↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Remote sensing (RS) imagery analysis faces challenges due to data scarcity and class imbalance, especially in spectrums beyond optical imagery. Training large models from scratch is infeasible, and transferring pre-trained models often leads to biased features, where major classes dominate. Fine-tuning or LoRA (Low-Rank Adaptation) methods also exacerbate this issue, resulting in poor performance on minor classes.
To overcome these issues, the researchers propose debLoRA, a new method that works with LoRA variants to create debiased features. This unsupervised learning approach identifies shared attributes between major and minor classes using clustering. It then calibrates the minor class features, moving them toward shared attributes represented by the cluster centers. Experiments on optical and multi-spectrum RS datasets show that debLoRA consistently outperforms previous methods, significantly improving the accuracy of minor classes while maintaining the accuracy of major classes. This demonstrates the efficacy and adaptability of debLoRA in various RS scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical issue of biased representations in remote sensing models, a significant challenge in the field due to data scarcity and class imbalance. By proposing a novel method to address this bias, the research opens up new avenues for improving the performance of remote sensing applications across various spectrums. This work is relevant to current research trends in data-efficient and robust model adaptation, particularly for long-tailed distributions.
Visual Insights#
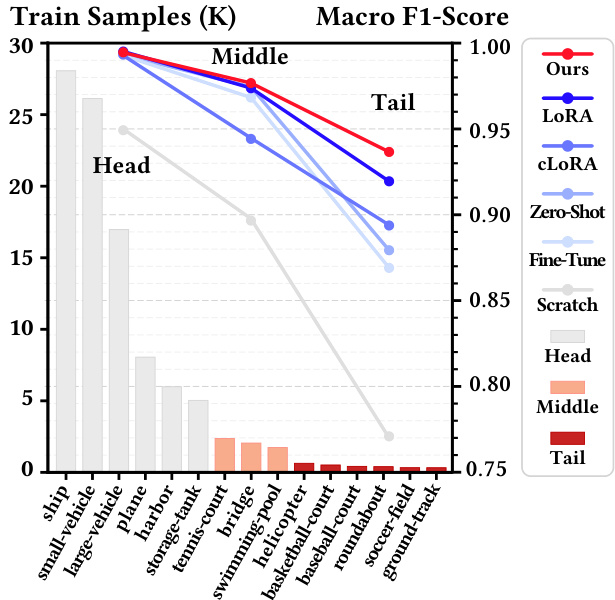
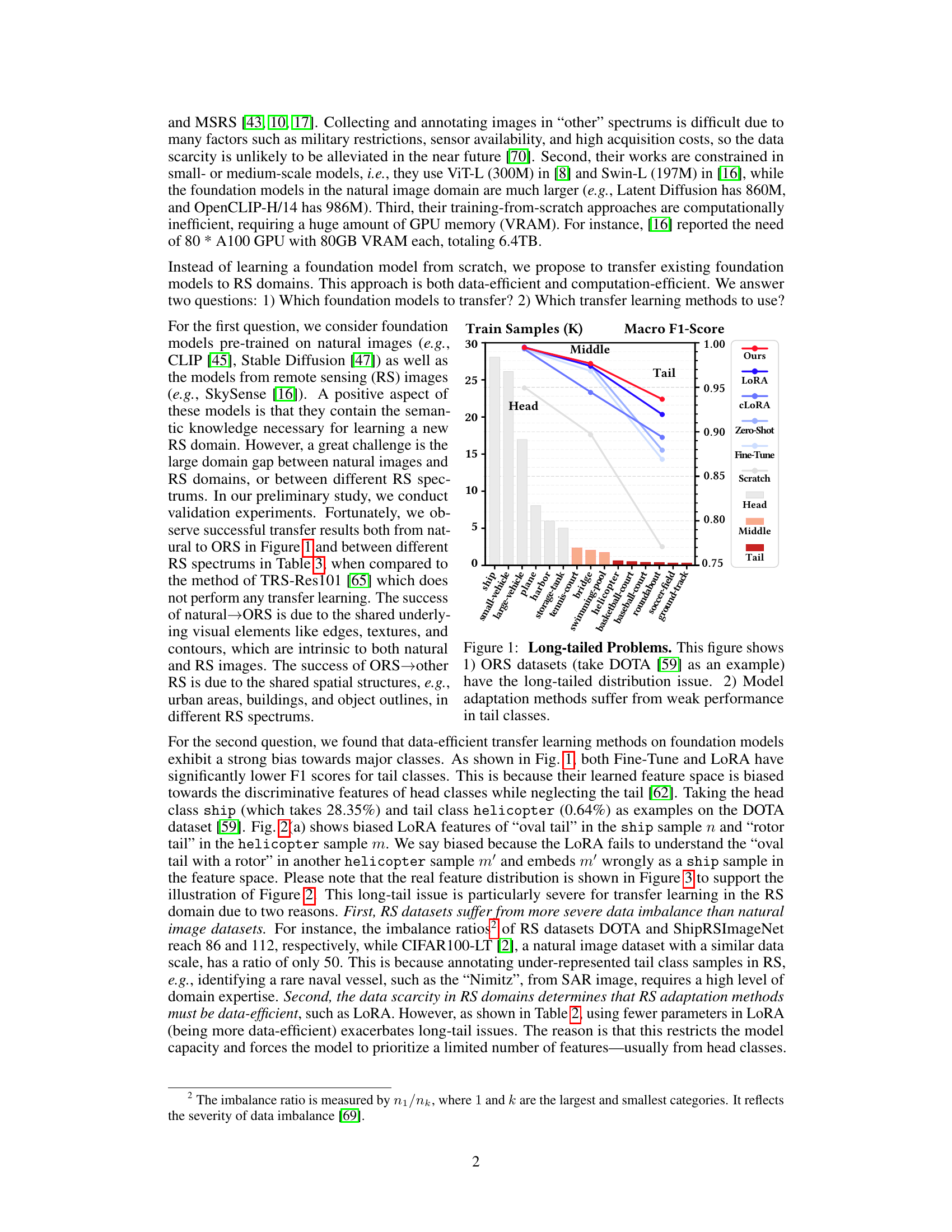
This figure illustrates the long-tailed distribution problem in object detection on Optical Remote Sensing (ORS) datasets, using DOTA as an example. It shows that the number of samples per class is highly imbalanced, with a few head classes dominating the dataset, while many tail classes have very few samples. The figure also demonstrates that common model adaptation methods like fine-tuning and LoRA struggle with the long-tailed distribution, resulting in significantly weaker performance on tail classes compared to head classes. This highlights the challenge of learning unbiased representations from imbalanced datasets, which is the problem addressed in the paper.

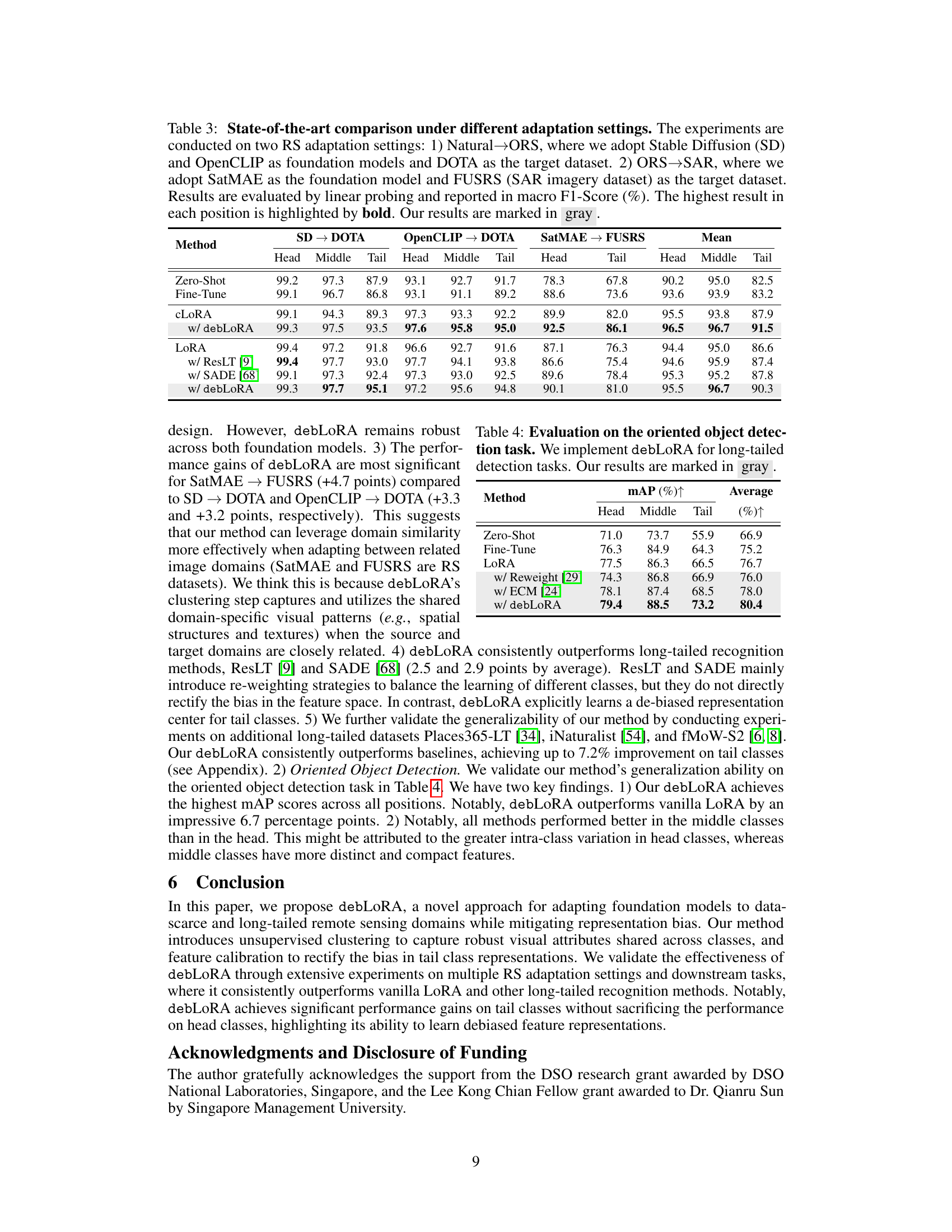
This table presents an ablation study evaluating the effectiveness of the proposed debLoRA method. It compares different model adaptation techniques: Zero-Shot, Fine-Tune, cLoRA, cLoRA with debLoRA, LoRA, and LoRA with debLoRA, in terms of macro F1 score (considering head, middle, and tail classes) and the number of parameters updated during adaptation on the DOTA dataset. The results demonstrate that debLoRA consistently improves the performance on tail classes without significantly affecting the performance on head classes.
In-depth insights#
Debiased LoRA#
The proposed “Debiased LoRA” method tackles the inherent bias in standard LoRA (Low-Rank Adaptation) techniques when applied to long-tailed remote sensing data. Standard LoRA often prioritizes major classes, leading to poor performance on under-represented minority classes. Debiased LoRA addresses this by introducing an unsupervised clustering step to identify shared attributes across classes. This helps diversify the feature representations of minor classes by associating them with attributes shared by major classes, effectively mitigating the class imbalance issue. A calibration step ensures that the features of minority classes are moved toward a de-biased cluster center, which is obtained by weighting cluster centers based on class sample sizes. The resulting de-biased features are then used to train a new LoRA module. This three-stage approach (clustering, calibration, and training) is computationally efficient and demonstrably improves performance on minority classes while preserving the performance on majority classes across various remote sensing tasks and data modalities. The method’s effectiveness is validated by multiple experiments and compared against existing methods in transfer learning settings. The findings underscore the significance of the approach in overcoming the challenge of long-tailed data distributions that are common in remote sensing.
RS Domain Gap#
The RS domain gap presents a significant challenge in adapting models pretrained on natural images to remote sensing data. Differences in imaging mechanisms, spectral characteristics, and data acquisition processes create a substantial disparity between the source and target domains. This gap manifests in varying degrees depending on the specific RS data type (e.g., optical, multispectral, SAR) and its characteristics compared to the natural images used for pretraining. Bridging this gap effectively often requires specialized techniques beyond simple fine-tuning, such as domain adaptation methods or data augmentation tailored to the unique characteristics of RS data. The success of such techniques hinges on identifying and leveraging shared underlying visual features while mitigating the impact of domain-specific differences. Understanding and addressing the RS domain gap is crucial for realizing the full potential of transfer learning in remote sensing applications, enabling efficient model adaptation and improved performance in diverse RS tasks.
Long-Tailed RS#
The concept of “Long-Tailed RS” highlights a critical challenge in remote sensing: data imbalance. Traditional machine learning models struggle with datasets where a few classes dominate (head classes) while many others have significantly fewer samples (tail classes). This imbalance leads to biased models that perform well on head classes but poorly on tail classes, hindering the effective detection and classification of rare phenomena. Addressing this long-tailed distribution in remote sensing is crucial for applications requiring the identification of under-represented objects or events. Solutions involve data augmentation, resampling techniques, and cost-sensitive learning, but they often require extra labeled data which is a considerable challenge in RS. New approaches, like the one in this paper, focus on learning de-biased representations to improve the performance on tail classes without sacrificing the accuracy of head classes, offering a more efficient and promising method for tackling this challenging problem. Unsupervised learning methods, like the one proposed, are particularly useful given the scarcity of labeled data in RS.
Feature Calibration#
Feature calibration, in the context of addressing class imbalance in remote sensing data, is a crucial step in the proposed debLoRA method. It aims to mitigate the inherent bias of pre-trained models towards majority classes by recalibrating the feature representations of minority classes. This calibration process involves strategically moving the feature vectors of under-represented samples closer to a de-biased center. This center is not simply the centroid of minority class samples but rather a weighted average of cluster centers obtained through an unsupervised clustering process. The weighting scheme ensures that the de-biased center is not dominated by majority class attributes, thereby promoting a more balanced representation across classes. This ensures that the model considers features shared among different classes, thereby enriching the features of under-represented classes and reducing the overall bias. The parameter α controls the degree of calibration. A higher α is used for classes with larger imbalances to pull their features closer to the de-biased center, while a smaller α is used for less imbalanced classes to retain their original discriminative information. This adaptive calibration strategy enhances the robustness of the method, ensuring its effectiveness across various datasets and tasks while preventing the over-correction of features in already well-represented classes.
Future of RS Adap.#
The future of remote sensing (RS) adaptation hinges on addressing data scarcity and class imbalance. Current methods, like the debLoRA approach, show promise in leveraging pre-trained models to improve performance on underrepresented classes, but more research is needed. Scaling foundation models effectively to diverse RS spectrums (optical, multispectral, SAR) while maintaining efficiency remains crucial. Unsupervised domain adaptation techniques, similar to debLoRA’s unsupervised clustering approach, will become increasingly important due to the inherent difficulty and high cost associated with extensive annotation of RS data. Future work should explore innovative methods for synthetic data generation and augmentation to enhance data diversity, and investigate new model architectures optimized for RS data characteristics. Finally, the development of more robust evaluation metrics that consider long-tailed distributions is necessary for accurately assessing the effectiveness of RS adaptation methods in real-world applications. Exploring fusion of diverse data sources, including combining RS imagery with other relevant data types, will unlock further improvements. The overarching goal is to create highly adaptable RS models capable of accurate and efficient analysis across various domains and spectrums, thus improving their utility in crucial applications such as environmental monitoring and disaster management.
More visual insights#
More on figures

This figure illustrates the two key steps in the debLoRA method: feature clustering and calibration. Panel (a) shows the biased feature space of the baseline LoRA model, where features of head classes dominate, misrepresenting tail classes. Panel (b) shows how K-means clustering is used to group features irrespective of class labels. The cluster centers represent shared attributes between classes. Panel (c) depicts the calibration step, where tail class features are moved toward a de-biased center, calculated from the cluster centers using a weighting scheme. This results in a de-biased feature space that better represents tail classes. Panel (d) shows examples of real samples and their corresponding positions in the biased and de-biased feature spaces.

This figure visualizes the effect of the debLoRA’s clustering and calibration steps using t-SNE. It shows how the initial biased feature space (a,b), where ship (head) samples dominate, is transformed. K-means clustering groups samples into clusters (c-g) based on shared features regardless of class labels. The de-biased center (h) for the helicopter (tail) class is calculated as a weighted average of cluster centers, pulling the tail samples towards it and mitigating the class imbalance, as illustrated by the arrows.

This figure shows the long-tailed distribution problem in optical remote sensing (ORS) datasets, using DOTA as an example. The left bar chart illustrates the class imbalance, where a few head classes have significantly more samples than tail classes. The right line chart displays the macro F1-score of different model adaptation methods across head, middle, and tail classes. Fine-tuning and LoRA methods, commonly used for adapting pre-trained models, exhibit weak performance in tail classes. This highlights the challenge of adapting models to ORS data and motivates the need for methods addressing this long-tailed distribution issue.
More on tables

This table presents the results of an ablation study comparing different ranks (8, 16, 32, 64) of the LoRA module on a long-tailed classification task. The macro F1 score (a metric considering all classes equally important) is shown for head, middle, and tail classes, along with an overall score. The number of parameters (in millions) for each LoRA rank is also provided. Rows with gray shading highlight the results when the debLoRA method is used.
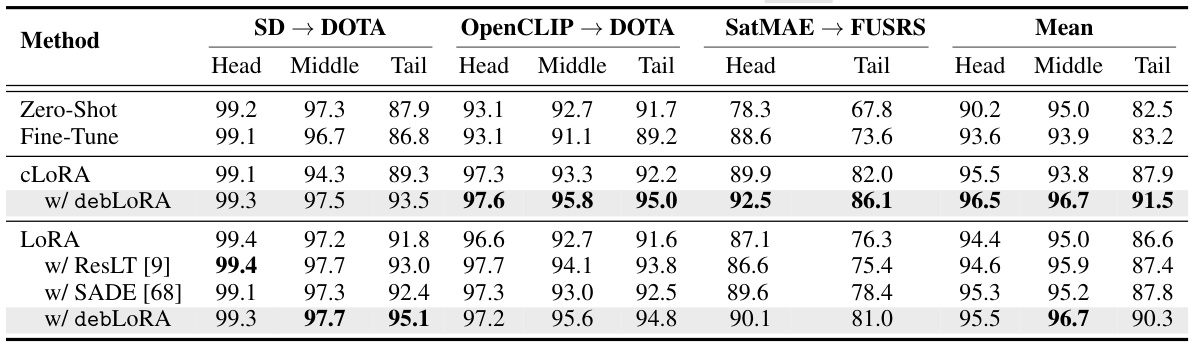
This table compares the proposed debLoRA method with state-of-the-art methods for two remote sensing (RS) adaptation tasks: adapting natural image foundation models to RS (Natural → ORS) and adapting ORS foundation models to SAR (ORS → SAR). The results are presented as macro F1-scores for three class groups (head, middle, and tail classes) and an overall mean, reflecting performance on different data distribution scenarios. The table highlights debLoRA’s superior performance, especially for tail classes (under-represented categories), demonstrating its effectiveness in mitigating class imbalance issues.
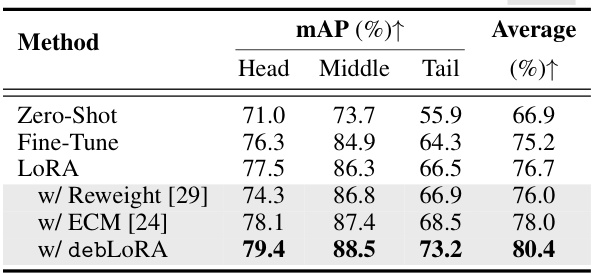
This table presents the results of an oriented object detection task on a long-tailed dataset. The methods compared include several baselines (Zero-Shot, Fine-Tune, LoRA) and other state-of-the-art long-tailed object detection methods (Reweight, ECM). The proposed debLoRA method is shown to improve performance, particularly for tail classes, outperforming other methods across all categories (head, middle, and tail). mAP (mean Average Precision) is used as the evaluation metric. The results highlight the effectiveness of debLoRA in addressing the long-tailed distribution issue in object detection tasks.

This table compares the performance of debLoRA against state-of-the-art methods on two remote sensing image adaptation tasks: adapting natural image foundation models to optical remote sensing (ORS) images (Natural → ORS) and adapting ORS models to synthetic aperture radar (SAR) images (ORS → SAR). The results, evaluated using macro F1-score, show debLoRA’s superiority in handling long-tailed distributions, especially for the challenging tail classes. The table highlights the consistent improvement debLoRA provides across different adaptation settings and foundation models.

This table compares the performance of the proposed debLoRA method against state-of-the-art methods on two remote sensing (RS) adaptation tasks: adapting natural image models to optical RS images (Natural→ORS), and adapting optical RS models to synthetic aperture radar (SAR) images (ORS→SAR). The results, evaluated using macro F1-score, show debLoRA’s superior performance across different adaptation scenarios, especially for the challenging tail classes (classes with fewer samples).
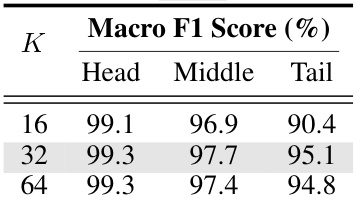
This table presents the ablation study results on the sensitivity of the debLoRA method to the number of clusters (K) used in the de-biasing process. The experiments were conducted on the SD → DOTA adaptation task, and the results are reported in terms of macro F1 score for head, middle, and tail classes. The default value of K=32 is highlighted in gray.
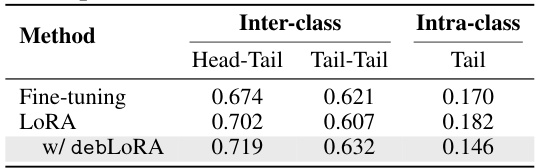
This table presents a quantitative analysis of the learned features by different methods (Fine-tuning, LoRA, and debLoRA) on the DOTA dataset. It shows the inter-class and intra-class distances measured by cosine similarity. Inter-class distances are calculated between head and tail classes, and between tail classes only. Intra-class distance is measured within the tail classes. The results demonstrate debLoRA’s effectiveness in increasing inter-class distances while reducing intra-class distances, especially for tail classes, leading to improved feature separation and classification performance.

This table presents an ablation study comparing different methods for adapting a Stable Diffusion model to the DOTA dataset for object recognition. It shows the macro F1 scores (a measure of classification accuracy) for head, middle, and tail classes (representing classes with varying numbers of samples) using different methods: zero-shot, fine-tuning, cLoRA, LoRA, LoRA with ResLT, and LoRA with debLoRA. The table highlights the performance improvement achieved by the proposed debLoRA method, especially for tail classes, while maintaining comparable performance on head and middle classes, and also shows the number of parameters updated for each method.
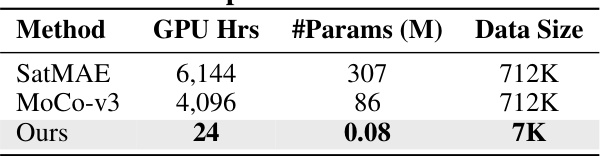
This table compares the proposed debLoRA method with self-supervised learning (SSL) methods such as SatMAE and MoCo-v3 in terms of computational cost (GPU hours), model parameters (#Params), and data size used for training. It highlights the significant reduction in computational cost and data requirements achieved by debLoRA compared to SSL methods.
Full paper#