TL;DR#
Image interpolation in latent spaces is well-studied, but interpolation with specific conditions (like text) often suffers from inconsistencies and poor fidelity. Current methods typically perform linear interpolation in the conditioning space, leading to suboptimal results. The paper addresses the challenges of condition-based image interpolation, particularly when multiple conditions (such as image and text) are involved.
To tackle these challenges, the paper introduces Attention Interpolation via Diffusion (AID). AID employs a novel training-free technique that leverages a fused interpolated attention mechanism, combining both cross and self-attention to improve image consistency and fidelity. Furthermore, the paper introduces a beta distribution for coefficient selection to enhance the smoothness of interpolations. The efficacy of this approach is validated through extensive experiments and user studies, demonstrating that AID surpasses existing methods in quality and control. An extension of AID, Prompt-guided AID (PAID), offers even greater benefits for compositional image generation and image manipulation.
Key Takeaways#
Why does it matter?#
This paper is important as it presents AID, a novel training-free method for high-quality conditional image interpolation, addressing limitations of existing approaches. It offers substantial improvements in consistency, smoothness, and efficiency, impacting various downstream tasks like compositional generation and image editing, opening new research avenues in controlled image generation.
Visual Insights#

🔼 This figure demonstrates the capability of the proposed Attention Interpolation via Diffusion (AID) method for generating smooth and conceptually consistent interpolations between different image conditions. Subfigures (a), (c), (d), and (e) showcase text-to-text interpolation, while (b) shows image-to-image interpolation. Subfigure (f) highlights the method’s ability to incorporate user-specified prompts to guide the interpolation process, allowing for more nuanced control over the generated images.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This table presents a quantitative comparison of different conditional interpolation methods on two datasets: CIFAR-10 and LAION-Aesthetics. The methods compared are Text Embedding Interpolation (TEI), Denoising Interpolation (DI), AID-O, and AID-I. The table shows the smoothness, consistency, and fidelity for each method on each dataset. Part (b) shows the results of ablation studies on AID-O, demonstrating the impact of different components of the method on the overall performance.
read the caption
Table 1: Quantitative results of conditional interpolation. Quantitative results where the best performance is marked as (*) and the worst is marked as red. (a) Performance on CIFAR-10 and LAION-Aesthetics. AID-O and AID-I both show significant improvement over the Text Embedding Interpolation (TEI). Though Denoising Interpolation (DI) achieves relatively high fidelity, there is a trade-off with very bad performance on consistency (0.4295). AID-O boosts the performance in terms of consistency and fidelity while AID-I boosts the performance of smoothness; (b) Ablation studies on AID-O's components, showcase that the Beta prior enhances smoothness, attention interpolation heightens consistency, and self-attention fusion significantly elevates fidelity.
In-depth insights#
AID: Attention Interp.#
The heading “AID: Attention Interpolation” suggests a novel method for image interpolation using attention mechanisms within a diffusion model. AID likely leverages the power of attention to guide the interpolation process, resulting in smoother and more coherent transitions between images compared to naive linear interpolation in latent space. This approach is particularly valuable for conditional image generation, where the goal is to create sequences of images that smoothly evolve between different conditions, such as varying text descriptions or image prompts. The technique likely involves modifying or fusing attention layers to achieve consistent and high-fidelity results without the need for additional training. A key strength of AID is its training-free nature, which greatly reduces the computational cost and complexity associated with training new models for interpolation. The success of AID likely hinges on carefully designing the way attention mechanisms are used to ensure that image consistency and smoothness are prioritized during the transition. The results are likely more aligned with human perception of natural image sequences.
Beta Distrib. Smoothing#
The concept of ‘Beta Distrib. Smoothing’ in a research paper likely refers to a technique that uses the Beta distribution to improve the smoothness of a process or data. The Beta distribution is particularly useful for modeling probabilities, making it well-suited for smoothing problems where the output needs to transition smoothly between certain boundaries. The parameters of the Beta distribution (alpha and beta) allow for control over the shape of the distribution, offering flexibility in how the smoothing is applied. A higher alpha value will shift the distribution towards 1, while a higher beta value shifts it toward 0. By carefully selecting these parameters, the authors can tailor the smoothing to their specific needs, creating a smooth transition between different states. This technique is likely applied in the context of a generative model, either directly to the output or to an intermediate representation within the model. The authors could leverage the Beta distribution to generate interpolation coefficients that result in smoother transitions between images, for instance, during image generation or morphing processes. The use of a Beta distribution for smoothing highlights the authors’ attention to detail in ensuring a high-quality and aesthetically pleasing output. The benefits could include increased visual coherence, reducing abrupt changes, and aligning better with human perceptions of smooth transitions.
PAID: Prompt Guidance#
Prompt guidance, as embodied in the concept of PAID (Prompt-guided Attention Interpolation via Diffusion), represents a significant enhancement to the core AID (Attention Interpolation via Diffusion) method. PAID injects user-specified text prompts into the interpolation process, offering a level of control previously unavailable in diffusion model interpolation. This allows for the generation of nuanced and conceptually blended image sequences, going beyond simple linear transitions in the conditioning space. The introduction of prompt guidance addresses a key limitation of relying solely on automated interpolation between existing text embeddings, which often results in inconsistent or semantically illogical transitions. By guiding the interpolation path through explicit textual descriptions, PAID ensures greater control over the generated imagery, thus enhancing the creativity and utility of diffusion-based image interpolation for various downstream tasks such as image editing, generation, and morphing. The efficacy of this approach highlights the importance of incorporating user intent directly into generative processes, demonstrating the potential of human-in-the-loop approaches for more sophisticated image manipulation.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In a text-to-image diffusion model, this might involve removing or modifying parts of the attention mechanism (e.g., the fused inner/outer interpolated attention), the coefficient selection method (e.g., the Beta distribution), or the prompt guidance component. Results would reveal the impact of each component on key metrics like image consistency, smoothness, and fidelity. For example, removing the Beta distribution might lead to a decrease in smoothness while removing the self-attention fusion might impact fidelity. A thorough ablation study provides strong evidence for design choices by showing how each part contributes to the overall model performance. The analysis would highlight the relative importance of different components and reveal any potential trade-offs between them. The study might also investigate interactions between components, demonstrating synergistic effects where multiple components working together produce better results than the sum of their individual contributions. Analyzing the results carefully allows researchers to optimise their model by focusing resources on the most valuable components and potentially simplifying model architecture by removing less important parts.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending AID and PAID to other generative models beyond diffusion models would broaden their applicability and impact. This includes investigating their effectiveness in GANs, VAEs, and autoregressive models. Another key area is developing more sophisticated methods for selecting interpolation coefficients, potentially leveraging reinforcement learning or other adaptive techniques to optimize smoothness and consistency more effectively. Investigating the theoretical underpinnings of AID and PAID more rigorously through mathematical analysis is crucial for a deeper understanding and further improvements. Additionally, exploring different ways of incorporating user guidance, beyond simple text prompts, is essential for creating more intuitive and flexible conditional interpolation tools. This may involve incorporating visual guidance, interactive editing, or other modalities to enhance user control. Finally, addressing potential ethical concerns around the applications of AI-based image generation is paramount. This involves carefully examining the potential biases in the generated images and developing safeguards against misuse such as the creation of deepfakes.
More visual insights#
More on figures

🔼 This figure shows a comparison of image interpolation results between two methods: AID (Attention Interpolation via Diffusion) and text embedding interpolation. The top row displays the results obtained using AID, demonstrating smoother transitions and higher fidelity images. The bottom row shows the results from text embedding interpolation, which suffers from inconsistent images and lower fidelity. The figure highlights the significant improvement in image quality and consistency achieved by AID.
read the caption
Figure 2: Results comparison between AID (the 1st row) and text embedding interpolation (the 2nd row). AID increases smoothness, consistency, and fidelity significantly.
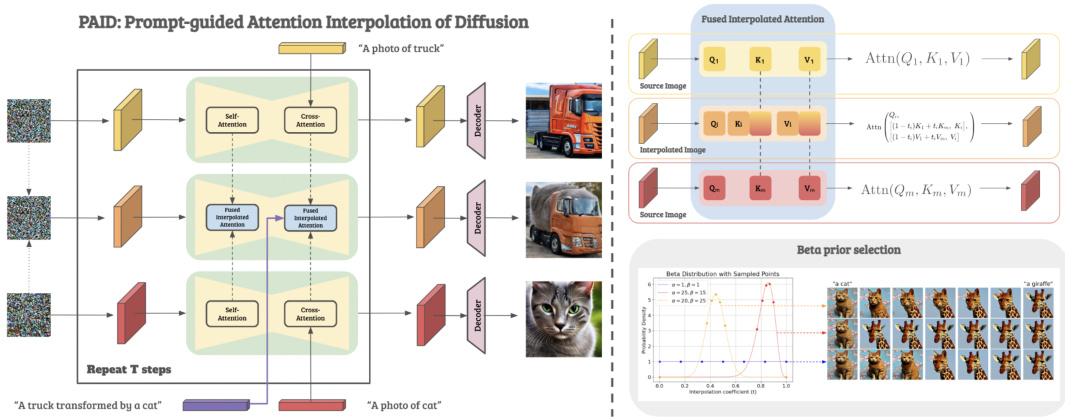
🔼 This figure illustrates the PAID (Prompt-guided Attention Interpolation of Diffusion) framework. It shows how the model uses fused interpolated attention (combining cross and self-attention) to generate interpolated images. The interpolation coefficients are selected using a Beta distribution for smoothness. Finally, prompt guidance is integrated into the cross-attention to further direct the interpolation process.
read the caption
Figure 3: An overview of PAID: Prompt-guided Attention Interpolation of Diffusion. The main components include: (1) Replacing both cross-attention and self-attention when generating interpolated image by fused interpolated attention; (2) Selecting interpolation coefficients with Beta prior; (3) Inject prompt guidance in the fused interpolated cross-attention.

🔼 This figure shows the ablation study results of the proposed AID method for conditional interpolation. Subfigure (a) presents a qualitative comparison of three variations of AID: one without self-attention fusion, one with self-attention fusion, and one with both self-attention fusion and Beta prior for interpolation coefficient selection. The results demonstrate improved image quality and smoothness with the addition of these components. Subfigure (b) provides a quantitative comparison of CLIP scores for different methods (Stable Diffusion, CEBM, CEBM-MCMC, and PAID) on a compositional generation task. The results indicate that PAID outperforms other methods, suggesting its effectiveness in generating high-quality images.
read the caption
Figure 4: Qualitative comparison of different ablation setting of AID. (a) Qualitative comparison between AID without fusion (1st row), AID with fusion (2nd row), and AID with fusion and beta prior (3rd row). Fusing interpolation with self-attention alleviates the artifacts of the interpolated image significantly, while beta prior increases smoothness based on AID with fusion. (b) CLIP score of different methods on composition generation.

🔼 This figure shows the results of image editing control experiments comparing the proposed method (P2P + AID) with a baseline method (P2P + TEI). The top row displays images generated using P2P + AID, demonstrating improved control over the editing process compared to the bottom row which shows images generated with P2P + TEI. The results suggest that the proposed AID method enhances the ability to precisely control the editing level in image editing tasks.
read the caption
Figure 5: Results of image editing control. Our method boosts the controlling ability over editing. The first row of (a) and (b) is generated by P2P + AID while the second row is P2P + TEI.

🔼 This figure compares the results of compositional generation using different methods: Vanilla Stable Diffusion, CEBM, RRR, and PAID. The results show that PAID is superior in generating images that accurately reflect both input conditions (‘a deer’ and ‘a plane’, ‘a robot’ and ‘a sea of flowers’) with significantly higher fidelity than other methods.
read the caption
Figure 6: Results of compositional generation. Images on the left are generated with 'a deer' and 'a plane' based on SD 1.4 [35] and images on the right are generated with 'a robot' and 'a sea of flowers' based on SDXL [30]. Compared to other methods, PAID-O properly captures both conditions with higher fidelity.

🔼 This figure shows the results of applying the AID method to image-conditioned generation using IP-Adapter. The first row in each part (a, b, and c) shows results using AID, while the second row displays results when using IP-Adapter’s scaling setting. Part (a) demonstrates image morphing between real images. Part (b) displays results for a global image prompt (‘A statue is running’). Part (c) shows results using a composition image prompt (‘A boy is smiling’). In all cases, the gradual increase in the additional image prompt’s scale is visible from left to right.
read the caption
Figure 7: Results of AID with image conditions. Our method is compatible with IP-Adapter for image-conditioned generation (a). In both global image prompt (b) and composition image prompt (c), from left to right the scale of additional image prompt slowly increases. The first row illustrates results controlled by AID, while the second row shows results achieved using the scale setting provided by IP-Adapter.
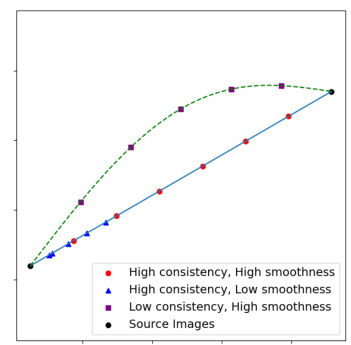
🔼 This figure illustrates the difference between smoothness and consistency when evaluating discrete sequences versus continuous paths in image interpolation. It highlights that a perceptually smooth continuous path may not always translate to a smooth sequence of discrete samples, and that consistency in image progression is a separate factor.
read the caption
Figure 8: Difference between smoothness and consistency in measurement of discrete sequence.

🔼 This figure presents an experimental analysis of text embedding interpolation. It compares the impact of replacing either cross-attention or self-attention mechanisms with those from a different image. The results show self-attention has a stronger influence on the spatial layout of the generated image than cross-attention. Additionally, it demonstrates the non-uniformity of visual transitions in text embedding interpolation, highlighting the need for a more sophisticated interpolation approach.
read the caption
Figure 9: Diagnosis of text embedding interpolation on spatial layout (a - e) and adjacent distance (f). (a) Image generated by “a cat wearing sunglasses”; (b) Image generated by “a dog wearing sunglasses”; (c) Replacing the cross-attention during generation of (b) by (a); (d) Replacing the self-attention during generation of (b) by (a); (e) Box plot of Dst(I, I'cross) and Dst(I, I'self). When fixing a query, the key and value in self-attention mostly determine the output of pixel space compared to cross-attention. (f) The maximum adjacent distance and the average of other adjacent pairs.

🔼 This figure shows examples of attention interpolation applied to different tasks. The top row demonstrates interpolation between two text prompts, resulting in a smooth transition between the concepts. The second row shows image-to-image interpolation, smoothly changing one image into another. The third and fourth rows show additional text-to-text interpolations. The bottom row shows how user-specified prompts can guide the interpolation process, creating even more nuanced transitions.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure demonstrates the AID (Attention Interpolation via Diffusion) method’s ability to generate smooth and coherent image interpolations between different conditions. Subfigure (a) shows text-to-text interpolation, (b) image-to-image, (c-e) other text-to-text examples, and (f) text-guided interpolation. The results highlight improved spatial and conceptual consistency compared to baseline methods.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure shows examples of attention interpolation applied to text-to-image diffusion models. It showcases the ability to generate smooth transitions between various conditions, including interpolations between different text prompts (a, c-e), images (b), and even with user-specified prompts guiding the interpolation path (f). The figure highlights the model’s capacity for nuanced spatial and conceptual blending during the interpolation process.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure demonstrates the capability of the proposed Attention Interpolation via Diffusion (AID) method in generating smooth and coherent image interpolations across various conditions, including both text and image prompts. Subfigures (a, c-e) showcase text-to-text interpolations, while (b) shows image-to-image interpolation. Subfigure (f) highlights the use of prompt guidance to further control the interpolation pathway.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure shows six examples of attention interpolation. The first five examples show different types of interpolation between different text prompts and one image-to-image interpolation. The last example demonstrates the use of prompt guidance for more fine-grained control over the interpolation path.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure showcases the capability of the proposed Attention Interpolation via Diffusion (AID) method in generating smooth and meaningful interpolations between different image conditions. It presents examples of text-to-text, image-to-image, and text-guided interpolations, demonstrating the ability to create nuanced transitions in both visual style and semantic content. The seamless transitions highlight the method’s effectiveness in generating high-quality interpolated images.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure demonstrates the results of attention interpolation on various image generation tasks. It shows examples of interpolating between different text prompts (a, c-e), image prompts (b), and guided interpolation paths using additional text prompts (f). The results showcase the method’s ability to generate smooth transitions, maintain conceptual coherence, and allow for precise control over the interpolation process.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure demonstrates the results of image editing control using two different methods: P2P+AID and P2P+TEI. The top row shows the results obtained with the P2P+AID method, while the bottom row displays the results from the P2P+TEI method. The results illustrate how AID improves the ability to control the level of editing applied to an image.
read the caption
Figure 5: Results of image editing control. Our method boosts the controlling ability over editing. The first row of (a) and (b) is generated by P2P + AID while the second row is P2P + TEI.

🔼 This figure shows the qualitative results of using Prompt-guided Attention Interpolation via Diffusion (PAID) to interpolate between different animal concepts. The interpolation smoothly transitions between the source images, demonstrating the method’s ability to create high-quality, detailed images that combine features from both input concepts.
read the caption
Figure 17: Qualitative results of interpolation between animal concepts. For an animal, we use 'A photo of {animal_name}, high quality, extremely detailed' to generate the corresponding source images. The guidance prompt is formulated as “A photo of an animal called {animal_name_A}-{animal_name_B}, high quality, extremely detailed”. PAID enables a strong ability to create compositional objects.

🔼 This figure shows examples of attention interpolation of diffusion model applied to different conditions. (a) shows text-to-text interpolation, (b) image-to-image interpolation, (c-e) text-to-text interpolation with different concepts, and (f) text-to-text interpolation with prompt guidance. The results demonstrate the model’s ability to generate smooth and consistent transitions between different conditions, even with complex and abstract concepts. This showcases the improvement in quality compared to other methods.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure showcases the capabilities of the proposed Attention Interpolation via Diffusion (AID) method for generating smooth transitions between different image conditions. It demonstrates successful interpolation between various text prompts (e.g., ‘a lady in the sea of flowers’ to ‘Mobile Suit Gundam’), image-to-image morphing (Mona Lisa to Taylor Swift), and text prompts guided with additional prompts (‘photo of a dog’ to ‘photo of a car’ with intermediate guidance prompts). The figure highlights the method’s ability to maintain consistency and smoothness in image transitions, as well as its potential for advanced image editing and controlled generation.
read the caption
Figure 1: Our approach enables text-to-image diffusion models to generate nuanced spatial and conceptual interpolations between different conditions including text (a, c-e) and image (b), with seamless transitions in layout, conceptual blending, and user-specified prompts to guide the interpolation paths (f).

🔼 This figure displays multiple image interpolation sequences generated using two different models: Animagine 3.0 and Stable Diffusion XL (SDXL). Each sequence shows a smooth transition between two different images, demonstrating the models’ ability to generate realistic and visually appealing interpolations. The variety of subject matter, artistic styles, and image qualities showcases the models’ versatility and effectiveness.
read the caption
Figure 20: More qualitative results generated by Animagine 3.0 [23] (the 1st row) and SDXL (from 2nd to 9th rows).
Full paper#



















