↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D object detection models struggle with domain gaps between indoor and outdoor datasets, limiting their applicability. Existing models either specialize in a single domain or struggle to generalize across multiple domains due to interferences from data variations and different label spaces. This results in a need for multiple models for different scenarios which is not efficient.
OneDet3D tackles these challenges using a novel multi-domain joint training approach. It employs 3D sparse convolutions for efficient feature extraction and an anchor-free head to accommodate point cloud variations, along with a domain-aware partitioning mechanism and language-guided classification to reduce interferences. Evaluations across various datasets demonstrate OneDet3D’s ability to generalize to unseen domains and categories, surpassing existing single-domain models, paving the way towards universal 3D object detection.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the significant challenge of domain gap in 3D object detection, a problem hindering the development of universal models. By introducing a novel multi-domain joint training approach and addressing data and category-level interferences, this research paves the way for more robust and generalizable 3D object detectors, impacting various applications like autonomous driving and robotics. Its findings inspire further research into universal foundation models for 3D computer vision.
Visual Insights#
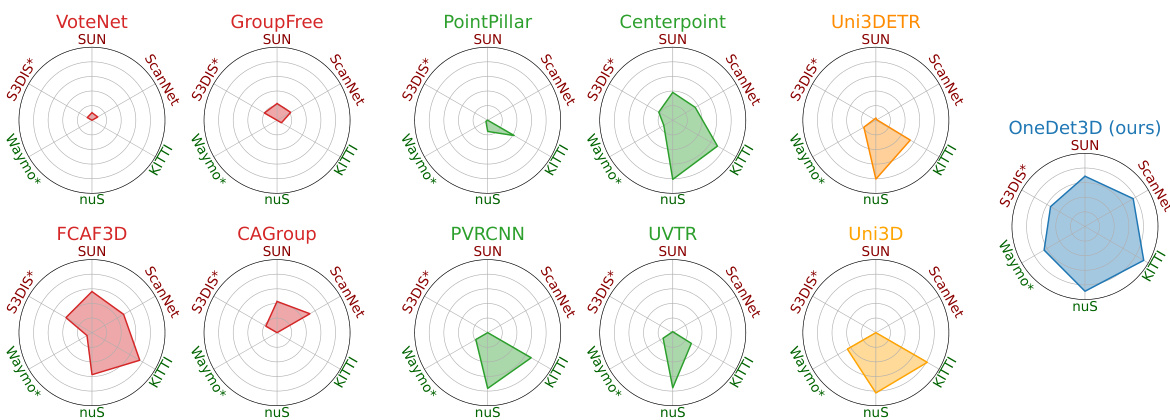
This figure compares the performance of OneDet3D against 10 other 3D object detectors across multiple datasets (SUN RGB-D, ScanNet, KITTI, nuScenes, S3DIS, and Waymo). The radar chart visualization shows the generalization ability of each model across different indoor and outdoor scenes. OneDet3D demonstrates superior performance and better generalization compared to other models.

This table provides a comparison of six different datasets used for 3D object detection, highlighting key differences in sensor type, point cloud range (length, width, and height), and scene view. The datasets include both indoor (SUN RGB-D, ScanNet, S3DIS) and outdoor (KITTI, nuScenes, Waymo) scenes, each with varying characteristics in terms of sensor technology, spatial coverage, and field of view. This information is crucial for understanding the challenges of multi-domain training and the differences in data distribution across datasets.
In-depth insights#
Multi-Domain 3D#
The concept of “Multi-Domain 3D” in research likely refers to tackling 3D computer vision tasks across diverse data sources and environments. This poses significant challenges due to domain disparities in terms of sensor types, data density, object scales, and annotation styles. A successful approach would necessitate a model robust enough to handle these variations, potentially through techniques like domain adaptation, multi-task learning, or data augmentation. The goal is to build a generalized 3D model applicable to various scenarios (indoor, outdoor, aerial, etc.), improving efficiency and applicability compared to models trained on single-domain data. Key considerations include handling data biases, ensuring fairness and generalization, and addressing the computational complexities of training such a universal model. Benchmarking across multiple datasets is crucial to validate the effectiveness of any proposed method.
OneDet3D Model#
The OneDet3D model is a novel, universal 3D object detection model designed for multi-domain joint training. Its key innovation lies in addressing the challenges of domain interference through domain-aware partitioning and language-guided classification. This enables OneDet3D to learn from diverse indoor and outdoor datasets with a single set of parameters, achieving strong generalization across various domains, categories, and diverse scenes. The fully sparse architecture and anchor-free head accommodate point clouds with significant scale disparities, further enhancing its versatility. Experimental results demonstrate OneDet3D’s superior performance compared to existing single-domain models, validating its effectiveness as a truly universal 3D object detector. The model’s ability to handle both close-vocabulary and open-vocabulary scenarios highlights its potential for broader applications and signifies a significant step toward universal 3D perception.
Domain Partitioning#
Domain partitioning, in the context of multi-domain learning for 3D object detection, is a crucial technique to address the challenge of domain discrepancy. It acknowledges that different datasets (indoor vs. outdoor, different sensor types) exhibit unique characteristics that can interfere with the learning process if treated uniformly. Therefore, instead of using a single set of parameters for all aspects of the model, domain partitioning strategically divides the model’s parameters, allocating specific parameters to handle data from particular domains, while keeping others shared across all domains. This approach allows the model to learn domain-specific features effectively while maintaining the ability to generalize across domains. Key components often partitioned include normalization layers (handling scale differences) and context modules (capturing scene-specific information). The effectiveness of domain partitioning lies in its ability to prevent interference while fostering knowledge transfer, ultimately leading to improved robustness and generalization in the resulting model for 3D object detection.
Language-Guided#
The concept of “Language-Guided” in the context of a research paper, likely focusing on a task involving multi-modal data (like images and text), suggests a method where natural language plays a crucial role in guiding or influencing the system’s operation. This could manifest in several ways: language could provide high-level instructions or constraints, shaping the model’s behavior; it could offer a means of aligning different data modalities, facilitating better cross-modal understanding; or it could serve to bridge semantic gaps between different datasets or domains, allowing for more robust generalization. A key aspect is how this linguistic guidance is integrated—is it a direct input to the model, a means of training data annotation, or used for post-processing? Furthermore, the effectiveness depends on several factors, including the quality of the language data, the sophistication of the language processing components, and the overall architecture of the model. The potential impact of this approach is significant, particularly in addressing challenges with ambiguity, generalization, and data heterogeneity.
Open-Vocabulary#
The concept of “Open-Vocabulary” in the context of 3D object detection signifies a significant advancement beyond traditional, closed-vocabulary approaches. Closed-vocabulary systems are limited to recognizing objects from a predefined set of categories, failing to generalize to novel or unseen objects. Open-vocabulary methods aim to overcome this limitation, enabling 3D detectors to identify objects even if they weren’t part of the training dataset. This enhanced generalization capability is crucial for real-world applications where encountering previously unseen objects is common. Achieving open-vocabulary performance typically involves innovative techniques such as leveraging large language models or incorporating text-based information to expand the model’s understanding of object categories. This allows the model to infer the identity of new objects based on their textual descriptions, rather than relying solely on visual features. The benefits are substantial, encompassing improved robustness and adaptability of 3D detectors, enabling wider applicability across diverse scenarios.
More visual insights#
More on figures
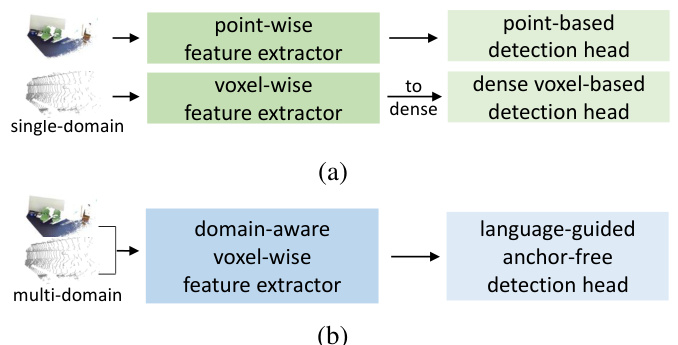
This figure illustrates the difference between existing single-domain 3D object detectors and the proposed OneDet3D multi-domain detector. (a) shows that traditional methods use either point-wise or voxel-wise feature extractors, followed by point-based or dense voxel-based detection heads respectively. These are trained and tested on a single dataset. (b) highlights OneDet3D’s approach which uses a domain-aware voxel-wise feature extractor and a language-guided anchor-free detection head, enabling joint training across multiple datasets and domains.
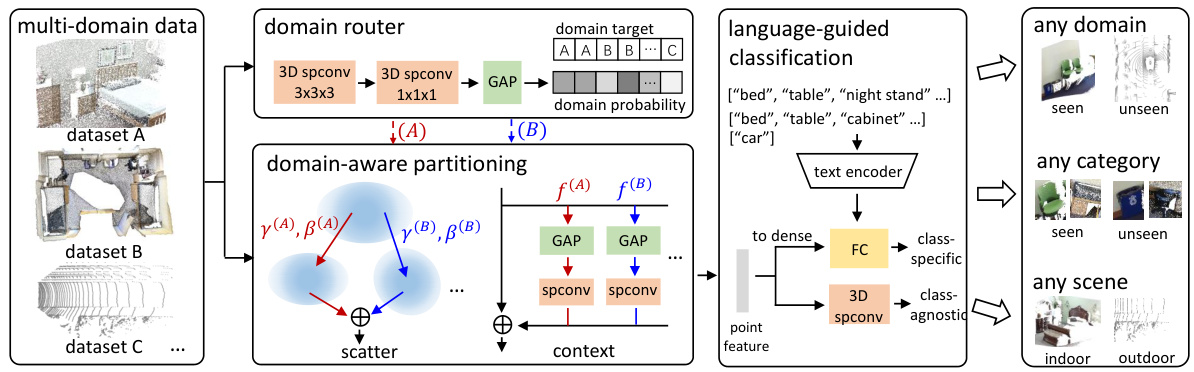
This figure shows the architecture of the OneDet3D model. The model takes multi-domain point cloud data as input. A domain router first determines the input domain and then the model applies domain-aware partitioning in scatter and context to mitigate data-level interference. Finally, language-guided classification addresses the category-level interference issue. The resulting model can generalize well to unseen domains, categories, and scenes.

This figure illustrates the architecture of OneDet3D, a multi-domain point cloud-based 3D object detection model. It shows how the model uses domain-aware partitioning (in scatter and context) and language-guided classification to address data-level and category-level interference problems respectively when training with data from diverse indoor and outdoor datasets. The final result is a model capable of generalizing to unseen domains, categories, and scenes.

This figure shows the visualization results of the OneDet3D model on four different datasets: SUN RGB-D and ScanNet (indoor datasets) and KITTI and nuScenes (outdoor datasets). The visualizations demonstrate the model’s ability to accurately detect 3D objects (represented by blue bounding boxes) in diverse indoor and outdoor scenes with varying object sizes, densities, and viewpoints. The results highlight the model’s generalization capability across different domains.

This figure shows the visualization results of the OneDet3D model on four different datasets: SUN RGB-D and ScanNet (indoor datasets) and KITTI and nuScenes (outdoor datasets). The images display point clouds with 3D bounding boxes predicted by OneDet3D, demonstrating its ability to generalize across diverse indoor and outdoor scenes.
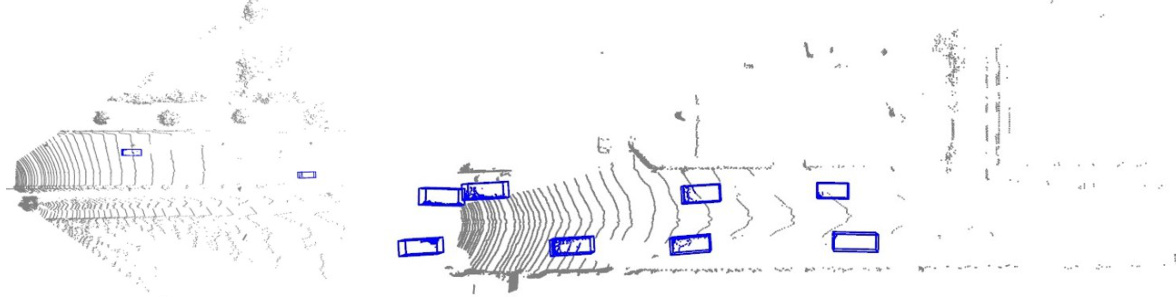
This figure shows the visualization of the OneDet3D model’s performance on four different datasets: SUN RGB-D (indoor), ScanNet (indoor), KITTI (outdoor), and nuScenes (outdoor). Each sub-figure displays a point cloud with detected 3D bounding boxes, highlighting OneDet3D’s ability to generalize across diverse indoor and outdoor scenes. The consistent performance across these disparate datasets showcases the model’s ability to handle variations in data characteristics, such as object scale, density, and scene complexity, which demonstrates the model’s effectiveness and generalization capability.

This figure shows the visualization of the OneDet3D model’s 3D object detection results on four different datasets: SUN RGB-D (indoor), ScanNet (indoor), KITTI (outdoor), and nuScenes (outdoor). The visualizations demonstrate the model’s ability to generalize across diverse indoor and outdoor scenes with varying levels of object density and scale, showcasing its one-for-all capability.
More on tables
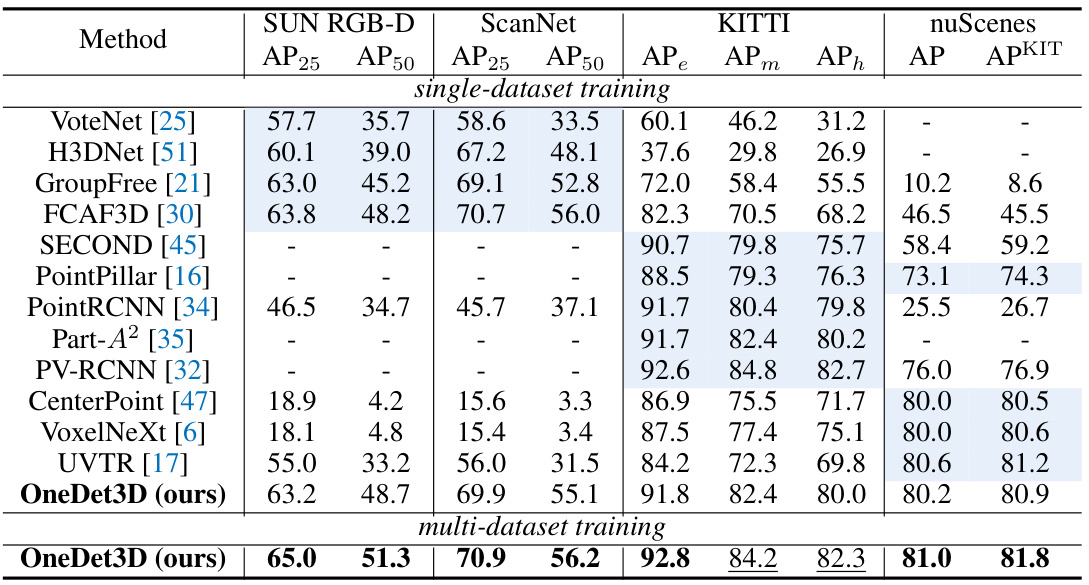
This table compares the performance of OneDet3D against other state-of-the-art 3D object detectors on four datasets (SUN RGB-D, ScanNet, KITTI, and nuScenes) in a closed-vocabulary setting. It shows the Average Precision (AP) scores for different difficulty levels (easy, moderate, hard) and a KITTI-style AP score. The table highlights OneDet3D’s ability to perform well across different datasets using a single set of parameters trained on multiple datasets. Gray cells indicate results reported by the original papers, while other results were re-implemented by the authors of this paper.
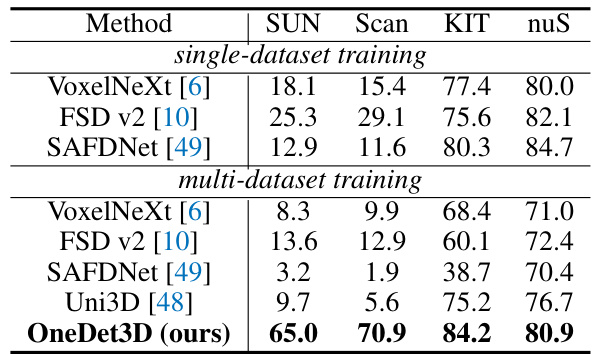
This table compares the performance of OneDet3D against other state-of-the-art 3D object detectors on four datasets (SUN RGB-D, ScanNet, KITTI, and nuScenes). The comparison considers both single-dataset and multi-dataset training scenarios. It highlights OneDet3D’s superior performance, particularly in multi-dataset settings, showcasing its ability to generalize across different domains.
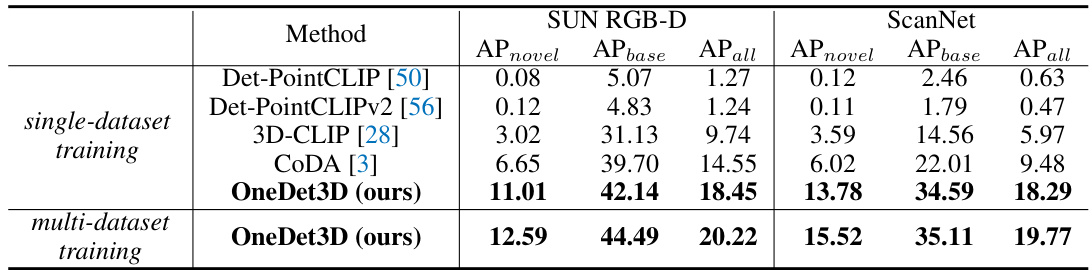
This table presents the results of open-vocabulary 3D object detection experiments using the OneDet3D model. It compares the performance of OneDet3D against other methods (Det-PointCLIP, Det-PointCLIPv2, 3D-CLIP, and CoDA) on the SUN RGB-D and ScanNet datasets. The table shows the AP (Average Precision) values broken down into APnovel (for novel categories), APbase (for base categories), and APall (for all categories). Results are shown for both single-dataset and multi-dataset training scenarios, highlighting OneDet3D’s performance improvement with multi-dataset training.
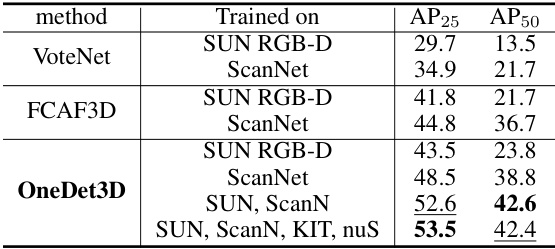
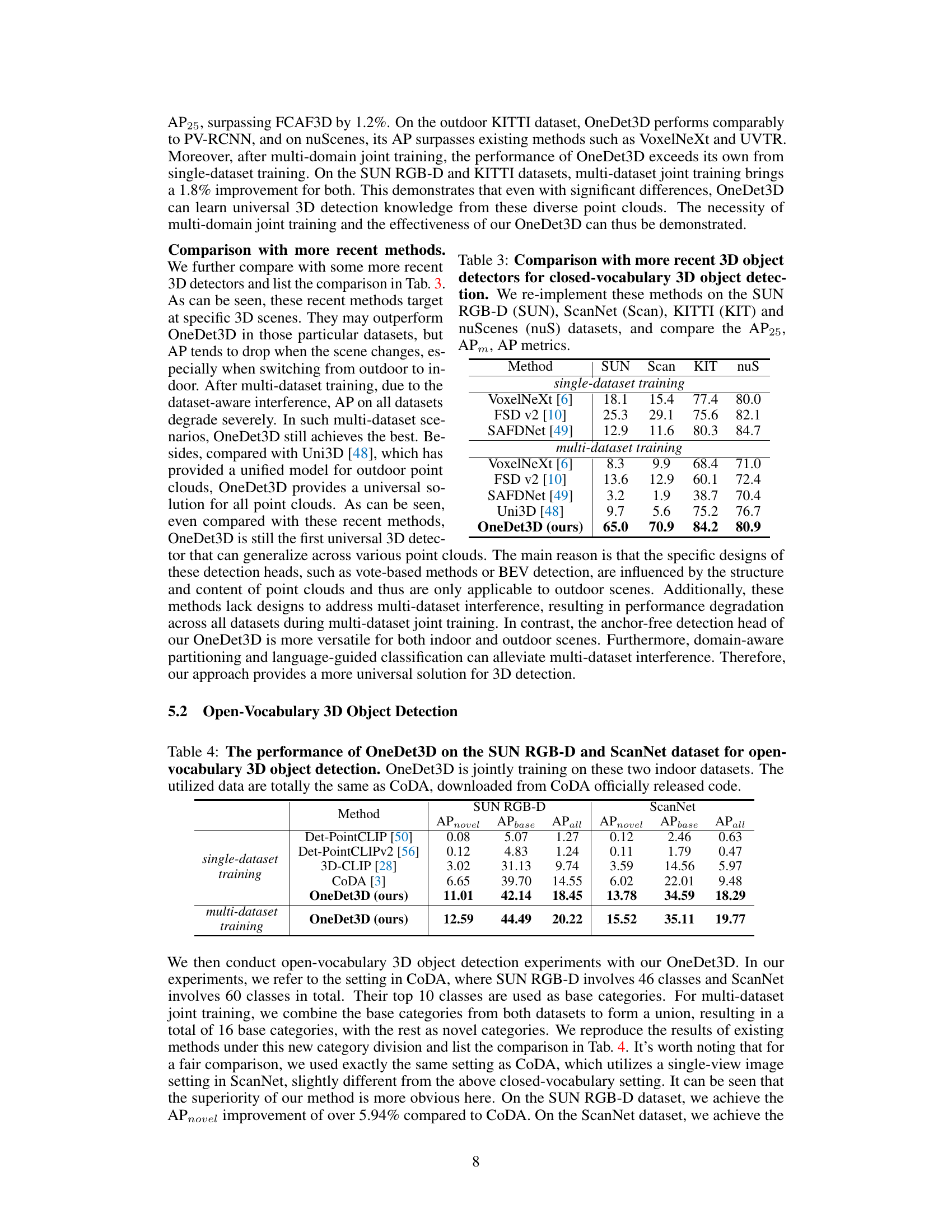
This table presents the cross-domain performance of the OneDet3D model on the S3DIS dataset. It shows the AP25 and AP50 scores for different methods trained on various datasets, highlighting OneDet3D’s ability to generalize across different domains. The results demonstrate OneDet3D’s superior performance compared to other methods, especially when trained on multiple datasets, showcasing its strong generalization capabilities.
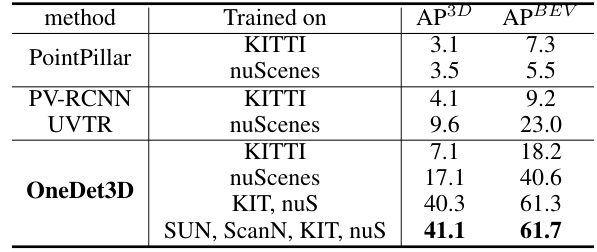
This table presents the cross-domain performance of the OneDet3D model on the Waymo dataset, an unseen dataset during training. It compares the AP3D and APBEV (Average Precision in 3D and Bird’s Eye View) metrics of OneDet3D when trained on different combinations of datasets (KITTI, nuScenes, SUN RGB-D, ScanNet). The results highlight OneDet3D’s ability to generalize to unseen datasets after multi-domain training.
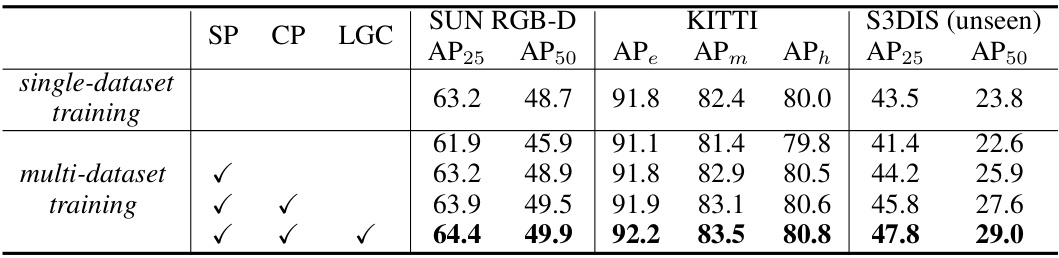
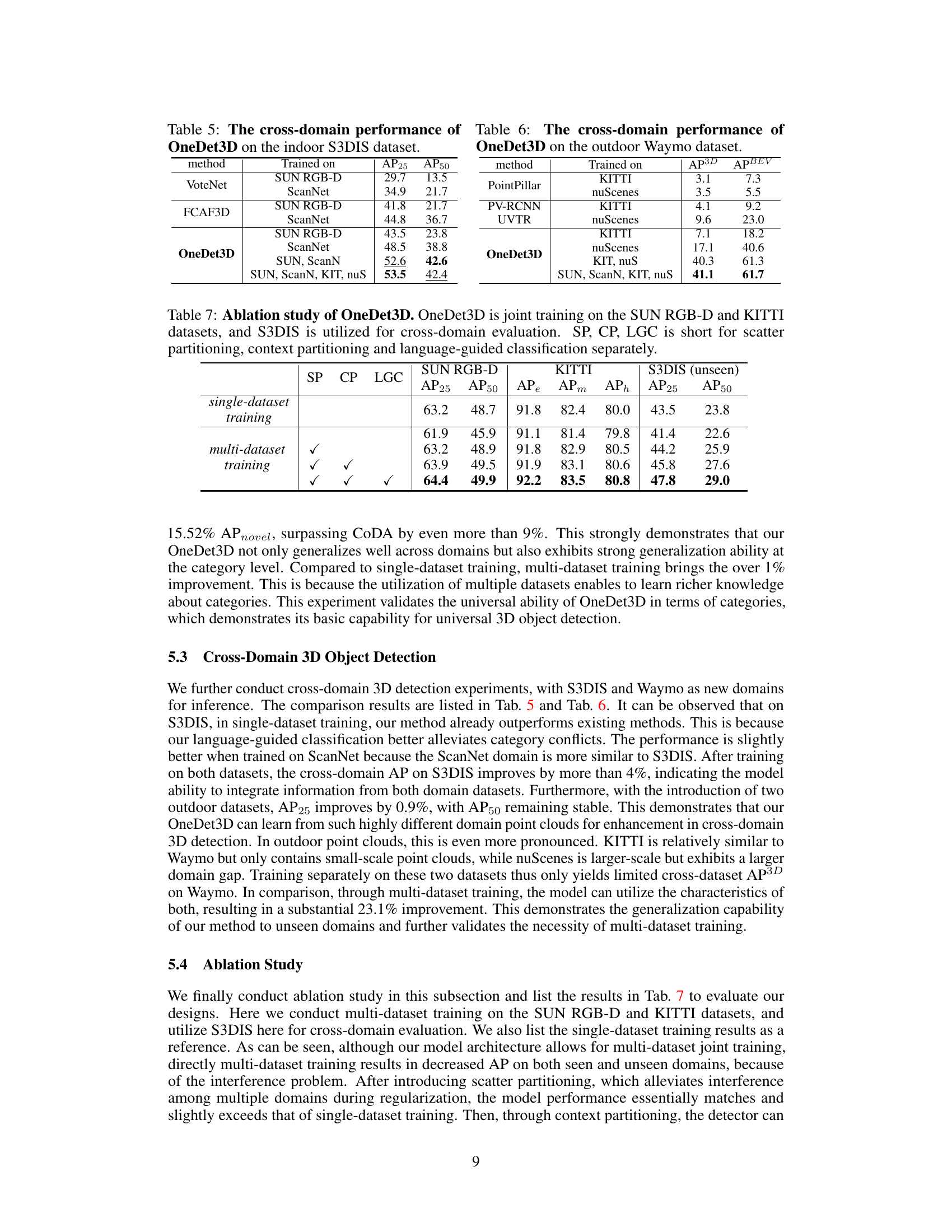
This table presents the results of ablation studies conducted on the OneDet3D model. It shows the impact of different components (scatter partitioning (SP), context partitioning (CP), and language-guided classification (LGC)) on the model’s performance, specifically focusing on the AP metrics (Average Precision) for different datasets (SUN RGB-D, KITTI, and S3DIS). The table compares the performance of the model with and without each of these components, both in single-dataset and multi-dataset training scenarios, providing a detailed analysis of their individual contributions to the overall performance.

This table presents an ablation study focusing on the impact of context partitioning within the OneDet3D model. It shows the performance (AP25, AP50, APe, APm, APh) on SUN RGB-D, KITTI, and S3DIS datasets under different training scenarios. Specifically, it compares single-dataset training with multi-dataset training using various context partitioning strategies (no CP, CP for indoor and outdoor, CP for indoor only) to highlight the effectiveness of context partitioning for improving performance, especially in cross-domain scenarios (S3DIS).

This table presents the ablation study on the language-guided classification method used in OneDet3D. It compares different classification approaches, including using only 3D sparse convolution, CLIP embeddings (frozen), CLIP embeddings (trainable), and a combination of 3D sparse convolution and frozen CLIP embeddings. The results are shown in terms of AP metrics (AP25, AP50, APE, APM, APh) for SUN RGB-D, KITTI, and S3DIS datasets (S3DIS is used for cross-domain evaluation). This demonstrates the impact of each classification approach on both seen and unseen datasets.
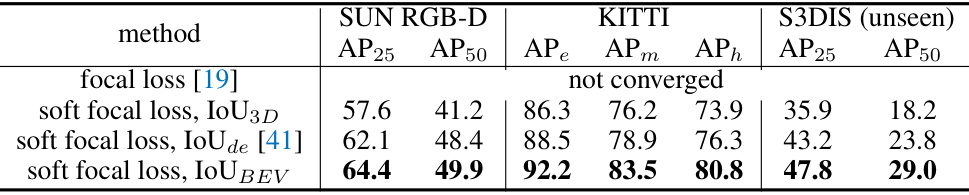
This table shows the ablation study of different classification loss functions used in OneDet3D. The model is trained on SUN RGB-D and KITTI datasets and evaluated on the unseen S3DIS dataset. The results demonstrate the impact of different loss functions on the overall performance of the model in terms of AP25, AP50, AP_e, AP_m, AP_h on SUN RGB-D and KITTI datasets and AP25, AP50 on the unseen S3DIS dataset.
Full paper#