TL;DR#
Unsupervised semantic segmentation, crucial for various applications, lags behind supervised methods due to the lack of labeled data. Existing unsupervised techniques often struggle to produce detailed and accurate segmentations. Some methods rely on extra image-text data, thus limiting their generalizability. Others struggle with discovering arbitrary numbers of segments, limiting their suitability for diverse scenes.
DiffCut overcomes these limitations by ingeniously employing diffusion model features and a recursive normalized cut algorithm. This approach results in high-quality segmentations without needing any labeled data or textual descriptions. The recursive nature of the algorithm dynamically adapts to the complexity of the scene, generating accurate segmentation maps with intricate detail. This significant improvement in accuracy, alongside the efficiency and lack of need for extra data, marks a substantial advancement in the field.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances unsupervised zero-shot semantic segmentation, a challenging problem in computer vision. DiffCut’s superior performance over existing methods opens up new avenues for research and development in foundation models for downstream tasks. The method’s efficiency and robustness make it highly relevant to current trends in sustainable AI.
Visual Insights#

🔼 This figure shows a comparison of unsupervised zero-shot image segmentation results between the proposed DiffCut method and the DiffSeg method. Three example images are shown with their corresponding segmentation maps generated by each method. DiffCut demonstrates improved accuracy and detail in its segmentation compared to DiffSeg, more accurately capturing semantic concepts within the images.
read the caption
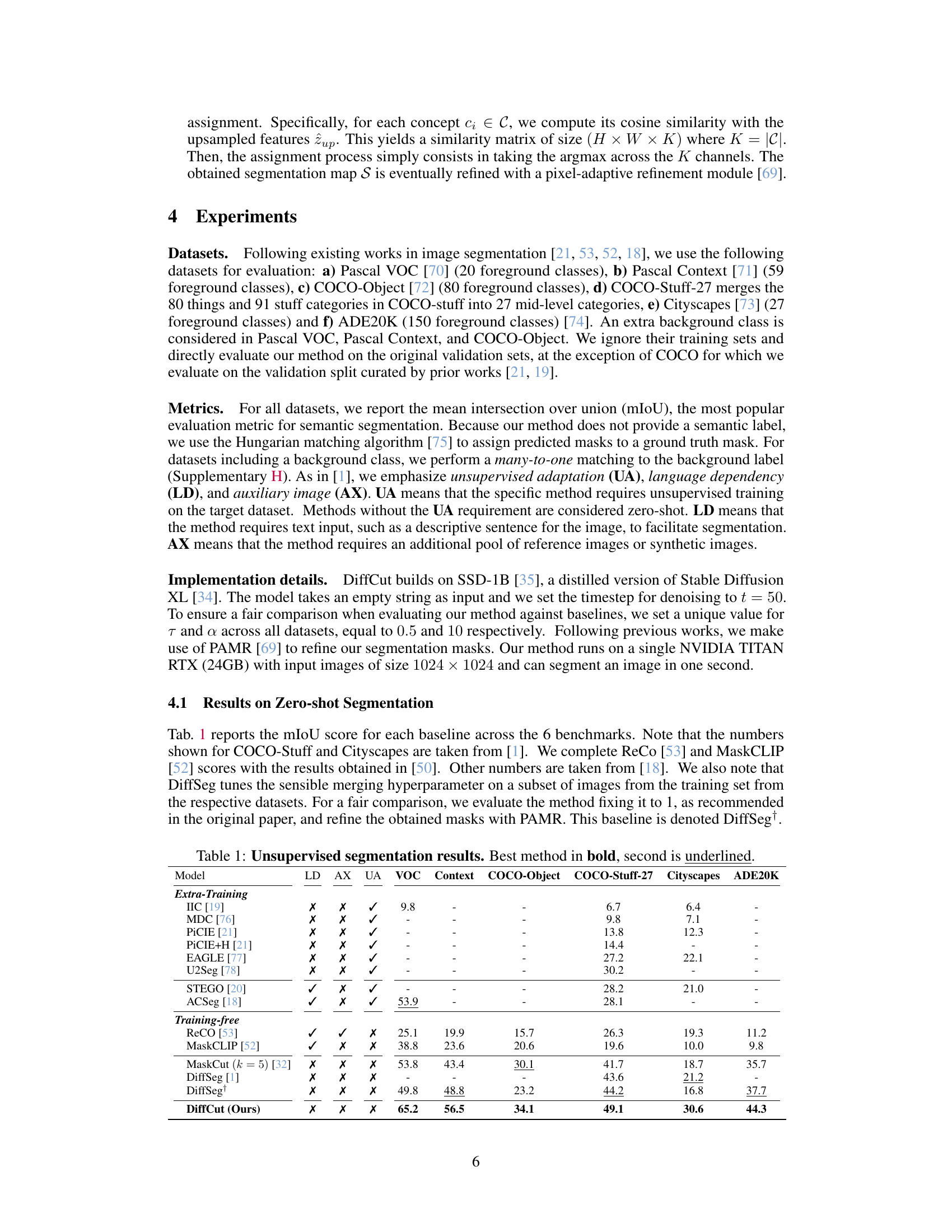
Figure 1: Unsupervised zero-shot image segmentation. Our DiffCut method exploits features from a diffusion UNet encoder in a graph-based recursive partitioning algorithm. Compared to DiffSeg [1], DiffCut provides finely detailed segmentation maps that more closely align with semantic concepts.

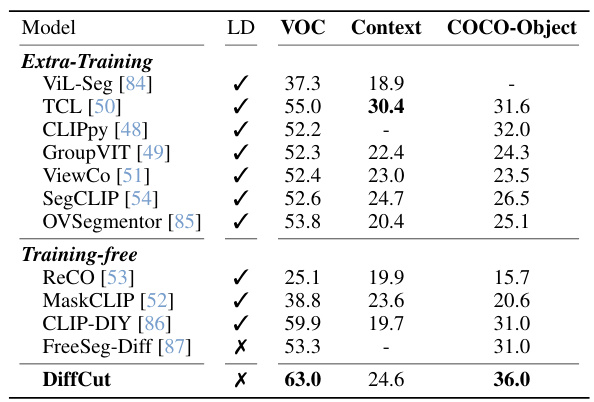
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by various unsupervised semantic segmentation methods on six benchmark datasets (Pascal VOC, Pascal Context, COCO-Object, COCO-Stuff-27, Cityscapes, and ADE20K). The methods are categorized into those requiring extra training data (Extra-Training) and those that are training-free (Training-free). The table highlights DiffCut’s superior performance compared to existing state-of-the-art methods. It also indicates whether a method relies on language dependency (LD), auxiliary images (AX), or unsupervised adaptation (UA).
read the caption
Table 1: Unsupervised segmentation results. Best method in bold, second is underlined.
In-depth insights#
DiffCut’s novelty#
DiffCut’s novelty lies in its two-pronged approach to unsupervised zero-shot semantic segmentation. First, it leverages the semantic richness embedded within the final self-attention block of a diffusion UNet encoder, bypassing the need for text prompts or cross-attention modules, which are computationally expensive and prone to inaccuracies. Second, it employs a recursive normalized cut algorithm, allowing for adaptive segmentation granularity based on image content, unlike previous methods limited to a pre-defined number of segments. This recursive approach coupled with the unique utilization of diffusion features makes DiffCut exceptionally efficient and robust, leading to more accurate and finely detailed segmentation maps. The combination of these two innovative aspects represents a significant advancement over existing unsupervised semantic segmentation techniques.
Recursive NCut#
The heading ‘Recursive NCut’ suggests a method for image segmentation that leverages the Normalized Cut algorithm in a recursive manner. This recursive application likely addresses the limitations of standard Normalized Cut, which often struggles with complex images containing multiple objects. Recursively applying NCut allows for a hierarchical segmentation process, starting with a coarse partitioning and progressively refining the segments to achieve finer granularity. This hierarchical approach is particularly valuable for zero-shot semantic segmentation, where prior knowledge about object classes is absent. The method’s ability to adapt the granularity of segmentation suggests robustness across diverse image content. A key benefit is the capacity to automatically determine the number of segments rather than relying on pre-defined parameters, making it well-suited for scenarios with unpredictable visual complexity.
Zero-shot seg#
Zero-shot semantic segmentation, a challenging task in computer vision, aims to segment images into meaningful regions without any prior training on the specific classes present in those images. This contrasts with traditional supervised methods that require large labeled datasets. A key focus in zero-shot seg is leveraging knowledge from pre-trained models, such as diffusion models or vision transformers, to generalize to unseen data. The effectiveness of this approach depends heavily on the richness of the learned representations and the ability of the method to effectively transfer that knowledge. Graph-based methods and recursive partitioning algorithms are commonly employed to handle the unsupervised nature of the problem. However, zero-shot seg faces the inherent limitation that without class-specific information, segmentation accuracy might not always perfectly align with human semantic understanding, particularly in complex scenes. Future improvements in zero-shot seg likely involve developing even more powerful and robust foundation models as well as creating more sophisticated algorithms that can better handle ambiguity and noisy inputs.
Feature coherence#
The concept of ‘feature coherence’ in the context of zero-shot semantic segmentation is crucial. It speaks to the internal consistency and semantic meaningfulness of the features extracted from a foundation model, such as a diffusion UNet. High feature coherence implies that features representing similar semantic concepts (e.g., different instances of ‘dog’) will cluster together in feature space, leading to improved segmentation accuracy. The paper likely investigates this by measuring the alignment of patch-level features, comparing the performance of different vision encoders. Strong feature coherence is essential for the success of the recursive normalized cut algorithm; well-clustered features make the task of partitioning the image graph easier and more accurate. A lack of coherence could lead to fragmented or semantically incorrect segmentations. The analysis of feature coherence, therefore, provides valuable insights into the quality of the chosen foundation model and its suitability for zero-shot segmentation. It also underscores the importance of selecting an appropriate foundation model with inherent semantic understanding for downstream tasks like semantic segmentation.
Future work#
The paper’s impactful results in zero-shot semantic segmentation using diffusion features open exciting avenues for future research. Extending DiffCut to handle more complex scenes and challenging datasets with diverse object interactions and occlusions is crucial. Investigating the influence of different diffusion model architectures and training strategies on the performance of DiffCut could significantly improve its capabilities. Exploring the integration of other modalities, such as depth or motion information, would enhance the robustness and contextual understanding of the segmentation process. Furthermore, developing a more efficient algorithm for recursive normalized cut is essential to improve scalability and reduce computational cost, particularly for very high-resolution images. Finally, analyzing the robustness of DiffCut’s hyperparameters and developing automated optimization methods is key to ensuring consistent performance across various datasets. This comprehensive approach will advance the state-of-the-art in zero-shot semantic segmentation.
More visual insights#
More on figures

🔼 This figure illustrates the pipeline of the DiffCut model. First, features from the final self-attention block of a diffusion UNet encoder are extracted from an input image. These features are used to create an affinity matrix, which is then processed by a recursive normalized cut algorithm to generate a low-resolution segmentation map. Finally, a high-resolution segmentation map is generated by upsampling the low-resolution map and using a concept assignment mechanism.
read the caption
Figure 2: Overview of DiffCut. 1) DiffCut takes an image as input and extracts the features of the last self-attention block of a diffusion UNet encoder. 2) These features are used to construct an affinity matrix that serves in a recursive normalized cut algorithm, which outputs a segmentation map at the latent spatial resolution. 3) A high-resolution segmentation map is produced via a concept assignment mechanism on the features upsampled at the original image size.
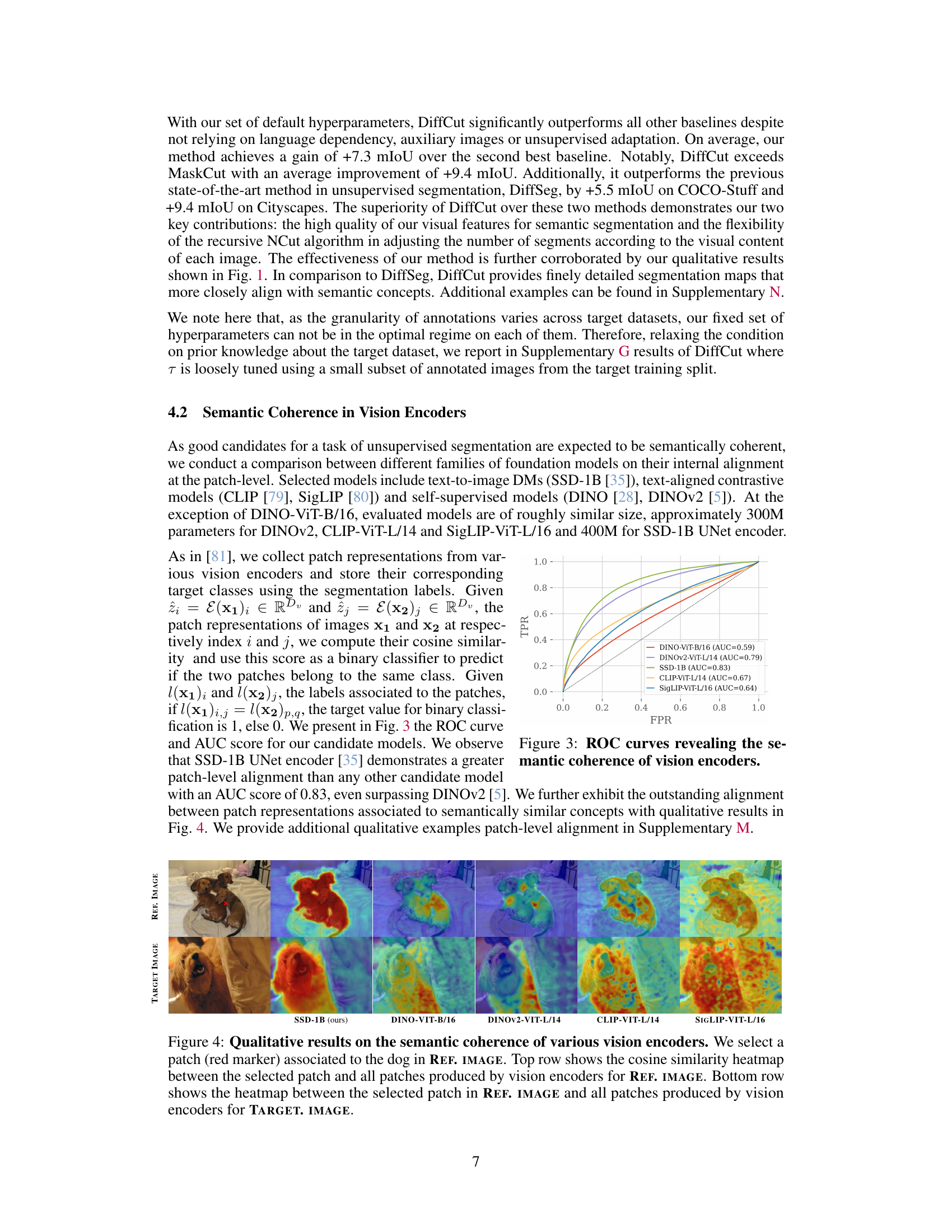
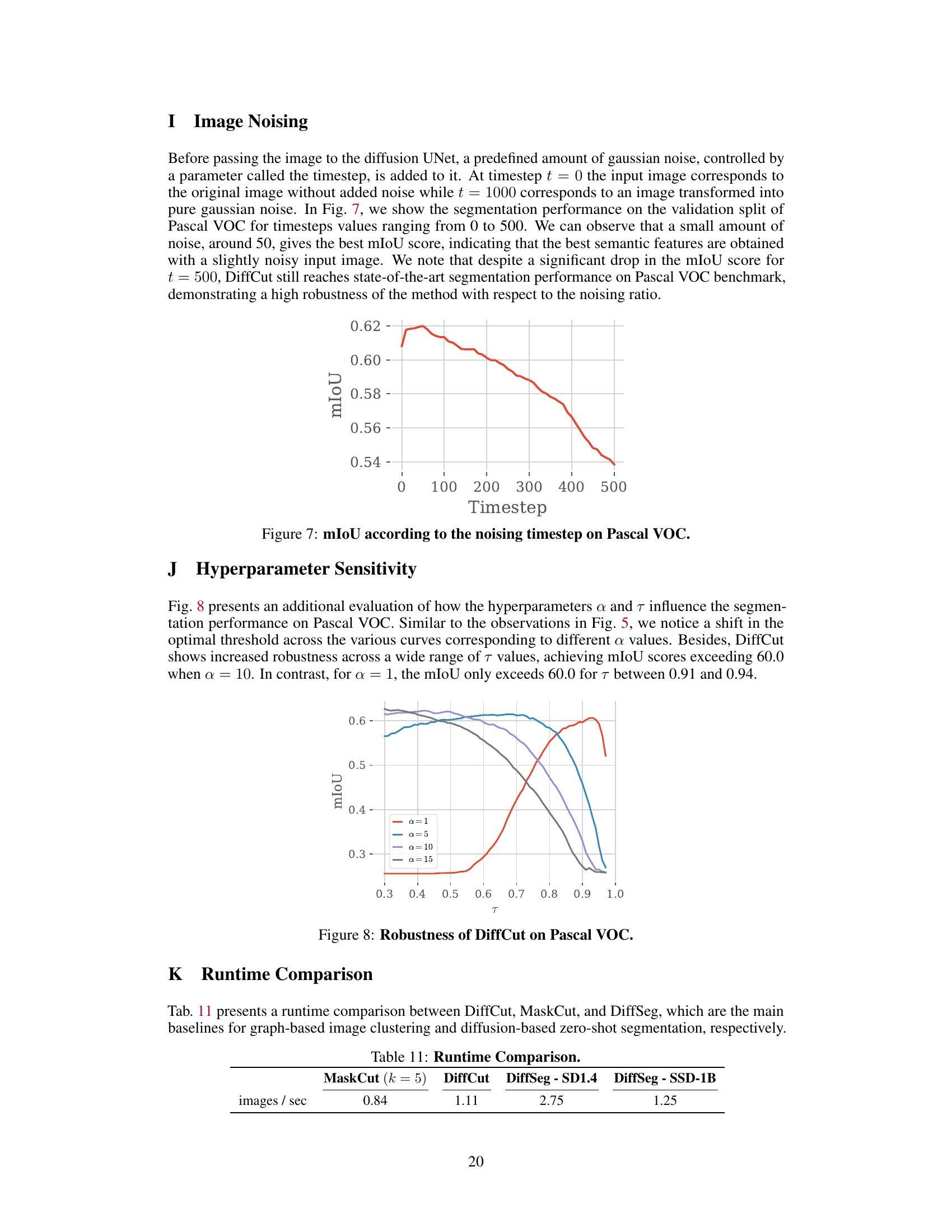
🔼 This ROC curve shows the area under the curve (AUC) scores for different vision encoders, measuring their ability to correctly identify whether pairs of image patches belong to the same semantic class. The higher the AUC score, the better the semantic coherence of the encoder’s feature representations. The figure demonstrates that the SSD-1B UNet encoder outperforms other models, indicating its strong semantic coherence for image segmentation.
read the caption
Figure 3: ROC curves revealing the semantic coherence of vision encoders.

🔼 This figure displays the results of an experiment designed to evaluate the semantic coherence of various vision encoders by comparing the patch-level alignment of features extracted from different models. The experiment focuses on measuring the cosine similarity between patches representing semantically similar concepts across different images. The visualization shows heatmaps illustrating the similarity scores, providing insights into the capacity of each vision encoder to capture and represent semantic information within image patches. The stronger alignment shown by certain models highlights their ability to group semantically related visual elements.
read the caption
Figure 4: Qualitative results on the semantic coherence of various vision encoders. We select a patch (red marker) associated to the dog in REF. IMAGE. Top row shows the cosine similarity heatmap between the selected patch and all patches produced by vision encoders for REF. IMAGE. Bottom row shows the heatmap between the selected patch in REF. IMAGE and all patches produced by vision encoders for TARGET. IMAGE.
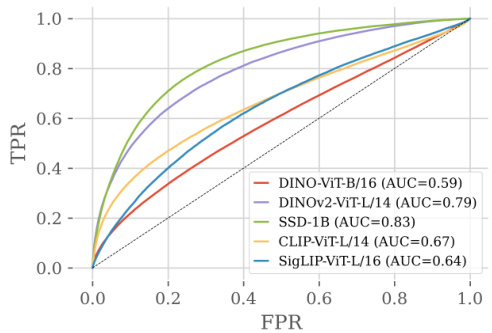
🔼 This figure shows the sensitivity analysis of the hyperparameters α (exponent value) and τ (threshold value) on the segmentation performance of the DiffCut method. It demonstrates that as α increases, the range of τ values resulting in competitive performance widens significantly, improving the robustness of DiffCut across various settings.
read the caption
Figure 5: Sensitivity of DiffCut. As α increases, DiffCut shows competitive results for a broad range of τ values.

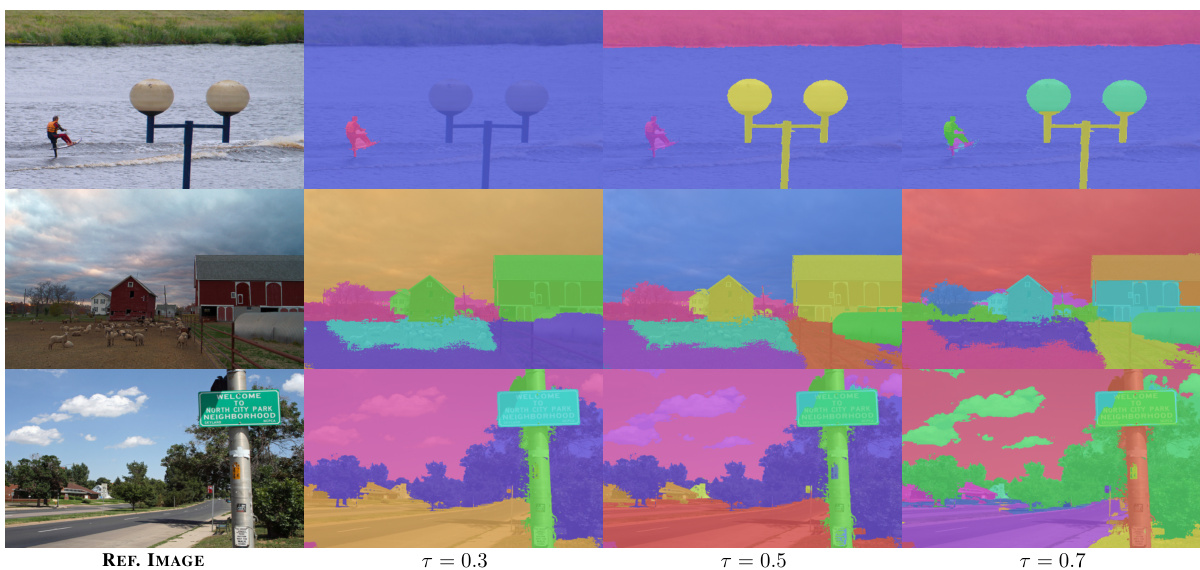
🔼 This figure shows the effect of the hyperparameter τ on the segmentation results. The hyperparameter τ controls the granularity of the segmentation. A smaller value of τ leads to finer-grained segmentations, while a larger value results in coarser segmentations. The figure displays segmentation results for three different values of τ (0.3, 0.5, and 0.7) on two example images. In both images, increasing τ leads to fewer, larger segments.
read the caption
Figure 6: Effect of τ. As τ corresponds to the maximum Ncut value, a larger threshold loosens the constraint on the partitioning algorithm and allows it to perform more recursive steps to uncover finer objects. It can be interpreted as the level of granularity of detected objects.

🔼 This figure showcases the results of unsupervised zero-shot image segmentation using three different methods: a reference image, DiffSeg, and the authors’ proposed method, DiffCut. DiffCut uses features from a diffusion UNet encoder within a recursive graph partitioning algorithm. The comparison highlights that DiffCut produces more detailed and semantically accurate segmentation maps compared to DiffSeg, aligning more closely with the actual semantic concepts in the image.
read the caption
Figure 1: Unsupervised zero-shot image segmentation. Our DiffCut method exploits features from a diffusion UNet encoder in a graph-based recursive partitioning algorithm. Compared to DiffSeg [1], DiffCut provides finely detailed segmentation maps that more closely align with semantic concepts.
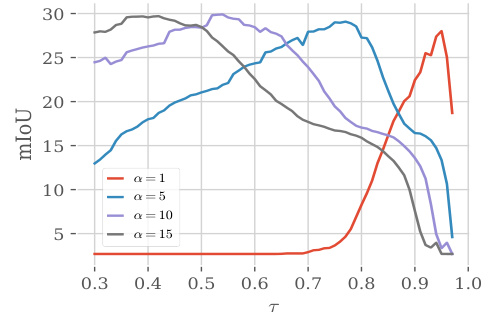
🔼 This figure shows the relationship between the amount of Gaussian noise added to the input image (controlled by the ’timestep’ parameter) and the resulting mean Intersection over Union (mIoU) score on the Pascal VOC dataset. The mIoU, a common metric for evaluating semantic segmentation, measures the accuracy of the segmentation produced. The graph illustrates that there’s an optimal level of noise; a small amount of noise leads to the best performance, demonstrating that the best semantic features are obtained with a slightly noisy input image. Conversely, adding too much noise significantly reduces performance.
read the caption
Figure 7: mIoU according to the noising timestep on Pascal VOC.
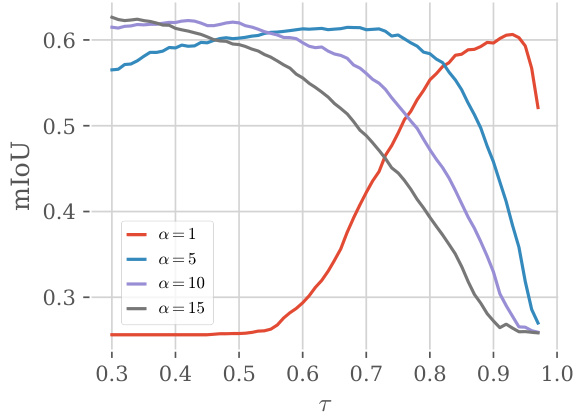
🔼 This figure shows the performance of DiffCut on the Pascal VOC dataset with respect to different values of the hyperparameters α and τ. The x-axis represents the threshold τ, and the y-axis represents the mean Intersection over Union (mIoU). Different curves represent different values of the hyperparameter α. The figure demonstrates that DiffCut is robust to changes in τ across a wide range of α values, indicating that the method is relatively insensitive to the precise tuning of these hyperparameters.
read the caption
Figure 8: Robustness of DiffCut on Pascal VOC.
🔼 This figure shows a comparison of unsupervised zero-shot image segmentation results between the proposed method, DiffCut, and a baseline method, DiffSeg. DiffCut leverages features from a diffusion UNet encoder in a recursive graph partitioning algorithm, resulting in more accurate and detailed segmentation maps that better align with semantic concepts. The figure visually demonstrates the improved performance of DiffCut by showcasing examples of image segmentation for various scenes.
read the caption
Figure 1: Unsupervised zero-shot image segmentation. Our DiffCut method exploits features from a diffusion UNet encoder in a graph-based recursive partitioning algorithm. Compared to DiffSeg [1], DiffCut provides finely detailed segmentation maps that more closely align with semantic concepts.

🔼 This figure showcases the performance of DiffCut on unsupervised zero-shot image segmentation. It compares the segmentation maps produced by DiffCut and DiffSeg on several sample images. DiffCut, by leveraging features from a diffusion UNet encoder and a recursive normalized cut algorithm, achieves more accurate and detailed segmentation maps that better align with semantic concepts compared to DiffSeg.
read the caption
Figure 1: Unsupervised zero-shot image segmentation. Our DiffCut method exploits features from a diffusion UNet encoder in a graph-based recursive partitioning algorithm. Compared to DiffSeg [1], DiffCut provides finely detailed segmentation maps that more closely align with semantic concepts.

🔼 This figure shows a comparison of unsupervised zero-shot image segmentation results between the proposed DiffCut method and the baseline DiffSeg method. DiffCut uses features from a diffusion UNet encoder within a recursive normalized cut algorithm to produce segmentation maps. The figure visually demonstrates that DiffCut produces more accurate and detailed segmentations that better align with semantic concepts compared to DiffSeg.
read the caption
Figure 1: Unsupervised zero-shot image segmentation. Our DiffCut method exploits features from a diffusion UNet encoder in a graph-based recursive partitioning algorithm. Compared to DiffSeg [1], DiffCut provides finely detailed segmentation maps that more closely align with semantic concepts.

🔼 This figure showcases the results of unsupervised zero-shot image segmentation using the proposed DiffCut method. It compares DiffCut’s performance against a previous method (DiffSeg). DiffCut utilizes features from a diffusion UNet encoder within a recursive graph partitioning algorithm. The images demonstrate that DiffCut produces finer segmentation maps that more accurately reflect the underlying semantic concepts compared to DiffSeg.
read the caption
Figure 1: Unsupervised zero-shot image segmentation. Our DiffCut method exploits features from a diffusion UNet encoder in a graph-based recursive partitioning algorithm. Compared to DiffSeg [1], DiffCut provides finely detailed segmentation maps that more closely align with semantic concepts.
More on tables

🔼 This ablation study compares the performance of DiffCut against two variations: DiffSeg (using a self-attention merging process) and AutoSC (using automated spectral clustering). The table shows the mean Intersection over Union (mIoU) scores achieved by each method across six different datasets (VOC, Context, COCO-Object, COCO-Stuff-27, Cityscapes, ADE20K). It demonstrates that DiffCut’s recursive partitioning significantly outperforms both alternatives, highlighting the effectiveness of its approach.
read the caption
Table 2: Ablation Study. The recursive partitioning of DiffCut yields superior results to both the self-attention merging process of DiffSeg and Automated Spectral Clustering.
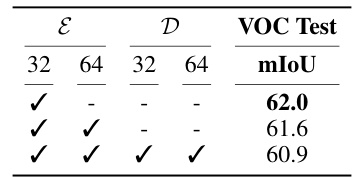
🔼 This table presents ablation study results to show the contribution of different hierarchical features extracted from the UNet encoder to the overall performance of DiffCut. It shows the mIoU scores achieved on the Pascal VOC validation set when using features from different encoder layers (32x32 and 64x64 resolution). The results indicate that the features from the 32x32 resolution layer provide the best performance, suggesting that lower resolution features are sufficient for optimal semantic segmentation in this context. Combining features from multiple layers does not improve performance, and instead increases computational overhead.
read the caption
Table 3: Features Contribution. Hierarchical features in E32 provide optimal performance (Pascal VOC validation set).
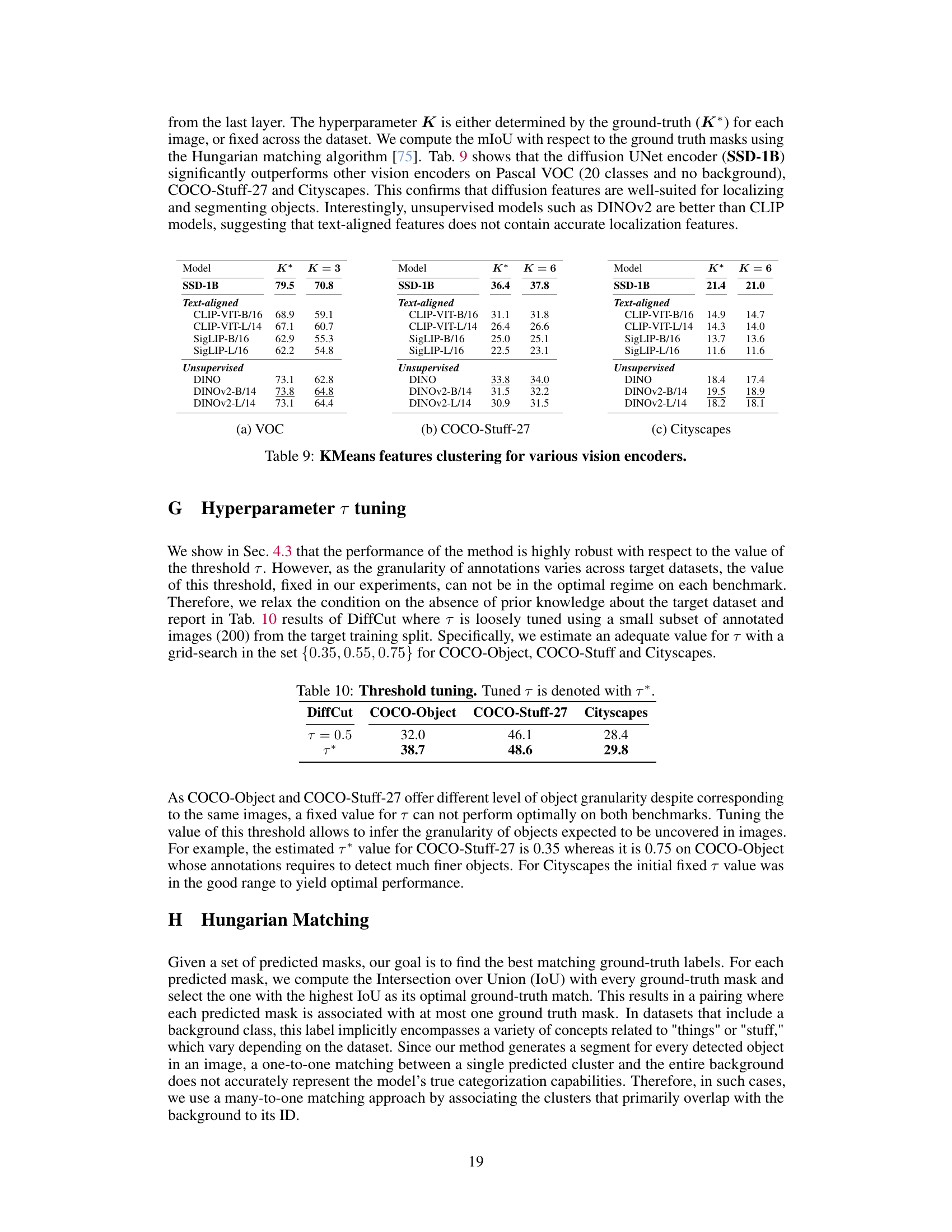
🔼 This table presents a comparison of unsupervised semantic segmentation methods on six benchmark datasets (Pascal VOC, Pascal Context, COCO-Object, COCO-Stuff-27, Cityscapes, and ADE20K). The methods are categorized as either requiring extra training or being training-free. The key metric is mean Intersection over Union (mIoU). DiffCut achieves the highest mIoU scores in most cases, highlighting its effectiveness compared to other state-of-the-art methods for zero-shot image segmentation.
read the caption
Table 1: Unsupervised segmentation results. Best method in bold, second is underlined.

🔼 This table presents the ablation study results, comparing the performance of DiffCut against two variations: DiffSeg (using self-attention merging) and Automated Spectral Clustering. It shows that DiffCut’s recursive partitioning approach significantly outperforms both alternatives across various datasets (VOC, Context, COCO-Object, COCO-Stuff, Cityscapes, ADE20K), demonstrating the effectiveness of its key design choices.
read the caption
Table 2: Ablation Study. The recursive partitioning of DiffCut yields superior results to both the self-attention merging process of DiffSeg and Automated Spectral Clustering.

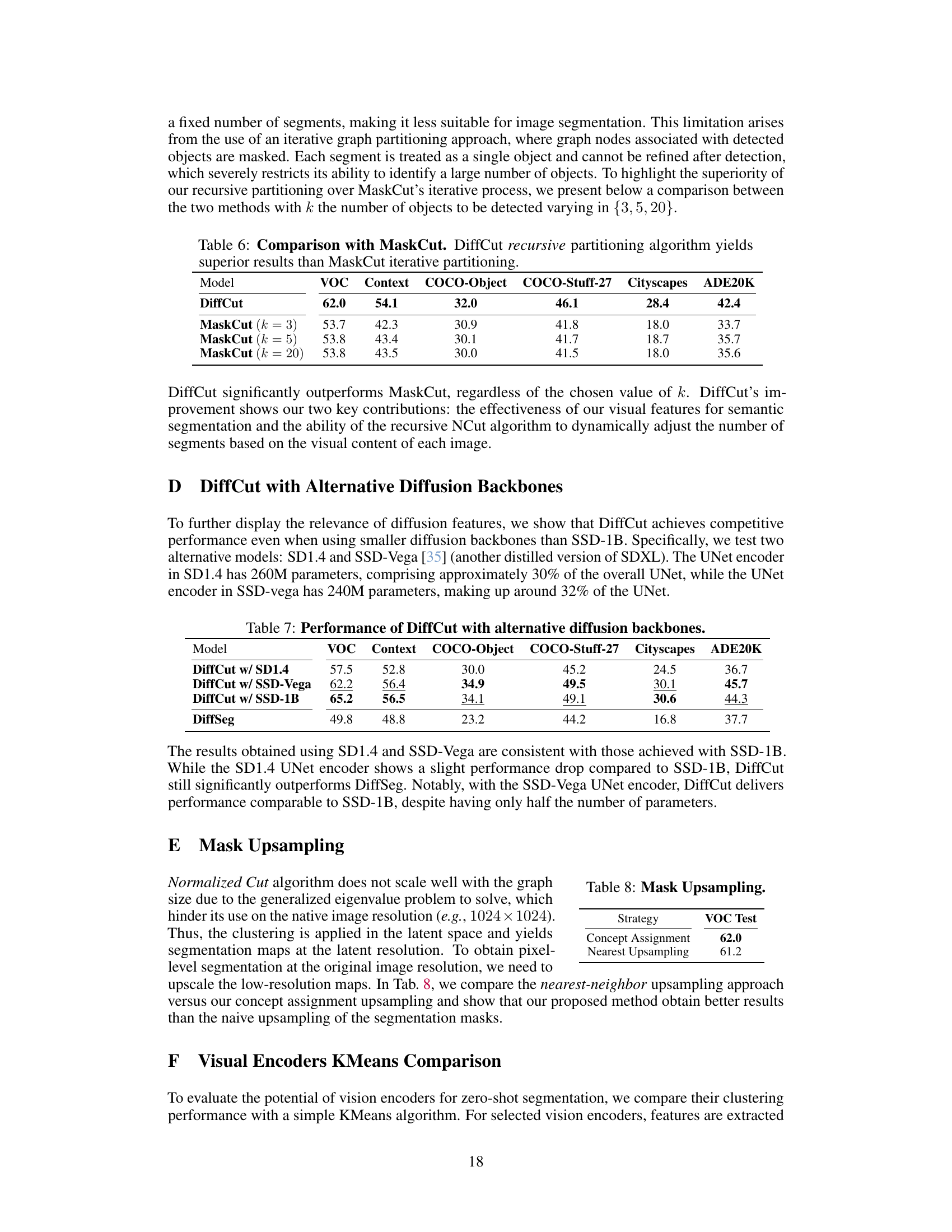
🔼 This table compares the performance of DiffCut and MaskCut on six benchmark datasets (VOC, Context, COCO-Object, COCO-Stuff-27, Cityscapes, ADE20K). It demonstrates that DiffCut’s recursive partitioning approach outperforms MaskCut’s iterative approach. The comparison is performed by varying the number of segments (k) detected by MaskCut (k = 3, 5, 20). DiffCut consistently achieves better mIoU scores across all datasets and k values, highlighting its ability to dynamically adjust the number of segments based on visual content.
read the caption
Table 6: Comparison with MaskCut. DiffCut recursive partitioning algorithm yields superior results than MaskCut iterative partitioning.

🔼 This table presents a comparison of DiffCut’s performance using three different diffusion backbones: SD1.4, SSD-Vega, and SSD-1B. It shows the mean Intersection over Union (mIoU) scores achieved on six different semantic segmentation benchmark datasets (VOC, Context, COCO-Object, COCO-Stuff-27, Cityscapes, and ADE20K). The results demonstrate DiffCut’s robustness across various backbone choices, achieving competitive performance even with smaller models like SD1.4 and SSD-Vega compared to DiffSeg, a state-of-the-art baseline.
read the caption
Table 7: Performance of DiffCut with alternative diffusion backbones.

🔼 This ablation study compares two different upsampling strategies for generating high-resolution segmentation maps from low-resolution maps produced by the recursive normalized cut algorithm. The ‘Concept Assignment’ strategy uses a concept assignment mechanism to assign pixel labels based on similarity to upsampled features of the segments, while the ‘Nearest Upsampling’ strategy simply performs nearest-neighbor upsampling. The results show that the concept assignment strategy significantly outperforms the nearest upsampling approach, achieving a mIoU score of 62.0 compared to 61.2 for nearest upsampling. This highlights the effectiveness of semantic information preservation in the concept assignment approach.
read the caption
Table 8: Mask Upsampling

🔼 This table presents the results of DiffCut where the threshold parameter τ is tuned using a small subset of annotated images from the target training split. The tuning process aims to find an optimal τ value for each dataset (COCO-Object, COCO-Stuff-27, and Cityscapes) that balances the trade-off between segment granularity and segmentation accuracy. The results demonstrate the impact of tuning τ on the performance of the method across different datasets.
read the caption
Table 10: Threshold tuning. Tuned τ is denoted with τ*.

🔼 This table presents a comparison of unsupervised semantic segmentation methods on six benchmark datasets (Pascal VOC, Pascal Context, COCO-Object, COCO-Stuff-27, Cityscapes, and ADE20K). The table shows the mean Intersection over Union (mIoU) achieved by each method. The methods are categorized by whether they require language dependency (LD), auxiliary images (AX), or unsupervised training (UA). The table highlights that DiffCut outperforms other state-of-the-art methods on this task.
read the caption
Table 1: Unsupervised segmentation results. Best method in bold, second is underlined.
Full paper#