-50 or CLIP ViT-B/16 as the backbone architecture, which is noted in the table.
read the caption
Table 10: Detailed comparison of our proposed method with the State-of-the-art methods on the OfficeHome dataset. * denotes the models that utilize the ResNet-50 backbone, and the rest utilize CLIP ViT-B/16 backbone.

🔼 This table compares the performance of the proposed CLIPCEIL model with other state-of-the-art domain generalization methods on the TerraIncognita dataset. It shows the average accuracy achieved by each method across four different sub-datasets (L100, L38, L43, L46) of the TerraIncognita dataset. The table highlights the superior performance of CLIPCEIL in comparison to other methods, demonstrating its effectiveness in handling domain shift during generalization.
read the caption
Table 11: Detailed comparison of our proposed method with the State-of-the-art methods on the TerraIncognita dataset. * denotes the models that utilize the ResNet-50 backbone, and the rest utilize the CLIP ViT-B/16 backbone.

🔼 This table compares the performance of CLIPCEIL using different backbones (ResNet-50 and ViT-based models) on the OfficeHome dataset. It shows the average accuracy across various image categories (Art, Clipart, Product, Real) and compares it to the performance of other models (SAGM, SWAD, DomainDrop, DISPEL, CLIP Zero-shot). This helps to understand the impact of the backbone architecture on the performance of the proposed method.
read the caption
Table 13: Performance with different backbones on OfficeHome datasets.

🔼 This table presents the ablation study on the architecture of the adapter g, comparing different designs, including a single linear projector, a linear projector with added refinement and direction loss, average pooling, a two-layer MLP, and the final CLIPCEIL model with a transformer layer. The results show the average accuracy across four domains (A, C, P, R) of the OfficeHome dataset for each adapter architecture, demonstrating the impact of each design choice on model performance.
read the caption
Table 14: Performance of a linear layer adapter g on OfficeHome dataset with ViT-B/16 backbone.

🔼 This table presents a comparison of the performance of using both visual and text multi-scale adapters versus using only a visual multi-scale adapter in the CLIPCEIL model. The results are shown for the Art, Clipart, Product, and Real categories of the OfficeHome dataset, along with the average performance across all four categories. It highlights the relative contribution of visual versus combined visual and textual features for improved generalization.
read the caption
Table 15: Performance comparison with text encoder adapter with ViT-B/16 backbone.
Full paper#