TL;DR#
Multimodal Sentiment Analysis (MSA) often struggles with real-world incomplete data. Existing methods lack a comprehensive evaluation under various noise scenarios, hindering fair comparison and knowledge dissemination. This paper tackles these issues by introducing a novel approach, proposing the Language-dominated Noise-resistant Learning Network (LNLN). LNLN prioritizes the typically more informative language modality, correcting it and performing multimodal learning to create robust sentiment analysis. This leads to superior performance across three benchmark datasets (MOSI, MOSEI, SIMS).
The paper’s strength lies in its extensive empirical evaluation across diverse and meaningful settings, establishing a higher standard for future MSA research. By addressing the limitations of existing methods and providing a robust, innovative approach, LNLN contributes significantly to the advancement of MSA, especially in challenging real-world situations. The consistent outperformance across numerous metrics provides strong evidence for the effectiveness of the proposed methodology, highlighting its potential for improved real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal sentiment analysis (MSA) as it directly addresses the prevalent challenge of incomplete data. It offers a comprehensive evaluation framework comparing existing methods under various noise conditions, promoting uniformity and fairness. Moreover, the proposed Language-dominated Noise-resistant Learning Network (LNLN) provides a novel solution for robust MSA, significantly outperforming existing methods across challenging evaluation metrics, thereby offering valuable insight and guidelines for future work.
Visual Insights#

🔼 This figure presents a comprehensive overview of the Language-dominated Noise-resistant Learning Network (LNLN) architecture for robust multimodal sentiment analysis. It details the entire process, from multimodal input with randomly missing data to final sentiment prediction. The diagram visually depicts the individual components: Multimodal Input, Feature Extraction, Dominant Modality Correction (DMC) module with Completeness Check and Proxy Dominant Feature Generation, Dominant Modality based Multimodal Learning (DMML) module containing Language, Visual, and Audio Embedding, Adaptive Hyper-modality Learning, Cross-modality Fusion Transformer, and a Reconstructor. Each component’s function and interconnections are clearly illustrated, along with the learnable vectors used in the process.
read the caption
Figure 1: Overall pipeline. Note: H, Hv, Ha, Hcc, and HD are randomly initialized learnable vectors.
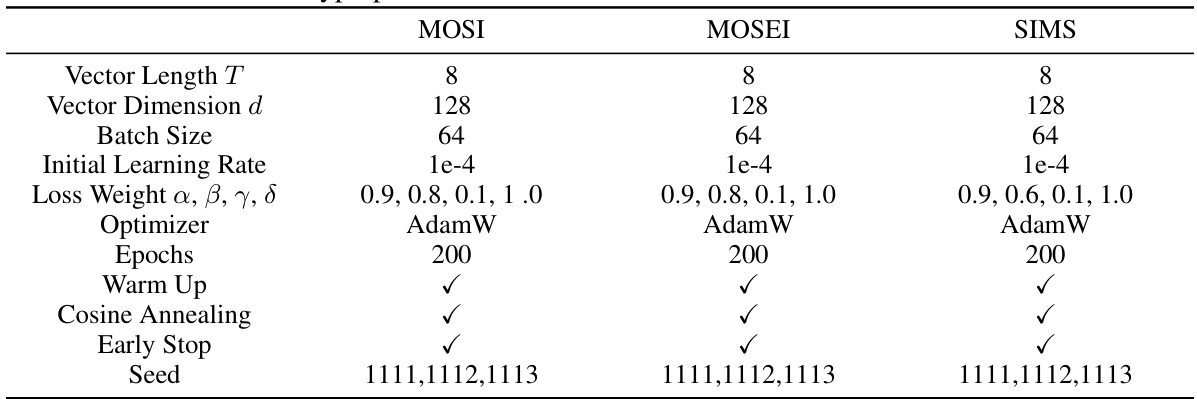
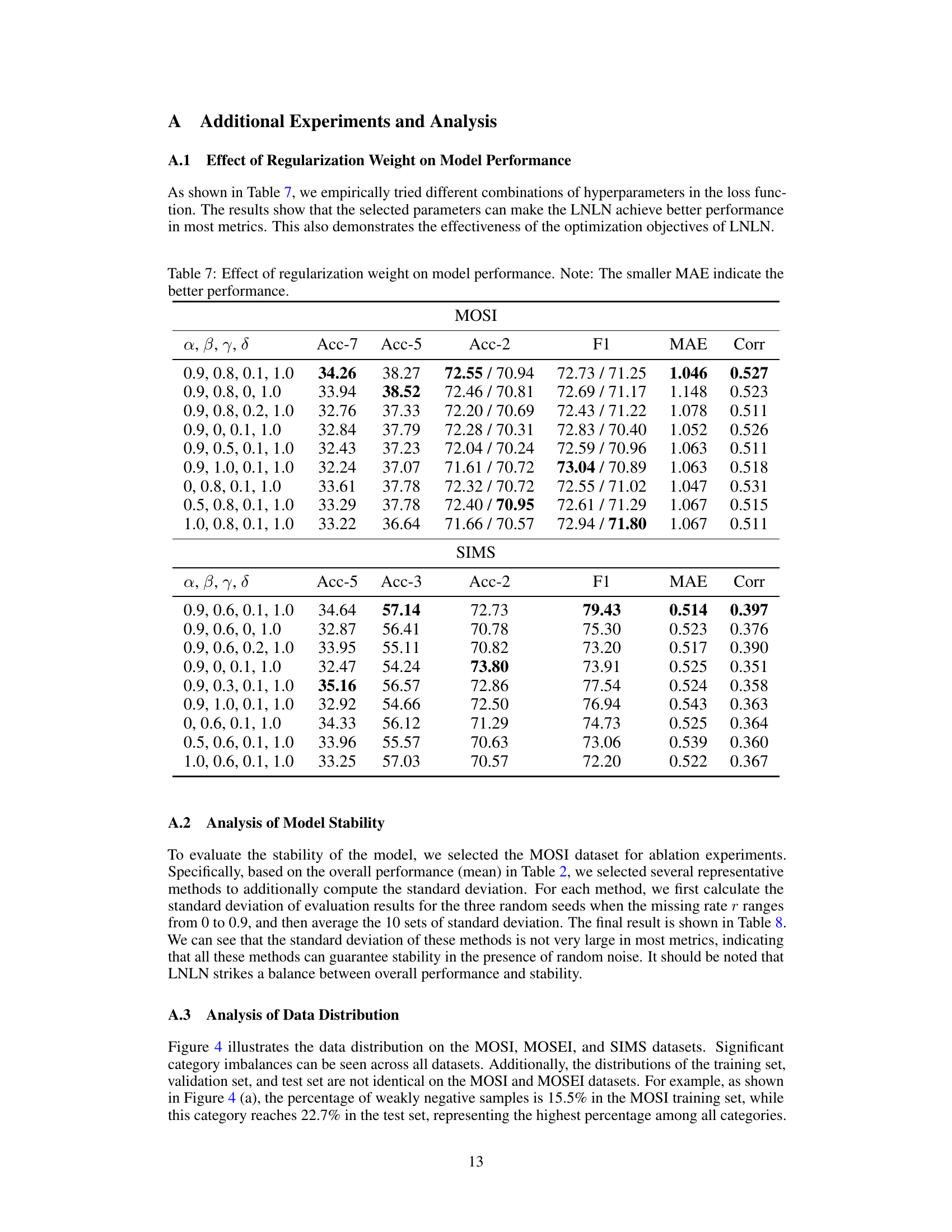
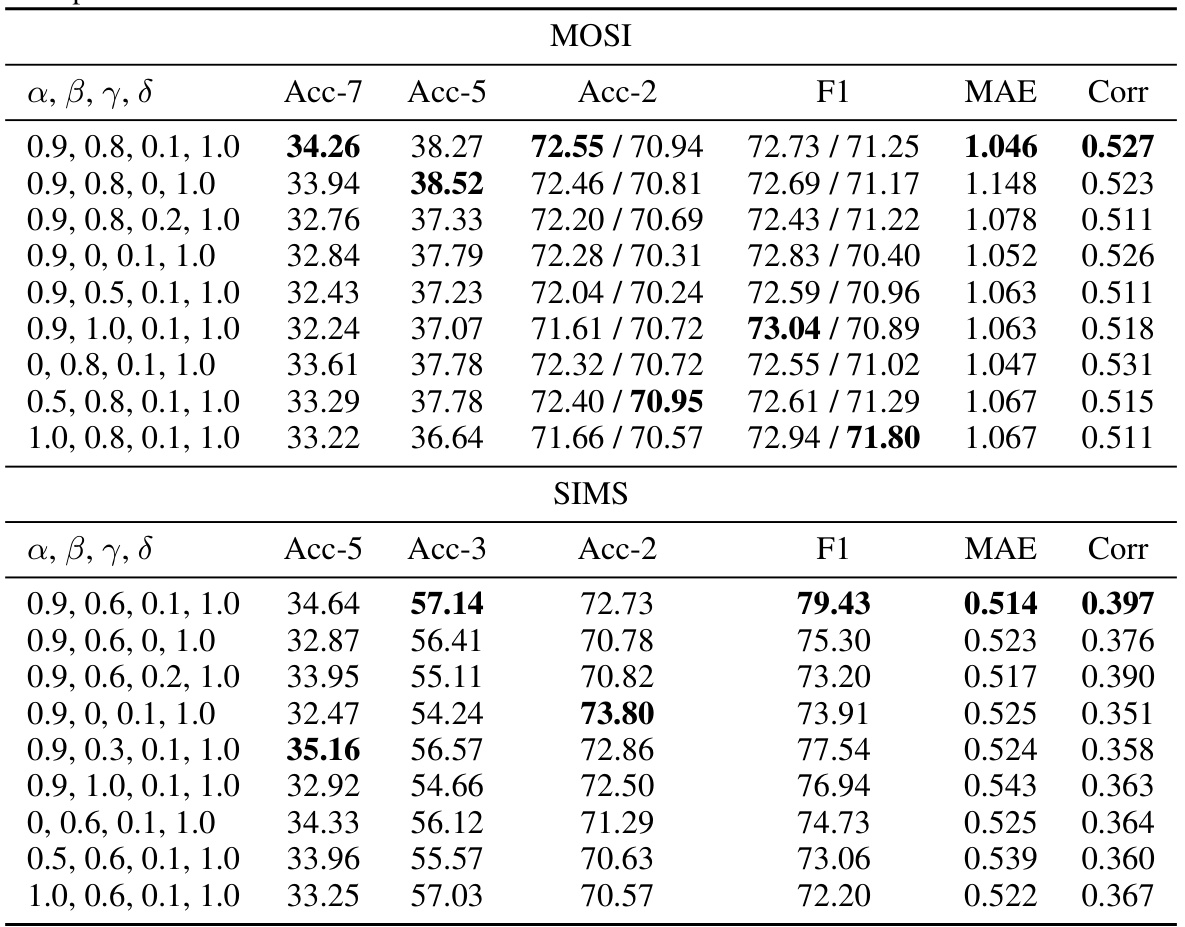
🔼 This table shows the hyperparameters used in the Language-dominated Noise-resistant Learning Network (LNLN) model for three different datasets: MOSI, MOSEI, and SIMS. The hyperparameters include vector length, vector dimension, batch size, initial learning rate, loss weights (α, β, γ, δ), optimizer, number of epochs, usage of warm-up and cosine annealing techniques, early stopping criteria, and the random seed used for reproducibility. The values for these hyperparameters may be adjusted or optimized for different datasets to achieve best performance.
read the caption
Table 1: Hyperparameters of LNLN we use on the different datasets
In-depth insights#
Incomplete MSA#
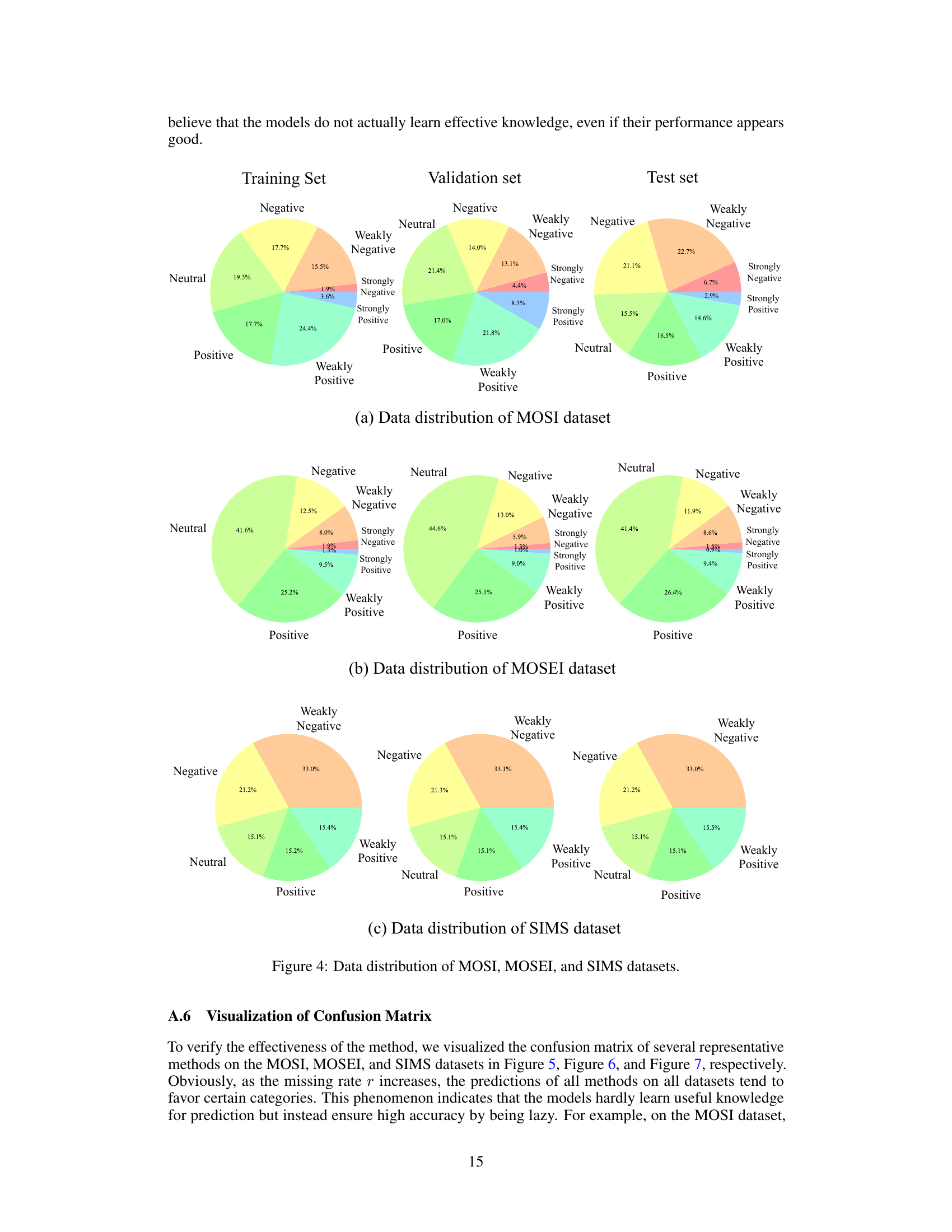
Multimodal Sentiment Analysis (MSA) often faces the challenge of incomplete data, where some modalities (e.g., audio, video, text) might be missing. This incompleteness significantly affects the accuracy and robustness of sentiment prediction. Strategies to address this issue typically focus on either data imputation or noise-resistant learning techniques. Data imputation attempts to fill in missing modalities using available information, often leveraging sophisticated models to reconstruct missing data. Noise-resistant learning, on the other hand, focuses on developing models that are inherently robust to missing information by incorporating mechanisms for handling uncertainty and missing values during training and inference. The choice between these approaches depends on the characteristics of the data and the goals of the analysis. While data imputation aims for accuracy in recovering complete data, noise-resistant learning prioritizes robustness. The ideal solution may involve a combination of both approaches, leveraging the strengths of each method.
LNLN Architecture#
The Language-dominated Noise-resistant Learning Network (LNLN) architecture is designed for robust multimodal sentiment analysis, particularly handling incomplete data. Its core innovation lies in prioritizing the language modality, which typically contains the most sentiment information. LNLN employs a Dominant Modality Correction (DMC) module to refine language features, mitigating noise effects via adversarial learning and weighted enhancement. A Dominant Modality based Multimodal Learning (DMML) module then integrates these corrected language features with audio and visual data, leveraging adaptive hyper-modality learning for effective fusion. Finally, a reconstructor module attempts to recover missing data, further enhancing robustness. This layered design ensures that the dominant modality is prioritized and protected from the negative effects of noise or missing data before multimodal fusion, thus leading to more accurate sentiment predictions.
Robustness Metrics#
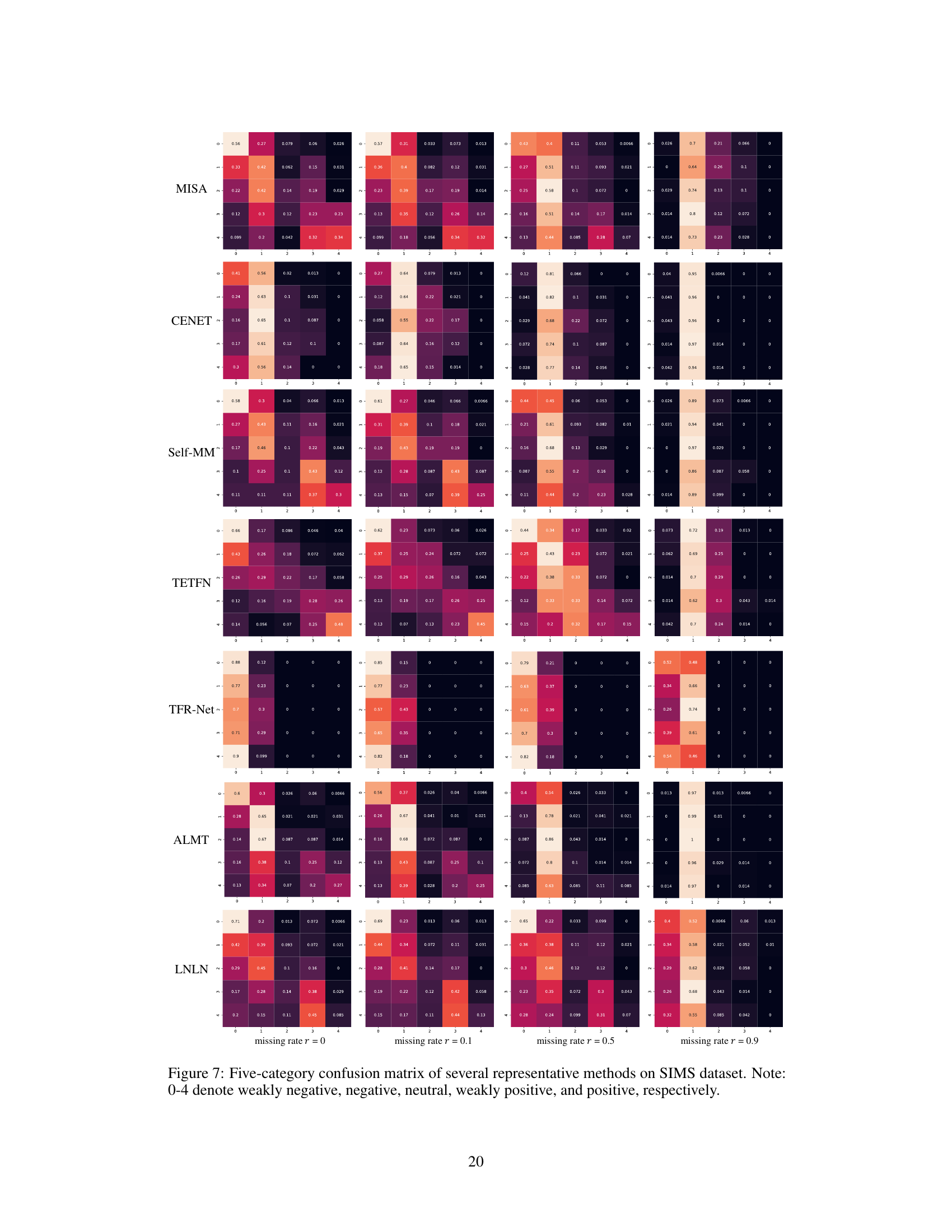
Robustness metrics are crucial for evaluating the performance of multimodal sentiment analysis (MSA) models, especially when dealing with incomplete or noisy data. A comprehensive evaluation should incorporate metrics that assess the model’s resilience to various types of data corruption, including random missing data, sensor noise, and inconsistencies in data alignment. Beyond simple accuracy, F1-score and MAE (Mean Absolute Error) offer insights into the model’s ability to correctly classify different sentiment levels and handle quantitative variations in sentiment intensity. Furthermore, correlation metrics comparing model predictions against human annotations provide another essential perspective, particularly when evaluating subjective aspects of sentiment. The selection of appropriate robustness metrics depends on the specific challenges posed by the dataset and real-world scenarios the model intends to address. A balanced approach is needed to provide a holistic assessment of MSA model robustness.
Future of MSA#
The future of Multimodal Sentiment Analysis (MSA) is bright, but challenging. Robustness remains a key area for improvement, especially in handling incomplete or noisy real-world data. Current methods often struggle with missing modalities or inconsistent data quality. Future research should focus on developing more advanced techniques for handling incomplete data, such as advanced imputation methods and robust representation learning that can effectively model diverse data types and noise. Further exploration of multimodal fusion strategies that account for varying levels of data quality and modality relevance is crucial. A more comprehensive evaluation methodology is needed to ensure fair and robust comparison of MSA methods. Finally, addressing ethical concerns around bias and privacy in MSA is critical for responsible development and deployment of this technology.
LNLN Limitations#
The LNLN model, while demonstrating strong performance in handling incomplete multimodal data, exhibits certain limitations. Its generalization ability across diverse real-world scenarios may be limited, particularly when facing significantly different data distributions or noise types than those encountered during training. The model’s reliance on the language modality as dominant could hinder performance when linguistic cues are weak or unreliable, necessitating improvements to better integrate and weigh other modalities. Further research is needed to enhance robustness in high missing rate situations, where most existing methods struggle, and to investigate its behavior under diverse noise conditions beyond random missing. Finally, the hyperparameter tuning process requires careful attention and might benefit from automated methods to achieve optimal performance across varied datasets and missing rates.
More visual insights#
More on figures

🔼 This figure presents a detailed overview of the Language-Dominated Noise-resistant Learning Network (LNLN) pipeline, highlighting the key components such as the embedding layer, Dominant Modality Correction (DMC) module, Dominant Modality based Multimodal Learning (DMML) module, and Reconstructor. The pipeline starts with a multimodal input that includes language, visual, and audio data, which may have random missing data. The DMC module corrects for noise in the dominant modality (language). The DMML module then integrates the corrected dominant modality with the other modalities, leading to more robust feature representation. A reconstructor is used to reconstruct missing data to further improve robustness. Finally, a classifier outputs the sentiment prediction. The figure illustrates the flow of data through each module, highlighting the interactions and dependencies between them.
read the caption
Figure 1: Overall pipeline. Note: H¹, H², H³, Hcc, and H are randomly initialized learnable vectors.

🔼 This figure presents a comprehensive overview of the Language-dominated Noise-resistant Learning Network (LNLN) pipeline. It illustrates the process of how the model handles multimodal input with random data missing. The input is first standardized using an embedding layer, then processed by the Dominant Modality Correction (DMC) module to improve the quality of dominant modality (language). The Dominant Modality based Multimodal Learning (DMML) module then fuses the corrected dominant modality with auxiliary modalities (audio and visual). Finally, a reconstruction layer reconstructs the missing data, boosting the system’s robustness. The entire process highlights the model’s ability to maintain high-quality representation and achieve robust sentiment analysis despite noise.
read the caption
Figure 1: Overall pipeline. Note: H¹, Hº, Hº, Hcc, and H are randomly initialized learnable vectors.

🔼 This figure presents a detailed illustration of the Language-dominated Noise-resistant Learning Network (LNLN) pipeline for robust multimodal sentiment analysis. The pipeline consists of several key modules: 1) Input Construction and Multimodal Input, which generates a multimodal input with random data missing; 2) Embedding, which standardizes the dimensions of each modality; 3) Dominant Modality Correction (DMC), which mitigates noise impacts using adversarial learning and a dynamic weighted enhancement strategy; 4) Dominant Modality based Multimodal Learning (DMML), which performs multimodal fusion and classification; 5) Reconstructor, which reconstructs missing data. These modules work together to enhance the robustness of LNLN across various noise scenarios. The figure visually demonstrates the flow of data through these modules, highlighting the key processes and learnable parameters within the network architecture.
read the caption
Figure 1: Overall pipeline. Note: H¹, H², H³, Hcc, and HD are randomly initialized learnable vectors.
🔼 This figure presents a schematic overview of the Language-dominated Noise-resistant Learning Network (LNLN). It illustrates the overall processing pipeline, starting with multimodal input (language, visual, audio) which may contain random missing data. The input is then processed sequentially through embedding, dominant modality correction (DMC), dominant modality based multimodal learning (DMML), and a reconstruction layer. The DMC module aims to improve the quality of the dominant language modality despite noise, while DMML integrates the refined language features with other modalities. The reconstruction layer handles missing data. Finally, a classifier produces the sentiment prediction.
read the caption
Figure 1: Overall pipeline. Note: Hl, Hv, Ha, Hcc, and HD are randomly initialized learnable vectors.
🔼 This figure presents a comprehensive overview of the proposed Language-Dominated Noise-resistant Learning Network (LNLN) for robust multimodal sentiment analysis. The pipeline starts with a multimodal input that has undergone random data missing. An embedding layer standardizes the input dimensions. A Dominant Modality Correction (DMC) module is responsible for refining the language modality (considered dominant due to its richer sentiment information), mitigating noise effects via adversarial learning. A Dominant Modality based Multimodal Learning (DMML) module fuses the enhanced dominant modality with auxiliary modalities. Finally, a reconstructor addresses missing data, enhancing robustness. The entire process is designed to achieve robust multimodal sentiment analysis, even with incomplete data.
read the caption
Figure 1: Overall pipeline. Note: H, Hv, Ha, Hcc, and Hd are randomly initialized learnable vectors.

🔼 This figure presents a detailed overview of the Language-dominated Noise-resistant Learning Network (LNLN) pipeline. It illustrates the process of handling multimodal input with missing data through several modules: embedding, dominant modality correction (DMC), dominant modality-based multimodal learning (DMML), and a reconstructor. Each module’s role in mitigating noise and improving sentiment analysis robustness is visualized. The figure highlights the flow of information and the interactions between different components of the LNLN architecture.
read the caption
Figure 1: Overall pipeline. Note: H¹, Hº, Hº, Hcc, and H are randomly initialized learnable vectors.
🔼 This figure presents a detailed illustration of the Language-dominated Noise-resistant Learning Network (LNLN) architecture. The pipeline begins with a multimodal input that incorporates data from three modalities: language, audio, and visual data. After an embedding layer, the Dominant Modality Correction (DMC) module uses an adversarial learning approach to reduce the negative impact of noise on the dominant modality (language). The Dominant Modality based Multimodal Learning (DMML) module then incorporates these features for effective multimodal fusion and classification. Finally, a reconstructor aims to refine the network’s robustness by reconstructing missing data. This comprehensive pipeline enhances the model’s robustness in handling incomplete and noisy data.
read the caption
Figure 1: Overall pipeline. Note: H¹, H², H³, Hcc, and H are randomly initialized learnable vectors.

🔼 This figure presents a schematic overview of the proposed Language-dominated Noise-resistant Learning Network (LNLN) architecture. The pipeline begins with a multimodal input, which is then processed through embedding, Dominant Modality Correction (DMC), and Dominant Modality based Multimodal Learning (DMML) modules. The DMC module addresses noise in the dominant modality (language). The DMML module integrates modalities for effective multimodal fusion and classification. A reconstructor addresses missing data. The final output is the sentiment prediction. The figure also visually illustrates the flow of information and the components of the LNLN.
read the caption
Figure 1: Overall pipeline. Note: H, H0, H0, Hcc, and H are randomly initialized learnable vectors.

🔼 This figure presents a comprehensive overview of the proposed Language-dominated Noise-resistant Learning Network (LNLN) architecture and its training pipeline. It illustrates the process, starting from the multimodal input with random data missing, through various modules such as embedding, dominant modality correction (DMC), dominant modality based multimodal learning (DMML), and reconstructor, ultimately leading to sentiment prediction. The figure highlights the key components of LNLN and their interactions, providing a visual representation of the model’s workflow. The learnable vectors (H¹, Hº, Hº, Hcc, and H) are also indicated, emphasizing the model’s trainable parameters.
read the caption
Figure 1: Overall pipeline. Note: H¹, Hº, Hº, Hcc, and H are randomly initialized learnable vectors.
More on tables
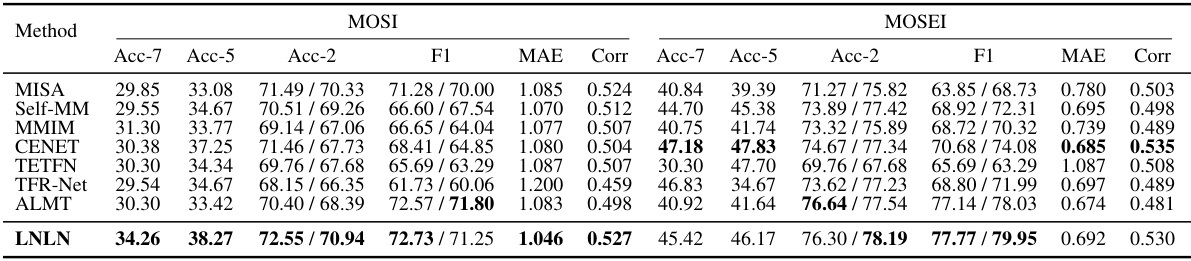
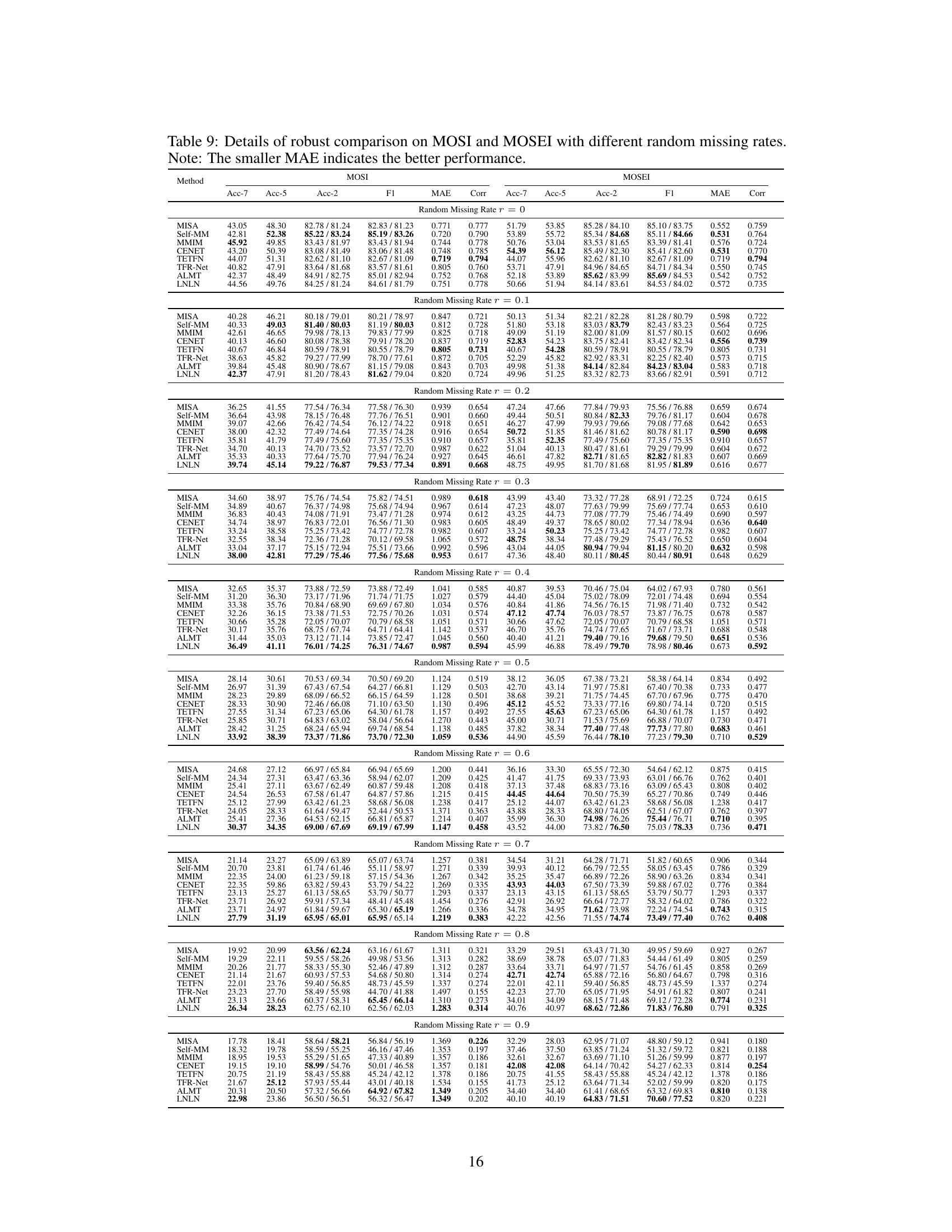
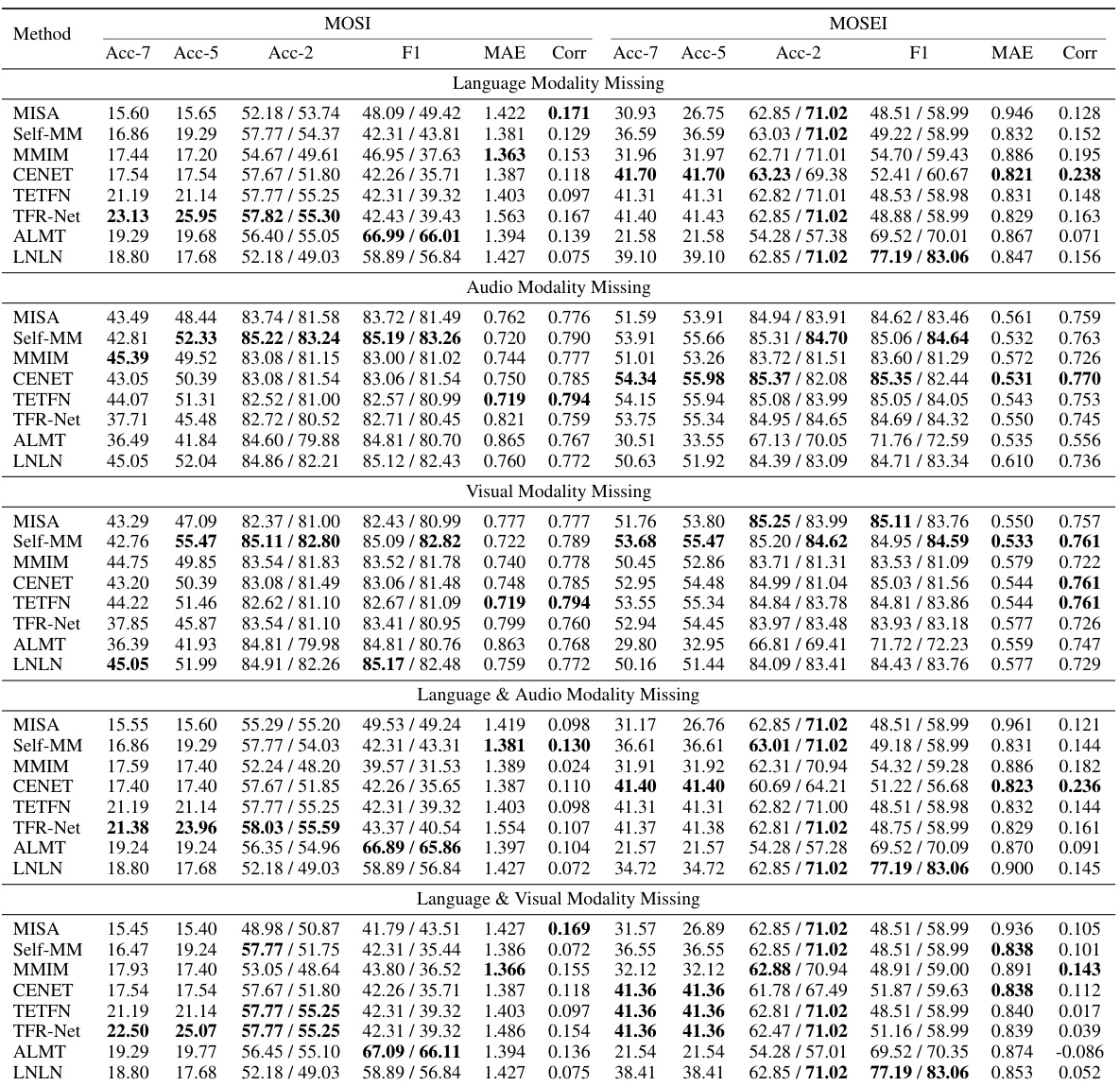
🔼 This table presents a comparison of the performance of several multimodal sentiment analysis (MSA) methods on the MOSI and MOSEI datasets under different levels of data incompleteness (noise). The comparison includes several metrics: binary classification accuracy (Acc-2), F1 score (F1) for the Acc-2, mean absolute error (MAE), and correlation (Corr). The table shows both the negative/positive accuracy and negative/non-negative accuracy for the Acc-2 metric. The lower MAE indicates better performance.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.
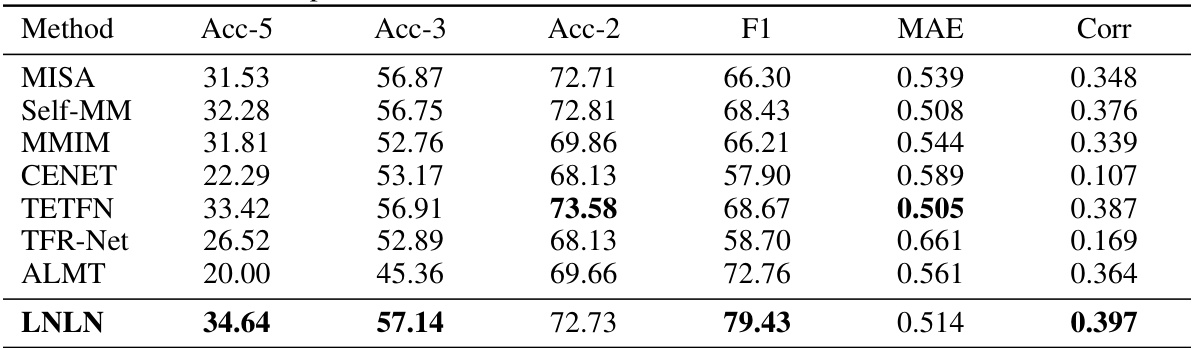
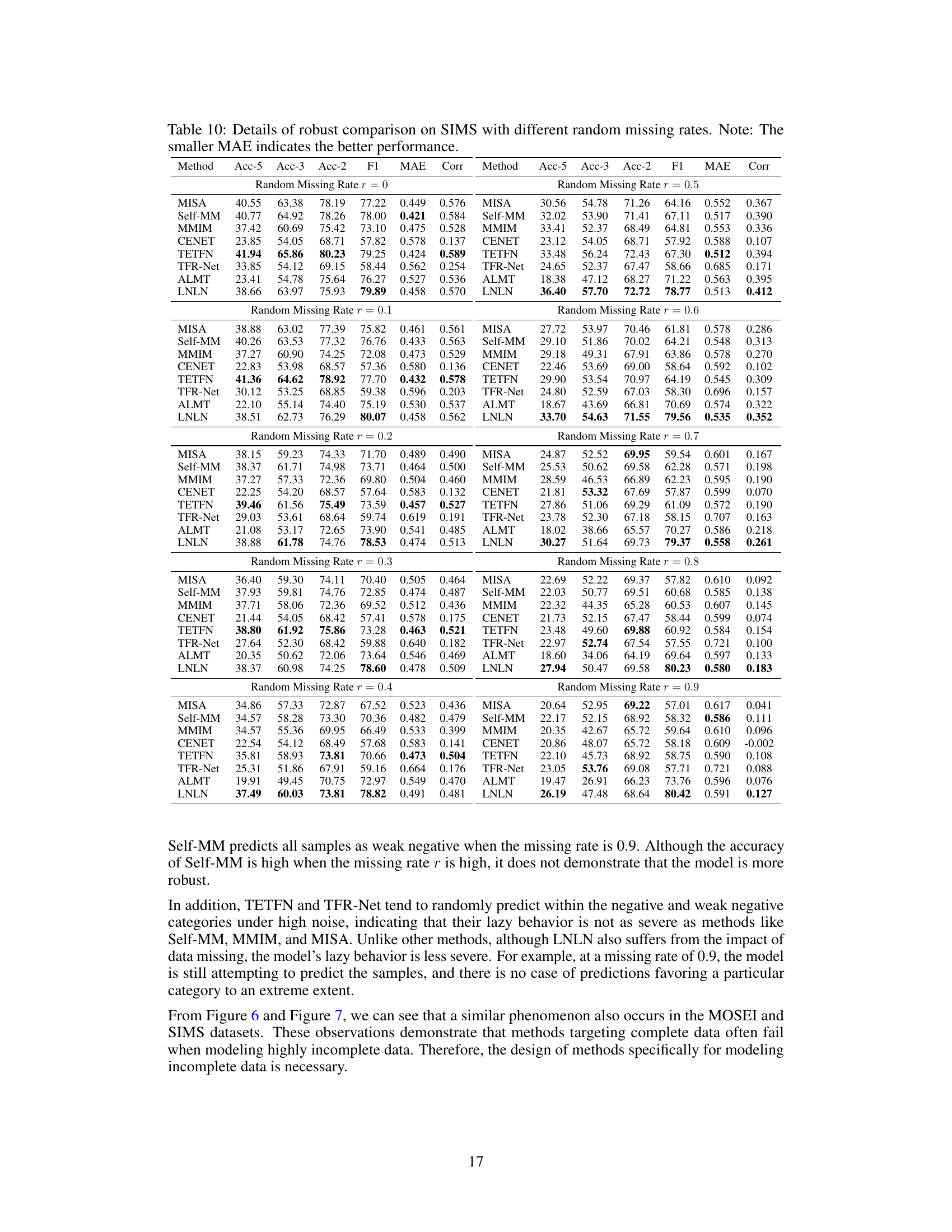
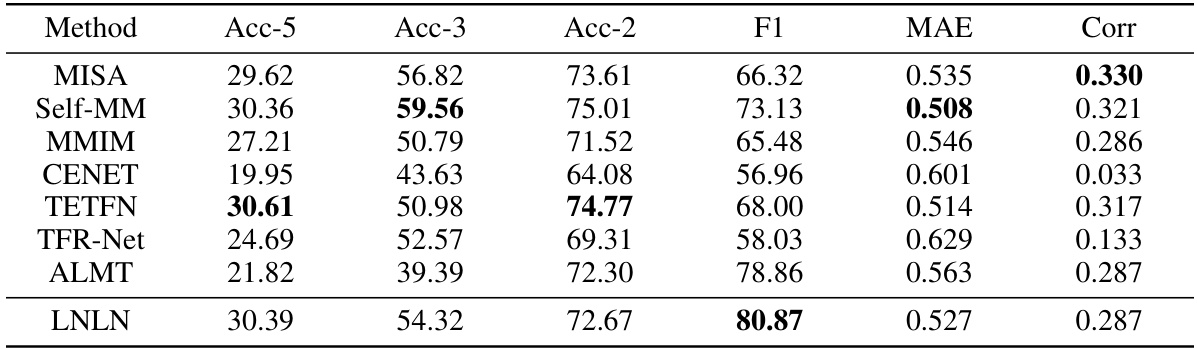
🔼 This table presents a comparison of the performance of several methods on the SIMS dataset under different missing rates. The metrics used include Acc-3 (three-class accuracy), Acc-2 (two-class accuracy), F1 score, MAE (mean absolute error), and Corr (correlation). Lower MAE values indicate better performance.
read the caption
Table 3: Robustness comparison of the overall performance on SIMS dataset. Note: The smaller MAE indicates the better performance.

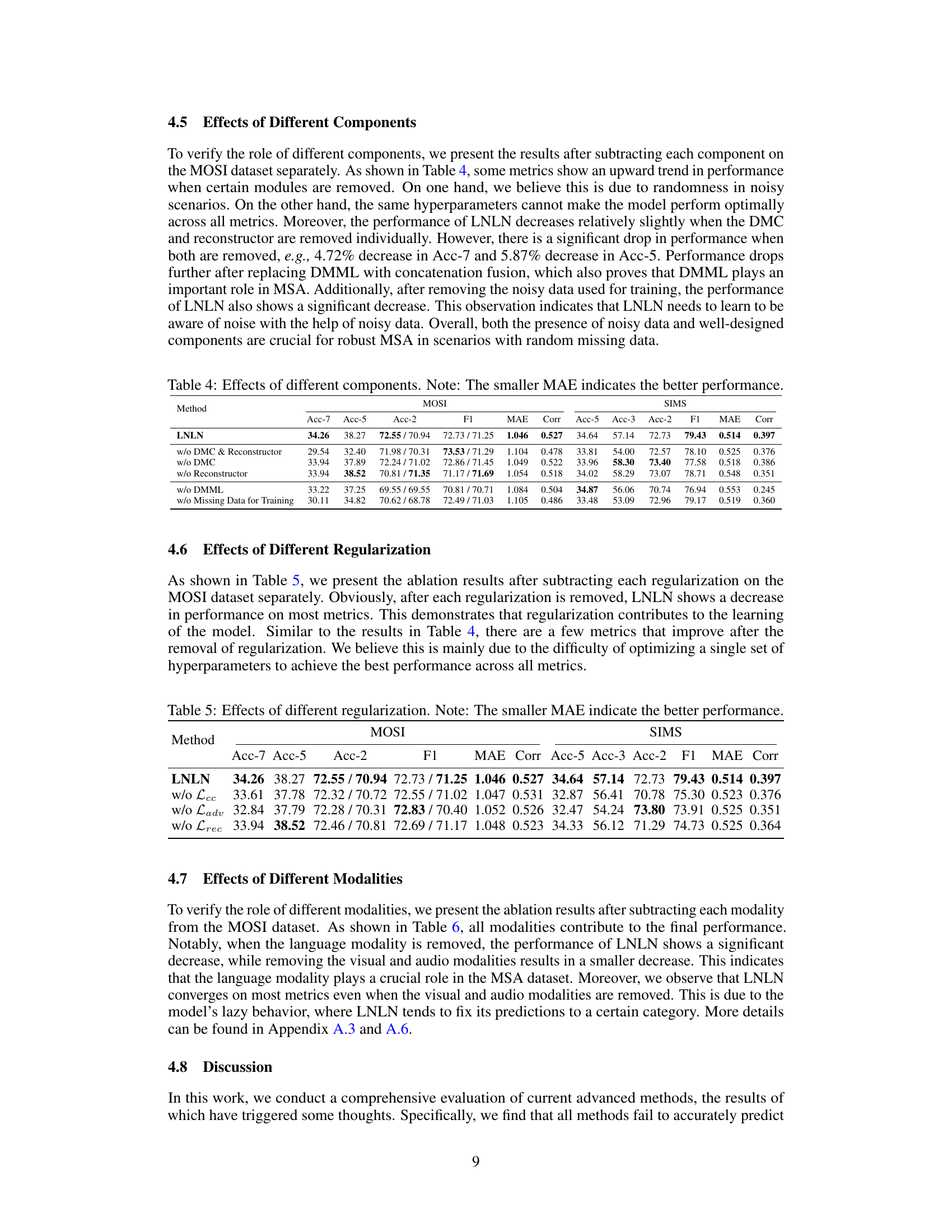
🔼 This table presents the ablation study results on the MOSI dataset by removing different components of the proposed LNLN model. It shows the impact on several metrics (Acc-7, Acc-5, Acc-2, F1, MAE, Corr) when removing the Dominant Modality Correction (DMC) module, the Reconstructor, the Dominant Modality based Multimodal Learning (DMML) module, and the noisy data used for training. The results highlight the importance of each component and the use of noisy data in achieving robust performance.
read the caption
Table 4: Effects of different components. Note: The smaller MAE indicates the better performance.

🔼 This table presents the ablation study results on the MOSI and SIMS datasets by removing different components of the proposed LNLN model. The results demonstrate the impact of each component (Dominant Modality Correction (DMC), Reconstructor, and Dominant Modality based Multimodal Learning (DMML) module) on the overall performance, measured by Acc-7, Acc-5, Acc-2, F1 score, MAE, and correlation (Corr). It also shows the effect of removing noisy data from the training set. The table helps to understand the contribution and importance of each component in achieving robustness against incomplete data.
read the caption
Table 4: Effects of different components. Note: The smaller MAE indicates the better performance.

🔼 This table presents the ablation study results of removing different components from the proposed LNLN model and evaluating its performance on the MOSI and SIMS datasets. The components evaluated include DMC (Dominant Modality Correction) module, Reconstructor, DMML (Dominant Modality based Multimodal Learning) module and the noisy data used for training. The table shows the effects of removing these individual components on the accuracy (Acc-7, Acc-5, Acc-2), F1 score, MAE (Mean Absolute Error), and correlation (Corr) metrics. The results illustrate the importance of each component to the overall performance of LNLN, particularly the combined effect of DMC and Reconstructor.
read the caption
Table 4: Effects of different components. Note: The smaller MAE indicates the better performance.
🔼 This table presents a comparison of the performance of different methods on the MOSI and MOSEI datasets across various noise levels. The metrics used for comparison include binary classification accuracy (Acc-2), F1-score (F1), mean absolute error (MAE), correlation of predictions with human ratings (Corr), three-class accuracy (Acc-3), and seven-class accuracy (Acc-7). Lower MAE values indicate better performance. The table highlights the relative improvements of the proposed method (LNLN) compared to other state-of-the-art methods.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.

🔼 This table presents a comparison of the performance of various multimodal sentiment analysis (MSA) methods on the MOSI and MOSEI datasets. The methods are evaluated under different levels of random data missing. The table shows the accuracy (Acc-2, Acc-7), F1 score, mean absolute error (MAE), and correlation (Corr) for each method on both datasets. The ‘smaller MAE’ indicates better performance, highlighting the robustness of each approach against noisy data.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.

🔼 This table presents a comparison of the overall performance of several different methods on the MOSI and MOSEI datasets across various missing data rates. The performance metrics included are Acc-7 (seven-class accuracy), Acc-5 (five-class accuracy), Acc-2 (binary classification accuracy), F1 (F1-score), MAE (mean absolute error), and Corr (correlation). The table highlights the robustness of each method by showing how well they perform under different noise levels. The smaller the MAE value, the better the performance.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.

🔼 This table presents a comparison of the overall performance of several multimodal sentiment analysis (MSA) methods on the MOSI and MOSEI datasets under different levels of random data missing. The metrics used to evaluate the model performance are three-class accuracy (Acc-3), two-class accuracy (Acc-2), F1 score (F1), mean absolute error (MAE), and correlation (Corr). The table demonstrates the robustness of each method by showing the performance under different percentages of missing data, helping to understand how each method deals with incomplete data.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.

🔼 This table presents a comparison of the performance of various methods on the MOSI and MOSEI datasets under different missing rate conditions. The performance is evaluated using multiple metrics, including accuracy (Acc-2 and Acc-7), F1 score, MAE, and correlation (Corr). The results highlight the robustness and competitiveness of each method in handling incomplete data.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.
🔼 This table presents a comparison of the overall performance of several methods on the SIMS dataset when random modality missing occurs. The results shown include accuracy metrics (Acc-5, Acc-3, Acc-2, F1), mean absolute error (MAE), and correlation (Corr). The experiment parameters are consistent with those used in the random data missing scenario. Lower MAE values indicate better performance.
read the caption
Table 12: Generalization comparison of the overall performance on SIMS dataset with random modality missing. Note: the parameters used for evaluation are consistent with those used for testing in random data missing. The smaller MAE indicates better performance.
🔼 This table presents a comparison of the performance of several Multimodal Sentiment Analysis (MSA) methods on two benchmark datasets, MOSI and MOSEI. The comparison focuses on the robustness of the methods under different levels of random data missing (noise). The metrics used for evaluation include binary and multi-class accuracy (Acc-2, Acc-7), F1 scores, Mean Absolute Error (MAE), and correlation (Corr). The smaller the MAE, the better the performance.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.

🔼 This table presents a comparison of the performance of different methods on MOSI and MOSEI datasets, considering various metrics such as accuracy, F1 score, and MAE. The comparison is done under various levels of random data missing, from 0% to 90%, evaluating the robustness of each model. The results are intended to illustrate the effectiveness of the methods and their ability to handle incomplete data. Lower MAE values are indicative of better performance.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.

🔼 This table presents a comparison of the overall performance of several methods on the MOSI and MOSEI datasets under various levels of random data missing. The metrics used for comparison include binary and multi-class accuracy (Acc-2, Acc-3, Acc-7), F1 score, mean absolute error (MAE), and correlation (Corr). The table highlights the robustness of each model by showing their performance across different levels of data incompleteness (missing rates). The smaller the MAE value, the better the performance.
read the caption
Table 2: Robustness comparison of the overall performance on MOSI and MOSEI datasets. Note: The smaller MAE indicates the better performance.
Full paper#