↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for guiding large language models (LLMs) in complex tasks, like web navigation, often struggle due to the models’ limited knowledge in such domains. Demonstration-based in-context learning, while intuitive, proves insufficient when faced with diverse, dynamic environments and lengthy context limitations. This paper introduces AUTOGUIDE, a novel framework that addresses this challenge.
AUTOGUIDE automatically extracts implicit knowledge from offline experiences to generate context-aware guidelines expressed in clear natural language. These guidelines are specifically designed to be concise and relevant to the current situation. The effectiveness of AUTOGUIDE is demonstrated through rigorous evaluations across various benchmark domains, including real-world web navigation, showcasing a significant improvement over existing methods. This approach enhances LLM agents’ adaptability and performance by supplying the pertinent information exactly when needed.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working with large language models (LLMs) and AI agents. It directly addresses the challenge of effectively guiding LLMs in unfamiliar domains, a critical limitation of current in-context learning methods. AUTOGUIDE offers a novel, data-driven approach for generating and selecting context-aware guidelines that significantly enhances LLM agent performance. The findings pave the way for more robust and adaptable AI agents capable of handling complex tasks and dynamic environments. Its focus on concise, natural language guidelines offers a practical and easily transferable solution. Furthermore, the evaluation using diverse benchmark domains and multi-modal websites establishes the broad applicability of AUTOGUIDE.
Visual Insights#
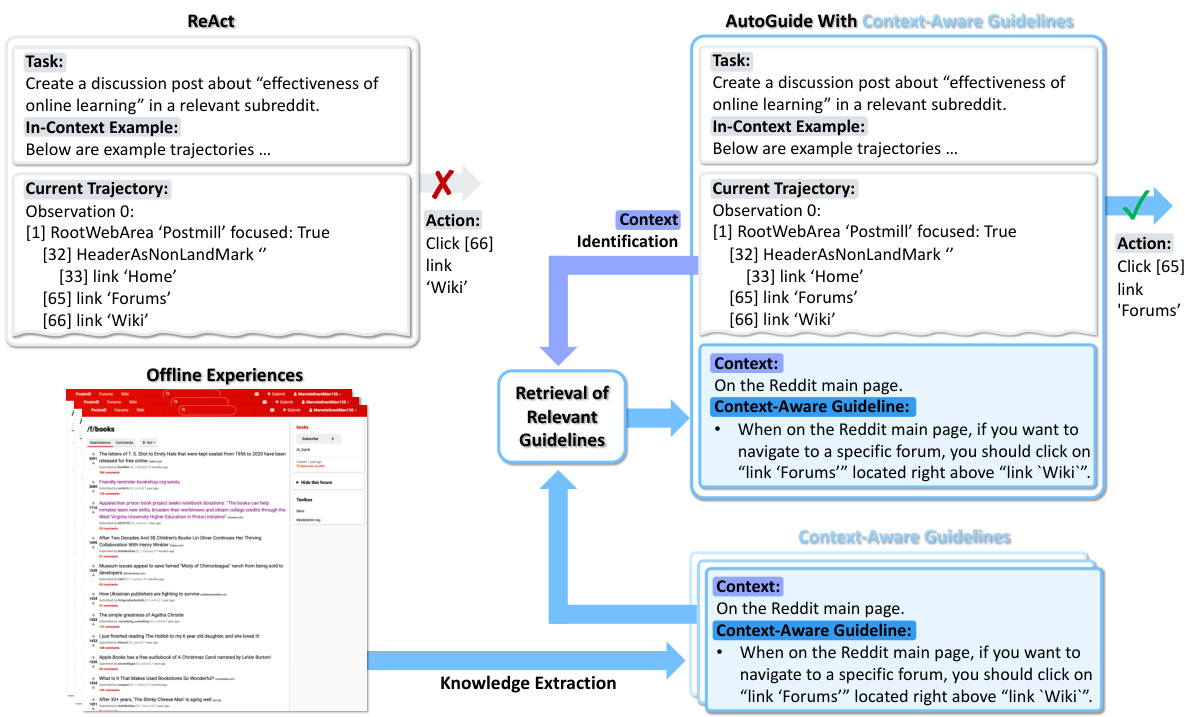
This figure illustrates the AUTOGUIDE framework. It shows how offline experiences are used to automatically generate context-aware guidelines. These guidelines are then used during the decision-making process of a large language model (LLM) agent. The key idea is to identify the context of the current situation and then retrieve relevant guidelines expressed in natural language. This approach improves the LLM agent’s performance by providing it with pertinent knowledge it might otherwise lack.

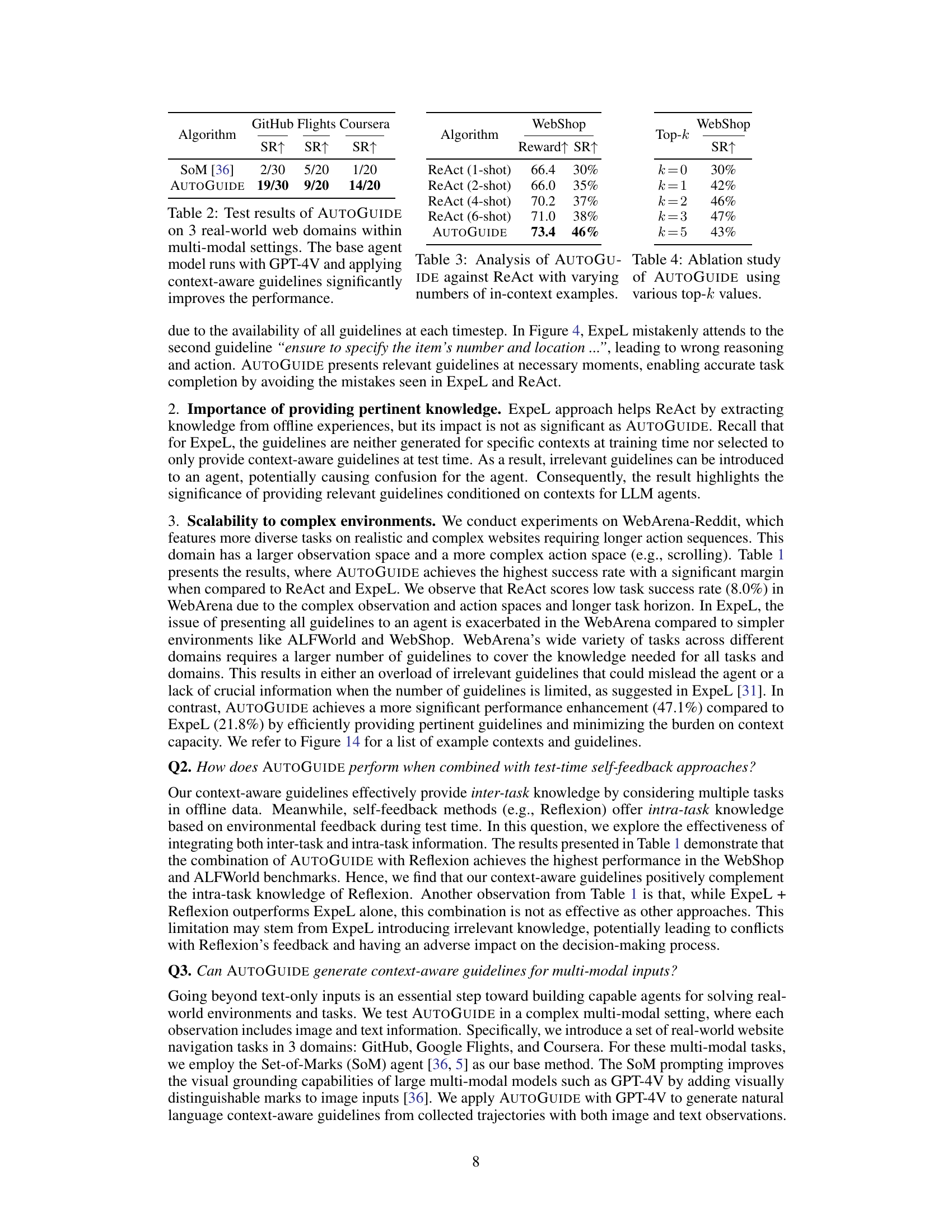
This table presents the performance comparison of different methods (ReAct, ExpeL, and AUTOGUIDE) across three benchmark tasks: ALFWorld, WebShop, and WebArena. It shows the success rate and reward achieved by each method, both with and without the addition of Reflexion (a self-reflection technique). The base language model used varies across the tasks (GPT-3.5-turbo for ALFWorld and WebShop; GPT-4-turbo for WebArena). Due to token limitations, Reflexion was not tested with WebArena.
In-depth insights#
LLM-based Agents#
LLM-based agents represent a significant advancement in AI, leveraging the power of large language models (LLMs) for complex sequential decision-making tasks. Their strength lies in the ability to combine pre-trained LLM capabilities with planning and reasoning, enabling effective policy execution in diverse domains. However, challenges exist, particularly when dealing with unfamiliar environments where LLMs lack sufficient knowledge. Traditional in-context learning, relying on demonstrations, struggles with the diversity and dynamism of real-world scenarios such as web navigation. The limitations of in-context learning, including context length restrictions and prompt sensitivity, highlight the need for more robust and adaptable methods. Context-aware guidelines offer a promising alternative, providing pertinent knowledge tailored to the specific situation, thus overcoming the shortcomings of simple demonstration-based approaches. The development and implementation of systems capable of automatically generating and selecting these context-aware guidelines are crucial for the future of LLM-based agents.
AutoGuide Framework#
The AutoGuide framework presents a novel approach to enhance Large Language Model (LLM) agents’ performance in complex, knowledge-scarce domains. It tackles the limitations of traditional in-context learning by automatically generating and selecting context-aware guidelines from offline data. This automation is crucial, as manually crafting such guidelines is laborious and inefficient. AutoGuide’s strength lies in its ability to express guidelines concisely in natural language, using a conditional structure that clearly specifies their applicability, thus providing highly relevant knowledge for the agent’s current decision-making process. The framework’s two core modules, context identification and guideline extraction, work in tandem to achieve this. By leveraging contrasting trajectories, AutoGuide efficiently extracts implicit knowledge from offline experiences, enabling effective knowledge transfer to online tasks. The resulting context-aware guidelines significantly boost LLM agent performance, as demonstrated through empirical evaluations in various benchmark domains. This makes it a significant advance, overcoming challenges faced by prior methods that either lacked contextual guidance or suffered from guideline overload.
Context-Aware Guides#
The concept of “Context-Aware Guides” in the research paper is crucial for bridging the knowledge gap between large language models (LLMs) and complex, unfamiliar domains. The core idea revolves around automatically generating concise, natural language guidelines that are not only informative but also explicitly tied to specific contexts. This approach contrasts with traditional in-context learning, which often struggles with handling diverse and dynamic situations. These context-aware guides provide the LLM agent with highly relevant information at each decision point, enhancing its ability to navigate complex tasks effectively. The method uses contrasting successful and unsuccessful trajectories from offline data to extract guidelines, enhancing the robustness and learning efficiency of the LLM agent. The explicit linkage of guidelines to contexts is key, preventing the LLM from being overwhelmed by irrelevant information. Ultimately, the contextual nature of these guides is the key innovation, effectively overcoming limitations of previous methods and significantly improving the performance of AI agents in various sequential decision-making domains.
Empirical Evaluation#
A robust empirical evaluation section is crucial for validating the claims of any research paper. For a paper on automated guideline generation for large language models (LLMs), a strong evaluation would necessitate diverse benchmark tasks encompassing varying complexities and modalities. Real-world tasks such as web navigation or embodied agent challenges would lend higher ecological validity than synthetic environments. The evaluation should compare the proposed approach (AutoGuide) against multiple baselines, including state-of-the-art methods and simpler alternatives to establish its superiority. Quantitative metrics like success rates and reward accumulation are essential, but qualitative analyses of the agent’s decision-making process could provide deeper insights into why AutoGuide succeeds or fails in specific scenarios. Furthermore, ablation studies systematically removing components of AutoGuide to understand individual contributions are vital. Finally, the robustness of the model should be assessed via out-of-distribution generalization, examining performance on unseen tasks or domains, demonstrating the model’s generalizability and practical applicability. A well-structured empirical evaluation strengthens the overall impact and trustworthiness of the research.
Future Directions#
Future research could explore enhancing AutoGuide’s ability to handle noisy or incomplete offline data, a common issue in real-world scenarios. Improving context identification and guideline extraction for more complex tasks involving multi-modal inputs (image, audio, video) is another crucial avenue. Further investigation into the generalization capabilities of generated guidelines across vastly different domains without retraining would unlock significant practical value. Evaluating the robustness of AutoGuide to biases present in offline data and developing techniques for mitigating such biases is vital for building fair and reliable AI agents. Finally, researching efficient strategies for continual learning in AutoGuide to adapt to ever-changing environments and the integration of other learning paradigms (e.g., reinforcement learning) could lead to more adaptable and intelligent agents. This also includes exploring methods for quantifying the quality of generated guidelines and contexts, crucial for systematic optimization and development of the overall approach.
More visual insights#
More on figures
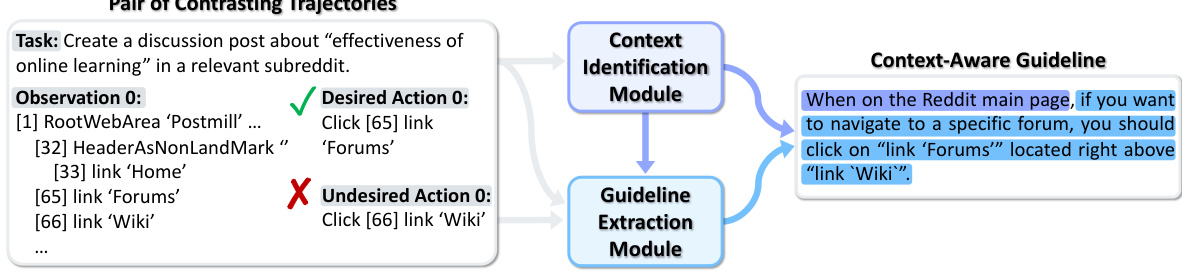
This figure illustrates the AUTOGUIDE framework. Offline experiences are processed by a context identification module and a guideline extraction module to generate context-aware guidelines. These guidelines are then used at test time to provide relevant knowledge to an LLM agent, improving its decision-making process in unfamiliar domains.

This figure illustrates the AUTOGUIDE framework. Offline experiences are used to generate context-aware guidelines. During testing, the current context is identified, and relevant guidelines are retrieved and used to improve the LLM agent’s decision-making. The process involves knowledge extraction, context identification, and guideline retrieval. Context-aware guidelines are concise and clearly state their applicability.

This figure compares the performance of three different methods (ReAct, ExpeL, and AUTOGUIDE) on the same task. ReAct fails due to selecting the wrong item. ExpeL makes mistakes because of irrelevant guidelines. AUTOGUIDE succeeds by selecting contextually relevant guidelines, demonstrating its effectiveness.
This figure illustrates the AUTOGUIDE framework. Offline experiences are used to generate context-aware guidelines. During testing, the current trajectory’s context is identified, and relevant guidelines are retrieved and incorporated into the LLM agent’s prompt, improving decision-making. The figure highlights the key difference between AUTOGUIDE and baselines, showcasing how AUTOGUIDE uses context to provide relevant guidelines, leading to better performance.

The figure illustrates the AUTOGUIDE framework. Offline experiences are processed to extract context-aware guidelines, which are then used by an LLM agent at test time. The agent’s current trajectory is analyzed to determine the relevant context, and the corresponding guidelines are applied to improve decision-making. This contrasts with methods that don’t use context-aware guidelines, which may perform poorly in unfamiliar domains where the LLM lacks sufficient knowledge.

This figure illustrates the AUTOGUIDE framework. Offline experiences are used to automatically generate context-aware guidelines. These guidelines are expressed in natural language and are only applied when their associated context matches the current situation. This contextual approach helps the LLM agent make better decisions, especially in unfamiliar domains.

This figure illustrates the AUTOGUIDE framework. Offline experiences are processed to extract context-aware guidelines. These guidelines are expressed in natural language and associated with specific contexts. During testing, the current context is identified, and the relevant guidelines are retrieved and incorporated into the LLM agent’s prompt, enhancing decision-making. The figure compares AUTOGUIDE’s approach to baselines that do not utilize context-aware guidelines.

The figure illustrates the AUTOGUIDE framework. Offline experiences are processed to extract context-aware guidelines, which are then used to guide an LLM agent during testing. The key advantage is that the guidelines are generated with their corresponding contexts, allowing for pertinent advice to be provided based on the current situation, improving LLM performance compared to methods that do not consider context.
More on tables
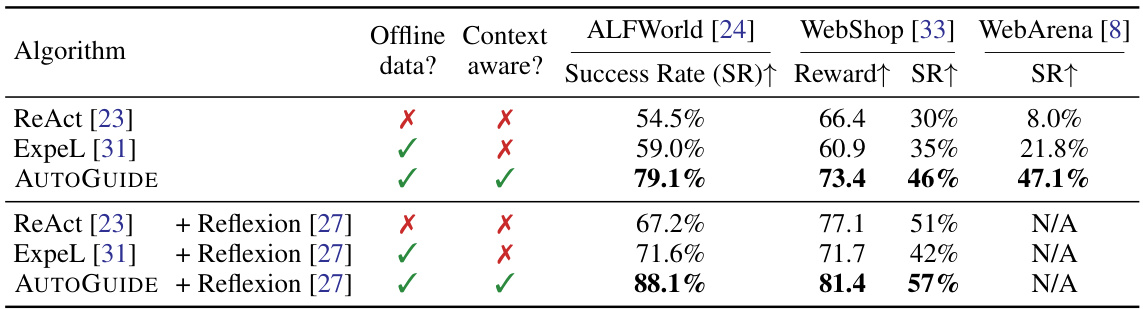
This table presents the performance comparison of different algorithms across three benchmark datasets: ALFWorld, WebShop, and WebArena. The success rate and reward are reported for each algorithm, including the baseline methods (ReAct and ExpeL) and their combinations with the Reflexion method. AUTOGUIDE consistently outperforms the baselines in terms of both success rate and reward. Note that the Reflexion method was not used with WebArena due to token limits.
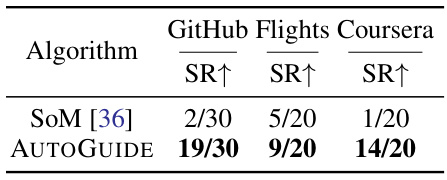
This table presents the results of AUTOGUIDE on three real-world multi-modal web domains: GitHub, Google Flights, and Coursera. The success rate (SR) is shown for each domain, comparing the performance of AUTOGUIDE against the SoM baseline. The results demonstrate a significant improvement in task success rates when using AUTOGUIDE’s context-aware guidelines with the GPT-4V model.
This table presents the results of experiments conducted on three benchmark datasets (ALFWorld, WebShop, and WebArena) comparing the performance of AUTOGUIDE against several baseline methods. The success rate and reward are shown for each method, with and without the addition of the Reflexion self-feedback method. The results demonstrate the superior performance of AUTOGUIDE in all three benchmark environments.

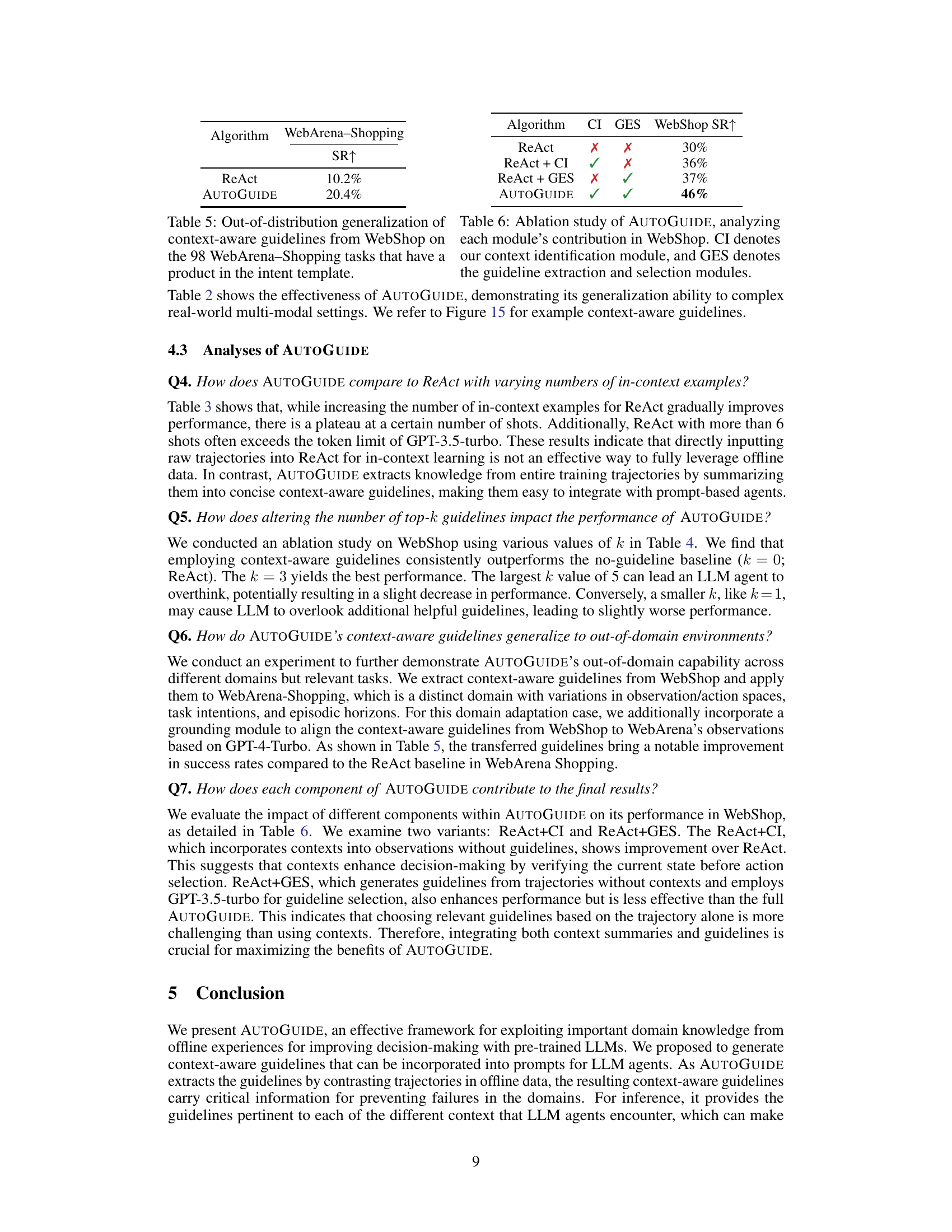
This table presents the results of applying WebShop’s context-aware guidelines to the WebArena-Shopping tasks. It specifically focuses on the 98 tasks that include a product in their description. The success rate (SR) of both ReAct and AUTOGUIDE are compared, showing AUTOGUIDE’s improved performance on out-of-distribution generalization.
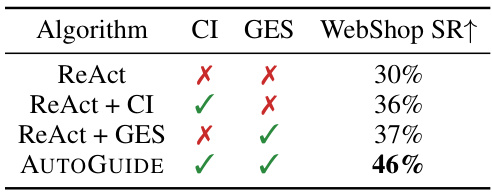
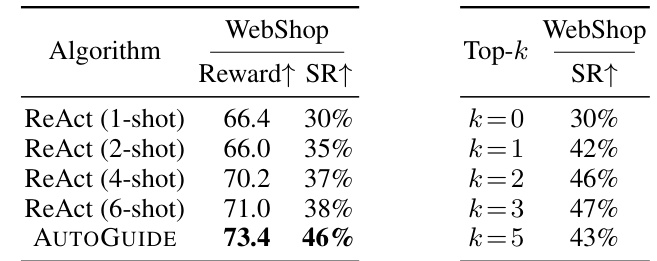
This ablation study analyzes the contribution of each module of AUTOGUIDE to the overall performance on the WebShop benchmark. It shows the success rate (SR) of ReAct alone, ReAct with only the context identification module (CI), ReAct with only the guideline extraction and selection module (GES), and AUTOGUIDE with both CI and GES. The results demonstrate the importance of both modules for achieving the highest performance.

This table compares the performance of different methods (ReAct, ExpeL, and AUTOGUIDE) across three benchmark tasks: ALFWorld, WebShop, and WebArena. It shows success rates and reward scores, illustrating the improvement achieved by AUTOGUIDE, especially when combined with Reflexion (a self-feedback method). Note that the token limits of the language models prevented using Reflexion on the WebArena tasks.
This table presents the results of the experiments performed on three different benchmark domains (ALFWorld, WebShop, and WebArena) using four different approaches: ReAct, ExpeL, AUTOGUIDE, and each of these combined with Reflexion. For each method and dataset, the success rate and reward are presented. The table highlights the superior performance of AUTOGUIDE, particularly when combined with Reflexion.

This table presents the results of experiments conducted on three different benchmark domains: ALFWorld, WebShop, and WebArena. The performance of several algorithms (ReAct, ExpeL, and AUTOGUIDE) are compared. The success rate and reward are presented for each algorithm, both with and without the addition of the Reflexion algorithm (which provides self-feedback to enhance learning). The table also notes which algorithms utilize offline data, highlighting AUTOGUIDE’s performance gains when leveraging this information.
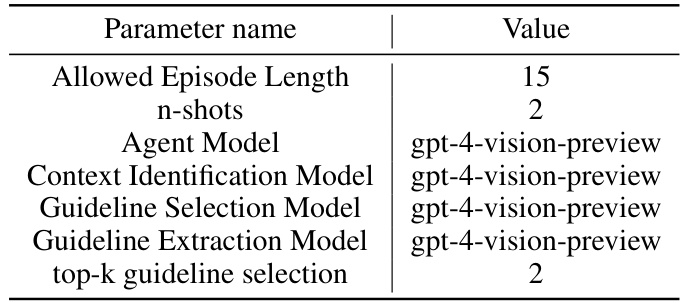
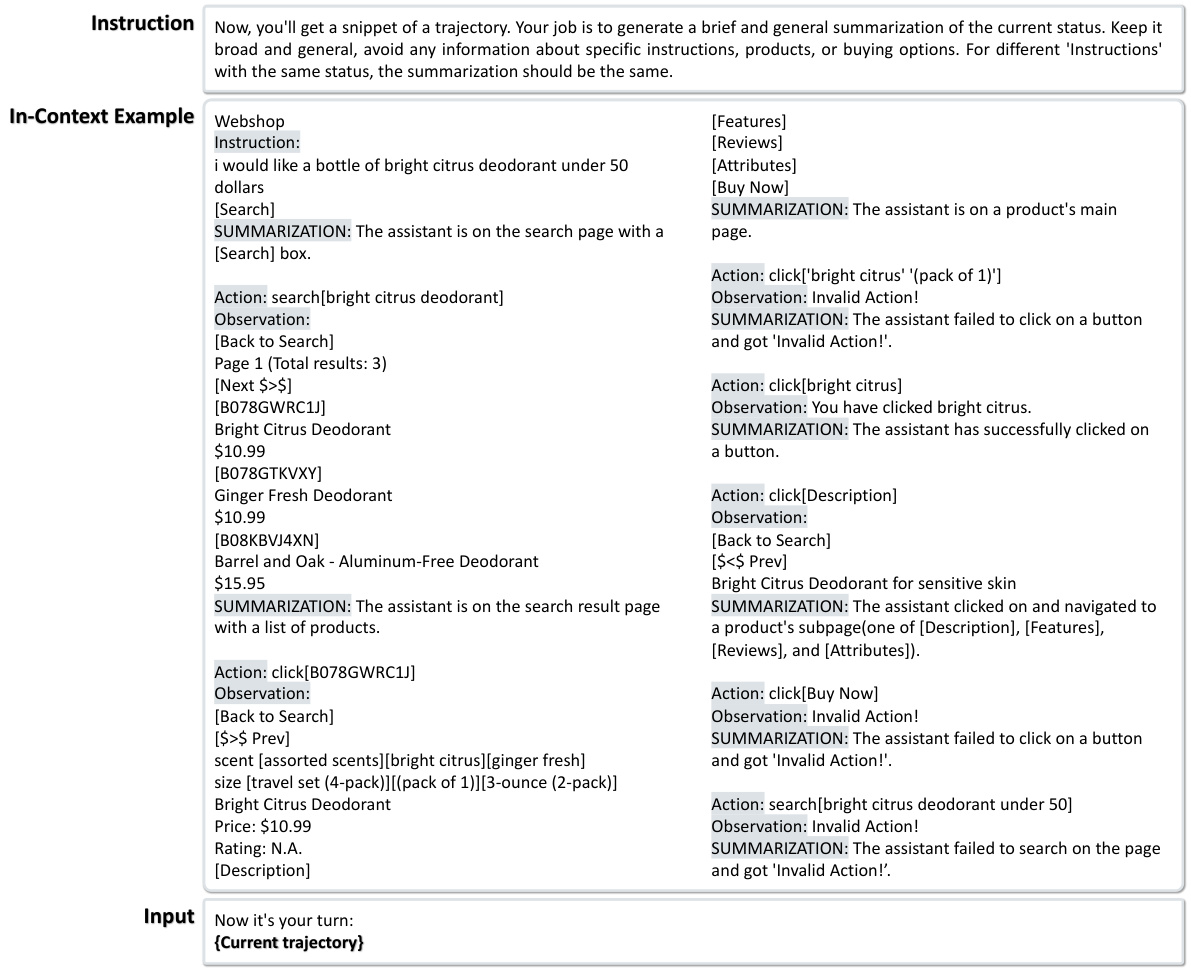
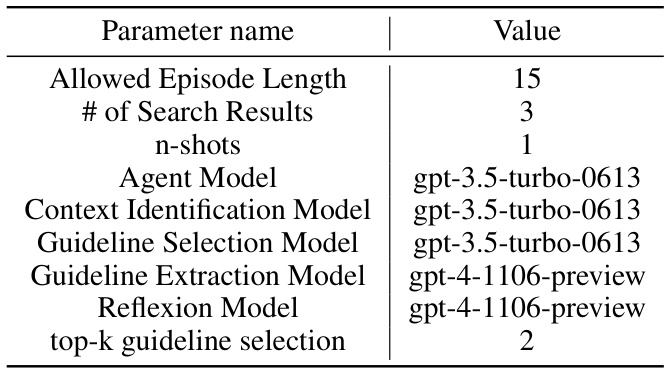
This table shows the hyperparameters used in the experiments conducted on real-world websites, which involve multi-modal inputs (image and text). The parameters specify the maximum allowed number of actions within an episode, the number of examples provided for in-context learning, the large language models used for various tasks (agent action generation, context identification, guideline selection, and guideline extraction), and the number of top guidelines selected at each step.

This table presents the results of experiments on three benchmark tasks: ALFWorld, WebShop, and WebArena. It compares the performance of several methods, including ReAct, ExpeL, and AUTOGUIDE, with and without the addition of the Reflexion self-reflection technique. Success rate and reward are shown for each method across the three tasks, highlighting the impact of context-aware guidelines and self-reflection on performance. Note that the token limitations of GPT prevented the use of Reflexion on the WebArena task.
Full paper#