TL;DR#
Large Language Models (LLMs) are powerful but computationally expensive. Structured pruning is a promising technique to reduce their size and cost, but restoring performance after pruning remains a major challenge. Existing methods often lead to significant performance degradation or are computationally costly.
SlimGPT tackles this by using the Optimal Brain Surgeon (OBS) framework with two key innovations: Batched Greedy Pruning accelerates near-optimal pruning for attention heads and feed-forward networks (FFNs) and Incremental Pruning Ratio addresses the limitations of layer-wise pruning by employing a non-uniform pruning strategy. Experiments show SlimGPT significantly outperforms existing methods on various benchmarks, achieving state-of-the-art results in LLM structured pruning.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces SlimGPT, a novel structured pruning method that significantly improves the efficiency of large language models (LLMs) without substantial performance loss. This addresses a critical challenge in deploying LLMs, which are often computationally expensive. The proposed method is efficient and effective, outperforming existing techniques and paving the way for more efficient and accessible LLMs. This research also explores non-uniform pruning strategies to minimize performance degradation further.
Visual Insights#

🔼 This figure illustrates the process of Batched Greedy Pruning, a method used to efficiently prune attention heads in large language models. It shows how the algorithm reorders columns of the weight matrix (W) and the inverse Hessian matrix (H⁻¹), performs a grouped Cholesky decomposition, and then prunes columns based on calculated errors. Finally, it shows how the columns are restored and compensated for after pruning.
read the caption
Figure 1: The figure illustrates Batched Greedy Pruning on attention blocks, where W is a output matrix and H is the corresponding Hessian. Different colors represent distinct attention heads and gray indicates the pruned weights.
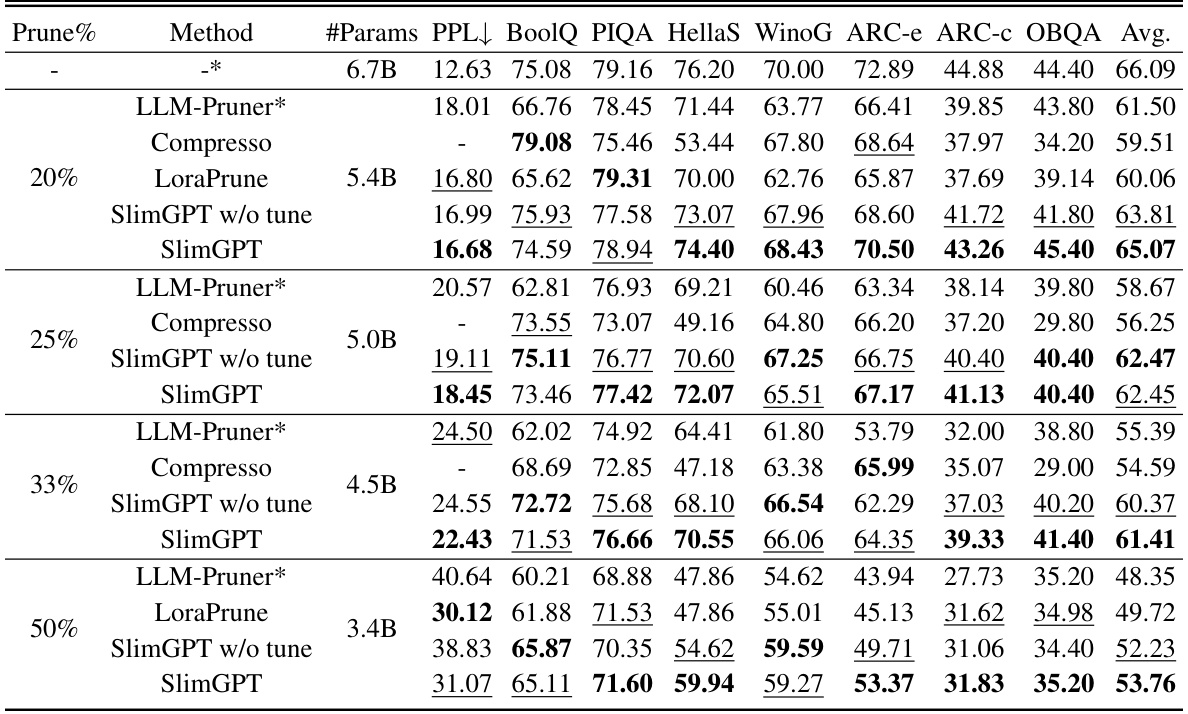
🔼 This table presents the results of the perplexity (PPL) and commonsense reasoning zero-shot performance evaluation on seven datasets for the pruned LLaMA-7B model. It compares different pruning methods (LLM-Pruner, Compresso, LoraPrune, and SlimGPT) at various pruning percentages (20%, 25%, 33%, 50%). The table highlights the best performing method for each pruning percentage and dataset.
read the caption
Table 1: PPL & Commonsense Reasoning zero-shot performance of the pruned LLaMA-7B. The average score is computed across seven datasets. The bolded results represent the optimal results, while the underlined ones is the sub-optimal results. The asterisk-marked (*) results are those replicated within a consistent experimental framework, which slightly differ from the original source.
In-depth insights#
SlimGPT: LLM Pruning#
SlimGPT presents a novel structured pruning method for Large Language Models (LLMs), addressing the challenge of balancing efficiency and performance. It leverages the Optimal Brain Surgeon (OBS) framework, adapting it for structured pruning through a novel Batched Greedy Pruning technique. This significantly speeds up the pruning process while maintaining near-optimal results by efficiently estimating pruning errors. SlimGPT also introduces Incremental Pruning Ratio, a non-uniform pruning strategy to mitigate performance degradation by addressing error accumulation issues inherent in layer-wise pruning. The method demonstrates state-of-the-art results on LLaMA benchmarks, showcasing its effectiveness and efficiency. The task-agnostic nature and scalability to different Transformer-based models are significant advantages, making SlimGPT a valuable contribution to LLM optimization.
OBS Framework Extension#
Extending the Optimal Brain Surgeon (OBS) framework for large language model (LLM) pruning presents exciting possibilities and unique challenges. OBS’s iterative, fine-grained nature, however, clashes with the inherent structure of LLMs, requiring modifications to adapt to the column or head-level pruning inherent in structured methods. A naive application would result in significant numerical errors and computational inefficiencies. Therefore, a key aspect of this extension involves developing strategies for efficiently approximating OBS’s local optimality within the constraints of structured pruning. This might include techniques like batched pruning, clever Hessian approximations, or novel update rules. Addressing the layer-wise nature of OBS is crucial, as it necessitates exploring error accumulation across layers and developing techniques for non-uniform pruning strategies to manage error propagation and prevent performance degradation. The success of such an extension would depend heavily on finding the right balance between computational efficiency and pruning accuracy, with the goal of achieving state-of-the-art compression rates without excessive performance loss.
Batched Greedy Pruning#
The proposed Batched Greedy Pruning method tackles the computational cost and suboptimality of traditional Optimal Brain Surgeon (OBS) based structured pruning in large language models (LLMs). It leverages grouped Cholesky decomposition to efficiently estimate head-wise pruning errors in the attention mechanism, allowing for near-optimal head selection without the iterative, single-parameter updates of standard OBS. This batching process significantly accelerates pruning speed and reduces computational burden. For feed-forward networks (FFNs), Dynamic Group Size is incorporated to further enhance efficiency by adjusting the size of the pruning groups to adapt to the error landscape. This method combines the advantages of structured pruning (reducing memory and computational costs) with rapid and near-optimal pruning, making it suitable for the computationally intensive task of LLM optimization. The efficacy of this approach is demonstrated by its ability to achieve state-of-the-art pruning results in LLMs, balancing efficiency gains with minimal performance degradation. The key is in the grouped Cholesky decomposition and the dynamic adjustment of group sizes which effectively reduces the computational complexity while maintaining pruning efficacy.
Incremental Pruning Ratio#
The proposed “Incremental Pruning Ratio” method tackles the challenge of non-uniform pruning in large language models (LLMs). Layer-wise pruning, a common approach, suffers from error accumulation; errors in early layers propagate and worsen in later layers. A uniform pruning ratio across all layers is suboptimal. The innovative solution involves a logarithmically increasing pruning ratio from the first to the last layer. This strategy elegantly addresses the error accumulation problem by starting with a lower pruning ratio in shallow layers and gradually increasing it. This approach offers a balance between effective compression and performance preservation, significantly reducing performance degradation compared to uniform pruning strategies. The logarithmic curve helps mitigate excessive pruning in deeper layers, leading to more effective compression while maintaining accuracy. The method is low-cost and efficient, requiring no additional computational overhead compared to traditional layer-wise techniques. SlimGPT incorporates this method for improved performance.
LLM Efficiency Gains#
LLM efficiency gains are crucial for broader adoption of large language models. Reducing computational costs and accelerating inference speeds are key areas of focus. Methods such as structured pruning, as explored in SlimGPT, offer a promising approach, systematically removing less-critical model parameters to significantly reduce model size without severely impacting performance. Other techniques like quantization also play a role in efficiency gains, minimizing memory footprint and improving processing speeds. The effectiveness of these methods depends on factors such as the model architecture and the specific task, and often involve trade-offs between efficiency and accuracy. Future research will likely explore novel ways to improve LLM efficiency by combining different methods, improving pruning algorithms, and potentially leveraging specialized hardware. Balancing performance and efficiency remains a key challenge in the development of practical and sustainable LLMs.
More visual insights#
More on figures

🔼 This figure shows the error accumulation in layer-wise pruning. Three models are pruned with different first-layer pruning ratios (25%, 50%, 75%). The y-axis represents the squared error between the outputs of the original and pruned models for each layer. The x-axis represents the layer index. The figure demonstrates that the error increases with model depth and accumulates at a rate exceeding linear progression as the initial layer’s pruning ratio increases.
read the caption
Figure 2: Per-layer FFN output error between the original LLaMA-7B and three distinct pruned models. The pruned models each implement a first-layer reduction of 25%, 50%, and 75%, respectively. The PPL of original model is 12.63. For ease of visualization, the layer index has been truncated to 25.
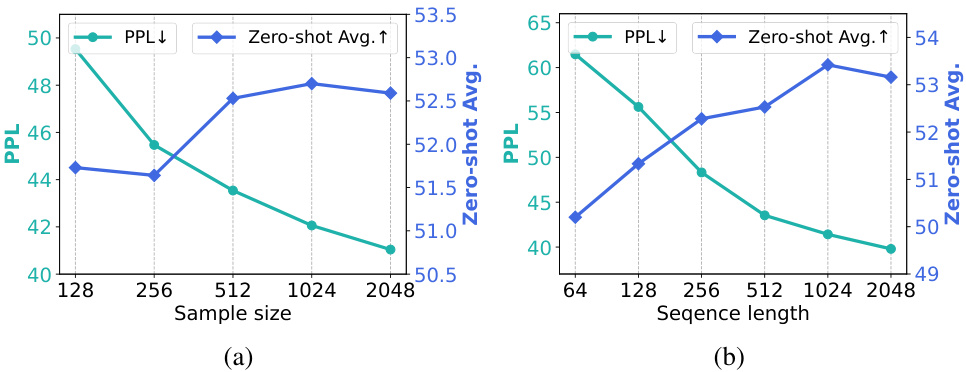
🔼 This figure shows the impact of calibration sample size and sequence length on the performance of SlimGPT. The left subplot (a) illustrates how both perplexity (PPL) and average zero-shot performance improve as the calibration sample size increases from 128 to 2048. The right subplot (b) shows a similar trend for increasing sequence lengths from 64 to 2048 tokens, indicating that larger and more diverse calibration data leads to better model compression and performance.
read the caption
Figure 3: Effects of Calibration Sample Size & Sequence Length.

🔼 This figure compares the layer-wise pruning ratios employed by two different methods: SlimGPT and LLM-Pruner, both aiming for a 50% overall pruning rate. The x-axis represents the layer index, and the y-axis shows the pruning ratio applied to each individual layer. SlimGPT adopts a logarithmic increase strategy, starting with a lower pruning ratio in the initial layers and gradually increasing it towards the deeper layers. In contrast, LLM-Pruner employs a heuristic approach with a uniform pruning ratio in the intermediate layers while avoiding pruning in the initial and final layers. This visualization highlights the distinct layer-wise pruning strategies and how they differ in distributing the overall pruning ratio across the different layers of the model.
read the caption
Figure 4: Layer-wise pruning ratio on LLaMA-7B with total pruning ratio 50%.
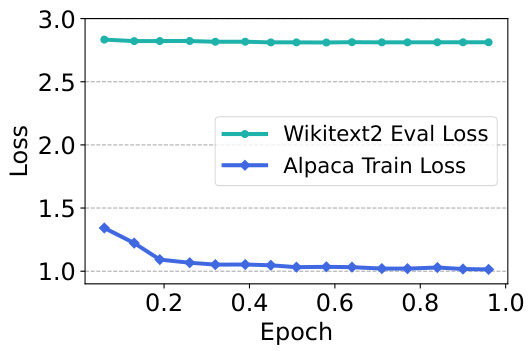
🔼 This figure shows the training loss on the Alpaca dataset and the evaluation loss on the Wikitext2 dataset during the fine-tuning stage. The training loss decreases and converges normally, while the evaluation loss shows no significant fluctuations, indicating that fine-tuning is not overfitting to the Wikitext2 dataset.
read the caption
Figure 5: Alpaca train loss & Wikitext2 evaluation loss.
More on tables
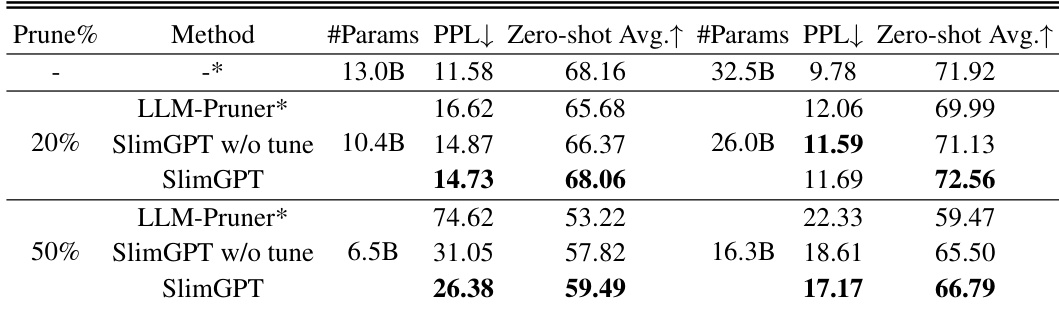
🔼 This table presents the results of the pruned LLaMA-7B model on seven different datasets, including perplexity (PPL) and commonsense reasoning zero-shot performance. The table compares SlimGPT to several baseline methods (LLM-Pruner, Compresso, LoraPrune) across various pruning percentages (20%, 25%, 33%, 50%). Results with and without fine-tuning are shown for SlimGPT. The best and near-best performing methods are highlighted.
read the caption
Table 1: PPL & Commonsense Reasoning zero-shot performance of the pruned LLaMA-7B. The average score is computed across seven datasets. The bolded results represent the optimal results, while the underlined ones is the sub-optimal results. The asterisk-marked (*) results are those replicated within a consistent experimental framework, which slightly differ from the original source.

🔼 This table presents the runtime and GPU memory usage of the SlimGPT pruning method on LLaMA 7B and 13B models. The runtime is broken down for two different pruning ratios: 20% and 50%. The memory usage represents the peak memory consumption during the pruning process.
read the caption
Table 3: Pruning Runtime and Memory Usage

🔼 This table presents the inference latency and memory usage of the pruned LLaMA-7B models. The models were pruned by 20% and 50%, resulting in parameter counts of 5.4B and 3.4B, respectively. The maximum output length was set to 512, and the results are averages from 50 inference trials. The table shows the reduction in memory usage and latency achieved by pruning.
read the caption
Table 4: Inference Latency and Memory Usage
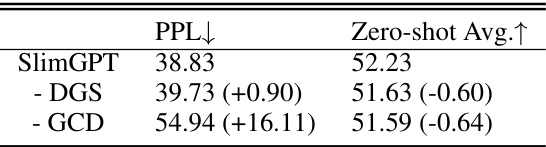
🔼 This table presents the ablation study results for SlimGPT, showing the impact of removing key components: Dynamic Group Size (DGS) for Feed-Forward Networks (FFNs) and Grouped Cholesky Decomposition (GCD) for attention blocks. The table compares the performance of the full SlimGPT model against versions with DGS removed (-DGS) and GCD removed (-GCD), providing PPL and Zero-shot Avg. metrics to assess the effect of each component on the overall model performance. The numbers in parentheses indicate the change in performance compared to the full SlimGPT model.
read the caption
Table 5: Pruning results under different strategies of SlimGPT. ‘-DGS’ means removing Dynamic Group Size for FFN while ‘-GCD’ means removing grouped Cholesky decomposition for attention blocks.
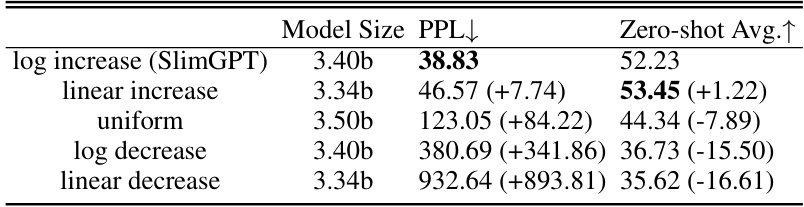
🔼 This table presents the results of experiments using various pruning ratio strategies. It compares the performance (PPL and Zero-shot Avg) of models pruned using a logarithmic increase strategy (SlimGPT’s default), linear increase, uniform, logarithmic decrease, and linear decrease strategies. The results highlight the effectiveness of SlimGPT’s logarithmic increase strategy compared to other methods. Note that the numbers in parentheses represent the difference compared to SlimGPT’s default method.
read the caption
Table 6: Pruning results with different pruning ratio strategies.
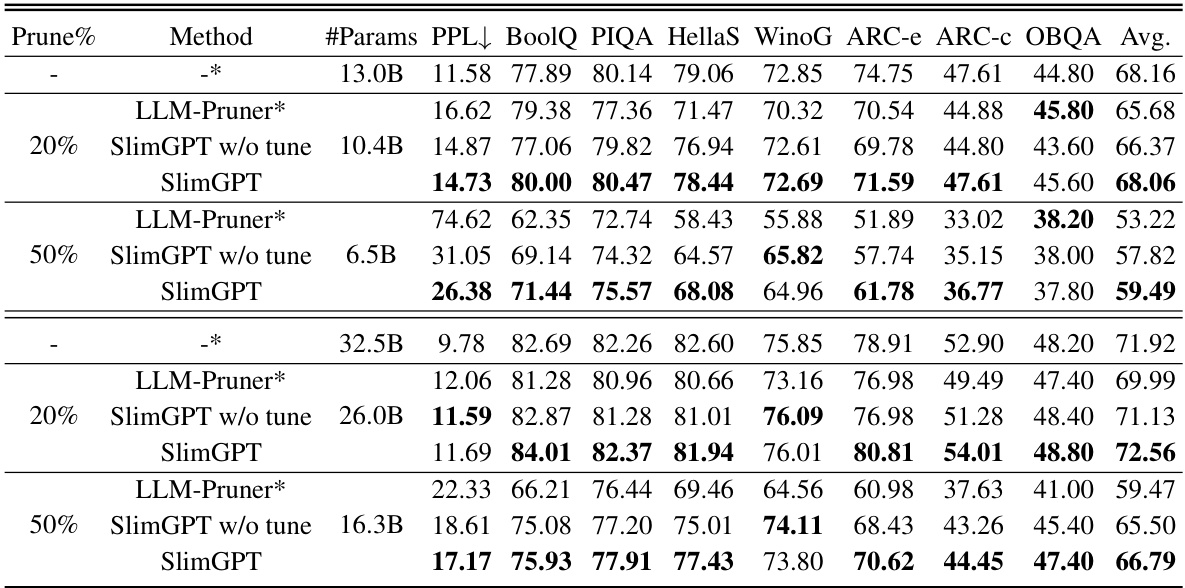
🔼 This table presents the results of the pruned LLaMA-7B model’s performance on various tasks. It compares the performance of SlimGPT with other state-of-the-art structured pruning methods (LLM-Pruner, Compresso, LoraPrune) across different pruning percentages (20%, 25%, 33%, 50%). The metrics used are Perplexity (PPL) for language modeling and average scores across seven commonsense reasoning datasets. The table highlights SlimGPT’s superior performance and the impact of fine-tuning on the results.
read the caption
Table 1: PPL & Commonsense Reasoning zero-shot performance of the pruned LLaMA-7B. The average score is computed across seven datasets. The bolded results represent the optimal results, while the underlined ones is the sub-optimal results. The asterisk-marked (*) results are those replicated within a consistent experimental framework, which slightly differ from the original source.
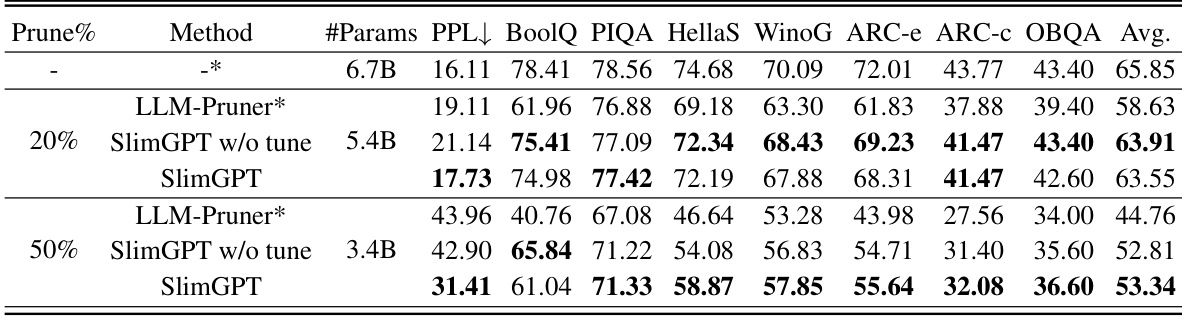
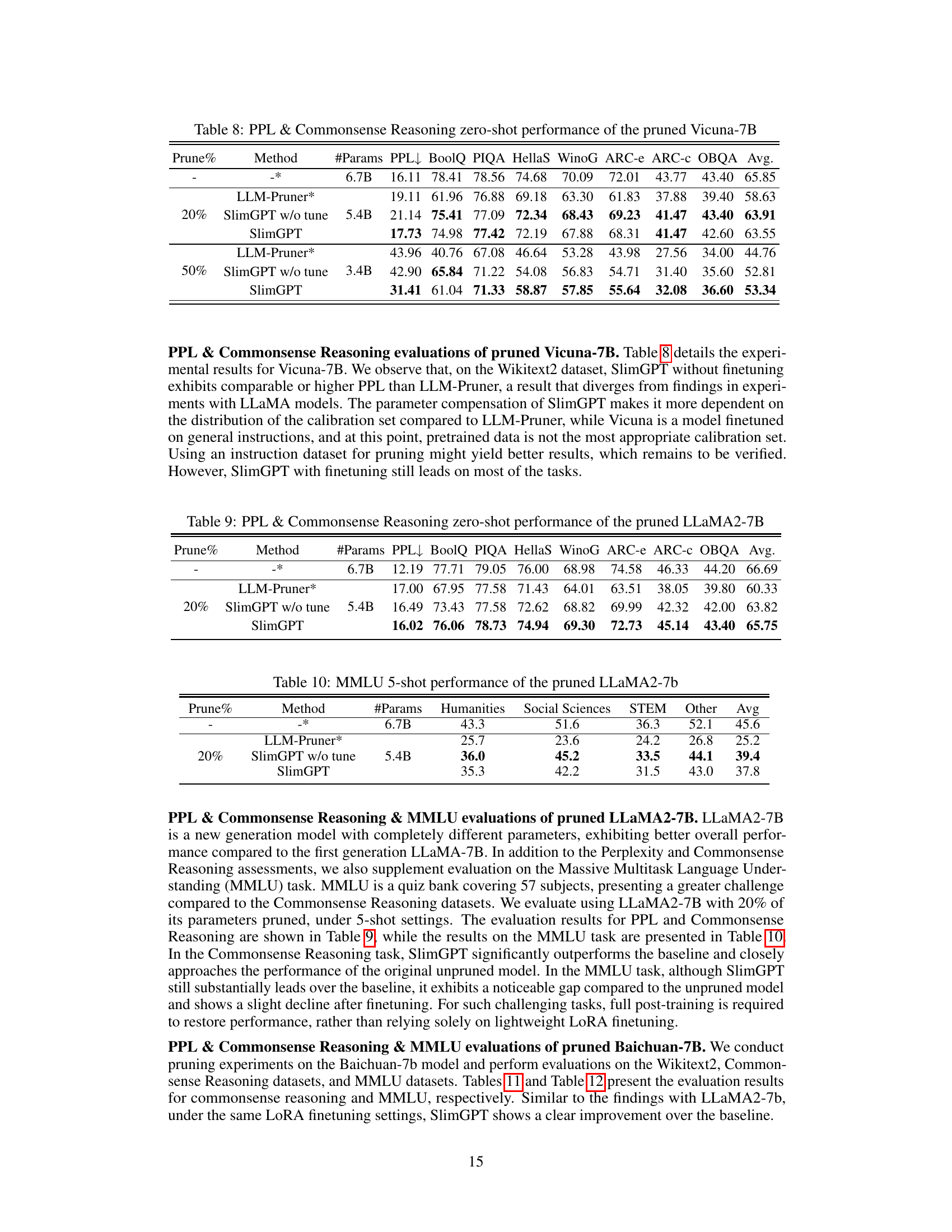
🔼 This table presents the results of evaluating the pruned Vicuna-7B model on the Wikitext2 dataset (perplexity) and seven common sense reasoning datasets (zero-shot performance). It compares the performance of the original Vicuna-7B model against LLM-Pruner and SlimGPT (with and without fine-tuning) at different pruning percentages (20% and 50%). The table shows the number of parameters remaining, perplexity scores, and average scores across the common sense reasoning datasets for each model and pruning level.
read the caption
Table 8: PPL & Commonsense Reasoning zero-shot performance of the pruned Vicuna-7B

🔼 This table shows the performance of pruned LLaMA2-7B models on the WikiText2 perplexity task and seven commonsense reasoning tasks. It compares the performance of the original, unpruned model to models pruned using LLM-Pruner and SlimGPT (with and without fine-tuning). The table presents the number of parameters, perplexity scores, and average scores across the commonsense reasoning tasks for different pruning percentages (20% and 50%).
read the caption
Table 9: PPL & Commonsense Reasoning zero-shot performance of the pruned LLaMA2-7B

🔼 This table presents the results of the MMLU (Massive Multitask Language Understanding) benchmark for pruned versions of the LLaMA2-7B model. The evaluation uses a 5-shot setting, meaning five examples are provided for each task before the model makes a prediction. The table compares the performance of the original model, a model pruned using LLM-Pruner, and two models pruned using SlimGPT (one fine-tuned with LoRA and one without). The performance is measured across four categories: Humanities, Social Sciences, STEM, and Other, with an average across all four. This allows for an assessment of how well SlimGPT’s pruning method preserves the model’s knowledge across different domains and the impact of LoRA fine-tuning.
read the caption
Table 10: MMLU 5-shot performance of the pruned LLaMA2-7b

🔼 This table presents the performance of different pruned versions of the LLaMA-7B model on several metrics. It compares the performance of SlimGPT with other state-of-the-art structured pruning methods such as LLM-Pruner and Compresso. The metrics include Perplexity (PPL) on the WikiText2 dataset, and average zero-shot performance across seven commonsense reasoning datasets (BoolQ, PIQA, HellaSwag, WinoGrande, ARC-easy, ARC-challenge, OpenbookQA). The table shows results for different pruning percentages (20%, 25%, 33%, 50%), highlighting the impact of pruning on model size and performance.
read the caption
Table 1: PPL & Commonsense Reasoning zero-shot performance of the pruned LLaMA-7B. The average score is computed across seven datasets. The bolded results represent the optimal results, while the underlined ones is the sub-optimal results. The asterisk-marked (*) results are those replicated within a consistent experimental framework, which slightly differ from the original source.

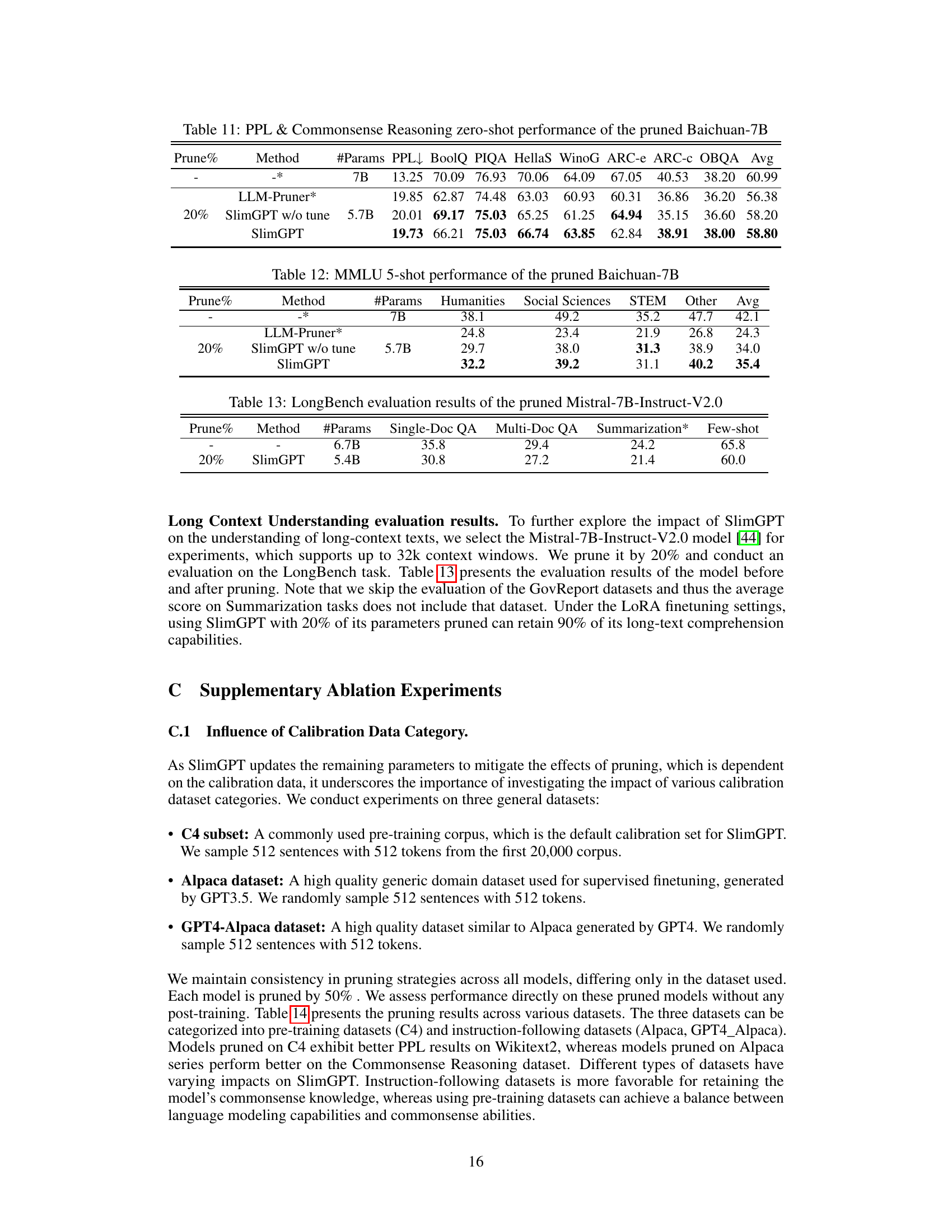
🔼 This table presents the results of the Massive Multitask Language Understanding (MMLU) benchmark on the pruned Baichuan-7B model. It shows the performance (5-shot) across four categories: Humanities, Social Sciences, STEM, and Other, for different pruning percentages (20%) and methods (LLM-Pruner, SlimGPT with and without finetuning). The table helps to evaluate the effectiveness of the pruning techniques on a complex multi-task language understanding benchmark.
read the caption
Table 12: MMLU 5-shot performance of the pruned Baichuan-7B

🔼 This table presents the results of evaluating the pruned Mistral-7B-Instruct-V2.0 model on the LongBench benchmark. It shows the performance (in terms of accuracy) on four different subtasks: Single-Doc QA, Multi-Doc QA, Summarization, and Few-shot. The table compares the performance of the original, unpruned model (6.7B parameters) with the performance of the model pruned by SlimGPT to 5.4B parameters (20% pruning). The results indicate how well the pruned model maintains its performance on these complex long-context understanding tasks.
read the caption
Table 13: LongBench evaluation results of the pruned Mistral-7B-Instruct-V2.0
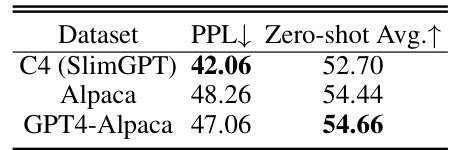
🔼 This table presents the results of pruning experiments conducted using different calibration datasets. The performance of SlimGPT is evaluated by comparing the perplexity (PPL) scores on WikiText2 and average zero-shot scores across seven commonsense reasoning datasets. Three different calibration datasets were used: C4 (the default for SlimGPT), Alpaca, and GPT4-Alpaca. The table shows that the choice of calibration dataset impacts the final results, suggesting that the dataset used for calibration should be carefully selected depending on the downstream task (language modeling versus commonsense reasoning).
read the caption
Table 14: Pruning results with various calibration datasets

🔼 This table presents the results of the perplexity (PPL) and commonsense reasoning zero-shot performance for the pruned LLaMA-7B model at different pruning percentages (20%, 25%, 33%, 50%). It compares the performance of SlimGPT (with and without fine-tuning) against other state-of-the-art methods like LLM-Pruner, Compresso, and LoraPrune. The average scores are calculated across seven different commonsense reasoning datasets. Optimal and suboptimal results are highlighted.
read the caption
Table 1: PPL & Commonsense Reasoning zero-shot performance of the pruned LLaMA-7B. The average score is computed across seven datasets. The bolded results represent the optimal results, while the underlined ones is the sub-optimal results. The asterisk-marked (*) results are those replicated within a consistent experimental framework, which slightly differ from the original source.
Full paper#