↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many model compression methods use differentiable mask pruning (DMP), which optimizes a continuous “soft” network as a proxy for the final pruned “hard” network. However, a significant performance drop is observed after discretization, creating a “discretization gap”. This gap severely limits the practical effectiveness of DMP.
The authors introduce S2HPruner, a new framework that addresses the discretization gap. It uses soft-to-hard distillation, training both a soft and hard network simultaneously and distilling knowledge from the soft to the hard network. This process, coupled with a decoupled bidirectional knowledge distillation approach, ensures effective mask optimization and significantly improved performance on CIFAR-100, Tiny ImageNet, and ImageNet benchmarks. S2HPruner’s superior performance comes without the need for time-consuming fine-tuning, making it a highly efficient and practical solution.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in differentiable mask pruning, a widely used model compression technique. By introducing S2HPruner and decoupled bidirectional knowledge distillation, it significantly improves pruning performance and opens new avenues for research in efficient deep learning models. It also provides publicly available code, enhancing reproducibility and collaboration.
Visual Insights#

This figure compares importance-based pruning and differentiable mask pruning (DMP). Importance-based pruning directly removes less important weights or connections based on their scores. However, DMP introduces learnable parameters to generate a weight mask, optimizing both the mask and the weights jointly. The figure highlights the ‘discretization gap’ in DMP, where the performance of the final pruned network (hard network) is significantly lower than the performance of the mask-coupled network (soft network) during training. This gap arises because the continuous relaxation architecture used to search for a good structure during training doesn’t fully translate to a similarly performing discrete structure after pruning.

This table compares the performance of different pruning methods (RST-S, Group-SL, OTOv2, Refill, and the proposed S2HPruner) on the CIFAR-100 dataset using ResNet-50, MBV3, and WRN28-10 network architectures. The Top-1 accuracy is reported for each method at three different levels of remaining FLOPs (15%, 35%, and 55%). This allows for a comparison of accuracy versus computational cost.
In-depth insights#
Discretization Gap#
The concept of “Discretization Gap” in the context of differentiable mask pruning highlights a critical challenge in bridging the continuous optimization of a soft network (a differentiable proxy) and the discrete, discontinuous nature of a hard network (the actual pruned model). The gap arises because the continuous relaxation during training may lead to a soft network with superior performance, but its discrete counterpart, obtained through a thresholding process, might significantly underperform. This discrepancy, which is not directly addressed by standard differentiable mask pruning methods, severely limits the effectiveness of pruning, as the goal is a high-performing, compact hard network, not just a well-optimized soft proxy. Strategies to reduce this gap often involve techniques like knowledge distillation and gradual transitions between the soft and hard networks, but these methods can introduce other complications, such as vanishing gradients or suboptimal mask generation. Addressing this discretization gap is crucial for creating more effective and reliable pruning techniques. Therefore, the research should focus on the development of new methods to effectively bridge the gap and ensure that the performance gains observed in the soft network translate to its discretized form.
S2HPruner Framework#
The S2HPruner framework tackles the discretization gap in differentiable mask pruning, a common issue where the continuous soft network’s performance doesn’t translate to the discrete hard network after pruning. S2HPruner uses soft-to-hard distillation, training both soft and hard networks simultaneously. The soft network guides the hard network via knowledge distillation, bridging the performance gap. A key innovation is the decoupled bidirectional knowledge distillation, which prevents performance degradation by selectively blocking gradient flow from the hard network to the soft network while maintaining the mask’s gradient flow. This approach leads to improved pruning performance, especially on challenging benchmarks, without requiring computationally expensive fine-tuning. The framework demonstrates a soft-to-hard paradigm, emphasizing the importance of optimizing the final pruned model and not just an intermediate proxy.
Decoupled KD#
Decoupled Knowledge Distillation (KD) addresses a critical challenge in model pruning where bidirectional KD, while intuitive, often leads to performance degradation. The core problem is the conflicting gradient updates between the soft (relaxed) and hard (discrete) networks. Unidirectional KD, from soft to hard, is insufficient, as it does not fully leverage the information from the hard network’s structure. Decoupled KD elegantly solves this by selectively blocking gradient flow from the hard to soft network for the model weights, while maintaining gradient flow for the mask parameters. This decoupled approach prevents the hard network from negatively impacting the soft network’s optimization of the pruning mask, allowing for superior structural search and better performance transfer to the final pruned model. The key is in isolating the beneficial knowledge transfer for mask refinement from the potentially disruptive influence of hard-network weight adjustments on the soft-network structure. The result is a more effective and efficient pruning mechanism, bridging the gap between the continuous proxy and the final discrete model.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a comprehensive evaluation of the proposed method against existing state-of-the-art techniques. This would involve using established datasets and metrics relevant to the problem domain. Key aspects would include a clear description of the benchmark datasets, the specific metrics used for evaluation (e.g., accuracy, precision, recall, F1-score, etc.), and a detailed comparison of the performance of the proposed method against competing methods. The results should be presented in a clear and concise manner, using tables and/or graphs to visually represent the performance differences. Statistical significance testing should be included to ensure that the observed performance differences are not due to chance. Furthermore, the discussion should analyze the results in a thoughtful and insightful way, explaining any unexpected findings and suggesting directions for future work. The overall presentation should focus on objectively demonstrating the effectiveness of the proposed method, rather than merely presenting favorable results.
Future Work#
Future research directions stemming from this work could involve exploring the discretization gap in diverse model architectures beyond those tested, such as exploring different pruning strategies or investigating the impact of varying levels of quantization. Another promising avenue would be to investigate the applicability of S2HPruner across a wider range of tasks. The current focus on image classification limits the understanding of the method’s potential for other computer vision problems, including object detection and semantic segmentation, as well as other domains beyond computer vision. A crucial area for future work involves evaluating the hardware efficiency of S2HPruner. While FLOPs reduction is important, the actual impact on inference time on a specific hardware is crucial and should be assessed. Finally, enhancing S2HPruner’s robustness by incorporating techniques to mitigate potential overfitting issues or adversarial attacks will be pivotal to make it more practical for real-world deployment.
More visual insights#
More on figures

This figure illustrates the forward and backward propagation in the S2HPruner model. It shows how the soft network and hard network are processed in parallel, with knowledge distillation used to guide the hard network’s weights towards those of the soft network. The figure highlights the key components including the learnable mask parameters (u), the relaxed mask (w), the binary mask (m), and the inputs (i) and outputs (s,h) of soft and hard networks. The backward flow illustrates the gradient calculation for both weights and the mask, with a decoupled approach to prevent performance degradation.
This figure illustrates the forward and backward passes of the proposed Soft-to-Hard Pruner (S2HPruner). It shows how the soft network (with continuous relaxation mask w) and hard network (with binary mask m) are jointly trained using a decoupled bidirectional knowledge distillation approach. The diagram uses an exemplary linear layer to show how the gradients for the parameters (θ), relaxed mask (w), and gap between soft and hard networks (G) are calculated and updated during the training process.
This figure compares importance-based pruning and differentiable mask pruning. Importance-based pruning directly prunes weights based on importance scores, while differentiable mask pruning uses a learnable mask to guide the pruning process, optimizing a continuous relaxation (soft network) as a proxy for the final discrete network (hard network). The figure highlights the ‘discretization gap’, which is the performance difference between the soft and hard networks after the discretization process. This gap is a key problem that the paper addresses.

This figure compares importance-based pruning and differentiable mask pruning methods. It highlights the discretization gap, which is the performance difference between the soft network (continuous relaxation) and the hard network (discrete pruned network) in differentiable mask pruning. The visualization shows how the soft network achieves high performance due to the continuous weights and masks, but the hard network suffers from the discretization process, leading to a performance drop. This gap is the central problem that S2HPruner aims to solve.

The figure compares importance-based pruning and differentiable mask pruning methods, highlighting the discretization gap. Importance-based pruning directly removes less important weights, leading to potential structural integrity issues. Differentiable mask pruning uses a learnable mask to guide the pruning process, aiming for a better structure but still facing the discretization gap where the continuous relaxation (soft network) and the discrete pruned network (hard network) differ significantly in performance. The discretization gap is visually represented by the discrepancy between the performance of soft and hard networks.
This figure illustrates the forward and backward passes of the Soft-to-Hard Pruner (S2HPruner) framework. It shows how the soft network (continuous relaxation) and hard network (discrete pruned network) are processed together, highlighting the roles of the learnable parameters (u), relaxed mask (w), estimated binary mask (m), and the loss functions (L, G, R) in the training process. The diagram uses a simplified linear layer as an example to depict the flow of information and gradient updates.
This figure compares importance-based pruning and differentiable mask pruning methods. It illustrates how differentiable mask pruning uses a soft network (continuous relaxation) as a proxy for the hard network (discrete pruned network). The main point is to highlight the ‘discretization gap,’ the performance difference between the soft and hard networks due to the discretization process. The visualization shows that the soft network generally achieves higher performance than the hard network after discretization.

This figure compares importance-based pruning and differentiable mask pruning methods, highlighting the difference in their performance and the concept of a ‘discretization gap’. Importance-based pruning directly removes less important weights, often resulting in performance degradation. Differentiable mask pruning uses a continuous relaxation of the binary mask, allowing for gradient-based optimization of the network architecture. However, the process of converting this continuous relaxation to a discrete binary mask introduces the discretization gap, where the performance of the final pruned network (hard network) is significantly lower than that of its continuous counterpart (soft network). The figure visually represents this gap using color intensity to show the magnitude of weights or masks.
More on tables

This table compares the performance of different pruning methods (RST-S, Group-SL, OTOv2, Refill, and the proposed S2HPruner) on the Tiny ImageNet dataset. The results are presented for three different levels of remaining FLOPs (15%, 35%, and 55%) for three different network architectures (ResNet-50, MBV3, and WRN28-10). Each cell shows the Top-1 accuracy achieved by each method under the specified conditions. The table demonstrates the superior performance of S2HPruner compared to existing methods, especially at lower FLOP constraints.

This table shows the Top-1 accuracy results for two transformer models, ViT and Swin Transformer, on the CIFAR-100 dataset after applying different pruning ratios (15%, 35%, and 55%). It compares the performance of the proposed S2HPruner method against the RST-S method, demonstrating the effectiveness of S2HPruner across various network architectures and pruning levels.

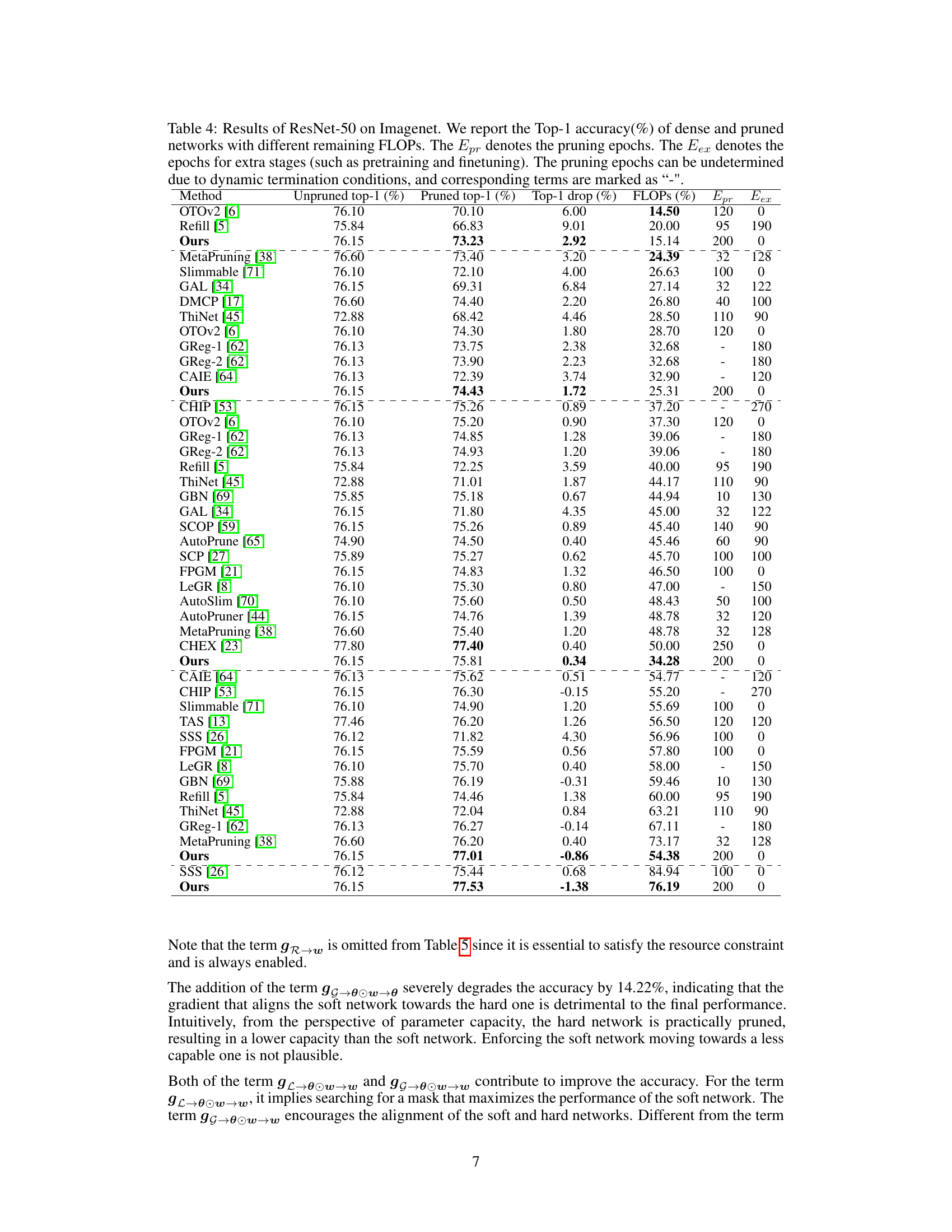
This table compares the performance of the proposed S2HPruner against other state-of-the-art pruning methods on the ImageNet dataset using ResNet-50 as the base model. It shows the Top-1 accuracy and remaining FLOPs after pruning, along with the number of pruning and extra epochs. The table highlights the performance gains of S2HPruner, particularly at lower FLOPs.
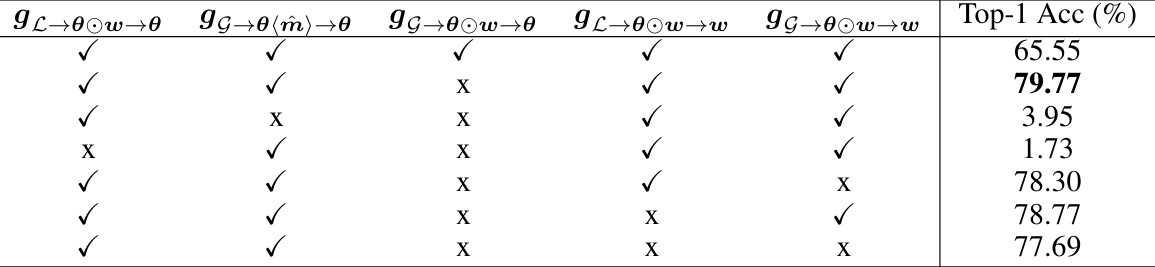
This table presents an ablation study, analyzing the impact of different gradient components on the performance of the S2HPruner model. By selectively including or excluding gradient terms (indicated by checkmarks and Xs), the researchers evaluated how each component contributes to the model’s overall accuracy when a 15% FLOPs reduction is targeted. The results show the importance of specific gradient components for achieving high accuracy in the pruned network.

This table compares three different problem formulations for network pruning: the proposed method (Ours), an alternative that directly optimizes the hard network (Alt 1), and an alternative that uses self-distillation (Alt 2). It evaluates the gap between the soft and hard networks using Jensen-Shannon divergence (JS) and L2 distance. The results demonstrate that the proposed method effectively bridges the discretization gap, resulting in superior performance.

This table shows the top-1 accuracy of both the soft network (θ⊙w) and the hard network (θ(m)) at different fine-tuning epochs (10, 50, 100, 250, 500). The purpose is to demonstrate the effect of fine-tuning on the hard network’s accuracy after the coupled training phase. The initial accuracy of the soft network before fine-tuning is 79.41%.
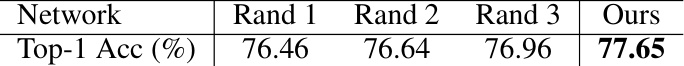
This table presents the Top-1 accuracy results of four different ResNet-50 networks pruned to 15% FLOPs. Three networks were randomly pruned, and one network was pruned using the proposed Soft-to-Hard Pruner (S2HPruner). The results demonstrate that the S2HPruner outperforms the randomly pruned networks in terms of accuracy, showcasing the architectural superiority of the proposed method.

This table presents the robustness of the proposed pruning method against randomness. Four independent experiments were conducted using different random seeds while keeping the same settings. The results demonstrate the consistency and reliability of the method, as the Top-1 accuracy and FLOPs remain stable across different runs, with negligible variations.

This table compares the training efficiency of the proposed S2HPruner method with other existing structured pruning methods. The comparison is based on ResNet-50 on the CIFAR-100 dataset. Metrics include Top-1 accuracy (both single and double epoch training), GPU time per epoch, and peak GPU memory usage during training and inference. The double-epoch training results for other methods are included to ensure a fairer comparison, as the authors’ method trains a soft and a hard network simultaneously, thus needing less epochs.
Full paper#