TL;DR#
Current No-Reference Point Cloud Quality Assessment (NR-PCQA) models struggle to separate content and distortion information, leading to inaccurate quality predictions. This is partly due to data imbalance, with limited variety in point cloud content compared to the range of distortions. Human visual perception also processes content and distortion differently.
DisPA, the proposed method, tackles these issues by using a dual-branch disentanglement network. This network minimizes mutual information between content and distortion representations, achieving explicit disentanglement. A masked auto-encoding strategy pre-trains the content-aware branch, addressing data imbalance and aligning with the human visual system’s processing. Extensive results show DisPA outperforms state-of-the-art methods on multiple PCQA datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in point cloud quality assessment because it introduces a novel disentangled representation learning framework. DisPA addresses the limitations of existing methods by minimizing mutual information between content and distortion representations, leading to more accurate and robust quality predictions. This work opens avenues for further research into disentangled representation learning and its applications in various multimedia quality assessment tasks.
Visual Insights#
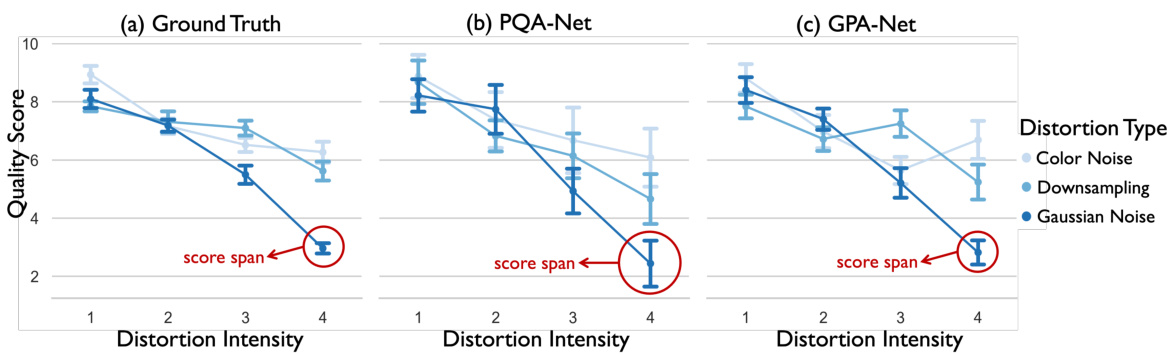
🔼 This figure compares the predicted quality scores from two no-reference point cloud quality assessment (NR-PCQA) models, PQA-Net and GPA-Net, with the ground truth scores from the SJTU-PCQA dataset. The graphs show how the quality scores vary for different distortion types (color noise, downsampling, Gaussian noise) and intensities (1-4). The red circles highlight the range of scores for different point cloud contents, even when the same distortion is applied. This visualization demonstrates the limitation of the existing NR-PCQA models in disentangling the effect of point cloud content and distortions on perceived quality.
read the caption
Figure 1: Statistics of SJTU-PCQA (part) [46] and predicted quality scores of NR-PCQA models (PQA-Net [21] and GPA-Net [32]). Quality scores of different distortion types are in lines of different colors. Red circles are to highlight the score span of different contents with the same distortion.
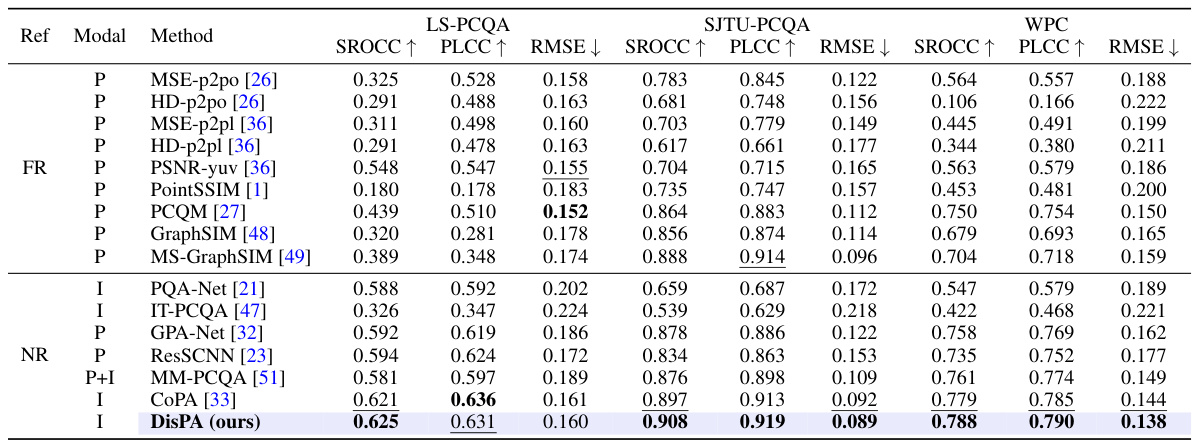
🔼 This table presents a quantitative comparison of the proposed DisPA method against several state-of-the-art methods for no-reference point cloud quality assessment (NR-PCQA). It evaluates performance across three datasets (LS-PCQA, SJTU-PCQA, and WPC) using three metrics: SROCC, PLCC, and RMSE. The table highlights the best and second-best performing methods for each dataset and metric, indicating whether higher or lower values are better for each metric. The modality of each method (point cloud or image-based) is also specified.
read the caption
Table 1: Quantitative comparison of the state-of-the-art methods and proposed DisPA on LS-PCQA [23], SJTU-PCQA [46], WPC [20]. The best results are shown in bold, and second results are underlined. 'P' / 'I' stands for the method is based on the point cloud/image modality, respectively. '↑'/'+' indicates that larger/smaller is better.
In-depth insights#
Disentangled NR-PCQA#
Disentangled NR-PCQA signifies a novel approach to no-reference point cloud quality assessment (NR-PCQA) by separating the representation of point cloud content from distortion patterns. Traditional NR-PCQA methods often learn these aspects jointly, leading to entangled representations and hindering performance. A disentangled approach, however, allows for a more nuanced understanding of quality. This is crucial because perceptual quality stems from both content fidelity and the types and levels of distortions present. By disentangling these factors, the model can better predict perceived quality, leading to more accurate assessment, especially when dealing with diverse content and various distortion types. Minimizing mutual information (MI) between content and distortion representations is key to achieving effective disentanglement. This innovative method promises improved accuracy and generalization, paving the way for a more robust and reliable NR-PCQA framework.
MI-based Regularization#
The heading ‘MI-based Regularization’ suggests a method using mutual information (MI) to encourage disentanglement in a model’s learned representations. MI quantifies the statistical dependence between variables, so minimizing MI between different representation components (e.g., content and distortion) aims to make them statistically independent. This is crucial for tasks like perceptual point cloud quality assessment, where disentangling content and distortion helps isolate the impact of each on perceived quality. A key challenge is accurately estimating MI, which is often intractable for high-dimensional data. The authors likely employ an approximation method, such as a variational bound, to make the MI estimation computationally feasible and optimize it during training. Minimizing this MI estimate acts as a regularizer, guiding the model to learn representations where content and distortion are less entangled, ultimately improving the assessment’s accuracy and robustness.
Masked Autoencoding#
Masked autoencoding, a crucial technique in self-supervised learning, shines a light on the core concept of predicting masked portions of an input. In the context of the provided research paper, this method is cleverly employed to pre-train the content-aware encoder. By masking parts of rendered images from distorted point clouds, the model learns to reconstruct the complete images, effectively learning robust representations of point cloud content without relying on explicit labels. This approach addresses the challenge of data imbalance in point cloud quality assessment datasets, where there’s a limited variety of point cloud content compared to distortion types. The pre-training stage helps the encoder focus on semantic information rather than distortions, laying a crucial foundation for later disentangling content and distortion representations, ultimately improving the accuracy and robustness of perceptual quality prediction.
Mini-Patch Map#
The concept of a “Mini-Patch Map” in the context of point cloud analysis is a clever approach to disentangle content and distortion features. By decomposing multi-view images of a point cloud into smaller patches and constructing a map of these mini-patches, the method effectively isolates local distortion patterns from the global scene content. This strategy is particularly useful in no-reference point cloud quality assessment (NR-PCQA), where separating these distinct aspects of quality is crucial. The mini-patch map serves as input for a dedicated distortion-aware encoder, allowing the network to focus on low-level details indicative of distortion and reducing the influence of high-level semantic information that could otherwise confound the quality assessment. This technique, therefore, represents a significant improvement in disentangling representation learning for NR-PCQA, leading to more accurate and robust quality predictions, particularly when dealing with datasets where content and distortion vary widely.
Future of NR-PCQA#
The future of No-Reference Point Cloud Quality Assessment (NR-PCQA) is bright, driven by several key trends. Advances in deep learning, particularly in disentangled representation learning, promise more accurate and robust quality predictions, going beyond simple correlation to capture nuanced perceptual aspects. The development of more comprehensive and diverse datasets is crucial, addressing current limitations in content variety and distortion types, to better train and validate models. Exploring innovative data augmentation techniques will help overcome data scarcity challenges, making models more generalizable. Furthermore, integrating human perception models directly into the assessment pipeline will allow for more accurate alignment with actual user experience. Finally, cross-modal learning, combining information from multiple modalities like images or videos, along with point clouds, can potentially lead to breakthroughs in NR-PCQA accuracy.
More visual insights#
More on figures
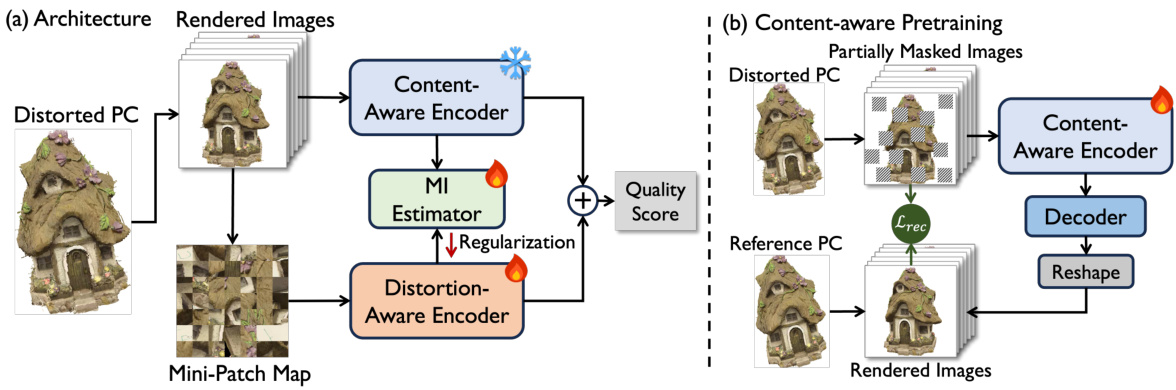
🔼 This figure illustrates the architecture of the DisPA model proposed in the paper. Panel (a) shows the overall architecture, which includes two encoders (F and G) for processing rendered images and mini-patch maps, respectively, an MI estimator (M) for disentangling the representations, and a quality score predictor (H). Panel (b) details the content-aware pretraining process, which uses a masked autoencoder to learn robust content representations.
read the caption
Figure 2: Architecture of proposed DisPA (a). Our DisPA consists of two encoders F and G for learning content-aware and distortion-aware representations, and an MI estimator M. The content-aware encoder F is pretrained using masked autoencoding (b). '' denotes concatenation.

🔼 This figure illustrates the process of generating a mini-patch map from multi-view images. The left side shows multi-view images of a rendered point cloud, each divided into a grid of patches. Selected patches (highlighted in green) are extracted from each view. The right side shows these selected patches assembled into a mini-patch map, which serves as input to the distortion-aware encoder. This process aims to create a representation focusing on local distortion patterns while blurring out global content information.
read the caption
Figure 3: Illustration of mini-patch map generation.

🔼 This figure shows a qualitative comparison of the predicted quality scores by three different NR-PCQA methods (PQA-Net, COPA, and the proposed DisPA) against the ground truth scores (GT) for eight different point cloud samples from the SJTU-PCQA and WPC datasets. The examples are grouped to show the performance of each method under the same distortion type (color noise and downsampling), highlighting how well each method handles variations in point cloud content while maintaining consistent distortion.
read the caption
Figure 5: Qualitative Evaluation of NR-PCQA methods (PQA-Net [21], CoPA [33] and DisPA) on SJTU-PCQA [46] and WPC [20]. Figure (b)-(d) share the same distortion pattern (i.e., color noise), same for (f)-(h) (i.e., downsampling). 'GT' denotes ground truth.

🔼 This figure compares the statistical analysis of predicted quality scores from the DisPA model against the ground truth scores from the SJTU-PCQA dataset (a subset). It focuses on the variation of scores across different distortion intensity levels and distortion types (color noise and downsampling). The key takeaway is that DisPA shows significantly less variation in its predictions compared to other methods (as shown in Figure 1), demonstrating its effectiveness and ability to handle variations in point cloud content more accurately. The red circles highlight the score span across various content with the same distortion type.
read the caption
Figure 4: Statistical Analysis of SJTU-PCQA (part) and predicted quality scores of DisPA.
Full paper#