TL;DR#
Current text-to-image models struggle with intricate details in complex prompts, and existing fine-tuning methods suffer from ‘reward hacking’ and generalization issues. Simply put, these methods often generate images that look good but don’t accurately capture the prompt’s meaning or generate unrealistic objects. This hinders the ability of these models to accurately capture the intended scene.
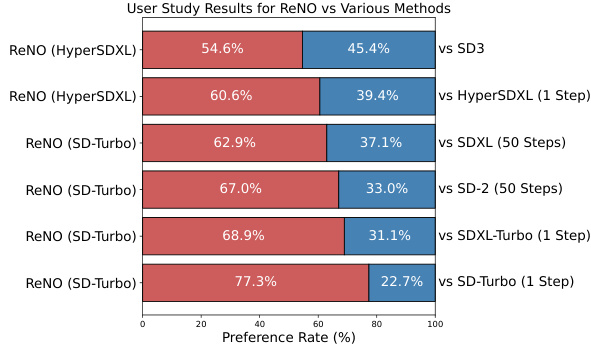
ReNO tackles these issues by optimizing the initial noise input to a one-step model using feedback from reward models. This avoids the problems of fine-tuning while significantly improving image quality and prompt adherence, often outperforming even complex, multi-step models. ReNO’s efficiency and effectiveness make it a valuable tool for enhancing text-to-image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-image synthesis. It introduces ReNO, a novel and efficient method for significantly improving the quality of images generated by one-step models without retraining. This offers a practical solution to current limitations, opens up new avenues of research into noise optimization, and provides a strong benchmark for reward model evaluation.
Visual Insights#

🔼 This figure shows the qualitative comparison of image generation results from four different one-step text-to-image models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, and HyperSD) with and without applying the proposed ReNO method. The same initial random noise was used for both the one-step generation and ReNO initialization. The results demonstrate that ReNO substantially improves image quality and prompt adherence across all four models.
read the caption
Figure 1: Qualitative results of four different one-step Text-to-Image models with and without ReNO over different prompts. The same initial random noise is used for the one-step generation and the initialization of ReNO. ReNO significantly improves upon the initially generated image with respect to both prompt faithfulness as well as aesthetic quality for all four models. Best viewed zoomed in.
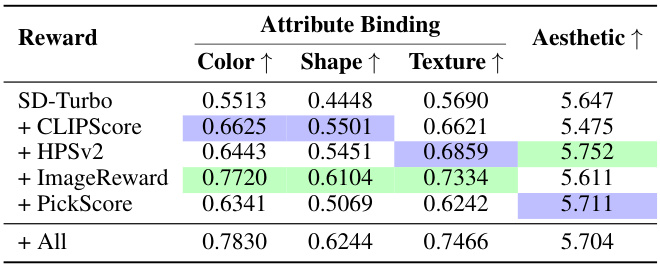
🔼 This table presents the performance of the SD-Turbo model on the attribute binding categories of the T2I-CompBench benchmark, using different reward models. It shows the impact of each reward model (CLIPScore, HPSv2, ImageReward, PickScore) individually and in combination on the Color, Shape, Texture attributes, as well as the overall aesthetic score. The table helps demonstrate the effectiveness of combining reward models to improve image quality and prompt faithfulness.
read the caption
Table 1: SD-Turbo evaluated on the attribute binding categories of T2I-CompBench and the LAION aesthetic score predictor [83] for different reward models.
In-depth insights#
ReNO: Noise Optimization#
The proposed ReNO (Reward-based Noise Optimization) method offers a novel approach to enhancing one-step text-to-image models. Instead of computationally expensive fine-tuning, ReNO optimizes the initial noise vector at inference time, leveraging feedback from human preference reward models. This approach cleverly sidesteps the challenges of “reward hacking” and poor generalization often associated with fine-tuning by directly improving the input to the generative model, resulting in significant performance gains. ReNO’s efficiency is remarkable, achieving impressive results within a limited computational budget, making it practical for real-world applications. By cleverly integrating human feedback and focusing on noise optimization, ReNO demonstrates a powerful strategy for improving the quality and fidelity of images generated by one-step models, while maintaining computational efficiency. The method’s success highlights the importance of the initial noise distribution in diffusion models and its potential for future research in improving the efficiency and effectiveness of T2I generation.
One-step Model Boost#
A hypothetical ‘One-step Model Boost’ section in a research paper would likely explore techniques to enhance the performance of one-step text-to-image models. This could involve several key strategies. First, improving the quality of the initial noise vector is crucial as it’s the foundation for image generation; optimization methods could focus on finding optimal noise distributions that align better with user preferences. Second, refining the model architecture itself might involve exploring different network structures or incorporating attention mechanisms to improve feature extraction and generation of intricate details. Third, the training process could be examined, with a focus on more efficient or targeted training data. A fourth focus area might investigate the effectiveness of various reward models during the inference phase, enabling better alignment between the textual prompts and generated images. The evaluation metrics would critically assess the model’s improvements across established benchmarks like FID (Fréchet Inception Distance) and CLIP score. The ultimate goal would be to achieve a significant boost in image quality, prompt fidelity, and generation speed without compromising computational efficiency. Ultimately, success hinges on demonstrating that these strategies enhance the model’s overall performance compared to existing one-step and multi-step methods.
Reward Model Fusion#
Reward model fusion in text-to-image synthesis aims to improve the quality and diversity of generated images by combining the strengths of multiple reward models. Each reward model provides a score reflecting human preference for an image given a prompt, but they often have different strengths and weaknesses. Therefore, fusing them can lead to a more robust and comprehensive evaluation metric, guiding the optimization process towards images that better satisfy the diverse aspects of human preferences. Careful consideration of weighting schemes and fusion strategies is crucial for successful fusion. Simple averaging might not be optimal; techniques like weighted averaging, where weights reflect the individual model’s reliability or confidence, or more sophisticated approaches using neural networks to learn optimal fusion weights, can significantly improve performance. Effective fusion can mitigate the problem of ‘reward hacking’, where models learn to exploit weaknesses in individual reward models to produce images that receive high scores but aren’t visually appealing or faithful to the prompt. A well-fused system is expected to be more generalized and less susceptible to biases present in individual reward models, ultimately leading to significantly improved image generation.
Diversity & Efficiency#
A crucial aspect of any text-to-image model is its ability to generate diverse and high-quality images efficiently. Diversity ensures the model avoids repetitive outputs and produces a wide range of visual styles and compositions, catering to the nuances of various prompts. Efficiency focuses on minimizing computational resources (time and memory) without compromising image quality. Balancing these two factors is challenging, as increasing diversity often requires more computational power. A successful model should exhibit strong diversity scores while remaining computationally inexpensive. The optimal approach might involve techniques that learn to optimize the initial noise vector for each generation, thereby guiding the model towards novel outputs without requiring extensive fine-tuning or increased model complexity. Careful consideration of the noise distribution is therefore paramount, as it significantly affects both aspects. Furthermore, the use of efficient one-step models over multi-step counterparts significantly enhances efficiency, achieving optimal performance in the generation of novel images within a practical timeframe.
Future Enhancements#
Future enhancements for this research could explore several key areas. First, investigating alternative reward models beyond the ones used is crucial. More robust and nuanced reward functions could mitigate the issue of “reward hacking” and improve the overall quality of generated images. Second, exploring different optimization techniques is important. While gradient ascent proved effective, advanced methods could potentially offer faster convergence or better handling of the high-dimensional space. Third, expanding the range of one-step diffusion models used in the framework would validate the generalizability of the approach. Finally, integrating user feedback more directly through interactive systems could personalize the image generation process significantly. This combination of improved reward signals, sophisticated optimization, model diversity, and direct user input holds the key to unlock even higher quality and more aesthetically pleasing results.
More visual insights#
More on figures
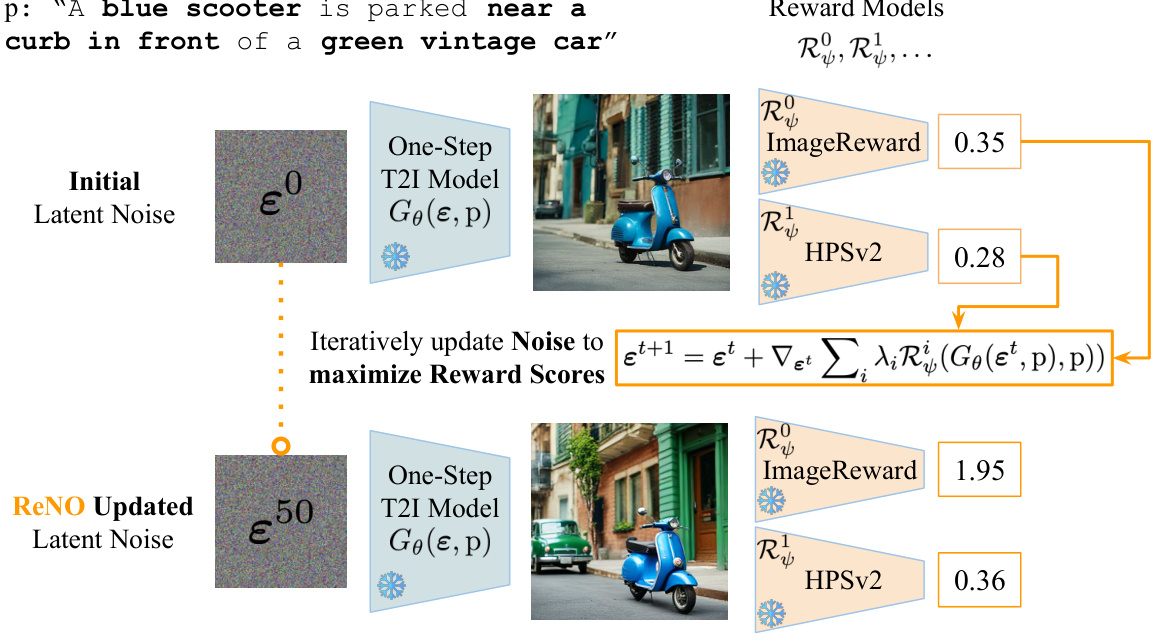
🔼 This figure illustrates the ReNO framework. It shows how, given multiple reward models that assess image quality based on human preferences, the initial noise input to a one-step text-to-image (T2I) model is iteratively refined. The optimization process aims to maximize the reward scores from the different reward models. The figure displays the initial random noise, the output of a one-step T2I model based on that initial noise, the iterative noise optimization process, and the final, refined noise resulting in an improved image generation. The reward scores before and after the optimization are shown for comparison.
read the caption
Figure 2: Overview of our proposed ReNO framework. Given reward models based on human preferences, we optimize the initial latent noise to maximize the reward scores (consisting HPSv2 [97], PickScore [46], ImageReward [100], and CLIP [73]) for the images generated by the one-step T2I model. Over 50 iterations, the quality of the images and the prompt faithfulness are improved.
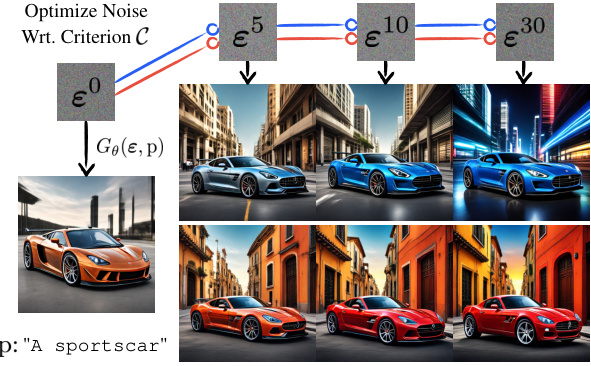
🔼 This figure shows how the initial noise is optimized iteratively to maximize a selected color channel of the generated image while minimizing the other two. The optimization process starts by adjusting the color of the car and then gradually modifies the background. The figure demonstrates the efficiency and effectiveness of the proposed one-step noise optimization approach.
read the caption
Figure 3: Initial noise optimization for one-step Gθ HyperSDXL with two color channel criterions (5).
🔼 This figure displays the qualitative results of applying the ReNO method to four different one-step text-to-image models. Each model generated images for various prompts both with and without the ReNO optimization. The comparison shows that ReNO significantly enhances the quality of the images, resulting in better adherence to the prompts (faithfulness) and improved aesthetic appeal. The same initial noise was used for all images for direct comparison.
read the caption
Figure 1: Qualitative results of four different one-step Text-to-Image models with and without ReNO over different prompts. The same initial random noise is used for the one-step generation and the initialization of ReNO. ReNO significantly improves upon the initially generated image with respect to both prompt faithfulness as well as aesthetic quality for all four models. Best viewed zoomed in.
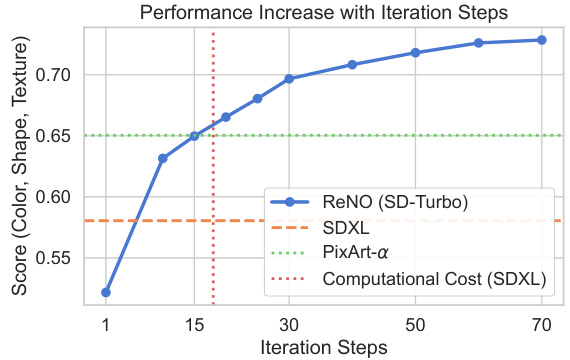
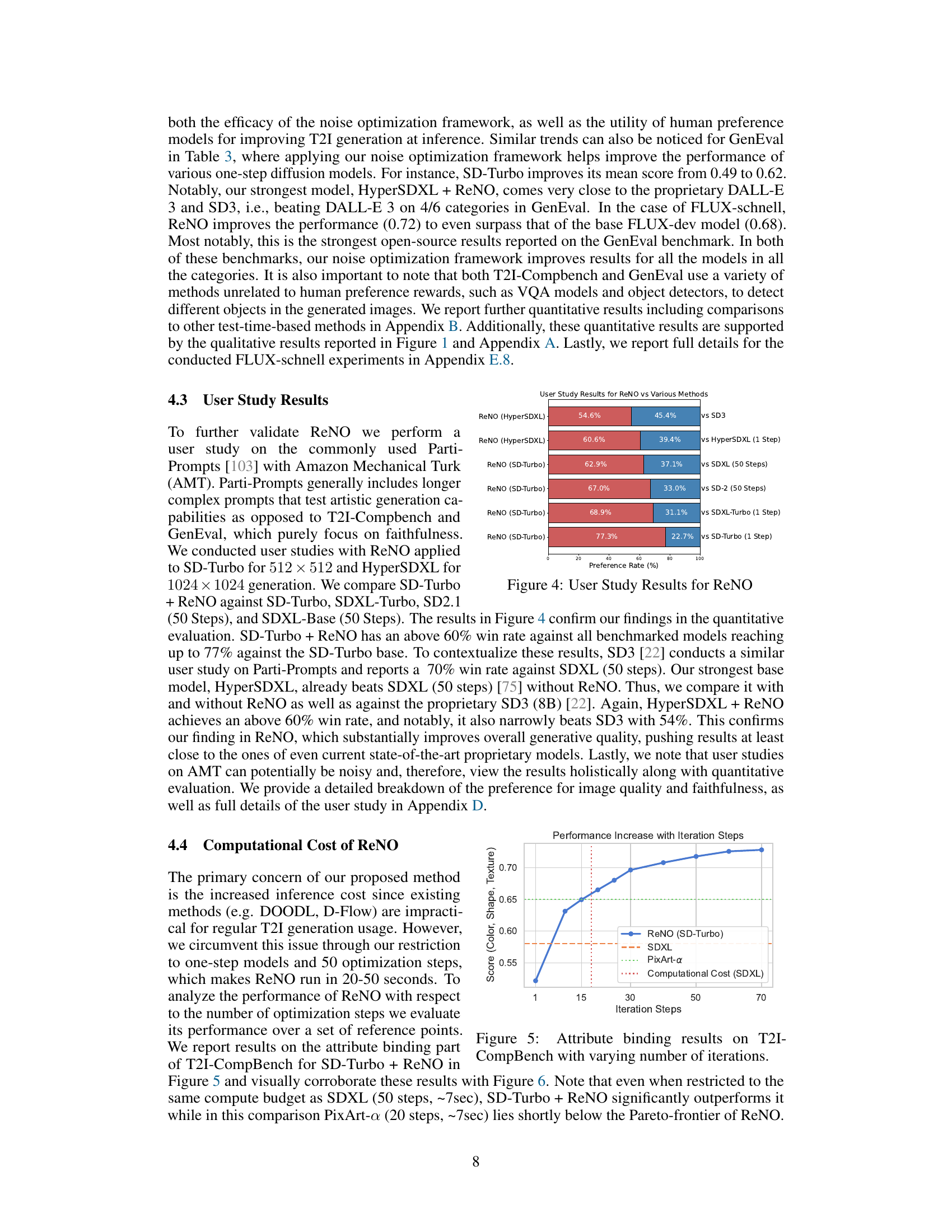
🔼 This figure shows the performance increase with the number of iterations in the ReNO (Reward-based Noise Optimization) method. The x-axis represents the iteration steps and the y-axis shows the score (Color, Shape, Texture) on the T2I-CompBench benchmark. The blue line shows the performance of ReNO with SD-Turbo, while the orange dashed line and the green dotted line represent the performances of SDXL and PixArt-a, respectively. The red dotted line indicates the computational cost of SDXL. This figure demonstrates the effectiveness of ReNO in improving the performance with limited computational resources.
read the caption
Figure 5: Attribute binding results on T2I-CompBench with varying number of iterations.

🔼 This figure shows the iterative optimization process of ReNO (Reward-based Noise Optimization) on four different one-step text-to-image models. The prompt is: ‘A yellow reindeer and a blue elephant’. Each row represents a different model (PixArt-a DMD, SD Turbo, SDXL Turbo, HyperSD). The columns show the image generated at different iteration steps (5, 10, 20, 30, 40, 50) of the ReNO optimization process. The images demonstrate how the initial noise is refined iteratively, based on feedback from a reward model, to better match the prompt’s description.
read the caption
Figure 6: The initial images are generated with four different one-step models Gθ given the prompt p 'A yellow reindeer and a blue elephant' and randomly initialized noise ε0. Each column shows the result of optimizing the noise latent εt for t steps with respect to our reward-based criterion.
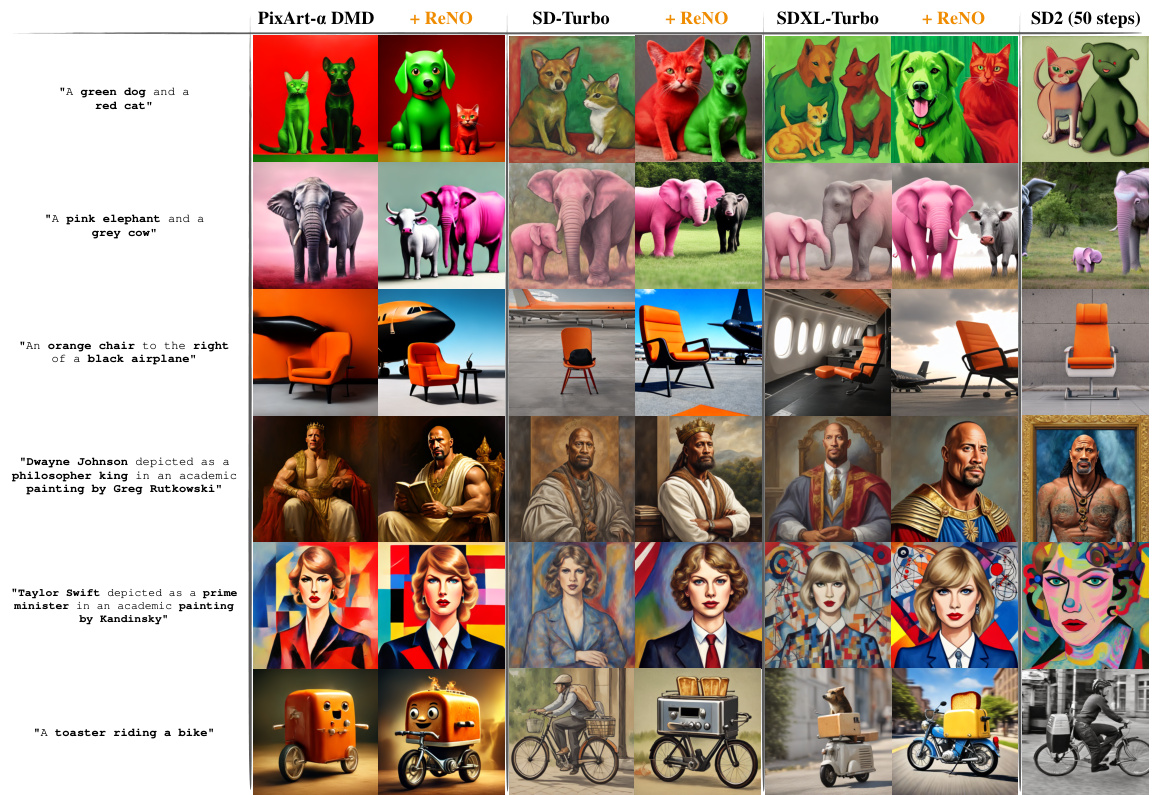
🔼 This figure compares the image generation results of four different one-step text-to-image models (PixArt-a DMD, SD-Turbo, SDXL-Turbo) with and without ReNO enhancement. It shows how ReNO improves the image quality for various prompts, demonstrating its effectiveness across different models. The same initial random noise is used for both the one-step generation and ReNO initialization to highlight the improvements achieved by ReNO.
read the caption
Figure 7: Comparison of images generated with and without ReNO at 512 × 512 resolution across various one-step models and SD v2.1. The noise used to generate the initial image is the same one that is used to initialize ReNO.

🔼 This figure showcases the qualitative improvements achieved by the ReNO method. Four different one-step text-to-image models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, HyperSD) are used to generate images for various prompts, both with and without ReNO. The results show that ReNO consistently enhances the quality of the generated images, improving their faithfulness to the prompt and aesthetic appeal. The same initial random noise was used for all generations, highlighting the effectiveness of ReNO in refining the image solely through noise optimization.
read the caption
Figure 1: Qualitative results of four different one-step Text-to-Image models with and without ReNO over different prompts. The same initial random noise is used for the one-step generation and the initialization of ReNO. ReNO significantly improves upon the initially generated image with respect to both prompt faithfulness as well as aesthetic quality for all four models. Best viewed zoomed in.

🔼 This figure displays the qualitative results of four different one-step text-to-image models, both with and without the application of the ReNO method. The same initial random noise was used for each model’s single-step image generation and for the initialization of the ReNO optimization. The images demonstrate that ReNO significantly improves the image quality and prompt faithfulness across all four models. It’s recommended to view the image at a zoomed-in level to fully appreciate the details.
read the caption
Figure 1: Qualitative results of four different one-step Text-to-Image models with and without ReNO over different prompts. The same initial random noise is used for the one-step generation and the initialization of ReNO. ReNO significantly improves upon the initially generated image with respect to both prompt faithfulness as well as aesthetic quality for all four models. Best viewed zoomed in.

🔼 This figure shows the qualitative results of applying the ReNO method to four different one-step text-to-image models. Each row represents a different text prompt, and each column represents a model. The leftmost column shows images generated by the model without ReNO. The subsequent columns show the same prompts rendered by the same models, but with ReNO applied. The results demonstrate that ReNO consistently improves image quality and faithfulness to the prompt across different models.
read the caption
Figure 1: Qualitative results of four different one-step Text-to-Image models with and without ReNO over different prompts. The same initial random noise is used for the one-step generation and the initialization of ReNO. ReNO significantly improves upon the initially generated image with respect to both prompt faithfulness as well as aesthetic quality for all four models. Best viewed zoomed in.

🔼 This figure illustrates the ReNO framework. It shows how a one-step text-to-image (T2I) model is enhanced at inference time by iteratively optimizing the initial latent noise. This optimization is guided by reward scores from multiple human preference reward models (HPSv2, PickScore, ImageReward, and CLIP). The process involves 50 iterations, progressively improving the image quality and its alignment with the input prompt.
read the caption
Figure 2: Overview of our proposed ReNO framework. Given reward models based on human preferences, we optimize the initial latent noise to maximize the reward scores (consisting HPSv2 [97], PickScore [46], ImageReward [100], and CLIP [73]) for the images generated by the one-step T2I model. Over 50 iterations, the quality of the images and the prompt faithfulness are improved.

🔼 This figure displays the qualitative results of applying ReNO to four different one-step text-to-image models. Each row shows a different prompt. Each column shows the image generated by the four models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, HyperSD) with and without ReNO. The same initial noise was used for both the initial generation and the ReNO optimization, clearly demonstrating the improvement achieved by ReNO in both the faithfulness and quality of generated images across all four models.
read the caption
Figure 1: Qualitative results of four different one-step Text-to-Image models with and without ReNO over different prompts. The same initial random noise is used for the one-step generation and the initialization of ReNO. ReNO significantly improves upon the initially generated image with respect to both prompt faithfulness as well as aesthetic quality for all four models. Best viewed zoomed in.
More on tables
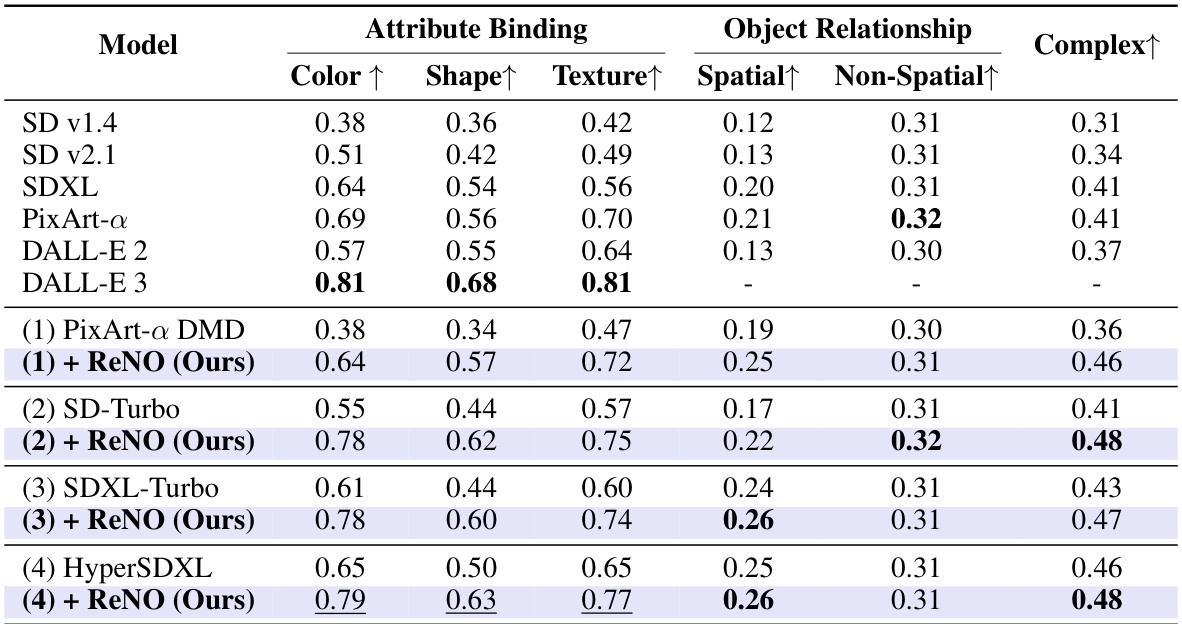
🔼 This table presents a quantitative comparison of different text-to-image models on the T2I-CompBench benchmark. It shows the performance of four one-step models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, and HyperSDXL) with and without the ReNO optimization method. The results are broken down by different aspects of image quality, including color, shape, texture, spatial and non-spatial relationships, and overall composition complexity. Multi-step models (from other research) are also included as a benchmark for comparison. The best performing model in each category is shown in bold.
read the caption
Table 2: Quantitative Results on T2I-CompBench. ReNO combined with (1) PixArt-a DMD [12, 13, 102], (2) SD-Turbo [81], (3) SDXL-Turbo [81], (4) HyperSD [75] demonstrates superior compositional generation ability in both attribute binding, object relationships, and complex compositions. The best value is bolded, and the second-best value is underlined. Multi-step results taken from [13, 22].

🔼 This table presents a quantitative comparison of different text-to-image models on the GenEval benchmark. It shows the performance of four one-step models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, and HyperSDXL) both with and without the ReNO optimization. The results are broken down by several categories (Mean, Single, Two, Counting, Colors, Position, Color Attribution) reflecting different aspects of image generation quality and faithfulness to the prompt. Multi-step models are also included for comparison, highlighting ReNO’s efficiency in improving one-step models.
read the caption
Table 3: Quantitative Results on GenEval. ReNO combined with (1) PixArt-a DMD [12, 13, 102], (2) SD-Turbo [81], (3) SDXL-Turbo [81], (4) HyperSDXL [75] improves results across all categories. The best value is bolded, and the second-best value is underlined. Multi-step results taken from [22].

🔼 This table presents the results of an experiment evaluating the diversity of images generated by different models. The experiment used 100 prompts from the Parti-Prompts dataset and generated images using 50 different random seeds for each prompt. The diversity was measured using two metrics: LPIPS (Learned Perceptual Image Patch Similarity) and DINO (self-supervised vision transformer). Lower scores indicate higher diversity. The table compares the diversity of images generated by SD-Turbo, SD-Turbo + ReNO, SD2.1 (50-step), SDXL-Turbo, SDXL-Turbo + ReNO, and SDXL (50-step).
read the caption
Table 4: We measure the average LPIPS and DINO similarity scores over images generated for 50 different seeds for 100 prompts from Parti-Promtps.

🔼 This table compares the performance of ReNO and DOODL on the attribute binding task of the T2I-CompBench benchmark. It shows the scores before and after optimization using both BLIP-VQA and CLIPScore, highlighting the improvements achieved by ReNO. The table also includes computational cost information (time per iteration and total time, VRAM usage) for each method.
read the caption
Table 5: Performance comparison of ReNO and DOODL over the first 50 prompts of each of the Attribute Binding categories in T2I-CompBench. We report scores from default T2I-Compbench evaluation using BLIP-VQA as well as the optimized CLIPScore before and after optimization.
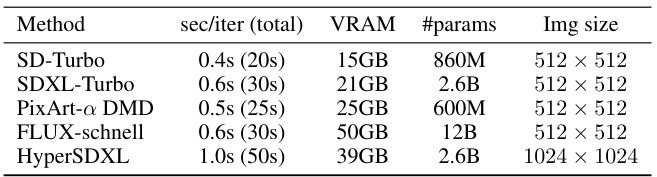
🔼 This table presents a comparison of the computational cost for applying ReNO to four different one-step text-to-image models. The metrics shown are seconds per iteration (and total time), VRAM usage in gigabytes, the number of parameters in the model, and the image resolution. It highlights the trade-off between model size and inference time for ReNO.
read the caption
Table 6: Computational cost comparison of ReNO optimizing four reward models on an A100 GPU.

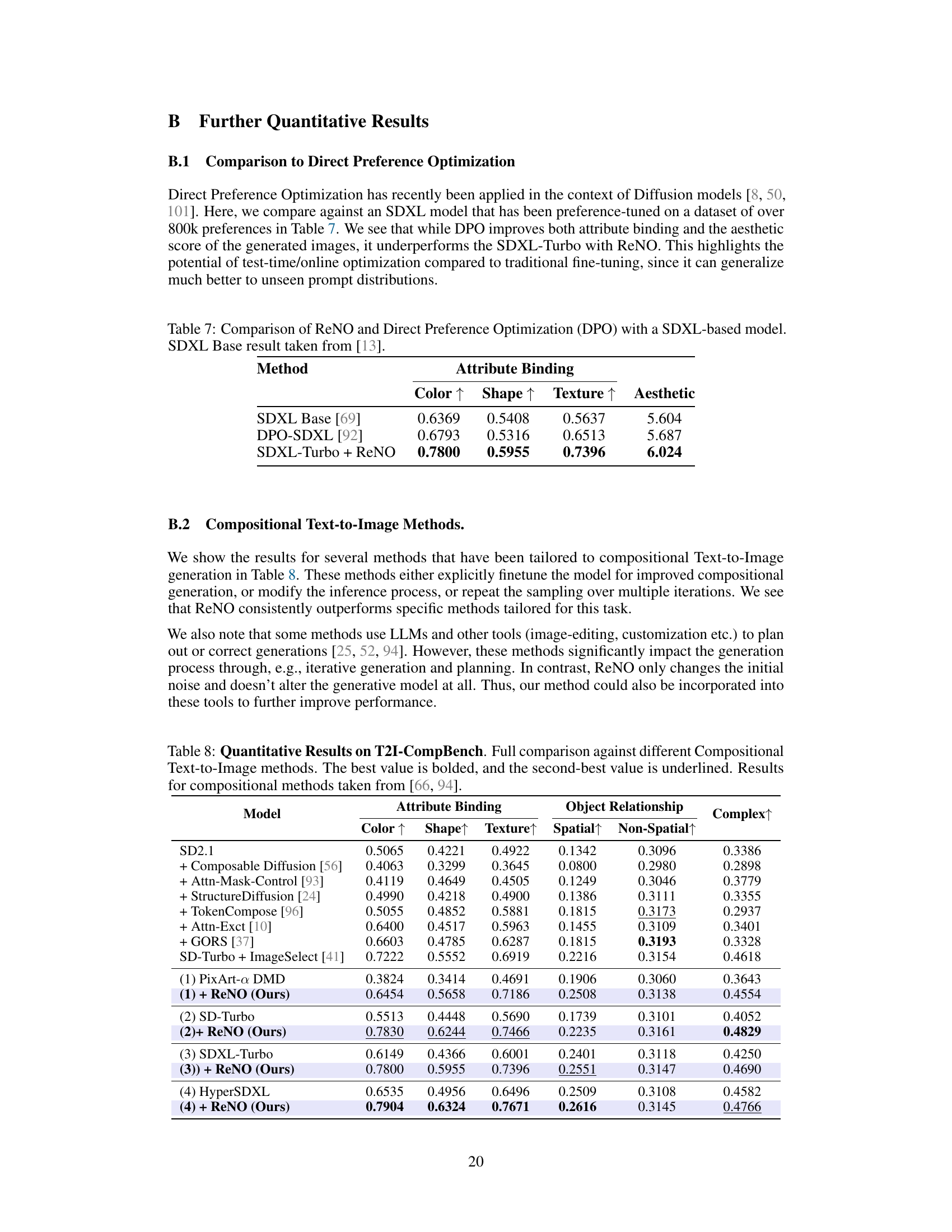
🔼 This table compares the performance of ReNO against direct preference optimization (DPO) using an SDXL-based model. The comparison focuses on attribute binding (color, shape, texture) and aesthetic scores. It highlights that while DPO improves the scores compared to the baseline SDXL, ReNO achieves superior performance across all metrics, demonstrating its potential for generalizing to unseen prompt distributions better than traditional fine-tuning methods.
read the caption
Table 7: Comparison of ReNO and Direct Preference Optimization (DPO) with a SDXL-based model. SDXL Base result taken from [13].

🔼 This table presents a quantitative comparison of different Text-to-Image (T2I) models on the T2I-CompBench benchmark. It shows the performance of four one-step models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, and HyperSD) both with and without the ReNO optimization method. The results are broken down by several sub-categories assessing different aspects of image generation quality, such as color, shape, texture, spatial and non-spatial relationships, and overall complexity of the generated images. Multi-step models’ results are also included for comparison.
read the caption
Table 2: Quantitative Results on T2I-CompBench. ReNO combined with (1) PixArt-a DMD [12, 13, 102], (2) SD-Turbo [81], (3) SDXL-Turbo [81], (4) HyperSD [75] demonstrates superior compositional generation ability in both attribute binding, object relationships, and complex compositions. The best value is bolded, and the second-best value is underlined. Multi-step results taken from [13, 22].

🔼 This table compares the computational cost of ReNO against DOODL, a multi-step noise optimization method. It shows that ReNO, even with multiple reward models, is significantly faster (120x) and requires less VRAM than DOODL while achieving comparable improvements in the T2I-CompBench benchmark. The table highlights ReNO’s efficiency advantage in terms of computation time and memory usage.
read the caption
Table 9: Computational cost comparison of ReNO compared to DOODL.

🔼 This table presents a quantitative analysis of the performance of the SD-Turbo model on the T2I-CompBench benchmark, specifically focusing on the attribute binding aspect (color, shape, texture) and aesthetic scores. The analysis is conducted using different reward models, individually and in combinations. It showcases the impact of different reward models on the model’s ability to accurately capture attributes and produce aesthetically pleasing images. The results are numerical scores, reflecting the model’s performance under different conditions.
read the caption
Table 1: SD-Turbo evaluated on the attribute binding categories of T2I-CompBench and the LAION aesthetic score predictor [83] for different reward models.

🔼 This table presents a quantitative comparison of different text-to-image models on the T2I-CompBench benchmark. It shows the performance of four one-step models (PixArt-a DMD, SD-Turbo, SDXL-Turbo, HyperSD) both with and without the ReNO optimization technique. The results are broken down by sub-categories of compositional generation (attribute binding: color, shape, texture, spatial; object relationship: non-spatial, spatial; complex). Multi-step model results are also included for comparison.
read the caption
Table 2: Quantitative Results on T2I-CompBench. ReNO combined with (1) PixArt-a DMD [12, 13, 102], (2) SD-Turbo [81], (3) SDXL-Turbo [81], (4) HyperSD [75] demonstrates superior compositional generation ability in both attribute binding, object relationships, and complex compositions. The best value is bolded, and the second-best value is underlined. Multi-step results taken from [13, 22].
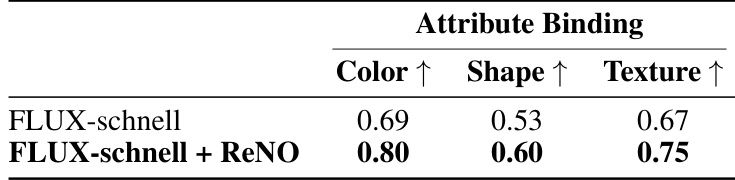
🔼 This table shows the quantitative results comparing the performance of the FLUX-schnell model with and without ReNO on the ‘Attribute Binding’ sub-task of the T2I-CompBench benchmark. The results are broken down into three categories: Color, Shape, and Texture. Each category shows the improvement gained by applying the ReNO optimization technique to the FLUX-schnell model. The table demonstrates that ReNO improves the performance across all categories.
read the caption
Table 12: Comparison of 512 × 512 FLUX-schnell with and without ReNO on the attribute binding categories of T2I-CompBench.
Full paper#