TL;DR#
Visual In-Context Learning (VICL) empowers foundation models to tackle new visual tasks using contextual examples. A core challenge is selecting the most effective prompts (contextual examples). Current methods struggle with finding the globally optimal prompt, often relying on limited metrics or inconsistent comparisons.
Partial2Global tackles this by using a transformer-based list-wise ranker to comprehensively compare various prompts. It leverages a consistency-aware aggregator to ensure globally consistent rankings, thereby identifying the most effective prompt for each query. Experiments show Partial2Global consistently outperforms existing methods in diverse visual tasks, establishing new state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in visual in-context learning (VICL). It addresses the critical issue of prompt selection, a major challenge limiting VICL’s effectiveness. The proposed framework, Partial2Global, significantly improves the performance of VICL across multiple tasks by enhancing the selection of optimal in-context examples. This research opens exciting avenues for improving the efficiency and generalizability of VICL, impacting various applications relying on effective visual learning and inference.
Visual Insights#
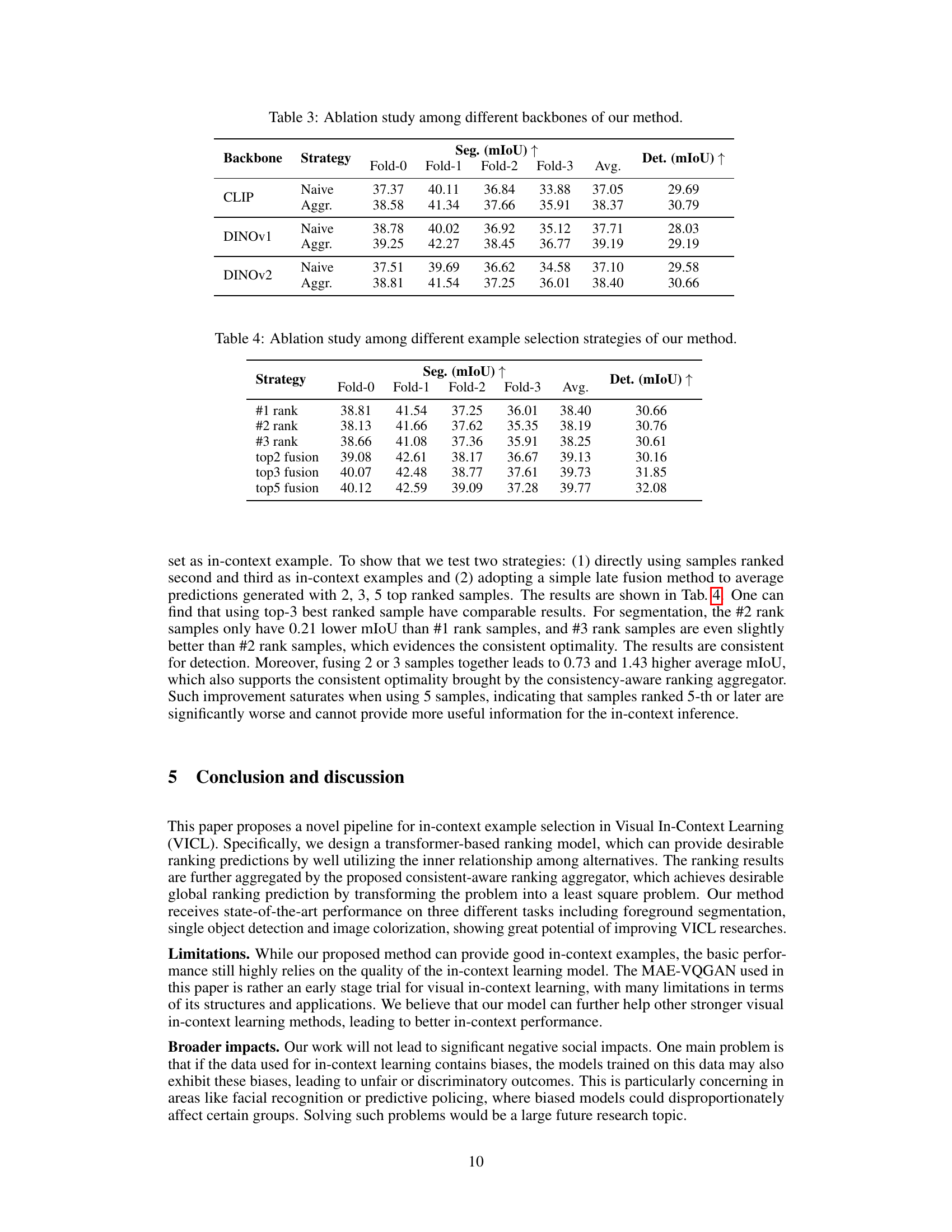
🔼 This figure systematically compares three different frameworks for selecting in-context examples in Visual In-Context Learning (VICL). (a) shows the VPR method, which uses a pairwise ranker and contrastive learning. (b) illustrates a naive approach using a list-wise ranker on non-overlapping subsets of alternatives. (c) presents the proposed Partial2Global method, which uses a list-wise ranker on shuffled subsets of alternatives and aggregates the results using a consistency-aware aggregator to achieve a more robust global ranking.
read the caption
Figure 2: Systematic comparison between three different frameworks for in-context example selection. (a) VPR, which uses pair-wise ranker trained with contrastive learning to calculate the relevance score for each alternative. (b) List-wise ranker with naive aggregation, in which alternatives are split into non-overlapped subsets. These subsets are ranked with the proposed list-wise ranker. Then we iteratively select the best example in each subset and rank them. (c) List-wise ranker with consistency-aware aggregator, in which alternatives are first shuffled and predicted with list-wise ranker into an observation pool. These partial observations are then aggregated with the proposed aggregator to achieve a global ranking.
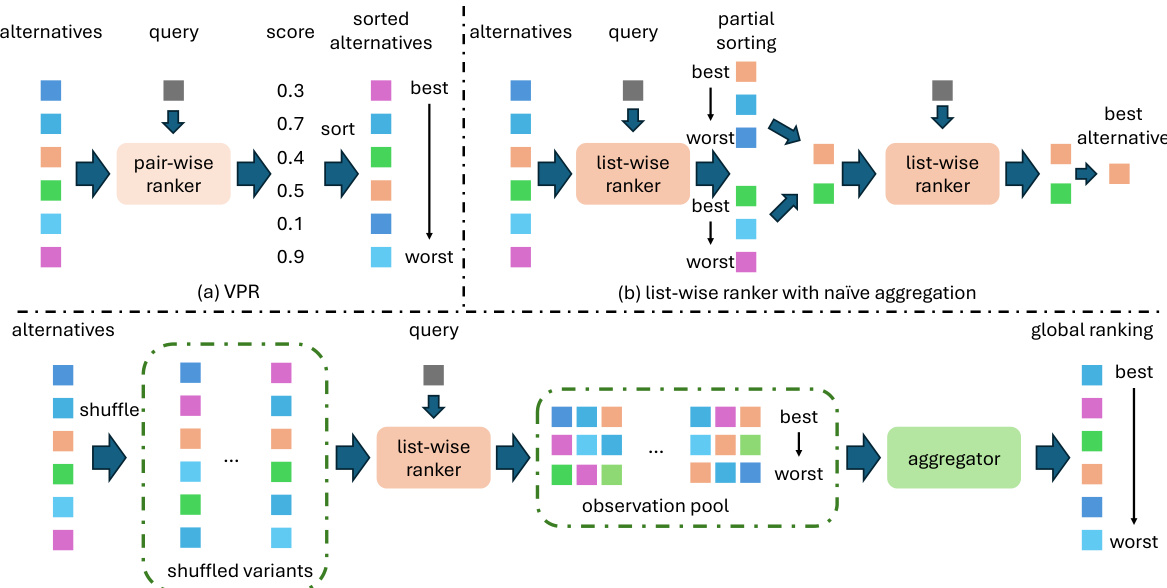
🔼 This table compares the performance of the proposed method (Partial2Global) against several existing in-context learning methods across three different tasks: foreground segmentation, single object detection, and image colorization. The metrics used for evaluation are mean Intersection over Union (mIoU) for segmentation and detection, and Mean Squared Error (MSE) for colorization. The table shows the performance of each method on four folds of data, along with an average. The results indicate that Partial2Global consistently outperforms other methods, achieving state-of-the-art results.
read the caption
Table 1: Comparison of our method with previous in-context learning methods.
In-depth insights#
Global Prompt Optimality#
The concept of “Global Prompt Optimality” in visual in-context learning (VICL) centers on selecting the most effective prompt from a pool of candidates to maximize model performance. A globally optimal prompt leverages the inherent relationships between all prompts, rather than relying on pairwise comparisons. This approach moves beyond the limitations of methods that only consider individual prompt-query similarities. Effective global prompt selection requires a robust ranking mechanism capable of capturing complex interactions between different prompts and the query, transcending simple visual similarity metrics. It necessitates methods capable of handling potentially inconsistent or noisy ranking signals from various subsets of prompts and aggregating them into a coherent global ranking. The challenge lies in efficiently exploring this high-dimensional space of prompt combinations to find the true global optimum, balancing computational costs with the need for accurate results. Achieving global optimality is crucial for unlocking VICL’s full potential, leading to more accurate and reliable predictions. This contrasts with methods employing partial or local ranking methods that fail to fully exploit the rich context provided by the entire pool of in-context examples. A system capable of achieving global prompt optimality would represent a significant advancement in VICL.
Partial2Global Framework#
The Partial2Global framework presents a novel approach to visual in-context learning (VICL) prompt selection by tackling the challenge of identifying the globally optimal prompt from a set of candidates. It leverages a transformer-based list-wise ranker to perform a more comprehensive comparison of the alternatives than previous pairwise methods. This allows the model to capture richer relationships between different in-context examples. A key innovation is the inclusion of a consistency-aware ranking aggregator, which combines partial ranking predictions to generate a globally consistent ranking. This addresses the inconsistencies often arising from directly aggregating partial rankings produced by individual rankers. The framework is empirically validated on various tasks, demonstrating consistent improvement over existing state-of-the-art methods. The method’s strength lies in its ability to effectively combine the local ranking information from partial rankers with a global consistency check leading to superior prompt selection and better VICL performance. It addresses core limitations of previous approaches, paving the way for more robust and effective VICL applications.
Listwise Ranker#
A listwise ranker, in the context of visual in-context learning (VICL), is a crucial component for efficiently and effectively selecting the optimal prompt from a pool of candidates. Unlike pairwise methods that compare samples individually, a listwise approach considers all samples simultaneously, capturing complex relationships and interdependencies within the entire set. This holistic view allows for a more nuanced understanding of the relative importance of each prompt, leading to more accurate ranking and improved selection of effective in-context examples. A well-designed listwise ranker is particularly important in VICL, where the cost of exhaustively evaluating all possible prompts is high, and a single, optimal choice significantly affects model performance. By incorporating a transformer-based architecture, a listwise ranker can learn richer representations and complex relationships between the query sample and the candidate prompts, further enhancing its ability to discern the most suitable choice. Ultimately, the sophistication of the listwise ranker plays a significant role in determining the overall success of the VICL system, bridging the gap between the computational cost of global ranking and the need for optimal prompt selection. The choice of a listwise ranking strategy is a critical design decision that directly impacts both the efficiency and the effectiveness of VICL.
Ablation Studies#
Ablation studies systematically evaluate the contribution of individual components within a complex model by removing or altering them one at a time. This helps isolate the impact of each part and understand its importance relative to the overall performance. By observing the changes in performance metrics (like accuracy or F1 score) after removing a specific module or hyperparameter, we gain a deeper understanding of its effectiveness. In a visual in-context learning system, for instance, ablation studies could examine the effect of different ranking models, or different aggregation strategies for ranking predictions, by comparing the results with and without these components. This provides valuable insights into which components are crucial, and which ones may be redundant or detrimental. Furthermore, ablation studies can highlight potential areas for future improvement, directing research efforts towards the most impactful components of the system, ultimately leading to more efficient and effective model design.
Future Directions#
Future research could explore several promising avenues. Improving the ranking model’s robustness to variations in data quality and different visual tasks is crucial. This could involve exploring more sophisticated architectures or training strategies. Investigating alternative ranking metrics beyond NDCG to better capture the nuances of in-context learning is also important. Furthermore, exploring ways to reduce the computational cost of the proposed pipeline, perhaps through model compression or efficient aggregation techniques, would enhance practicality. Finally, a deeper investigation into the theoretical underpinnings of in-context learning, particularly concerning optimal prompt selection, is needed to better guide future algorithm designs. This would involve developing a more comprehensive theoretical framework that goes beyond empirical observations.
More visual insights#
More on figures

🔼 This figure compares the performance of the proposed method (Ours) and the baseline method (SupPR) on foreground segmentation. Each example shows a query image and its prediction from both methods, using the same in-context examples. The IoU (Intersection over Union) score is displayed for each prediction, which quantifies the accuracy of the segmentation. The figure demonstrates that the proposed method generally achieves higher IoU scores, indicating more accurate foreground segmentation results.
read the caption
Figure 3: Qualitative comparison between our method and VPR, specifically SupPR, in foreground segmentation. In each item we present the image grid in the same order as the input of MAE-VQGAN, i.e. in-context example and its label in the first row, query image and its prediction in the second row. The IoU is listed below each image grid.
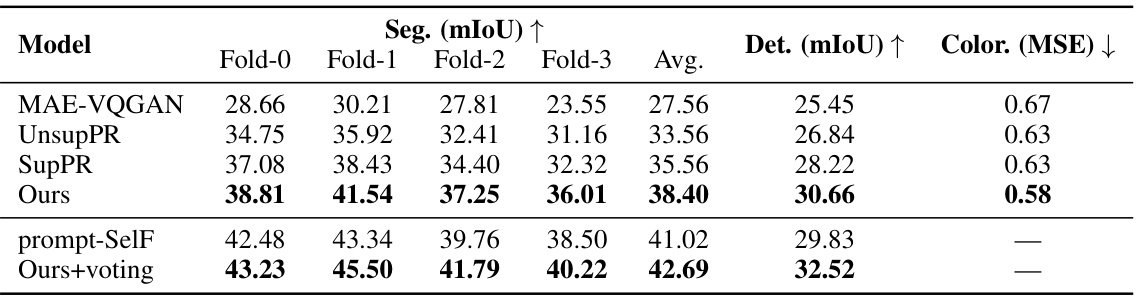
🔼 This figure shows the correlation between visual similarity and the Intersection over Union (IoU) for foreground segmentation using both the Visual Prompt Retrieval (VPR) method and the proposed Partial2Global method. The scatter plots in (a) and (b) visualize this relationship, revealing that while high visual similarity is often associated with good performance, there are many cases where high visual similarity does not guarantee high IoU. Part (c) provides example images with low visual similarity but high IoU and vice versa, demonstrating the complexity of choosing effective in-context examples based solely on visual similarity.
read the caption
Figure 4: (a) Scatter plot of visual similarity against IoU for VPR on segmentation. (b) Scatter plot of visual similarity against IoU for our method on segmentation. (c) Visualization of several cases with uncorrelated visual similarity and IoU. The first row presents samples with low similarity but proper in-context performance. The second row presents samples with high similarity but poor in-context performance. Captions below each image grid denote IoU and visual similarity sequentially.

🔼 This figure shows a qualitative comparison of the proposed method (Ours) and the Visual Prompt Retrieval (VPR) method, specifically SupPR, on the task of single object detection. For each example, the left image displays the in-context example selected by each method, and the right image shows the query image along with the resulting bounding boxes. The IoU (Intersection over Union) scores are shown below each pair of images. The comparison visually demonstrates that the proposed method consistently selects better in-context examples resulting in significantly improved object detection accuracy.
read the caption
Figure 5: Qualitative comparison between our method and VPR, specifically SupPR, in single object detection. For simplicity we present the bounding boxes on images instead of showing the image grids. In each item the left image denotes the in-context example and the right one denotes the query.
More on tables
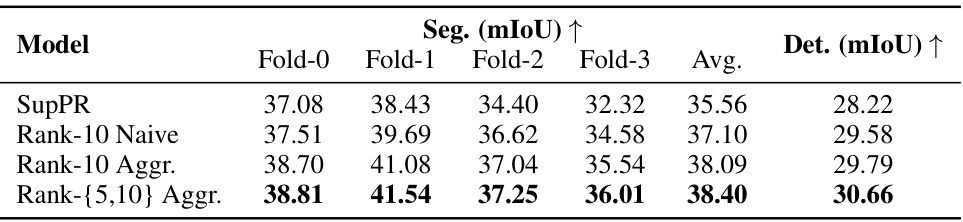
🔼 This table presents the ablation study results comparing different variations of the proposed method. It compares the performance of three models: Rank-10 Naive (using a rank-10 model directly for selection), Rank-10 Aggr (using a rank-10 model with the consistency-aware aggregator), and Rank-{5,10} Aggr (the full model using both rank-5 and rank-10 models with the aggregator). The results are shown in terms of mean Intersection over Union (mIoU) for foreground segmentation and single object detection tasks.
read the caption
Table 2: Ablation study among different variants of our method.
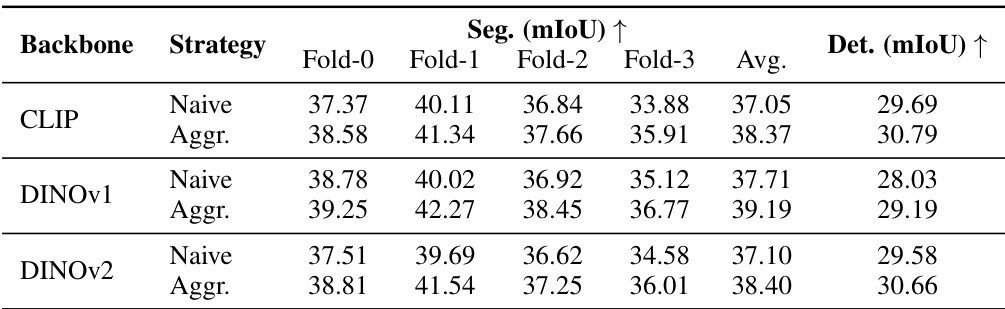
🔼 This table presents the results of an ablation study comparing the performance of the proposed method using different backbone networks (CLIP, DINOv1, and DINOv2) for foreground segmentation and object detection tasks. Two strategies are compared: a ‘Naive’ approach using the ranking predictions directly and an ‘Aggr.’ approach that incorporates a consistency-aware ranking aggregator. The table shows the mIoU for segmentation and object detection across four folds and an average across all folds for each backbone and strategy.
read the caption
Table 3: Ablation study among different backbones of our method.
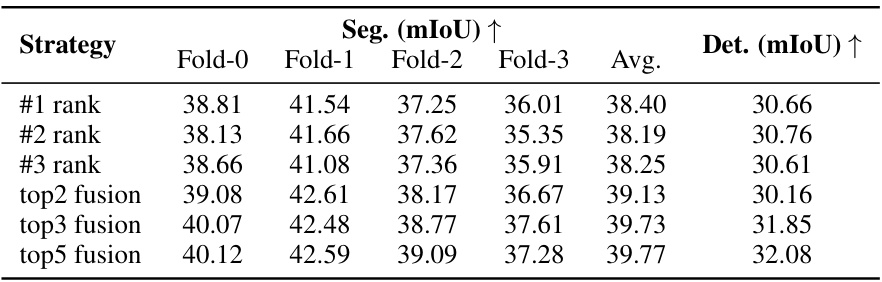
🔼 This table presents the ablation study comparing different variants of the proposed method. It shows the performance (Seg. mIoU and Det. mIoU) of four models: SupPR (baseline), Rank-10 Naive (using a rank-10 model without aggregation), Rank-10 Aggr (using a rank-10 model with the consistency-aware aggregator), and Rank-{5,10} Aggr (the full model using both rank-5 and rank-10 models with aggregation). The results demonstrate the effectiveness of the proposed list-wise ranker and consistency-aware ranking aggregator in improving the overall performance.
read the caption
Table 2: Ablation study among different variants of our method.
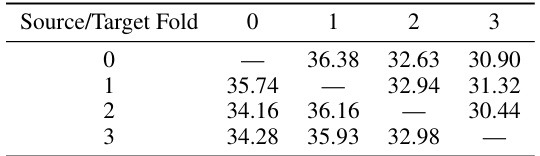
🔼 This table presents the results of a cross-validation experiment evaluating the transferability of the proposed method for image segmentation. The model trained on one fold of the dataset is tested on the remaining three folds. Each cell shows the mean Intersection over Union (mIoU) achieved on the target fold using the model trained on the source fold. The diagonal elements represent the performance of the model on the training fold (i.e., no transfer learning). The values show that while performance is reduced in cross-fold scenarios, the model trained with the proposed method generally exhibits better performance than competitors.
read the caption
Table 5: Cross-fold performance of our method on segmentation task.

🔼 This table presents the results of a cross-validation experiment evaluating the performance of the SupPR model on the foreground segmentation task. The model was trained on one fold of the Pascal-5i dataset and tested on the remaining folds. The table shows the mean Intersection over Union (mIoU) achieved by SupPR on each test fold, when trained on each of the source folds. This demonstrates the model’s generalizability and robustness across different training sets within the same dataset.
read the caption
Table 6: Cross-fold performance of SupPR on segmentation task.

🔼 This table shows the inference time for each query with different alternative set sizes (25, 50, and 100). The inference time includes feature extraction, sub-sequence ranking with the list-wise ranker, and ranking aggregation. The time increases with the size of the alternative set, as expected.
read the caption
Table 7: Inference speed with different alternative set size.

🔼 This table compares the performance of the proposed method (Ours) against several other methods for visual in-context learning on three tasks: foreground segmentation, single object detection, and colorization. The performance metrics used are mean Intersection over Union (mIoU) for segmentation and detection, and Mean Squared Error (MSE) for colorization. Results are shown for multiple folds of the dataset to provide a more robust evaluation. The table shows the performance of methods both with and without a voting strategy to combine predictions. It highlights the improvements achieved by the proposed method in all tasks and with both strategies.
read the caption
Table 1: Comparison of our method with previous in-context learning methods.

🔼 This table presents the results of an ablation study on the hyperparameters delta (margin) and tau (temperature) used in the NeuralNDCG loss function. It shows the Mean Squared Error (MSE) achieved for different values of these hyperparameters in a colorization task. The results demonstrate the impact of these hyperparameters on model performance and help to determine optimal settings.
read the caption
Table 9: Ablation study for hyper-parameters.

🔼 This table shows the results of an ablation study conducted to evaluate the impact of varying the size of the alternative set on the performance of the proposed method. The model was tested on all folds of the segmentation task with three different sizes of the alternative sets: 25, 50 (the main setting in the paper), and 100. The results demonstrate the robustness of the method to the size of the alternative set.
read the caption
Table 10: Ablation study for different alternative set sizes.
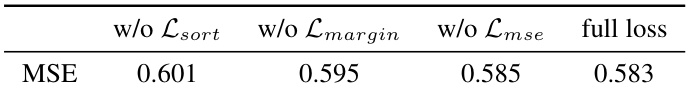
🔼 This table shows the result of ablation study on the effectiveness of different terms in the proposed loss function for the colorization task. The results indicate that all three loss terms contribute to the final performance, with Lsort playing the most important role.
read the caption
Table 11: Ablation study for loss terms.
Full paper#