TL;DR#
Referring Image Segmentation (RIS) aims to identify and segment an object within an image using a textual description. Weakly-supervised RIS (WRIS) presents a challenge as it requires accurate object localization solely from image-text pairs, unlike fully supervised methods. Existing WRIS methods often struggle with localization ambiguity due to using the entire description without focusing on key elements.
The paper introduces PCNet, a novel approach that tackles this issue by mimicking human comprehension. PCNet progressively refines object localization using a large language model to break down the description into key phrases, fed into a Conditional Referring Module (CRM) for multi-stage processing. The innovative Region-aware Shrinking (RaS) and Instance-aware Disambiguation (IaD) losses further enhance localization accuracy by focusing on foreground regions and reducing overlapping predictions. This progressive comprehension method significantly improves results on benchmark datasets, showcasing its effectiveness compared to state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a challenging weakly-supervised problem in referring image segmentation. By mimicking human comprehension, the proposed method enhances localization accuracy, which is crucial for various downstream applications and opens up new avenues for research in weakly supervised learning and visual-linguistic alignment.
Visual Insights#
🔼 This figure illustrates the core idea of the proposed Progressive Comprehension Network (PCNet). It shows how humans progressively refine their understanding of a referring expression to locate the target object. The top row demonstrates this human process using ground truth segmentation masks showing steps of progressive localization based on key cues from the textual description. The bottom row shows the results of the TRIS method and the proposed PCNet, highlighting that PCNet better mimics the human step-by-step refinement and achieves better localization.
read the caption
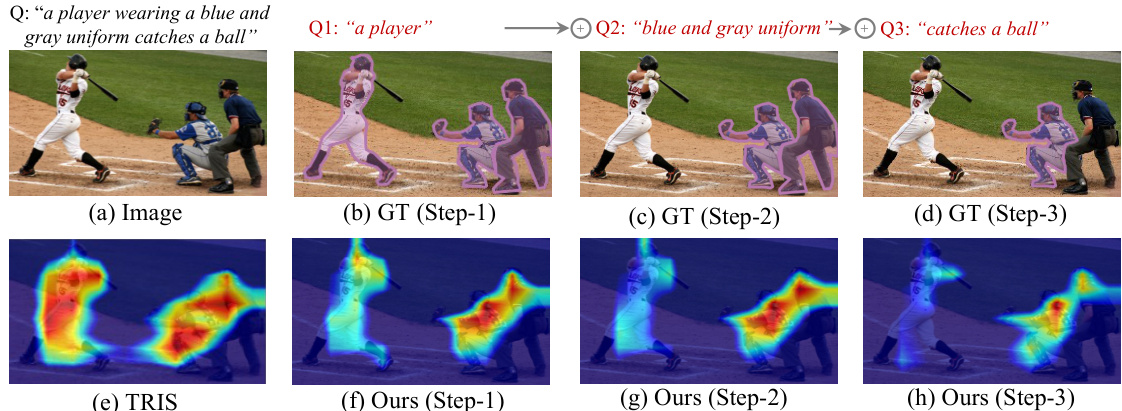
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

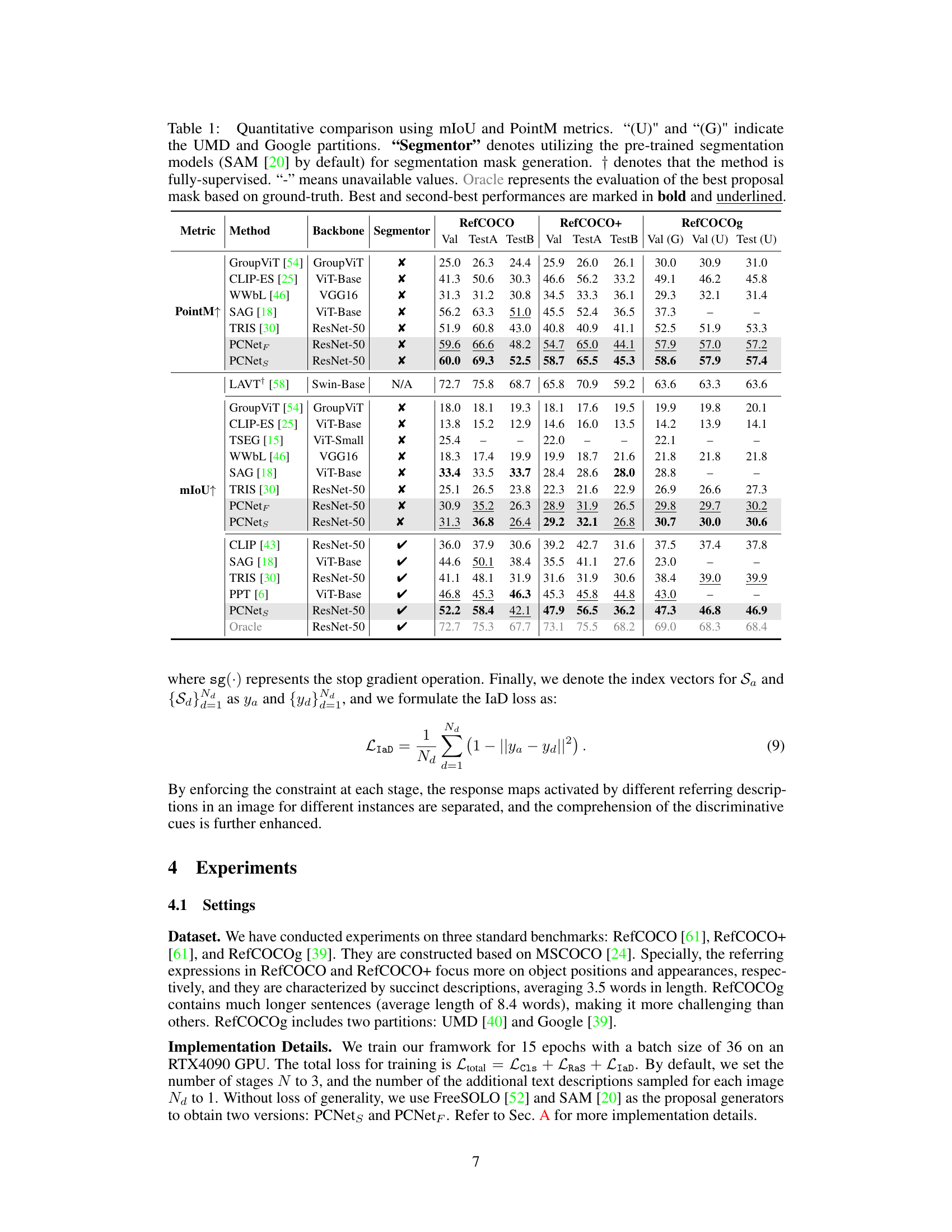
🔼 This table presents a quantitative comparison of different referring image segmentation (RIS) methods using two evaluation metrics: mean Intersection over Union (mIoU) and PointM. The table compares several state-of-the-art (SOTA) methods, including the proposed PCNet method, across three benchmark datasets (RefCOCO, RefCOCO+, and RefCOCOg). It shows the performance of each method using different backbones and segmentors, with fully supervised and weakly supervised methods listed. The ‘Oracle’ row shows the best possible performance, indicating the upper limit achievable.
read the caption
Table 1: Quantitative comparison using mIoU and PointM metrics. \textquotesingle(U)\textquotesingle and \textquotesingle(G)\textquotesingle indicate the UMD and Google partitions. \textquotesingleSegmentor\textquotesingle denotes utilizing the pre-trained segmentation models (SAM [20] by default) for segmentation mask generation. $\dagger$ denotes that the method is fully-supervised. \textquotesingle-\textquotesingle means unavailable values. Oracle represents the evaluation of the best proposal mask based on ground-truth. Best and second-best performances are marked in bold and underlined.
In-depth insights#
Progressive Comprehension#
The concept of “Progressive Comprehension” in the context of weakly supervised referring image segmentation is insightful. It leverages the observation that humans process information step-by-step, rather than holistically. The model mimics this by decomposing the textual description into shorter, more manageable phrases. Each phrase serves as a cue, progressively refining the localization of the target object within the image. This approach is a significant departure from methods that directly process the entire description as a single input. This progressive refinement addresses the ambiguity inherent in weakly supervised learning, where the model lacks precise ground truth masks, by allowing for more focused attention and less reliance on a single, potentially ambiguous, textual representation. The progressive nature also allows the model to refine its understanding through a sequence of progressively more focused visual and textual interactions. By incorporating multi-stage processing and region-aware loss functions, the system tackles the challenge of overlapping object responses and enhances localization precision. Therefore, Progressive Comprehension offers an effective strategy to boost the accuracy and efficiency of weakly supervised referring image segmentation.
Multi-Stage Localization#
Multi-stage localization in referring image segmentation leverages the inherent sequential nature of human comprehension. Instead of directly mapping the entire textual description to the target object, it decomposes the description into smaller, more manageable semantic units. Each stage focuses on specific attributes or relationships mentioned in these units, progressively refining the localization map. This approach is advantageous because it mitigates ambiguity by addressing localization in a coarse-to-fine manner and reduces the impact of noisy or irrelevant information within the complete description. The use of multiple stages allows for a more robust and accurate localization, potentially leading to improved performance, particularly in challenging scenarios with complex scenes or ambiguous descriptions. Careful loss function design is crucial for effective multi-stage learning, often involving mechanisms to guide the model to progressively shrink localization uncertainty over each stage. The progressive refinement of the predicted segmentation masks across different stages demonstrates the efficacy of this method compared to the more typical single-stage approaches.
Region-Aware Loss#
A region-aware loss function in the context of referring image segmentation aims to improve localization accuracy by focusing on specific regions of interest. Unlike global loss functions that consider the entire image, a region-aware approach refines the model’s attention to the target object and its immediate surroundings, thus reducing ambiguity caused by background noise or similar objects. This is often achieved by weighting the loss differently across spatial locations, giving greater importance to pixels within the region of the target. Multi-stage approaches may incorporate region-aware losses at each step, progressively narrowing the area of focus from a coarser to finer level of granularity, mimicking human attention mechanisms. This method is particularly useful in weakly-supervised scenarios, where precise object localization is challenging, and helps resolve challenges such as instances overlapping and background clutter. The success of a region-aware loss function hinges on the effectiveness of its region identification. A robust method for accurately defining and isolating the region is crucial to its performance. Ultimately, it contributes towards more precise segmentation masks by leveraging spatial context effectively.
Instance Disambiguation#
Instance disambiguation in weakly supervised referring image segmentation tackles the challenge of distinguishing between multiple objects in an image when the provided textual description could refer to more than one. The core problem is that the model might produce overlapping response maps for multiple instances, leading to inaccurate localization. Effective instance disambiguation techniques focus on designing loss functions that encourage the model to generate distinct response maps for each target object. This could involve contrasting the positive response map for the target object with negative response maps for other objects or penalizing the model for overlapping activations. Additionally, strategies like incorporating contextual cues (e.g., spatial relationships, object attributes) or multi-stage processing to progressively refine the localization process can help improve disambiguation. Ultimately, successful instance disambiguation enhances the accuracy and reliability of weakly supervised referring image segmentation by precisely identifying the correct object within potentially ambiguous visual contexts.
Future of WRIS#
The future of weakly supervised referring image segmentation (WRIS) hinges on addressing its current limitations and leveraging emerging technologies. Improved handling of complex scenes and ambiguous descriptions is crucial, requiring more robust models capable of discerning subtle visual cues within cluttered backgrounds. More sophisticated language understanding, potentially through larger language models or advanced attention mechanisms, will enable WRIS to better interpret nuanced descriptions and contextual information. Integrating multi-modal learning frameworks that fuse visual and linguistic features more effectively will significantly enhance accuracy and reduce reliance on extensive annotations. Finally, exploring innovative loss functions to guide training towards improved localization and segmentation precision remains a promising research direction, while incorporating domain adaptation techniques would allow WRIS to be easily applied in various domains with limited training data. This holistic approach will unlock WRIS’s full potential for a broad range of applications.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the Progressive Comprehension Network (PCNet). PCNet processes image-text pairs by first using a Large Language Model (LLM) to break down the text description into shorter, more focused phrases. These phrases are then sequentially processed through multiple Conditional Referring Modules (CRMs). Each CRM updates the linguistic embedding and refines the response map for target localization. The process is guided by two novel loss functions: Region-aware Shrinking (RaS) loss, which refines localization progressively from coarse to fine, and Instance-aware Disambiguation (IaD) loss, which addresses ambiguity by differentiating overlapping response maps generated by different descriptions. The final output is a refined response map indicating the segmented target object.
read the caption
Figure 2: The pipeline of PCNet. Given a pair of image-text as input, PCNet enhances the visual-linguistic alignment by progressively comprehending the target-related textual nuances in the text description. It starts with using a LLM to decompose the input description into several target-related short phrases as target-related textual cues. The proposed Conditional Referring Module (CRM) then processes these cues to update the linguistic embeddings across multiple stages. Two novel loss functions, Region-aware Shrinking (RaS) and Instance-aware Disambiguation (IaD), are also proposed to supervise the progressive comprehension process.

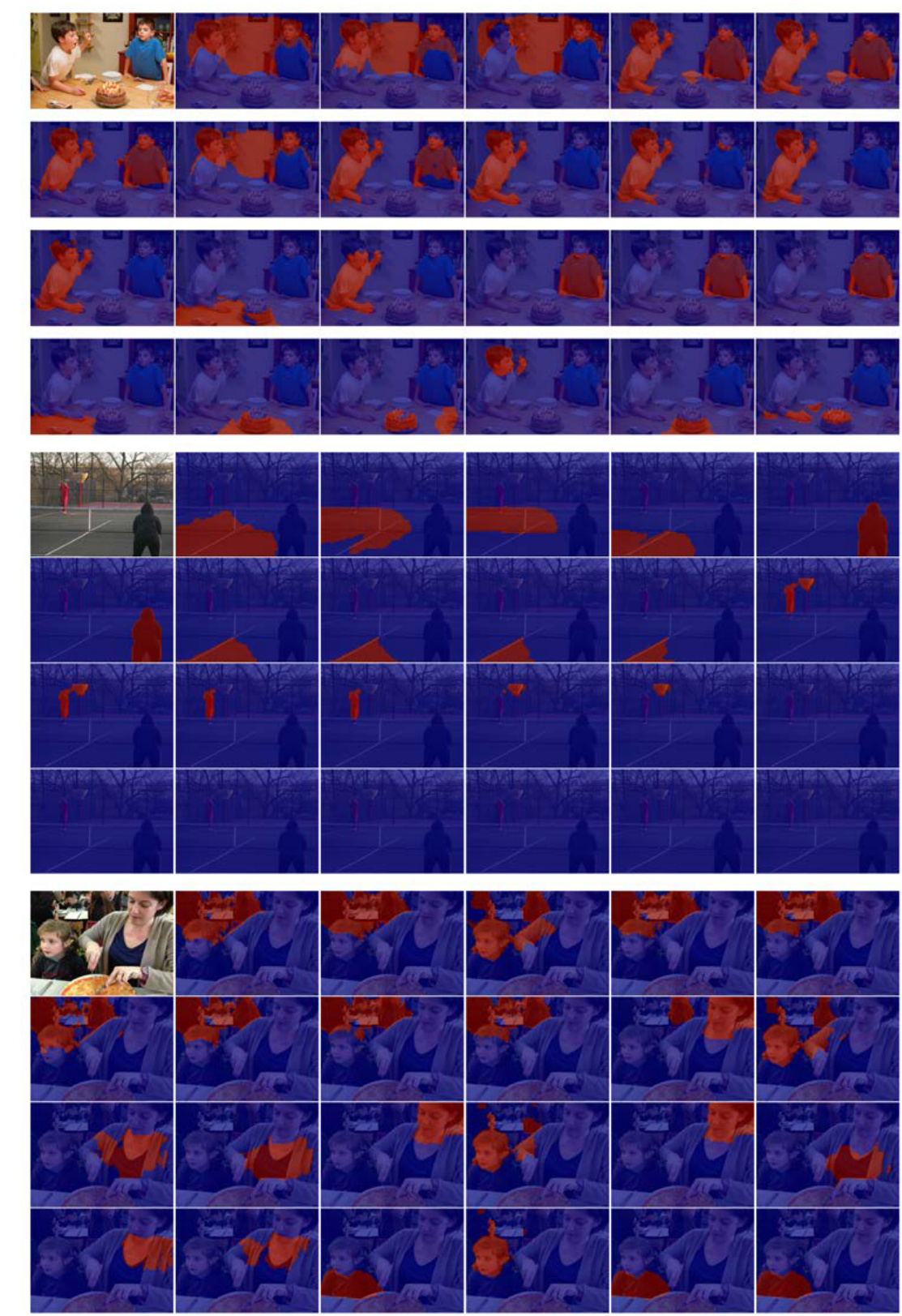
🔼 This figure showcases example results from the proposed Progressive Comprehension Network (PCNet) for referring image segmentation. For several images, multiple referring expressions are given, each attempting to isolate a specific object within the image. The response maps generated by the PCNet model are overlaid on top of each image, with the green markers indicating the location predicted by the model as the peak of the response map. This visual representation effectively demonstrates the model’s ability to accurately locate the target object in different scenarios and complexities.
read the caption
Figure 3: Visual results of our PCNet. The green markers denote the peaks of the response maps.
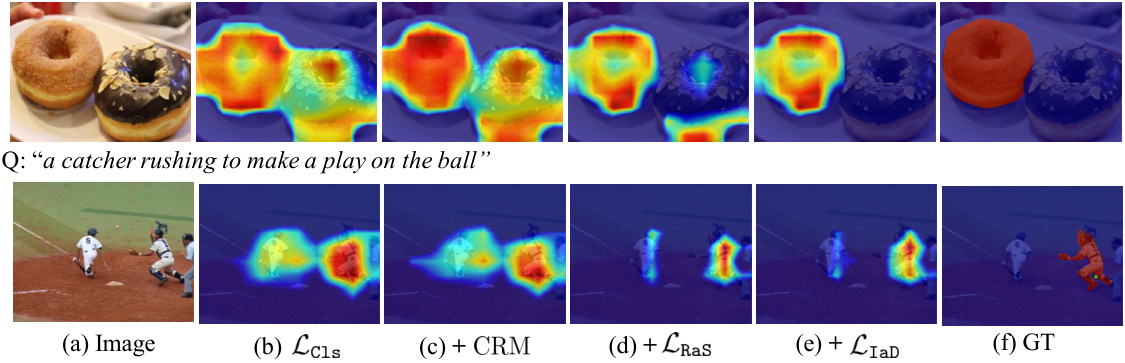
🔼 This figure visualizes the ablation study, demonstrating the effect of each component (Lcls, CRM, LRaS, LIaD) on the response maps generated for referring image segmentation. The results show how each component contributes to improving the accuracy and precision of localization. By comparing the response maps generated with different combinations of components, the importance of each component in refining the localization process is clearly shown. The ground truth mask is also provided as a benchmark for comparison.
read the caption
Figure 4: Visualization of the ablation study to show the efficacy of each proposed component.

🔼 This figure shows visual results of the proposed Progressive Comprehension Network (PCNet) on three example images. Each row presents an image, ground truth mask, and segmentation result produced by PCNet. The green markers in the PCNet results highlight the predicted peaks of the response maps, indicating the model’s ability to accurately locate the target objects within the images. The examples illustrate PCNet’s ability to handle various scenarios, including complex backgrounds, multiple instances, similar appearances, and low-light conditions.
read the caption
Figure 3: Visual results of our PCNet. The green markers denote the peaks of the response maps.

🔼 This figure illustrates the architecture of the Progressive Comprehension Network (PCNet). PCNet uses a Large Language Model (LLM) to break down the input text description into shorter, more manageable phrases, each focusing on a specific aspect of the target object. These phrases are then processed sequentially by a Conditional Referring Module (CRM) which updates the linguistic embeddings to progressively refine the localization of the object. The process is further guided by two novel loss functions: Region-aware Shrinking (RaS) loss to constrain the visual localization in a coarse-to-fine manner, and Instance-aware Disambiguation (IaD) loss to handle ambiguity caused by overlapping response maps.
read the caption
Figure 2: The pipeline of PCNet. Given a pair of image-text as input, PCNet enhances the visual-linguistic alignment by progressively comprehending the target-related textual nuances in the text description. It starts with using a LLM to decompose the input description into several target-related short phrases as target-related textual cues. The proposed Conditional Referring Module (CRM) then processes these cues to update the linguistic embeddings across multiple stages. Two novel loss functions, Region-aware Shrinking (RaS) and Instance-aware Disambiguation (IaD), are also proposed to supervise the progressive comprehension process.

🔼 This figure demonstrates the difference between the proposed method PCNet and existing methods for weakly supervised referring image segmentation. Given an image and a descriptive sentence (a), the goal is to segment the target object (d), which is shown as ground truth (b-d). Traditional methods (e.g., TRIS [30], shown in (e)) directly use the entire sentence for localization, which may lead to inaccuracies. The authors propose that humans process the sentence in a progressive way, breaking it down into smaller cues (Q1-Q3). PCNet mimics this process (f-h), leading to more accurate localization by merging text cues incrementally.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.
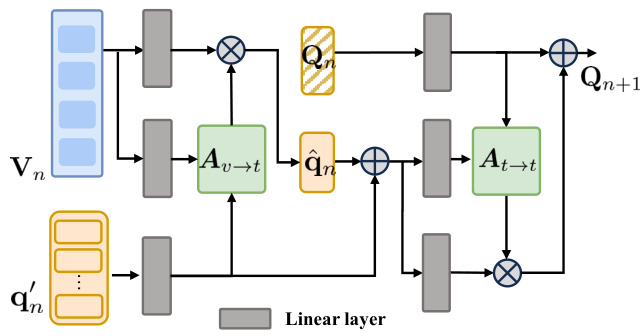
🔼 This figure illustrates the architecture of the Progressive Comprehension Network (PCNet). PCNet processes image-text pairs to perform weakly supervised referring image segmentation. The process begins with an LLM decomposing the input text description into multiple short phrases. These phrases are then fed into a Conditional Referring Module (CRM), which iteratively updates the linguistic embeddings across multiple stages, using both visual and textual information. Two novel loss functions, RaS and IaD, further refine the localization by progressively shrinking the relevant region and disambiguating overlapping responses from different referring texts. The figure shows the data flow and the components (LLM, CRM, RaS, IaD) of the model.
read the caption
Figure 2: The pipeline of PCNet. Given a pair of image-text as input, PCNet enhances the visual-linguistic alignment by progressively comprehending the target-related textual nuances in the text description. It starts with using a LLM to decompose the input description into several target-related short phrases as target-related textual cues. The proposed Conditional Referring Module (CRM) then processes these cues to update the linguistic embeddings across multiple stages. Two novel loss functions, Region-aware Shrinking (RaS) and Instance-aware Disambiguation (IaD), are also proposed to supervise the progressive comprehension process.

🔼 This figure visualizes the progressive localization process of the proposed PCNet model across three stages. Each row displays an image and its corresponding response maps generated at each stage. The response maps highlight the activated regions related to the target object. In the first row, the initial response map is ambiguous, but with the addition of more specific cues (e.g., “with gold necklace”), the localization becomes increasingly accurate and focused on the target. The third row shows that in complex scenarios, the model correctly identifies the target even after adding cues that lead to multiple potential targets. This demonstrates the effectiveness of the proposed progressive comprehension strategy and shows how multiple pieces of information in the text description help refine the target localization throughout multiple stages of processing.
read the caption
Figure 9: Visualization of progressive localization. With the integration of discriminative cues, the identification of target instance gradually improves.

🔼 This figure shows example results of the proposed PCNet model on four different images. Each row shows the results for a single image. The first column shows the original image. Subsequent columns show the response maps generated at different stages of the progressive comprehension process. The green markers indicate the peak activation of the response map, showing where the model believes the target object is located. As the process goes on, the localization becomes more precise and refined.
read the caption
Figure 3: Visual results of our PCNet. The green markers denote the peaks of the response maps.

🔼 This figure visualizes the progressive localization process of the proposed PCNet model across three stages. Each stage incorporates additional target-related textual cues, leading to increasingly precise localization. The first stage shows an ambiguous response map. The second stage refines the localization by incorporating the cue ‘with gold necklace.’ Finally, the third stage integrates all cues, resulting in a less ambiguous and more accurate localization of the target object. This demonstrates how the model progressively refines its localization using increasingly specific textual information.
read the caption
Figure 9: Visualization of progressive localization. With the integration of discriminative cues, the identification of target instance gradually improves.

🔼 This figure demonstrates the progressive comprehension process used in the proposed PCNet method. It shows how a human would typically localize a target object in an image using a given language description by breaking down the sentence into smaller parts and progressively refining the localization. It contrasts this with an existing method that uses the entire description, illustrating the advantages of the PCNet approach.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

🔼 This figure demonstrates the difference between the proposed Progressive Comprehension Network (PCNet) and existing methods for weakly supervised referring image segmentation. It shows that humans tend to break down a sentence into smaller cues to progressively identify a target object, as opposed to existing methods that rely on the entire sentence at once. PCNet mimics this human behavior to improve accuracy.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d)). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

🔼 This figure demonstrates the difference between existing weakly-supervised referring image segmentation (WRIS) methods and the proposed method, PCNet. It uses an example of an image with three players and a caption describing one player performing an action. (a) shows the original image and caption. (b), (c), (d) show progressive localization steps a human might take using cues from the caption. (e) shows the localization output of TRIS, a state-of-the-art WRIS method, showing erroneous activation of all three players. (f), (g), (h) show the progressive localization produced by the PCNet, accurately localizing the target player step-by-step.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d)). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

🔼 This figure demonstrates the difference between existing weakly supervised referring image segmentation methods and the proposed method (PCNet). The existing method (TRIS) directly uses the full text description to localize the target object, while PCNet breaks down the description into smaller cues and progressively refines the localization, mimicking how humans comprehend and locate objects in an image. The figure showcases this process through several stages, highlighting the improvement in localization accuracy achieved by PCNet.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d)). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

🔼 This figure shows an example of referring image segmentation (RIS). Given an image and a language description, the goal is to locate and segment the target object. Existing methods often use the entire description at once, while humans tend to break the description into smaller parts and process them sequentially. The figure illustrates this by showing how the ground truth mask (GT) is progressively refined (Step 1, Step 2, Step 3), and how the proposed method (Ours) mimics this human-like process, achieving more accurate localization than a baseline method (TRIS).
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

🔼 This figure showcases the visual results obtained using the Progressive Comprehension Network (PCNet). The images display the localization process across different stages. Each image shows a target object identified in the image, with green markers indicating the peak activation points in the response maps generated by the PCNet. This demonstrates the PCNet’s ability to progressively refine the localization of the target object. The visualization highlights the network’s ability to accurately locate target objects even in complex scenes with several possible objects that might match the textual description.
read the caption
Figure 3: Visual results of our PCNet. The green markers denote the peaks of the response maps.

🔼 This figure shows example results from the PCNet model. Each row presents an image with a corresponding referring expression. The model’s response maps are visualized as heatmaps for each stage of processing. Warmer colors (red/yellow) indicate higher activation and greater confidence in the predicted region. The green markers highlight the peak activation point within the response map, representing the model’s most likely localization of the object described in the referring expression. The results illustrate the progressive refinement of localization accuracy as the model processes the multiple stages of its comprehension.
read the caption
Figure 3: Visual results of our PCNet. The green markers denote the peaks of the response maps.
🔼 This figure demonstrates the difference between existing weakly supervised referring image segmentation (WRIS) methods and the proposed method. Existing methods use the entire sentence to locate the target, which can lead to ambiguity. Humans, however, often break down the sentence into smaller, relevant phrases and use these phrases sequentially to locate the object. This figure illustrates this process, showing how the proposed Progressive Comprehension Network (PCNet) mimics the human approach by progressively refining the localization through multiple stages.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.

🔼 This figure demonstrates the progressive comprehension process used in the proposed PCNet method for weakly supervised referring image segmentation (WRIS). It contrasts the direct localization approach of existing methods (TRIS) with the step-by-step, cue-based approach of humans and PCNet. The image shows how the model breaks down a sentence into key cues (Q1-Q3) to progressively narrow the focus towards the target object, significantly improving visual localization compared to the direct approach. Each step in the process is depicted in terms of ground truth (GT) and model output for both the existing TRIS method and the proposed PCNet method.
read the caption
Figure 1: Given an image and a language description as inputs (a), RIS aims to predict the target object (d). Unlike existing methods (e.g., TRIS [30] (e) – a WRIS method) that directly utilize the complete language description for target localization, we observe that humans would naturally break down the sentence into several key cues (e.g., Q1 – Q3) and progressively converge onto the target object (from (b) to (d). This behavior inspires us to develop the Progressive Comprehension Network (PCNet), which merges text cues pertinent to the target object step-by-step (from (f) to (h)), significantly enhancing visual localization. denotes the text combination operation.
More on tables
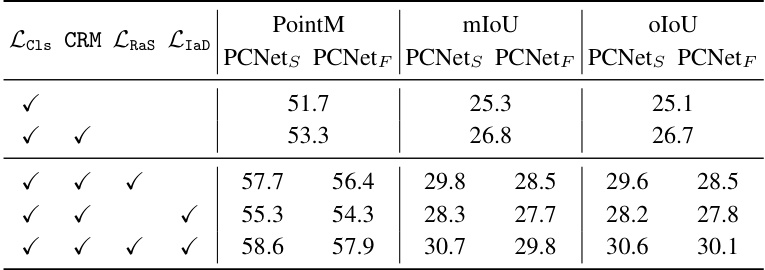
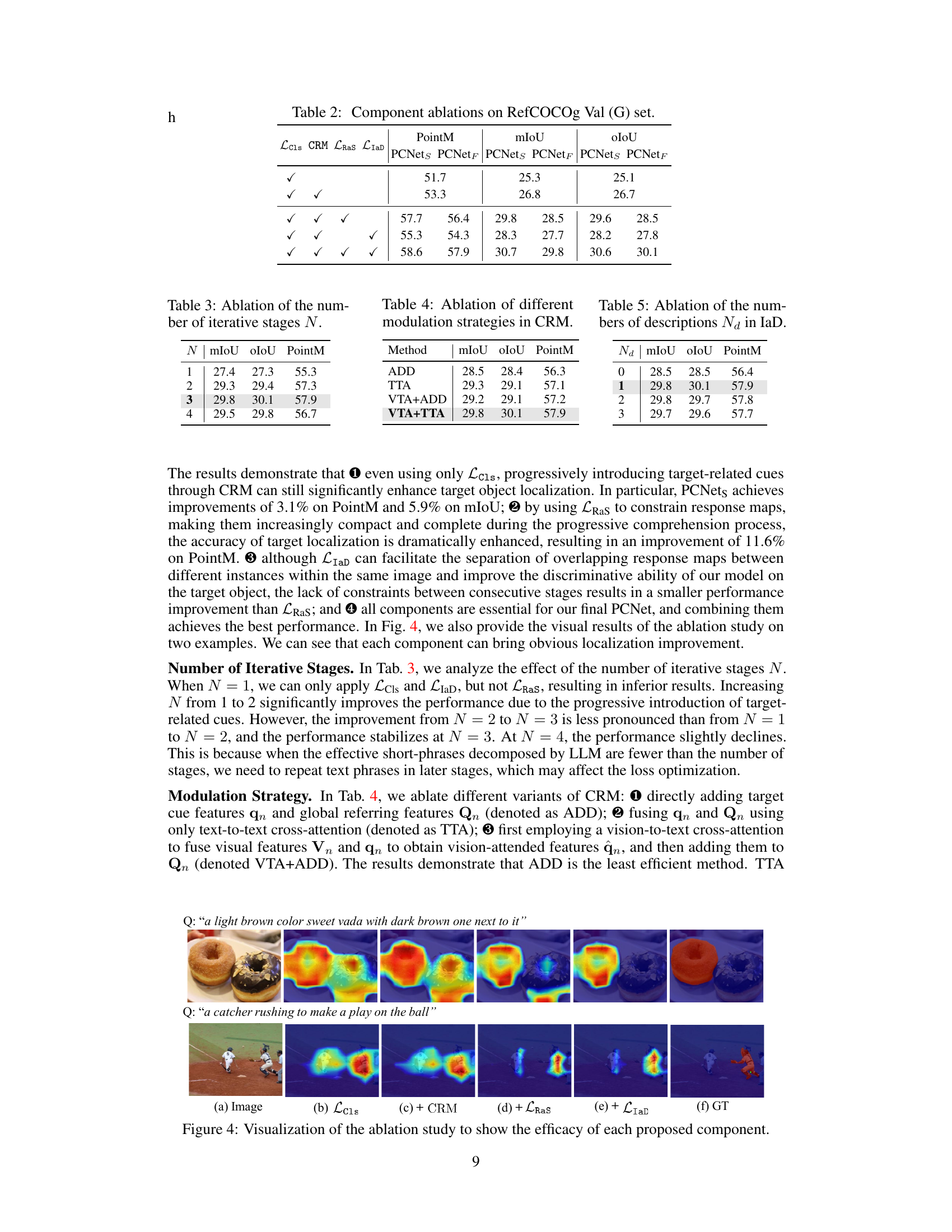
🔼 This table presents the ablation study of the proposed PCNet model on the RefCOCOg dataset’s Val (G) set. It shows the impact of each component (classification loss, CRM, RaS loss, IaD loss) on the model’s performance using PointM, mIoU, and oIoU metrics. Each row represents a different combination of components, allowing for analysis of their individual and combined effects.
read the caption
Table 2: Component ablations on RefCOCOg Val (G) set.
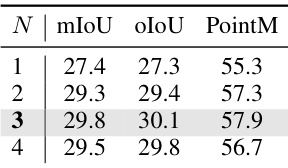
🔼 This table presents the ablation study on the number of iterative stages (N) in the proposed PCNet model. It shows the impact of varying N (1, 2, 3, and 4) on the performance metrics mIoU, oIoU, and PointM. The results demonstrate how the progressive comprehension process affects the accuracy of the model at different stages. The best performance is observed at N=3, indicating the optimal number of stages for progressive comprehension in this model architecture.
read the caption
Table 3: Ablation of the number of iterative stages N.
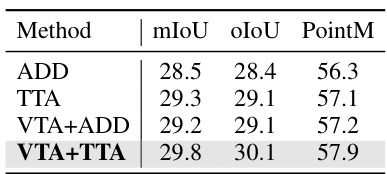
🔼 This table presents the ablation study of different modulation strategies used in the Conditional Referring Module (CRM) of the proposed Progressive Comprehension Network (PCNet). The strategies compared are ADD (direct addition of target cues and global features), TTA (fusion using only text-to-text cross-attention), and VTA+ADD/VTA+TTA (vision-to-text cross-attention followed by addition/text-to-text cross-attention). The results show the performance (mIoU, oIoU, and PointM) achieved using each strategy on the RefCOCOg Val (G) dataset.
read the caption
Table 4: Ablation of different modulation strategies in CRM.
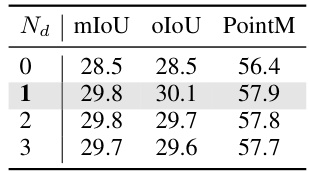
🔼 This table presents the ablation study on the number of iterative stages (N) in the proposed PCNet model. It shows the impact of varying N (1, 2, 3, 4) on the model’s performance, as measured by mIoU, oIoU, and PointM metrics. The results demonstrate the effect of the progressive comprehension process on localization accuracy.
read the caption
Table 3: Ablation of the number of iterative stages N.
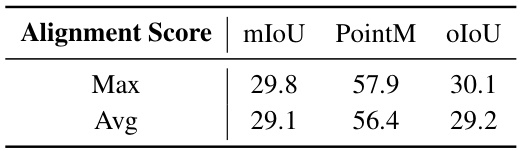
🔼 This table presents an ablation study comparing different methods for calculating alignment scores in the region-aware shrinking (RaS) loss function. It shows the effect of using either the maximum or average alignment score for measuring the uncertainty of target object localization at each stage. The results, measured by mIoU, PointM, and oIoU, indicate which scoring method yields better performance in the localization task.
read the caption
Table 6: Different criterions for alignment score measurement in Lras.

🔼 This table presents an ablation study comparing two different methods for calculating the alignment score in the Region-aware Shrinking (RaS) loss function: using the maximum value versus the average value of the response map in each proposal. The results show that using the maximum value provides better performance in terms of mIoU, PointM, and oIoU metrics.
read the caption
Table 6: Different criterions for alignment score measurement in Lras.
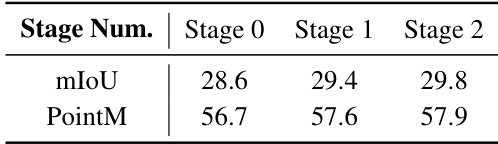
🔼 This table shows the quantitative comparison of the proposed PCNet model at different stages (Stage 0, Stage 1, and Stage 2). It displays the mIoU (mean Intersection over Union) and PointM (a localization-based metric) scores for each stage. The results demonstrate the progressive improvement of the model’s performance as more target-related textual cues are integrated during the multi-stage processing. Higher scores in both mIoU and PointM indicate better localization and segmentation accuracy.
read the caption
Table 8: Comparison between different stages.
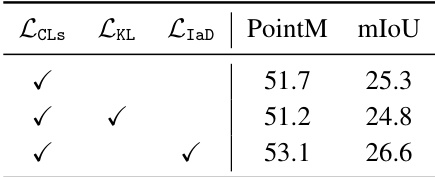
🔼 This table presents the ablation study comparing the performance of the proposed Instance-aware Disambiguation (IaD) loss against a Kullback-Leibler (KL) divergence based loss. It shows the impact of each loss function on the PointM and mIoU metrics, demonstrating the effectiveness of IaD in improving localization accuracy.
read the caption
Table 9: Comparison between IaD loss and KL loss.
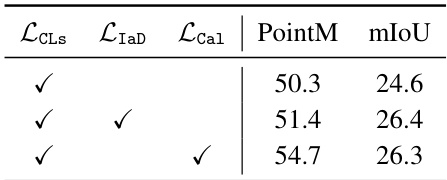
🔼 This table presents the ablation study comparing the performance of the proposed Instance-aware Disambiguation (IaD) loss against a calibration loss (Lcal) from a prior work (TRIS). The comparison uses three loss functions: the classification loss (LCLS), IaD, and Lcal. The results, measured by PointM and mIoU metrics, show the impact of each loss on the model’s performance in the weakly-supervised referring image segmentation task.
read the caption
Table 10: Comparison between IaD loss and calibration loss Lcal.
Full paper#