↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing Contrastive Language-Image Pre-training (CLIP) models struggle with fine-grained details, limiting their effectiveness in dense prediction tasks. Existing solutions often sacrifice visual-semantic consistency or rely on limited annotations. This necessitates a new approach that maintains visual-semantic consistency while enhancing fine-grained understanding.
FineCLIP addresses these issues by introducing two key innovations: 1) A real-time self-distillation scheme that facilitates the transfer of representation capability from global to local features. 2) A semantically-rich regional contrastive learning paradigm that leverages generated region-text pairs to boost local representation capabilities with abundant fine-grained knowledge. Extensive experiments demonstrate FineCLIP’s effectiveness on various tasks, surpassing previous state-of-the-art models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models and fine-grained image understanding. FineCLIP’s innovative self-distillation and regional contrastive learning methods offer significant improvements over existing techniques. Its superior performance on various benchmarks and scalability showcases its potential to advance the field. The automated region-text data generation method is also a significant contribution, streamlining future research in this area. The findings open new avenues for investigation into more robust and scalable vision-language models.
Visual Insights#
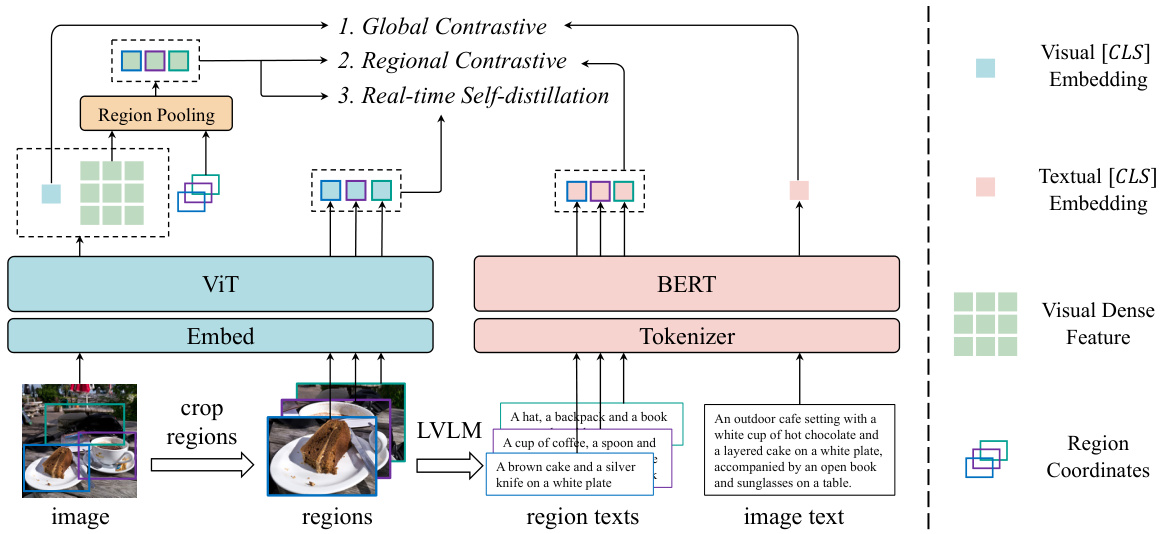
This figure illustrates the overall architecture of FineCLIP, highlighting its three main components: global contrastive learning, regional contrastive learning, and real-time self-distillation. It shows how FineCLIP processes image and text data to align visual and textual embeddings at both global and regional levels, leveraging a large vision-language model (LVLM) to generate semantically rich region-text pairs. The diagram simplifies the representation by omitting unused visual and textual dense features for clarity.
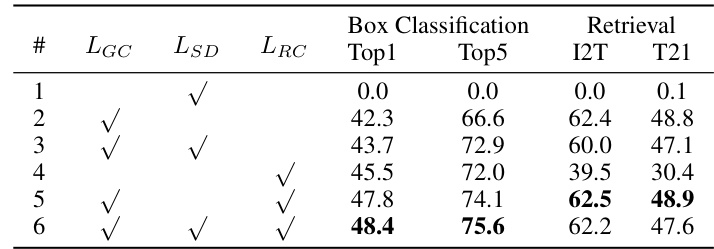
This table presents the ablation study results on the three objective components of FineCLIP: global contrastive loss (LGC), real-time self-distillation loss (LSD), and semantically-rich regional contrastive loss (LRC). It shows the performance of FineCLIP when different combinations of these components are used for training, evaluated on box classification (Top1 and Top5 accuracy) and retrieval (I2T and T2I R@1 accuracy) tasks. The results demonstrate the individual and combined contributions of each component to the overall performance of FineCLIP.
In-depth insights#
FineCLIP’s Core#
FineCLIP’s core innovation lies in its multi-faceted approach to enhancing fine-grained visual understanding within the CLIP framework. It intelligently combines global contrastive learning, preserving the vital visual-semantic consistency of CLIP, with two key advancements: a real-time self-distillation mechanism for transferring knowledge from global to local representations and a semantically rich regional contrastive learning paradigm leveraging large vision-language models (LVLMs) to generate diverse region-text pairs. This synergistic approach allows FineCLIP to move beyond CLIP’s limitations in dense prediction tasks. The real-time self-distillation avoids the limitations of using a frozen teacher model, which boosts the overall performance. The LVLMs provide the rich fine-grained semantics needed to overcome the inherent lack of semantic diversity in pre-defined templates. FineCLIP’s architecture thus effectively leverages both global and local image-text relationships to achieve superior performance in complex visual tasks. This unified approach leads to a more robust and scalable model, making FineCLIP a significant advancement in vision-language representation learning.
Multi-grained Learning#
Multi-grained learning, in the context of visual-language models, goes beyond solely relying on global image-text correspondences. It leverages information at multiple levels of granularity, combining coarse-grained global features with fine-grained local details. This approach addresses the limitations of models that struggle with fine-grained understanding, such as identifying specific attributes or relationships within an image. By incorporating regional information and contextual cues, the model develops a more robust and nuanced understanding. Self-distillation techniques, transferring knowledge from global representations to local features, are key enablers of this approach, enhancing the efficacy of fine-grained learning. The combination of global and local contrastive learning paradigms further strengthens visual-semantic alignment, leading to improved performance on dense prediction tasks and image-level tasks. This multi-faceted learning paradigm results in more comprehensive and semantically rich visual representations, exceeding the capabilities of methods relying solely on global features or pre-defined labels.
Self-Distillation#
Self-distillation, in the context of deep learning models, is a powerful technique where a model learns from its own predictions. FineCLIP leverages self-distillation to bridge the gap between global and local feature understanding. By using a real-time self-distillation scheme, knowledge learned from global image-text embeddings is transferred to local, region-specific feature extractions. This transfer is not from a frozen teacher model, as in prior methods, but from the trainable FineCLIP model itself. This dynamic approach allows for continuous refinement of both global and local representations throughout training, improving scalability and fine-grained understanding capabilities. In essence, self-distillation acts as a powerful mechanism to ensure that the lower-level, fine-grained features are consistent with, and benefit from, the high-level semantic understanding obtained through global contrastive learning. The resulting synergy between global and regional feature alignment enhances the model’s overall effectiveness in both image-level and dense prediction tasks. The real-time nature of FineCLIP’s self-distillation is key to this success, avoiding the limitations of previous methods that rely on frozen teachers and thus limit potential performance gains.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In a research paper, a well-executed ablation study is crucial for demonstrating the effectiveness of specific design choices. A strong ablation study isolates the impact of each component, showing that the improvements aren’t simply due to the increased model complexity or other confounding factors. By carefully removing elements one by one, researchers can highlight the unique benefits of each part and establish a clear understanding of the model’s architecture. Well-designed ablation studies demonstrate causality, not just correlation; the findings should robustly support the paper’s claims. The results need to be presented clearly and concisely, often in tabular format, to allow for easy comparison of performance with and without the components in question. A lack of, or a poorly conducted, ablation study can weaken the paper’s conclusions, casting doubt on the reliability and generalizability of the results. A thorough ablation study is essential for building trust and confidence in the presented research, adding significant weight to the overall findings.
Future Works#
Future research directions stemming from this FineCLIP work could involve several key areas. Improving the region proposal methods is crucial; current approaches struggle to balance category richness and accurate segmentation, hindering performance, especially with numerous categories. Exploring more advanced Large Vision-Language Models (LVLMs) for generating higher-quality region descriptions is also essential, as the quality of these descriptions directly impacts the model’s fine-grained understanding. Scaling FineCLIP to even larger datasets while maintaining efficiency is vital for further enhancing its capabilities. Investigating the potential for incorporating more sophisticated self-distillation techniques to better transfer knowledge from global to local representations could significantly boost performance. Finally, a thorough investigation into the trade-offs between efficiency and model complexity, especially concerning the number of parameters used, is necessary for better scalability and practical deployment of FineCLIP.
More visual insights#
More on figures

This figure displays the performance of various models (CLIP, RegionCLIP, CLIPSelf, and FineCLIP) on three different tasks: COCO box classification, COCO R@1 image-to-text retrieval, and COCO R@1 text-to-image retrieval. The models were pre-trained on datasets of three different sizes (100K, 500K, and 2.5M samples). The graphs clearly show FineCLIP’s superior performance and superior scaling ability compared to other methods across all three tasks and dataset scales.

This figure illustrates the overall architecture of the proposed FineCLIP model. It shows how FineCLIP combines global and regional contrastive learning with a real-time self-distillation mechanism. The diagram shows the processing of images and texts through Vision and Language encoders, including the extraction of global and regional visual features. It highlights the generation of region-text pairs using a Large Vision-Language Model (LVLM), emphasizing the model’s ability to learn from both coarse-grained (global) and fine-grained (regional) image-text information.

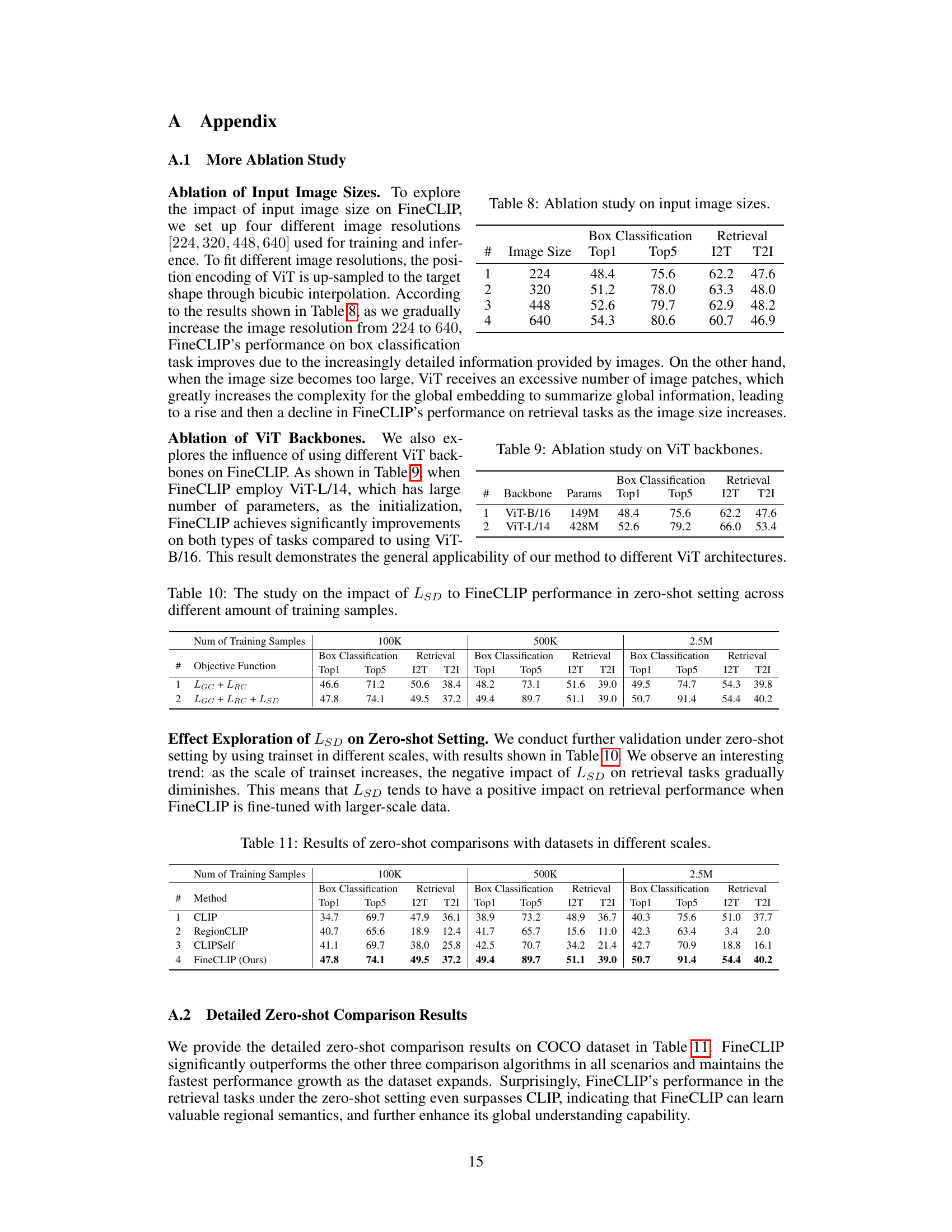
This figure visualizes the dense features extracted by CLIP and FineCLIP using k-means clustering. It shows the original images alongside the k-means clustering results for both CLIP and FineCLIP. The visualization helps illustrate how FineCLIP produces more focused and semantically consistent dense features compared to CLIP.
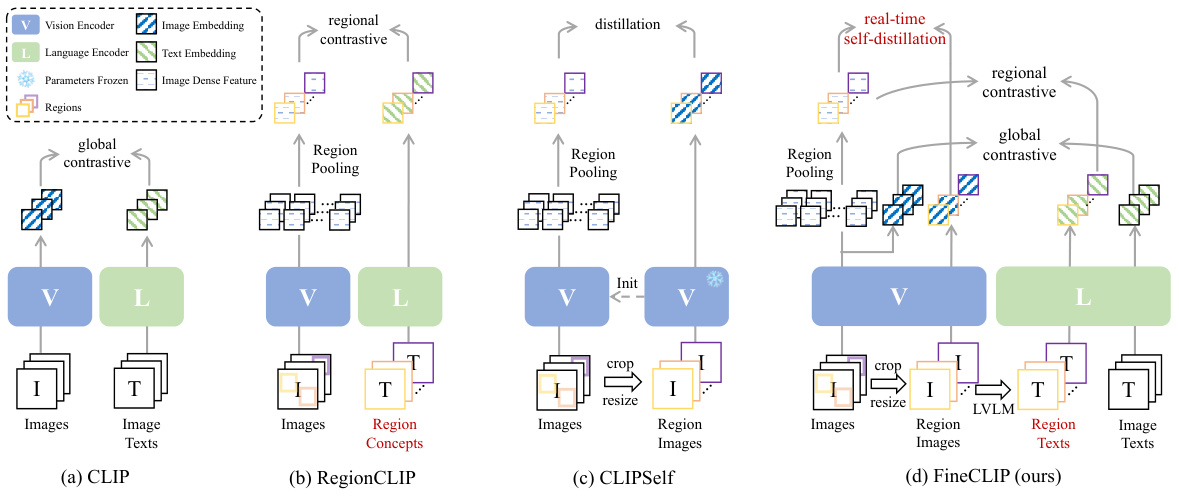
This figure illustrates the architecture of FineCLIP, highlighting its key components: global contrastive learning, regional contrastive learning, and real-time self-distillation. FineCLIP processes image-text pairs and generated region-text pairs to align visual global embeddings, regional dense features, and textual global embeddings in a unified space, thereby capturing both coarse-grained and fine-grained information.
More on tables

This table compares the performance of FineCLIP using four different region proposal methods: manual annotations from COCO, FastSAM [69], RPN [43], and YOLOv9 [51]. The results show the Top1 and Top5 accuracy for box classification, and the Recall@1 (R@1) for image-to-text (I2T) and text-to-image (T2I) retrieval. The number of regions per image and time overhead for each method are also included. The table demonstrates the impact of different region proposal methods on FineCLIP’s performance, highlighting the trade-off between the number of proposals, precision, and overall accuracy.
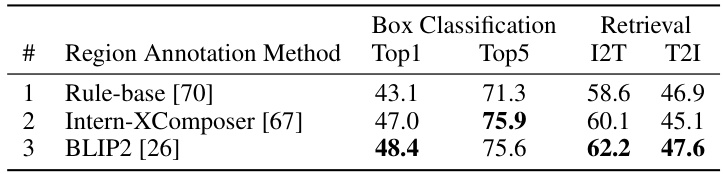
This table presents the ablation study on different region annotation methods used in FineCLIP. Three methods are compared: a rule-based method [70], Intern-XComposer [67], and BLIP2 [26]. The performance is evaluated using Top1 and Top5 accuracy for box classification and I2T and T2I for image-to-text and text-to-image retrieval tasks, respectively. The results show that LVLMs (like BLIP-2) outperform the rule-based method, highlighting the effectiveness of LVLMs in generating valuable fine-grained knowledge for the model.
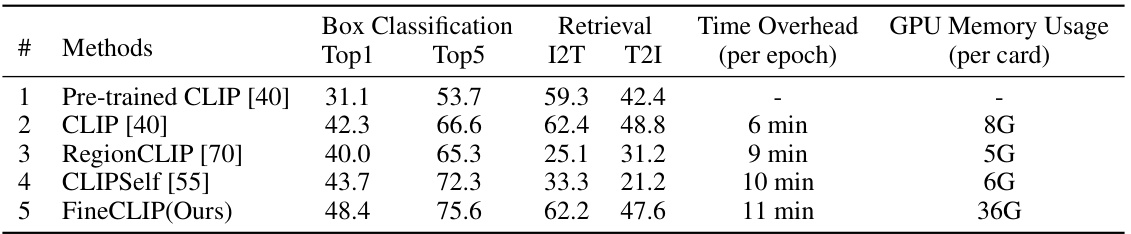
This table compares the performance of FineCLIP against three other methods (Pre-trained CLIP, RegionCLIP, and CLIPSelf) on the COCO dataset. It shows the Top1 and Top5 accuracy for box classification, and the Recall@1 (R@1) accuracy for image-to-text (I2T) and text-to-image (T2I) retrieval tasks. Additionally, it provides the time overhead per epoch and the GPU memory usage per card for each method during training.
This table compares the performance of FineCLIP using four different region proposal methods: manual annotations from COCO, FastSAM, RPN, and YOLOv9. The metrics used are Top1 and Top5 accuracy for box classification, and Recall@1 for image-to-text (I2T) and text-to-image (T2I) retrieval tasks. The number of regions per image and the time overhead for each method are also reported. This allows for a comparison of the trade-off between accuracy and efficiency for various region proposal methods.
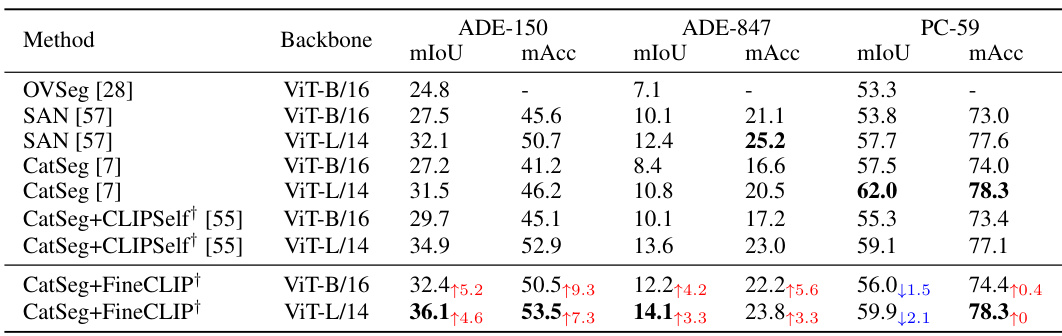
This table compares the performance of different methods on open-vocabulary semantic segmentation tasks using two different backbones (ViT-B/16 and ViT-L/14) and three different datasets (ADE-150, ADE-847, and PC-59). The metrics used are mean Intersection over Union (mIoU) and mean accuracy (mAcc). The † symbol indicates that the CLIP ViT backbone was initialized with a pre-trained model on the CC2.5M dataset. The table shows that FineCLIP consistently outperforms other methods, particularly with the ViT-L/14 backbone.
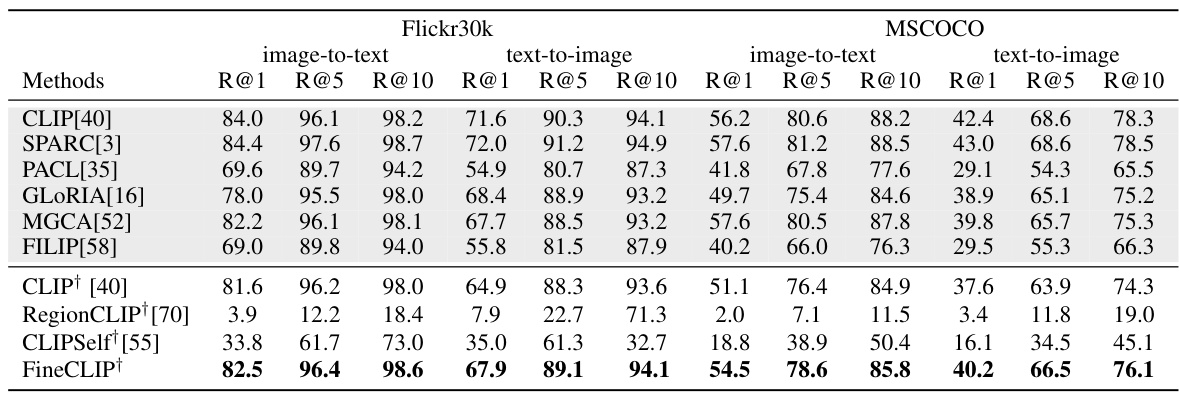
This table compares the performance of various methods on zero-shot image-text retrieval tasks using the Flickr30k and MSCOCO datasets. The results are presented in terms of Recall at different ranks (R@1, R@5, R@10). The table shows that FineCLIP achieves state-of-the-art performance, surpassing other methods including pre-trained models.

This table presents the results of an ablation study conducted to investigate the impact of different input image sizes on the performance of FineCLIP. Four different image resolutions (224, 320, 448, and 640) were used for training and inference. The table shows the Top1 and Top5 accuracy for box classification, and the I2T and T2I accuracy for retrieval tasks, for each image size. The results indicate how the image size affects FineCLIP’s performance on both classification and retrieval.

This table presents the ablation study on different ViT backbones used in FineCLIP. It shows the impact of using different ViT backbones (ViT-B/16 and ViT-L/14) on the performance of FineCLIP in terms of Top1 and Top5 accuracy for box classification and Image-to-Text (I2T) and Text-to-Image (T2I) retrieval tasks. The number of parameters for each backbone is also provided. The results demonstrate the effect of the different backbones on the model’s performance.

This table presents an ablation study focusing on the impact of the self-distillation loss (LSD) on FineCLIP’s performance under zero-shot conditions. It investigates how the addition of LSD affects the model across different training set sizes (100K, 500K, and 2.5M samples). The results are evaluated using metrics for both Box Classification (Top1 and Top5 accuracy) and Retrieval (I2T and T2I R@1 accuracy). The purpose is to understand if the self-distillation method enhances FineCLIP’s capacity for local detail understanding (and consequently, improved zero-shot performance) across varying scales of training data.

This table presents the zero-shot performance comparison of four different methods (CLIP, RegionCLIP, CLIPSelf, and FineCLIP) across three different scales of training datasets (100K, 500K, and 2.5M). The performance is evaluated on two tasks: box classification (Top1 and Top5 accuracy) and image-text retrieval (I2T and T2I Recall@1). The results demonstrate the impact of dataset scale on model performance and the relative strengths of each method in terms of fine-grained understanding (box classification) and global visual-semantic alignment (retrieval).

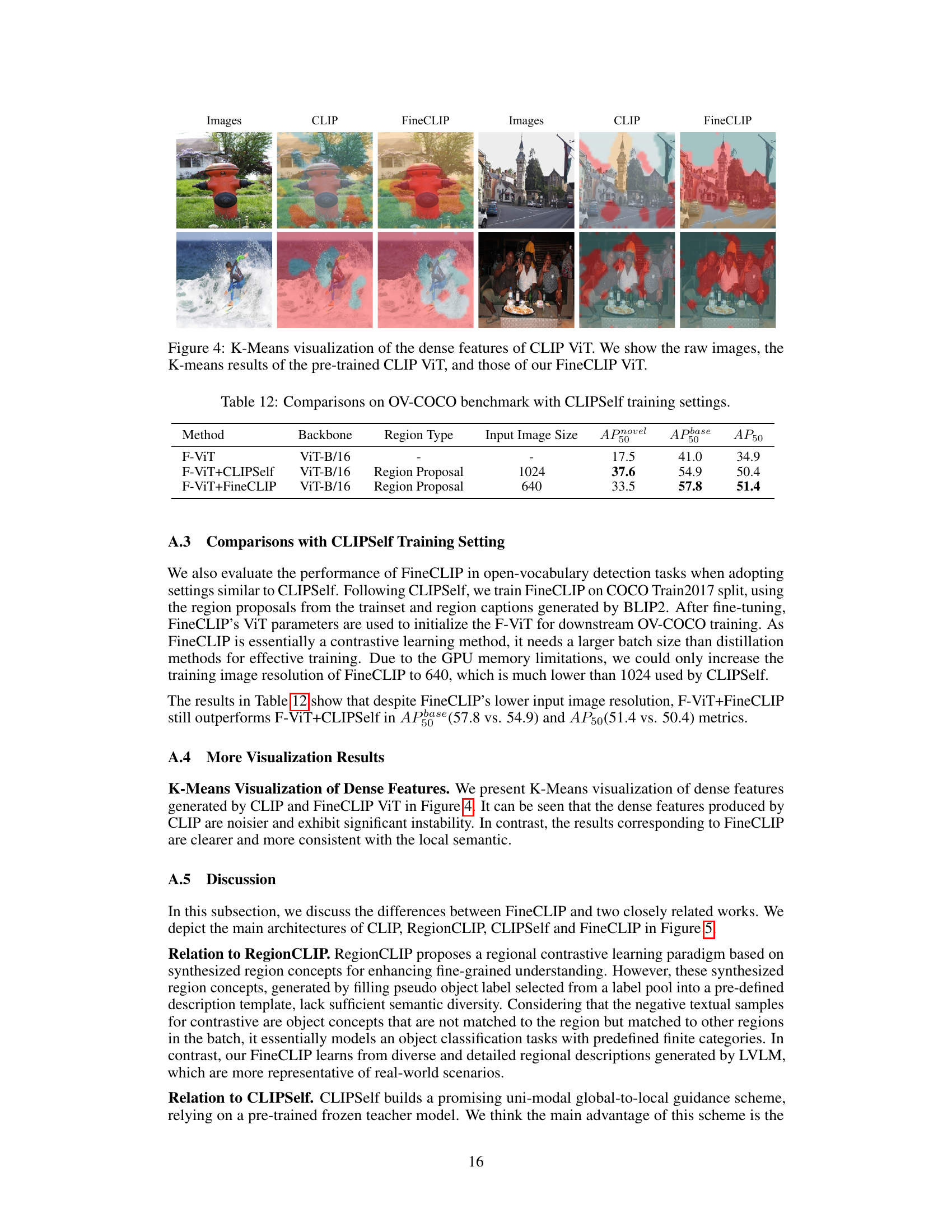
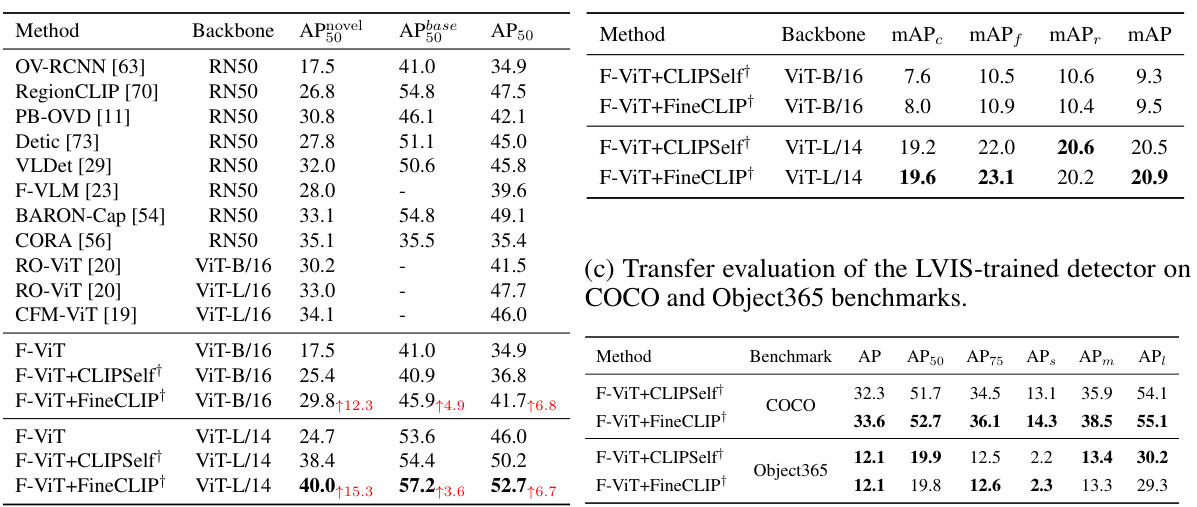
This table compares the performance of three different methods on the OV-COCO benchmark using CLIPSelf’s training settings. The methods are: F-ViT (a baseline), F-ViT+CLIPSelf (CLIPSelf model), and F-ViT+FineCLIP (the proposed FineCLIP model). The table shows the Average Precision (AP) at IoU threshold of 0.5 for novel and base categories (APnovel_50, APbase_50), along with the overall AP50. Different backbones (ViT-B/16), region types (Region Proposal), and input image sizes (1024 and 640) are used to compare the effectiveness of each model under the same training configuration as CLIPSelf. FineCLIP shows competitive performance.
Full paper#