TL;DR#
Class-agnostic object detection, crucial for many downstream vision tasks, faces challenges due to diverse object types and contextual complexities. Existing methods struggle to achieve high recall rates, especially for small or out-of-distribution objects. Manually crafted text queries for vision-language models often yield low confidence due to semantic overlap.
To address these limitations, the paper introduces DiPEx, a novel self-supervised prompt expansion technique. DiPEx progressively learns and expands a set of non-overlapping hyperspherical prompts using dispersion losses to maximize inter-class discrepancy while ensuring semantic consistency between parent and child prompts. Early termination based on maximum angular coverage (MAC) prevents prompt set overgrowth. Experiments on MS-COCO and LVIS datasets show that DiPEx significantly improves class-agnostic object detection performance and outperforms existing methods in both average recall (AR) and average precision (AP).
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenging problem of class-agnostic object detection, improving the recall rate significantly. This is crucial for various downstream tasks, especially in open-vocabulary and out-of-distribution object detection, areas of current focus in computer vision research. The proposed method, DiPEx, offers a novel approach to enhance the performance of Vision-Language Models, paving the way for more robust and versatile object detection systems. The code’s availability further promotes reproducibility and facilitates further research in this field.
Visual Insights#
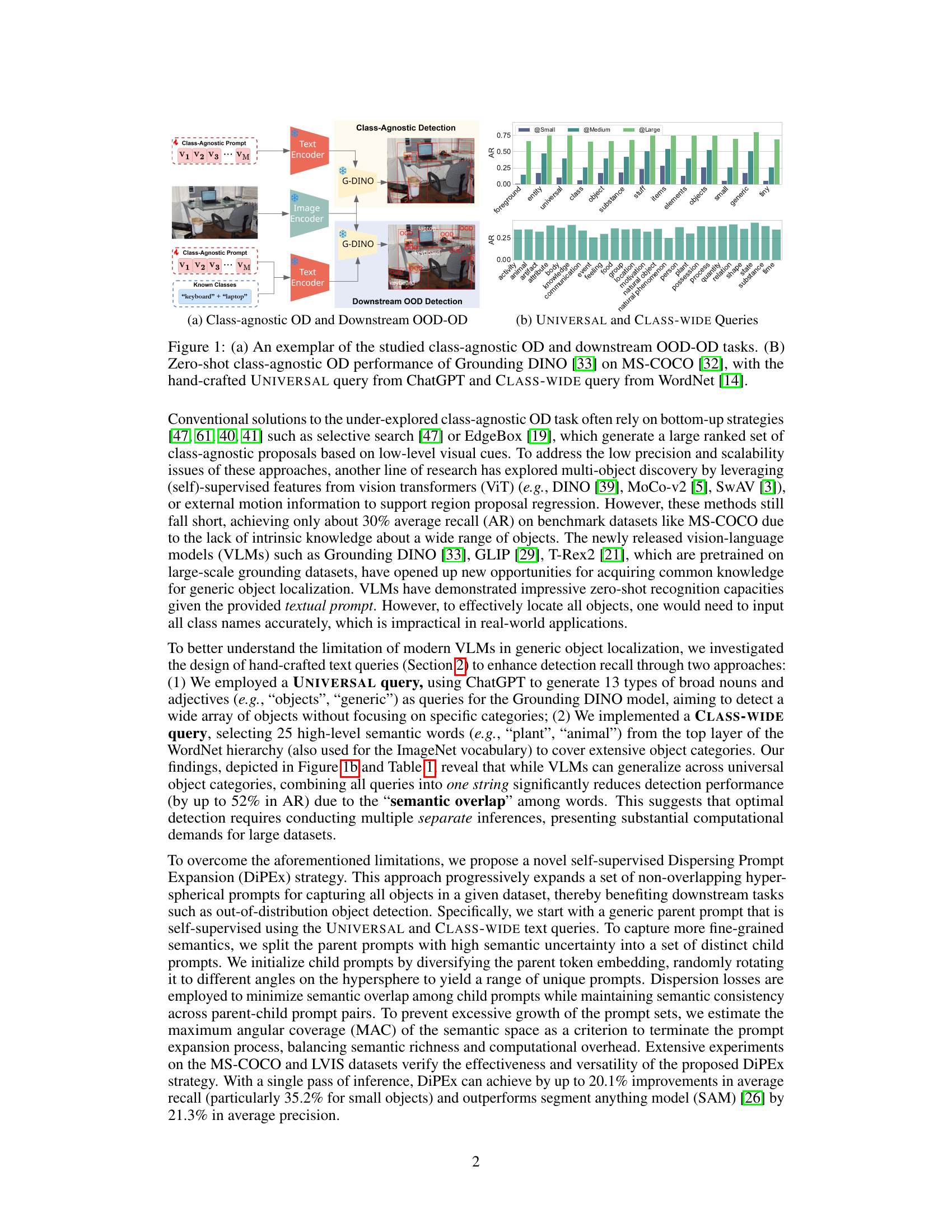
🔼 This figure shows two subfigures. Subfigure (a) illustrates the class-agnostic object detection (OD) task and its downstream out-of-distribution (OOD) object detection task. It displays examples of images with detected objects. Subfigure (b) presents a bar chart comparing the zero-shot class-agnostic object detection performance of Grounding DINO on MS-COCO using two different types of hand-crafted queries: UNIVERSAL queries (generated by ChatGPT) and CLASS-WIDE queries (from WordNet). The chart shows the average recall (AR) for various query types, highlighting the impact of query design on detection performance.
read the caption
Figure 1: (a) An exemplar of the studied class-agnostic OD and downstream OOD-OD tasks. (B) Zero-shot class-agnostic OD performance of Grounding DINO [33] on MS-COCO [32], with the hand-crafted UNIVERSAL query from ChatGPT and CLASS-WIDE query from WordNet [14].
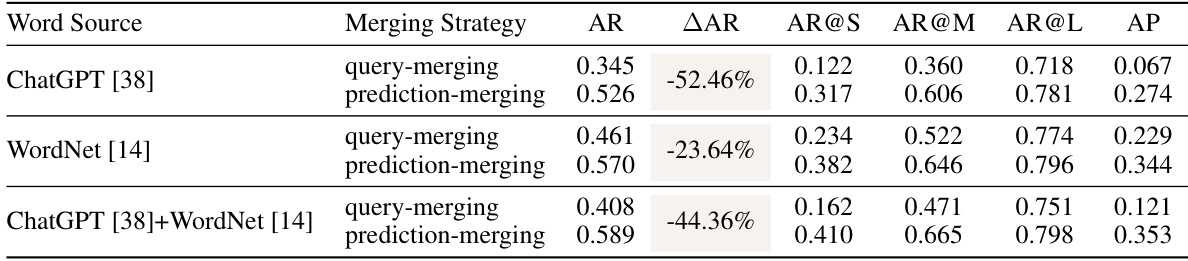
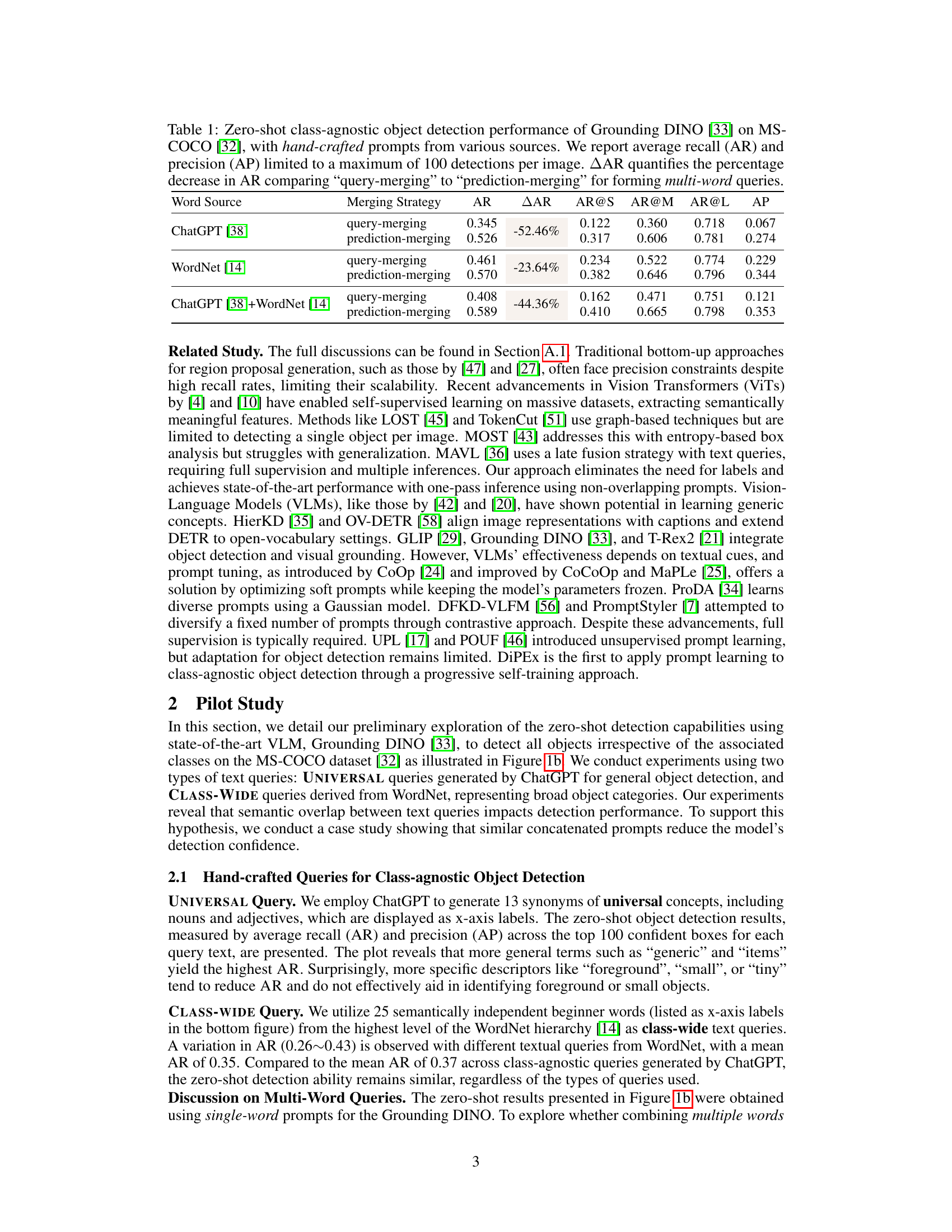
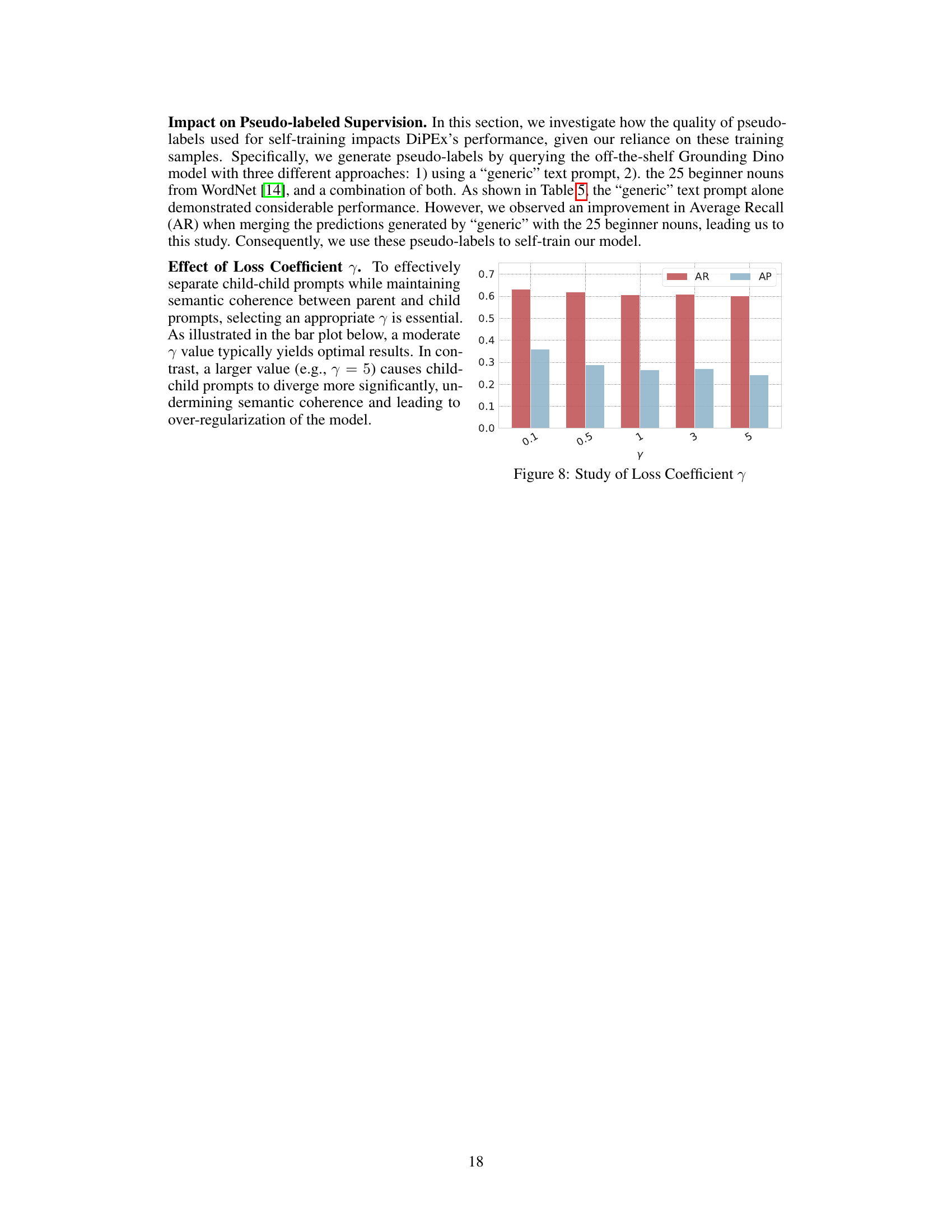
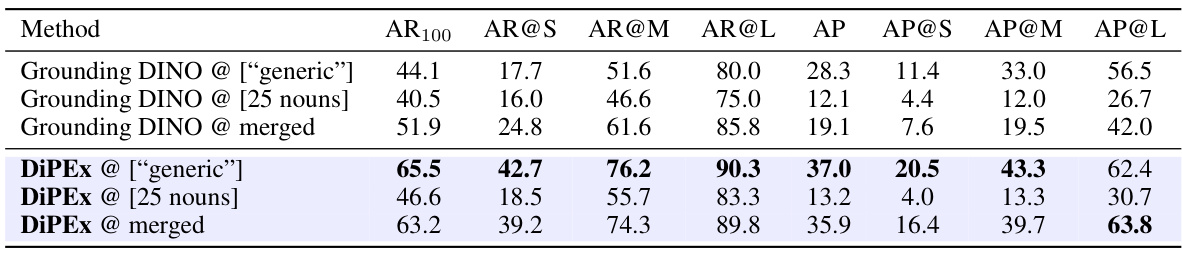
🔼 This table presents the zero-shot class-agnostic object detection results on the MS-COCO dataset using Grounding DINO. Three different prompt sources (ChatGPT, WordNet, and a combination of both) are used, and two merging strategies (query-merging and prediction-merging) are compared. The table reports average recall (AR), average recall at different object sizes (AR@S, AR@M, AR@L), average precision (AP), and the percentage decrease in AR when using query-merging instead of prediction-merging (AAR). This allows for analysis of how different query approaches and merging methods affect the performance of class-agnostic object detection.
read the caption
Table 1: Zero-shot class-agnostic object detection performance of Grounding DINO [33] on MS-COCO [32], with hand-crafted prompts from various sources. We report average recall (AR) and precision (AP) limited to a maximum of 100 detections per image. AAR quantifies the percentage decrease in AR comparing “query-merging” to “prediction-merging” for forming multi-word queries.
In-depth insights#
DiPEx: Core Idea#
DiPEx’s core idea revolves around addressing the recall limitations in class-agnostic object detection by leveraging vision-language models (VLMs). Instead of relying on generic prompts that suffer from semantic overlap, DiPEx progressively learns and expands a set of diverse, non-overlapping hyperspherical prompts. This expansion is guided by semantic uncertainty, ensuring that newly generated prompts capture increasingly fine-grained semantic details. A crucial component is the use of dispersion loss to maximize inter-class discrepancy, preventing the prompts from becoming overly similar and hindering performance. To control prompt set growth and computational cost, DiPEx incorporates maximum angular coverage (MAC) as an early termination criterion. By dynamically refining the prompt set, DiPEx aims for a more thorough and comprehensive object detection across various classes, even those outside the training distribution.
Prompt Expansion#
Prompt expansion, in the context of vision-language models (VLMs) for object detection, signifies a technique to enhance the model’s ability to identify a wider range of objects. Instead of relying on a fixed set of prompts, prompt expansion techniques aim to iteratively grow and diversify the set of prompts, leading to a richer semantic representation and improved recall. This is particularly crucial for class-agnostic object detection, where the goal is to detect objects irrespective of their class labels. The core idea is that a small set of generic prompts might miss objects due to semantic overlap, while expanding prompts allows the VLM to capture more nuanced details and improve performance on both in-distribution and out-of-distribution object detection tasks. Successful strategies often involve employing dispersion losses to avoid semantic overlap between newly generated prompts, thereby promoting diversity and preventing overfitting. Careful management of prompt expansion is also essential to avoid excessive computational costs, with techniques like maximum angular coverage used to control the growth of the prompt set, striking a balance between richer semantic information and computational efficiency.
Zero-Shot Limits#
Zero-shot learning aims to enable models to recognize novel classes without explicit training examples. However, inherent limitations exist, especially in complex scenarios. A key limitation is the reliance on transferable features, learned from a base dataset. If the features from the base dataset aren’t well-suited to the new classes (domain shift, object variability), performance will suffer. Semantic ambiguity in prompts is another constraint. Vague or overlapping prompts hinder accurate object identification. Contextual information is crucial, which zero-shot models often lack, leading to misinterpretations. Bias in base datasets can lead to unfair or inaccurate results for underrepresented groups. Computational cost can be high for complex zero-shot scenarios, limiting real-time applications. Therefore, understanding and mitigating these limitations are crucial for advancing zero-shot capabilities and ensuring reliable performance in real-world applications. Future research should focus on robust feature learning, enhanced prompt engineering techniques, contextual awareness, bias mitigation, and computationally efficient approaches.
OOD-OD Results#
An analysis of out-of-distribution object detection (OOD-OD) results would delve into the model’s performance on unseen object classes. Key aspects to consider include the average precision (AP) and average recall (AR) metrics across various Intersection over Union (IoU) thresholds. A breakdown by object size (small, medium, large) would reveal any biases in detection capabilities. Comparisons against state-of-the-art methods are essential to establish the proposed method’s effectiveness. Furthermore, analyzing results across multiple datasets would help determine its generalizability. A deeper analysis should investigate how well the model handles the uncertainty associated with novel objects, exploring factors like false positives and false negatives. Ultimately, the goal is to demonstrate robustness and superior performance on OOD-OD scenarios, highlighting any limitations and potential areas for improvement.
Future of DiPEx#
The future of DiPEx hinges on several key areas. Extending DiPEx to other Vision-Language Models (VLMs) beyond Grounding DINO is crucial to establish its generalizability and robustness. Investigating different prompt initialization strategies could enhance efficiency and effectiveness, potentially exploring techniques beyond random hyperspherical rotations. Addressing the computational cost associated with iterative prompt expansion is vital for real-world applications; exploring more efficient expansion algorithms or early stopping criteria is necessary. Further research should focus on analyzing the semantic space more rigorously to understand the relationship between prompt embeddings and object detection performance, potentially informing more principled prompt expansion methods. Finally, developing a better understanding of the interplay between semantic overlap, prompt diversity, and overall detection accuracy will help refine the approach and push the boundaries of class-agnostic object detection.
More visual insights#
More on figures

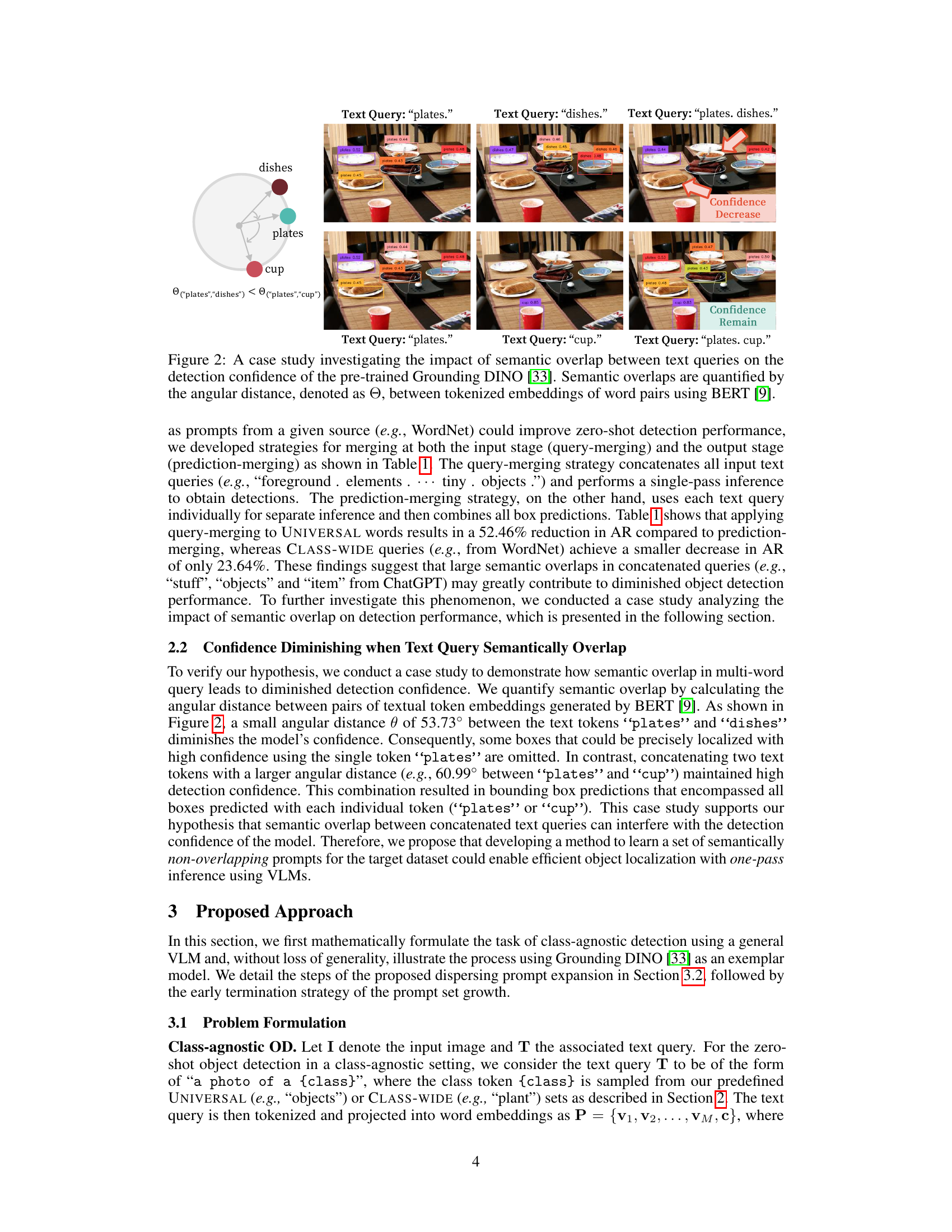
🔼 This figure shows a case study demonstrating how semantic overlap between text queries affects object detection confidence using the Grounding DINO model. Three different query combinations are tested: ‘plates’, ‘dishes’, and ‘plates. dishes’. The results show that when semantically similar words (‘plates’ and ‘dishes’) are combined, the detection confidence decreases compared to using each word individually. However, combining words with less semantic overlap (‘plates’ and ‘cup’) maintains high detection confidence. The angular distance between word embeddings, calculated using BERT, is used to quantify the semantic overlap.
read the caption
Figure 2: A case study investigating the impact of semantic overlap between text queries on the detection confidence of the pre-trained Grounding DINO [33]. Semantic overlaps are quantified by the angular distance, denoted as θ, between tokenized embeddings of word pairs using BERT [9].

🔼 This figure illustrates the DiPEx (Dispersing Prompt Expansion) approach. The left panel shows the hierarchical structure of the prompt expansion process, where a parent prompt is iteratively expanded into multiple child prompts over L layers. The middle panel details how child prompt embeddings are initialized by diversifying the parent prompt embedding on a hypersphere through random rotations. The right panel demonstrates how the maximum angular coverage (@max) is calculated to determine when to stop expanding prompts, balancing the richness of semantic information and computational cost. This figure visually summarizes the key steps of DiPEx, showing how it efficiently expands prompts while avoiding excessive growth and semantic overlap.
read the caption
Figure 3: An illustration of the ① proposed prompt expansion strategy that selectively grows a set of child prompts for the highlighted parent prompt across L iterations; ② diversifying initialized embeddings of the child prompt on a hypersphere and ③ quantifying maximum angular coverage @max for early termination of the prompt growth.
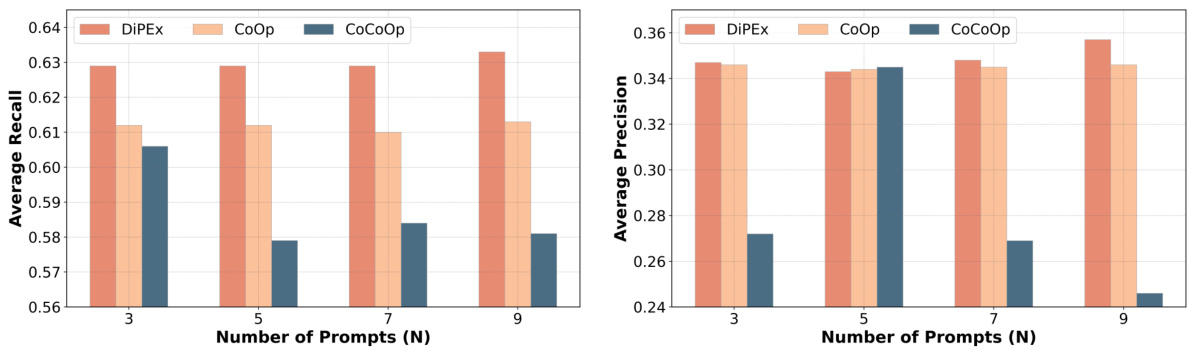
🔼 This figure shows the impact of the number of prompts on the average recall (AR) and average precision (AP) for class-agnostic object detection on the MS-COCO dataset. It compares the performance of DiPEx against two other methods, CoOp and CoCoOp, demonstrating that increasing the number of prompts generally improves performance for DiPEx but not necessarily for other methods. The x-axis represents the number of prompts and the y-axis shows the average recall and precision scores.
read the caption
Figure 4: Impact of the prompt length on the MS-COCO dataset. The average recall (AR) and precision (AP) are reported to compare the derived DiPEx against CoOp [24] and CoCoOp [23].

🔼 This figure displays heatmaps showing the angular coverage of learned prompts after 2, 3, and 4 training rounds. The heatmaps visualize the pairwise angular distances between the prompts. The maximum angular coverage (MAC) increases monotonically over the rounds, indicating that the prompts are successfully expanding to cover a broader semantic space. The diminishing rate of increase in MAC in later rounds suggests the model is approaching convergence, implying the prompt expansion process is nearing completion.
read the caption
Figure 5: The heatmap visualization presents the angular coverage across all learned prompts through the 2nd, the 3rd, and the 4th round of training. The maximum angular coverage (MAC) monotonically increases from 67.7° in the 2nd round to 75.95° in the final round. The gradual reduction in rate of change in angular coverage towards the final round suggests that the model nearing convergence.
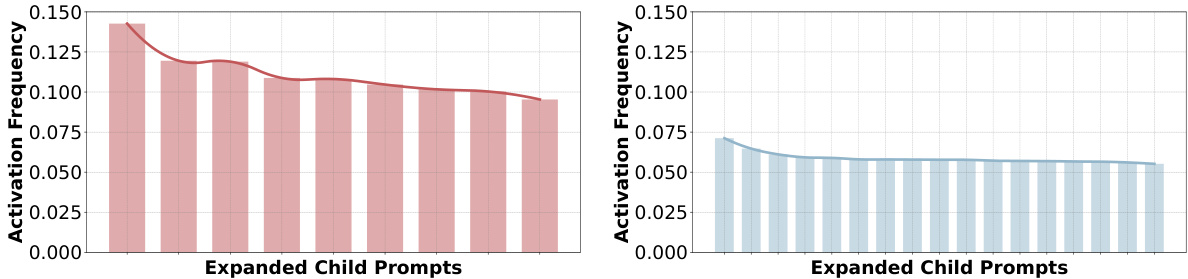
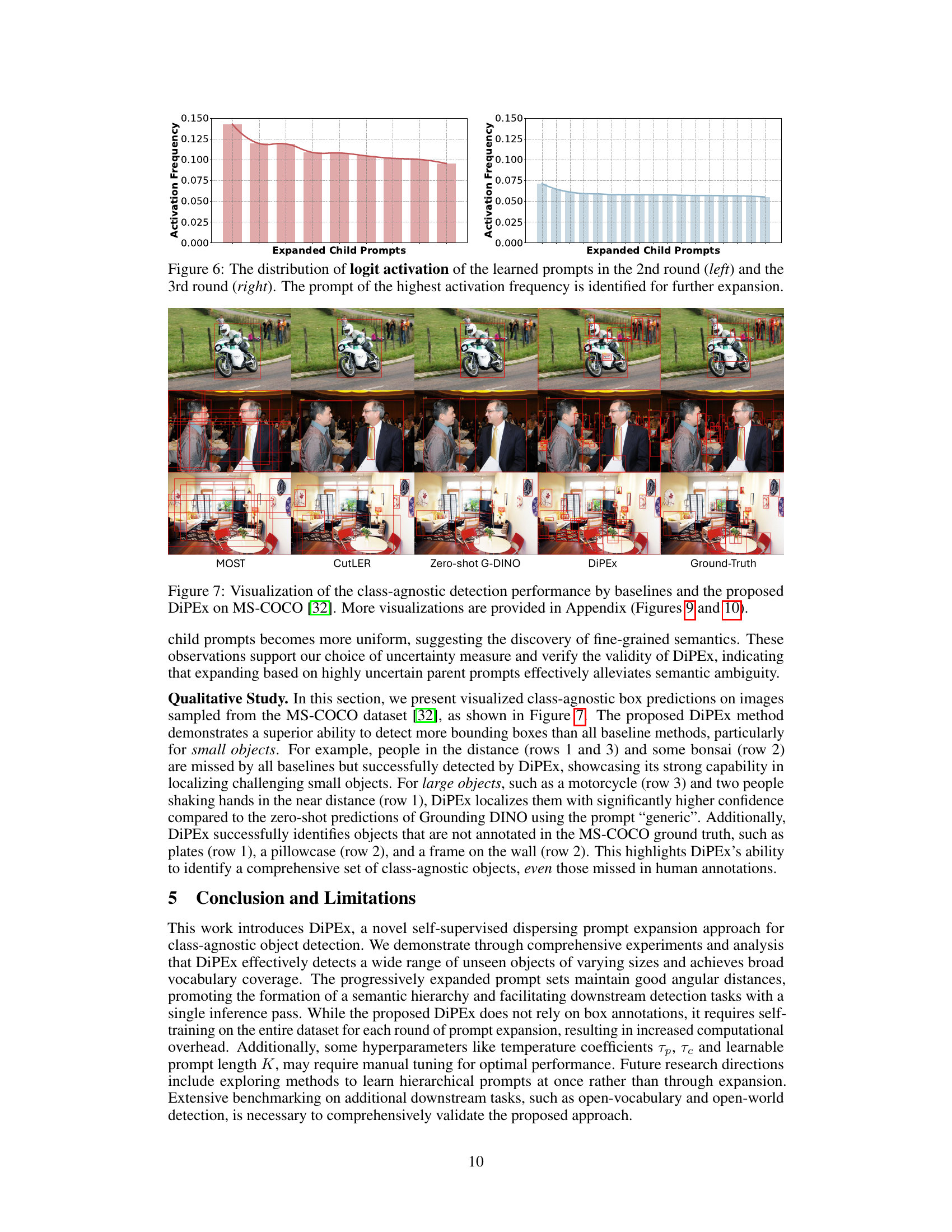
🔼 This figure shows the distribution of logit activation frequencies for the learned prompts after the second and third rounds of prompt expansion in the DiPEx method. The left panel displays the distribution after the second round, while the right panel shows the distribution after the third round. The prompt with the highest activation frequency (the one with the most uncertainty) is then selected for further expansion in subsequent rounds. This visualization helps to illustrate how the method iteratively refines the prompts and addresses semantic ambiguity by focusing on the most uncertain prompts.
read the caption
Figure 6: The distribution of logit activation of the learned prompts in the 2nd round (left) and the 3rd round (right). The prompt of the highest activation frequency is identified for further expansion.

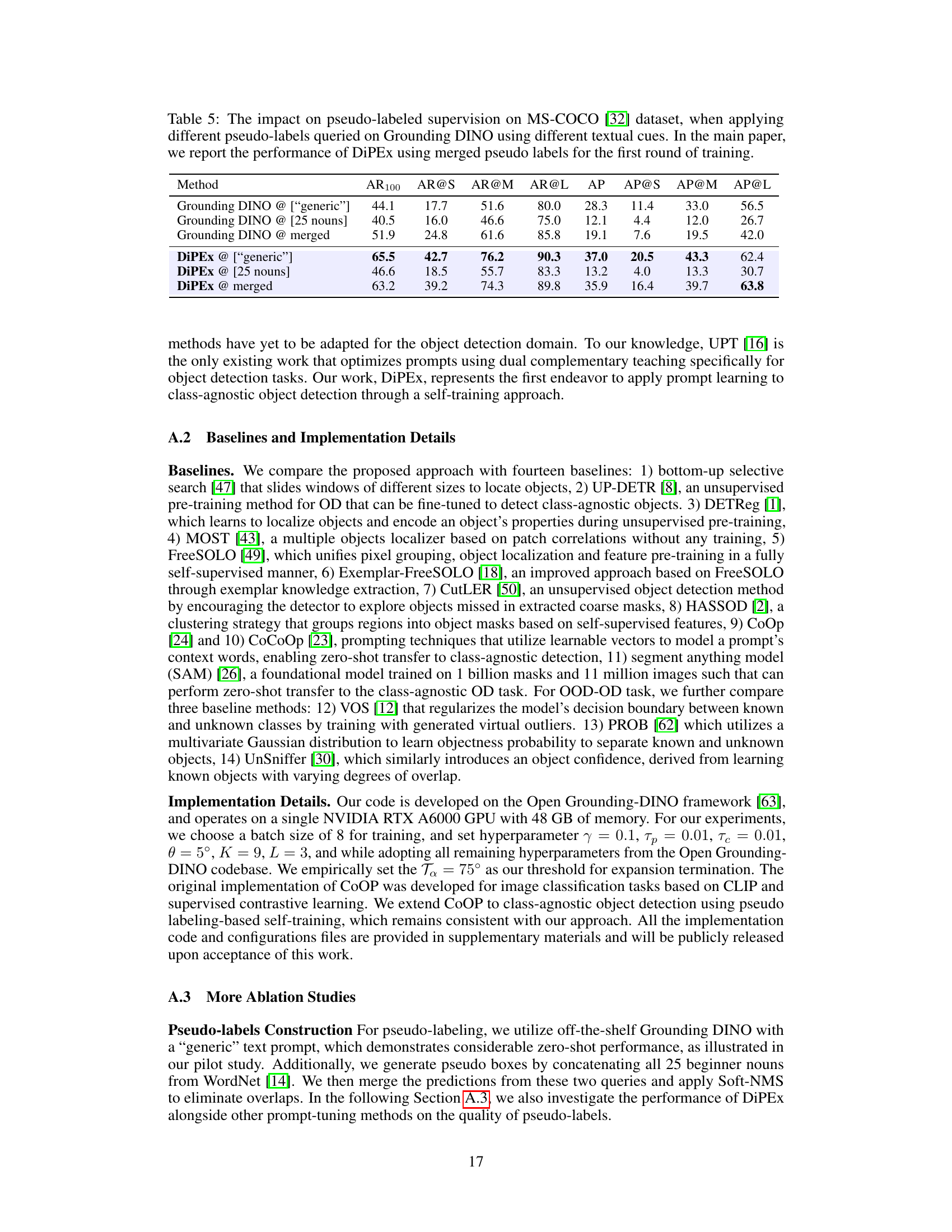
🔼 This figure shows a qualitative comparison of class-agnostic object detection results on several images from the MS-COCO dataset. It compares the performance of several methods: MOST, CutLER, Zero-shot G-DINO, and the proposed DiPEx. Each column represents the detection results from a different method, while the last column shows the ground truth bounding boxes. The figure aims to visually demonstrate DiPEx’s superior ability to detect a wider range of objects, especially smaller objects, compared to other baselines.
read the caption
Figure 7: Visualization of the class-agnostic detection performance by baselines and the proposed DiPEx on MS-COCO [32]. More visualizations are provided in Appendix (Figures 9 and 10).
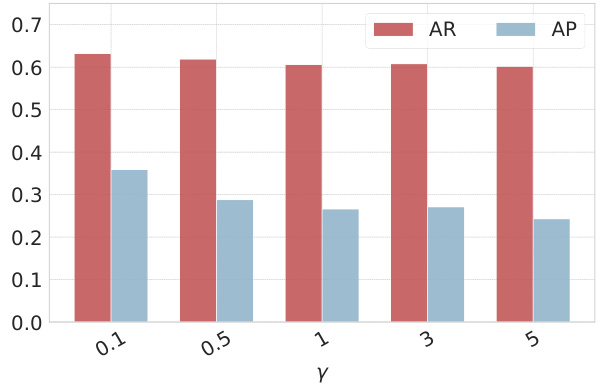
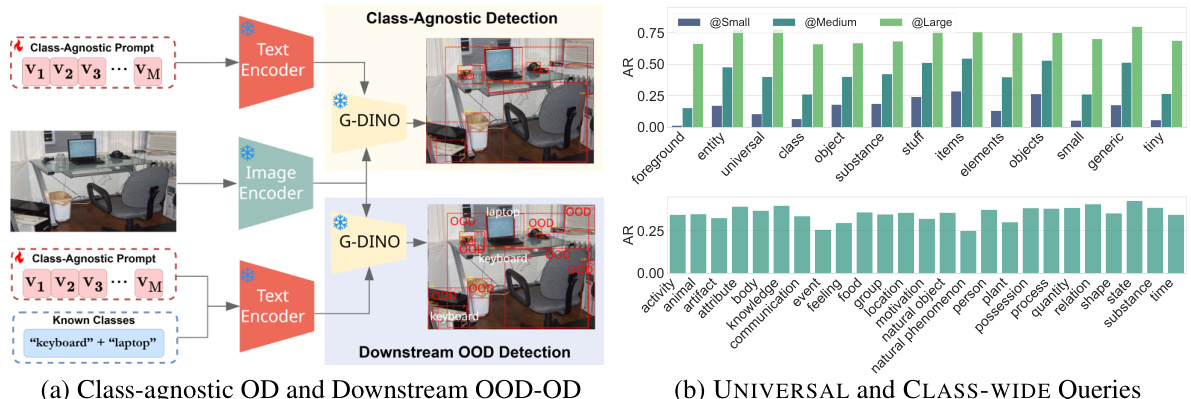
🔼 This bar chart displays the impact of the loss coefficient γ on the average recall (AR) and average precision (AP) in the DiPEx model. It shows that a moderate value of γ yields optimal results; larger values lead to over-regularization, while smaller values may not sufficiently separate child prompts.
read the caption
Figure 8: Study of Loss Coefficient γ

🔼 This figure provides a qualitative comparison of class-agnostic object detection performance between several methods, including MOST, CutLER, zero-shot Grounding DINO, and the proposed DiPEx method. Each column displays the detection results from a different method for the same set of images, while the last column shows the ground truth bounding boxes. This visualization allows for a direct comparison of the detection accuracy and the ability to locate objects in different scenes.
read the caption
Figure 9: Additional visualizations of class-agnostic box predictions. Columns 1–4 correspond to the following methods: MOST [43], CutLER [50], zero-shot Grounding DINO [“generic”] [9], and our proposed DiPEx, respectively. The final column presents human-annotated ground truth bounding boxes from the MS-COCO dataset [32].

🔼 This figure provides a visual comparison of class-agnostic object detection results on several images from the MS-COCO dataset. The results from four different methods (MOST, CutLER, zero-shot Grounding DINO, and DiPEx) are shown alongside the ground truth bounding boxes. The figure demonstrates DiPEx’s superior ability to detect a wider range of objects, particularly smaller objects, compared to the baseline methods.
read the caption
Figure 7: Visualization of the class-agnostic detection performance by baselines and the proposed DiPEx on MS-COCO [32]. More visualizations are provided in Appendix (Figures 9 and 10).
More on tables

🔼 This table presents the performance comparison of various class-agnostic object detection methods on the MS-COCO dataset. It includes both traditional bottom-up methods and more recent self-training and prompting-based approaches using the Grounding DINO model. The table shows the Average Recall (AR) at different detection thresholds (AR@1, AR@10, AR@100), average recall by object size (AR@S, AR@M, AR@L), and Average Precision (AP). The methods are categorized by their approach (e.g., self-training, zero-shot). The table highlights the improvement achieved by the proposed DiPEx method.
read the caption
Table 2: Class-agnostic object detection on the MS-COCO dataset. [] indicate the prompt word for Grounding DINO. The prompting methods indicated with '*' are adapted to the OD task.
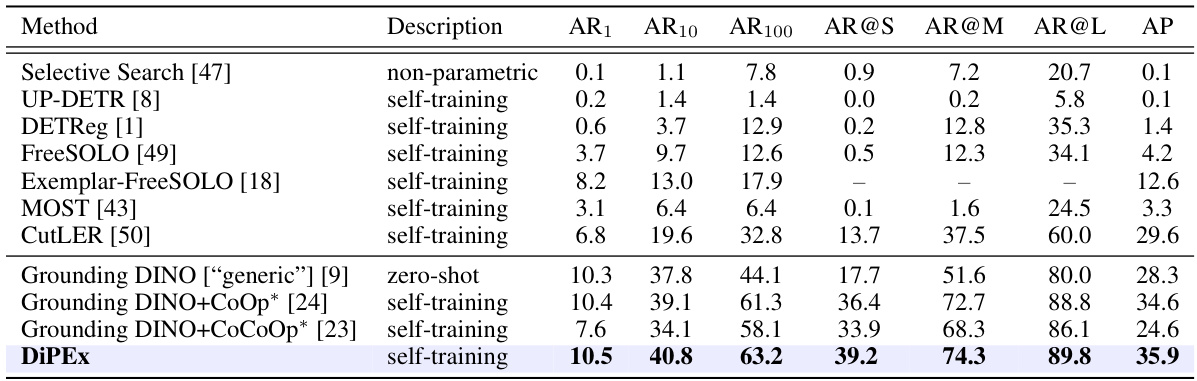
🔼 This table presents the results of class-agnostic object detection experiments on the MS-COCO dataset. It compares various methods, including several self-training approaches and zero-shot methods using Grounding DINO with different prompts. The metrics used to evaluate performance are Average Recall (AR) at different detection thresholds (AR1, AR10, AR100) along with average precision (AP) and average recall based on object size (AR@S, AR@M, AR@L). The table highlights the superior performance of DiPEx compared to other methods.
read the caption
Table 2: Class-agnostic object detection on the MS-COCO dataset. [] indicate the prompt word for Grounding DINO. The prompting methods indicated with '*' are adapted to the OD task.
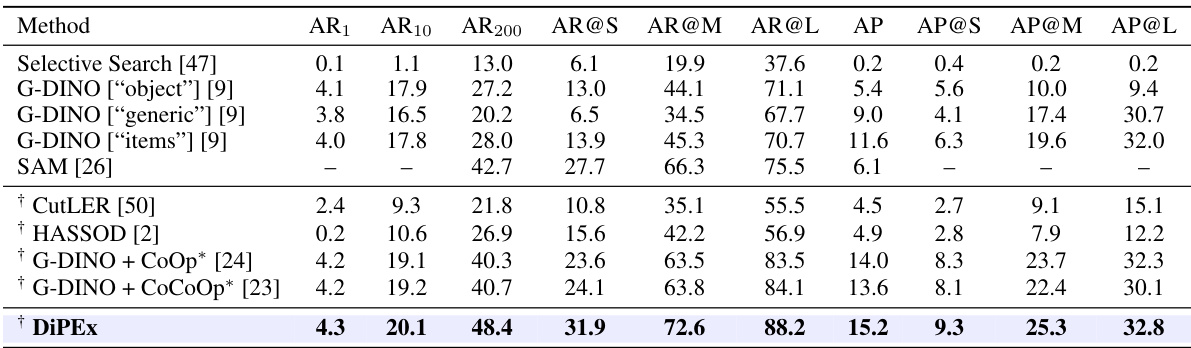
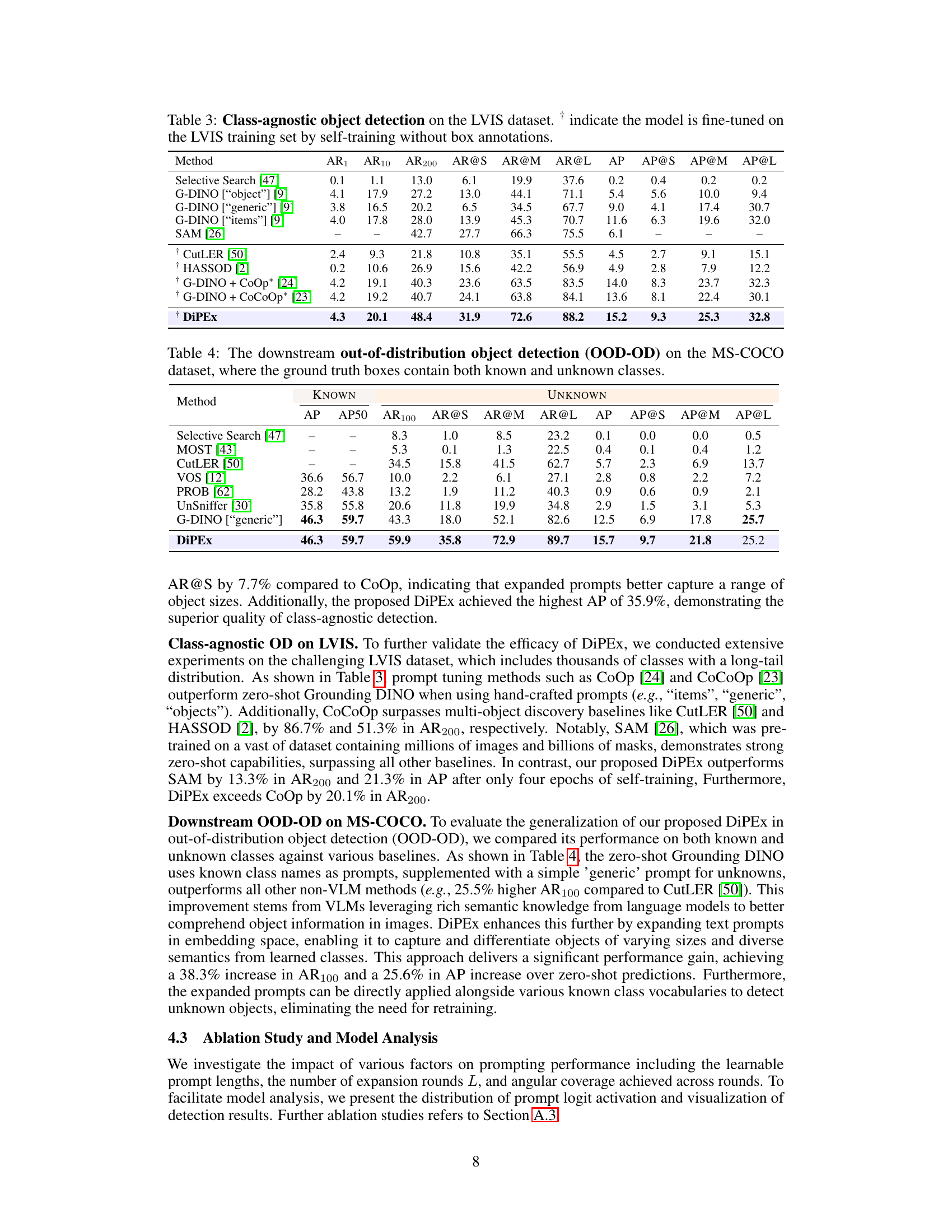
🔼 This table presents the results of class-agnostic object detection experiments conducted on the LVIS dataset. It compares the performance of various methods, including several baselines and the proposed DiPEx approach. The metrics reported include average recall (AR) at different detection thresholds (AR1, AR10, AR200), average recall for small, medium, and large objects (AR@S, AR@M, AR@L), and average precision (AP) and AP for small, medium, and large objects (AP@S, AP@M, AP@L). The † symbol indicates that the model was fine-tuned on the LVIS training set using self-training without ground truth bounding box annotations.
read the caption
Table 3: Class-agnostic object detection on the LVIS dataset. † indicate the model is fine-tuned on the LVIS training set by self-training without box annotations.
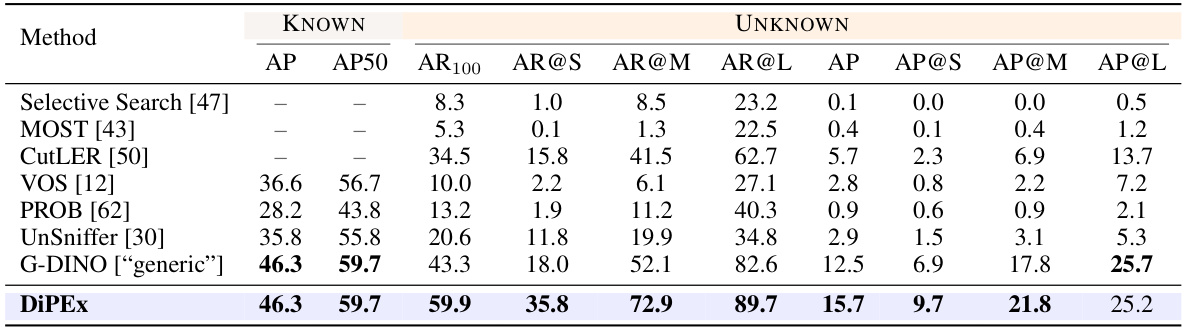
🔼 This table presents the results of out-of-distribution object detection experiments on the MS-COCO dataset. It compares different methods’ performance on identifying both known and unknown classes within the ground truth bounding boxes. The metrics used include Average Precision (AP), AP at IoU=0.5 (AP50), Average Recall at 100 detections (AR100), and Average Recall at different object scales (AR@S, AR@M, AR@L). The results are broken down to show performance on known classes and unknown classes separately, providing a comprehensive evaluation of the methods’ ability to generalize to unseen objects.
read the caption
Table 4: The downstream out-of-distribution object detection (OOD-OD) on the MS-COCO dataset, where the ground truth boxes contain both known and unknown classes.
🔼 This table presents the performance comparison of various methods for class-agnostic object detection on the MS-COCO dataset. It shows the average recall (AR) at different detection thresholds (AR@1, AR@10, AR@100) and average precision (AP) for different object sizes (small, medium, large). Methods include several baselines (e.g., Selective Search, UP-DETR, etc.) and different prompting methods using Grounding DINO, with and without adaptation for object detection tasks. DiPEx achieves the best performance.
read the caption
Table 2: Class-agnostic object detection on the MS-COCO dataset. [ ] indicate the prompt word for Grounding DINO. The prompting methods indicated with ‘*’ are adapted to the OD task.
Full paper#