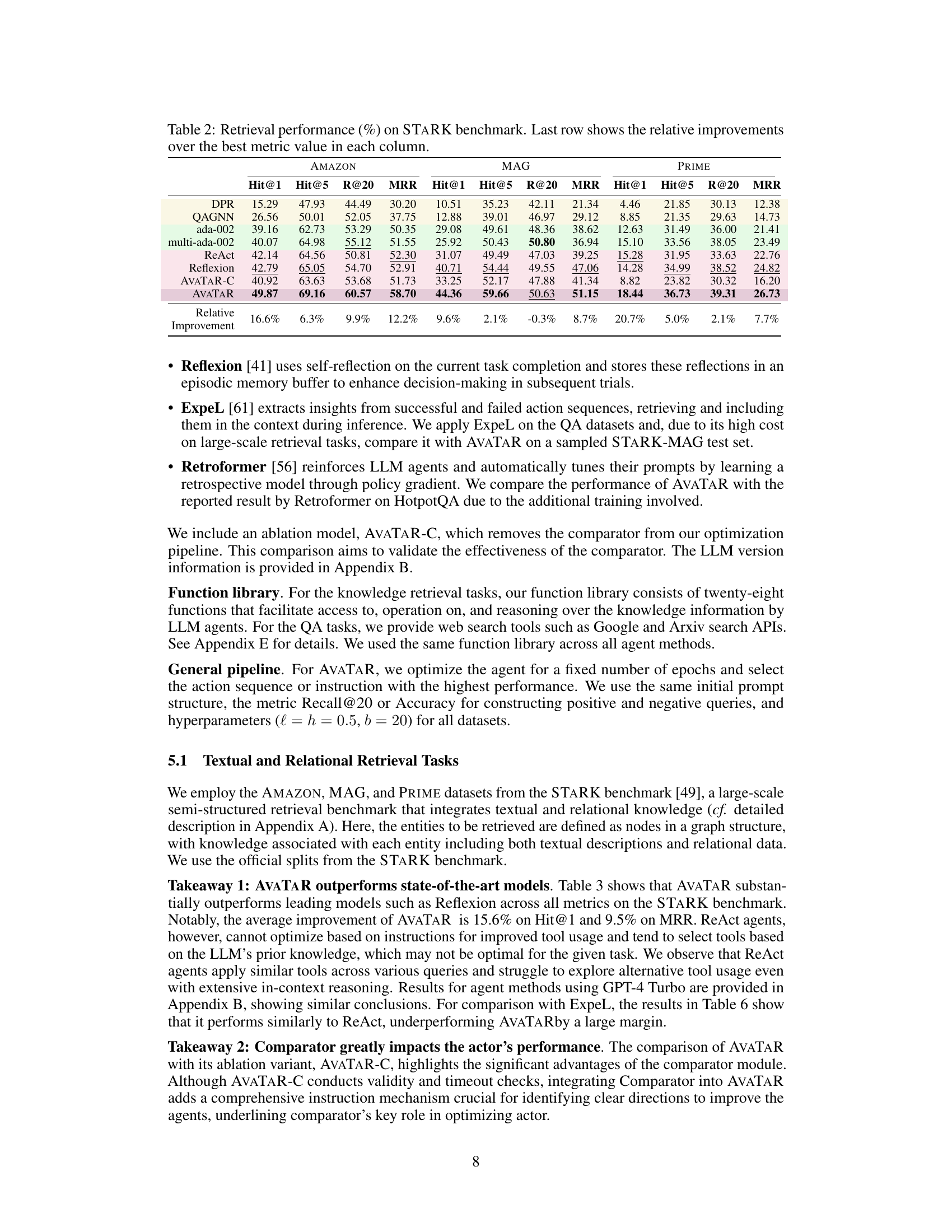
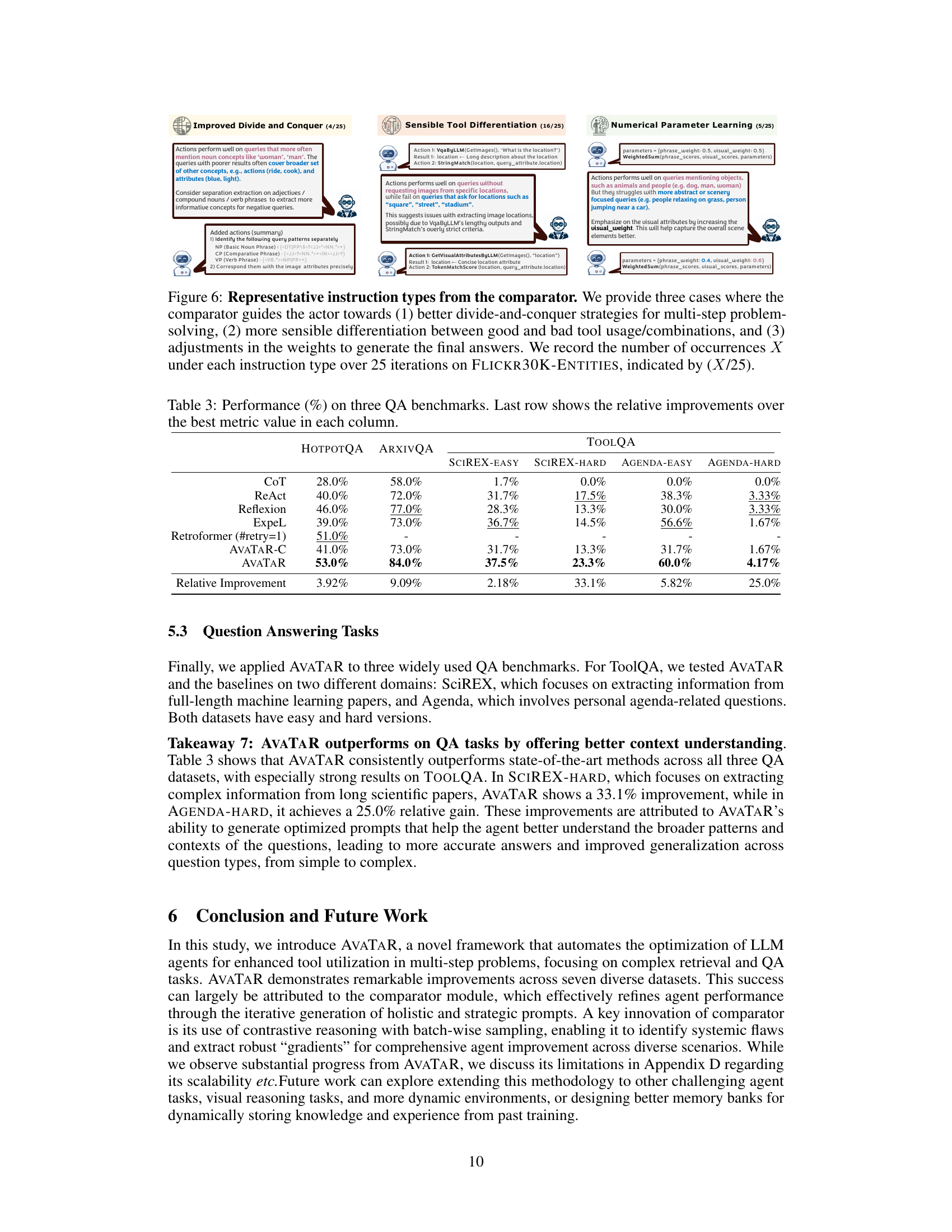
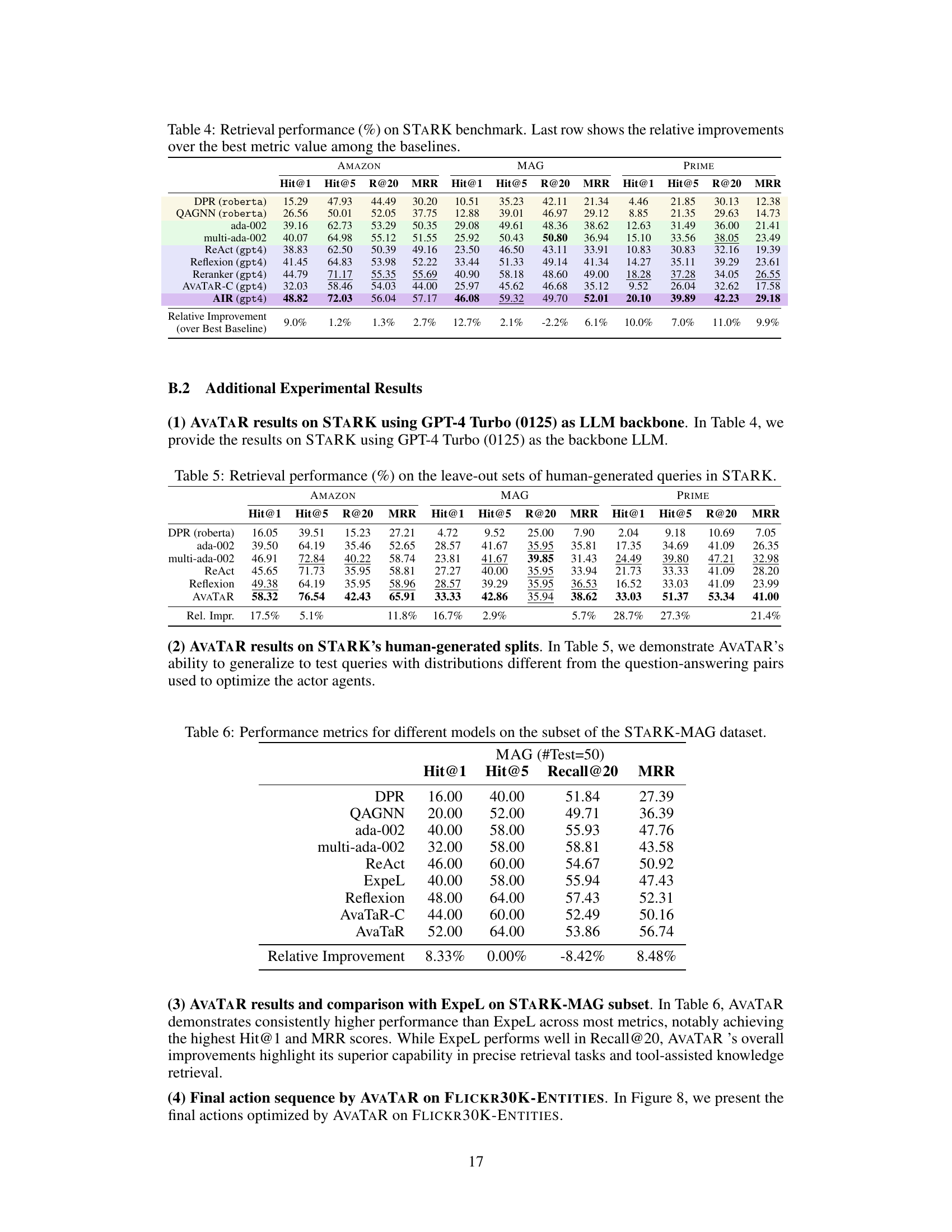
TL;DR#
Current methods for developing prompting techniques that enable LLM agents to effectively use tools are heuristic and labor-intensive. This paper introduces AVATAR, a novel automated framework that optimizes an LLM agent to effectively leverage provided tools. AVATAR uses a comparator module to contrastively reason between positive and negative examples, iteratively delivering insightful prompts.
AVATAR was demonstrated on four complex multimodal retrieval datasets and three general question-answering datasets. Results show that AVATAR consistently outperforms state-of-the-art approaches, exhibiting strong generalization ability and achieving a 14% average relative improvement in the Hit@1 metric for retrieval and 13% for QA. This automated framework addresses a key challenge in LLM agent development, significantly improving efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) and autonomous agents. It introduces a novel framework for optimizing LLM agents’ tool usage, a significant challenge in the field. The findings offer substantial improvements in performance across various complex tasks and suggest promising new avenues for developing more effective and generalizable AI agents. The automated optimization approach is particularly valuable given the labor-intensive nature of current methods, significantly accelerating research progress and advancing the state-of-the-art.
Visual Insights#
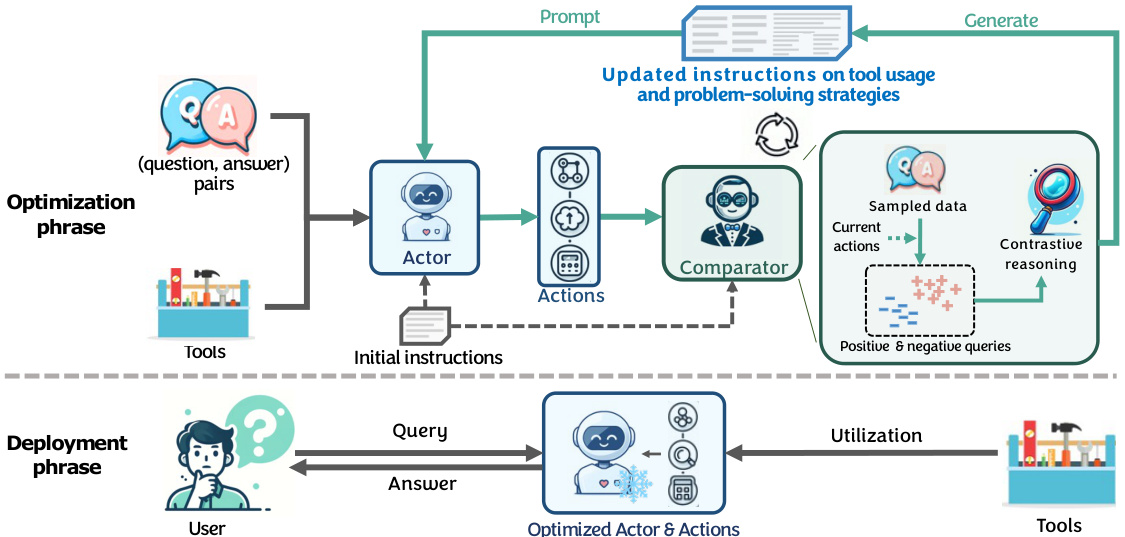
🔼 This figure illustrates the AVATAR framework, highlighting its two main components: the actor and the comparator. The actor LLM uses tools to answer queries, while the comparator LLM analyzes the actor’s performance on positive and negative examples to iteratively refine prompts and improve tool usage. The optimization phase focuses on improving the actor’s strategies through contrastive reasoning, while the deployment phase leverages the optimized actor for efficient query answering.
read the caption
Figure 1: Overview of AVATAR. AVATAR consists of a actor LLM and a comparator LLM. (a) During optimization, the actor generates actions to answer queries by leveraging the provided tools. Then, the comparator contrasts a set of well-performing (positive) and poorly-performing (negative) queries, automatically generating holistic prompts to teach the actor more effective retrieval strategies and tool usage (cf. Section 4). (b) At deployment, the actor with optimized prompts or actions can be effectively used to answer new queries.

🔼 This table summarizes the key differences between AVATAR and other existing agent methods (ReAct, Self-refine, and Reflexion) across four aspects: self-improvement, memory retention, generalization ability, and holistic prompt generation for tool usage. It highlights that AVATAR outperforms other methods in all four aspects, particularly in generating holistic prompts that effectively guide tool usage.
read the caption
Table 1: Key differences between AVATAR and prevailing agent methods. AVATAR demonstrates the ability to: 1) self-improve on specific tasks, 2) retain memory throughout the optimization process, 3) enhance the agent's generalization capability, and 4) autonomously generate holistic, high-quality prompts for better tool usage. Please refer to Section 4 for details.
In-depth insights#
LLM Tool Use#
The effective utilization of external tools by Large Language Models (LLMs) is a crucial area of research. LLM tool use significantly enhances capabilities, moving beyond simple question answering to complex, multi-step problem solving. However, current approaches often rely on heuristics and manual prompt engineering, which is both time-consuming and inefficient. This necessitates the development of automated frameworks to optimize tool usage. Key challenges involve the effective decomposition of complex tasks into smaller, manageable sub-tasks, strategic tool selection and sequencing, and the synthesis of intermediate results into coherent outputs. Promising solutions leverage techniques such as contrastive reasoning, which compares successful and unsuccessful tool usage examples to iteratively refine prompt strategies. This leads to significant performance gains across various tasks, demonstrating the effectiveness of automated optimization techniques. Furthermore, generalization ability is critical; optimized LLM agents should perform well on unseen instances, a key aspect requiring further investigation. Future research directions should explore more sophisticated prompt optimization methods, more robust mechanisms for handling tool errors and failures, and methods to enhance the explainability and transparency of the reasoning process. Ultimately, effective LLM tool use is essential for achieving truly intelligent and autonomous agents that can seamlessly leverage external resources to solve complex real-world problems.
Contrastive Training#
Contrastive training is a powerful technique for improving the performance of machine learning models, particularly in scenarios involving complex data or ambiguous labels. The core idea is to learn by comparing and contrasting different data points, explicitly pushing similar instances closer together in the embedding space while simultaneously separating dissimilar ones. This approach forces the model to learn more nuanced representations that capture subtle differences, leading to enhanced generalization and robustness. Effective implementation requires careful consideration of several factors, including the selection of appropriate similarity and dissimilarity measures, the sampling strategy for data pairs, and the choice of loss function. The design of a suitable contrastive loss is crucial; it must effectively balance the pull towards similarity and the push away from dissimilarity. While computationally more expensive than traditional training methods, the potential gains in accuracy and robustness often justify the increased cost. Successfully applying contrastive training can significantly benefit various domains such as image classification, natural language processing, and recommendation systems, where capturing fine-grained semantic distinctions is vital for superior performance.
Multi-step Reasoning#
Multi-step reasoning is a crucial capability for advanced artificial intelligence, enabling systems to solve complex problems that require a sequence of actions and decisions. Effective multi-step reasoning necessitates several key components: Firstly, the ability to decompose complex problems into smaller, manageable sub-problems. This decomposition is essential for breaking down the initial challenge into a series of steps that can be addressed individually. Secondly, robust planning and decision-making capabilities are needed to sequence actions strategically, maximizing the chances of success while mitigating potential risks. This requires the ability to predict the outcomes of individual actions and adapt the plan accordingly. Thirdly, effective utilization of external tools and resources is key. Many complex problems require leveraging external information or executing specialized operations, which necessitates seamless integration of the reasoning system with such tools. Finally, successful multi-step reasoning must exhibit both robustness and generalizability. A robust system can handle unexpected events or erroneous intermediate results without catastrophic failure. Generalizability ensures that the reasoning process effectively transfers to novel problems and situations, demonstrating true intelligence rather than simple pattern-matching.
Generalization Ability#
A crucial aspect of any machine learning model, especially large language models (LLMs) used as agents, is its generalization ability. Strong generalization means the model can successfully apply what it has learned to new, unseen situations or tasks that differ from those encountered during training. In the context of LLM agents, this is paramount, as they need to function effectively in real-world scenarios where novelty and uncertainty are inherent. The paper’s methodology attempts to achieve this through optimization techniques designed to improve the agent’s ability to use tools strategically, which should improve performance on various tasks. The effectiveness of these techniques is often assessed via metrics like Hit@1 or Recall@20. Contrastive reasoning, a key component of this approach, is specifically aimed at helping the model distinguish between effective and ineffective tool usage. By learning from both successful and unsuccessful attempts, the model is better equipped to generalize. However, the question of how well this optimization translates into improved generalization remains a significant point requiring attention. The paper’s empirical results showing improvement across datasets hints at good generalization, but further, more rigorous evaluations against unseen datasets would greatly enhance the evidence of genuine generalization ability.
Future Work#
The authors suggest several promising avenues for future research. Extending AVATAR to handle more complex tasks and diverse data modalities is a key area. This could involve incorporating more sophisticated tools, perhaps even allowing the agent to dynamically discover and learn new tools through interaction with the environment. Another crucial direction is improving the scalability and efficiency of AVATAR. The current framework relies on computationally expensive large language models, and optimizing its efficiency for real-world deployment is essential. The development of more robust and adaptive memory mechanisms to learn from and generalize across diverse situations is also critical. Finally, the authors propose a deeper investigation into the theoretical underpinnings of contrastive reasoning, examining its impact on the generalization and learning abilities of LLM agents. This enhanced understanding would guide the design of more effective training strategies. Overall, the future work outlined emphasizes increasing the robustness, efficiency, and generalizability of LLM agents, paving the way for broader real-world applications.
More visual insights#
More on figures

🔼 This figure compares the performance of AVATAR and ReAct on a sample query. ReAct uses lengthy string matching and suboptimal tool combinations, resulting in poor performance. AVATAR, in contrast, effectively decomposes the query into multiple steps (decomposing into sub-queries, using embedding tool to filter, using token matching, LLM reasoning for validation), which improves the overall accuracy of the system. It uses a more sophisticated approach, utilizing multiple tools strategically and combining scores with learned parameters, thus achieving significantly better results.
read the caption
Figure 2: Comparison between AVATAR and ReAct. (a) The ReAct agent exhibits incomplete task decomposition and employs suboptimal tool combinations, such as lengthy string matching, leading to poor task performance. (b) AVATAR decomposes the task into multiple steps, such as type filtering and flexible token matching. Moreover, it implements robust tool usage and precise synthesis with learned parameters from the optimization phase to achieve excellent performance on new queries.
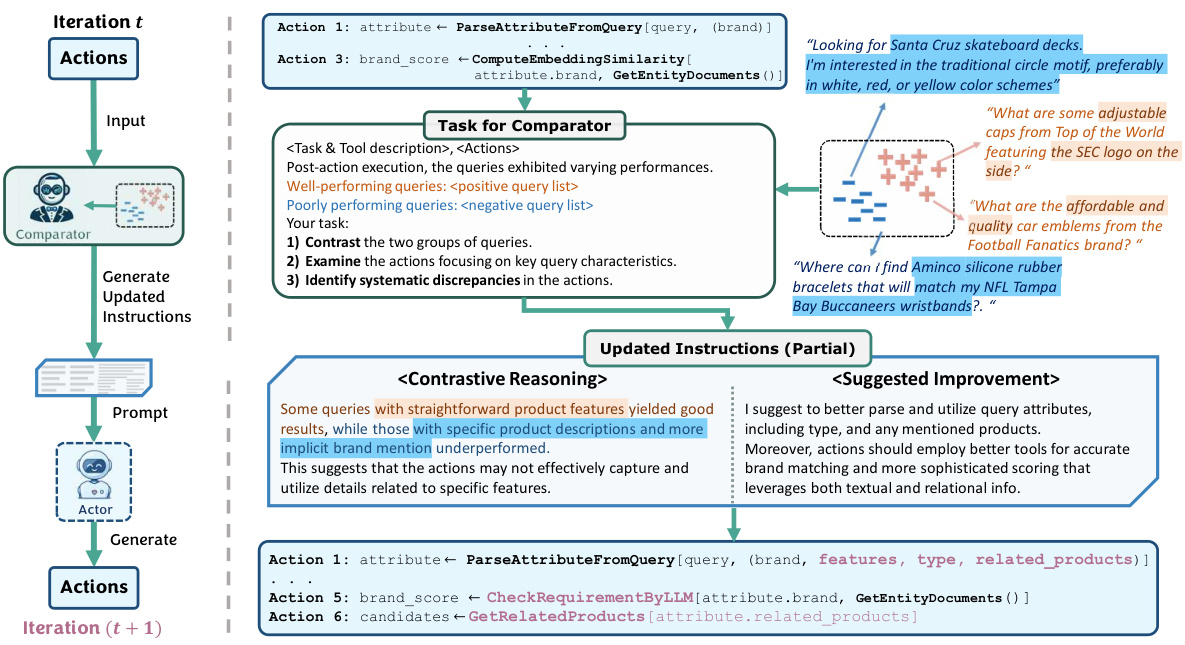
🔼 This figure shows a demonstration of AVATAR’s optimization process. The comparator analyzes positive (successful) and negative (unsuccessful) query examples from the actor’s previous attempts. By contrastively reasoning between these examples, the comparator generates holistic instructions (not just single-query corrections) to improve the actor’s query decomposition strategy, tool selection, and use of information. The updated instructions are shown to guide the actor toward improved performance in subsequent iterations.
read the caption
Figure 3: Demonstration example during optimization. Best viewed in color. The task of the comparator is to automatically generate instructions based on sampled positive and negative queries. Then comparator provides holistic instructions that guide the actor to improve query decomposition, utilize better tools, and incorporate more comprehensive information.

🔼 This figure displays the performance of AVATAR agents during the optimization process on the STARK benchmark. Three subplots show the optimization dynamics for each of the three datasets within the STARK benchmark (Amazon, MAG, Prime). The solid lines represent the validation performance at each iteration, while the dashed lines represent the moving average of the validation performance. This visualization helps to understand how AVATAR agents improve over iterations and to assess the stability and convergence of the optimization process.
read the caption
Figure 4: Optimization dynamics of AVATAR agents on STARK. The figures show validation performance (solid line) and its moving average (dashed line) during the optimization of AVATAR.

🔼 This figure displays graphs illustrating the performance of AVATAR agents on the STARK benchmark during the optimization process. The graphs plot the validation performance (solid line) and its moving average (dashed line) over a series of iterations. This visualization helps to show the improvement of AVATAR during optimization process. There are three subfigures which correspond to three different metrics (Hit@1, Hit@5, MRR).
read the caption
Figure 4: Optimization dynamics of AVATAR agents on STARK. The figures show validation performance (solid line) and its moving average (dashed line) during the optimization of AVATAR.

🔼 This figure shows a demonstration of AVATAR’s optimization process. The comparator module analyzes positive (successful) and negative (unsuccessful) query examples. Based on this analysis, the comparator generates improved instructions for the actor module. These instructions guide the actor to enhance its query decomposition strategy, select more appropriate tools, and utilize more comprehensive information when responding to new queries, ultimately leading to improved performance. The visual representation illustrates the iterative process of contrastive reasoning and instruction refinement.
read the caption
Figure 3: Demonstration example during optimization. Best viewed in color. The task of the comparator is to automatically generate instructions based on sampled positive and negative queries. Then comparator provides holistic instructions that guide the actor to improve query decomposition, utilize better tools, and incorporate more comprehensive information.

🔼 This figure shows three example images from the FLICKR30K-ENTITIES dataset. Each image has multiple bounding boxes highlighting different objects within the image. Each bounding box is also associated with a textual description, which is displayed in the figure. The images represent diverse scenes, including a portrait of a person wearing an orange hat and glasses, a group of people at a pride parade, and a wedding scene. This visual representation demonstrates how images and associated textual descriptions are organized in the dataset, emphasizing its multimodal and complex nature.
read the caption
Figure 7: Example data on FLICKR30K-ENTITIES. Each entity is an image along with its image patches and associated phrases with the image patches.
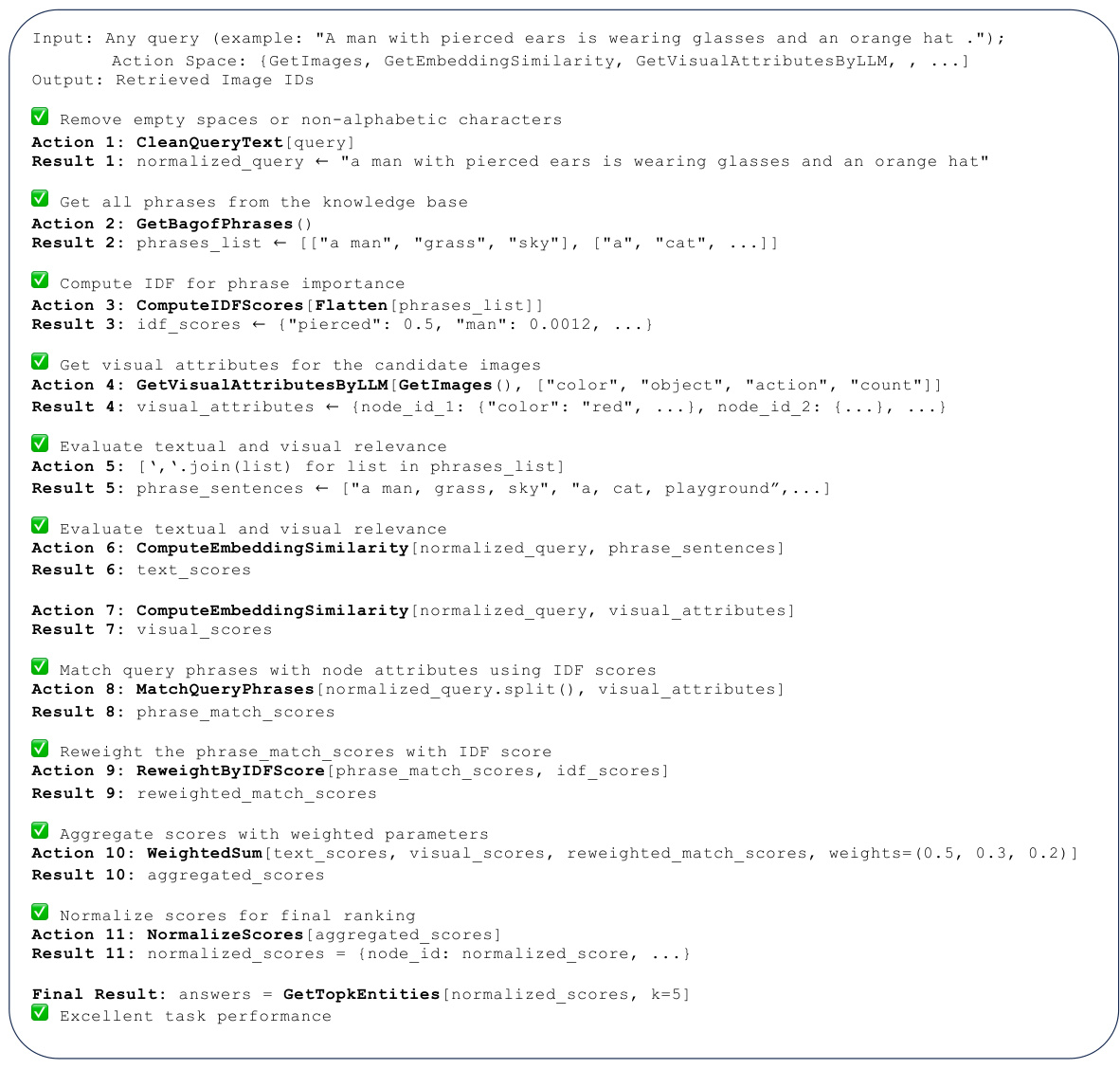
🔼 This figure demonstrates an example of how the AVATAR framework works during optimization. The comparator module analyzes positive and negative query examples to identify systematic flaws in the actor’s actions and tool usage. Then, it generates holistic instructions to guide the actor towards improved query decomposition, more effective tool selection, and the use of more comprehensive information. The illustration shows iterative updates to the instructions and the actor’s actions, highlighting the contrastive reasoning mechanism of AVATAR.
read the caption
Figure 3: Demonstration example during optimization. Best viewed in color. The task of the comparator is to automatically generate instructions based on sampled positive and negative queries. Then comparator provides holistic instructions that guide the actor to improve query decomposition, utilize better tools, and incorporate more comprehensive information.
More on tables
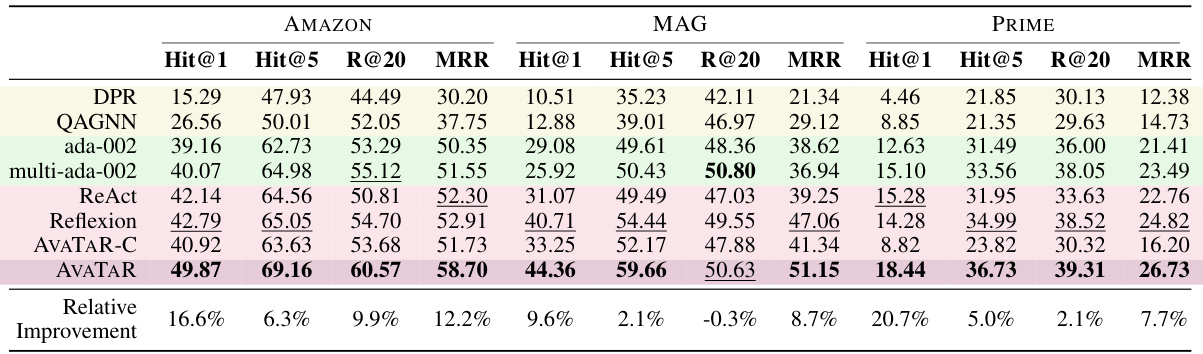
🔼 This table presents the results of the retrieval performance of different models on the STARK benchmark dataset. The metrics used are Hit@1, Hit@5, Recall@20, and MRR (Mean Reciprocal Rank). The models compared are DPR, QAGNN, ada-002, multi-ada-002, ReAct, Reflexion, AVATAR-C, and AVATAR. The last row shows the percentage improvement of AVATAR over the best performing baseline for each metric across all three subsets of the STARK dataset (AMAZON, MAG, PRIME).
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
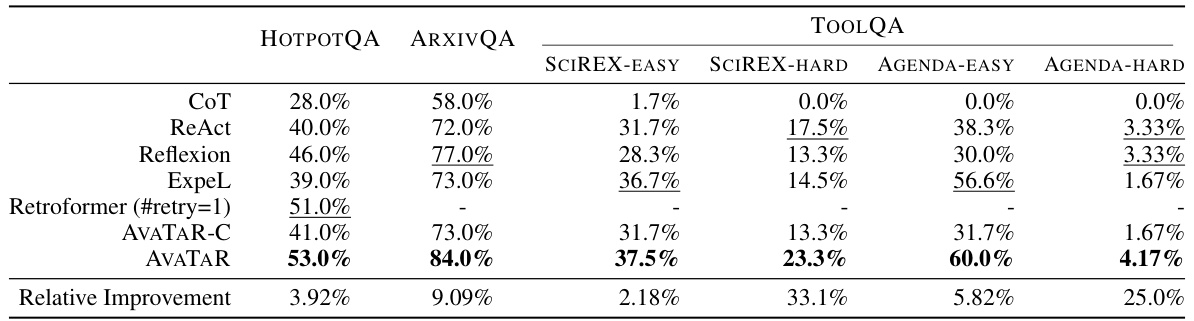
🔼 This table presents the performance of different models on three question answering benchmarks: HotpotQA, ArxivQA, and ToolQA. The performance is measured by several metrics, including exact match, and the last row shows the percentage improvement of AVATAR over the best performing baseline model for each metric on each benchmark.
read the caption
Table 3: Performance (%) on three QA benchmarks. Last row shows the relative improvements over the best metric value in each column.

🔼 This table presents the results of retrieval experiments conducted on the STARK benchmark dataset. It compares the performance of several retrieval methods, including DPR, QAGNN, ada-002, multi-ada-002, ReAct, Reflexion, AVATAR-C, and AVATAR. The performance metrics used are Hit@1, Hit@5, Recall@20, and MRR (Mean Reciprocal Rank), calculated across three subsets of the STARK benchmark: AMAZON, MAG, and PRIME. The last row shows the percentage improvement of AVATAR over the best-performing baseline for each metric and dataset.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
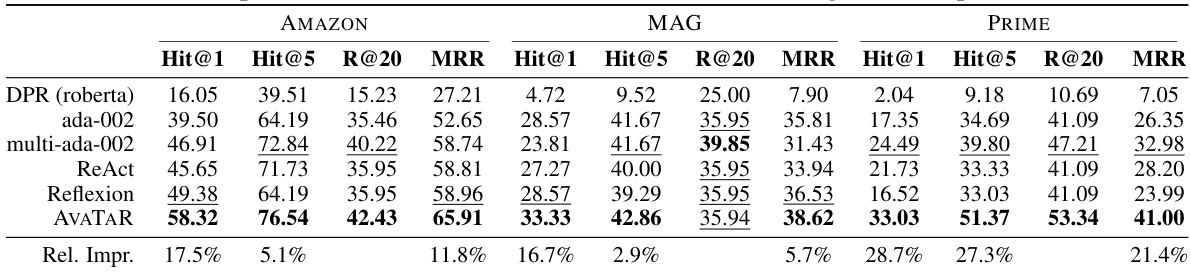
🔼 This table presents the performance of different retrieval models on the STARK benchmark dataset. The models are compared across various metrics, including Hit@1, Hit@5, Recall@20, and MRR, for three different subsets of the dataset (AMAZON, MAG, PRIME). The last row shows the percentage improvement of AVATAR compared to the best-performing baseline model for each metric.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
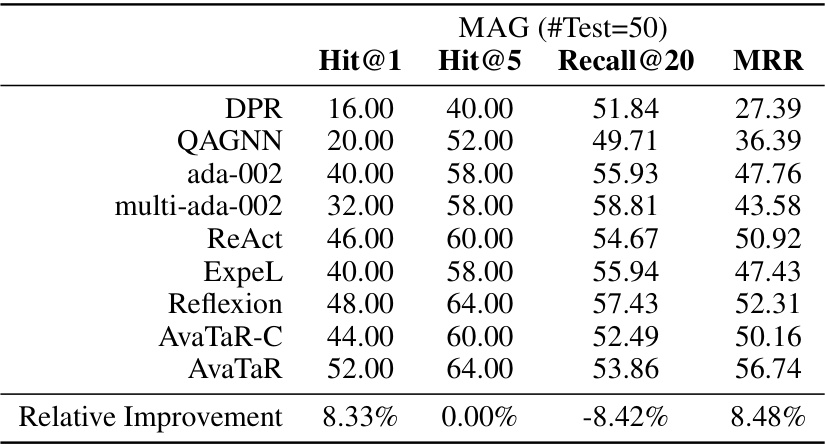
🔼 This table presents the performance of different retrieval models on the STARK benchmark. The models are evaluated using four metrics: Hit@1, Hit@5, Recall@20, and MRR. The table shows the performance of several baselines (DPR, QAGNN, ada-002, multi-ada-002, ReAct, Reflexion, AVATAR-C) and the proposed model, AVATAR. The last row displays the relative improvement achieved by AVATAR compared to the best-performing baseline for each metric. The results demonstrate the superior performance of the AVATAR model on this benchmark.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
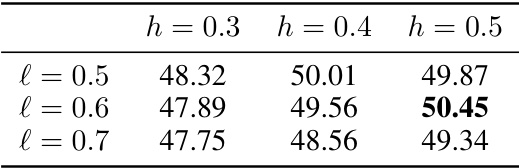
🔼 This table presents the performance of different retrieval models on the STARK benchmark, including DPR, QAGNN, ada-002, multi-ada-002, ReAct, and Reflexion. The metrics used are Hit@1, Hit@5, Recall@20, and MRR. The results are broken down by dataset (AMAZON, MAG, PRIME). The final row shows the percentage improvement of AVATAR over the best performing baseline model for each metric and dataset.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.

🔼 This table presents the results of the retrieval performance on the STARK benchmark using different methods. The metrics used include Hit@1, Hit@5, Recall@20, and MRR (Mean Reciprocal Rank). The table compares AVATAR’s performance against several baselines (DPR, QAGNN, ada-002, multi-ada-002, ReAct, and Reflexion) across three subsets of the benchmark (AMAZON, MAG, and PRIME). The last row shows the percentage improvement of AVATAR relative to the best-performing baseline for each metric and dataset.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
🔼 This table presents the performance of different retrieval models on the STARK benchmark across three datasets: AMAZON, MAG, and PRIME. The metrics used are Hit@1, Hit@5, Recall@20, and MRR. The table compares the performance of AVATAR against several baselines including DPR, QAGNN, ada-002, multi-ada-002, ReAct, and Reflexion. The last row shows the relative improvement of AVATAR over the best performing baseline for each metric and dataset.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
🔼 This table presents the results of retrieval experiments conducted on the STARK benchmark, a large-scale semi-structured retrieval benchmark. It compares the performance of several methods, including DPR, QAGNN, ada-002, multi-ada-002, ReAct, Reflexion, AVATAR-C and AVATAR, across three different subsets of the benchmark (AMAZON, MAG, PRIME). The metrics used are Hit@1, Hit@5, Recall@20, and MRR. The last row shows the relative improvement of AVATAR over the best performing baseline for each metric and dataset.
read the caption
Table 2: Retrieval performance (%) on STARK benchmark. Last row shows the relative improvements over the best metric value in each column.
Full paper#