TL;DR#
Large multimodal models (LMMs) are powerful but lack interpretability, hindering trust and deployment. Existing methods struggle to understand LMM’s internal representations, particularly concerning multimodal interactions between vision and language components. This paper tackles this challenge by focusing on the internal representations of a given token, allowing the study of multimodal interactions in a focused manner.
The proposed CoX-LMM framework uses dictionary learning to extract multimodal concepts from LMM representations. These concepts are then grounded in both vision (via images activating the concepts) and text (via words associated with them). The framework’s effectiveness is shown qualitatively (visualizations) and quantitatively (evaluation of disentanglement between concepts and quality of grounding). The work represents a significant advancement in understanding LMMs, making it more reliable and trustworthy.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on multimodal model explainability and interpretability. It addresses a critical gap in understanding the internal representations of large multimodal models, which are increasingly being deployed in various applications. The proposed framework, CoX-LMM, offers a novel approach to extract and ground multimodal concepts, enabling a deeper understanding of these complex models and opening up new avenues for research in this area. The public availability of the implementation further enhances its impact, encouraging broader adoption and further development.
Visual Insights#

🔼 This figure illustrates the CoX-LMM framework for multimodal concept extraction and grounding. Starting with a pre-trained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the method extracts internal representations from the LMM for that token across multiple images. These representations form a matrix Z, which is then linearly decomposed using dictionary learning into a concept dictionary U and activation matrix V. Each concept in U is grounded in both visual and textual domains: visual grounding is done by identifying the images that maximally activate each concept, and textual grounding is achieved by decoding the concept using the LLM’s unembedding matrix to find the most probable associated words.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.
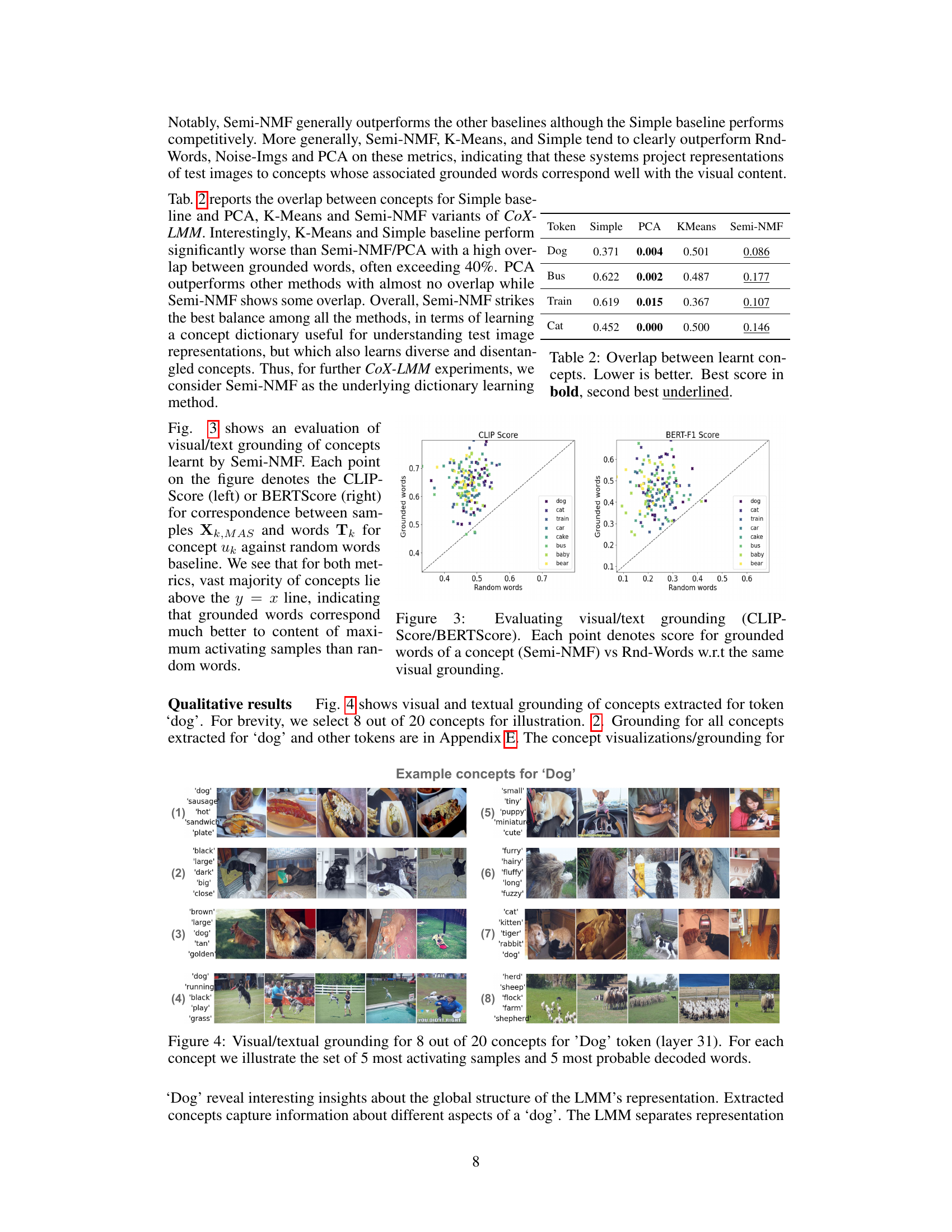
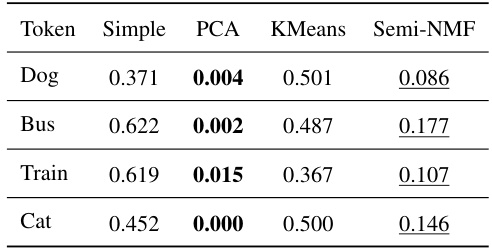
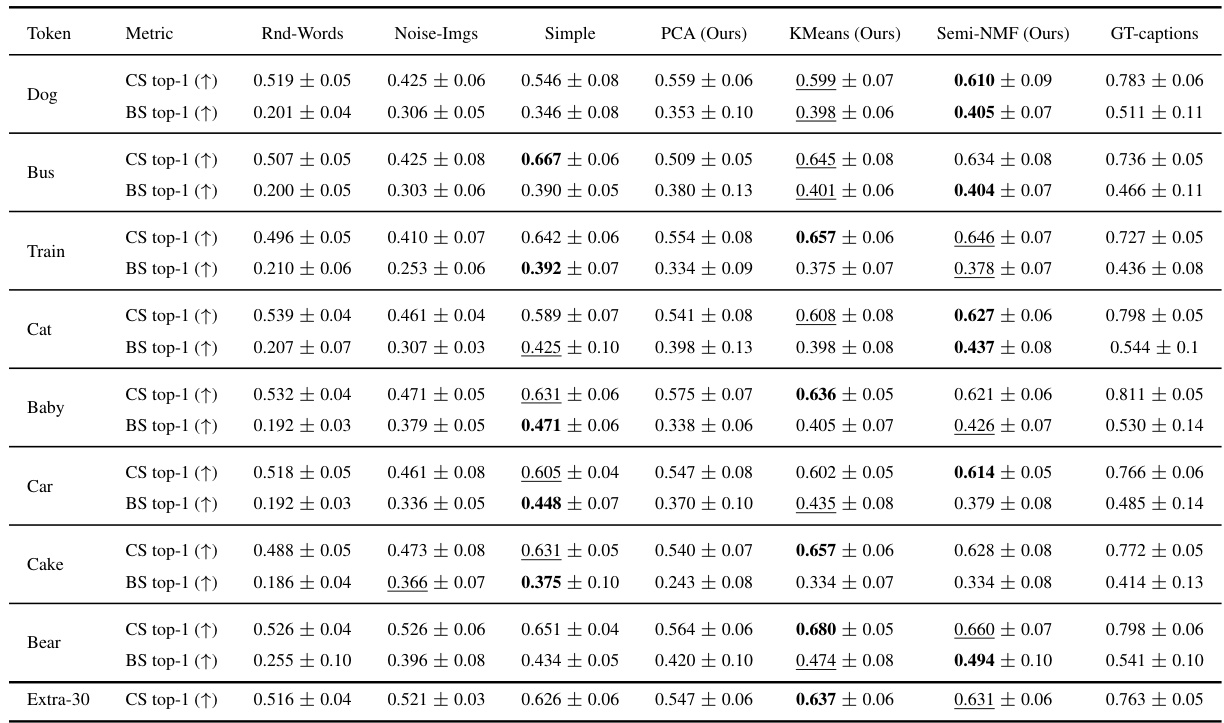
🔼 This table presents the quantitative results of the experiments conducted to evaluate the performance of the proposed CoX-LMM framework and its baselines on five different tokens (‘Dog’, ‘Bus’, ‘Train’, ‘Cat’). The evaluation metrics used are CLIPScore (CS) and BERTScore (BS), which measure the correspondence between the visual and textual grounding of the top-1 activating concept for each token. The table shows that the Semi-NMF variant of CoX-LMM generally outperforms other baselines in terms of both CLIPScore and BERTScore. The results highlight the effectiveness of Semi-NMF as a dictionary learning method for concept extraction in LMMs and its potential for understanding internal representations of LMMs.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.
In-depth insights#
Multimodal Concept#
The concept of “Multimodal Concept” in the context of large multimodal models (LMMs) represents a significant advancement in explainable AI. It proposes moving beyond the limitations of unimodal analysis by integrating visual and textual information to understand the model’s internal representations. This integration allows for the extraction of concepts that are inherently grounded in both visual and textual domains, offering a more holistic and nuanced understanding compared to approaches that treat each modality separately. The approach uses dictionary learning to discover these multimodal concepts, providing a framework that can be applied for interpreting the model’s predictions. Qualitative and quantitative evaluations of these extracted concepts are crucial to assess their usefulness and validity in model explainability. A key strength lies in the multimodal grounding, where concepts are contextualized through visual and textual elements, which significantly enhances interpretability. The framework’s ability to disentangle different concepts is also important in ensuring that each concept captures a distinct piece of information, improving the clarity and understanding of the model’s decision process. In essence, “Multimodal Concept” provides a powerful and insightful pathway toward comprehending the intricacies of LMMs.
Dictionary Learning#
Dictionary learning, in the context of this research paper, is a crucial technique for extracting meaningful concepts from the complex, high-dimensional data representations generated by large multimodal models (LMMs). The core idea is to learn a dictionary of basis vectors (concepts) that can linearly approximate the LMM’s internal representations. Each basis vector represents a concept, and the coefficients indicate how strongly each concept contributes to a specific representation. The method’s strength lies in its ability to discover underlying semantic structures in the data, which are often obscured by the model’s inherent complexity. Non-negative matrix factorization (NMF) and its variant, Semi-NMF, are employed to ensure the interpretability of the learned concepts. The use of Semi-NMF is particularly noteworthy as it allows for a more relaxed constraint, enabling the decomposition of data with mixed positive and negative values, unlike traditional NMF which only accepts non-negative values. The resulting concept dictionary is then used for explainability and to analyze the model’s internal functioning. This approach is a significant advancement because it provides a framework for understanding the multimodal nature of LMM representations, grounding the concepts semantically both visually and textually which is useful for generating local interpretations.
Grounding Concepts#
The concept of grounding, in the context of multimodal models, is crucial for bridging the gap between abstract internal representations and human-understandable meaning. Grounding concepts within a multimodal model involves connecting learned features to their corresponding semantic representations in both visual and textual domains. This process isn’t simply about assigning labels but delves into establishing a meaningful relationship between the model’s internal representations and the real-world concepts they represent. The paper likely explores techniques to achieve this grounding, perhaps using dictionary learning to discover concepts that are inherently multimodal, activating strongly when specific semantic information is present in both image and text data. Qualitative evaluations might involve visualization of the images and words most strongly associated with each learned concept, demonstrating its semantic coherence. Quantitative metrics could assess the degree of disentanglement between concepts, ensuring that they represent distinct semantic units. Successful grounding leads to a more interpretable model, enhancing trust and facilitating further model refinement and application by providing insights into how the model reasons and makes decisions.
LMM Interpretability#
Large multimodal models (LMMs), combining the power of visual encoders and large language models (LLMs), present a significant challenge for interpretability. Understanding their internal representations is crucial for building trust and reliability, yet remains largely elusive. Existing unimodal interpretability techniques often fall short when applied to the complex interplay of modalities within LMMs. Concept-based methods, while promising for explaining individual model decisions, need to be adapted to effectively capture the rich semantic connections across visual and textual data inherent in LMMs. This necessitates the development of new methods capable of extracting and grounding concepts in the multimodal context, ideally identifying concepts that are simultaneously meaningful and relevant to both visual and textual inputs. Future research should address the disentanglement of multimodal concepts, ensuring that the extracted concepts provide a clear and interpretable understanding of the model’s internal workings. The evaluation of LMM interpretability methods presents further complexities, requiring new metrics beyond traditional accuracy measures and incorporating qualitative assessment of the grounded concepts’ meaningfulness and relevance. Addressing these challenges is key to unlocking the full potential of LMMs and fostering responsible deployment of these powerful AI systems.
Future Directions#
Future research could explore extending the concept-based explainability framework to analyze diverse LMM architectures and multimodal tasks beyond image captioning. Investigating the impact of different pre-training methods and data on the learned concepts is crucial. Furthermore, exploring the relationships between concepts across layers within the LLM and across modalities would provide deeper insights into LMM internal representations. Developing more sophisticated methods for concept grounding, possibly incorporating external knowledge bases, could enhance interpretability. Quantifying the impact of concept disentanglement on model performance is another key area. Finally, applying this framework to assess fairness and robustness in LMMs, and addressing potential biases embedded within the learned concepts would be a significant contribution.
More visual insights#
More on figures

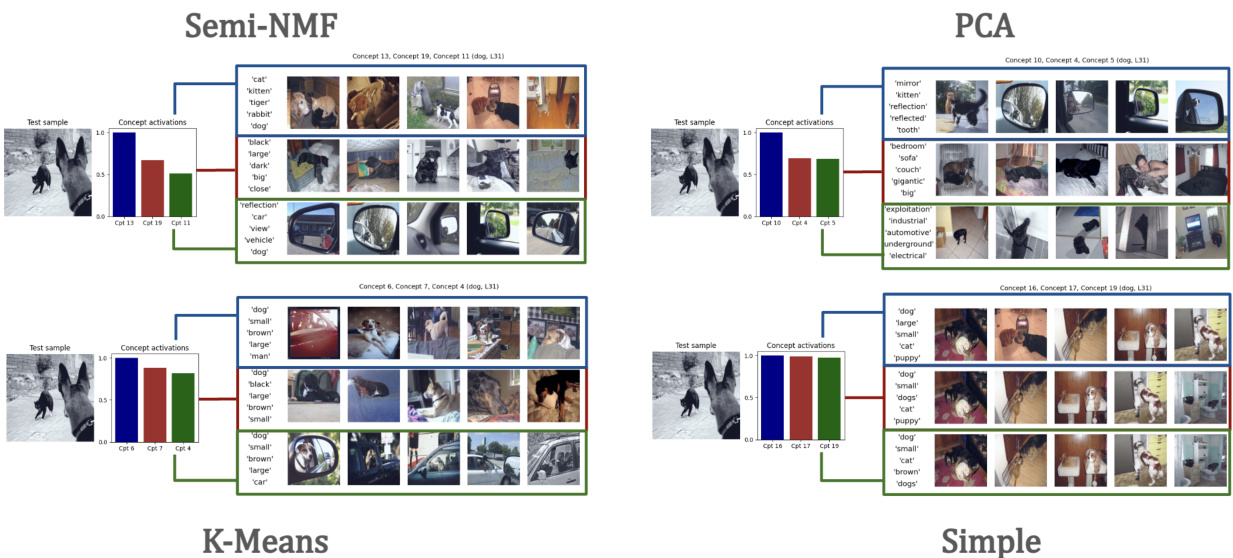
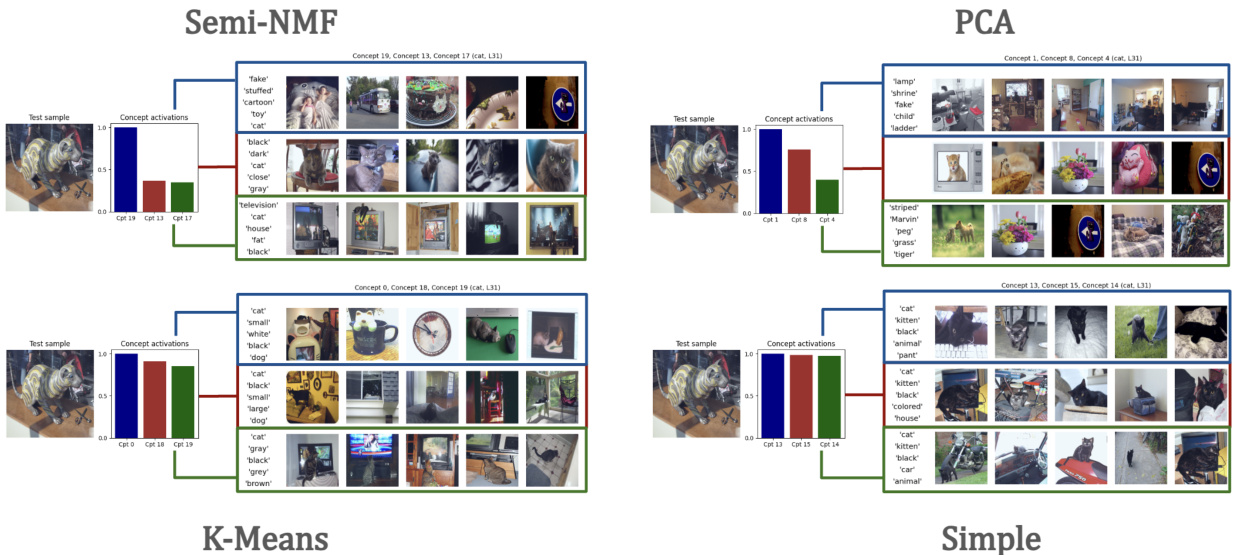
🔼 This figure shows an example of how the model grounds a learned concept in both visual and textual domains. The top row displays five images that maximally activate a specific concept extracted from the model’s internal representation of the word ‘dog’. These images represent a variety of dogs with different colors, sizes, and settings. The bottom row shows the top five words predicted by the model as being most associated with that concept. The combination of images and words illustrates how the concept is semantically grounded in both modalities, providing a multi-modal interpretation of the model’s internal representation.
read the caption
Figure 2: Example of multimodal concept grounding in vision and text. Five most activating samples (among decomposed in Z) and five most probable decoded words are shown.
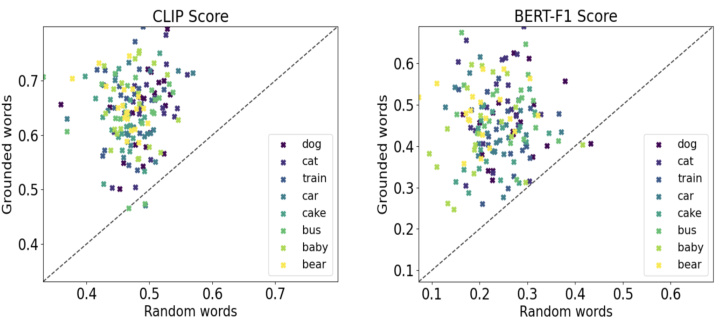
🔼 This figure shows a quantitative evaluation of the visual and textual grounding of the concepts learned by the Semi-NMF method. Each point represents a concept, and its position is determined by the CLIPScore (left) or BERTScore (right) achieved. The x-axis represents the score obtained using random words as a baseline, while the y-axis shows the score obtained using the actual grounded words for each concept. The plot demonstrates that the grounded words generated using the Semi-NMF method show significantly better correspondence with the visual data than random words, across both CLIPScore and BERTScore metrics, indicating a strong multimodal grounding of the learned concepts.
read the caption
Figure 3: Evaluating visual/text grounding (CLIPScore/BERTScore). Each point denotes score for grounded words of a concept (Semi-NMF) vs Rnd-Words w.r.t the same visual grounding.

🔼 This figure demonstrates the multimodal concept grounding approach used in the paper. It shows an example of a concept related to the word ‘Dog.’ The top part displays five images that highly activate this specific concept. These images provide a visual grounding of the concept, illustrating the visual features that the model associates with it. The bottom part shows the top five words that the language model produced when decoding the concept’s representation. These words are ‘white,’ ’light,’ ‘fluffy,’ ‘golden,’ and ‘dog.’ They represent a textual grounding of the concept, illustrating the semantic meaning of the concept in terms of words related to the visual images. The combination of the visual and textual grounding shows that the concept is well grounded in both the visual and textual domains, making it a multimodal concept. This approach is crucial to interpreting the internal representations of the large multimodal models (LMMs) studied in this paper.
read the caption
Figure 2: Example of multimodal concept grounding in vision and text. Five most activating samples (among decomposed in Z) and five most probable decoded words are shown.

🔼 This figure illustrates the proposed CoX-LMM framework for multimodal concept extraction and grounding. Starting with a pre-trained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the framework extracts internal representations of the token across multiple images. These representations are compiled into a matrix Z, which is then decomposed linearly into a concept dictionary U and activation matrix V. Each concept in U is then grounded in both the visual and textual domains. Visual grounding is achieved by identifying images that maximally activate each concept, while textual grounding is done by decoding the concept through the LLM to find the most probable words associated with it.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.
🔼 This figure illustrates the process of multimodal concept extraction and grounding using the proposed CoX-LMM framework. Starting with a pretrained large multimodal model (LMM) trained for image captioning and a target token (e.g., ‘dog’), the method extracts the LMM’s internal representations for that token across multiple images. These representations are compiled into a matrix Z, which is then linearly decomposed using dictionary learning into a concept dictionary (U) and a matrix of concept activations (V). Each concept in the dictionary is then ‘grounded’ in both the visual and textual domains. Visual grounding is done by identifying the images that maximally activate each concept, while text grounding is achieved by decoding the concept vector through the LLM’s unembedding matrix to obtain the most probable words associated with that concept. This process leads to the extraction of meaningful ‘multimodal concepts’ that are useful for interpreting the LMM’s internal representations.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

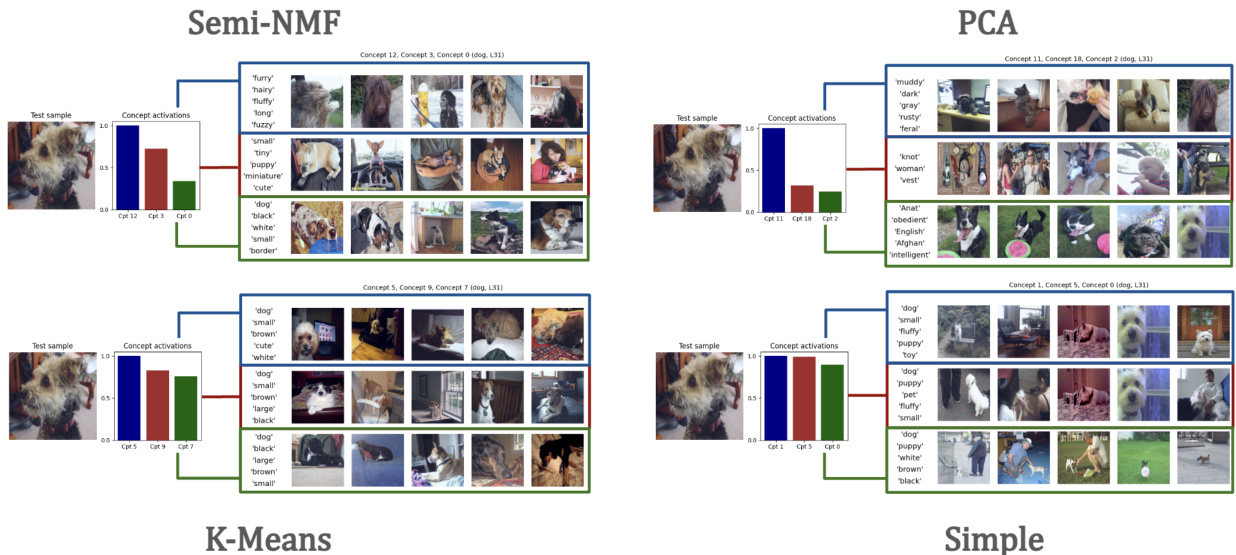
🔼 This figure shows the multimodal grounding of concepts extracted for the token ‘Dog’. For each of the 20 learnt concepts, it displays five images that maximally activate that concept (visual grounding) and the five most probable words associated with that concept as decoded from the language model (textual grounding). The figure illustrates how concepts learned by the model represent semantically meaningful combinations of visual and textual features relating to the concept of ‘dog’. The token representations used were extracted from layer 31 of the Language Model (LLM) component within the larger multimodal model.
read the caption
Figure 7: Multimodal concept grounding in vision and text for the token ‘Dog’. The five most activating samples and the five most probable decoded words for each component uk, k ∈ {1, ..., 20} are shown. The token representations are extracted from L=31 of the LLM section of our LMM.

🔼 This figure illustrates the CoX-LMM framework, starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘dog’). The method extracts internal representations of the token across numerous images, forming a matrix Z. Dictionary learning linearly decomposes Z into a concept dictionary U and activation matrix V. Each concept (uk) in U is then multimodally grounded; visual grounding (Xk,MAS) is achieved by finding the most activating images for that concept, while textual grounding (Tk) is done by decoding the concept through the language model to get the most probable words. This demonstrates how the framework extracts and grounds multimodal concepts.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM framework. It begins with a pretrained large multimodal model (LMM) processing images related to a target token (e.g., ‘Dog’). The resulting representations are compiled into a matrix, which is then decomposed using dictionary learning into a concept dictionary (U) and concept activations (V). Each concept in the dictionary is then grounded in both the visual and textual domains. Visual grounding identifies the images that most strongly activate each concept, while textual grounding involves decoding the concept through the LMM’s language model to find the most associated words.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

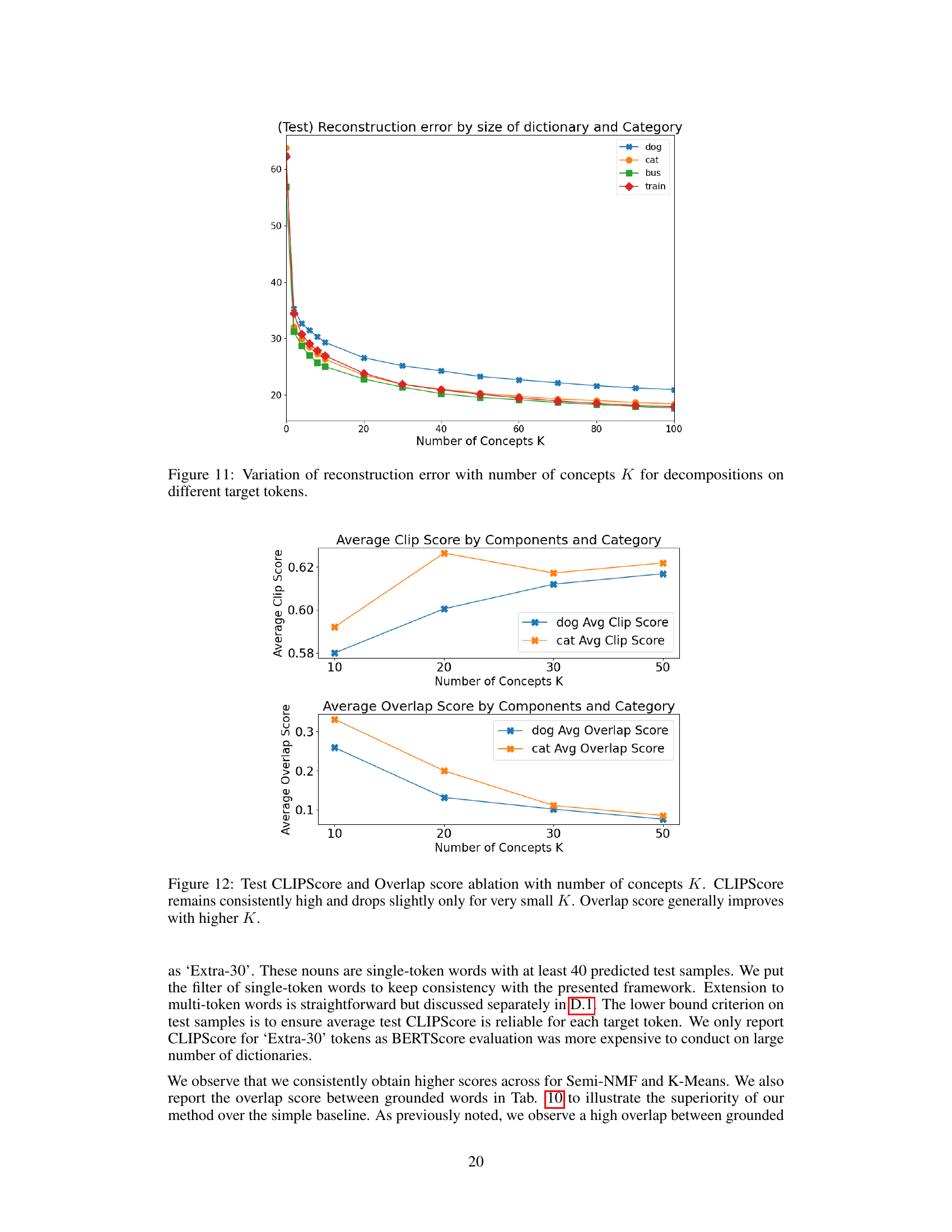
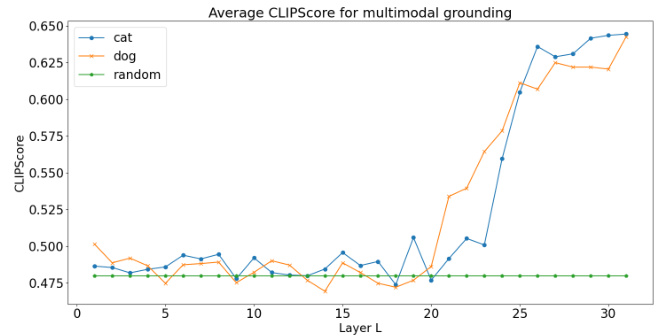
🔼 This figure shows how the reconstruction error changes as the number of concepts (K) used in the dictionary learning process varies. The reconstruction error represents the difference between the original data and the approximation produced by the decomposition. Separate lines show the results for different tokens (dog, cat, bus, train), indicating how the optimal number of concepts may vary depending on the specific token. The graph helps determine the best value for K, balancing accurate representation and model complexity.
read the caption
Figure 11: Variation of reconstruction error with number of concepts K for decompositions on different target tokens.
🔼 This figure illustrates the CoX-LMM framework. It starts with a pretrained large multimodal model (LMM) processing images related to a target token (e.g., ‘dog’). The resulting representations are formed into a matrix (Z). Dictionary learning decomposes Z into a concept dictionary (U) and activation coefficients (V). Each concept in U is then connected to visual and textual representations. Visual grounding involves identifying images that strongly activate a concept, while textual grounding involves decoding the concept through the LLM to find related words.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM pipeline. Starting with a pretrained Large Multimodal Model (LMM) and a target token (e.g., ‘Dog’), the method extracts internal representations from the LMM for that token across multiple images. These representations form a matrix Z, which is decomposed using dictionary learning into a concept dictionary U (basis vectors representing concepts) and an activation matrix V (coefficients showing concept activations for each sample). Each concept in U is multimodally grounded: visually by identifying images that strongly activate it, and textually by decoding it through the LLM to find the most probable words associated with it.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure provides a visual summary of the CoX-LMM pipeline. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the process involves extracting internal representations of that token across multiple images, forming a matrix Z. Dictionary learning is then used to decompose Z into a concept dictionary (U) and activation coefficients (V). Each concept in the dictionary is multimodally grounded, meaning it’s linked to both visual (images that strongly activate that concept) and textual (words strongly associated with that concept) information. The figure illustrates this entire process with a visual diagram of the model, the decomposition steps, and the resulting multimodal concept grounding.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure provides a visual overview of the CoX-LMM framework. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the framework extracts internal representations of the token from multiple images. These representations are compiled into a matrix Z, which is then linearly decomposed using dictionary learning to obtain a concept dictionary U and activation matrix V. Each concept in the dictionary (uk) is then multimodally grounded, meaning its meaning is connected to both visual and textual domains. Visual grounding is achieved by identifying the images that most strongly activate each concept, while textual grounding is performed by decoding the concept through the LLM to find the most probable associated words.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM pipeline for multimodal concept extraction and grounding. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the method extracts internal representations of the token across multiple images. These representations are organized into a matrix (Z), which is then linearly decomposed using dictionary learning into a concept dictionary (U) and activation coefficients (V). Each concept in the dictionary is multimodally grounded, meaning it’s connected to both visual and textual information. Visual grounding is achieved by identifying the images that most strongly activate each concept. Textual grounding involves decoding each concept through the LMM’s language model to find the most probable words associated with it.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.
🔼 This figure illustrates the CoX-LMM framework’s pipeline. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the framework extracts internal representations of that token from multiple images. These representations form a matrix Z, which is then linearly decomposed into a concept dictionary U and activation matrix V. Each concept in U is multimodally grounded; its textual grounding is found by decoding it through the LLM’s unembedding matrix to get the most probable words, and its visual grounding is the set of images that maximally activate that concept.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.
🔼 This figure illustrates the CoX-LMM pipeline for multimodal concept extraction and grounding. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the method extracts internal representations of the token from multiple images. These representations form a matrix Z which is linearly decomposed using dictionary learning into a concept dictionary U and activation matrix V. Each concept in U is then multimodally grounded: visually, by identifying the images that maximally activate it (Xk,MAS); and textually, by decoding it through the LLM’s unembedding matrix to find the most probable words (Tk).
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.
🔼 This figure illustrates the CoX-LMM pipeline. It starts with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’). The model processes internal representations of the token from multiple images, creating a matrix Z. Dictionary learning decomposes Z into a concept dictionary (U) and activations (V). Each concept in U is then grounded in both visual and textual domains; visual grounding by identifying images that strongly activate the concept, and textual grounding by decoding the concept back through the LLM’s unembedding matrix to obtain the most probable words associated with it.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM framework’s pipeline for multimodal concept extraction and grounding. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the method extracts internal representations of the token across multiple images, forming a matrix Z. Dictionary learning decomposes Z into a concept dictionary U and activation matrix V. Each concept in U is then grounded in both visual and textual domains. Visual grounding involves identifying the images that maximally activate each concept. Text grounding involves decoding each concept through the LLM’s unembedding matrix to obtain the most probable associated words.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM framework. Starting with a pretrained large multimodal model (LMM) and a target token (e.g., ‘Dog’), the model’s internal representations for that token are extracted from multiple images and compiled into a matrix Z. Dictionary learning decomposes Z into a concept dictionary U and activation matrix V. Each concept in U is then grounded in both the visual and textual domains. Visual grounding is achieved by identifying the images that most activate each concept, while textual grounding involves decoding the concept through the LLM to find the most probable words associated with it.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM framework for multimodal concept extraction and grounding. Starting with a pre-trained large multimodal model (LMM) and a target token (e.g., ‘dog’), the framework extracts internal representations of the token from multiple images. These representations are compiled into a matrix Z, which is then linearly decomposed into a concept dictionary U and activation matrix V. Each concept in the dictionary (uk) is then grounded in both visual and textual domains. Visual grounding is achieved by identifying the images that maximally activate each concept, while text grounding involves decoding each concept through the LLM’s unembedding matrix to find the most probable associated words.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.

🔼 This figure illustrates the CoX-LMM framework’s pipeline for multimodal concept extraction and grounding. It starts with a pre-trained large multimodal model (LMM) processing images related to a target token (e.g., ‘Dog’). The resulting internal representations are compiled into a matrix Z. This matrix is then linearly decomposed using dictionary learning to produce a concept dictionary (U) and its activation coefficients (V). Each concept in the dictionary is then ‘grounded’ in both the visual and textual domains. Visual grounding is achieved by identifying images that strongly activate each concept. Text grounding involves decoding the concept representation to obtain the most probable words associated with it. This figure demonstrates the process of extracting and interpreting multimodal concepts within the LMM.
read the caption
Figure 1: Overview of multimodal concept extraction and grounding in CoX-LMM. Given a pretrained LMM for captioning and a target token (for eg. 'Dog'), our method extracts internal representations of f about t, across many images. These representations are collated into a matrix Z. We linearly decompose Z to learn a concept dictionary U and its coefficients/activations V. Each concept uk ∈ U, is multimodally grounded in both visual and textual domains. For text grounding, we compute the set of most probable words Tk by decoding uk through the unembedding matrix Wu. Visual grounding Xk,MAS is obtained via vk as the set of most activating samples.
More on tables
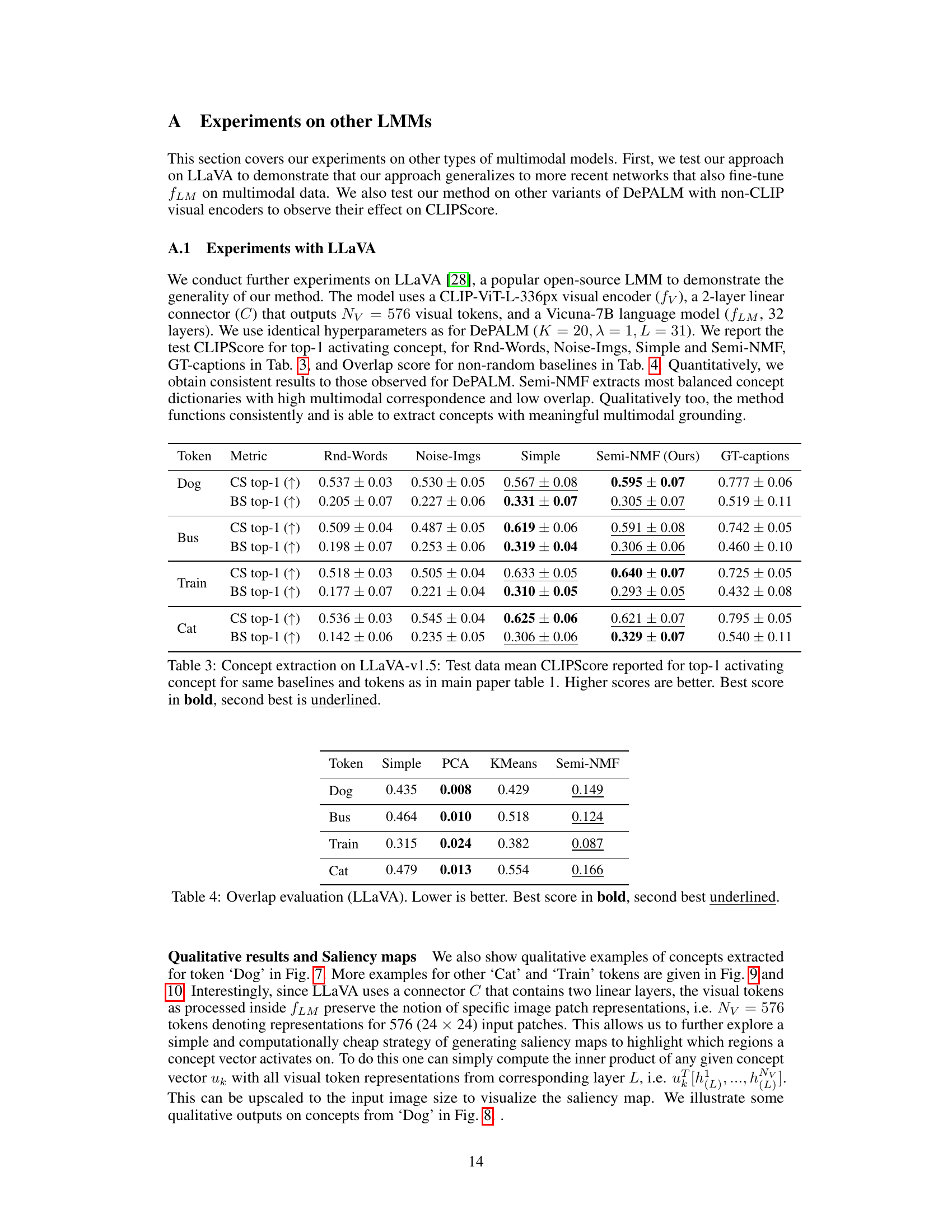
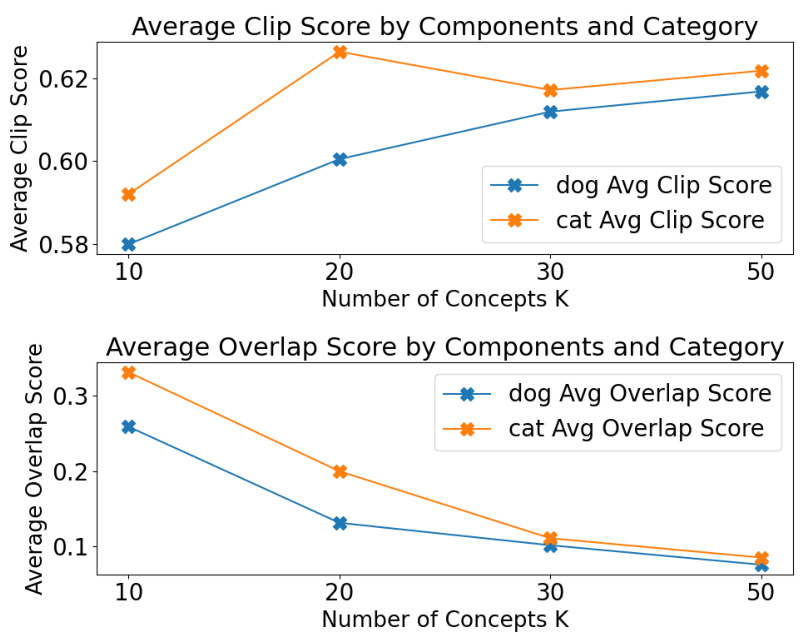
🔼 This table presents the overlap between concepts for different variants of the CoX-LMM model using the LLaVA dataset. The overlap measures how much the grounded words of different concepts share common words. Lower overlap scores indicate better disentanglement between concepts, suggesting that each concept represents unique semantic information. The results show that Semi-NMF achieves the best balance, offering a low overlap while maintaining high performance in other metrics.
read the caption
Table 2: Overlap evaluation (LLaVA). Lower is better. Best score in bold, second best underlined.

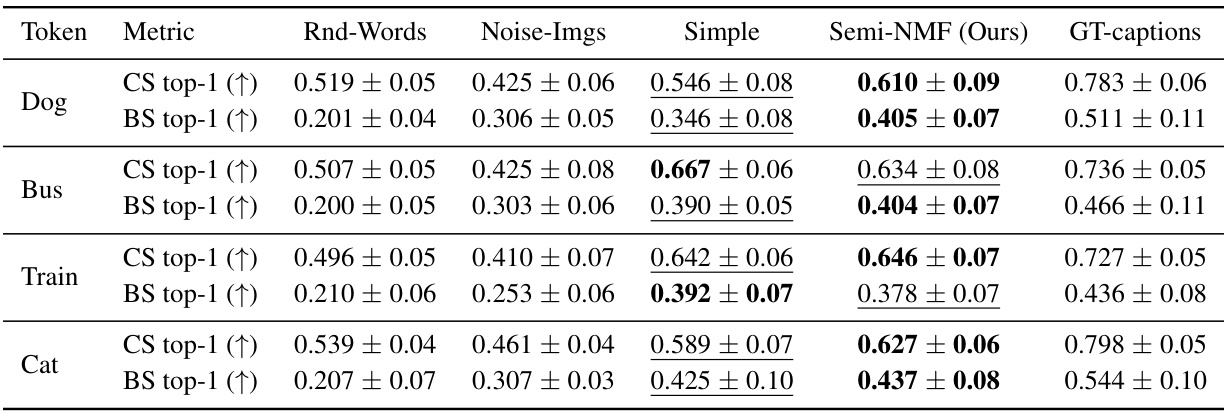
🔼 This table presents the quantitative results of the proposed CoX-LMM framework and several baseline methods for concept extraction on five different tokens (Dog, Bus, Train, Cat). It shows the CLIPScore (CS) and BERTScore (BS) for the top-1 activating concept, providing a comparison of the performance of the proposed Semi-NMF approach against other dictionary learning methods (Simple, PCA, K-Means), random word baselines (Rnd-Words), and baselines using noise images (Noise-Imgs). The results indicate that the Semi-NMF method generally outperforms the baselines, demonstrating its effectiveness in identifying semantically relevant concepts within the LMM representations.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the overlap between learnt concepts for different dictionary learning methods used in the CoX-LMM framework, specifically for the LLaVA model. Lower overlap scores indicate better disentanglement between the extracted concepts. The results show that Semi-NMF achieves the lowest overlap, suggesting that it produces more distinct and less entangled concepts compared to other methods like Simple, PCA, and KMeans.
read the caption
Table 2: Overlap evaluation (LLaVA). Lower is better. Best score in bold, second best underlined.

🔼 This table presents the quantitative evaluation results of the proposed CoX-LMM framework and several baseline methods for concept extraction in Large Multimodal Models (LMMs). The evaluation is performed on five different tokens (‘Dog’, ‘Bus’, ‘Train’, ‘Cat’, etc.) using two metrics: CLIPScore (CS) and BERTScore (BS), both measuring the correspondence between the learned concepts and the ground truth. The results are shown for the top-1 activating concept, comparing the performance of the proposed Semi-NMF based approach with baselines such as Random words, Noise images, a simple method, and PCA. Higher scores indicate better performance. The table highlights the superior performance of Semi-NMF, showcasing its effectiveness in capturing semantically meaningful multimodal concepts.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the quantitative results of the experiment. It compares the performance of the proposed CoX-LMM framework against various baselines using two evaluation metrics: CLIPScore (CS) and BERTScore (BS). The evaluation focuses on the top-1 activating concept for five different tokens (‘Dog’, ‘Bus’, ‘Train’, ‘Cat’, and one other). The table highlights the effectiveness of the Semi-NMF based dictionary learning method within the CoX-LMM framework, demonstrating superior performance compared to other methods (Simple, PCA, K-Means, ‘Rnd-Words’, ‘Noise-Imgs’, and using ground-truth captions as a benchmark).
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the quantitative evaluation results of the proposed CoX-LMM framework and several baseline methods on five different tokens (Dog, Bus, Train, Cat, and others). The evaluation metrics used are CLIPScore (CS) and BERTScore (BS), both measuring the correspondence between visual and textual information related to the concepts. The table shows the top-1 activating concept scores for each method, including random word baselines, noise image baselines, simple baselines, and the proposed Semi-NMF approach. The best and second best scores for each token and metric are highlighted in bold and underlined, respectively. Statistical significance analysis is provided in Appendix D.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the quantitative evaluation results of the proposed CoX-LMM framework and several baseline methods on five different tokens. The evaluation metrics are CLIPScore (CS) and BERTScore (BS), both measuring the top-1 activating concept’s correspondence to the test data. The baselines include using random words, noisy images, a simple concept extraction approach, and PCA and K-Means clustering. The table highlights the performance of CoX-LMM using Semi-NMF, demonstrating its superiority in achieving high scores for both metrics across various tokens. Statistical significance details are provided in Appendix D.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.
🔼 This table presents the quantitative results of the proposed CoX-LMM framework and several baselines on five different tokens. For each token, it shows the CLIPScore and BERTScore for the top-activated concept. The baselines used include Rnd-Words (random words), Noise-Imgs (noise images), Simple (a simpler concept extraction method), and PCA and K-Means (other dictionary learning methods). The table highlights the superior performance of the CoX-LMM framework using Semi-NMF (Semi-Non-negative Matrix Factorization) compared to the baselines. Statistical significance between the CoX-LMM and baselines is detailed in Appendix D.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the overlap between the grounded words of concepts learned using different dictionary learning methods within the CoX-LMM framework. Lower scores indicate less overlap, signifying more disentangled concepts. The results are specifically for the LLaVA model. The table shows that Semi-NMF achieves the best balance between learning useful concepts and keeping them distinct. K-Means and Simple perform significantly worse, showing a high degree of overlap.
read the caption
Table 2: Overlap evaluation (LLaVA). Lower is better. Best score in bold, second best underlined.

🔼 This table presents the quantitative results of the proposed CoX-LMM framework and several baselines on five different tokens. It shows the CLIPScore and BERTScore for the top-1 activating concept using different dictionary learning methods (Simple, PCA, K-Means, Semi-NMF). The table compares the performance of the methods to those using random words or noisy images as baselines. The best and second-best scores are highlighted. Details about statistical significance are available in Appendix D.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the quantitative evaluation results for the proposed CoX-LMM framework and several baseline methods. It shows the CLIPScore and BERTScore for the top-1 activating concept on five different tokens (‘Dog’, ‘Bus’, ‘Train’, ‘Cat’, ‘Bus’). The scores are compared across different methods, including a random words baseline, a noise images baseline, a simple baseline, and the proposed Semi-NMF method. Higher scores indicate better performance, with statistically significant differences (detailed in Appendix D) indicating the superiority of the Semi-NMF approach.
read the caption
Table 1: Test data mean CLIPScore and BERTScore for top-1 activating concept for all baselines on five tokens. CLIPScore denoted as CS, and BERTScore as BS. Statistical significance is in Appendix D. Our CoX-LMM framework is evaluated with Semi-NMF as underlying dictionary learning method. Higher scores are better. Best score in bold, second best is underlined.

🔼 This table presents the overlap between concepts for different dictionary learning methods when using the LLaVa model. Lower scores indicate better disentanglement between the extracted concepts. The results show that Semi-NMF generally outperforms other methods, achieving the lowest overlap.
read the caption
Table 4: Overlap evaluation (LLaVA). Lower is better. Best score in bold, second best underlined.
Full paper#