↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current high-resolution image generation using latent diffusion models (LDMs) faces challenges due to the high computational cost and memory requirements of the autoencoder component. This paper introduces LiteVAE, a novel autoencoder design that significantly improves efficiency. Existing VAEs in LDMs are computationally expensive to train and affect the speed of diffusion training, often requiring pre-computation of latent codes. The encoder network’s high resource usage also hinders applications based on pretrained models.
LiteVAE addresses these issues by leveraging the 2D discrete wavelet transform to enhance scalability and computational efficiency. The authors investigate various training methodologies and decoder architectures, proposing enhancements such as self-modulated convolution to boost training and reconstruction quality. Their findings demonstrate that LiteVAE matches the quality of established VAEs while significantly reducing encoder parameters, resulting in faster training and lower GPU memory needs. Experiments show that LiteVAE outperforms VAEs of comparable complexity across multiple metrics.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and machine learning, particularly those working with latent diffusion models. It offers a novel, efficient VAE design that significantly reduces computational cost and memory requirements, a major bottleneck in high-resolution image generation. The improved efficiency and comparable or superior performance opens doors for larger-scale training, real-time applications, and research into more complex generative models. Its introduction of self-modulated convolution also contributes to a broader understanding and improvement of autoencoder architecture.
Visual Insights#
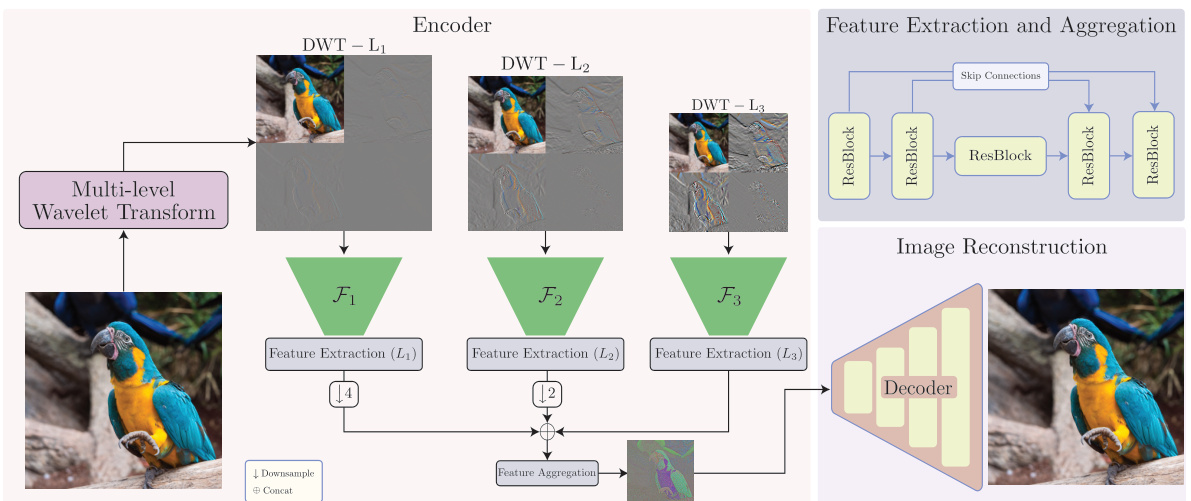
This figure illustrates the architecture of LiteVAE, a lightweight and efficient variational autoencoder for latent diffusion models. The input image undergoes a multi-level discrete wavelet transform (DWT), separating it into different frequency sub-bands. Each sub-band is processed by a separate feature extraction network (F1, F2, F3), using a lightweight UNet architecture without spatial downsampling. A feature aggregation module combines the features from all sub-bands to generate the latent representation. Finally, a fully convolutional decoder reconstructs the image from this latent code.
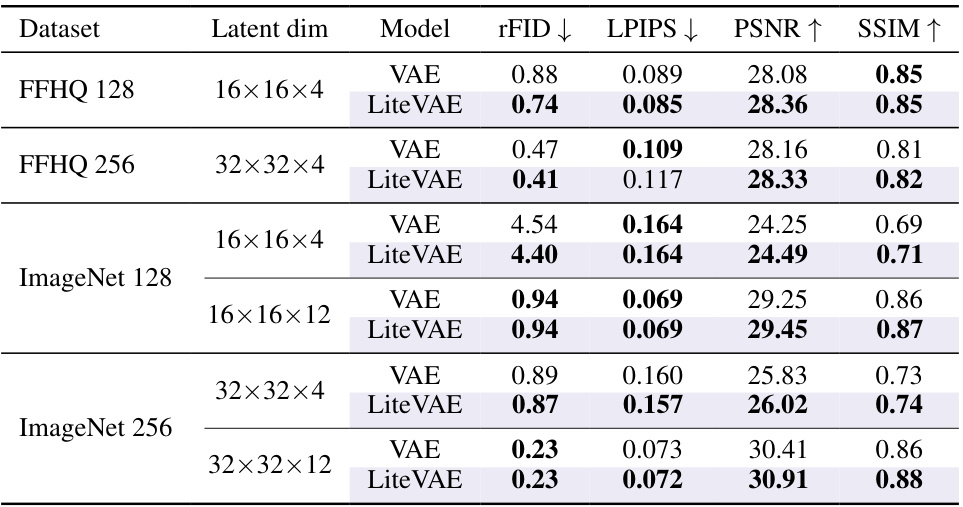
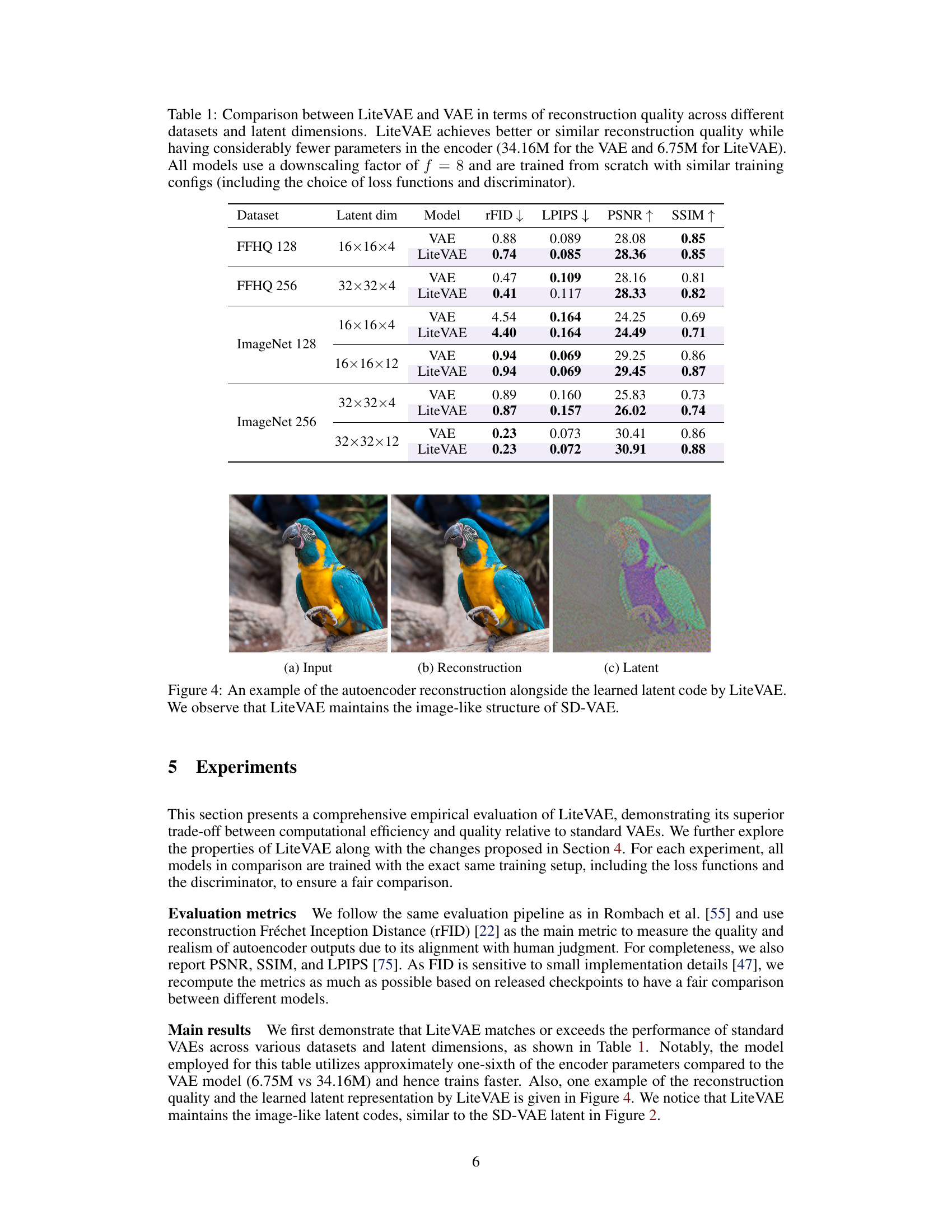
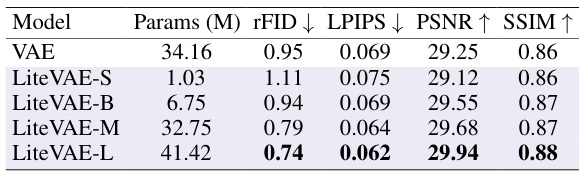
This table compares the reconstruction quality of LiteVAE and standard VAEs across different datasets (FFHQ and ImageNet) and latent dimensions. It shows that LiteVAE achieves comparable or better reconstruction quality (measured by rFID, LPIPS, PSNR, and SSIM) despite having significantly fewer parameters in its encoder (a six-fold reduction). All models were trained with similar settings for a fair comparison.
In-depth insights#
Wavelet VAE Design#
A wavelet-based variational autoencoder (VAE) design offers a compelling approach to enhance the efficiency of latent diffusion models (LDMs). The core idea is to leverage the 2D discrete wavelet transform (DWT) to decompose the input image into multi-level wavelet coefficients. This multi-resolution representation facilitates the extraction of compact and meaningful features, simplifying the encoder’s task and reducing computational costs. The proposed architecture typically consists of a wavelet processing stage followed by feature extraction and aggregation modules. The key advantage of this design lies in its ability to capture rich image information in a more compact manner compared to standard VAEs, leading to faster training and lower GPU memory requirements. The choice of wavelets, the depth of wavelet decomposition, and the architecture of the feature extraction and aggregation networks are crucial design choices that impact the final performance. Self-modulated convolutions (SMC) can be incorporated to address potential imbalances in the feature maps learned by the decoder, resulting in improved reconstruction quality and training stability. While the wavelet transform simplifies the encoder, the effectiveness of this approach ultimately depends on the complexity of the input data and the specific application requirements. Careful selection of the wavelet basis and the depth of decomposition is crucial for balancing the trade-off between efficiency and reconstruction quality.
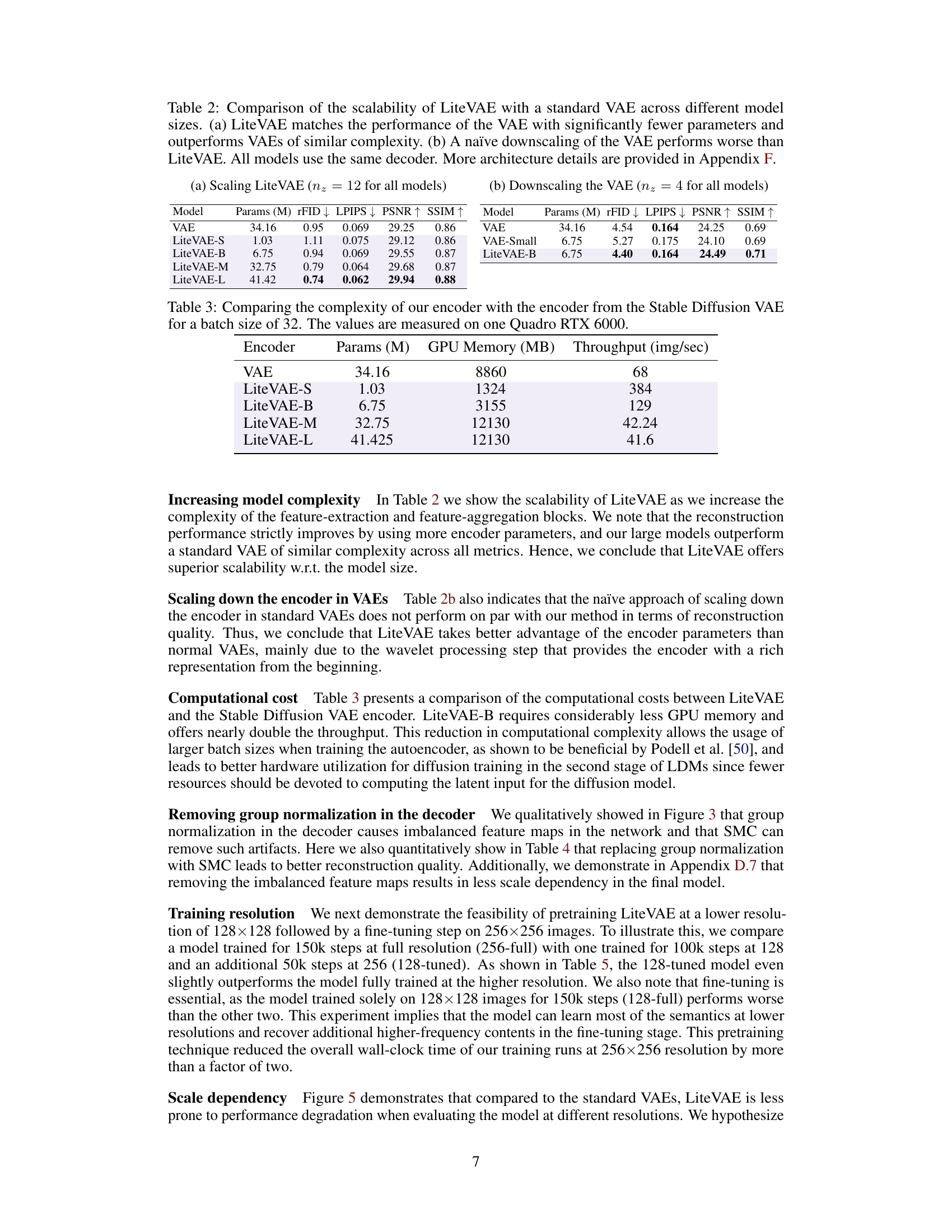
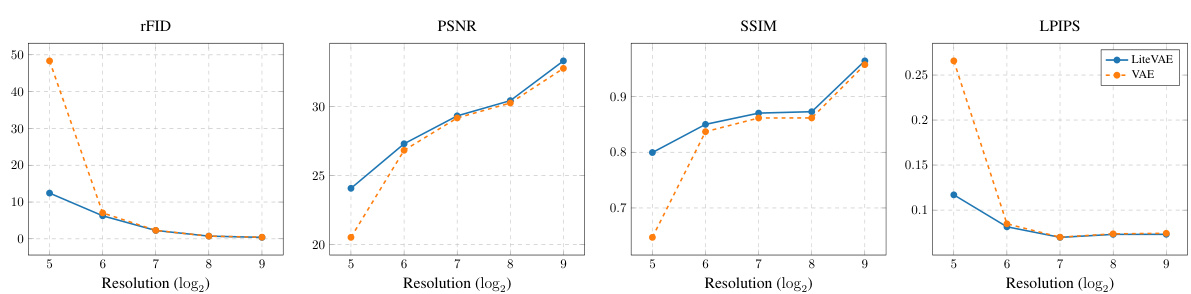
LiteVAE Scalability#
LiteVAE demonstrates strong scalability. Smaller LiteVAE models surprisingly match or exceed the performance of larger, standard VAEs, highlighting its efficiency. Increasing model size in LiteVAE leads to consistent improvements in reconstruction quality, showcasing its ability to leverage increased capacity effectively. Comparison with naive VAE downscaling reveals LiteVAE’s superior architecture, as simply reducing VAE parameters does not yield comparable results. The wavelet transform’s inherent multi-scale nature allows LiteVAE to efficiently capture image features, leading to fewer parameters needed for high-quality reconstruction. This efficiency translates into faster training and lower GPU memory requirements, making LiteVAE suitable for resource-constrained environments or large-scale applications. The superior scalability of LiteVAE is a key advantage, providing flexibility in balancing model size, performance, and resource consumption.
Ablation Study Insights#
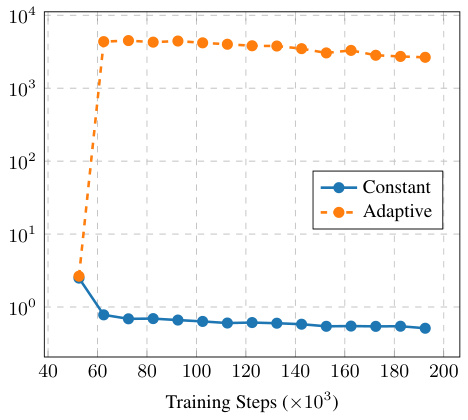
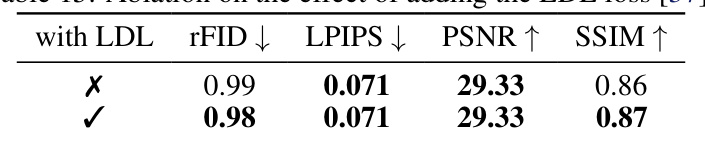
Ablation studies systematically remove components of a model to understand their individual contributions. In this research, removing the adaptive weight for the adversarial loss showed no significant impact, suggesting it’s not crucial and simplifies the training process. Using a constant weight instead is simpler and yields comparable results, highlighting the importance of considering efficiency. The impact of adding high-frequency loss functions, such as Gaussian and wavelet losses, is positive, improving the reconstruction quality, suggesting they capture important high-frequency details often lost in simpler models. Exploring the choice of discriminator architectures, the study reveals that a UNet-based discriminator outperforms others in terms of FID scores, suggesting its superior ability to differentiate between real and generated samples. The impact of lower training resolutions, such as 128x128, was significant in terms of compute time; while maintaining the reconstruction quality after fine-tuning, showcasing the potential for efficient training strategies that could be beneficial across various models.
Training Efficiency#
Training efficiency is a critical aspect of any machine learning model, especially for large-scale models like those used in high-resolution image generation. The paper introduces LiteVAE, a variational autoencoder designed for improved training efficiency in latent diffusion models (LDMs). LiteVAE achieves this by leveraging the 2D discrete wavelet transform, a technique that reduces the computational cost associated with processing high-resolution images. This leads to faster training times, lower GPU memory requirements, and ultimately makes high-resolution image generation more accessible. Beyond the core architecture, LiteVAE also incorporates several training enhancements. These include a novel training resolution strategy that leverages lower resolution training initially before fine-tuning on higher resolutions, ultimately reducing overall training time. Additionally, the self-modulated convolution (SMC) is introduced, which addresses issues of feature map imbalance in existing decoder networks, contributing to faster convergence and better training dynamics. The combination of architectural and training improvements significantly enhances the efficiency of the autoencoding process in LDMs, enabling significant improvements in speed and computational resource usage, while maintaining or even exceeding the quality of state-of-the-art approaches. The results suggest LiteVAE provides a highly effective approach to enhance training efficiency and scalability for various image generation applications.
Future Research#
The authors of the LiteVAE paper, while presenting a compelling case for their efficient autoencoder architecture, wisely acknowledge the limitations of their current work. Future research should focus on expanding LiteVAE’s applicability beyond image generation in latent diffusion models. The wavelet transform’s effectiveness in other domains, such as video processing, audio, and even high-dimensional data analysis, warrants investigation. Exploring the use of LiteVAE in conjunction with other generative modeling techniques, such as GANs or normalizing flows, could reveal interesting synergies and improved performance. Further investigation into the latent space learned by LiteVAE is crucial, potentially focusing on disentanglement, interpretability, and its inherent properties. A deeper analysis of the impact of the wavelet transform’s inherent multi-resolution capabilities on the overall quality and efficiency across diverse datasets and model scales would enhance understanding. Finally, extending LiteVAE to handle varying input resolutions and data modalities seamlessly is key to ensuring its wider adoption in various applications.
More visual insights#
More on figures

The figure shows RGB visualization of the first three channels of a Stable Diffusion VAE (SD-VAE) latent code. The latent code is image-like, showing strong similarity to the input image, which motivates the authors’ exploration of simplifying the latent representation learning in LiteVAE.

This figure shows a comparison of feature maps from the final decoder block with and without Self-Modulated Convolutions (SMC). The left two images are the feature maps using Group Normalization, where imbalances in feature magnitudes are clearly visible as bright spots. The right two images demonstrate the use of SMC, resulting in more balanced and less extreme feature magnitudes. This highlights the benefits of SMC in preventing feature map imbalance, improving the quality of the decoder’s output.

This figure shows a schematic of the LiteVAE architecture. The input image undergoes a multi-level wavelet transform, separating it into different frequency sub-bands. Each sub-band is processed by a separate feature extraction network (a lightweight UNet). These features are then aggregated to create a compact latent representation. The decoder, similar to Stable Diffusion’s VAE, reconstructs the image from this latent code. The design prioritizes efficiency without sacrificing reconstruction quality.
This figure shows the architecture of LiteVAE, a lightweight and efficient variational autoencoder for latent diffusion models. The input image is first decomposed into multi-level wavelet coefficients using a multi-level wavelet transform. Each wavelet sub-band is processed independently by a feature extraction network. A feature aggregation module combines the features from each sub-band to produce the final latent code. This code is then used by the decoder to reconstruct the original image. The decoder is based on a lightweight UNet, and the entire architecture is designed to improve efficiency and maintain high image reconstruction quality compared to standard VAEs used in latent diffusion models.

This figure provides a detailed overview of the LiteVAE architecture. The process begins with a multi-level wavelet transform of the input image, breaking it down into different frequency components. Each component is then fed into a separate feature extraction network. These individual feature representations are then combined in a feature aggregation module to produce the final latent code. This code is then decoded via a lightweight U-Net-based decoder (similar to Stable Diffusion’s VAE) to reconstruct the original image. The key takeaway is the efficient use of wavelet decomposition to reduce computational cost without sacrificing reconstruction quality.
This figure illustrates the architecture of LiteVAE, a lightweight and efficient variational autoencoder for latent diffusion models. It shows how the input image is processed through a multi-level wavelet transform, feature extraction, and aggregation to generate a compact latent code, which is then decoded back into the reconstructed image. The key is using a lightweight UNet for feature extraction and aggregation, avoiding spatial downsampling/upsampling, thus making it more efficient than standard VAEs.
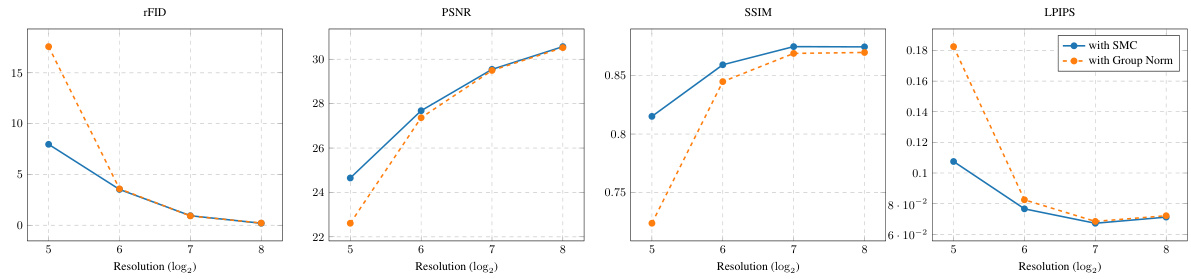
This figure shows feature maps from the decoder’s final block, comparing before and after replacing group normalization with self-modulated convolutions (SMC). The SMC approach leads to more balanced feature maps, improving the quality of image reconstruction.

This figure shows the architecture of LiteVAE, a lightweight and efficient variational autoencoder for latent diffusion models. The input image is first processed using a multi-level 2D discrete wavelet transform to decompose it into multiple wavelet sub-bands. Each sub-band is then fed into a separate feature extraction network. These feature maps are aggregated to produce the latent representation. Finally, the decoder, similar to Stable Diffusion’s VAE, reconstructs the image from the latent code. The use of wavelets and a lightweight UNet contribute to LiteVAE’s efficiency compared to standard VAEs.
More on tables
This table compares the scalability of LiteVAE and a standard VAE across various model sizes. Part (a) shows that LiteVAE achieves comparable or better performance than the VAE with significantly fewer parameters. Part (b) demonstrates that simply downscaling a standard VAE does not yield the same results as LiteVAE’s design.
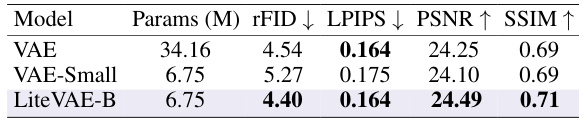
This table compares the scalability of LiteVAE and a standard VAE across different model sizes. It shows that LiteVAE achieves comparable or better performance with significantly fewer parameters. It also demonstrates that simply downscaling a standard VAE is less effective than LiteVAE’s design.
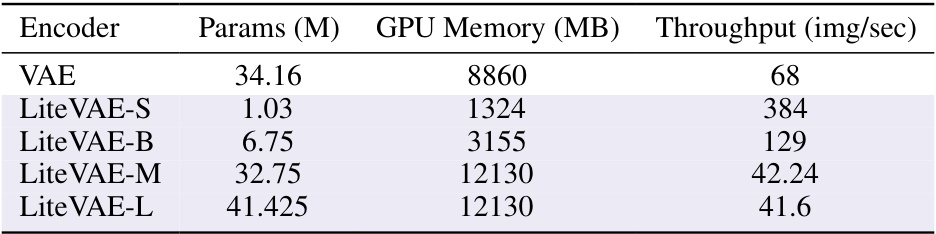
This table compares the computational complexity of the proposed LiteVAE encoder against the Stable Diffusion VAE encoder. It shows the number of parameters (in millions), GPU memory usage (in MB), and throughput (images per second) for each model. The comparison highlights the significant efficiency gains achieved by LiteVAE.

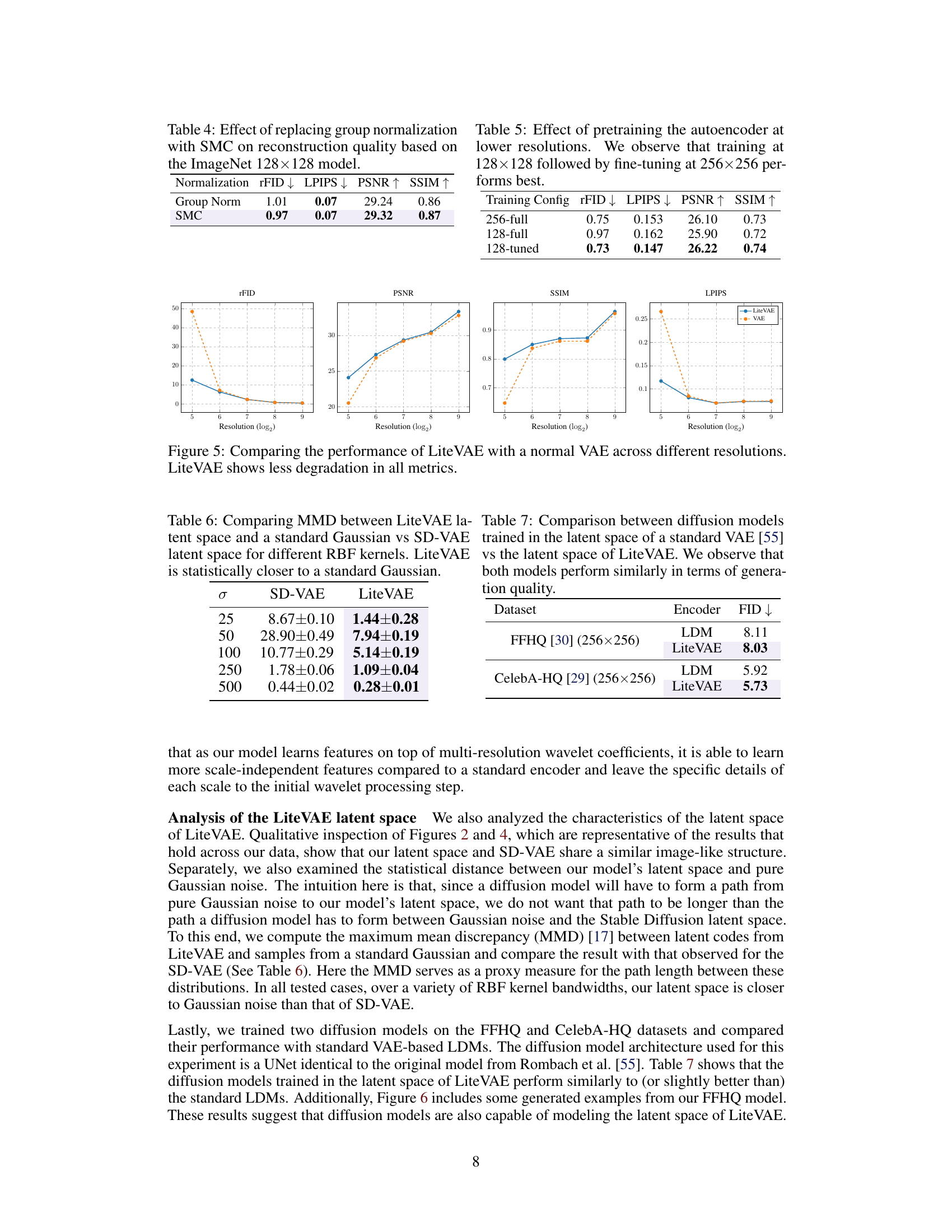
This table shows the results of replacing group normalization layers with self-modulated convolution (SMC) layers in the decoder of the LiteVAE model trained on the ImageNet 128x128 dataset. It compares the reconstruction quality using metrics such as rFID, LPIPS, PSNR, and SSIM. Lower values for rFID and LPIPS indicate better quality, while higher PSNR and SSIM values indicate better quality.
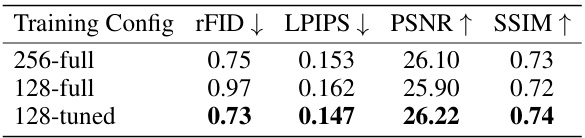
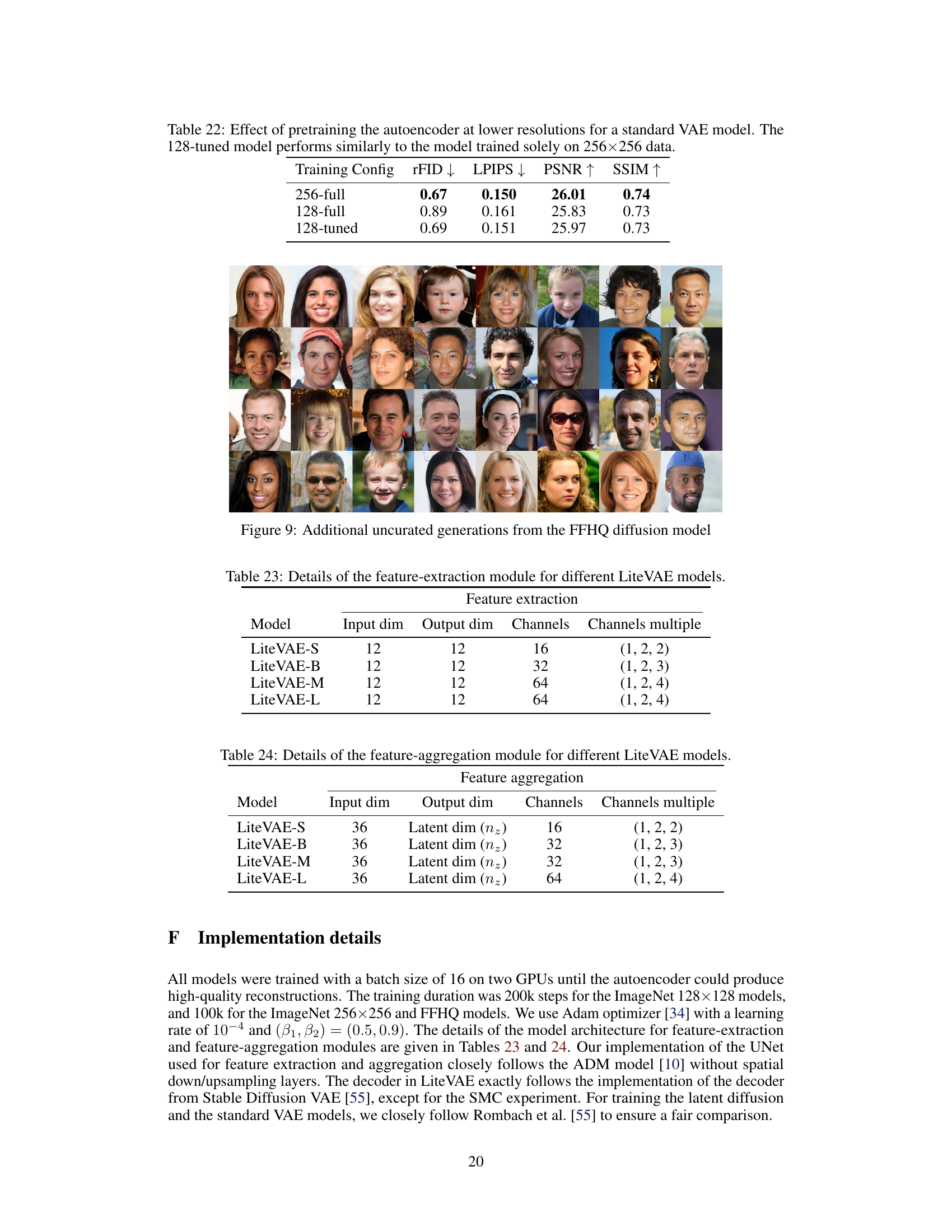
This table compares the performance of three different training configurations for the autoencoder. The ‘256-full’ configuration trains the model at the full 256x256 resolution for 150k steps. The ‘128-full’ configuration trains the model at a lower 128x128 resolution for 150k steps. The ‘128-tuned’ configuration first trains the model at 128x128 resolution for 100k steps, and then fine-tunes it at 256x256 resolution for an additional 50k steps. The results show that the ‘128-tuned’ configuration achieves the best reconstruction quality, as measured by rFID, LPIPS, PSNR, and SSIM.

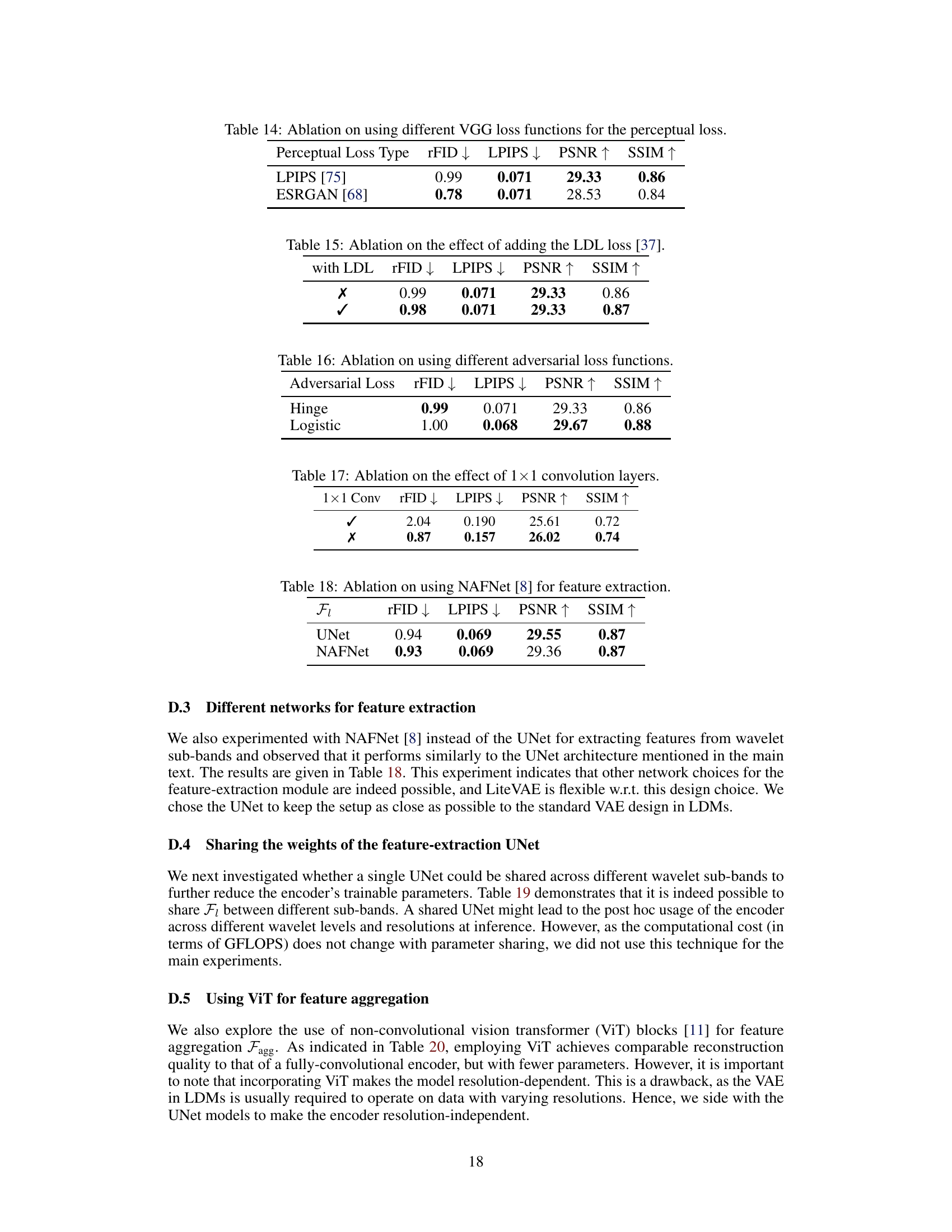
This table compares the Maximum Mean Discrepancy (MMD) between the latent spaces generated by LiteVAE and the Stable Diffusion VAE (SD-VAE) against a standard Gaussian distribution using different radial basis function (RBF) kernels. Lower MMD values indicate a closer match to the Gaussian distribution. The results show that LiteVAE’s latent space is statistically more similar to a standard Gaussian distribution compared to the SD-VAE latent space, suggesting a simpler latent space structure for LiteVAE.

This table compares the Fréchet Inception Distance (FID) scores of diffusion models trained using two different VAEs: a standard VAE and LiteVAE. The FID is a metric used to evaluate the quality of generated images. Lower FID indicates better image quality. The results show that the diffusion models trained with both VAEs achieved comparable performance, suggesting that LiteVAE does not negatively impact the quality of generated images.

This table compares the reconstruction quality (measured by rFID, LPIPS, PSNR, and SSIM) of the model when using an adaptive weight versus a constant weight for the adversarial loss. The results show that using a constant weight yields slightly better results.
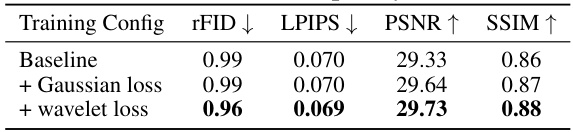
This table presents the ablation study of adding Gaussian and wavelet loss to the training process. The baseline model is trained without any additional loss functions. The results show that adding both Gaussian and wavelet loss leads to improved reconstruction quality, as measured by rFID, LPIPS, PSNR, and SSIM.
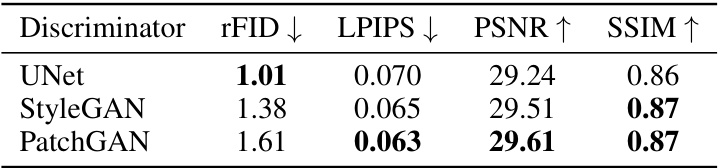
This table compares the reconstruction quality achieved by using different discriminators (UNet, StyleGAN, and PatchGAN) in the LiteVAE model. The metrics used to evaluate the quality are rFID (lower is better), LPIPS (lower is better), PSNR (higher is better), and SSIM (higher is better). The results show that the UNet discriminator performs best across all metrics.
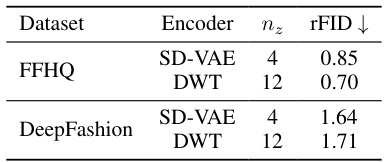
This table compares the reconstruction quality (measured by rFID) of the standard VAE encoder used in Stable Diffusion and a simple encoder that only uses the discrete wavelet transform (DWT) on two datasets: FFHQ and DeepFashion. The results show that even a non-learned encoder based on DWT can achieve relatively good reconstruction quality, especially when a higher number of channels (nz) is used. This demonstrates the potential efficiency gains of using wavelet-based encoders for autoencoders in LDMs.
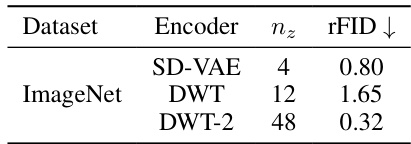
This table compares the reconstruction quality (measured by rFID) of different encoders on the ImageNet dataset. It shows that a simple DWT encoder with 12 channels performs poorly compared to a standard VAE, but a more complex DWT encoder with 48 channels can achieve comparable results to the VAE. This highlights the importance of a learned encoder with a richer feature representation for more complex datasets.

This table compares the Fréchet Inception Distance (FID) scores of diffusion models trained using two different VAEs: a standard VAE and LiteVAE. The FID score measures the quality of generated images. Lower FID scores indicate higher-quality images. The results show that diffusion models trained with LiteVAE achieve comparable image generation quality to those trained with a standard VAE.

This table compares the reconstruction quality of LiteVAE and a standard VAE across different datasets and latent dimensions. It shows that LiteVAE achieves similar or better reconstruction quality (measured by rFID, LPIPS, PSNR, and SSIM) despite having significantly fewer parameters in its encoder (a 6x reduction). All models used the same downsampling factor and similar training configurations.
This table compares the reconstruction quality of LiteVAE and standard VAEs across different datasets and latent dimensions. It shows that LiteVAE achieves comparable or better reconstruction quality with significantly fewer parameters in the encoder, highlighting its efficiency.

This table compares the reconstruction quality of LiteVAE and standard VAEs across different datasets (FFHQ and ImageNet) and latent dimensions. Key metrics include rFID, LPIPS, PSNR, and SSIM. LiteVAE demonstrates comparable or superior performance with significantly fewer encoder parameters, highlighting its efficiency gains.

This table compares the reconstruction quality of LiteVAE and VAE across different datasets and latent dimensions. It shows that LiteVAE achieves comparable or better reconstruction quality with significantly fewer parameters in its encoder, demonstrating improved efficiency.

This table compares the reconstruction quality of LiteVAE and standard VAE models across different datasets (FFHQ and ImageNet) and latent dimensions. It shows that LiteVAE achieves similar or better reconstruction quality (measured by rFID, LPIPS, PSNR, and SSIM) with significantly fewer parameters in the encoder, demonstrating its improved efficiency.

This table compares the reconstruction quality (rFID, LPIPS, PSNR, SSIM) of three different training configurations for the LiteVAE model on the ImageNet 128x128 dataset. The configurations vary in the training resolution and whether fine-tuning was performed. The results indicate that pretraining at a lower resolution (128x128) and then fine-tuning at a higher resolution (256x256) provides the best reconstruction quality. Training only at the lower resolution results in inferior performance compared to both other methods.

This table compares the scalability of LiteVAE and standard VAEs across different model sizes. It demonstrates that LiteVAE achieves comparable or better reconstruction quality with significantly fewer parameters, showcasing its superior scalability and efficiency. It also shows that simply downscaling a standard VAE does not achieve the same results as LiteVAE.

This table presents the ablation study results on removing the highest resolution wavelet sub-bands from the feature extraction process in LiteVAE. It compares the model’s performance (measured by rFID, LPIPS, PSNR, and SSIM) when using all wavelet sub-bands versus only the last two. The results show a clear performance degradation when higher-frequency information is excluded, highlighting the importance of multi-resolution analysis in LiteVAE.
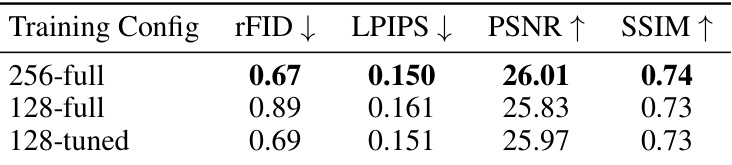
This table presents the results of an experiment to evaluate the effect of training the autoencoder at lower resolutions (128x128) before fine-tuning it at higher resolution (256x256). The results show that this approach (128-tuned) outperforms training only at the higher resolution (256-full) and even surpasses a model trained only at the lower resolution (128-full). This suggests that training at a lower resolution first allows the model to learn the fundamental image semantics efficiently before fine-tuning improves the detail at a higher resolution.
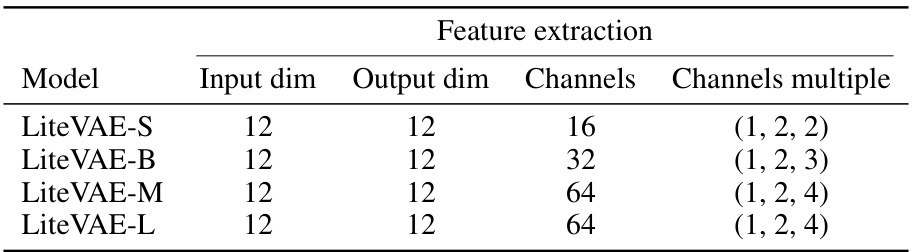
This table compares the scalability of LiteVAE and standard VAEs across different model sizes. It shows that LiteVAE achieves comparable or better performance with significantly fewer parameters. A simple downscaling of a VAE is shown to underperform LiteVAE.
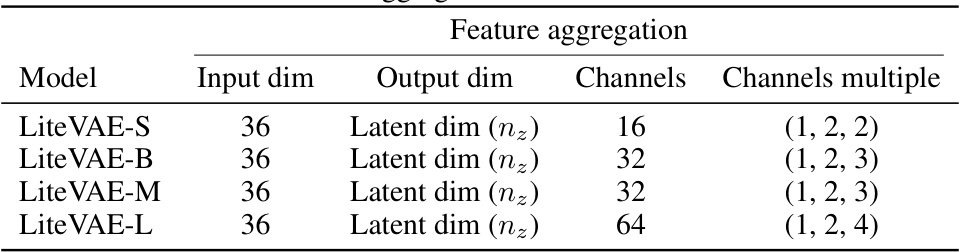
This table compares the scalability of LiteVAE and standard VAE across various model sizes. It demonstrates that LiteVAE achieves comparable or better reconstruction quality with significantly fewer parameters, showcasing its superior scalability and efficiency. The table also shows that simply downscaling a standard VAE does not yield the same benefits as the LiteVAE design.
Full paper#