TL;DR#
Current visually-grounded language models (VLMs) struggle with basic image classification tasks, despite having large numbers of parameters and often utilizing CLIP as a vision encoder. This paper investigates why this is and explores several hypotheses, including differences in inference algorithms, training objectives, and data processing. Their analysis shows that the primary reason is the insufficient amount of classification data used during VLM training. Information necessary for image classification is encoded in the VLM’s latent space but remains inaccessible without adequate training data.
This research proposes a simple method to improve VLMs’ image classification ability by including datasets focused on classification during the training process. The researchers demonstrate that enhancing VLMs with classification data substantially boosts their classification performance on benchmark datasets. Furthermore, this improved performance transfers to other more advanced visual reasoning tasks, which suggests that robust classification is foundational for more complex VLM applications. The enhanced VLM achieves an 11.8% improvement on the newly-created ImageWikiQA dataset, showing the positive impact of this approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with visually-grounded language models (VLMs). It reveals a critical limitation of VLMs—their poor image classification performance—and proposes a straightforward solution: integrating classification data into their training. This finding challenges existing assumptions about VLM capabilities and opens up new avenues for research and development in this rapidly evolving area. The paper’s detailed analysis, open-sourced code and data, and clear explanations make it easily accessible to other researchers.
Visual Insights#

🔼 This figure provides a high-level overview of the paper’s main findings. The left panel shows that various VLMs significantly underperform CLIP on image classification tasks. The middle panel illustrates the hypotheses explored in the paper to understand why VLMs struggle with classification, ultimately concluding that insufficient training data is the primary cause. The right panel demonstrates how integrating classification data into VLM training can improve both classification and overall performance.
read the caption
Figure 1: Overview. (Left) Different visually-grounded language models (VLMs) underperform CLIP in classification by a large margin, though they often use CLIP as a vision encoder. (Middle) We investigate several hypotheses about why VLMs are bad classifiers and find that the main reason is data. Critical information for image classification is encoded in the VLM's latent space but can only be decoded with enough data during VLM training. (Right) Based on our analysis, we improve a VLM by integrating classification data into its training, and find that the improved classification capabilities serve as foundations for more advanced capabilities such as visual question answering.

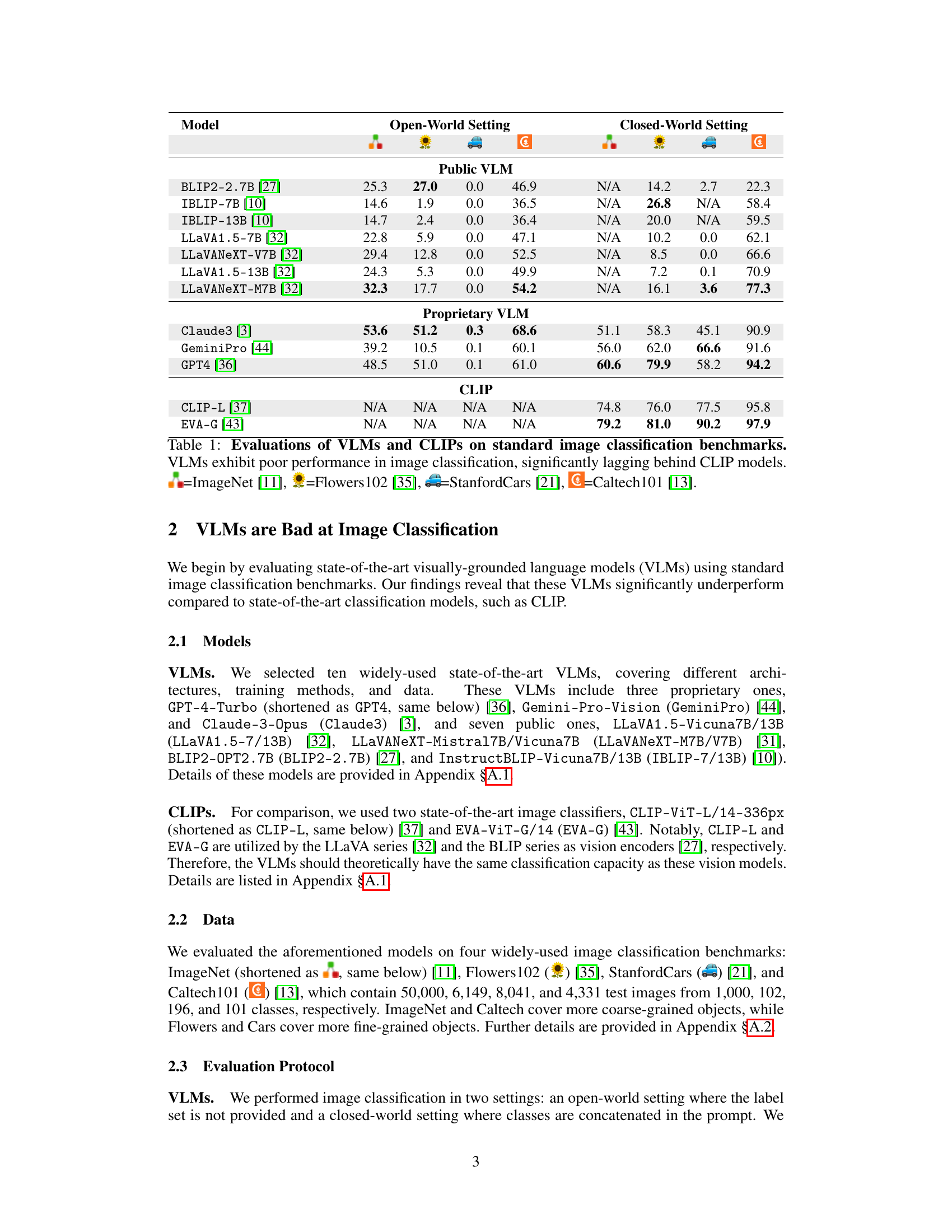
🔼 This table presents the results of evaluating various visually-grounded language models (VLMs) and CLIP models on four standard image classification benchmarks: ImageNet, Flowers102, Stanford Cars, and Caltech101. The table shows that the VLMs significantly underperform compared to the CLIP models, highlighting a key weakness of VLMs in image classification.
read the caption
Table 1: Evaluations of VLMs and CLIPs on standard image classification benchmarks. VLMs exhibit poor performance in image classification, significantly lagging behind CLIP models. =ImageNet [11], =Flowers102 [35], =StanfordCars [21],=Caltech101 [13].
In-depth insights#
VLM Classification Gap#
The “VLM Classification Gap” highlights the surprising underperformance of visually-grounded language models (VLMs) in image classification tasks compared to simpler models like CLIP. This gap is particularly intriguing given that many VLMs utilize CLIP as their vision encoder and possess significantly more parameters. The paper investigates several hypotheses to explain this discrepancy, ultimately concluding that insufficient training data is the primary culprit. Information crucial for effective image classification is present within the VLM’s latent space, but this information can only be reliably accessed and utilized with ample training examples representative of a wide range of classes. This finding emphasizes the critical role of data in shaping VLM capabilities and suggests that enhanced classification performance through data augmentation can serve as a foundation for improving VLMs’ overall capabilities.
Data-Centric Analysis#
A data-centric analysis of visually-grounded language models (VLMs) for image classification would delve into the relationship between the characteristics of training data and model performance. This would likely involve investigating the distribution of classes within the training data, the frequency of class instances, and the diversity of visual features associated with each class. The analysis would examine if any biases in the data (e.g., overrepresentation of certain classes or underrepresentation of others) impact model accuracy. A key aspect would be analyzing whether the information necessary for effective image classification is adequately captured in the VLM’s latent space and can be reliably extracted during inference, with an exploration of whether insufficient or insufficiently diverse training data leads to limitations in the model’s ability to generalize across different images and classes. Furthermore, the correlation between the frequency of exposure to a class during training and the model’s performance on that class would be thoroughly investigated. The results of such an analysis can guide improvements in data curation and training strategies to enhance VLM’s capabilities and reduce biases.
VLM Enhancement#
The paper explores enhancing visually-grounded language models (VLMs) by integrating classification-focused datasets into their training. This data-centric approach addresses the core limitation of VLMs underperforming in image classification tasks. The authors hypothesize that while VLMs encode necessary classification information, sufficient training data is crucial for effective decoding. Experiments demonstrate a strong correlation between class exposure during training and VLM performance. By incorporating classification data, the enhanced VLMs achieve performance comparable to state-of-the-art models. Importantly, this improvement generalizes beyond image classification, improving performance on complex visual question answering tasks. This signifies that bolstering foundational classification abilities is fundamental to unlocking more advanced capabilities in VLMs, highlighting the importance of robust data in model development and the critical interplay between specialized and generalized training for optimal VLM performance.
ImageWikiQA Dataset#
The ImageWikiQA dataset, created by leveraging GPT-4 and Wikipedia, presents a novel approach to evaluating visually-grounded language models (VLMs). Unlike existing datasets that focus primarily on either classification or advanced reasoning tasks, ImageWikiQA bridges this gap by combining both. It consists of multiple-choice questions about ImageNet objects, demanding both object recognition and world knowledge for accurate answers. This design makes it particularly effective for assessing the broader capabilities of VLMs, revealing limitations not apparent through simple image classification. The dataset’s creation process, using GPT-4 to generate questions based on Wikipedia entries for ImageNet classes, ensures that questions are both challenging and relevant. The inclusion of diverse question types further enhances the dataset’s comprehensiveness, moving beyond simple classification and into the realm of knowledge-based reasoning. By integrating classification-focused data into its training, the ImageWikiQA dataset demonstrates the importance of proper data for enhancing VLMs, showcasing how classification serves as a foundation for more sophisticated capabilities. Therefore, ImageWikiQA offers a more holistic evaluation that extends beyond zero-shot classification and allows researchers to assess the robustness and reasoning power of VLMs in more realistic scenarios.
Future Research#
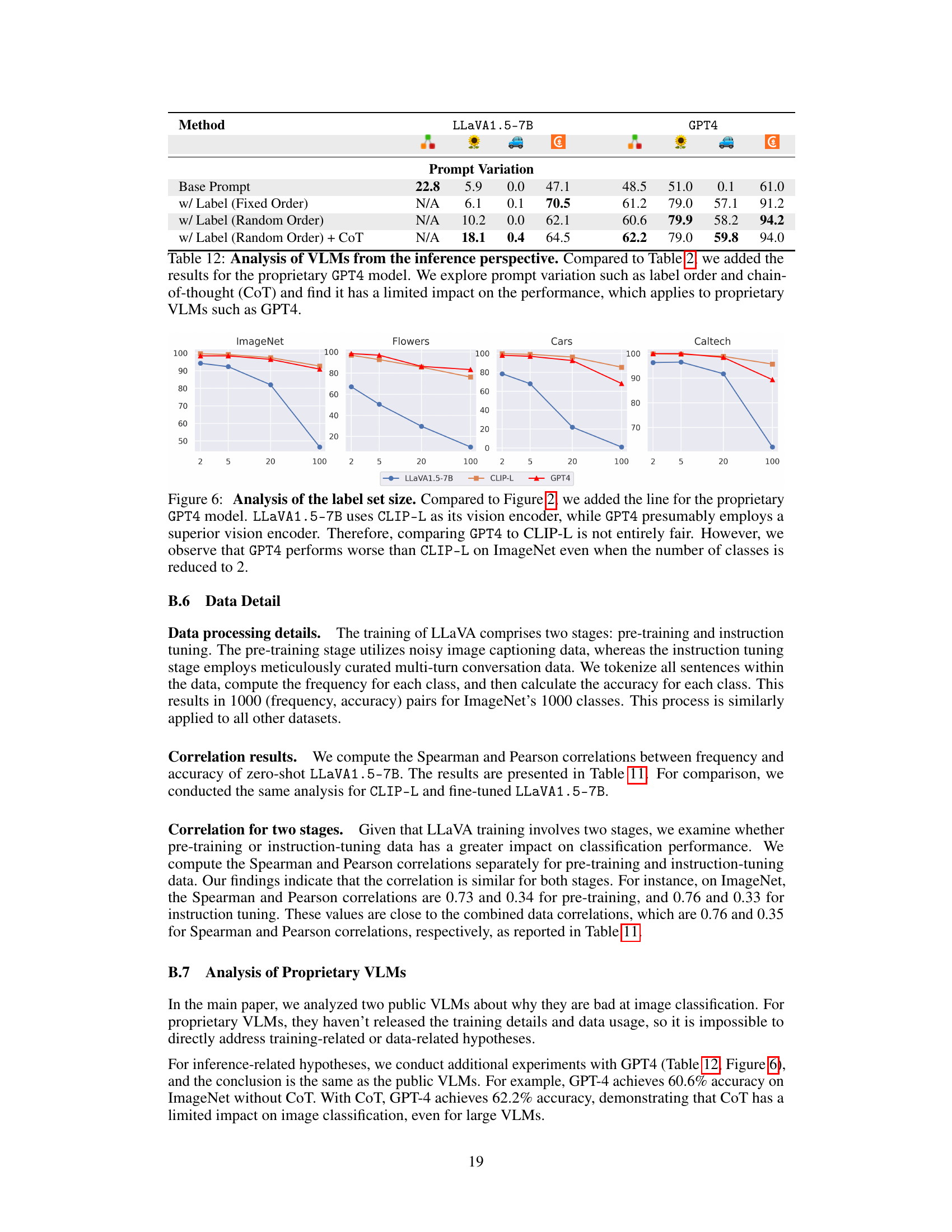
Future research directions stemming from this work on visually-grounded language models (VLMs) could explore several key areas. Improving zero-shot classification performance without extensive fine-tuning is crucial, potentially through more sophisticated data augmentation or architectural modifications. Investigating alternative training objectives beyond the text generation approach is needed to determine if better performance can be achieved with classification-specific losses. Furthermore, a deeper investigation into the role of data diversity in VLM performance is warranted. This includes exploring how the variety and quality of training data impact not only classification accuracy but also generalization to unseen classes and complex reasoning tasks. Finally, there is a need to develop methods that mitigate catastrophic forgetting during fine-tuning. A better understanding of how to balance enhancing specific capabilities (such as classification) with preserving a VLM’s overall general capabilities will be key in making VLMs more versatile and robust.
More visual insights#
More on figures

🔼 This figure shows the effect of reducing the number of classes considered when performing image classification using both visually-grounded language models (VLMs) and CLIP models. As the number of candidate classes decreases (from 100 to 2), the performance gap between VLMs and CLIPs shrinks. This suggests that a key factor in VLMs’ underperformance in image classification is the vast number of classes they need to differentiate, a challenge that lessens with fewer options.
read the caption
Figure 2: Analysis of the label set size. For each image, we randomly sample 100, 20, 5, 2 candidate classes from all the classes. The performance gap between VLMs and CLIPs becomes smaller when the number of classes is reduced. X-axis: number of classes; Y-axis: accuracy (%).

🔼 This figure shows the relationship between the frequency of ImageNet classes in the training data of visually grounded language models (VLMs) and their classification accuracy on those classes. The x-axis represents the frequency of each class (number of times the class appeared in the training data), divided into bins. The y-axis shows the zero-shot classification accuracy of three different models: LLaVA, CLIP, and a fine-tuned version of LLaVA. The plot demonstrates a strong positive correlation between class frequency in the training data and classification accuracy. Classes that appeared frequently during training achieve much higher accuracy than less frequent classes, indicating that sufficient training data is crucial for good VLM performance in image classification.
read the caption
Figure 3: Analysis of VLMs from the data perspective. We study the relation between the ImageNet class frequency in the VLM training data and the VLM's classification performance on those classes. A strong correlation is observed, indicating that data determines VLM classification performance.

🔼 This figure shows the performance of LLaVA1.5-7B and CLIP-L models on ImageNet, Flowers, Cars, and Caltech datasets with varying numbers of candidate classes. The x-axis represents the number of candidate classes randomly selected for each image (100, 20, 5, 2), while the y-axis shows the classification accuracy. The figure demonstrates that as the number of candidate classes decreases, the performance gap between VLMs and CLIPs shrinks, suggesting that the size of the label set influences the performance difference.
read the caption
Figure 2: Analysis of the label set size. For each image, we randomly sample 100, 20, 5, 2 candidate classes from all the classes. The performance gap between VLMs and CLIPs becomes smaller when the number of classes is reduced. X-axis: number of classes; Y-axis: accuracy (%)
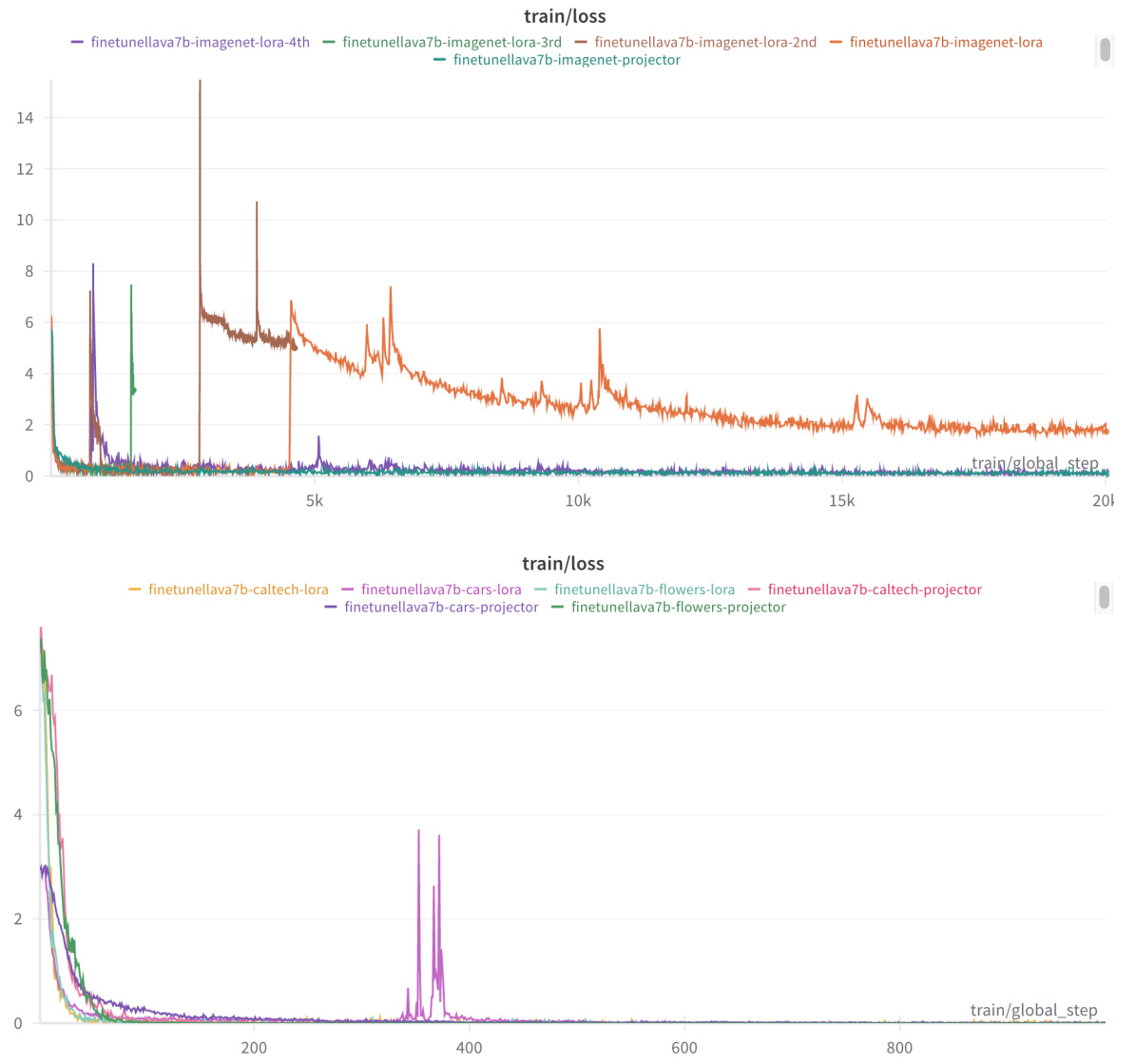
🔼 This figure shows the training loss curves for different fine-tuning methods on various datasets. Fine-tuning only the projector (a smaller part of the model) results in more stable training compared to fine-tuning the entire language model (LLM) with LoRA. The instability in the LLM fine-tuning manifests as sudden spikes in the loss curve. Although these spikes may eventually resolve themselves, fine-tuning the projector consistently shows a smoother, more stable descent in the loss.
read the caption
Figure 5: Fine-tuning only the projector improves numerical stability. (Top) Fine-tuning LLMs with LoRA often results in numerical instabilities, manifesting as spikes in loss (purple, green, brown, orange curves). In contrast, fine-tuning only the projector leads to a consistently steady decrease in loss (teal curve). Despite experimenting with various hyperparameters for ImageNet, the instability remained. (Bottom) Occasionally, the spikes normalize with continued training. Here, we present an example using the StanfordCars dataset (pink curve).
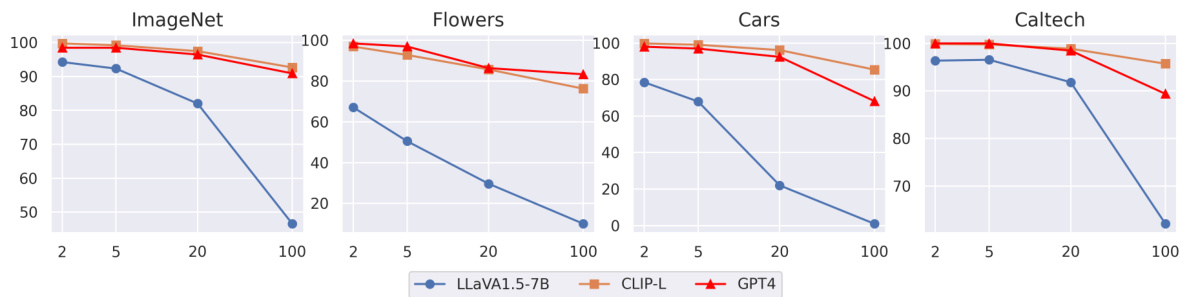
🔼 This figure analyzes how the number of classes provided to the model impacts the performance difference between visually grounded language models (VLMs) and CLIP models in image classification. The x-axis shows the number of classes randomly selected for each image, while the y-axis represents the accuracy. The results show that as the number of classes decreases, the performance gap between VLMs and CLIP reduces, suggesting data scarcity as a major factor in the inferior performance of VLMs.
read the caption
Figure 2: Analysis of the label set size. For each image, we randomly sample 100, 20, 5, 2 candidate classes from all the classes. The performance gap between VLMs and CLIPs becomes smaller when the number of classes is reduced. X-axis: number of classes; Y-axis: accuracy (%).
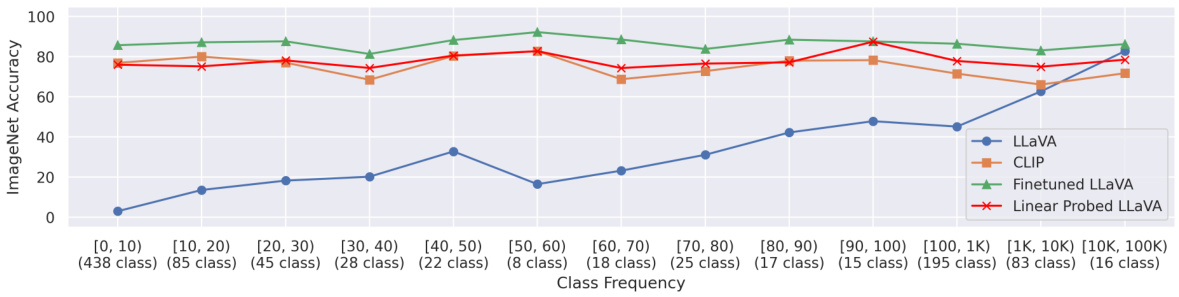
🔼 This figure shows a strong positive correlation between the frequency of ImageNet classes in the training data of visually-grounded language models (VLMs) and their classification accuracy on those classes. The x-axis represents the frequency of each class in the training data, categorized into ranges (e.g., [0,10), [10,20), etc.). The y-axis shows the accuracy of the VLMs on classifying images from those classes. The plot demonstrates that as the frequency of a class in the training data increases, the VLMs’ accuracy in classifying that class also increases. This highlights the importance of data in determining the performance of VLMs for image classification; sufficient training data is crucial for achieving high accuracy.
read the caption
Figure 3: Analysis of VLMs from the data perspective. We study the relation between the ImageNet class frequency in the VLM training data and the VLM’s classification performance on those classes. A strong correlation is observed, indicating that data determines VLM classification performance.
More on tables
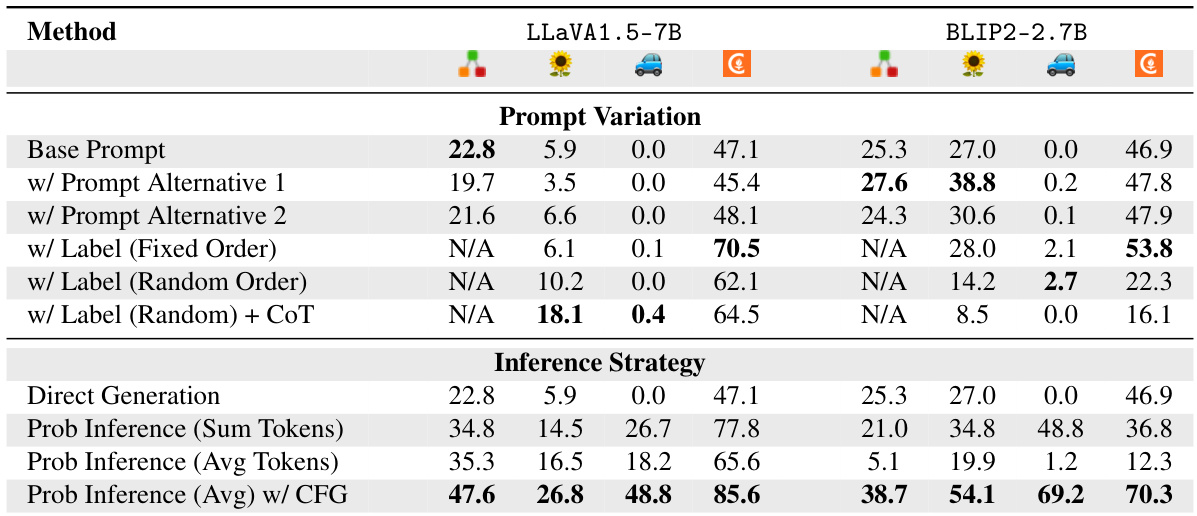
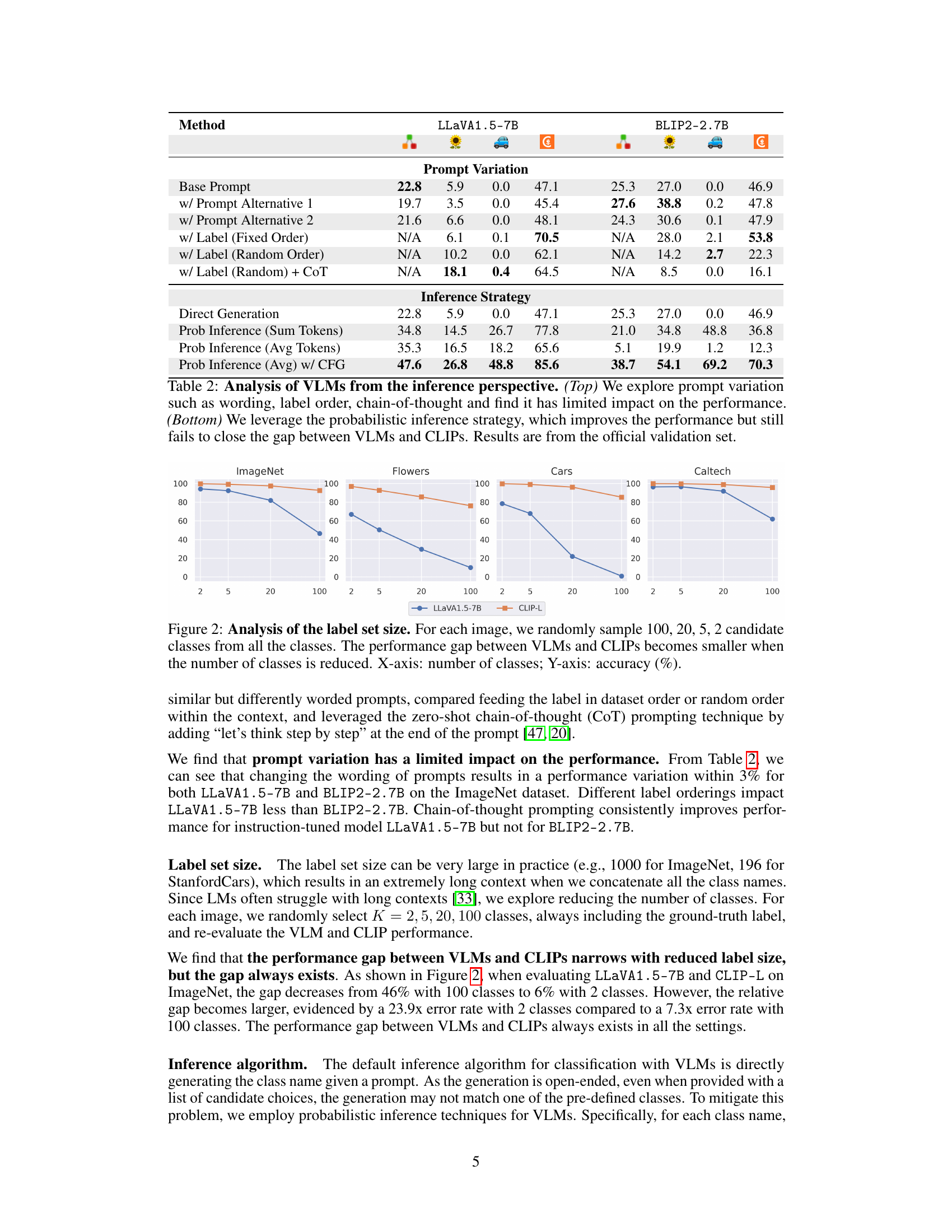
🔼 This table presents the results of experiments that investigate the impact of different inference strategies on the performance of two VLMs (LLaVA1.5-7B and BLIP2-2.7B) on ImageNet classification. The top half shows the effect of varying the prompt wording and order of labels in the prompt. The bottom half explores the use of probabilistic inference techniques to improve the accuracy of the models. Despite these attempts, the VLMs still underperform CLIP.
read the caption
Table 2: Analysis of VLMs from the inference perspective. (Top) We explore prompt variation such as wording, label order, chain-of-thought and find it has limited impact on the performance. (Bottom) We leverage the probabilistic inference strategy, which improves the performance but still fails to close the gap between VLMs and CLIPs. Results are from the official validation set.
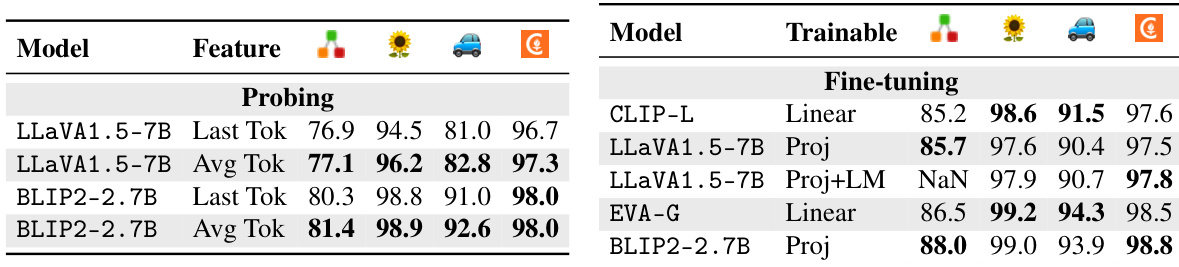
🔼 This table presents the results of probing experiments and fine-tuning experiments performed to analyze the training aspect of VLMs. The left part shows that information crucial for classification is mostly preserved in the VLM’s latent space. The right part demonstrates that fine-tuning VLMs on classification datasets using the text generation objective achieves state-of-the-art classification results, closing the gap between VLMs and CLIP.
read the caption
Table 3: Analysis of VLMs from the training perspective. (Left) We conduct feature probing experiments on the VLM's last layer and find that the information required for classification is mostly preserved in the VLM's latent space. (Right) We fine-tune VLMs on the classification datasets using the text generation objective and find that the text generation training objective is as effective as the traditional cross-entropy for learning classification, which eliminates the VLM-CLIP performance gap, with VLMs now being the state-of-the-art classifier. Results are from the official validation set.

🔼 This table presents the results of fine-tuning a VLM (LLaVA1.5-7B) on different types of data: classification data and captioning data. The goal is to determine if the type of data used for fine-tuning significantly affects the VLM’s performance on image classification tasks (ImageNet, Flowers102, StanfordCars). The table compares the zero-shot performance of LLaVA1.5-7B with the performance after fine-tuning on classification data and captioning data, showing that the quantity of data is more important than the type of data.
read the caption
Table 4: Analysis of data types. We fine-tune the VLM on the caption-focused data generated by GPT4 using the same experimental settings as Table 3 and find that data is the main determining factor for VLM performance, and the data type does not matter much.

🔼 This table presents the results of evaluating various visually grounded language models (VLMs) on the ImageWikiQA dataset. ImageWikiQA is a newly created dataset designed to test both the classification abilities and more advanced reasoning capabilities of VLMs. The results show that even advanced models perform poorly, highlighting the limitations of current VLMs in applying classification knowledge to more complex tasks. The table also shows improved performance when classification data is included in the VLM training.
read the caption
Table 5: Evaluations of VLMs on ImageWikiQA. ImageWikiQA is a multiple-choice question-answering dataset collected by feeding the Wikipedia pages of ImageNet classes to GPT-4. We find that current VLMs perform poorly in answering these questions, suggesting that their poor classification performance is a fundamental limitation for more advanced capabilities. Integrating classification data into VLM training enhances both their classification and overall capabilities.

🔼 This table presents the results of evaluating various visually-grounded language models (VLMs) and CLIP models on four standard image classification benchmark datasets: ImageNet, Flowers102, StanfordCars, and Caltech101. The table shows that the VLMs significantly underperform compared to the CLIP models in terms of classification accuracy, highlighting a major gap in performance despite often using CLIP as a vision encoder. The results emphasize the poor performance of VLMs in image classification tasks.
read the caption
Table 1: Evaluations of VLMs and CLIPs on standard image classification benchmarks. VLMs exhibit poor performance in image classification, significantly lagging behind CLIP models. ImageNet [11], =Flowers102 [35], =StanfordCars [21],=Caltech101 [13].

🔼 This table presents the results of evaluating various visually-grounded language models (VLMs) and CLIP models on four standard image classification benchmark datasets: ImageNet, Flowers102, StanfordCars, and Caltech101. The table highlights the significant underperformance of VLMs compared to CLIP models, demonstrating that even with substantially more parameters, VLMs struggle to achieve comparable accuracy in image classification. The results are categorized by whether the evaluation was in an ‘open-world’ (class labels not provided) or ‘closed-world’ (class labels provided) setting.
read the caption
Table 1: Evaluations of VLMs and CLIPs on standard image classification benchmarks. VLMs exhibit poor performance in image classification, significantly lagging behind CLIP models. =ImageNet [11], =Flowers102 [35], =StanfordCars [21],=Caltech101 [13].

🔼 This table presents the results of evaluating various visually grounded language models (VLMs) and CLIP models on four standard image classification benchmarks: ImageNet, Flowers102, Stanford Cars, and Caltech101. The table highlights the significant underperformance of VLMs compared to CLIP models, even though many VLMs utilize CLIP as their vision encoder. The results are presented as accuracy percentages for each benchmark and model, illustrating the substantial gap in performance.
read the caption
Table 1: Evaluations of VLMs and CLIPs on standard image classification benchmarks. VLMs exhibit poor performance in image classification, significantly lagging behind CLIP models. =ImageNet [11], =Flowers102 [35], =StanfordCars [21],=Caltech101 [13].

🔼 This table shows the performance of three different models (LLaVA1.5-7B, BLIP2-2.7B, and CLIP-L) on four datasets (ImageNet, Flowers, Cars, and Caltech) with varying numbers of candidate classes (2, 5, 20, and 100). It provides a quantitative comparison of the models’ performance as the number of classes considered in the classification task is reduced. The table complements Figure 2 which presents the same data graphically, showing the accuracy of each model in relation to the number of candidate classes considered.
read the caption
Table 9: Analysis of the label set size. This is the table version of Figure 2.

🔼 This table presents the results of a feature probing experiment. The experiment tested different positions within the LLaVA1.5-7B model’s output to determine which position(s) contained the most information relevant for classification. The results indicate that probing the last token or average token yielded significantly better performance (accuracy) compared to other token positions. This suggests that critical information for classification is concentrated towards the end of the model’s processing.
read the caption
Table 10: Probing the last token or the average token results in much better performance than probing other token positions. Experiments are done using LLaVA1.5-7B on the Flowers102 dataset.

🔼 This table presents the results of evaluating various visually-grounded language models (VLMs) and CLIP models on four standard image classification benchmarks (ImageNet, Flowers102, StanfordCars, and Caltech101). The results highlight the significant underperformance of VLMs compared to CLIP models, despite VLMs often utilizing CLIP as their vision encoder and having significantly more parameters. The table reveals the accuracy scores of each model on each benchmark in both open-world and closed-world settings.
read the caption
Table 1: Evaluations of VLMs and CLIPs on standard image classification benchmarks. VLMs exhibit poor performance in image classification, significantly lagging behind CLIP models. ImageNet [11], Flowers102 [35], StanfordCars [21], =Caltech101 [13].

🔼 This table presents the results of experiments conducted to analyze the impact of different inference strategies on the performance of visually-grounded language models (VLMs) in image classification. The top part of the table shows the effect of prompt variations (wording, label order, chain-of-thought prompting) on two different VLMs (LLaVA1.5-7B and BLIP2-2.7B), revealing a limited impact on performance. The bottom half shows results using a probabilistic inference strategy, which improves performance but does not eliminate the gap between VLMs and CLIP (a strong baseline model).
read the caption
Table 2: Analysis of VLMs from the inference perspective. (Top) We explore prompt variation such as wording, label order, chain-of-thought and find it has limited impact on the performance. (Bottom) We leverage the probabilistic inference strategy, which improves the performance but still fails to close the gap between VLMs and CLIPs. Results are from the official validation set.

🔼 This table presents the performance comparison of the original LLaVA1.5-7B model and its further fine-tuned version across three different datasets: TextVQA, POPE (Popular and Adverse subsets), and MMVet. The fine-tuning process did not significantly alter the model’s performance, demonstrating its robustness across diverse tasks.
read the caption
Table 13: Performance of LLaVA1.5-7B before and after fine-tuning on TextVQA, POPE, and MMVet datasets. Fine-tuning resulted in consistent performance across all benchmarks.

🔼 This table presents the results of evaluating various visually-grounded language models (VLMs) and CLIP models on four standard image classification benchmark datasets: ImageNet, Flowers102, StanfordCars, and Caltech101. The table shows that VLMs significantly underperform CLIP models in image classification across all datasets, highlighting a key limitation of VLMs in this fundamental task.
read the caption
Table 1: Evaluations of VLMs and CLIPs on standard image classification benchmarks. VLMs exhibit poor performance in image classification, significantly lagging behind CLIP models. =ImageNet [11], =Flowers102 [35], =StanfordCars [21],=Caltech101 [13].
Full paper#