↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Recurrent neural networks (RNNs) and Transformers are commonly used in reinforcement learning (RL) to handle partially observable Markov decision processes (POMDPs). However, they suffer from scalability issues when dealing with long sequences, often requiring the splitting of sequences into smaller segments, which reduces efficiency and introduces theoretical problems. Prior work has attempted to address these limitations with varying degrees of success, but a truly effective and general solution has been lacking. This research highlights the shortcomings of existing segment-based approaches, paving the way for a novel solution.
The core contribution of this paper is the introduction of memoroids, a novel mathematical framework based on monoids. The authors show how many existing efficient memory models can be formulated as memoroids. This framework is leveraged to develop Tape-Based Batching (TBB), a new batching method that eliminates the need for segmenting long sequences. TBB significantly improves sample efficiency and return while simplifying the implementation of loss functions. Experiments demonstrate the superiority of TBB over traditional segment-based approaches across various tasks and memory models.
Key Takeaways#
Why does it matter?#
This paper is significant because it offers a novel solution to a critical problem in recurrent reinforcement learning (RL): the inefficiency of handling long sequences. By introducing memoroids, a new mathematical framework, and Tape-Based Batching (TBB), the researchers dramatically improve sample efficiency and simplify implementation. This work has the potential to accelerate the development of RL models for complex tasks that require processing extensive data streams.
Visual Insights#

This figure illustrates the Segment-Based Batching (SBB) method commonly used in reinforcement learning. A worker collects multiple episodes of data, each represented by a different color. Because recurrent neural networks (RNNs) and Transformers have difficulty handling variable-length sequences, the episodes are split into fixed-length segments (length L). Shorter episodes are padded with zeros to match the length L. This padding introduces inefficiencies (wasted computation, biased normalization), and theoretical problems (inability to backpropagate through the entire episode due to the padding).

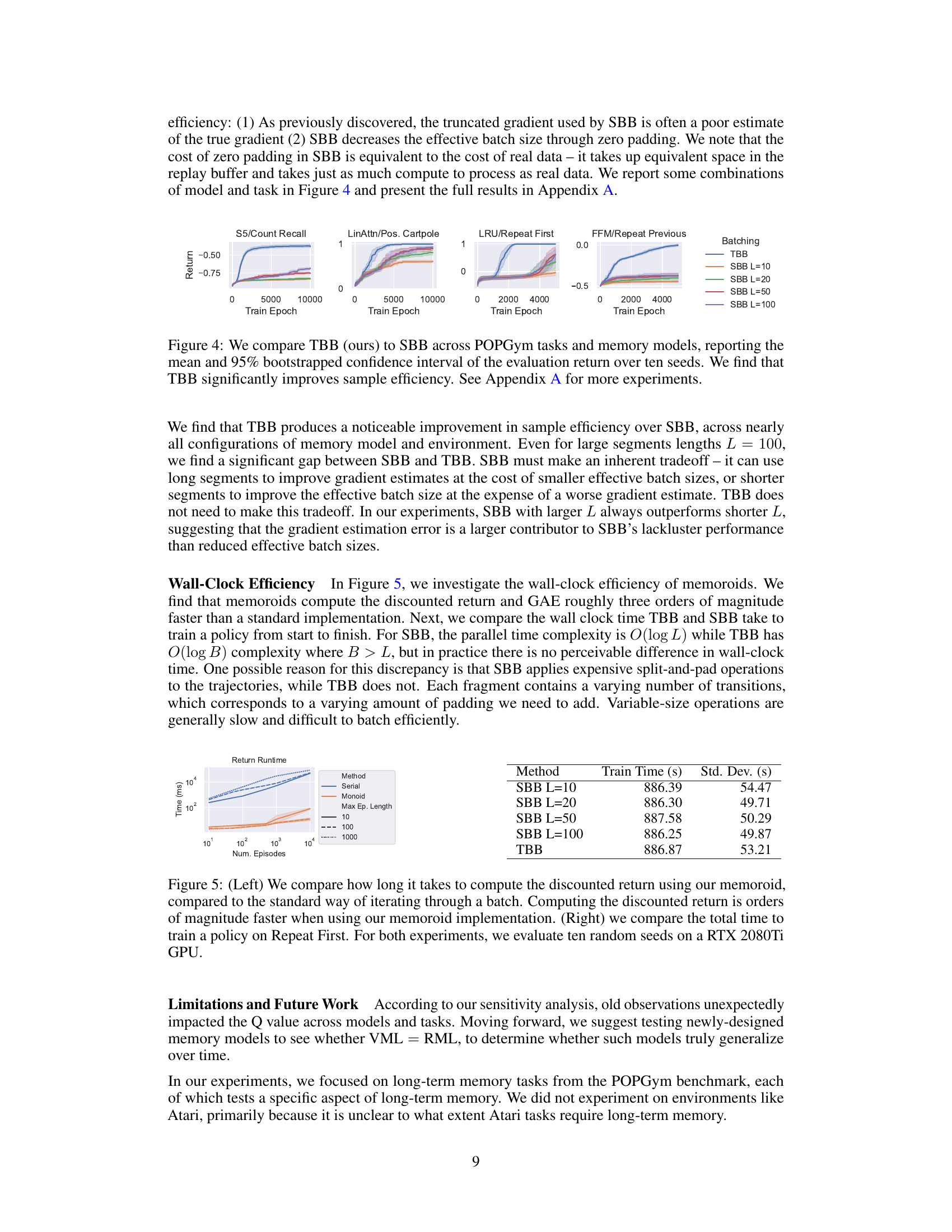
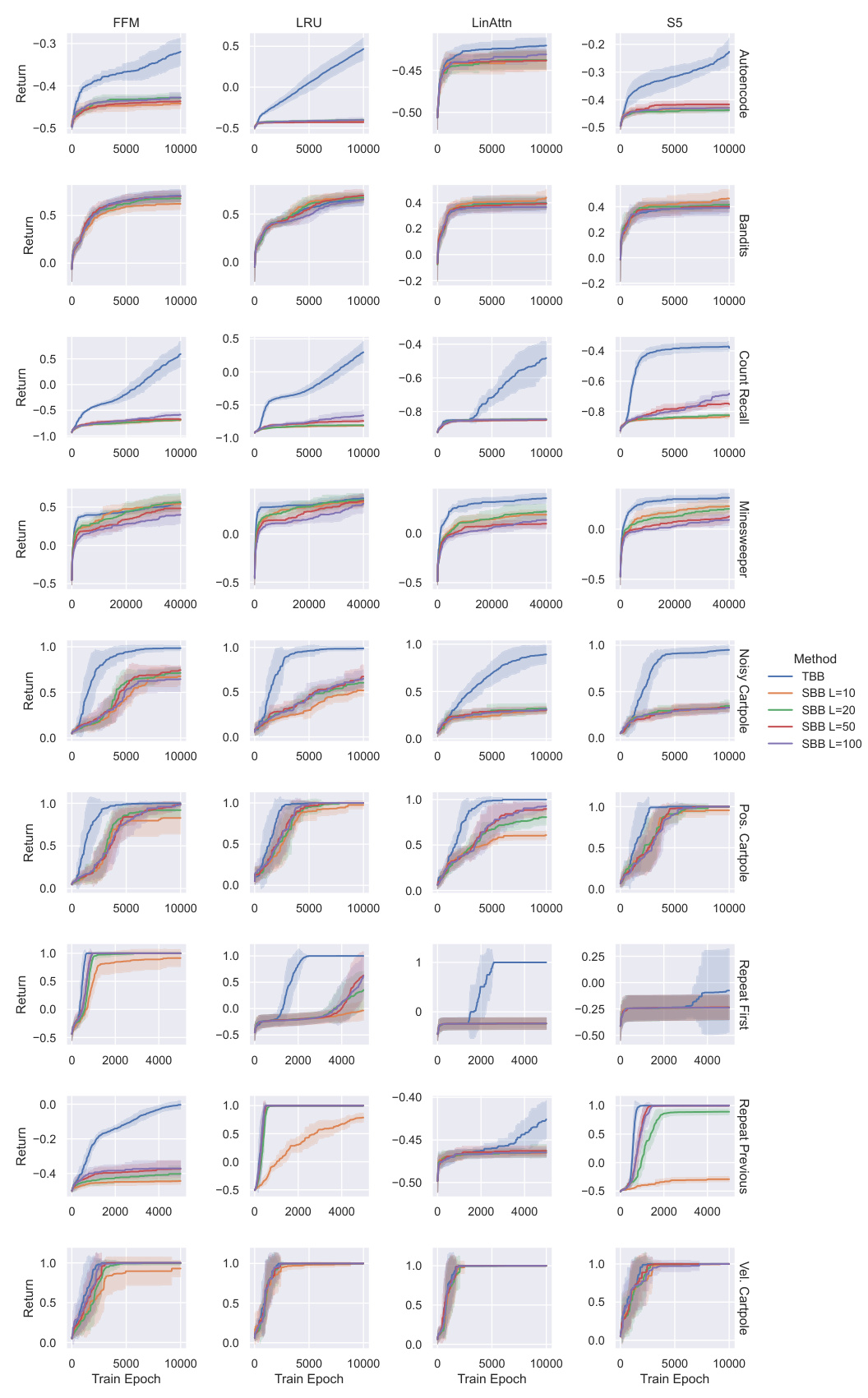
This figure compares the performance of Tape-Based Batching (TBB) and Segment-Based Batching (SBB) across various tasks and memory models within the POPGym benchmark. The results show the mean evaluation return and 95% bootstrapped confidence intervals across ten different seeds for each configuration. The key finding is that TBB significantly improves sample efficiency compared to SBB.
In-depth insights#
Memoroid Framework#
The core idea behind the “Memoroid Framework” is to reframe existing efficient sequence models (like Linear Transformers and Linear Recurrent Units) within a unifying mathematical structure. This structure, the memoroid, is essentially an extension of the monoid concept from category theory. Memoroids leverage the associative property of monoid operations to allow for parallel computation, significantly enhancing efficiency when processing long sequences. The key advantage is the elimination of the need for segment-based batching, a common but inefficient approach in recurrent reinforcement learning. This approach introduces theoretical issues, reduces efficiency, and increases complexity. By using memoroids and a novel batching technique (Tape-Based Batching), the authors aim to improve sample efficiency, increase return, and simplify implementation in recurrent RL scenarios. The framework offers a clean, mathematically grounded method for dealing with sequences of varying lengths, thereby overcoming limitations of traditional recurrent models in handling long, variable-length sequences.
TBB Batching#
The proposed Tape-Based Batching (TBB) method offers a significant advancement in handling variable-length sequences in recurrent reinforcement learning. It elegantly removes the need for segment-based batching, a common practice that introduces inefficiencies and theoretical issues like zero-padding and truncated backpropagation. TBB leverages the inherent efficiency of memoroids, a novel framework for representing memory models, to process multiple episodes concurrently. By concatenating episodes into a single, continuous tape and using a resettable monoid transformation, TBB eliminates the need for segmentation, improving sample efficiency and simplifying loss function implementation. This approach allows for parallelization across the entire sequence and avoids information leakage between episodes, which is a limitation of other methods. The results demonstrate substantial improvements in sample efficiency and return, particularly in tasks with long-range temporal dependencies, making TBB a superior alternative to existing methods. The key contribution lies in the combination of memoroids and a novel reset mechanism that enables seamless and efficient processing of variable-length sequences without the drawbacks of traditional approaches.
SBB Shortcomings#
The segment-based batching (SBB) approach, while prevalent in recurrent reinforcement learning, suffers from several critical shortcomings. Zero-padding, used to standardize segment lengths, wastes computational resources and hinders normalization techniques like batch normalization. This padding also truncates backpropagation through time (BPTT), limiting the model’s capacity to learn long-range dependencies crucial for many tasks. The resulting approximation of the true gradient with the truncated BPTT gradient reduces the accuracy and effectiveness of training. Finally, SBB adds significant implementation complexity, requiring careful management of segments and masks, thus reducing overall efficiency. These limitations highlight the need for alternative batching strategies that can overcome the inherent limitations of SBB.
Recurrent Value#
In recurrent reinforcement learning, the concept of “Recurrent Value” signifies the value estimations produced by recurrent neural networks (RNNs) or similar models to estimate the expected cumulative reward. Unlike traditional value functions in Markov Decision Processes (MDPs) which consider only the current state, recurrent value functions leverage past observations and actions, represented by a hidden state, to produce more informed value estimates. This is crucial for handling partial observability, where the true state is hidden and only noisy or ambiguous observations are available. However, the efficiency and accuracy of recurrent value functions are significantly affected by the chosen memory model and the training method. The paper highlights the inefficiencies of segment-based batching, a standard technique in recurrent RL, which truncates long sequences of observations impacting backpropagation and limiting the ability to learn long-range dependencies. It introduces the concept of ‘memoroids’, emphasizing the use of mathematical monoids to create computationally efficient memory models that overcome these limitations. Memoroids allow for efficient handling of variable-length sequences without the need for segmentation, thus potentially leading to improved sample efficiency and more accurate recurrent value estimates. The significance of this work lies in its contribution to more robust and efficient learning in partially observable environments, improving the accuracy and scalability of recurrent value functions through a novel architectural and training methodology.
Future Work#
The paper’s lack of a dedicated ‘Future Work’ section is notable. However, we can infer potential avenues for future research based on the paper’s limitations and open questions. Extending the memoroid framework to encompass a wider range of memory models is crucial, and investigating its applicability to more complex tasks beyond those in POPGym would enhance its significance. Addressing the efficiency trade-off observed between TBB’s logarithmic scaling with batch size and SBB’s logarithmic scaling with segment length is paramount. Thoroughly exploring the impact of very long sequences on TBB’s performance is also vital, as the current study’s sequences were relatively short. Finally, deepening the understanding of the relationship between RML and VML is essential to assess the effectiveness of TBB in fully capturing temporal dependencies for various tasks. This will involve rigorous experimentation to determine whether efficient models can consistently achieve VML = RML, signifying that they learn only necessary temporal information. In essence, future work should focus on broadening the applicability and improving the efficiency and understanding of the proposed memoroid and TBB methods.
More visual insights#
More on figures
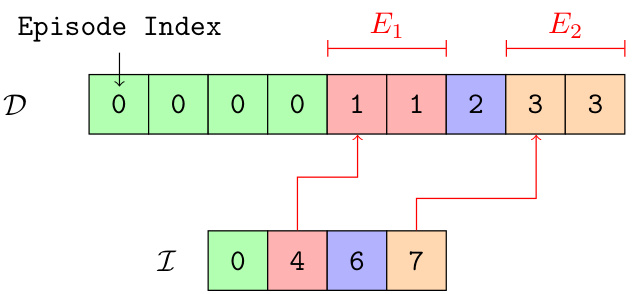
This figure illustrates the Tape-Based Batching (TBB) method for sampling training data. Transitions from multiple episodes are concatenated into a single tape (D). Episode boundaries are marked in a separate index array (I). The method randomly selects B episode segments to form a training batch, concatenating consecutive transitions from the selected episodes. This avoids zero-padding and allows for efficient handling of variable-length episodes.

This figure illustrates the Segment-Based Batching (SBB) method commonly used in recurrent reinforcement learning. It shows how a worker collects multiple episodes of data, where each episode is a sequence of transitions. To handle variable episode lengths, the episodes are split into fixed-length segments and padded with zeros. This padding leads to several inefficiencies, such as reduced computational efficiency and biased normalization.

This figure illustrates the Segment-Based Batching (SBB) method commonly used in recurrent reinforcement learning. It shows how a worker collects episodes, which are then split into fixed-length segments and zero-padded. This process leads to several inefficiencies, including wasted computation on padding, biased normalization due to padding, and a limitation of backpropagation through time. The figure highlights the problems with using fixed-length segments and motivates the need for the proposed Tape-Based Batching method which removes the need for segmentation.

This figure illustrates the Segment-Based Batching (SBB) method commonly used in recurrent reinforcement learning. It shows how a rollout (a sequence of episodes) is processed. Each episode is broken into fixed-length segments, and any remaining space in a segment is filled with zeros (zero-padding). The zero-padding and segmentation introduce issues, such as reduced efficiency, biased normalization, and problems with backpropagation. The image displays episodes, denoted by color, which are partitioned into segments, highlighting their fixed size, zero-padding, and batching dimension.
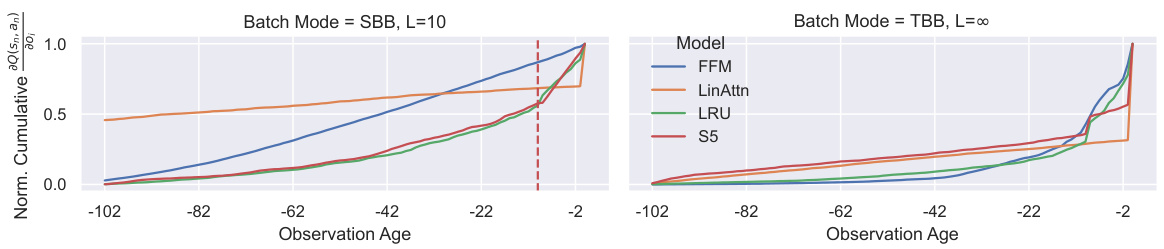
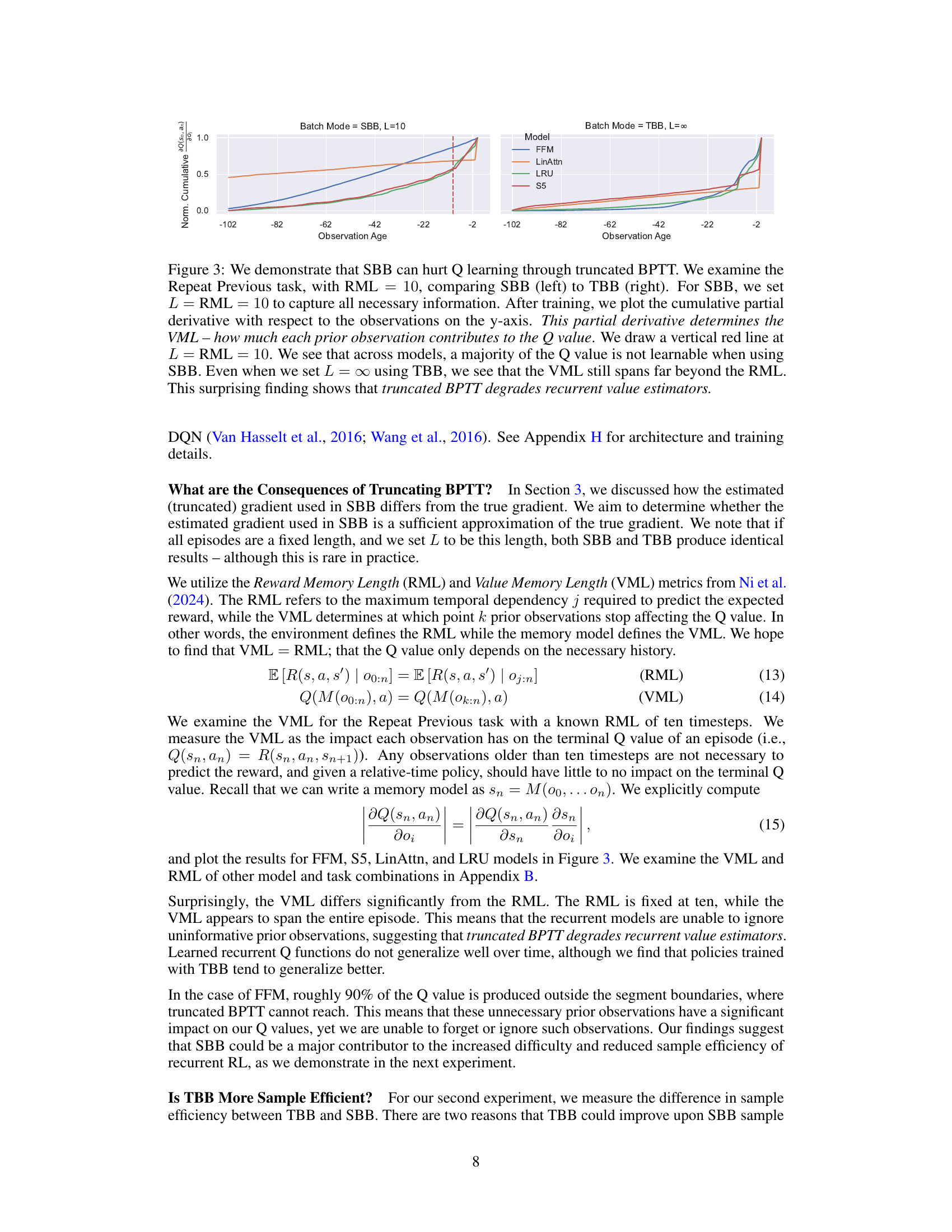
This figure compares the effects of Segment-Based Batching (SBB) and Tape-Based Batching (TBB) on learning in a recurrent Q-learning setting using the Repeat Previous task. The y-axis shows the cumulative partial derivative of the Q-value with respect to past observations (Value Memory Length or VML), while the x-axis represents the age of the observation. The red dashed line indicates the Reward Memory Length (RML), which represents the length of the past observations necessary to predict the reward. The left panel shows the results for SBB and the right for TBB. The figure demonstrates that with SBB, much of the Q-value is not learned due to truncated backpropagation through time, while with TBB, the VML extends beyond the RML, indicating the need for a more complete backpropagation approach.

This figure compares the performance of Tape-Based Batching (TBB) and Segment-Based Batching (SBB) across various tasks and memory models in the POPGym benchmark. The y-axis represents the evaluation return, and the x-axis represents the training epoch. Error bars (95% bootstrapped confidence intervals) show the variability in performance across multiple runs (10 seeds). The results demonstrate a significant improvement in sample efficiency using TBB compared to SBB, regardless of the segment length used in SBB. Appendix A contains further experimental results.
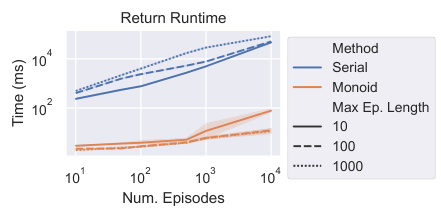
The left panel shows that using memoroids to compute the discounted return is significantly faster than the traditional method. The right panel compares the total training time for TBB and SBB on the Repeat First task, showing that there is no significant difference in training time despite the logarithmic difference in computational complexity.
This figure illustrates the common segment-based batching method in recurrent reinforcement learning. Rollouts (sequences of interactions) are divided into fixed-length segments, zero-padded to ensure consistent length, and processed as batches. This method introduces inefficiencies due to the zero-padding and prevents full backpropagation through the entire sequence, affecting training efficiency and potentially biasing the results.
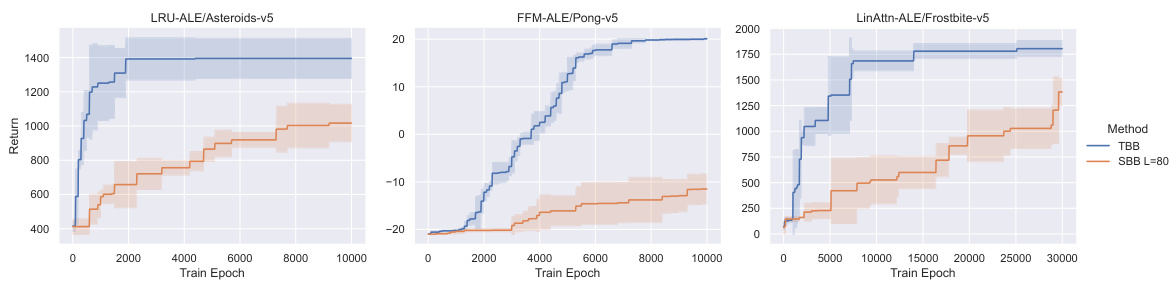
This figure compares the performance of Tape-Based Batching (TBB) against Segment-Based Batching (SBB) across three different Atari games from the Arcade Learning Environment using three different memoroid models. The results show that TBB consistently outperforms SBB across all games and models tested, demonstrating the efficacy of TBB in improving sample efficiency. The plot displays the mean and 95% confidence intervals of the cumulative return obtained over three runs with different random seeds for both TBB and SBB.
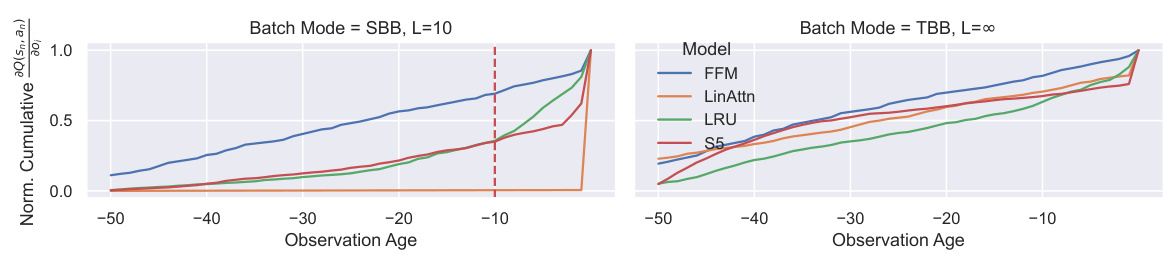
This figure compares the impact of Segment-Based Batching (SBB) and Tape-Based Batching (TBB) on the ability of recurrent models to learn long-term dependencies in a reinforcement learning task. It plots the cumulative partial derivative of the Q-value with respect to past observations, showing that SBB severely limits the model’s ability to learn from observations beyond a certain range (L=10), while TBB allows the model to learn longer-term dependencies. This demonstrates that the truncated backpropagation through time inherent in SBB degrades the accuracy and effectiveness of recurrent value estimation.
More on tables
This figure shows the results of two experiments evaluating the wall-clock efficiency of the proposed memoroid-based approach and the Tape-Based Batching (TBB) method. The left panel demonstrates the significant speedup achieved by the memoroid in computing discounted returns compared to the standard iterative method. The right panel compares the total training time for TBB against Segment-Based Batching (SBB) with various segment lengths on the Repeat First task. The results highlight the efficiency gains offered by the memoroid and TBB.

This table compares the performance of Tape-Based Batching (TBB) and Segment-Based Batching (SBB) across different tasks and memory models in the POPGym benchmark. The results show the mean and 95% confidence intervals of the evaluation return, calculated over ten different random seeds for each configuration. The key finding is that TBB significantly improves sample efficiency compared to SBB.

This figure compares the performance of Tape-Based Batching (TBB) and Segment-Based Batching (SBB) across various tasks and memory models within the POPGym benchmark. The results show the mean and 95% bootstrapped confidence intervals of the evaluation return over ten seeds. A key finding is that TBB demonstrates significantly better sample efficiency than SBB.
Full paper#