↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current methods for training decision-making AI agents struggle with efficiently learning optimal strategies in complex, interactive environments. Existing fine-tuning approaches often rely on pre-collected datasets, which may not capture the full range of decision-making scenarios. This limits the ability of AI agents to adapt and learn effectively in real-world situations.
This paper introduces a novel algorithm that addresses these challenges by fine-tuning vision-language models (VLMs) using reinforcement learning (RL). The key innovation is the integration of chain-of-thought (CoT) reasoning, which allows the VLM to generate intermediate reasoning steps leading to more efficient exploration. The generated text actions are then parsed into executable actions, and RL is used to fine-tune the entire VLM based on the obtained rewards. Experiments demonstrate that this approach significantly improves VLM decision-making abilities, outperforming existing commercial models in several challenging tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on decision-making AI agents, especially those using large vision-language models (VLMs). It introduces a novel framework that enhances the capabilities of VLMs in complex, interactive scenarios by leveraging reinforcement learning (RL) and chain-of-thought (CoT) reasoning. This work paves the way for more robust and effective VLM agents, opening up possibilities for various applications from robotic control to virtual assistants.
Visual Insights#
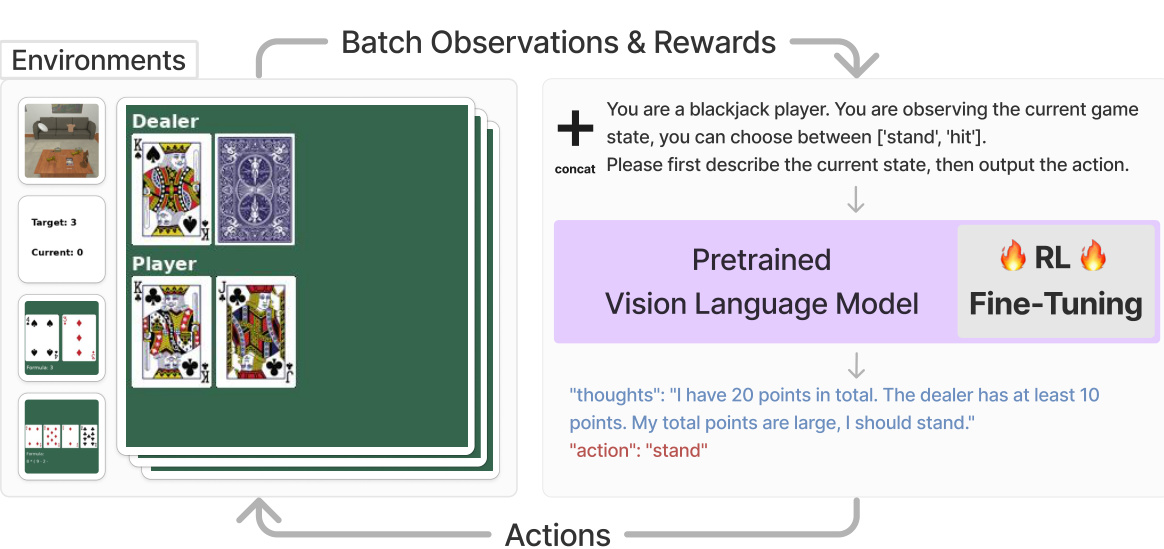
This figure illustrates the proposed framework for fine-tuning large Vision-Language Models (VLMs) using reinforcement learning (RL). The process starts with an environment providing a batch of observations and rewards. These are combined with a predesigned prompt and fed into a pretrained VLM. The VLM generates an utterance incorporating chain-of-thought reasoning and a textual action. This action is then parsed and sent to the environment, producing a reward that is used to fine-tune the entire VLM via RL.
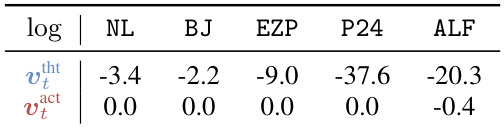
This table shows the absolute values of the sum of log probabilities for the chain-of-thought (CoT) tokens and action tokens in the VLM outputs for different tasks. It highlights that the magnitude of log probabilities for CoT tokens is significantly larger than that for action tokens, a point that motivates the use of a scaling factor in the action probability estimation to balance the influence of CoT reasoning.
In-depth insights#
VLM-RL Framework#
A VLM-RL framework integrates large vision-language models (VLMs) with reinforcement learning (RL) to create autonomous decision-making agents. The core idea is to leverage the VLM’s ability to process both visual and textual information, generating a chain of thought reasoning which guides it to perform actions within an environment. RL provides the mechanism for learning optimal policies, allowing the agent to improve its decision-making capabilities through interaction and reward feedback. A key advantage is the ability to handle multi-step tasks and complex scenarios where purely supervised methods might fall short. The framework’s success relies on effective prompt engineering to elicit reasoned actions from the VLM and a robust method for translating the VLM’s open-ended text output into executable actions. Challenges include managing the complexity of the VLM’s output, designing appropriate reward functions and ensuring the RL training process is efficient. Overall, this approach is a significant step towards building more robust and versatile AI agents capable of operating effectively in real-world environments.
CoT Reasoning#
The concept of Chain-of-Thought (CoT) reasoning is central to this research, enhancing the decision-making capabilities of large vision-language models (VLMs). CoT prompting acts as a crucial intermediary step, guiding the VLM through a process of intermediate reasoning before arriving at a final action. This structured approach, unlike traditional fine-tuning methods, enables more efficient exploration of complex problem spaces. The study empirically demonstrates that removing CoT reasoning significantly reduces the overall performance, underscoring its critical role in effective decision-making. The integration of CoT within the reinforcement learning (RL) framework is a key innovation, bridging the gap between open-ended language generation and the need for precise, executable actions in interactive environments. Careful consideration is given to the weighting of CoT reasoning versus the final action prediction, demonstrating the impact of the choice of the hyperparameter λ on overall effectiveness.
RLHF Contrast#
RLHF (Reinforcement Learning from Human Feedback) contrast in research papers typically involves comparing and contrasting the performance, efficiency, and ethical considerations of RLHF-trained models against models trained using other methods. A key area of contrast often revolves around the data requirements; RLHF demands significant human annotation, making it resource-intensive and potentially less scalable compared to methods relying on pre-existing datasets. Another point of comparison focuses on the alignment of models with human values. While RLHF aims for better alignment by directly incorporating human feedback, there are challenges related to bias in human preferences and the difficulty of specifying desired behavior comprehensively. Finally, a notable contrast emerges regarding model interpretability. RLHF’s iterative feedback loops can complicate understanding the model’s internal reasoning process, thus presenting a trade-off between performance and interpretability. Researchers frequently explore these contrasts to determine the optimal training approach for specific tasks, considering factors such as available resources, desired alignment level, and the need for interpretable results.
Empirical Gains#
An ‘Empirical Gains’ section in a research paper would detail the quantitative improvements achieved by the proposed method. It would likely present key performance metrics, comparing the new approach against existing state-of-the-art techniques. Crucially, the results should be statistically significant and robust across various datasets or experimental conditions to demonstrate genuine advancement. The analysis should include error bars or confidence intervals to convey the reliability of the findings, and a discussion of potential limitations impacting the results. A thoughtful presentation would include ablation studies, which isolate and measure the impact of individual components of the new method, helping to explain the source of the improvements. Finally, it’s essential to discuss the generalizability of the gains. Do the results hold across diverse datasets and scenarios, hinting at broad applicability or are they specific to the tested conditions?
Future Works#
Future research could explore several promising directions. Extending the proposed RL framework to other visual decision-making tasks beyond those presented would be valuable, demonstrating its generality and robustness. Investigating alternative RL algorithms and reward shaping techniques could further improve the efficiency and performance of VLM fine-tuning. A crucial area is understanding the impact of different prompting strategies on the effectiveness of both CoT reasoning and RL training, which could lead to significant enhancements. Exploring larger scale VLMs and investigating model architectures better suited for RL integration may unlock even greater performance gains. Finally, thorough analysis of the interaction between CoT reasoning and visual perception within VLMs is needed to optimize the decision-making process. This multifaceted approach would establish a comprehensive understanding of the VLM-RL paradigm.
More visual insights#
More on figures
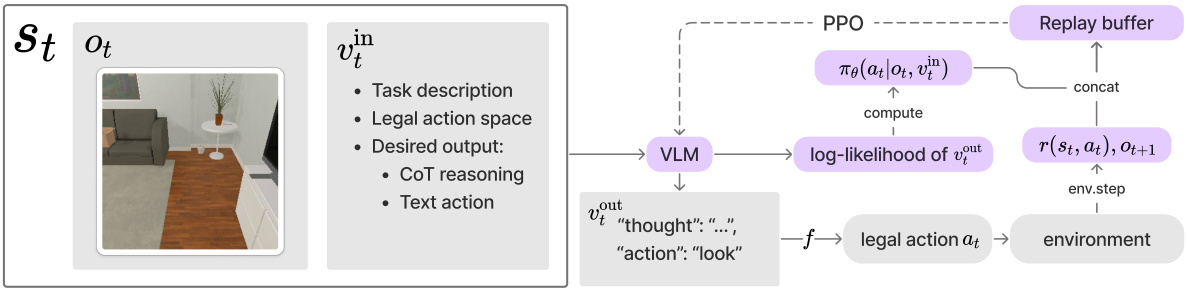
This figure illustrates the Reinforcement Learning (RL) fine-tuning framework for Vision-Language Models (VLMs). At each time step, the VLM receives visual observation (ot) and a task-specific prompt (vin) as input. The VLM generates open-ended text (vout) which includes chain-of-thought reasoning and a text-based action. A post-processing function (f) converts this text action into an executable action (at) to interact with the environment. The environment then provides a reward (r(st, at)) and the next observation (Ot+1), which are used to fine-tune the VLM via Proximal Policy Optimization (PPO). The log-likelihood of the VLM’s output is also computed and used in the training process.

This figure illustrates the overall framework of the proposed method. It starts with an environment providing a batch of observations and rewards. A pretrained vision-language model takes these observations along with a prompt, generates a chain of thought reasoning and outputs a text-based action. This action is then parsed and fed back to the environment. The generated reward is used for reinforcement learning (RL) to fine-tune the entire vision-language model.
This figure illustrates the overall framework of the proposed method. It shows how a pretrained vision-language model is fine-tuned using reinforcement learning to become a decision-making agent. The model receives an observation from the environment and a prompt. It then generates a chain of thought (CoT) reasoning and a text-based action. The action is executed in the environment, yielding a reward, which is then used to fine-tune the model via RL.

This figure shows the training curves of different methods (Ours, CNN+RL, GPT4-V, Gemini, LLaVA-sft) on four tasks (NumberLine, EZPoints, Blackjack from gym_cards and alfworld). The x-axis represents the number of environment steps, and the y-axis represents the episode success rate (%). The plot visualizes the learning progress of each method, showing how their performance improves over time. The Points24 task is excluded due to poor performance by all methods. The plot provides a direct comparison of the proposed method’s performance against existing baselines and commercial models.

This figure shows the training curves of different methods on four tasks: NumberLine, EZPoints, Blackjack from the gym_cards environment and alfworld. The x-axis represents the number of environment steps, and the y-axis represents the episode success rate (%). The figure compares the performance of the proposed method (Ours) against other methods like GPT4-V, Gemini, a supervised fine-tuned version of LLaVa (LLaVa-sft), and a CNN-based RL approach (CNN+RL). It demonstrates that the proposed method generally achieves higher success rates across all tasks compared to the baselines. The Points24 task is excluded because none of the tested methods performed well on this task.
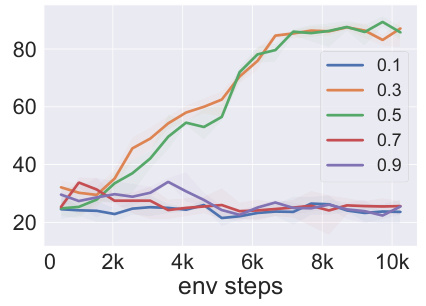
This figure displays the training curves for four different tasks (NumberLine, EZPoints, Blackjack, and alfworld) comparing several different methods: Our method, CNN+RL, GPT4-V, Gemini, and LLaVA-sft. The x-axis represents the number of environment steps, and the y-axis represents the episode success rate (%). The curves show how each method’s performance improves over time during training. Notably, the Points24 task is excluded because none of the tested methods achieved a reasonable success rate. This figure visually demonstrates the effectiveness of the proposed method in enhancing the decision-making capabilities of VLMs across various tasks.

This figure illustrates the proposed framework for fine-tuning large Vision-Language Models (VLMs) using reinforcement learning (RL). The process begins with the VLM receiving both a visual observation (from an environment like Blackjack) and a pre-designed prompt. The VLM then generates an utterance containing reasoning steps (Chain-of-Thought) and a text-based action. This text action is interpreted by a parser, fed back into the environment to produce a reward, and finally, the entire VLM is fine-tuned using the generated reward via RL.

This figure illustrates the proposed framework for fine-tuning large vision-language models (VLMs) using reinforcement learning (RL). It shows how the VLM processes visual and textual information, generates a chain of thought reasoning leading to a text-based action, and then receives a reward from interacting with the environment. This reward is then used to fine-tune the entire VLM, making it a better decision-making agent.

This figure illustrates the proposed framework for training large vision-language models (VLMs) using reinforcement learning (RL). The process begins with the VLM receiving an observation and a prompt. The VLM then generates an utterance containing chain-of-thought reasoning and a text-based action. This action is parsed and sent to the environment, generating rewards that are then used to fine-tune the entire VLM via RL. The figure highlights the key components, including the environment, observations and rewards, the pretrained VLM, the RL fine-tuning process, and the actions generated by the VLM.

This figure illustrates the proposed framework for training large Vision-Language Models (VLMs) using reinforcement learning (RL). The process starts with the VLM receiving both the current observation from the environment and a pre-designed prompt. The VLM then generates an utterance containing chain-of-thought reasoning and a text-based action. This action is parsed and sent to the environment, which returns task rewards. Finally, RL utilizes the task rewards to fine-tune the whole VLM.

This figure illustrates the overall framework of the proposed method. It shows how a pretrained vision-language model is fine-tuned using reinforcement learning for decision-making. The model receives an image (observation) and a pre-defined prompt. It then generates a chain of thought, culminating in a text-based action. This action is passed to the environment, which returns a reward. The reward is then used to fine-tune the entire vision-language model via reinforcement learning.

This figure illustrates the proposed framework for fine-tuning large Vision-Language Models (VLMs) using reinforcement learning (RL). The VLM receives an observation (e.g., image from a game) and a prompt. It then generates a chain of thought (CoT) reasoning and outputs a text-based action. This action is parsed and sent to the environment, which provides a reward. This reward is used in the RL process to fine-tune the entire VLM, improving its decision-making abilities in the specific task.

This figure illustrates the proposed framework for training large Vision-Language Models (VLMs) using reinforcement learning (RL). The VLM receives visual input (e.g., a blackjack game state) and a prompt. It then generates an utterance with chain-of-thought reasoning and a text-based action. This action is interpreted by the environment, yielding rewards. Finally, RL uses these rewards to fine-tune the entire VLM.

This figure provides a high-level overview of the proposed reinforcement learning framework for fine-tuning large vision-language models. It shows how the VLM processes visual and textual information at each step, generates chain-of-thought reasoning and a textual action, and uses the environment’s feedback to adjust its decision-making process through RL fine-tuning. The process is shown as a flow diagram encompassing the environment, the VLM, and the RL process.

This figure illustrates the proposed framework for training large Vision-Language Models (VLMs) using reinforcement learning (RL). The process begins with the VLM receiving an observation and a pre-designed prompt. The VLM then generates an utterance that includes chain-of-thought reasoning and a text-based action. This action is fed to the environment, resulting in a reward. This reward is used to fine-tune the entire VLM via RL.

This figure illustrates the proposed framework for training large Vision-Language Models (VLMs) using reinforcement learning. The VLM receives an observation and a prompt, generates a chain of thought reasoning and a text-based action, which is then parsed and sent to the environment. The environment provides a reward, and this reward is used to fine-tune the entire VLM via reinforcement learning.
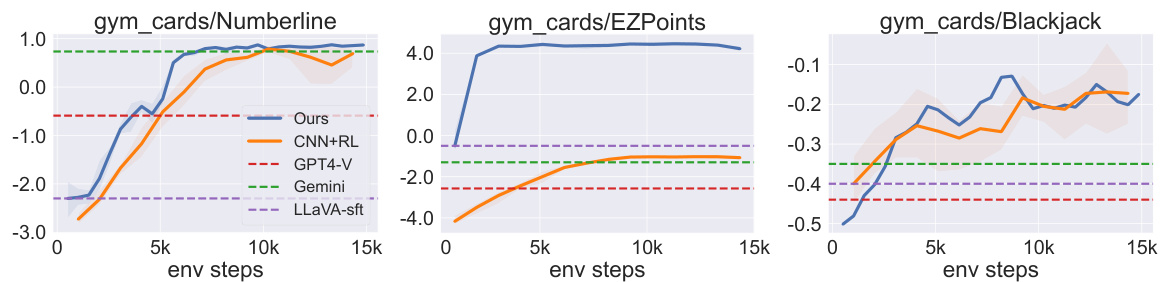
This figure shows the training curves of episode success rates for different methods across four tasks in two domains. The x-axis represents the number of environment steps. The y-axis represents the episode success rate. The four tasks are NumberLine, EZPoints, Blackjack from the gym_cards domain and all tasks from the alfworld domain. The methods compared are Ours, CNN+RL, GPT4-V, Gemini, and LLaVA-sft. The Points24 task is excluded because no methods achieved reasonable performance.
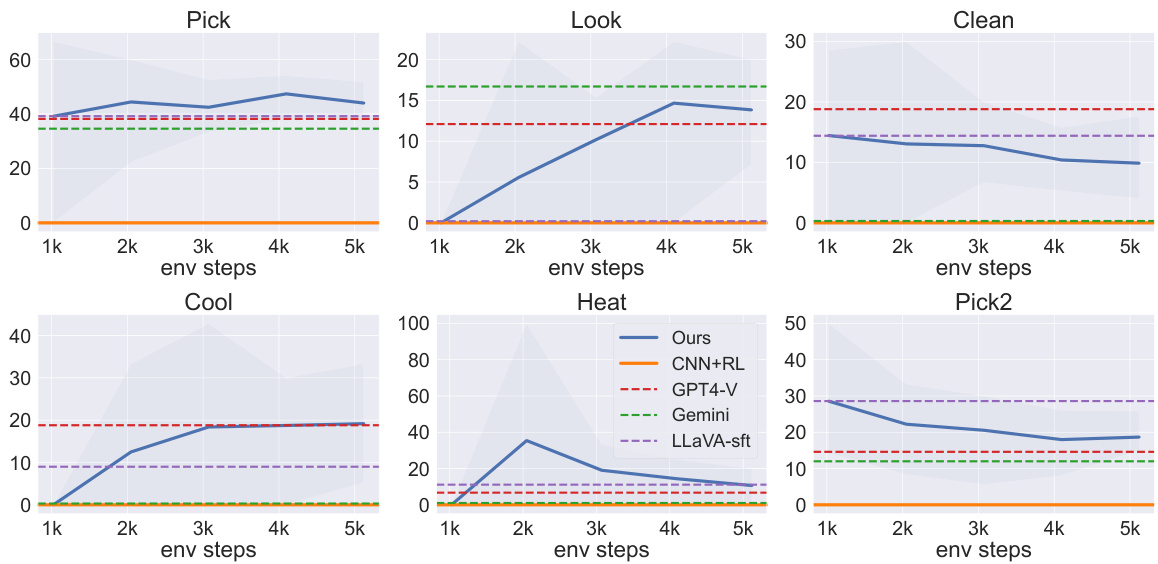
This figure presents the training curves of several methods, including the proposed method, on four different tasks across two domains: gym_cards and alfworld. The gym_cards tasks (NumberLine, EZPoints, Blackjack) assess arithmetic reasoning and visual recognition, while the alfworld task tests visual semantic understanding in an embodied AI setting. The plots show the episode success rate over the number of environment steps during training. The Points24 task’s results were omitted due to poor performance from all evaluated methods.

This figure illustrates the proposed framework for training large Vision-Language Models (VLMs) using reinforcement learning (RL). The process begins with the VLM receiving both the current observation from the environment and a predefined prompt. The VLM then generates an utterance including a chain-of-thought reasoning process and a text-based action. This action is interpreted by the environment, which provides a reward to the VLM. The reward is used to fine-tune the entire VLM via RL, improving its decision-making ability.

This figure provides a high-level overview of the proposed reinforcement learning framework for training large vision-language models (VLMs) as decision-making agents. It illustrates the process: The VLM receives an observation from the environment and a pre-defined prompt. It then uses chain-of-thought reasoning to generate a text-based action. This action is parsed and sent to the environment to obtain a reward. Finally, this reward signal is used to fine-tune the VLM using reinforcement learning.

This figure illustrates the overall framework of the proposed method. It shows how a pretrained vision-language model is fine-tuned using reinforcement learning. The process involves taking an observation from the environment, incorporating a pre-designed prompt, generating a chain of thought (CoT) reasoning and a text-based action from the VLM, parsing the action into the environment, receiving task rewards, and finally using these rewards to fine-tune the entire VLM.

This figure illustrates the overall framework of the proposed method. A pretrained vision-language model receives an observation and a prompt. It then generates a chain of thought, reasoning, and a text-based action. This action is sent to an environment and feedback (rewards) are used to fine-tune the vision-language model through reinforcement learning.

This figure illustrates the proposed framework for training large vision-language models (VLMs) using reinforcement learning (RL). The VLM receives an observation and a prompt, generates a chain of thought reasoning and a text-based action, which is then executed in an environment to obtain a reward. This reward is used to fine-tune the VLM via RL. The diagram shows the interaction between the VLM, the environment, and the RL algorithm.

This figure illustrates the proposed framework for fine-tuning large vision-language models (VLMs) using reinforcement learning. The VLM receives visual input (e.g., a game state) and a prompt. It then generates a chain of thought (CoT) to reason through the problem and outputs a text-based action. This action is parsed, fed to an environment, which returns a reward signal. The reward is then used to fine-tune the VLM via reinforcement learning, improving its decision-making abilities in interactive environments. The Blackjack game example shows the input (game state), the CoT reasoning, the action (‘stand’), and the overall process.

This figure illustrates the overall framework of the proposed method. It shows how a pretrained vision-language model is fine-tuned using reinforcement learning. The model receives visual input (e.g., a game board), along with a prompt describing the task. The model then generates a chain of thought, explaining its reasoning process, before outputting a text-based action. This action is interpreted and executed within the environment, yielding a reward. This reward is then used to further fine-tune the vision-language model, improving its decision-making capabilities.

This figure provides a high-level overview of the proposed reinforcement learning framework for fine-tuning large vision-language models (VLMs) as decision-making agents. The process begins with the VLM receiving both visual input (from the environment) and a predefined prompt. The VLM then generates an utterance, incorporating chain-of-thought reasoning and a text-based action. This action is interpreted and sent to the environment, resulting in a reward. This reward signal is then used to fine-tune the entire VLM via reinforcement learning, improving its decision-making abilities over time.

This figure illustrates the proposed framework for training large Vision-Language Models (VLMs) using reinforcement learning (RL). The VLM receives an observation (e.g., a game state image) and a prompt, then generates an utterance consisting of reasoning steps (chain of thought) and a final action. This action is given to the environment, which generates rewards based on the action’s effect on the game. Finally, the rewards are used to fine-tune the VLM via RL. This method allows VLMs to become effective decision-making agents in multi-step tasks.

This figure illustrates the method overview of training large vision-language models (VLMs) using reinforcement learning (RL). The process starts with an environment providing batch observations and rewards. A pretrained VLM receives these observations along with a designed prompt. Then, the VLM generates an utterance including chain-of-thought reasoning and a text-based action. This action is then parsed and fed into the environment to get rewards. Finally, RL uses these rewards to fine-tune the whole VLM.

This figure illustrates the proposed framework for fine-tuning large Vision-Language Models (VLMs) using Reinforcement Learning (RL). The VLM receives an observation and a prompt, generates a chain of thought reasoning and a text-based action, which is then executed in the environment to obtain rewards. The rewards are used to fine-tune the entire VLM via RL.

This figure provides a high-level overview of the proposed method. It shows how a pretrained vision-language model is fine-tuned using reinforcement learning to act as a decision-making agent in various environments. The model receives observations from the environment and a prompt, generating a chain of thought and a text-based action. This action is then executed in the environment, yielding rewards that are used to further train the model via reinforcement learning.
More on tables
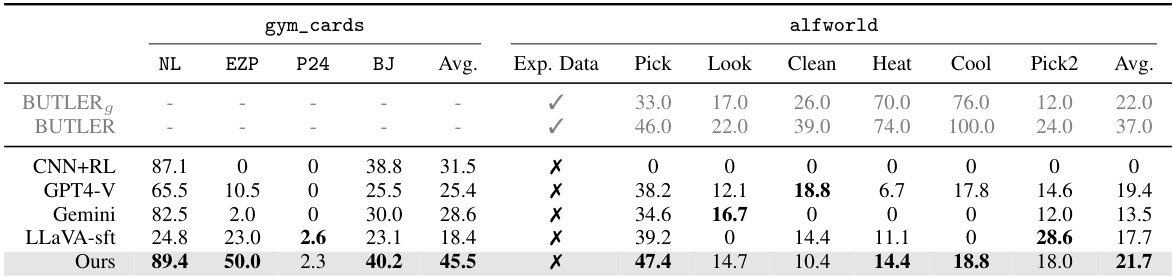
This table compares the performance of different methods (including the proposed method) on two sets of tasks: gym_cards (arithmetic reasoning with visual inputs) and alfworld (visual semantic reasoning in an embodied AI environment). The table shows the average success rate across all tasks in each domain for each method. Note that the results for RL-based methods represent peak performance within a limited number of training steps, and that alfworld’s average is weighted due to the uneven probability distribution of subtasks. Comparison is also made to methods that require expert data, highlighting the advantage of the proposed approach.

This table compares the average episode success rates of different methods on two datasets: gym_cards and alfworld. It shows the peak performance (within a certain number of environment steps) of each method. The gym_cards results are averaged across four tasks, while the alfworld results are weighted averages across multiple subtasks. The table highlights that the proposed method generally outperforms other methods across various tasks and datasets.
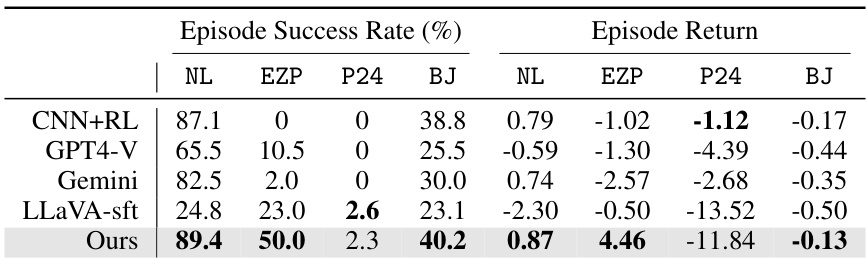
This table compares the average episode success rates and returns of different methods on two sets of tasks: gym_cards and alfworld. Gym_cards contains four tasks of increasing difficulty, including a stochastic task (Blackjack). ALFWorld is an embodied AI environment with six distinct goal-conditioned tasks requiring visual semantic understanding. The table highlights the performance of our proposed method against other methods, including commercial models (GPT4-V, Gemini), a supervised fine-tuned version of the base model (LLaVA-sft), and a vanilla RL method with a CNN-based policy network (CNN+RL). The results show our method’s consistent improvement across various tasks and its superior performance compared to the other methods.
Full paper#



















