TL;DR#
3D reconstruction, a vital task in computer vision, traditionally relies on real-world datasets which are expensive, time-consuming and have license issues. This significantly limits the progress in 3D vision research. Existing 3D datasets, while useful, often lack diversity and completeness, hindering the development of truly robust and generalizable 3D reconstruction models. The lack of high-quality, easily accessible 3D data creates a significant bottleneck for researchers in the field.
This paper introduces LRM-Zero, a novel approach that addresses these limitations. LRM-Zero uses a procedurally generated synthetic dataset called Zeroverse to train a large reconstruction model. Zeroverse, unlike existing datasets, ignores realistic global semantics but is rich in locally complex geometric and textural details. The results demonstrate that LRM-Zero achieves high-quality reconstruction of real-world objects, competitive with models trained on real-world data like Objaverse. This work highlights the potential of fully synthetic data for 3D reconstruction, paving the way for more accessible and scalable research in 3D vision.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates the feasibility of training high-quality 3D reconstruction models using only synthetic data This challenges the field’s reliance on scarce and expensive real-world datasets, opening doors for broader accessibility and innovation in 3D vision research. The procedural data generation method is also a significant contribution, offering a new approach to creating diverse and complex 3D training data.
Visual Insights#

🔼 This figure shows a comparison of the LRM-Zero framework trained on synthetic data (Zeroverse) and a traditional LRM trained on real-world data (Objaverse). It demonstrates that despite lacking realistic global semantics, the procedurally generated Zeroverse dataset allows LRM-Zero to achieve similar reconstruction quality to the LRM trained on Objaverse, suggesting that local geometric and textural information are crucial for successful 3D reconstruction.
read the caption
Figure 1: We present our LRM-Zero framework trained with synthesized procedural data Zeroverse. Zeroverse (top left) is created from random primitives with textures and augmentations, thus it does not contain semantical information as in Objaverse (bottom left). Nevertheless, when training with the same large reconstruction model architecture [107] on both datasets, LRM-Zero can match objaverse-trained LRM's (denoted as ‘LRM') visual quality (right part) of reconstructions. A possible explanation is that 3D reconstruction, although serves as a core task in 3D vision, rely mostly on local information instead of global semantics. Reconstruction is visualized with RGB and position-based renderings, and interactive viewers can be found on our website.
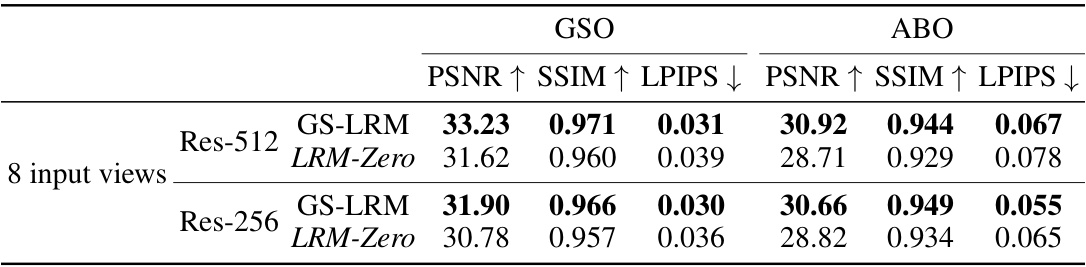
🔼 This table presents a quantitative comparison of the performance of two 3D reconstruction models: LRM-Zero (trained on synthetic data) and GS-LRM (trained on Objaverse). The comparison is based on metrics (PSNR, SSIM, LPIPS) calculated using two benchmark datasets (GSO and ABO) with 8 input views. The results show that LRM-Zero achieves competitive results to GS-LRM, demonstrating the efficacy of training with fully synthesized data.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.
In-depth insights#
Synth Data 3D Recon#
Synthetic data is revolutionizing 3D reconstruction, offering a compelling alternative to the limitations of real-world datasets. Challenges associated with real data, such as acquisition cost, licensing restrictions, and inherent biases, are largely mitigated with synthetic datasets. A procedural approach to generating synthetic 3D data, as discussed in many papers, allows for the creation of highly diverse and complex scenes containing intricate geometric details and realistic textures. This approach ensures that the resulting datasets are abundant and significantly reduces the need for manual labor. However, carefully considering the characteristics of the synthetic data is critical; simply mimicking the visual appearance of real objects is insufficient. A focus on the local geometry and textural features, rather than replicating global semantic properties of real-world objects, emerges as a successful strategy. The effectiveness of this method underscores the power of synthetic data and its transformative potential in advancing the field of 3D vision.
Zeroverse Dataset#
The Zeroverse dataset, a core component of the LRM-Zero framework, represents a significant departure from traditional 3D datasets. Instead of relying on real-world scans or human-crafted models, Zeroverse is procedurally generated, using simple primitives like cubes and spheres, which are then randomly combined, textured, and augmented. This procedural approach offers several key advantages: it addresses the scarcity and cost of high-quality 3D data, avoids issues of licensing and bias associated with real-world datasets, and enables the generation of a virtually unlimited quantity of diverse 3D shapes with intricate geometric detail. While lacking real-world semantics, Zeroverse’s richness in local geometric and textural variations proves surprisingly effective for training a high-performing 3D reconstruction model, challenging the conventional assumption that real-world data is essential for robust 3D vision tasks. The success of LRM-Zero highlights the potential of fully synthetic datasets in driving future advancements in 3D computer vision.
LRM-Zero Model#
The LRM-Zero model represents a significant advancement in 3D reconstruction, demonstrating the feasibility of training high-quality models using only synthetic data. By leveraging a procedurally generated dataset, Zeroverse, LRM-Zero sidesteps the limitations of real-world datasets like Objaverse, such as data scarcity, licensing issues, and biases. The model’s success highlights the importance of local geometric details over global semantic information in 3D reconstruction tasks and shows potential to address 3D vision challenges without reliance on real-world data’s inherent complexities and limitations. The work’s implications extend beyond mere reconstruction to potentially improve other 3D vision tasks. However, the model’s performance is impacted by the coverage of input views, indicating a need for future work focusing on improving view synthesis capabilities to address this shortcoming. Furthermore, the generalizability of the model trained exclusively on synthetic data to real-world scenarios could benefit from further evaluation. The release of the procedural synthesis code and interactive visualization promotes reproducibility and fosters further research within the community.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a complex system. In the context of a research paper, they often involve removing or altering specific parts of a model or process (e.g., a model layer, a data augmentation technique, or a hyperparameter) to determine their impact on overall performance. The goal is to isolate the effects of each component and understand their relative importance. Well-designed ablation studies are crucial for establishing causality and for separating the effects of different design choices. They provide strong evidence for the claims made by the authors. A complete ablation study comprehensively explores variations of every key component, whereas a partial ablation study might focus on specific components, or those considered most critical for improved understanding. Results from an ablation study guide the development of future iterations of the system, directing researchers towards improvements that will have the most impact on performance. Furthermore, they help the reader better assess the robustness of the approach by highlighting potential limitations and vulnerabilities.
Future of 3D Vision#
The future of 3D vision is bright, driven by advances in deep learning, data synthesis, and computational power. Deep learning models are rapidly improving 3D reconstruction from various modalities like images and point clouds, leading to more accurate and detailed 3D models of the world. The creation of synthetic datasets is mitigating data scarcity issues, fueling the development of more robust and generalizable algorithms. Increased computational capabilities are enabling the training of larger and more complex models, leading to higher-quality 3D reconstructions and enabling new applications like real-time 3D scene understanding. However, challenges remain such as creating truly photorealistic synthetic data that accurately reflects real-world complexities and ensuring the ethical use of generated 3D data. Overcoming these will pave the way for applications in diverse fields including robotics, AR/VR, autonomous driving, and medical imaging.
More visual insights#
More on figures

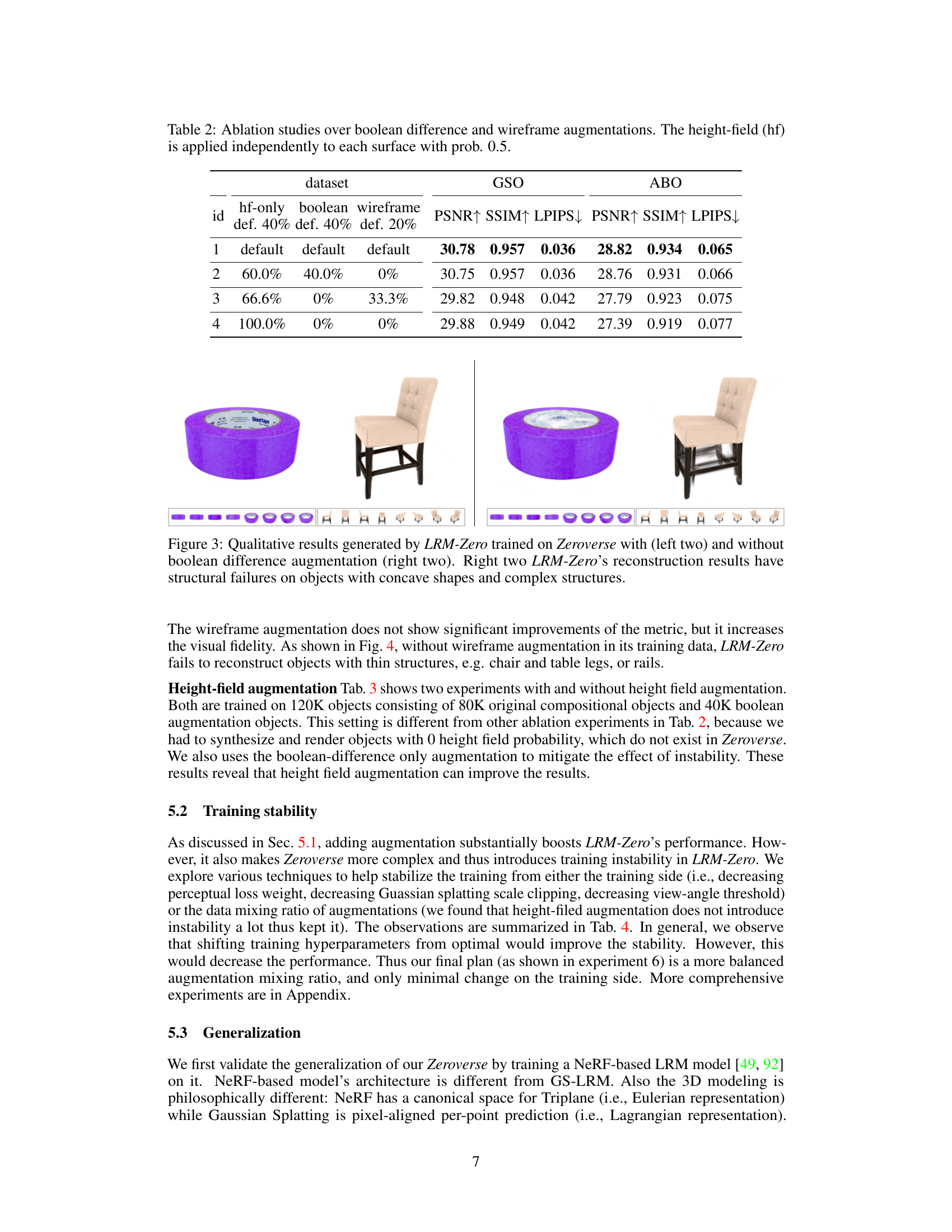
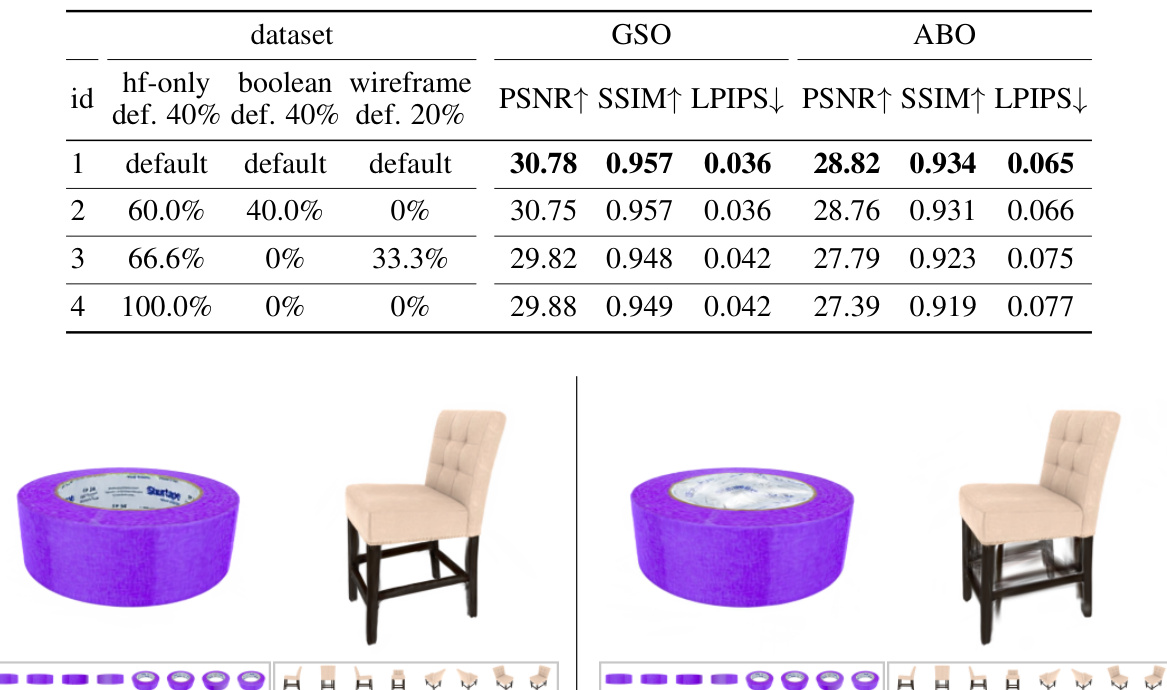
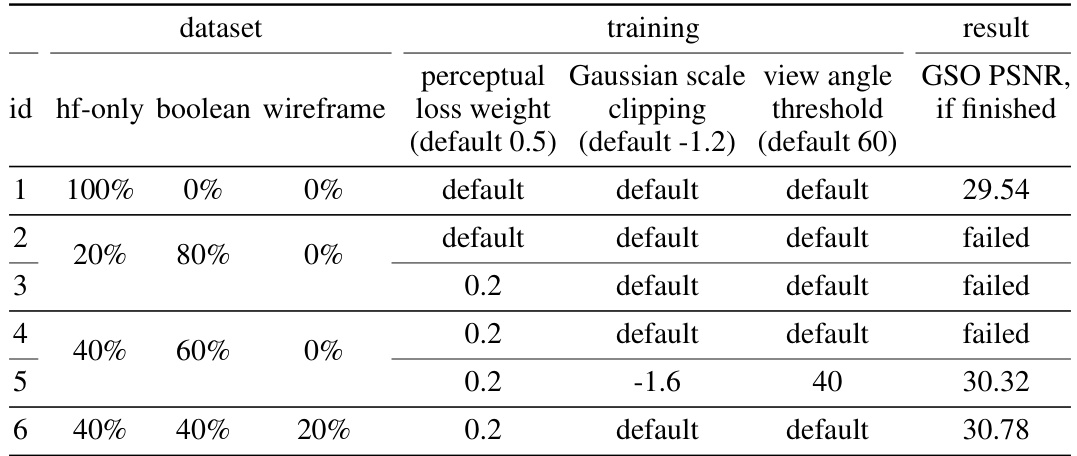
🔼 This figure illustrates the process of creating synthetic 3D shapes for the Zeroverse dataset. It starts with a pool of primitive shapes (cube, sphere, cylinder, cone, and torus) and random textures. These primitives are combined randomly to create a composite shape. Three types of augmentations are then applied to add complexity and diversity to the shapes: height-field augmentation, boolean difference augmentation, and wireframe augmentation. The resulting shapes are more intricate and better resemble real-world objects.
read the caption
Figure 2: Illustration of the Zeroverse data creation process. A random textured shape is first composited from primitive shapes and textures (Sec. 3.1). Then different augmentations (i.e., height field, boolean difference, wireframes in Sec. 3.2) are applied to enhance the dataset characteristics (e.g., curved surfaces, concavity, and thin structures). More visualizations in Appendix and website.
🔼 This figure shows a comparison of the LRM-Zero framework trained on synthetic data (Zeroverse) and a comparable model trained on real-world data (Objaverse). It highlights that despite using entirely synthetic data lacking global semantic information, LRM-Zero achieves similar reconstruction quality to the Objaverse-trained model, suggesting that local geometric and textural details are more crucial for successful 3D reconstruction than previously thought. The figure includes visualizations of the input data, the model architecture, and the reconstruction results.
read the caption
Figure 1: We present our LRM-Zero framework trained with synthesized procedural data Zeroverse. Zeroverse (top left) is created from random primitives with textures and augmentations, thus it does not contain semantical information as in Objaverse (bottom left). Nevertheless, when training with the same large reconstruction model architecture [107] on both datasets, LRM-Zero can match objaverse-trained LRM's (denoted as ‘LRM') visual quality (right part) of reconstructions. A possible explanation is that 3D reconstruction, although serves as a core task in 3D vision, rely mostly on local information instead of global semantics. Reconstruction is visualized with RGB and position-based renderings, and interactive viewers can be found on our website.

🔼 This figure shows a comparison between the LRM-Zero framework trained on synthetic data (Zeroverse) and a traditional LRM trained on real-world data (Objaverse). The left side displays examples from each dataset, highlighting Zeroverse’s procedural generation of non-semantic shapes compared to Objaverse’s realistic objects. The right side shows the reconstruction results from both models, demonstrating that LRM-Zero achieves comparable visual quality despite being trained solely on synthetic data. This suggests that local geometric and textural information might be more crucial for 3D reconstruction than global semantic understanding.
read the caption
Figure 1: We present our LRM-Zero framework trained with synthesized procedural data Zeroverse. Zeroverse (top left) is created from random primitives with textures and augmentations, thus it does not contain semantical information as in Objaverse (bottom left). Nevertheless, when training with the same large reconstruction model architecture [107] on both datasets, LRM-Zero can match objaverse-trained LRM's (denoted as ‘LRM') visual quality (right part) of reconstructions. A possible explanation is that 3D reconstruction, although serves as a core task in 3D vision, rely mostly on local information instead of global semantics. Reconstruction is visualized with RGB and position-based renderings, and interactive viewers can be found on our website.

🔼 This figure illustrates the LRM-Zero framework and compares its performance against a model trained on real data. LRM-Zero uses synthetic data generated procedurally (Zeroverse) that lacks semantic information unlike the Objaverse dataset used for comparison. The comparison shows that despite the lack of real-world semantics in its training data, LRM-Zero achieves comparable reconstruction quality to models trained on real data. This suggests that local geometric and textural features may be more crucial to reconstruction than global scene understanding.
read the caption
Figure 1: We present our LRM-Zero framework trained with synthesized procedural data Zeroverse. Zeroverse (top left) is created from random primitives with textures and augmentations, thus it does not contain semantical information as in Objaverse (bottom left). Nevertheless, when training with the same large reconstruction model architecture [107] on both datasets, LRM-Zero can match objaverse-trained LRM's (denoted as ‘LRM') visual quality (right part) of reconstructions. A possible explanation is that 3D reconstruction, although serves as a core task in 3D vision, rely mostly on local information instead of global semantics. Reconstruction is visualized with RGB and position-based renderings, and interactive viewers can be found on our website.

🔼 This figure shows a collection of 16 randomly sampled 3D objects generated by the Zeroverse dataset. The images illustrate the diversity of shapes, textures, and compositions produced by the procedural generation process. It highlights the complexity and variety of objects present in Zeroverse, which are not constrained by real-world semantic information but exhibit rich local geometric details.
read the caption
Figure 6: Uniformly sampled objects from Zeroverse to visualize its data distribution.

🔼 This figure shows the overall framework of the LRM-Zero model. The left side shows the training data: Zeroverse (synthetic data generated from simple primitives) and Objaverse (real-world data). The right side shows the input (sparse-view images) and output (3D reconstruction) of the model. The comparison highlights that despite using entirely synthetic data, LRM-Zero achieves comparable reconstruction quality to a model trained on real-world data, suggesting that local geometric features are more critical than global semantics for this task.
read the caption
Figure 1: We present our LRM-Zero framework trained with synthesized procedural data Zeroverse. Zeroverse (top left) is created from random primitives with textures and augmentations, thus it does not contain semantical information as in Objaverse (bottom left). Nevertheless, when training with the same large reconstruction model architecture [107] on both datasets, LRM-Zero can match objaverse-trained LRM's (denoted as ‘LRM') visual quality (right part) of reconstructions. A possible explanation is that 3D reconstruction, although serves as a core task in 3D vision, rely mostly on local information instead of global semantics. Reconstruction is visualized with RGB and position-based renderings, and interactive viewers can be found on our website.

🔼 This figure compares the qualitative results of 3D reconstruction between LRM-Zero and GS-LRM on several examples. The first row shows that when some parts of the objects are not visible in the input views, the reconstruction quality of LRM-Zero is significantly worse than GS-LRM. However, when the input views provide good coverage of the object (from the second row to the last row), both models achieve comparable results.
read the caption
Figure 8: Qualitative comparison of LRM-Zero (left two columns) and GS-LRM (right two columns). When there is invisible region in the input views (first row), LRM-Zero produces poor reconstruction results. When the input views have good coverage (second row to fifth row), LRM-Zero performs similarly well as GS-LRM.
More on tables

🔼 This table presents a quantitative comparison of the performance of the LRM-Zero model (trained on synthetic data) and the GS-LRM model (trained on Objaverse) on two standard 3D reconstruction benchmarks: GSO and ABO. The comparison uses three metrics: PSNR, SSIM, and LPIPS, which evaluate the visual quality of the 3D reconstructions. The results demonstrate that LRM-Zero achieves competitive performance compared to GS-LRM, suggesting that high-quality 3D reconstruction is possible even without training on real-world data.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.
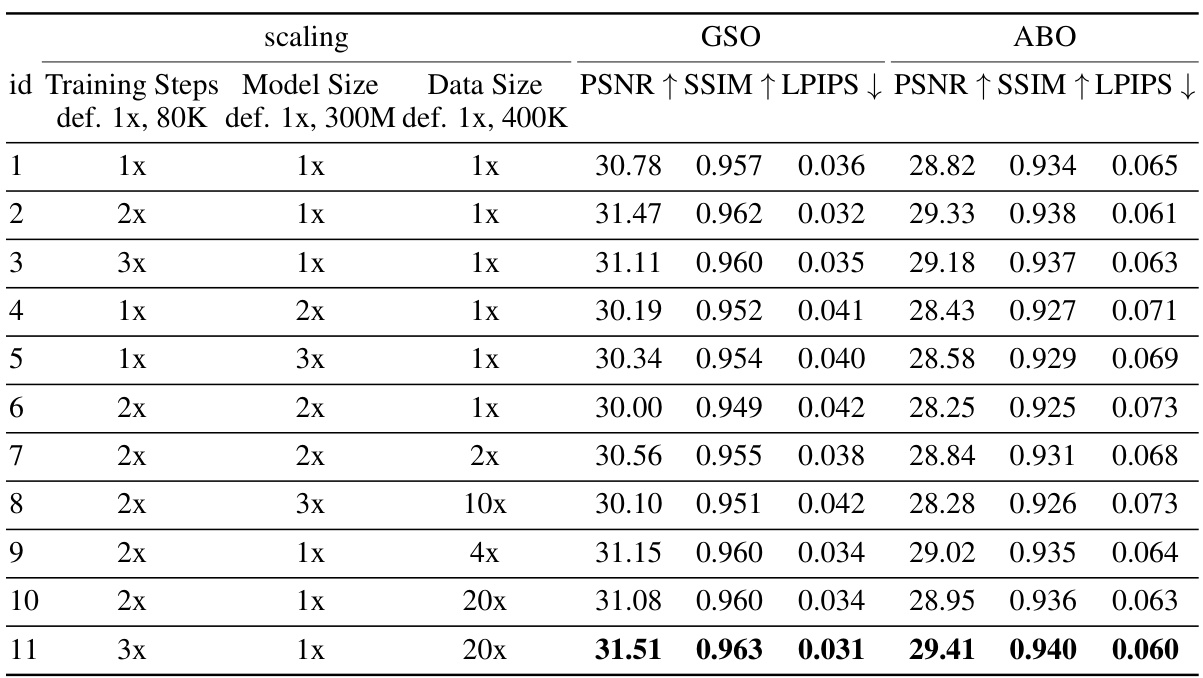
🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM on two standard 3D reconstruction benchmarks, GSO and ABO. The comparison uses the PSNR, SSIM, and LPIPS metrics, with the experiment configured to use 8 input views. The results show that LRM-Zero achieves competitive performance compared to GS-LRM, which was trained on the Objaverse dataset, despite LRM-Zero being trained solely on synthetic data.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.

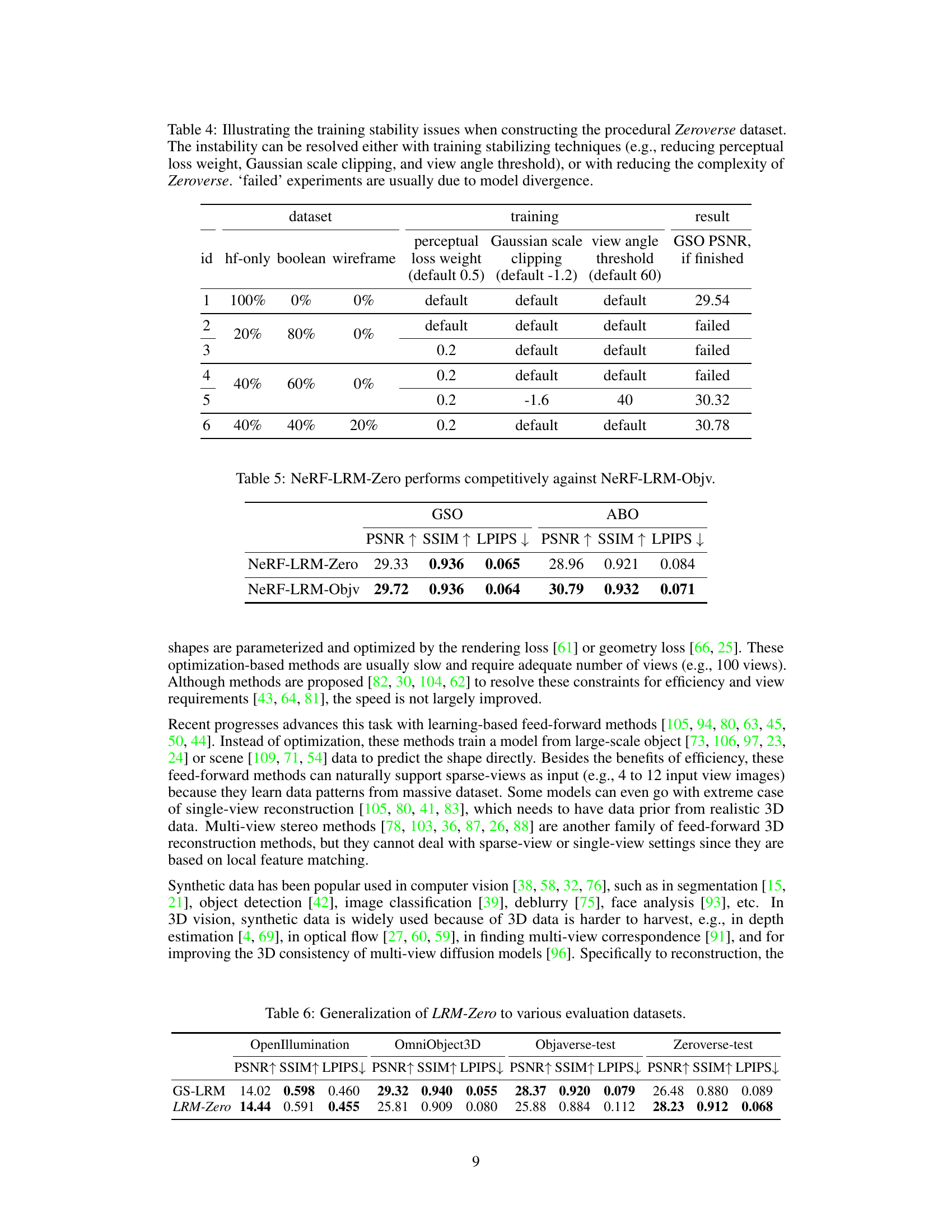
🔼 This table presents a quantitative comparison of the performance of two NeRF-based Large Reconstruction Models (LRMs): NeRF-LRM-Zero and NeRF-LRM-Objv. NeRF-LRM-Zero is trained using the synthetic Zeroverse dataset, while NeRF-LRM-Objv is trained using the Objaverse dataset. The comparison is based on the PSNR, SSIM, and LPIPS metrics evaluated on the GSO and ABO benchmark datasets. The results indicate that despite being trained on fully synthesized data, NeRF-LRM-Zero achieves comparable performance to NeRF-LRM-Objv, which is trained on real-world data. This highlights the potential of using synthetic data for training effective 3D reconstruction models.
read the caption
Table 5: NeRF-LRM-Zero performs competitively against NeRF-LRM-Objv.

🔼 This table presents a quantitative comparison of the performance of two 3D reconstruction models: LRM-Zero and GS-LRM. LRM-Zero is trained using only synthetic data, while GS-LRM is trained on the Objaverse dataset. The comparison is made using three metrics (PSNR, SSIM, LPIPS) and two evaluation datasets (GSO, ABO). The results show that LRM-Zero, despite being trained on synthetic data, achieves competitive performance compared to GS-LRM.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.

🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM on two benchmark datasets (GSO and ABO) using three metrics (PSNR, SSIM, and LPIPS). LRM-Zero, trained on synthetic data, is compared to GS-LRM, which was trained on the Objaverse dataset. The results show that LRM-Zero achieves competitive performance to GS-LRM, demonstrating the effectiveness of training with synthetic data.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.
🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM on two benchmark datasets (GSO and ABO) using three metrics (PSNR, SSIM, LPIPS). The comparison is done for the 8-input-view setting, highlighting the performance of LRM-Zero, which is trained only on synthetic data, relative to the GS-LRM model trained on real-world data (Objaverse).
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.

🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM on two standard 3D reconstruction benchmarks (GSO and ABO). It uses 8 input views and evaluates the results using three metrics: PSNR, SSIM, and LPIPS. The results demonstrate that LRM-Zero, despite being trained only on synthetic data, achieves comparable performance to GS-LRM, which is trained on real-world data (Objaverse).
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.

🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM models on two benchmark datasets, GSO and ABO. The comparison is done using three metrics: PSNR, SSIM, and LPIPS, all common in evaluating image quality. The results show that LRM-Zero, a model trained entirely on synthetic data, achieves comparable results to GS-LRM, which was trained on the real-world Objaverse dataset. The comparison is performed using 8 input views.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.

🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM models on two benchmark datasets, GSO and ABO. The comparison is based on three metrics: PSNR, SSIM, and LPIPS. The results show that LRM-Zero, trained entirely on synthetic data, achieves competitive performance to GS-LRM, which was trained on the real-world Objaverse dataset. The experiment used 8 input views.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.

🔼 This table presents a quantitative comparison of the performance of LRM-Zero and GS-LRM on two standard 3D reconstruction benchmarks (GSO and ABO) using 8 input views. The metrics used are PSNR, SSIM, and LPIPS, which measure the visual quality of the 3D reconstruction. The results show that LRM-Zero, which is trained solely on synthetic data, achieves competitive results to GS-LRM, which uses real-world data for training.
read the caption
Table 1: Quantitative results comparing LRM-Zero with GS-LRM [107] (trained on Objaverse) under the 8-input-view setting. We use GSO [28] and ABO [18] evaluation datasets and PSNR, SSIM, and LPIPS [108] metrics. LRM-Zero demonstrates competitive performance against GS-LRM.
Full paper#