TL;DR#
Current text-to-image models struggle with precise control and complex scene generation. Existing methods lack layout editing capabilities and fine-grained control over attributes. Multi-layer generation shows promise but often lacks fine-grained control and smooth composition. This research addresses these limitations.
The researchers propose a novel two-stage approach. First, they train a diffusion model to generate individual scene components as RGBA images, ensuring transparency control. Second, they introduce a multi-layer compositing process to assemble these components realistically, offering fine-grained control and interactivity. The experiments demonstrate the method’s superiority in generating high-quality and diverse instances and building highly complex scenes with precise control over appearance and location compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on text-to-image generation and scene composition. It significantly advances fine-grained control over image generation, enabling more interactive and flexible image manipulation. The proposed multi-layer approach using RGBA instances opens new avenues for building complex and realistic scenes, pushing the boundaries of current generative models. This work directly addresses limitations in existing text-to-image methods and provides a novel methodology that has strong implications for image editing, virtual world creation, and various other computer vision applications.
Visual Insights#
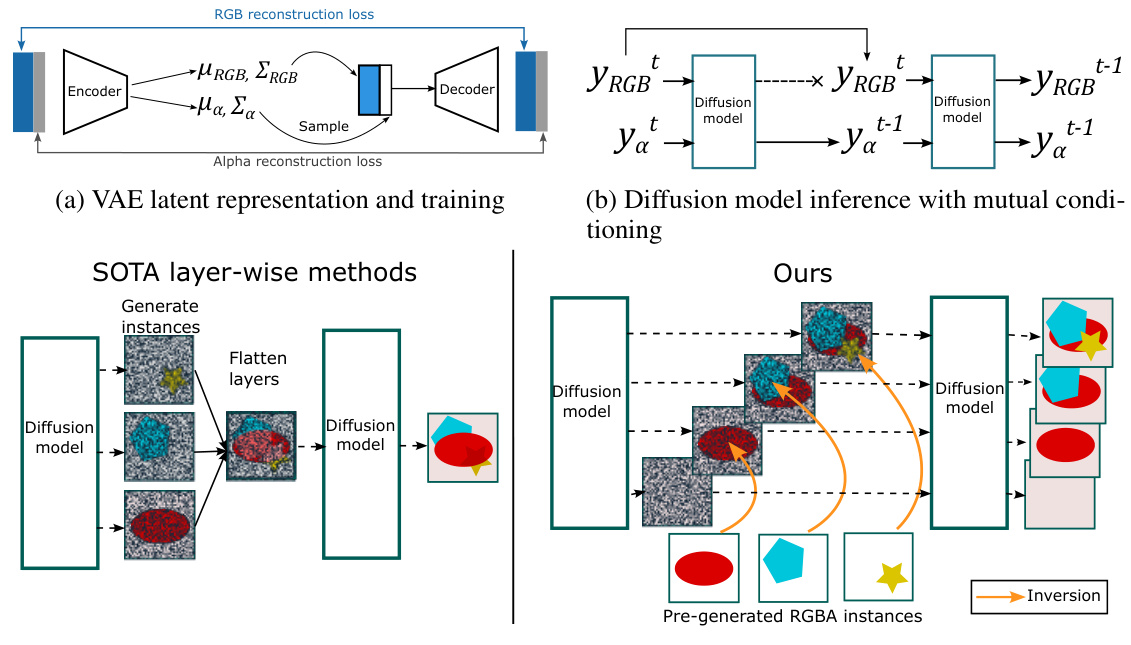
🔼 This figure provides a visual representation of the proposed methodology, including the VAE latent representation and training, the diffusion model inference with mutual conditioning, and the scene composition process compared to state-of-the-art multi-layer methods. Panel (a) shows the VAE architecture and training process, highlighting the disentanglement of RGB and alpha channels for transparency preservation. Panel (b) illustrates the diffusion model inference process, showing the mutual conditioning between RGB and alpha channels during denoising. Panel (c) visually compares the proposed multi-stage scene composition approach with existing multi-layer methods, demonstrating its iterative integration of pre-generated RGBA instances and its ability to achieve fine-grained control over object attributes and scene layout.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This table presents a quantitative comparison of the proposed RGBA generator against several baselines. It evaluates performance using three metrics: Kernel Inception Distance (KID) to assess image quality, Intersection over Union (IoU) to measure the accuracy of generated alpha masks against ground truth, and CLIP Score to evaluate the semantic similarity between generated images and their corresponding captions. The table also includes ablation studies showing the impact of removing key components of the proposed training procedure.
read the caption
Table 1: Quantitative evaluation of our RGBA generator. We measure KID for instance generation quality, IoU (Jaccard) between the alpha masks and ICON segmentation, and CLIP Score for the caption/image similarity. †: our reimplementation, best results are highlighted in bold.
In-depth insights#
RGBA Diffusion#
The concept of “RGBA Diffusion” introduces a novel approach to image generation by leveraging the RGBA color model, which includes an alpha channel for transparency. This allows for the creation of images with intricate transparency effects and precise control over the blending of different image components. Unlike traditional text-to-image models that typically output only RGB images, RGBA diffusion directly generates images with alpha channel information. This is a significant advantage because it simplifies the creation of complex scenes with overlapping objects and fine-grained control over object attributes such as colors, patterns, and transparency. The training process for such a model would require a dataset of images with associated alpha masks, allowing the model to learn the relationship between color and transparency. By generating images with embedded transparency information, this approach reduces the need for post-processing steps such as image matting, thereby improving efficiency and control over the final result. The output of an RGBA diffusion model lends itself well to layer-based composition, enabling more sophisticated scene construction and image editing workflows. The ability to finely control individual object attributes and seamlessly integrate them into composite images is a key innovation in the image generation space, offering improved control, interactivity, and realism compared to existing methods.
Multi-Layer Comp#
A multi-layer composition approach in image generation offers a compelling solution to achieve fine-grained control and flexibility. By generating individual image components (instances) as RGBA images with transparency information, the method allows for precise control over object attributes and placement within a scene. The iterative integration of these instances, creating intermediate layered representations, ensures realistic scene coherence and strong content preservation during scene manipulation. This contrasts with single-layer methods where modifications often require expensive re-generation. The ability to manipulate individual layers provides the capability to perform intricate edits, including displacement, resizing, and attribute adjustments, without the need for complete image regeneration. This makes it particularly effective for creating and modifying images from highly complex prompts with many specific requirements. Moreover, the use of RGBA instances directly supports smooth and realistic scene blending, avoiding the inaccuracies and inconsistencies of post-hoc image-matting techniques. The layered nature of this approach offers a higher degree of control and interactivity, enabling powerful and flexible image manipulation compared to conventional single-stage methods.
Scene Manipulation#
The section on scene manipulation highlights a key advantage of the proposed multi-layer generation framework. By generating individual RGBA instances first, the model offers intrinsic scene manipulation capabilities. This allows for flexible and precise editing of the composed scene, including modifying instance attributes, moving or resizing objects, and even replacing entire instances. This contrasts sharply with single-stage text-to-image methods, where such edits often require complete image regeneration. The ability to easily control object properties and positions without compromising image quality or realism is a significant advancement. The paper showcases this flexibility through examples that demonstrate how the scene can be modified seamlessly and intuitively, showing strong content preservation and high-quality output, even with complex scenes and overlapping objects. The iterative composition process inherently supports editing, allowing the user to selectively manipulate specific layers without affecting the entire image. This advanced level of control opens up possibilities for more interactive and creative applications of text-to-image generation.
Transparency Info#
The concept of incorporating transparency information into image generation models presents a significant challenge and opportunity. Accurate representation of transparency is crucial for realistic scene composition, as it allows for the seamless layering of objects and realistic occlusion effects. Methods for achieving this vary widely. Some approaches use separate alpha channels within the image data itself, while others employ post-processing techniques to extract or generate transparency masks. Training models to understand and generate transparency effectively requires carefully curated datasets, ideally containing images with accurate and consistent alpha information. A key consideration is disentangling the RGB and alpha channels during training to avoid artifacts or inconsistencies. A disentangled approach promotes better control over object appearance and transparency levels, enabling more nuanced and realistic image generation. The effectiveness of different methods hinges on their ability to preserve fine-grained detail within the transparency information and achieve accurate composition. Therefore, further research should focus on developing novel training paradigms and evaluation metrics specifically tailored for generating high-quality images with precise transparency control.
Future Works#
The authors acknowledge the limitations of their current multi-layer generation framework, specifically mentioning the independent generation of instances as a key challenge impacting scene coherence. Future work should focus on developing techniques for conditioned RGBA generation, allowing for the intrinsic generation of coherent scenes. This could involve training models to predict the contextual relationships between instances or developing more sophisticated scene composition algorithms that consider spatial relationships and object interactions. Furthermore, exploring RGBA image editing methods would enhance fine-grained control over generated content. The combination of these advancements could create a more powerful and flexible framework for generating sophisticated, visually appealing, and easily manipulated composite images. The authors also suggest researching new methods to increase computational efficiency, particularly related to the conditional sampling process used in the current model, and investigating how to improve the quality of the alpha masks generated within the instances.
More visual insights#
More on figures

🔼 This figure showcases the ability of the RGBA generator to produce diverse and high-quality images while adhering to detailed instructions embedded in the prompts. Each image demonstrates mastery over style and fine-grained attributes. The top row shows a variety of styles from cartoonish to anime-style, and the bottom row demonstrates realism, precise attributes, and even complex object descriptions.
read the caption
Figure 2: Our model can generalise to different styles and to follow detailed instructions. Top row: ‘a cartoon style frog’, ‘a digital artwork of an anime-style character with long, flowing white hair and large and expressive purple eyes in a white attire’, ‘a stylised character with a traditional Asian hat, with a red and green pattern’, ‘a man with a contemplative expression and a neatly trimmed beard’, Bottom row: ‘a woman with a classic, vintage style, curly hair, red lipstick, fair skin in a dark attire’, ‘a bird mid-flight with brown and white feathers and orange head’, ‘a hand-painted ceramic vase in blue and yellow colours and with a floral pattern’, ‘a woman with short, blonde hair, vivid green eyes, in a white blouse, with a gold necklace featuring a pendant with a gemstone’.

🔼 This figure shows qualitative comparison results of instances generated by different methods. The compared methods are PixArt-a, Stable Diffusion v1.5, the two combined with Matte Anything matting, Text2Layer, LayerDiffusion and the proposed method. The captions used to generate the images are provided in the caption of the figure. The figure demonstrates that the proposed method is capable of generating realistic images following detailed instructions in the caption.
read the caption
Figure 3: Instances generated with the captions: ‘a majestic brown bear with dark brown fur, its head slightly tilted to the left and its mouth slightly open’, ‘an Impressionist portrait of a woman’, ‘a portrait of a young man, depicted in a blend of blue and red tones’.

🔼 This figure shows a high-level overview of the proposed methodology for generating compositional scenes via text-to-image RGBA instance generation. It consists of three main parts: (a) VAE latent representation and training, illustrating how the variational autoencoder (VAE) is trained to learn a disentangled representation of RGB and alpha channels for RGBA images; (b) Diffusion model inference with mutual conditioning, showing how the diffusion model is used to generate RGBA instances by sequentially denoising RGB and alpha latents with mutual conditioning; and (c) Our scene composition process compared to state-of-the-art multi-layer methods, highlighting how the proposed multi-layer composite generation process smoothly assembles pre-generated RGBA instances into complex images with realistic scenes.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual overview of the proposed methodology for generating compositional scenes via text-to-image RGBA instance generation. It consists of three main parts: (a) VAE latent representation and training: Illustrates the variational autoencoder (VAE) used for latent representation learning and training, highlighting the disentanglement of RGB and alpha channels for transparency preservation. (b) Diffusion model inference with mutual conditioning: Shows the diffusion model inference process with mutual conditioning between RGB and alpha channels latents for sequential denoising and improved transparency control. (c) Our scene composition process compared to state-of-the-art multi-layer methods: Contrasts the proposed multi-layer scene composition process with existing methods, emphasizing the sequential integration of pre-generated instances for improved control and realism.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual summary of the proposed methodology for generating compositional scenes. It shows three main stages: 1) VAE latent representation and training for generating RGBA instances, 2) Diffusion model inference with mutual conditioning for generating RGBA instances, and 3) Scene composition process that compares the proposed method to other state-of-the-art multi-layer methods.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual overview of the proposed methodology for generating compositional scenes via text-to-image RGBA instance generation. It consists of three main parts: (a) VAE latent representation and training: Illustrates the process of training a variational autoencoder (VAE) to generate a latent representation of images with transparency information. (b) Diffusion model inference with mutual conditioning: Shows how the diffusion model is used to generate images by iteratively denoising the latent representation with mutual conditioning between RGB and alpha channels. (c) Our scene composition process compared to state of the art multi-layer methods: Compares the proposed multi-layer scene composition process with existing state-of-the-art methods. This part highlights the sequential integration of instances in intermediate layered representations, allowing for fine-grained control over attributes and layout.
read the caption
Figure 1: Overview of key components of our proposed methodology.
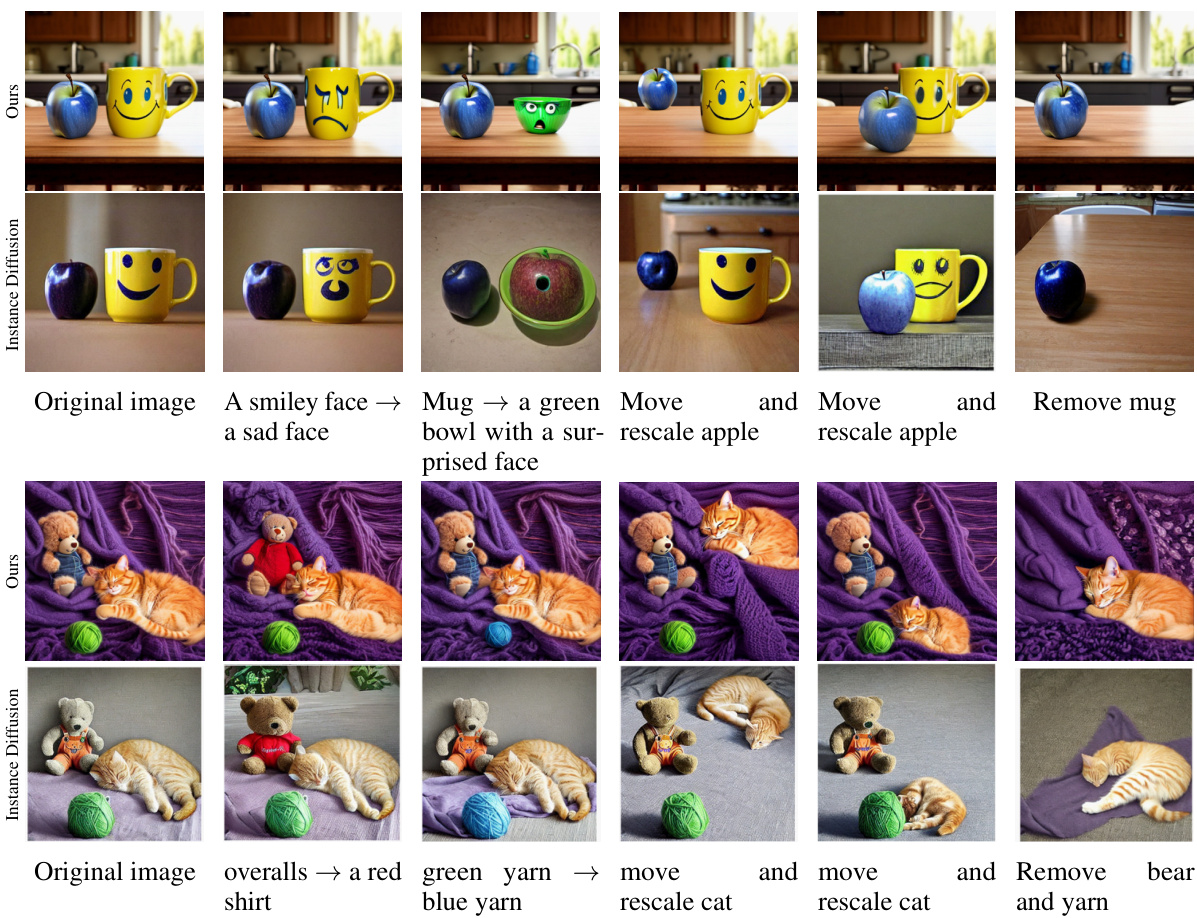
🔼 This figure compares the scene manipulation capabilities of the proposed method with the Instance Diffusion method. It shows several examples of modifications made to a scene, including replacing objects and changing their position. The results demonstrate the proposed method’s superior ability to maintain scene consistency during these edits, unlike Instance Diffusion, which produces more significant changes to the overall scene. This highlights the advantages of using the proposed layer-based approach for fine-grained control and scene manipulation.
read the caption
Figure 6: Visual examples of scene manipulations compared to Instance Diffusion. Our layer-based approach allows to replace instances or modify their positions.

🔼 This figure shows the impact of different training paradigms for the RGBA VAE on generated samples. Three images generated with a diffusion model fine-tuned on different VAE latent spaces are presented. (a) shows images generated using a single KL loss with weight 10e-6, (b) uses 2 separate KL losses each with weight 10e-6, and (c) uses 2 KL losses with weight 1. The differences illustrate how the choice of VAE training affects the quality and contrast of the generated images.
read the caption
Figure 7: Images generated with our LDM fine-tuned in the latent space of VAEs that were trained with a single KL loss with weight 10e – 6 (a), 2 separate KL losses each with weight 10e – 6 (b), and 2 KL losses with weight 1 (c).
🔼 This figure shows a diagram that illustrates the three main components of the proposed methodology: (a) VAE latent representation and training; (b) Diffusion model inference with mutual conditioning; (c) Our scene composition process compared to state-of-the-art multi-layer methods. It provides a visual overview of the system architecture, highlighting the different steps and how they interact with each other. The multi-layer scene composition process is compared against other state-of-the-art methods to highlight its unique characteristics.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 The figure provides a visual representation of the proposed methodology, showcasing three key components: (a) VAE latent representation and training: Illustrates the Variational Autoencoder (VAE) used for latent space representation and its training process, emphasizing disentanglement of RGB and alpha channels for transparency handling. (b) Diffusion model inference with mutual conditioning: Shows the diffusion model inference process with mutual conditioning between RGB and alpha channels during sequential denoising. (c) Our scene composition process compared to state-of-the-art multi-layer methods: Compares the proposed multi-layer scene composition approach with existing methods, highlighting the sequential integration of pre-generated RGBA instances. This contrasts with existing methods that often process all layers simultaneously, showcasing a key differentiator of the proposed approach.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual overview of the proposed methodology, showing three key components: (a) VAE latent representation and training; (b) diffusion model inference with mutual conditioning; and (c) scene composition process compared to state-of-the-art multi-layer methods. It illustrates the two-stage process of the approach, first generating individual instances as RGBA images and then integrating them in a multi-layer composite image. The figure contrasts the proposed method with existing layer-wise methods, highlighting the differences in the generation and composition processes. It visually represents the key concepts, training process, and the overall workflow of the proposed multi-stage generation paradigm.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual overview of the methodology used in the paper. Panel (a) shows the VAE latent representation and training process, highlighting the separation of RGB and alpha channels and the mutual conditioning during inference. Panel (b) illustrates the diffusion model inference with mutual conditioning between RGB and alpha latents, emphasizing the sequential denoising process. Panel (c) compares the proposed scene composition process to state-of-the-art multi-layer methods, showcasing the sequential integration of pre-generated RGBA instances in a multi-layer composite image, highlighting the benefits of this approach in terms of flexibility and control.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual overview of the proposed methodology’s key components. It showcases the VAE latent representation and training, the diffusion model inference with mutual conditioning, and the scene composition process. The scene composition process is compared with state-of-the-art multi-layer methods, highlighting the differences in approach and workflow. Overall, it presents a high-level visual summary of the key steps involved in the novel multi-stage generation paradigm.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a high-level overview of the proposed methodology for generating compositional scenes. It shows three key stages: (a) VAE latent representation and training which focuses on disentangling RGB and alpha channels; (b) Diffusion model inference with mutual conditioning that leverages this disentanglement to generate individual objects as RGBA images; and (c) Scene composition process that contrasts the authors’ approach with other state-of-the-art methods, showcasing the iterative integration of RGBA instances into a multi-layer composite image, achieving fine-grained control over attributes and layout.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure compares the results of scene manipulations using the proposed multi-layer approach versus the Instance Diffusion method. The goal is to showcase the ability to easily replace or reposition objects in the generated scene, maintaining overall scene consistency. The top row demonstrates changes to object attributes and the addition/removal of objects, while the bottom row demonstrates moving and resizing objects. The proposed approach is shown to maintain higher fidelity and better scene coherence compared to the baseline method.
read the caption
Figure 6: Visual examples of scene manipulations compared to Instance Diffusion. Our layer-based approach allows to replace instances or modify their positions.

🔼 This figure shows a schematic overview of the proposed methodology, which consists of three main components: VAE latent representation and training, diffusion model inference with mutual conditioning, and the scene composition process. The VAE is used to create a latent representation of the images, the diffusion model is used to generate images from the latent representation, and the scene composition process is used to combine multiple images into a single composite image. The figure also shows how the proposed methodology compares to state-of-the-art multi-layer methods.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure shows the key components of the proposed methodology. Panel (a) illustrates the VAE latent representation and training process, panel (b) shows the diffusion model inference with mutual conditioning of RGB and alpha channels, and panel (c) compares the scene composition process used in the proposed methodology with state-of-the-art multi-layer methods. The proposed method uses RGBA images for generating isolated scene components and then iteratively integrating them into a multi-layer composite image to build complex scenes.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure compares the results of scene manipulation experiments using the proposed multi-layer approach and the Instance Diffusion method. The images demonstrate the ability to modify scene elements, such as replacing objects or repositioning them, while maintaining overall scene consistency. The proposed approach shows a greater ability to preserve the original scene context during manipulations compared to the Instance Diffusion method.
read the caption
Figure 6: Visual examples of scene manipulations compared to Instance Diffusion. Our layer-based approach allows to replace instances or modify their positions.

🔼 This figure shows a schematic overview of the proposed methodology. (a) shows the VAE latent representation and training. (b) shows the diffusion model inference with mutual conditioning. (c) shows the scene composition process compared to state-of-the-art multi-layer methods. The proposed method uses a multi-stage generation process that first generates individual instances as RGBA images with transparency information, then integrates these instances into a multi-layer composite image according to a specific layout.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure compares the results of scene manipulation using the proposed multi-layer approach against the Instance Diffusion method. It shows that the proposed approach allows for easier replacement of instances and modification of their positions while maintaining a higher degree of scene consistency. The images demonstrate various changes including adding a new item (a ball of yarn), changing an item (the expression of a mug), moving items, and rescaling items.
read the caption
Figure 6: Visual examples of scene manipulations compared to Instance Diffusion. Our layer-based approach allows to replace instances or modify their positions.

🔼 This figure provides a high-level overview of the proposed methodology for generating compositional scenes using RGBA instance generation. It shows three main stages: (a) VAE latent representation and training: This stage focuses on training a Variational Autoencoder (VAE) to learn a latent representation of RGBA images, which are images with an alpha channel representing transparency information. This allows for generating images with fine-grained control over object attributes, including color, pattern, and pose. (b) Diffusion model inference with mutual conditioning: This stage describes the fine-tuning of a diffusion model to generate RGBA images by leveraging mutual conditioning of the RGB and alpha channels in the latent space. This ensures accurate and realistic generation of transparent images. (c) Our scene composition process compared to state-of-the-art multi-layer methods: This stage presents the multi-layer composite generation process that iteratively integrates pre-generated RGBA instances into a composite image. This approach allows for fine-grained control over object appearance, location, and the layout of the scene, resulting in a high degree of control and flexibility compared to existing methods. The figure highlights that the authors’ proposed method offers advantages in terms of controllability, flexibility, and interactivity in scene composition compared to state-of-the-art approaches.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a high-level overview of the proposed methodology in the paper, illustrating the three main components: VAE latent representation and training, diffusion model inference with mutual conditioning, and the scene composition process. The VAE section shows how it learns to represent images in a latent space, disentangling the RGB and alpha channels. The diffusion model section illustrates the inference process with mutual conditioning for generating RGBA images. Finally, the scene composition section compares the proposed multi-layer process with existing state-of-the-art methods, highlighting the advantages of the proposed approach in generating complex scenes with precise control over instance attributes and locations.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure shows an overview of the proposed methodology, which consists of three main components: VAE latent representation and training, Diffusion model inference with mutual conditioning, and scene composition process. The VAE is used to learn a latent representation of RGBA images, which are then used to train a diffusion model. The diffusion model is used to generate images by iteratively denoising the latent representation. The scene composition process is used to combine multiple RGBA instances into a single image.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual representation of the three key components of the proposed methodology. (a) shows the VAE latent representation and training process for generating images with transparency information. (b) illustrates the diffusion model inference process with mutual conditioning of RGB and alpha channels. (c) compares the authors’ scene composition process with state-of-the-art multi-layer methods, highlighting the difference in generating and integrating pre-generated instances as RGBA images into the final scene.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual overview of the proposed methodology for generating compositional scenes. It highlights three key components: (a) The VAE latent representation and training which generates the individual instances as RGBA images. (b) The diffusion model inference with mutual conditioning which ensures control over instance attributes. (c) The scene composition process that smoothly assembles components in realistic scenes, compared to other state-of-the-art multi-layer methods. The figure showcases the multi-stage generation process with the steps involved and how the components are integrated into a final image.
read the caption
Figure 1: Overview of key components of our proposed methodology.

🔼 This figure provides a visual summary of the paper’s methodology, broken down into three stages: (a) VAE latent representation and training, (b) Diffusion model inference with mutual conditioning, and (c) Our scene composition process compared to state-of-the-art multi-layer methods. The diagram shows the steps involved in generating RGBA images, incorporating transparency information, and using a multi-layer composite generation process for building complex scenes. It highlights the differences between the proposed method and existing multi-layer approaches.
read the caption
Figure 1: Overview of key components of our proposed methodology.
Full paper#



















