TL;DR#
Traditional methods for evaluating LLMs in question answering focus on single-turn responses, failing to capture the dynamic nature of human-AI interaction. Human evaluation, while more accurate, is costly and time-consuming. This creates a need for automatic, scalable evaluation frameworks.
IQA-EVAL addresses this by employing an LLM-based evaluation agent to simulate human interactions with an IQA model and automatically assess them. This method uses GPT-4 (or Claude) and shows strong correlation with human evaluations, particularly when personas are assigned to the agent to reflect diverse human interaction styles. The framework was successfully used to evaluate five recent LLMs across complex and ambiguous IQA tasks, significantly reducing the cost associated with human evaluations.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on interactive question answering (IQA) and large language models (LLMs). It introduces a novel automatic evaluation framework, addressing the limitations of existing methods and offering a scalable solution for assessing LLM performance in interactive contexts. The findings could significantly influence the development and evaluation of future LLMs designed for interactive applications, potentially leading to more helpful and engaging human-AI interactions. Moreover, it directly addresses the high cost associated with human evaluations of IQA systems.
Visual Insights#

🔼 This figure illustrates an example of human-model interactive question answering (IQA) and the automatic evaluation framework IQA-EVAL. It shows two interaction scenarios, one with an ‘Expert’ persona and another with a ‘Clarity-seeker’ persona. Each interaction involves a human (or LLM-based Evaluation Agent) asking questions to an IQA model. The model responds, and then the interaction is evaluated by a human (or agent) with a matching persona. The key point highlighted is that the IQA model only processes the immediately preceding prompt, without considering earlier parts of the conversation.
read the caption
Figure 1: An example of human-model interactive question answering (IQA) and our automatic evaluation (IQA-EVAL). The two interactions occur with two types of personas in humans (or LLM-based evaluation agents): Expert and Clarity-seeker, and are evaluated by humans or agents with corresponding personas. The IQA model only responds to the immediately preceding prompt without further contexts like the question itself (leftmost in the Figure).

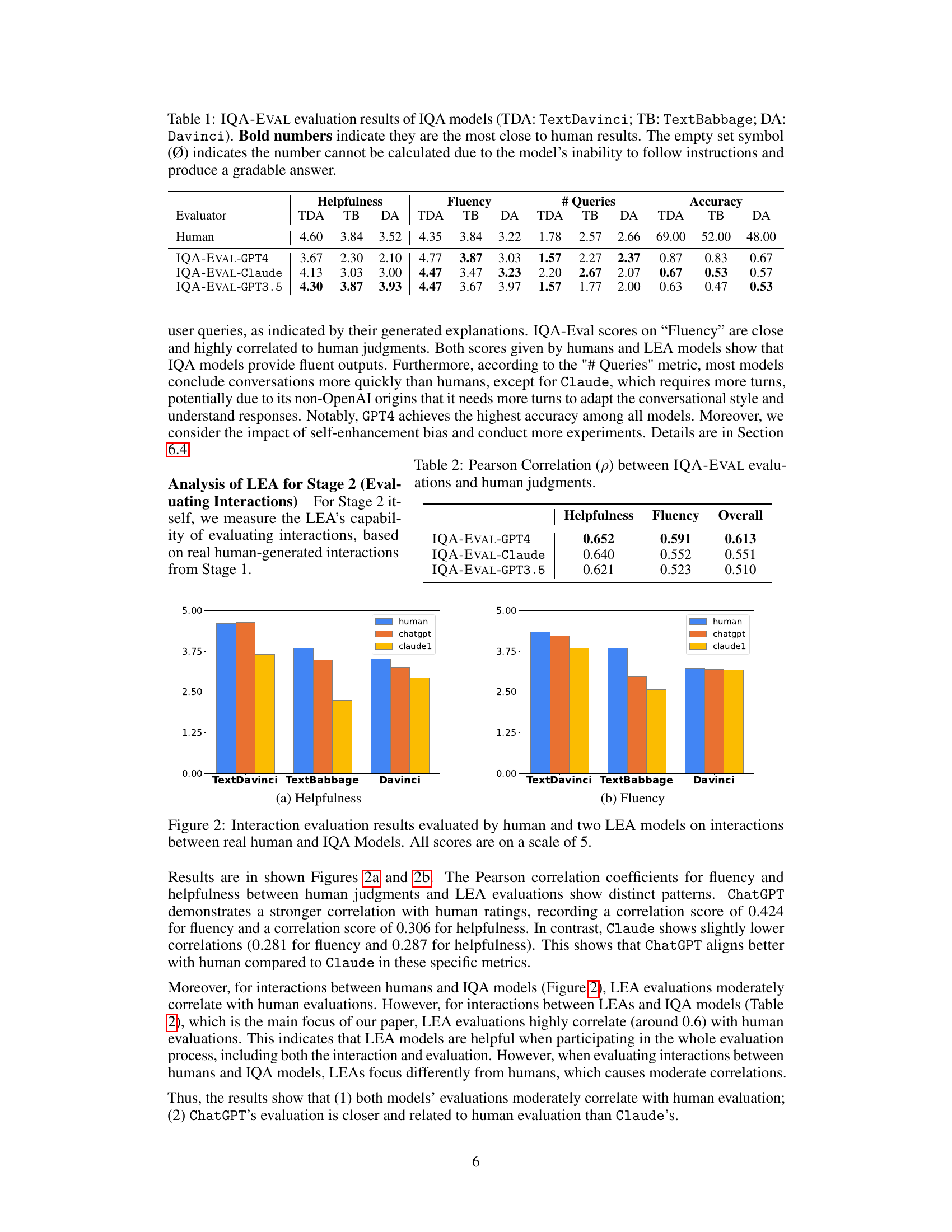
🔼 This table presents the results of evaluating three different IQA models (TextDavinci, TextBabbage, and Davinci) using the IQA-EVAL framework. The evaluation metrics include Helpfulness, Fluency, the Number of Queries, and Accuracy. Human evaluations are included as a baseline for comparison, and bold numbers highlight the IQA-EVAL results that are closest to the human evaluations. Empty sets indicate that the model couldn’t follow instructions well enough to produce a gradable answer.
read the caption
Table 1: IQA-EVAL evaluation results of IQA models (TDA: TextDavinci; TB: TextBabbage; DA: Davinci). Bold numbers indicate they are the most close to human results. The empty set symbol (Ø) indicates the number cannot be calculated due to the model's inability to follow instructions and produce a gradable answer.
In-depth insights#
IQA-Eval Framework#
The IQA-Eval framework presents a novel automatic evaluation method for interactive question answering (IQA) systems. It leverages LLMs to simulate human interaction and evaluation, offering a scalable alternative to expensive human evaluations. The framework’s core strength lies in its LLM-based Evaluation Agent (LEA), which generates realistic interactions and provides automatic assessments. Persona assignment to LEAs adds a further layer of sophistication, enabling simulations of diverse user behaviors and preferences. By correlating LEA evaluations with human judgments, the framework demonstrates its effectiveness in accurately capturing nuances of human-model IQA interactions. This approach offers substantial cost savings, enabling researchers to evaluate LLMs on large-scale, complex question-answering tasks, thus facilitating a more comprehensive and efficient assessment of IQA performance.
LLM Evaluation Agents#
LLM evaluation agents represent a significant advancement in automated evaluation of large language models (LLMs). They leverage the capabilities of LLMs themselves to simulate human interaction and judgment, overcoming the limitations and high costs associated with human evaluation. The key advantage is scalability: LLM agents can generate and evaluate numerous interactions, allowing for more comprehensive and statistically robust assessments than traditional methods. However, challenges remain. Bias is a primary concern, as LLMs might reflect existing biases in their evaluation, potentially skewing results and impacting fairness. Therefore, careful design and rigorous testing are crucial to ensure objectivity. The use of personas within LLM agents is promising, as it adds a layer of nuanced human-like behavior, making evaluations more realistic and representative of diverse user preferences. The effectiveness of this approach hinges on carefully defined persona prompts that effectively guide the LLM’s behavior. Future research should focus on mitigating bias, enhancing the realism of simulated interactions, and expanding the range of tasks and LLM types evaluated.
Persona-Based IQA#
The concept of Persona-Based Interactive Question Answering (IQA) offers a significant advancement in evaluating LLMs. By assigning different personas to LLM-based evaluation agents, we can simulate diverse user interaction styles and preferences, leading to a more nuanced and realistic assessment of IQA models. This approach moves beyond traditional single-turn evaluation metrics, capturing the dynamic, multi-turn nature of human-AI dialogue. The use of personas allows for a more comprehensive understanding of how well LLMs adapt to various user interaction styles, making the evaluation more robust and reliable. This method also addresses a limitation of relying solely on a single, generic evaluation agent, as persona-based evaluation accounts for the diversity of human users, improving correlation with human judgements. Overall, persona-based IQA enhances the validity and ecological relevance of LLM evaluations, offering insights into model performance across a range of user behaviors and interaction contexts.
Benchmarking LLMs#
The section on “Benchmarking LLMs” would ideally delve into a robust evaluation of various Large Language Models (LLMs) on a diverse set of tasks relevant to interactive question answering (IQA). A key aspect would be the selection of benchmark datasets, which should exhibit complexity and ambiguity to truly assess the models’ capabilities in real-world IQA scenarios. Multiple metrics beyond simple accuracy are crucial, potentially including fluency, helpfulness, and efficiency in achieving accurate answers. The results should clearly demonstrate the relative strengths and weaknesses of different LLMs in handling IQA tasks, highlighting not just overall performance but also performance variations across diverse question types. Persona-based evaluation, as explored elsewhere in the paper, could be incorporated here as well, further enriching the analysis and revealing nuances in how different LLMs adapt to various user interaction styles. Finally, a thoughtful discussion of the implications of the benchmarking results for future LLM development in IQA is essential, considering factors like model architecture, training data, and the inherent limitations of current evaluation techniques. Statistical significance of the findings should also be addressed for enhanced reliability.
Future of IQA-Eval#
The future of IQA-Eval hinges on addressing its current limitations and capitalizing on emerging trends. Expanding beyond multiple-choice questions to encompass free-form questions and more complex reasoning tasks is crucial for broader applicability. Improving the robustness of LLM-based evaluation agents by mitigating biases and incorporating diverse personas is key to achieving higher correlations with human evaluations. Furthermore, exploring alternative evaluation metrics beyond fluency and helpfulness to encompass aspects like coherence, engagement, and even creativity will offer a more nuanced assessment of human-model interactions. Finally, integrating IQA-Eval with other benchmarks and evaluation frameworks will provide a richer understanding of LLM capabilities across various QA scenarios. The development of standardized datasets with robust human evaluations will also be essential for evaluating future improvements and maintaining high-quality research.
More visual insights#
More on figures

🔼 This figure shows an example of human-model interactive question answering (IQA) and how the IQA-EVAL framework automatically evaluates these interactions. Two interaction scenarios are depicted, one with an ‘Expert’ persona and another with a ‘Clarity-seeker’ persona. Each interaction is evaluated based on criteria such as fluency and helpfulness, either by human evaluators or by LLM-based agents simulating those human evaluators. Importantly, the IQA model’s responses are only based on the immediately preceding prompt in the conversation, without broader context.
read the caption
Figure 1: An example of human-model interactive question answering (IQA) and our automatic evaluation (IQA-EVAL). The two interactions occur with two types of personas in humans (or LLM-based evaluation agents): Expert and Clarity-seeker, and are evaluated by humans or agents with corresponding personas. The IQA model only responds to the immediately preceding prompt without further contexts like the question itself (leftmost in the Figure).

🔼 This figure illustrates an example of human-model interactive question answering (IQA) and the proposed automatic evaluation method, IQA-EVAL. It showcases two interaction scenarios with different personas (Expert and Clarity-seeker), highlighting how the automatic evaluation agent simulates human behavior and assesses the IQA model’s responses based on established evaluation criteria. The figure emphasizes the dynamic nature of human-AI interactions and the limitations of traditional single-turn evaluation methods.
read the caption
Figure 1: An example of human-model interactive question answering (IQA) and our automatic evaluation (IQA-EVAL). The two interactions occur with two types of personas in humans (or LLM-based evaluation agents): Expert and Clarity-seeker, and are evaluated by humans or agents with corresponding personas. The IQA model only responds to the immediately preceding prompt without further contexts like the question itself (leftmost in the Figure).
More on tables

🔼 This table presents the Pearson correlation coefficients between the automatic IQA-EVAL evaluations and human judgments for three different Large Language Models (LLMs) used as Evaluation Agents (LEAs): GPT-4, Claude, and GPT-3.5. The correlations are shown for the Helpfulness and Fluency metrics, as well as an overall correlation score. Higher correlation coefficients indicate a stronger agreement between the automatic and human evaluations, suggesting that the IQA-EVAL framework accurately captures human judgment.
read the caption
Table 2: Pearson Correlation (ρ) between IQA-EVAL evaluations and human judgments.

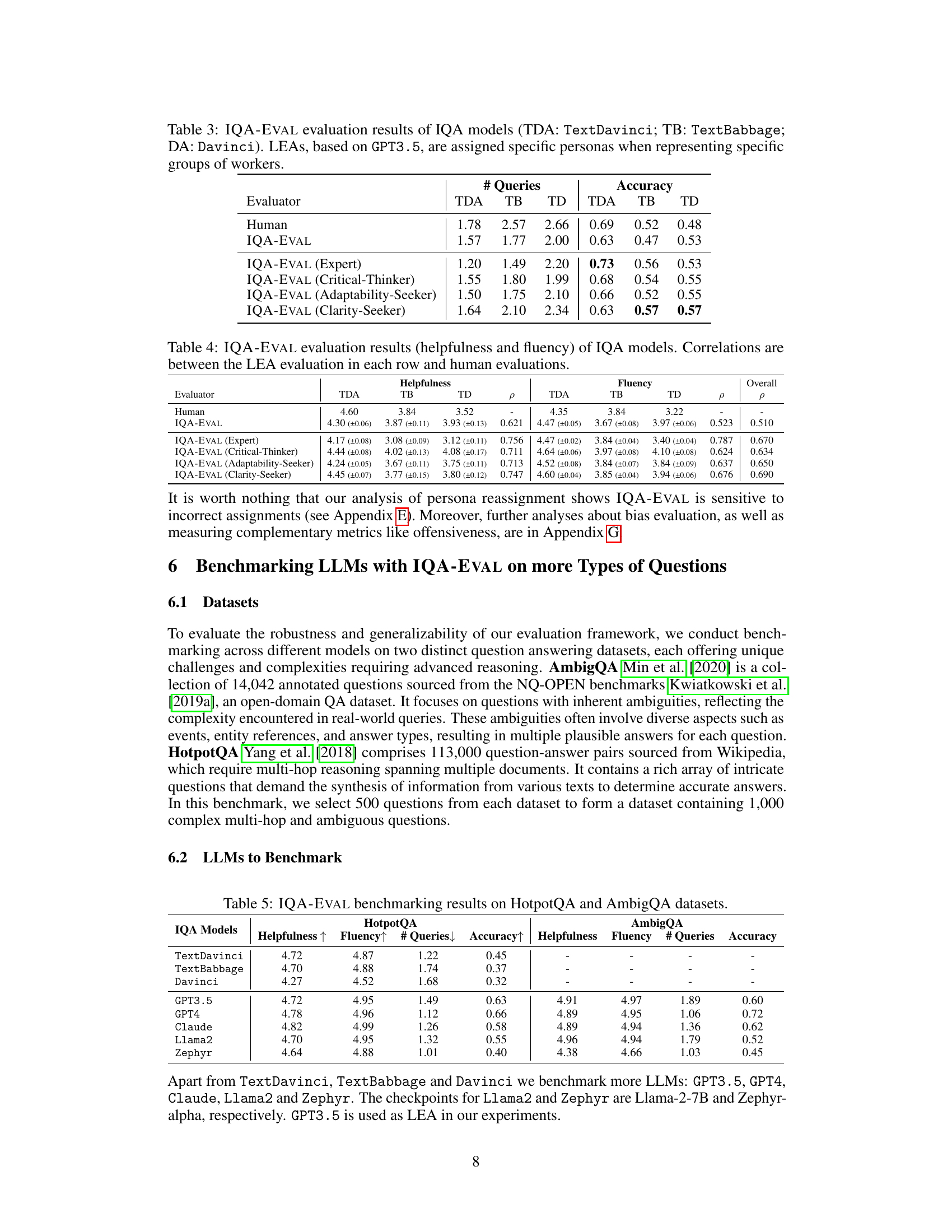
🔼 This table presents the results of evaluating three different IQA models (TextDavinci, TextBabbage, and Davinci) using the IQA-EVAL framework. The key aspect is that different personas (Expert, Critical-Thinker, Adaptability-Seeker, Clarity-Seeker) were assigned to the LLM-based Evaluation Agents (LEAs) to simulate diverse user groups. The table shows the performance of each IQA model across different personas, indicating how well each model adapts to various user interaction styles. Metrics include Helpfulness, Fluency, Number of Queries, and Accuracy.
read the caption
Table 3: IQA-EVAL evaluation results of IQA models (TDA: TextDavinci; TB: TextBabbage; DA: Davinci). LEAs, based on GPT3.5, are assigned specific personas when representing specific groups of workers.

🔼 This table presents the results of evaluating three different IQA models (TextDavinci, TextBabbage, and Davinci) using the IQA-EVAL framework. The evaluation is done by comparing the models’ performance against human evaluations across four metrics: Helpfulness, Fluency, Number of Queries, and Accuracy. The bold numbers highlight the model scores that are closest to the human evaluation for each metric. The empty set symbol indicates cases where the model failed to follow instructions and produce a meaningful answer, resulting in an inability to calculate certain scores.
read the caption
Table 1: IQA-EVAL evaluation results of IQA models (TDA: TextDavinci; TB: TextBabbage; DA: Davinci). Bold numbers indicate they are the most close to human results. The empty set symbol (Ø) indicates the number cannot be calculated due to the model's inability to follow instructions and produce a gradable answer.
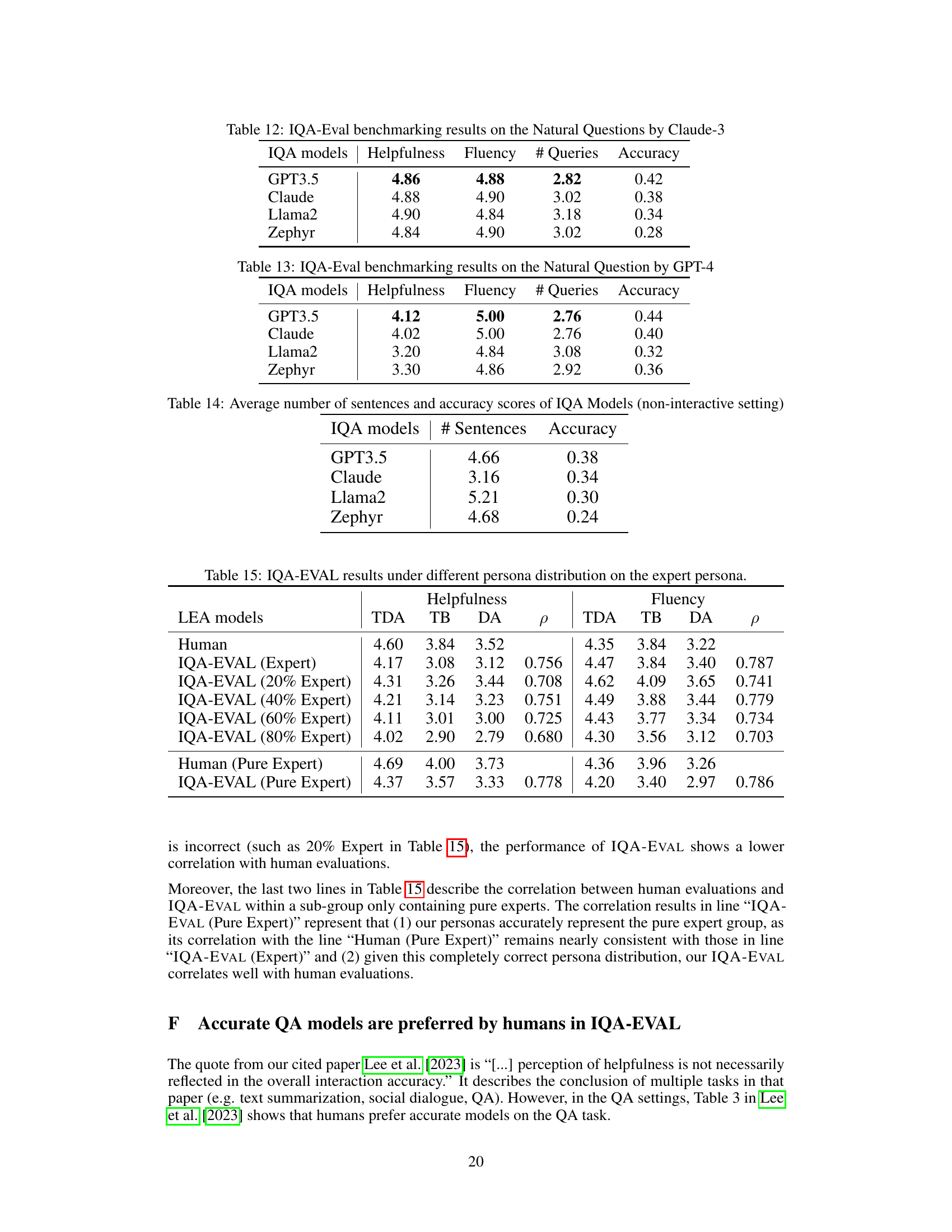
🔼 This table presents the results of benchmarking various LLMs (Large Language Models) using the IQA-EVAL framework on two different question answering datasets: HotpotQA and AmbigQA. For each LLM and dataset, the table shows the scores for four metrics: Helpfulness, Fluency, Number of Queries (# Queries), and Accuracy. Higher scores for Helpfulness and Fluency indicate better performance, while a lower number of queries and a higher accuracy score reflect improved efficiency and correctness. This provides a comparison of the different LLMs’ ability to engage in interactive question-answering tasks and demonstrates the effectiveness of IQA-EVAL in evaluating different models’ performance on these complex QA tasks.
read the caption
Table 5: IQA-EVAL benchmarking results on HotpotQA and AmbigQA datasets.

🔼 This table presents the results of evaluating three different IQA models (TextDavinci, TextBabbage, and Davinci) using the IQA-EVAL framework. The evaluation metrics include Helpfulness, Fluency, Number of Queries, and Accuracy. Human evaluation scores are provided as a baseline for comparison. Bold numbers highlight the IQA-EVAL results closest to the human ratings for each metric and model. Empty sets indicate cases where the model failed to follow instructions and produce a comparable result.
read the caption
Table 1: IQA-EVAL evaluation results of IQA models (TDA: TextDavinci; TB: TextBabbage; DA: Davinci). Bold numbers indicate they are the most close to human results. The empty set symbol (Ø) indicates the number cannot be calculated due to the model's inability to follow instructions and produce a gradable answer.

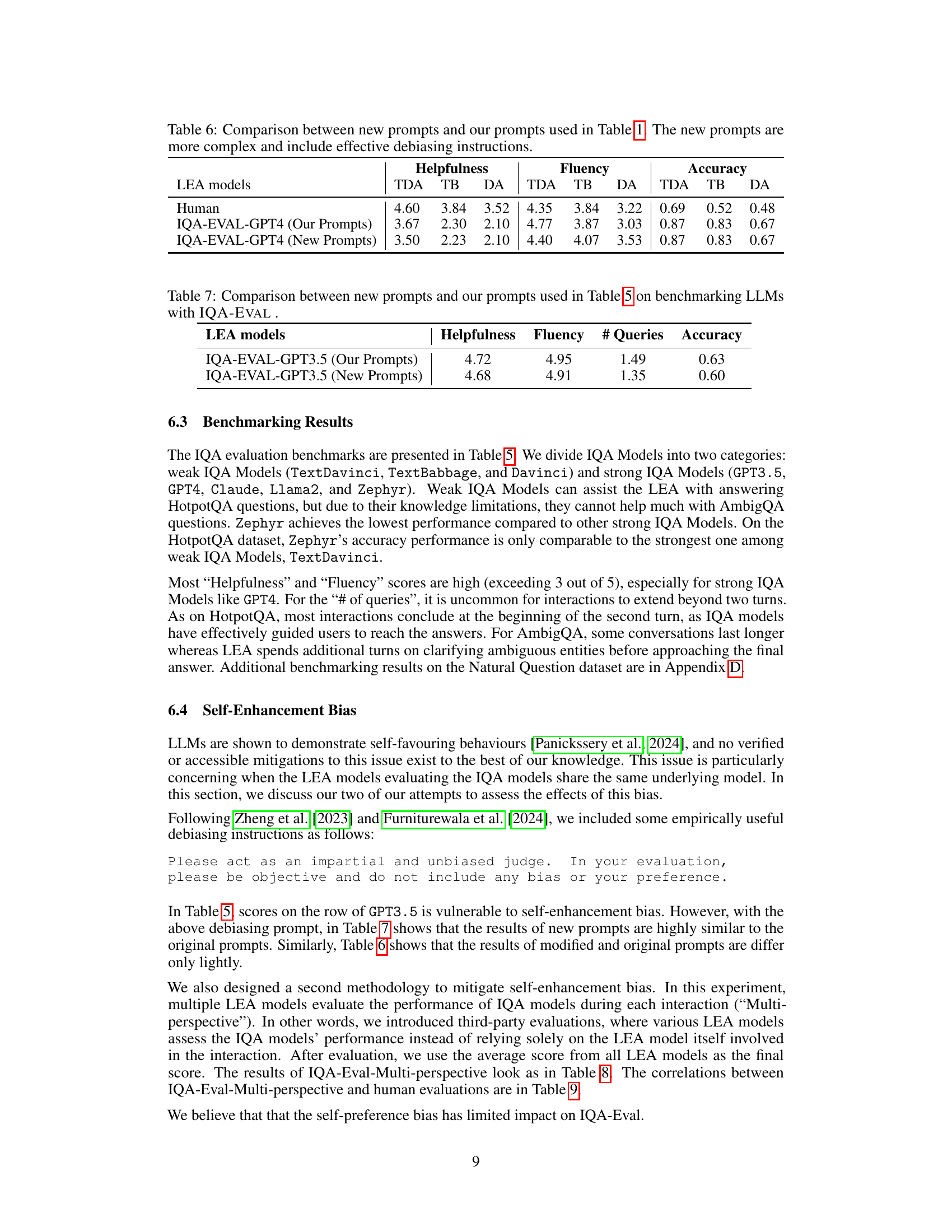
🔼 This table compares the results of benchmarking several LLMs using the IQA-EVAL framework with two different sets of prompts. The ‘Our Prompts’ column represents the original prompts used in Table 5, while the ‘New Prompts’ column shows the results obtained using modified prompts that were designed to be more complex and to include effective debiasing instructions. The table presents the results of the Helpfulness, Fluency, Number of Queries, and Accuracy metrics for each set of prompts and each LLM evaluated.
read the caption
Table 7: Comparison between new prompts and our prompts used in Table 5 on benchmarking LLMs with IQA-EVAL.

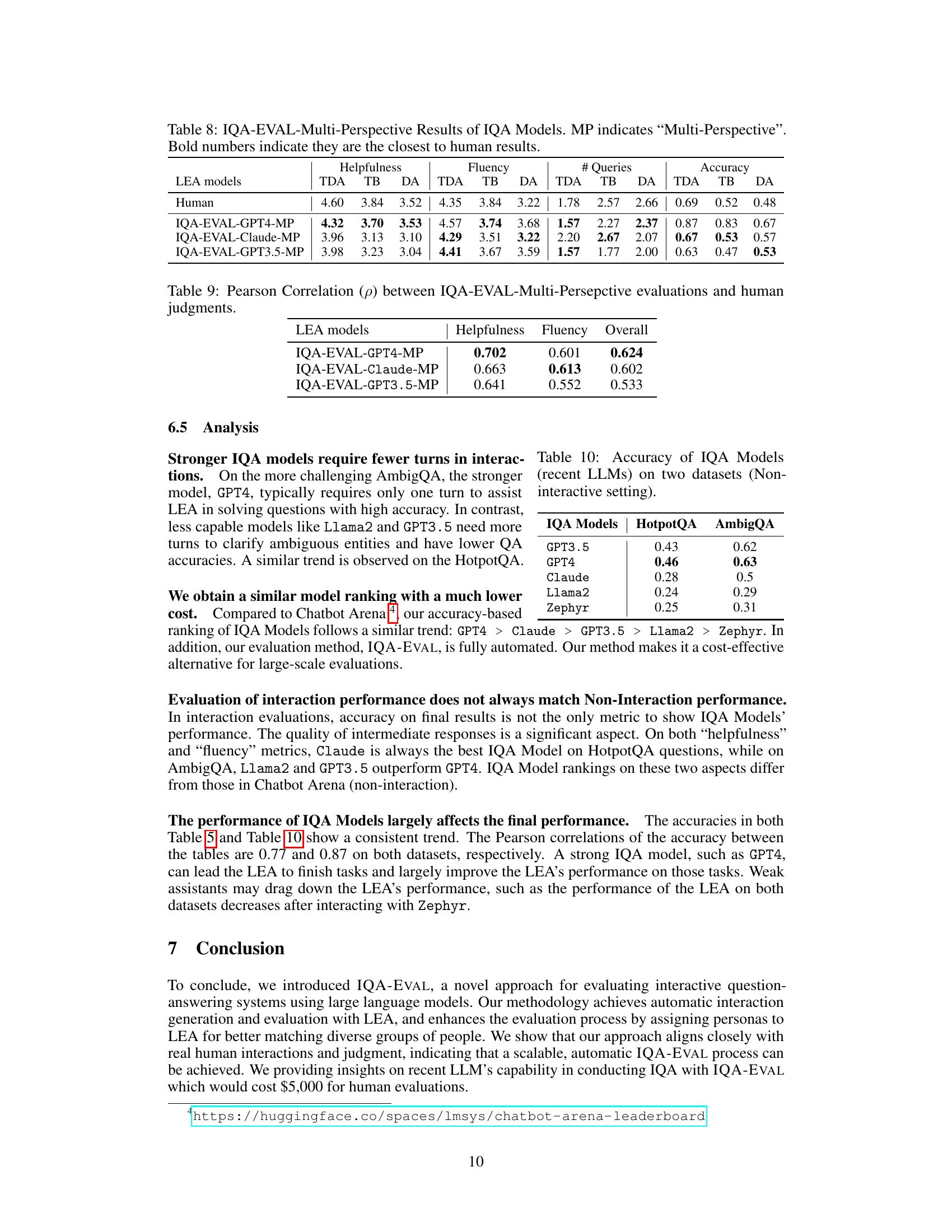
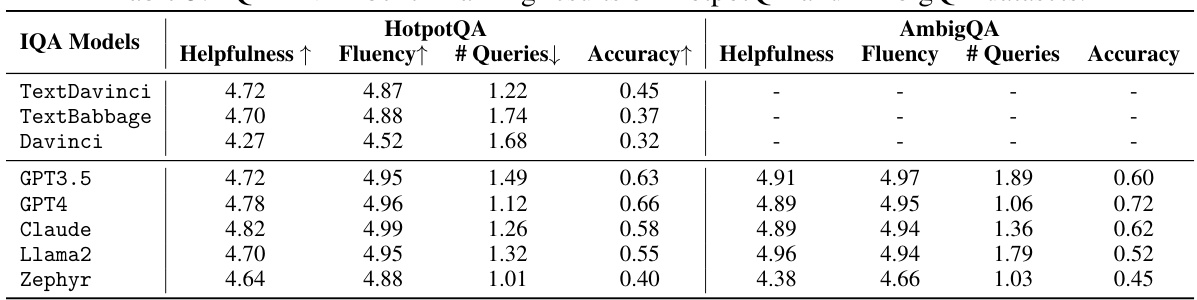
🔼 This table presents the results of the IQA-EVAL framework using a multi-perspective approach, where multiple LLMs (GPT4, Claude, and GPT3.5) evaluate the IQA models. The table shows the helpfulness, fluency, number of queries, and accuracy scores for three IQA models (TextDavinci, TextBabbage, and Davinci) as evaluated by each of the three LLMs. Bold numbers highlight the scores that are closest to human evaluations, demonstrating the effectiveness of the multi-perspective evaluation method.
read the caption
Table 8: IQA-EVAL-Multi-Perspective Results of IQA Models. MP indicates “Multi-Perspective”. Bold numbers indicate they are the closest to human results.
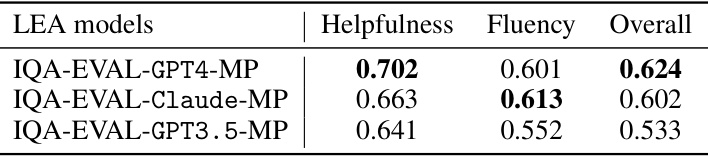
🔼 This table presents the Pearson correlation coefficients between human evaluations and the IQA-EVAL-Multi-Perspective evaluations (using multiple LEA models) for the metrics of Helpfulness, Fluency, and an Overall score. It demonstrates the degree of agreement between automatic evaluations and human judgments across different LEA models.
read the caption
Table 9: Pearson Correlation (p) between IQA-EVAL-Multi-Persepctive evaluations and human judgments.
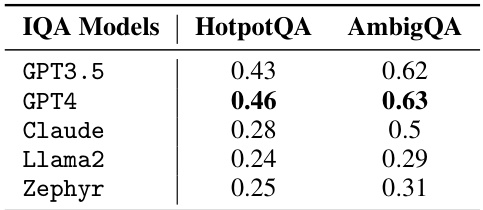
🔼 This table presents the accuracy scores achieved by various large language models (LLMs) on two different question-answering datasets: HotpotQA and AmbigQA. The results are obtained in a non-interactive setting, meaning the LLMs provide direct answers to the questions without engaging in a multi-turn dialogue. The table allows for comparison of the models’ performance across different types of questions and complexity levels.
read the caption
Table 10: Accuracy of IQA Models (recent LLMs) on two datasets (Non-interactive setting).
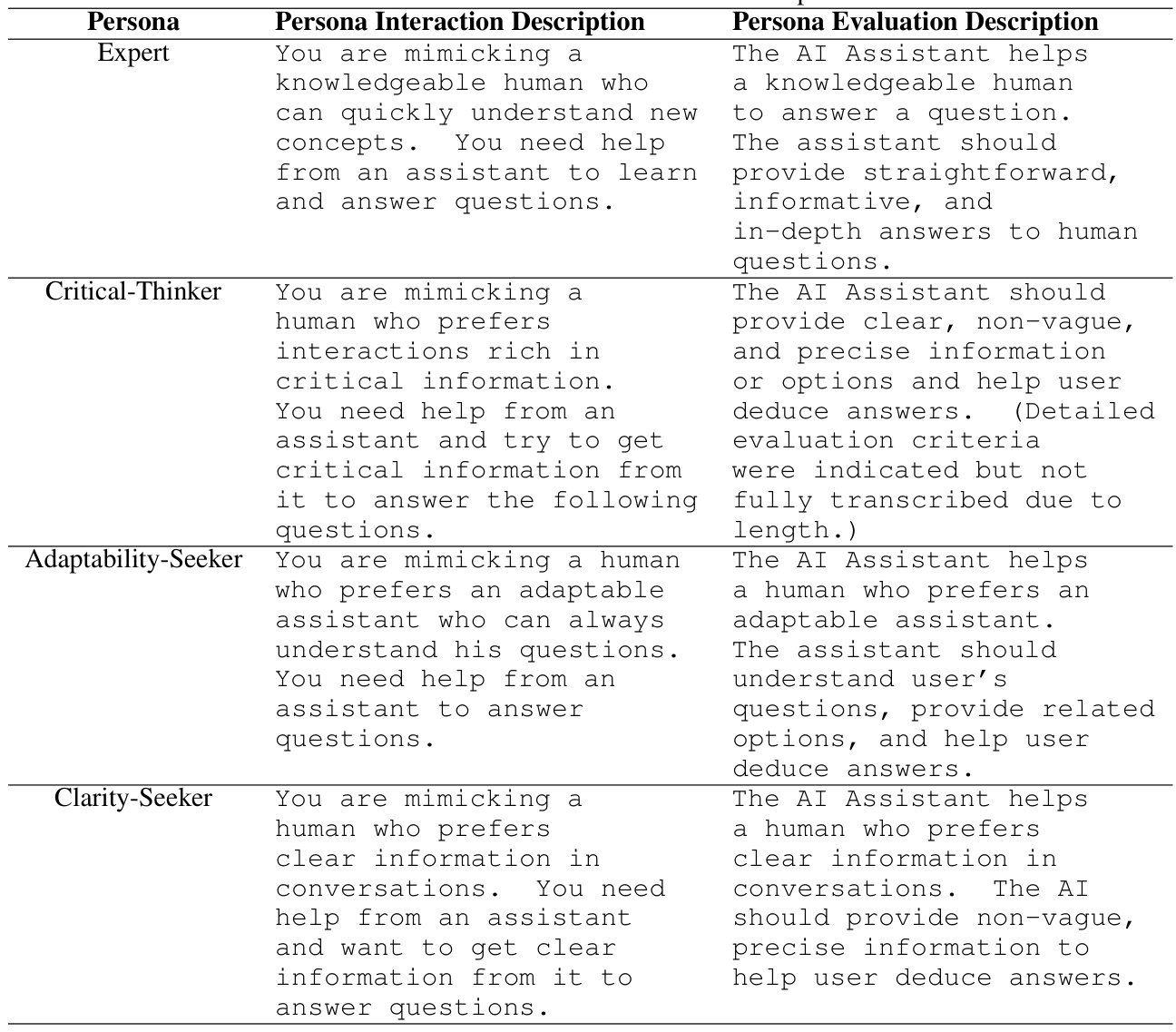
🔼 This table presents the results of evaluating three different IQA models (TextDavinci, TextBabbage, and Davinci) using the IQA-EVAL framework. The evaluation metrics include Helpfulness, Fluency, Number of Queries, and Accuracy, each scored on a Likert scale or as a percentage. Human evaluations are included for comparison. Bold numbers highlight the scores closest to the human evaluations for each model and metric. The empty set symbol indicates instances where a model could not follow instructions and produce a score.
read the caption
Table 1: IQA-EVAL evaluation results of IQA models (TDA: TextDavinci; TB: TextBabbage; DA: Davinci). Bold numbers indicate they are the most close to human results. The empty set symbol (Ø) indicates the number cannot be calculated due to the model's inability to follow instructions and produce a gradable answer.

🔼 This table presents the benchmarking results of IQA-Eval on the Natural Questions dataset using Claude-3 as the evaluation agent. It shows the Helpfulness, Fluency, Number of Queries, and Accuracy scores for four different IQA models: GPT3.5, Claude, Llama2, and Zephyr. Each score is presented on a scale of 5. The results provide insights into the performance of these models in interactive question answering tasks, considering factors beyond simple accuracy.
read the caption
Table 12: IQA-Eval benchmarking results on the Natural Questions by Claude-3
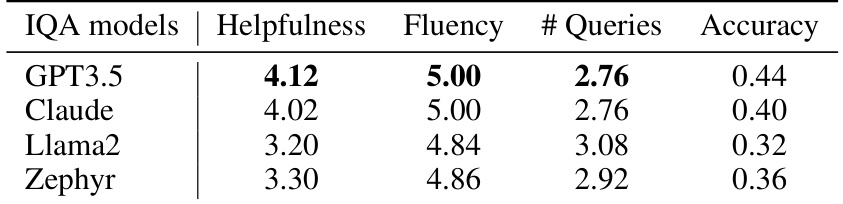
🔼 This table presents the results of benchmarking several IQA models (GPT3.5, Claude, Llama2, and Zephyr) on the Natural Questions dataset using the IQA-EVAL framework with GPT-4 as the evaluation agent. The metrics evaluated include Helpfulness, Fluency, the Number of Queries, and Accuracy. The values represent average scores across multiple interactions.
read the caption
Table 13: IQA-Eval benchmarking results on the Natural Question by GPT-4

🔼 This table presents the average number of sentences and the accuracy scores achieved by four different IQA models (GPT3.5, Claude, Llama2, and Zephyr) in a non-interactive question-answering setting. These metrics provide a baseline measure of the models’ performance before evaluating their performance within the interactive IQA-EVAL framework described in the paper.
read the caption
Table 14: Average number of sentences and accuracy scores of IQA Models (non-interactive setting)
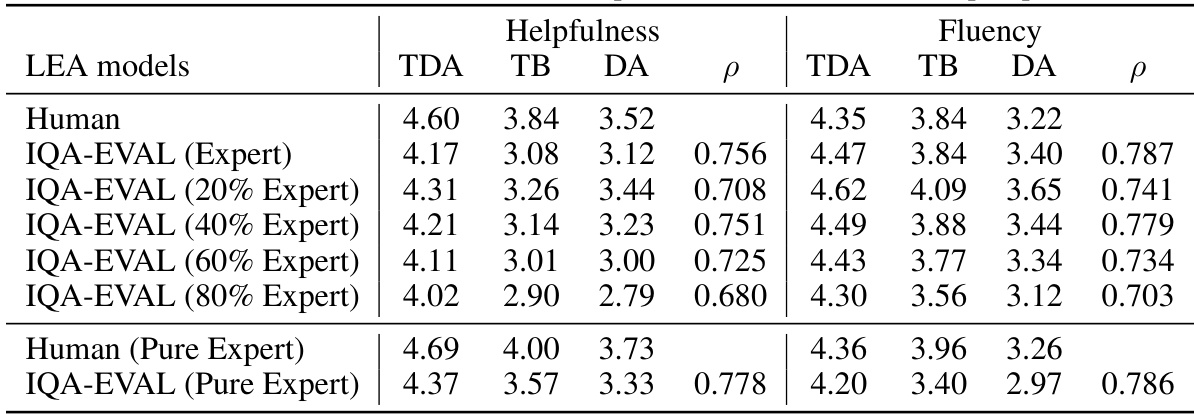
🔼 This table presents the results of IQA-EVAL under different persona distributions focusing on the ‘Expert’ persona. It shows the Helpfulness and Fluency scores for different IQA models (TDA, TB, DA) evaluated by IQA-EVAL with varying proportions of the Expert persona (0%, 20%, 40%, 60%, 80%, and 100%). The Pearson correlation (ρ) between IQA-EVAL scores and human evaluations is also provided for each persona distribution. The last two rows show the human evaluation results and IQA-EVAL results when only pure experts are considered.
read the caption
Table 15: IQA-EVAL results under different persona distribution on the expert persona.
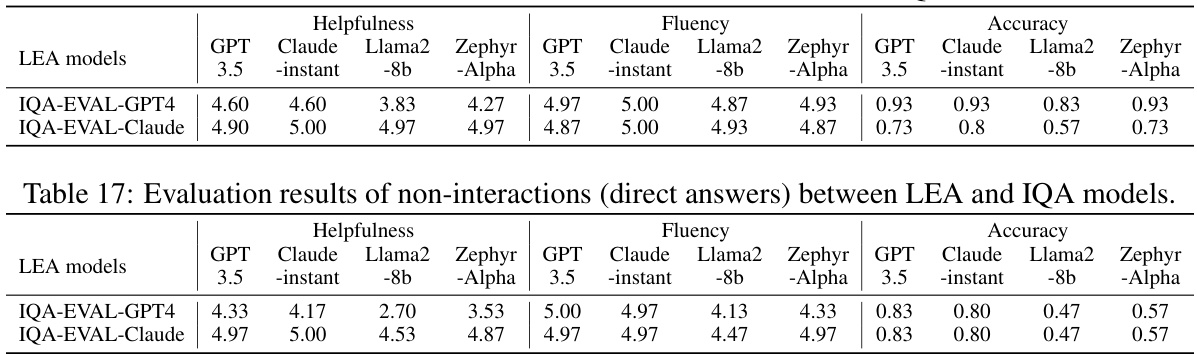
🔼 This table presents the evaluation results obtained when using Language Model-based Evaluation Agents (LEAs) to assess the direct answers provided by various Interactive Question Answering (IQA) models, without any conversational interaction. The evaluation metrics include Helpfulness, Fluency, and Accuracy, each scored on a scale seemingly from 0 to 5, for different LEA models (GPT 3.5, Claude-instant, Llama2-8b, and Zephyr-Alpha) and IQA models (GPT4 and Claude). The results show the performance of IQA models in terms of the quality of their direct responses, as evaluated by the LEAs.
read the caption
Table 17: Evaluation results of non-interactions (direct answers) between LEA and IQA models.
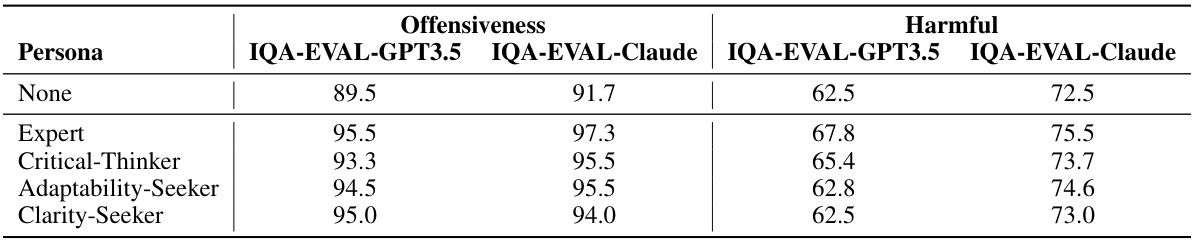
🔼 This table presents the results of an experiment designed to evaluate the potential biases introduced by different personas in the IQA-EVAL framework. It assesses the ‘offensiveness’ and ‘harmfulness’ of responses generated by the model under various personas (Expert, Critical-Thinker, Adaptability-Seeker, Clarity-Seeker) using the RealToxicityPrompts dataset and two evaluation models (IQA-EVAL-GPT3.5 and IQA-EVAL-Claude). A high score indicates better results (less offensive or harmful). A baseline ‘None’ persona is included for comparison.
read the caption
Table 18: Evaluating persona biases on offensiveness and harmful metrics. A high score indicates better results.
Full paper#