TL;DR#
Current methods for aligning text-to-image models with human preferences rely on either reinforcement learning with complex reward models or direct fine-tuning on expensive pairwise preference data. These approaches are computationally costly and limited by data acquisition challenges. The challenge is to find a way to align models efficiently and effectively without collecting large amounts of manually labeled data.
This paper introduces Diffusion-KTO, a novel framework that tackles these challenges. Diffusion-KTO formulates the alignment objective as maximizing expected human utility using only per-image binary feedback (likes or dislikes). Instead of training a reward model or requiring pairwise preferences, it directly optimizes a utility function at each sampling step, making it computationally efficient. Experiments demonstrate that Diffusion-KTO significantly improves model alignment compared to existing methods, judged both by human users and automatic metrics.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach for aligning text-to-image diffusion models using only per-image binary feedback, which is readily available and much cheaper to obtain than pairwise preferences. This method offers a scalable solution, overcoming the computational limitations of existing techniques, and broadening the application of aligning AI models with human preferences.
Visual Insights#

🔼 This figure shows examples of images generated by text-to-image diffusion models before and after being aligned using the proposed Diffusion-KTO method. The alignment is achieved using only per-image binary feedback (likes/dislikes), avoiding the need for more complex pairwise comparisons or the training of a reward model. The improvement in image quality and alignment with human preferences is visually apparent.
read the caption
Figure 1: Diffusion-KTO is a novel framework for aligning text-to-image diffusion models with human preferences using only per-sample binary feedback. Diffusion-KTO bypasses the need to collect expensive pairwise preference data and avoids training a reward model. As seen above, Diffusion-KTO aligned text-to-image models generate images that better align with human preferences. We display results after fine-tuning Stable Diffusion v1-5 and sampling prompts from HPS v2 [50], Pick-a-Pic [27], and PartiPrompts [54] datasets.
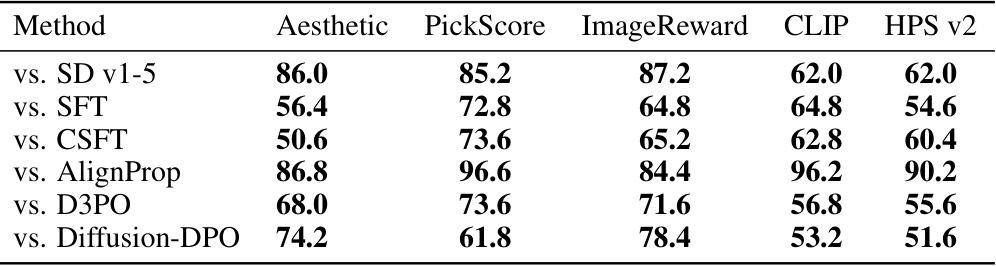
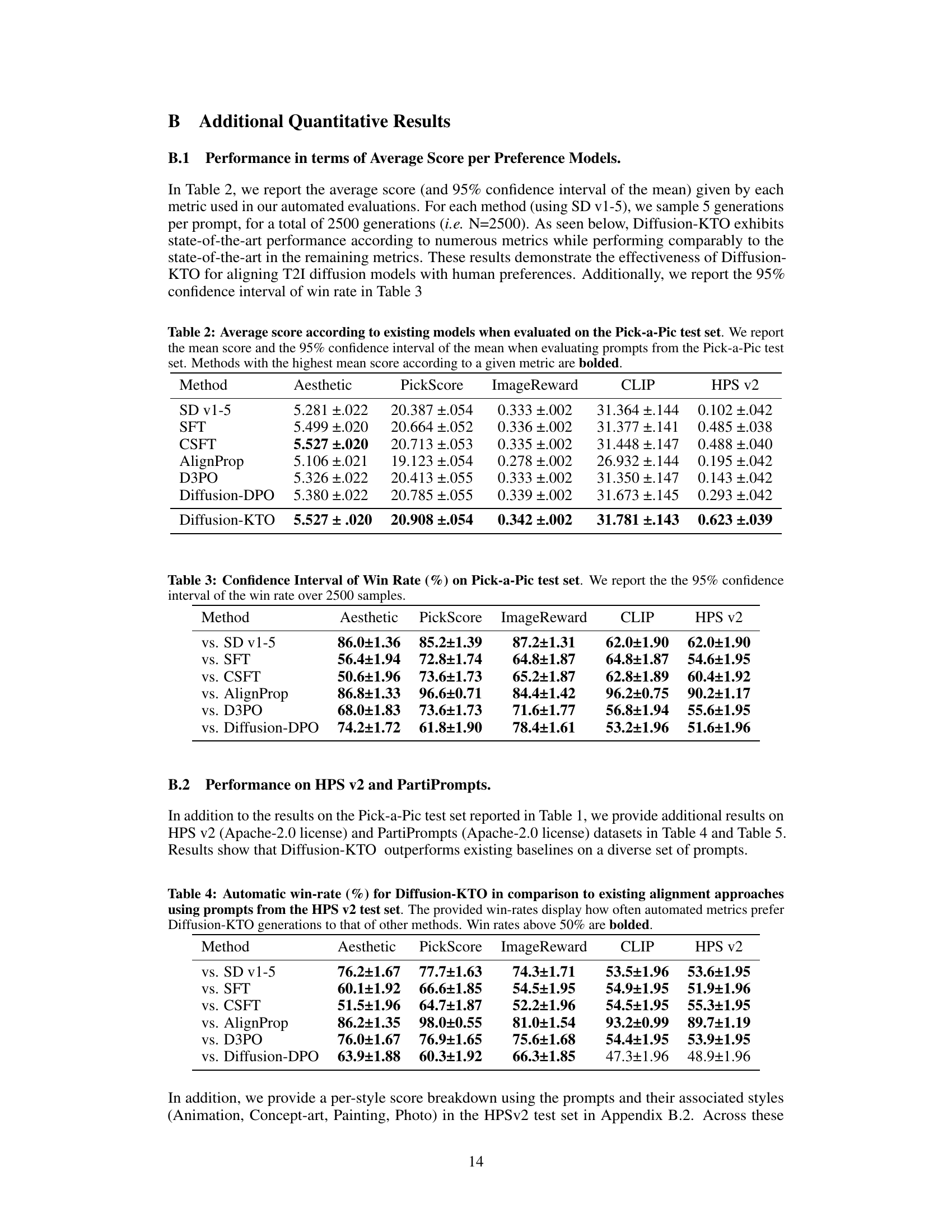
🔼 This table presents the results of an automated evaluation of the Diffusion-KTO model’s performance in aligning text-to-image diffusion models with human preferences. It compares the model to several existing alignment approaches using prompts from the Pick-a-Pic v2 test set, using various automated preference metrics (Aesthetic, PickScore, ImageReward, CLIP, HPS v2). The win rate shows how often Diffusion-KTO’s generation was preferred by each metric, with rates above 50% indicating better performance than the comparison method.
read the caption
Table 1: Automatic win-rate (%) for Diffusion-KTO (SD v1-5) in comparison to existing alignment approaches using prompts from the Pick-a-Pic v2 test set. We use off-the-shelf models, e.g. preference models such as PickScore, to compare generations and determine a winner based on the method with the higher scoring generation. Diffusion-KTO drastically improves the alignment of the base SD v1-5 and demonstrates significant improvements in alignment when compared to existing approaches. Win rates above 50% are bolded.
In-depth insights#
Utility Maximization#
The concept of utility maximization is central to aligning AI models with human preferences. Instead of directly optimizing for complex metrics or requiring extensive paired comparisons, this framework focuses on maximizing the expected human utility of model outputs. This shift simplifies the training process, making it more feasible to use readily available per-sample feedback such as likes or dislikes. The approach’s effectiveness lies in its ability to directly learn from readily available human feedback, thereby aligning model outputs with desired qualities without needing to collect or model complex preferences. This approach is particularly powerful because it uses readily available data, avoiding the need for expensive pairwise comparisons, and significantly reduces computational costs compared to traditional methods. The strength of the approach lies in its simplicity and scalability, paving the way for aligning more complex generative models with human preferences efficiently.
Diffusion-KTO Framework#
The hypothetical Diffusion-KTO framework presents a novel approach to aligning text-to-image diffusion models with human preferences. Its core innovation lies in leveraging readily available per-image binary feedback, bypassing the need for expensive pairwise comparisons or complex reward models. This efficiency is key, as it allows for scaling to larger datasets and real-world applications where acquiring detailed preference data is impractical. By framing the alignment as the maximization of expected human utility, Diffusion-KTO directly optimizes the diffusion process, potentially addressing limitations of previous reinforcement learning approaches. A key aspect to explore further would be the robustness of this framework to noisy or biased feedback, and a comprehensive analysis of its performance across different diffusion model architectures and datasets would be valuable. The choice of utility function is also crucial, with implications for the framework’s overall behavior, highlighting the need for careful consideration of human preference modeling. Generalizability and scalability are significant potential advantages of Diffusion-KTO, making it a promising direction for future research.
Human Utility Tuning#
Human utility tuning, in the context of aligning AI models with human preferences, presents a crucial challenge. Directly optimizing for human preferences avoids the limitations of reward models and indirect preference learning methods. However, defining and measuring human utility is complex; it’s subjective, context-dependent, and varies across individuals. Effective methods need to incorporate individual differences, potentially using personalized utility functions learned from individual feedback. Moreover, the data used for training is critical; using biased or poorly representative datasets will result in models that reflect those biases. Careful consideration is needed regarding the tradeoffs between model accuracy and potential negative societal impacts stemming from misaligned preferences. Finally, research needs to address the scalability and efficiency of human utility tuning methods, particularly for complex tasks and large datasets. The ideal approach would be flexible enough to accommodate a variety of feedback types, and robust enough to handle noisy or incomplete data.
Binary Feedback Use#
The utilization of binary feedback, representing simple ’like’ or ‘dislike’ assessments, presents a compelling alternative to more resource-intensive pairwise comparison methods for training and aligning generative models. This approach significantly reduces the annotation burden, making it scalable to large datasets and diverse user preferences. The effectiveness of binary feedback hinges on the design of the utility maximization objective function, which translates these simple signals into informative training signals for the model. While less granular than pairwise comparisons, binary feedback offers the advantage of readily available large-scale data from platforms such as social media and online reviews. This abundance of data could unlock the potential for continuously learning and adapting generative models to evolving user preferences. However, challenges remain in mitigating biases inherent in user-generated datasets and optimizing the utility function to effectively capture the nuances of human preference. Future research should focus on these limitations to fully leverage the potential of binary feedback for creating truly aligned and useful AI systems.
Future Directions#
Future research could explore several promising avenues. Extending Diffusion-KTO to other generative models beyond text-to-image diffusion models would significantly broaden its applicability. Investigating alternative utility functions and their impact on model alignment is crucial; exploring functions beyond the Kahneman-Tversky model might reveal superior performance. Addressing the inherent limitations of current T2I models—such as biases, negative stereotypes and hallucination—is paramount; Diffusion-KTO’s framework could be enhanced to directly mitigate these issues. A key area to explore would be incorporating diverse feedback modalities, possibly including ranking, comparative feedback, or continuous feedback signals, to enhance the richness and accuracy of user preferences. Finally, research into improving efficiency and scalability is vital for real-world applications; reducing computational costs and increasing the feasibility of training on massive datasets would unlock Diffusion-KTO’s full potential.
More visual insights#
More on figures

🔼 This figure compares the results of aligning text-to-image diffusion models using two different methods: Diffusion-DPO/RLHF and Diffusion-KTO. Diffusion-DPO/RLHF relies on expensive pairwise preference data, while Diffusion-KTO leverages readily available per-image binary feedback (likes/dislikes). The figure shows that Diffusion-KTO produces images that are better aligned with human preferences, even with the simpler feedback mechanism.
read the caption
Figure 2: Diffusion-KTO aligns text-to-image diffusion models using per-image binary feedback. Existing alignment approaches (Left) are restricted to learning from pairwise preferences. However, Diffusion-KTO (Right) uses per-image preferences which are abundantly available on the Internet. As seen above, the quality of an image can be assessed independent of another generation for the same prompt. More importantly, such per-image preferences provide valuable signals for aligning T2I models, as demonstrated by our results.
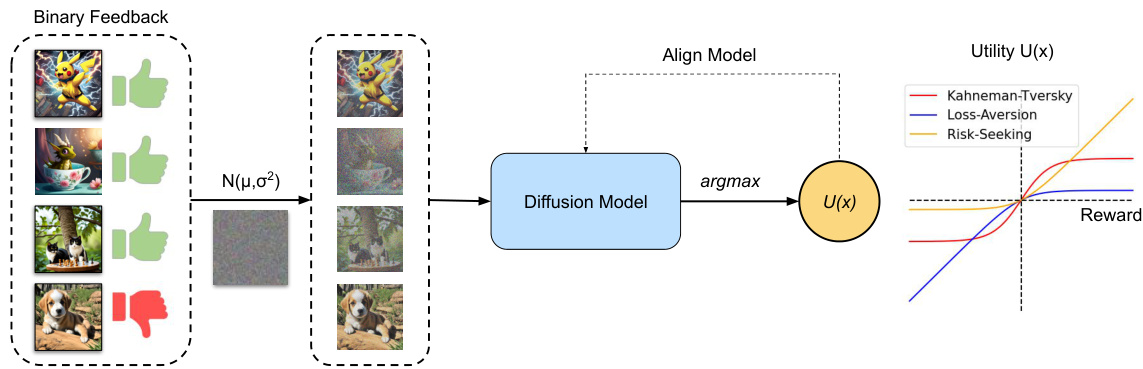
🔼 This figure illustrates the Diffusion-KTO framework. The left side shows how per-image binary feedback (likes/dislikes) is used to train the diffusion model. The middle section depicts the process of aligning the diffusion model using Diffusion-KTO by maximizing expected utility. The right side shows the types of utility functions (Kahneman-Tversky, Loss-Aversion, Risk-Seeking) considered within the framework. The framework bypasses the need for pairwise comparisons and avoids training a reward model, making it more efficient than alternative approaches.
read the caption
Figure 3: We present Diffusion-KTO, which aligns text-to-image diffusion models by extending the utility maximization framework to the setting of diffusion models. Since this framework aims to maximize the utility of each generation (U(x)) independently, it does not require paired preference data. Instead, Diffusion-KTO trains with per-image binary feedback signals, e.g. likes and dislikes. Our objective also extends to each step in the diffusion process, thereby avoiding the need to back-propagate a reward through the entire sampling process.

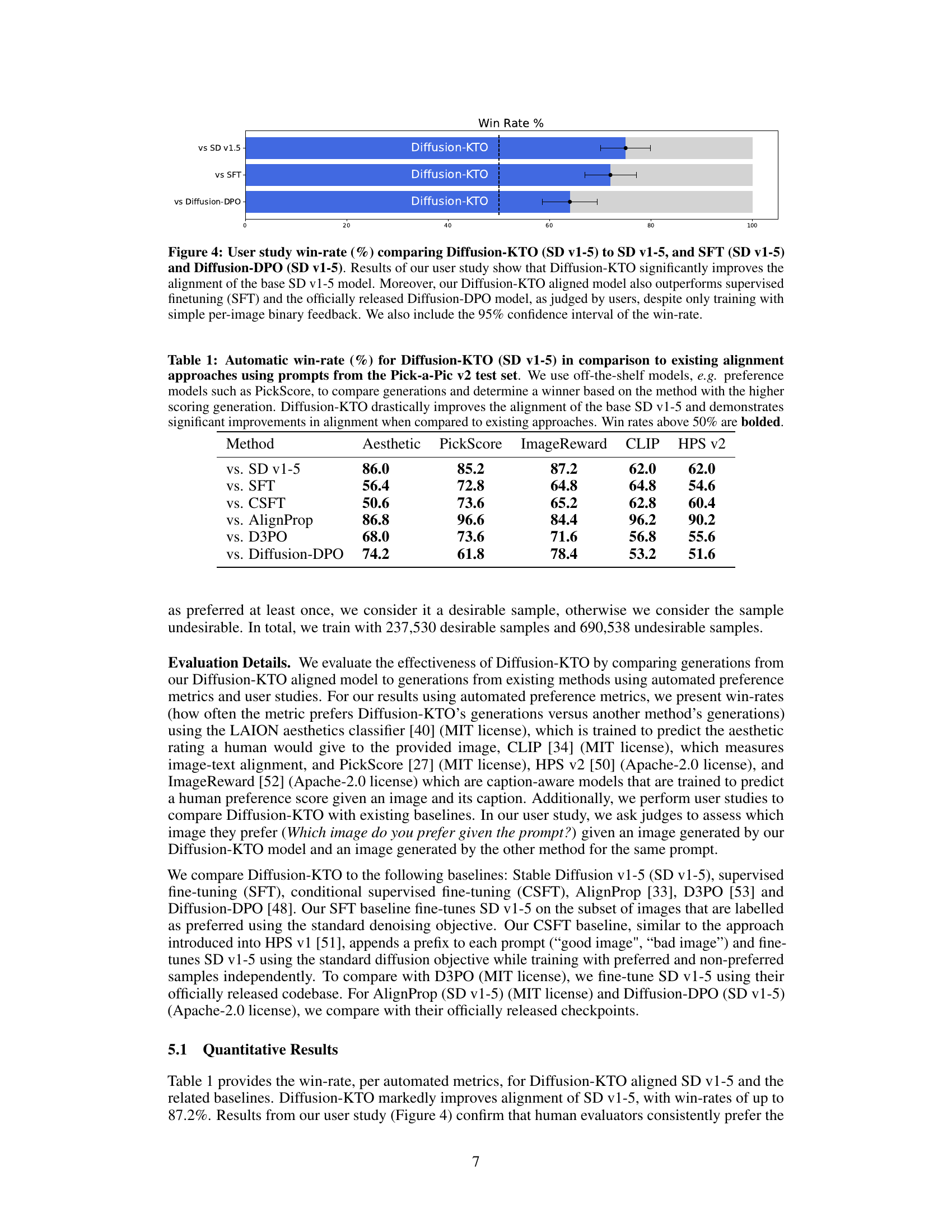
🔼 This figure presents the results of a user study comparing the performance of Diffusion-KTO against three baseline methods: Stable Diffusion v1.5, supervised fine-tuning (SFT), and Diffusion-DPO. The win rate shows how often Diffusion-KTO generated images were preferred by users over the images produced by the alternative methods. Error bars represent 95% confidence intervals. The results demonstrate that Diffusion-KTO significantly improved image generation alignment with human preferences, outperforming the other methods.
read the caption
Figure 4: User study win-rate (%) comparing Diffusion-KTO (SD v1-5) to SD v1-5, and SFT (SD v1-5) and Diffusion-DPO (SD v1-5). Results of our user study show that Diffusion-KTO significantly improves the alignment of the base SD v1-5 model. Moreover, our Diffusion-KTO aligned model also outperforms supervised finetuning (SFT) and the officially released Diffusion-DPO model, as judged by users, despite only training with simple per-image binary feedback. We also include the 95% confidence interval of the win-rate.
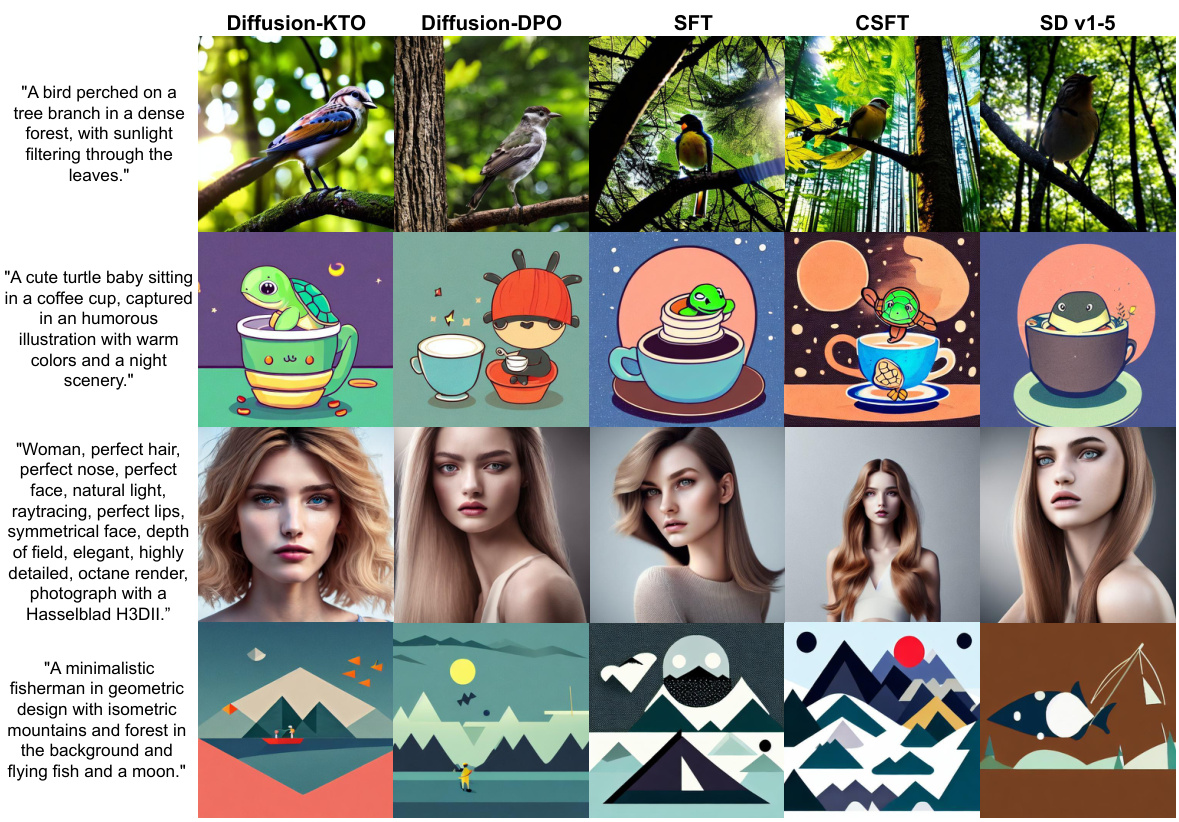
🔼 This figure presents a visual comparison of images generated by different methods (Diffusion-KTO, Diffusion-DPO, SFT, CSFT, and SD v1-5) for four different prompts. It showcases the improved image quality and fidelity to the prompt descriptions achieved by the Diffusion-KTO method. Each row shows the results for a specific prompt and demonstrates how Diffusion-KTO produces images that better align with the desired aesthetics and content of the prompt than the other models.
read the caption
Figure 5: Side-by-side comparison of images generated by related methods using SD v1-5. Diffusion-KTO demonstrates a significant improvement in terms of aesthetic appeal and fidelity to the caption (see Sec. 5.2).
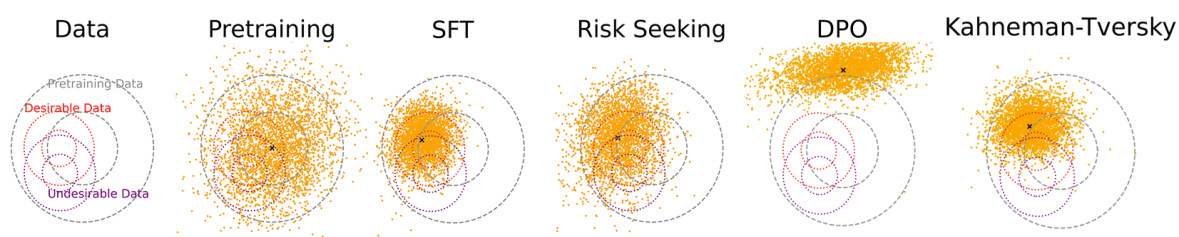
🔼 This figure visualizes how different utility functions (Loss-Averse, Risk-Seeking, DPO, and Kahneman-Tversky) affect the alignment of a diffusion model with desirable and undesirable data distributions. Samples from MLP diffusion models are shown, demonstrating that the Kahneman-Tversky function best balances aligning with the desirable distribution while minimizing overlap with the undesirable distribution.
read the caption
Figure 6: Visualizing the effect of various utility functions. We sample from MLP diffusion models trained using various alignment objectives. We find that using the Kahneman-Tversky utility function leads to the best performance in terms of aligning with the desirable distribution and avoiding the undesirable distribution.
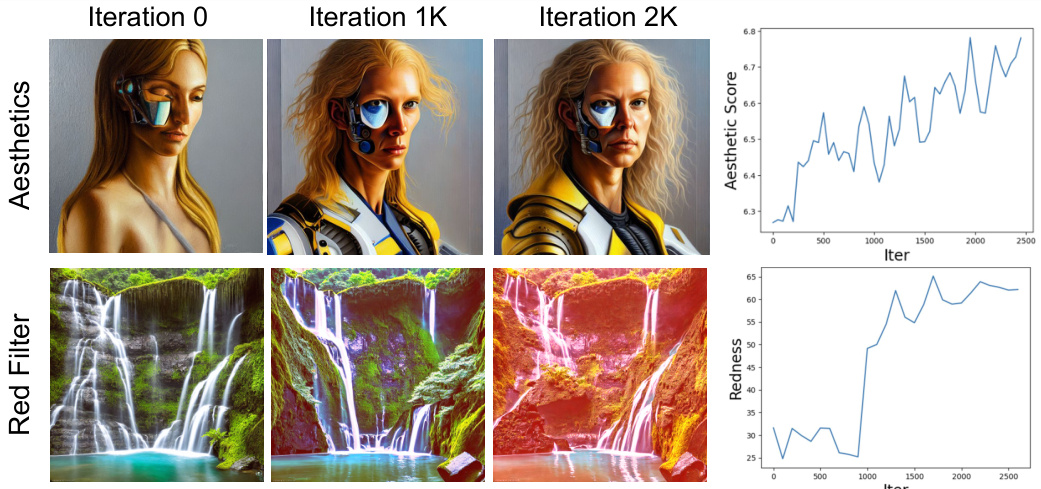
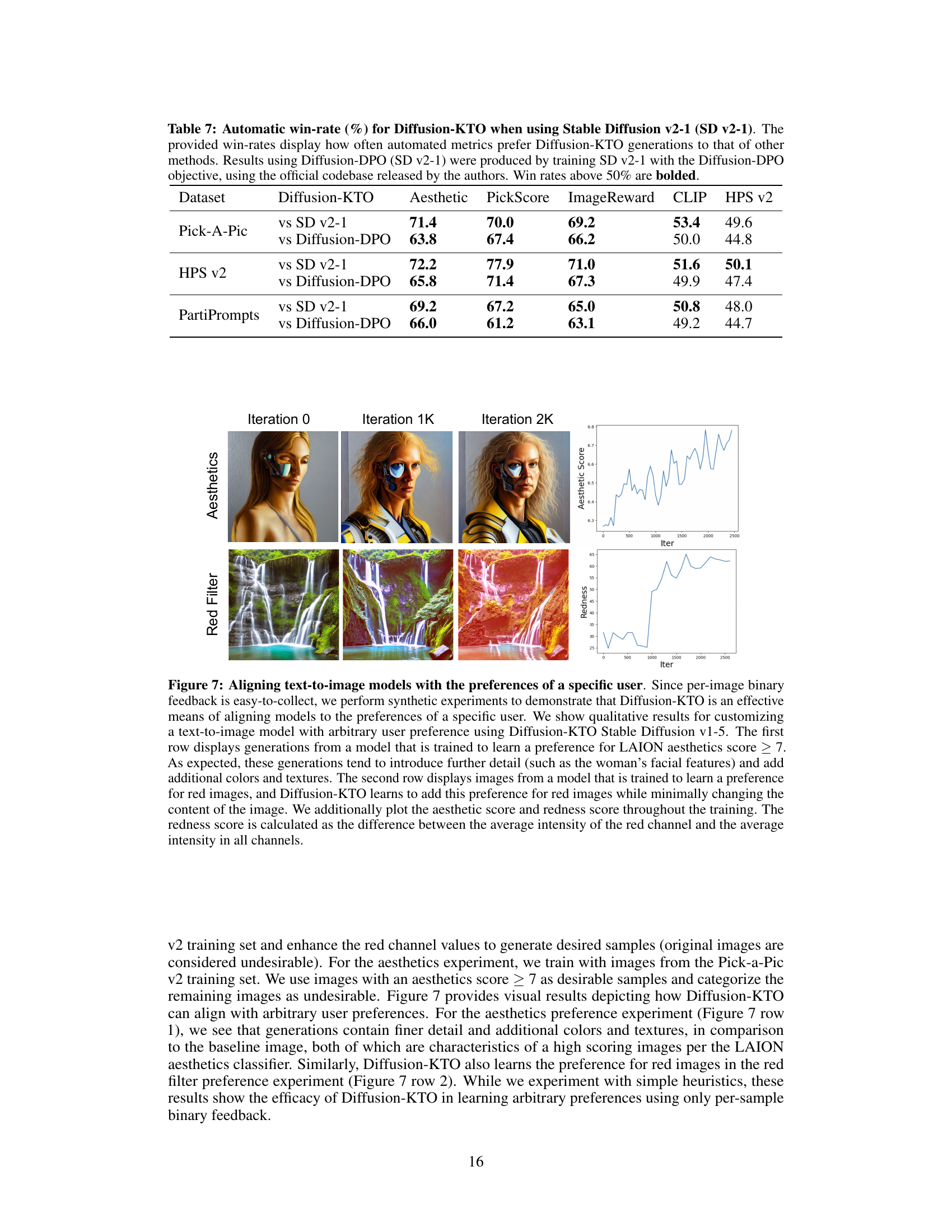
🔼 This figure shows the results of two synthetic experiments to demonstrate how Diffusion-KTO can align the model to specific user preferences using only per-image binary feedback. The first experiment aims to train the model to prefer images with high aesthetic scores (LAION score >7), resulting in more detailed and colorful outputs. The second trains the model to prefer red images. The plots show how the average aesthetic score and the redness (the difference between average red channel intensity and average intensity across all channels) change over training iterations.
read the caption
Figure 7: Aligning text-to-image models with the preferences of a specific user. Since per-image binary feedback is easy-to-collect, we perform synthetic experiments to demonstrate that Diffusion-KTO is an effective means of aligning models to the preferences of a specific user. We show qualitative results for customizing a text-to-image model with arbitrary user preference using Diffusion-KTO Stable Diffusion v1-5. The first row displays generations from a model that is trained to learn a preference for LAION aesthetics score > 7. As expected, these generations tend to introduce further detail (such as the woman's facial features) and add additional colors and textures. The second row displays images from a model that is trained to learn a preference for red images, and Diffusion-KTO learns to add this preference for red images while minimally changing the content of the image. We additionally plot the aesthetic score and redness score throughout the training. The redness score is calculated as the difference between the average intensity of the red channel and the average intensity in all channels.
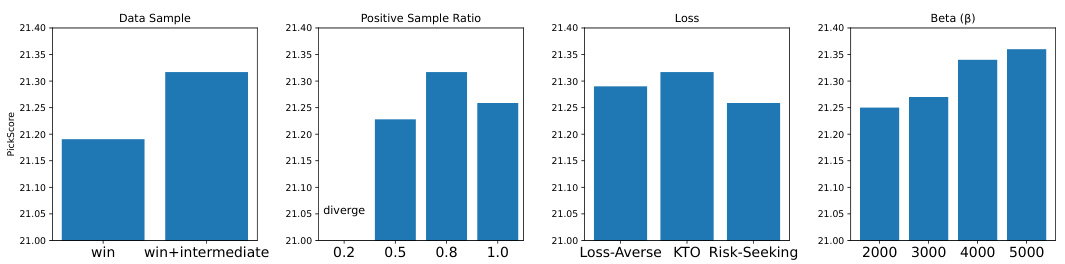
🔼 This figure presents the results of ablation studies performed to analyze the effect of various design choices within the Diffusion-KTO framework on model performance, specifically focusing on the PickScore metric. Four different ablation experiments are shown: varying data sampling strategies (using winning samples only versus including intermediate samples), altering the proportion of positive samples in the training data, testing different utility functions (Loss-Averse, KTO, and Risk-Seeking), and adjusting the beta (β) hyperparameter in the optimization process. The results illustrate the optimal configuration for achieving the highest PickScore, highlighting the importance of data sampling strategy, utility function selection, and hyperparameter tuning in optimizing the performance of the Diffusion-KTO method.
read the caption
Figure 8: Ablation Studies. We experiment with different data sampling strategy and different utility functions. Results show the best combination is to a) use the winning (i.e., images that are always preferred) and intermediate (i.e., images that are sometimes preferred and sometimes non-preferred) samples, b) use a positive ratio of 0.8, c) use the KTO objective function, d) use a beta β value of 5000.
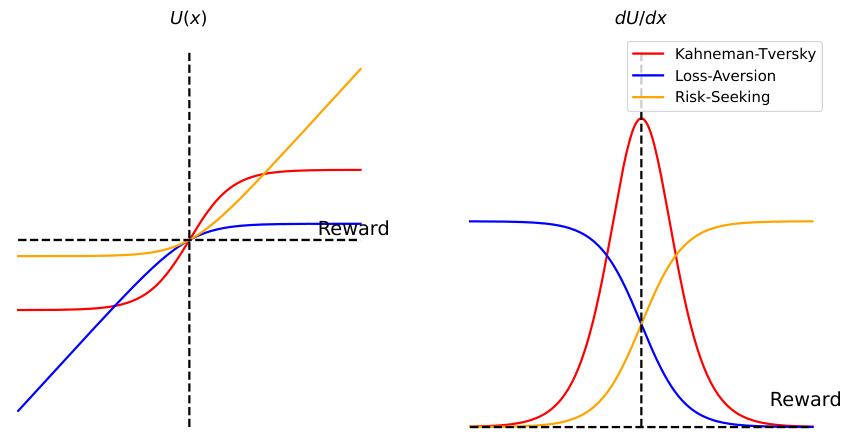
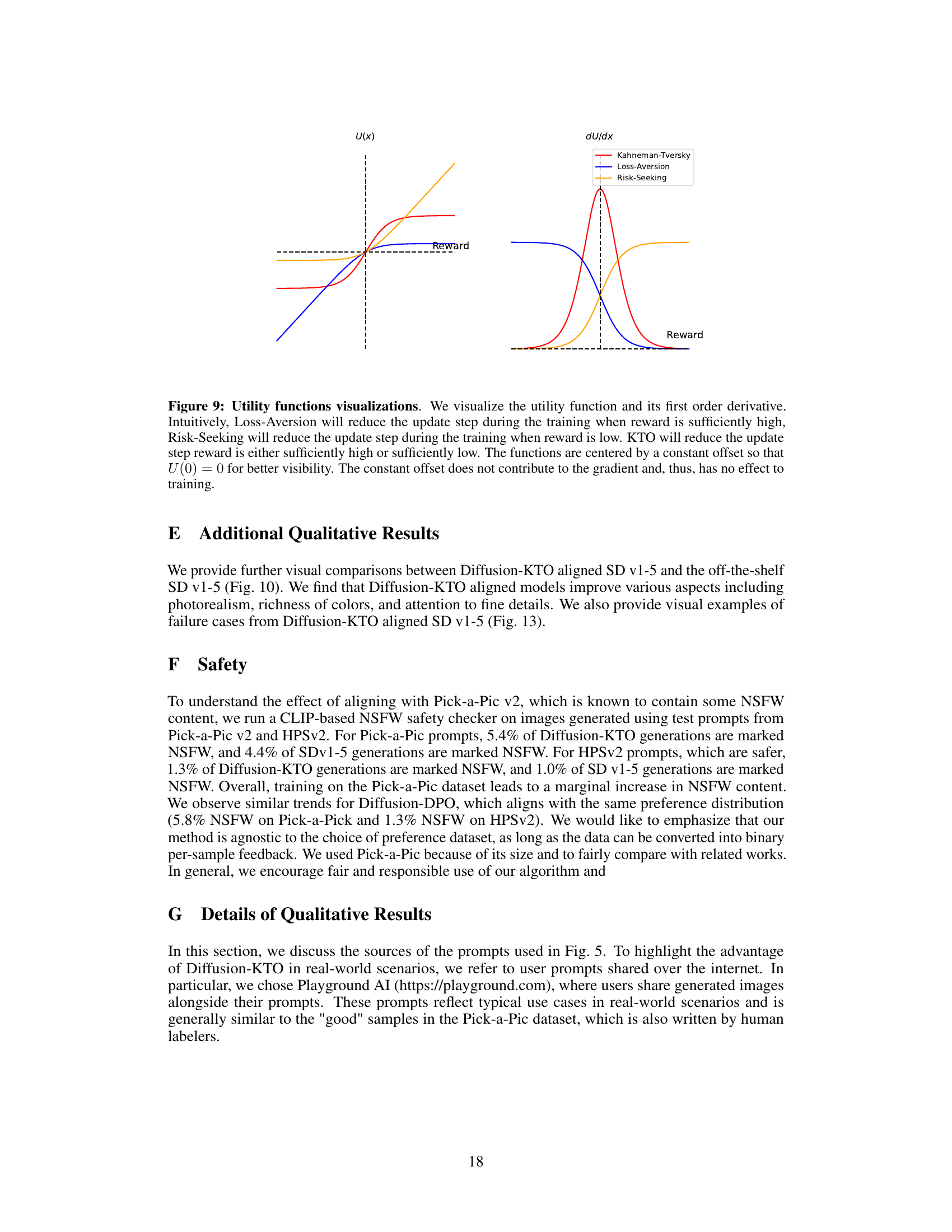
🔼 This figure visualizes three different utility functions: Kahneman-Tversky, Loss-Aversion, and Risk-Seeking. It shows both the utility function itself (U(x)) and its derivative (dU/dx). The plot illustrates how each function’s sensitivity to reward changes, impacting the training process. Loss-Aversion reduces updates when rewards are high, Risk-Seeking reduces updates when rewards are low, and Kahneman-Tversky, which is used in Diffusion-KTO, balances this behavior for better robustness to noisy reward signals.
read the caption
Figure 9: Utility functions visualizations. We visualize the utility function and its first order derivative. Intuitively, Loss-Aversion will reduce the update step during the training when reward is sufficiently high, Risk-Seeking will reduce the update step during the training when reward is low. KTO will reduce the update step if the reward is either sufficiently high or sufficiently low. The functions are centered by a constant offset so that U(0) = 0 for better visibility. The constant offset does not contribute to the gradient and, thus, has no effect to training.

🔼 This figure shows examples of images generated by text-to-image diffusion models before and after being aligned using the Diffusion-KTO framework. The alignment is achieved using only per-sample binary feedback (likes/dislikes), demonstrating the effectiveness of Diffusion-KTO in improving image quality and alignment with user preferences. The prompts used are sourced from various datasets including HPS v2, Pick-a-Pic, and PartiPrompts, and the base model used is Stable Diffusion v1.5.
read the caption
Figure 1: Diffusion-KTO is a novel framework for aligning text-to-image diffusion models with human preferences using only per-sample binary feedback. Diffusion-KTO bypasses the need to collect expensive pairwise preference data and avoids training a reward model. As seen above, Diffusion-KTO aligned text-to-image models generate images that better align with human preferences. We display results after fine-tuning Stable Diffusion v1-5 and sampling prompts from HPS v2 [50], Pick-a-Pic [27], and PartiPrompts [54] datasets.

🔼 This figure shows a comparison of images generated by different methods (Diffusion-KTO, Diffusion-DPO, SFT, CSFT, and SD v1-5) using the same prompts. It visually demonstrates the improved quality and alignment with the prompt descriptions achieved by the Diffusion-KTO method compared to others. The improved aesthetic quality and fidelity to the captions is discussed in Section 5.2 of the paper.
read the caption
Figure 5: Side-by-side comparison of images generated by related methods using SD v1-5. Diffusion-KTO demonstrates a significant improvement in terms of aesthetic appeal and fidelity to the caption (see Sec. 5.2).

🔼 This figure shows a comparison of images generated by Diffusion-KTO and Stable Diffusion v1-5 for three different prompts. The prompts are designed to test the models’ ability to generate images with different levels of detail, realism, and artistic style. The results show that Diffusion-KTO is able to generate images that are more faithful to the prompts than Stable Diffusion v1-5.
read the caption
Figure 12: Additional side-by-side comparison of Diffusion-KTO (SD v1-5) versus Stable Diffusion v1-5. The images were created using the prompts: 'A dramatic scene of two ships caught in a stormy sea, with lightning striking the waves and sailors struggling to steer, 8k resolution.', 'A cinematic black and white portrait of a man with a weathered face and stubble, soft natural light through a window, shallow depth of field, shot on a Canon 5D Mark III.', 'A hyperrealistic close-up of a cherry blossom branch in full bloom, with each petal delicately illuminated by the morning sun, 8k resolution.'

🔼 This figure showcases the results of aligning text-to-image diffusion models using the proposed Diffusion-KTO framework. Diffusion-KTO leverages per-sample binary feedback (likes/dislikes) instead of more costly pairwise comparisons, and it avoids training a separate reward model. The images demonstrate that models fine-tuned with Diffusion-KTO generate outputs better aligned with human preferences compared to the original model.
read the caption
Figure 1: Diffusion-KTO is a novel framework for aligning text-to-image diffusion models with human preferences using only per-sample binary feedback. Diffusion-KTO bypasses the need to collect expensive pairwise preference data and avoids training a reward model. As seen above, Diffusion-KTO aligned text-to-image models generate images that better align with human preferences. We display results after fine-tuning Stable Diffusion v1-5 and sampling prompts from HPS v2 [50], Pick-a-Pic [27], and PartiPrompts [54] datasets.
More on tables
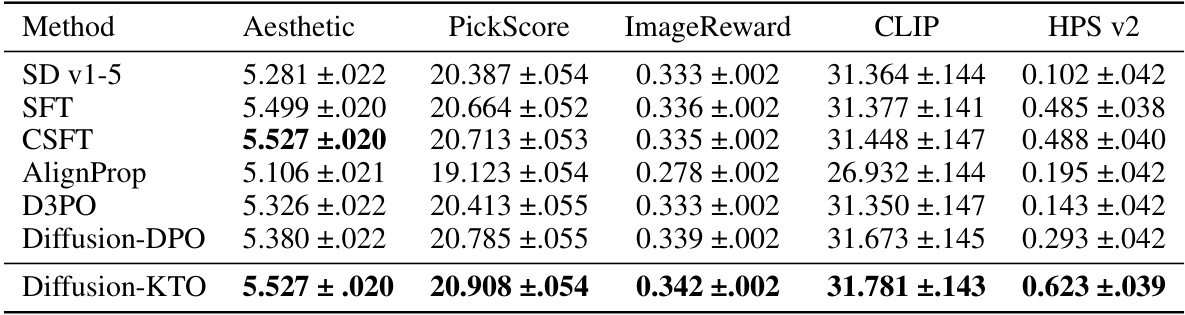
🔼 This table presents the average scores and 95% confidence intervals obtained by different methods (including Diffusion-KTO) across various automated evaluation metrics (Aesthetic, PickScore, ImageReward, CLIP, HPS v2) on the Pick-a-Pic test set. The bolded values indicate the top-performing method for each metric. The table serves to showcase the performance of Diffusion-KTO against established baselines in terms of quantitative image quality assessment.
read the caption
Table 2: Average score according to existing models when evaluated on the Pick-a-Pic test set. We report the mean score and the 95% confidence interval of the mean when evaluating prompts from the Pick-a-Pic test set. Methods with the highest mean score according to a given metric are bolded.
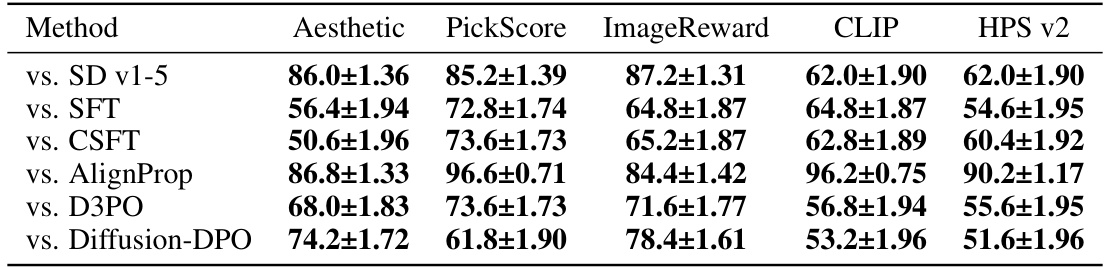
🔼 This table presents the results of automated evaluation metrics comparing Diffusion-KTO against other alignment methods on the Pick-a-Pic v2 test set. The metrics used (Aesthetic, PickScore, ImageReward, CLIP, HPS v2) assess different aspects of image quality and alignment with the prompt. Win rates show the percentage of times Diffusion-KTO’s generations were preferred according to each metric. The results highlight Diffusion-KTO’s significant improvement over other methods.
read the caption
Table 1: Automatic win-rate (%) for Diffusion-KTO (SD v1-5) in comparison to existing alignment approaches using prompts from the Pick-a-Pic v2 test set. We use off-the-shelf models, e.g. preference models such as PickScore, to compare generations and determine a winner based on the method with the higher scoring generation. Diffusion-KTO drastically improves the alignment of the base SD v1-5 and demonstrates significant improvements in alignment when compared to existing approaches. Win rates above 50% are bolded.

🔼 This table presents the results of comparing Diffusion-KTO against several other methods for aligning text-to-image diffusion models. The comparison uses prompts from the Pick-a-Pic v2 test set and several automatic metrics (PickScore, ImageReward, CLIP, HPS v2) to determine which method produced better image generations. Win rates above 50% indicate Diffusion-KTO outperformed the other methods according to that metric.
read the caption
Table 1: Automatic win-rate (%) for Diffusion-KTO (SD v1-5) in comparison to existing alignment approaches using prompts from the Pick-a-Pic v2 test set. We use off-the-shelf models, e.g. preference models such as PickScore, to compare generations and determine a winner based on the method with the higher scoring generation. Diffusion-KTO drastically improves the alignment of the base SD v1-5 and demonstrates significant improvements in alignment when compared to existing approaches. Win rates above 50% are bolded.
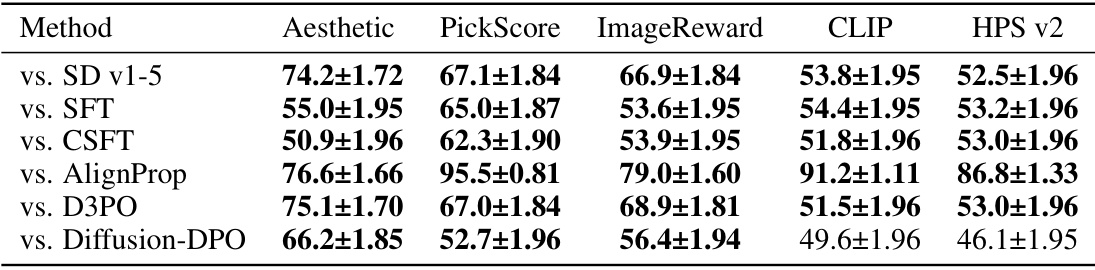
🔼 This table presents the win rates of Diffusion-KTO against several other methods for text-to-image generation on the Pick-a-Pic v2 test set. Win rate is determined using several automated preference metrics (Aesthetic, PickScore, ImageReward, CLIP, HPS v2) to compare image generations, with the model scoring higher considered the winner. The table highlights Diffusion-KTO’s improved image alignment compared to base SD v1-5, supervised fine-tuning (SFT), and other state-of-the-art approaches.
read the caption
Table 1: Automatic win-rate (%) for Diffusion-KTO (SD v1-5) in comparison to existing alignment approaches using prompts from the Pick-a-Pic v2 test set. We use off-the-shelf models, e.g. preference models such as PickScore, to compare generations and determine a winner based on the method with the higher scoring generation. Diffusion-KTO drastically improves the alignment of the base SD v1-5 and demonstrates significant improvements in alignment when compared to existing approaches. Win rates above 50% are bolded.

🔼 This table presents a breakdown of the average scores achieved by different automated evaluation metrics (Aesthetic, PickScore, ImageReward, CLIP, and HPS v2) for images generated by different models. The scores are categorized by image style (anime, concept-art, paintings, and photo) from the HPSv2 test set, revealing how model performance varies across different image styles and evaluation criteria.
read the caption
Table 6: Per-style score breakdown for different metrics in the HPSv2 test set.

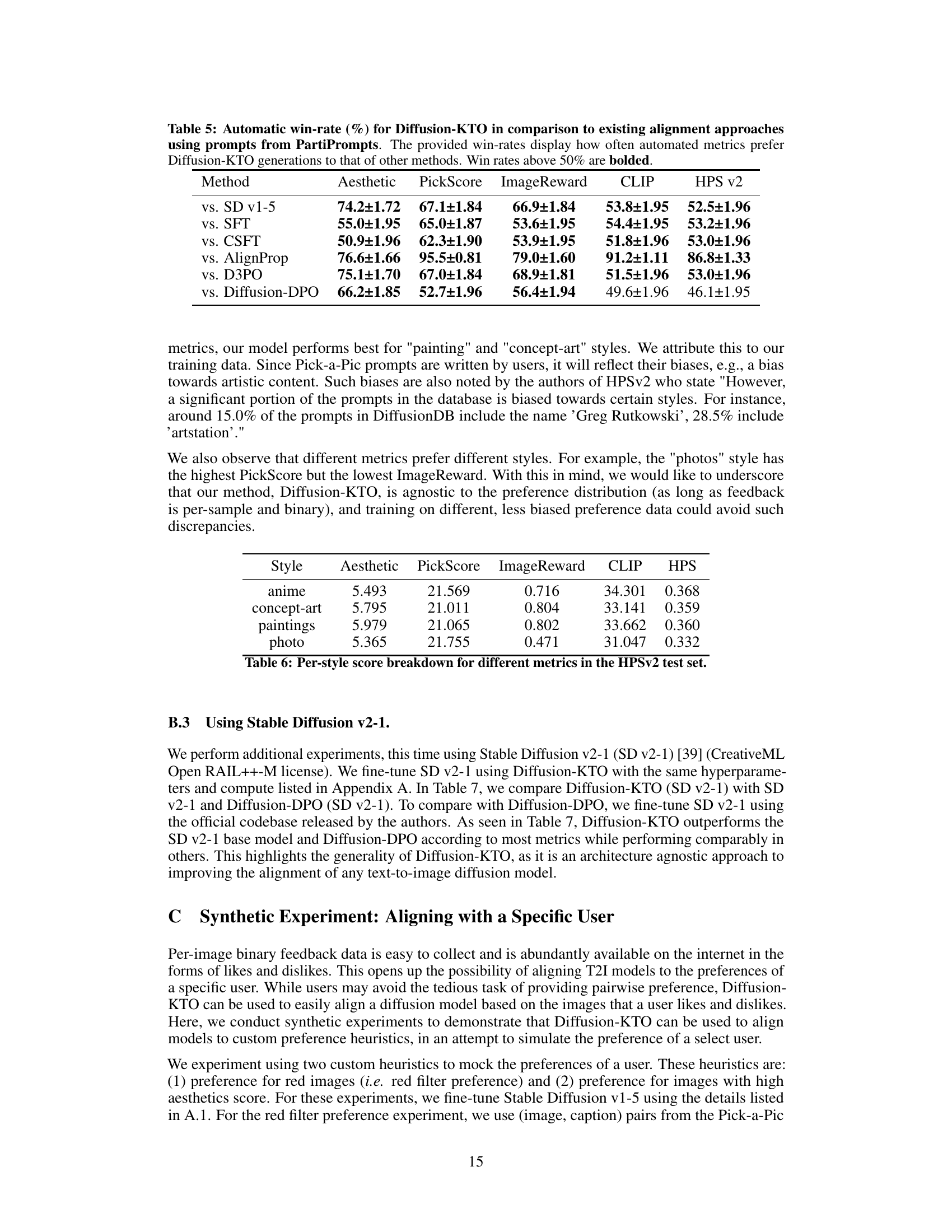
🔼 This table presents the win rates of Diffusion-KTO against Stable Diffusion v2-1 and Diffusion-DPO on three different datasets: Pick-A-Pic, HPS v2, and PartiPrompts. Win rate is calculated using various automated metrics: Aesthetic, PickScore, ImageReward, CLIP, and HPS v2. The table shows that Diffusion-KTO outperforms or performs comparably to the baselines across most metrics and datasets. Win rates over 50% are highlighted in bold, indicating that Diffusion-KTO is preferred by the automated metrics in those cases.
read the caption
Table 7: Automatic win-rate (%) for Diffusion-KTO when using Stable Diffusion v2-1 (SD v2-1). The provided win-rates display how often automated metrics prefer Diffusion-KTO generations to that of other methods. Results using Diffusion-DPO (SD v2-1) were produced by training SD v2-1 with the Diffusion-DPO objective, using the official codebase released by the authors. Win rates above 50% are bolded.
Full paper#