TL;DR#
Current advanced diffusion models struggle with scalability issues due to numerical errors and reduced noisy prediction capabilities as network depth increases, hindering the development of truly deep models similar to large language models. This paper delves into the nature of effective generative denoising in neural networks, highlighting the consistent dynamic property of the intrinsic residual unit. It proposes a unified and massively scalable framework called Neural-RDM, incorporating learnable gated residual parameters that conform to generative dynamics.
Neural-RDM introduces a simple yet meaningful change by introducing a series of learnable gated residual parameters. The framework’s effectiveness stems from its ability to adaptively correct network propagation errors and approximate the mean and variance of the data. Rigorous theoretical proofs and extensive experiments demonstrate significant improvements in generated content fidelity, consistency, and large-scale training capabilities, achieving state-of-the-art results on image and video generative benchmarks. The introduction of continuous-time ODEs and adjoint sensitivity methods provide further theoretical insights into the model’s stability and scalability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in deep learning and computer vision due to its introduction of Neural-RDM, a novel framework enabling massively scalable training of diffusion models. It addresses a key limitation of current diffusion models, paving the way for developing more powerful generative models for images and videos, as demonstrated by its state-of-the-art performance on multiple benchmarks. The theoretical analysis and practical contributions of Neural-RDM make this paper highly influential for future research in deep generative models.
Visual Insights#
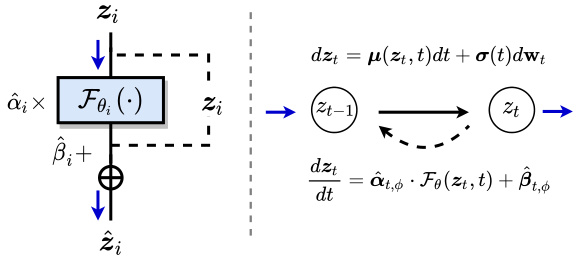
🔼 This figure shows the framework of Neural Residual Diffusion Models (Neural-RDM). It consists of two parts: (a) mrs-unit block and (b) Neural Residual Denoising Models. The mrs-unit block is a minimum residual stacking unit that uses a learnable gating residual mechanism to modulate the non-trivial transformation of the input signal. The Neural Residual Denoising Models framework combines multiple mrs-unit blocks to build a deep generative model. The framework aims to unify mainstream residual-style generative architectures and guide the emergence of brand new scalable network architectures.
read the caption
Figure 1: Neural Residual-style Diffusion Models framework with massively scalable gating-based minimum residual stacking unit (mrs-unit).
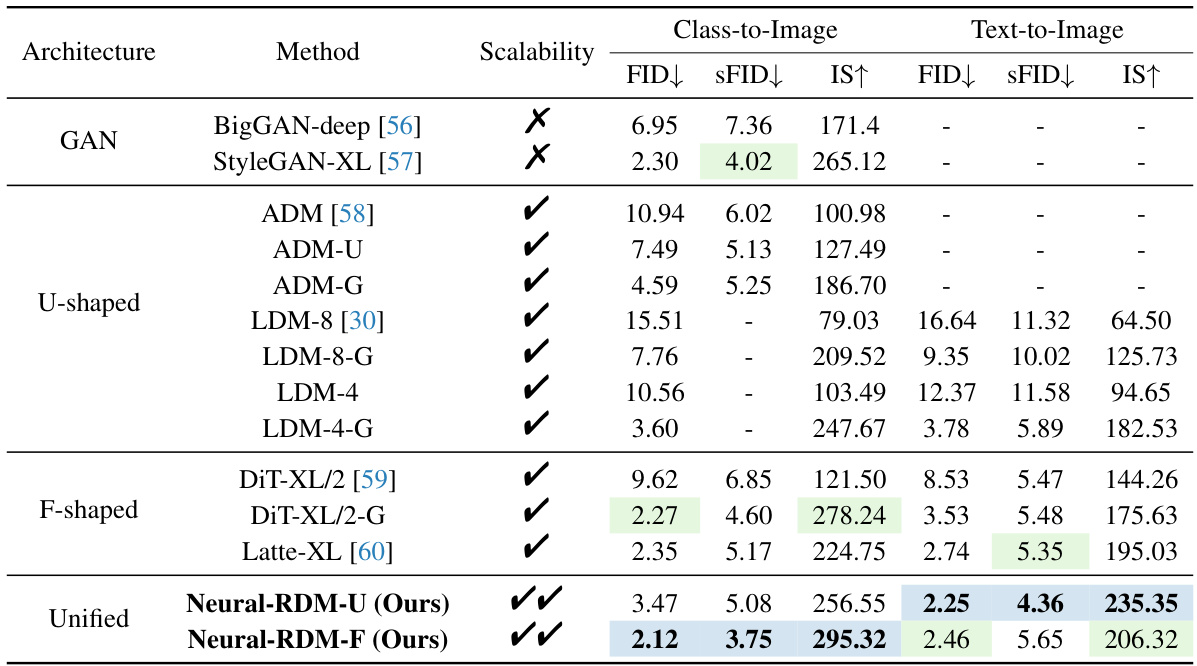
🔼 This table presents the main results of image generation experiments on two datasets, ImageNet and JourneyDB, using various methods and architectures. The FID, sFID, and IS scores are used to evaluate the quality of generated images. The ‘Scalability’ column indicates whether the method and architecture used in each experiment support scalable training.
read the caption
Table 1: The main results for image generation on ImageNet [61] (Class-to-Image) and JourneyDB [53] (Text-to-Image) with 256 × 256 image resolution. We highlight the best value in blue, and the second-best value in green. The Scalability column indicates the scaling capability of the parameter scale and architecture.
In-depth insights#
Diffusion Model Scaling#
Scaling diffusion models effectively presents a unique challenge. While increasing model size often boosts performance, it also introduces issues like numerical instability and increased computational costs. Strategies to overcome these limitations include architectural modifications, such as using residual connections or employing efficient attention mechanisms. Careful parameterization of the diffusion process, including the variance schedule and the model’s capacity to denoise at different noise levels, is critical. Moreover, training techniques need to be adapted to handle very large models, perhaps through techniques like gradient accumulation or model parallelism. Finally, evaluating the effectiveness of scaling strategies requires robust metrics that capture both quantitative improvements in sample quality and qualitative aspects like diversity and coherence. The trade-off between model size, computational resources, and generative capabilities needs to be carefully considered when designing and implementing diffusion model scaling strategies.
Gated Residuals#
The concept of “Gated Residuals” introduces a novel mechanism for enhancing deep neural networks, particularly within the context of diffusion models. Gating allows for adaptive control over the flow of information through residual connections, modulating the contribution of each residual unit. This dynamic adjustment is crucial for managing the challenges of numerical instability and error propagation commonly encountered in extremely deep architectures. Learnable gating parameters allow the network to selectively emphasize or suppress residual signals, optimizing information flow and mitigating vanishing/exploding gradients. This mechanism significantly improves the fidelity and consistency of generated content, enabling large-scale training of deep diffusion models with substantially improved results. The approach is theoretically grounded and shows remarkable effectiveness across various vision generation tasks. By addressing deep network challenges inherent in diffusion models, gated residuals promote greater scalability and enhanced performance.
Deep Scalability#
The concept of “Deep Scalability” in the context of neural networks, especially within diffusion models, centers on the ability to train increasingly deep models without encountering issues like vanishing gradients or exploding variances that hinder performance and stability. The paper likely explores techniques to mitigate these challenges inherent in stacking numerous network layers. This might involve innovative residual connections, novel normalization methods, or specialized training strategies such as adaptive learning rate scheduling or careful initialization schemes. Achieving deep scalability is crucial for unlocking the full potential of diffusion models, allowing them to learn more complex representations and generate higher-quality results. The core idea is to design architectures and training methodologies that maintain consistent information flow and stability, even as model depth dramatically increases. This often requires a deep understanding of the underlying dynamics and theoretical properties of the neural network architecture.
Theoretical Analysis#
A theoretical analysis section in a research paper would typically delve into the mathematical underpinnings and logical framework supporting the proposed model or method. It would likely involve rigorous proofs and derivations to validate claims and establish the soundness of the approach. For example, in a paper on a novel machine learning algorithm, this section might demonstrate convergence properties, bound generalization error, or analyze computational complexity. Key assumptions underlying the theoretical results should be clearly stated, acknowledging potential limitations. Furthermore, the analysis should connect the theoretical findings to the practical implications, bridging the gap between abstract concepts and concrete applications. The level of mathematical sophistication will vary depending on the field of research, but the emphasis should always be on clarity, rigor, and relevance to the overall goals of the paper. A strong theoretical analysis strengthens the credibility of the research and provides a deeper understanding of the underlying mechanisms.
Future Directions#
Future research could explore deeper investigations into the dynamic interplay between residual units and the reverse diffusion process, potentially leading to more sophisticated architectural designs. Exploring alternative gating mechanisms beyond the simple learnable parameters proposed in the paper could unlock further improvements in stability and scalability. Addressing the limitations related to sensitivity decay and numerical errors in very deep networks remains a crucial challenge, demanding innovative solutions that either circumvent these issues entirely or effectively manage them. Finally, extending the Neural-RDM framework to handle more complex data modalities and tasks, such as high-resolution 3D vision generation or other generative AI domains, holds significant potential.
More visual insights#
More on figures

🔼 This figure illustrates the three different residual stacking network architectures. (a) shows the flow-shaped residual stacking, which is a linear chain of residual units, where each unit takes the output of the previous unit as input. (b) shows the U-shaped residual stacking, which is a more complex architecture that uses skip connections to connect the earlier layers to the later layers. (c) shows the proposed Neural-RDM architecture, which combines the features of both flow-shaped and U-shaped residual stacking to achieve a more unified and massively scalable architecture. (d) shows how Neural-RDM processes the residual denoising.
read the caption
Figure 2: Overview. (a) Flow-shaped residual stacking networks. (b) U-shaped residual stacking networks. (c) Our proposed unified and massively scalable residual stacking architecture (i.e., Neural-RDM) with learnable gating-residual mechanism. (d) Residual denoising process via Neural-RDM.

🔼 This figure compares image generation results between the state-of-the-art model SDXL-1.0 and the proposed Neural-RDM. Neural-RDM shows improved fidelity and consistency in generated images, especially in terms of detail and adherence to text prompts. Six examples of image generation are shown for both models, demonstrating Neural-RDM’s superiority.
read the caption
Figure 3: Compared with the latest baseline (SDXL-1.0 [7]), the samples produced by Neural-RDM (trained on JourneyDB [53]) exhibit exceptional quality, particularly in terms of fidelity and consistency in the details of the subjects in adhering to the provided textual prompts.

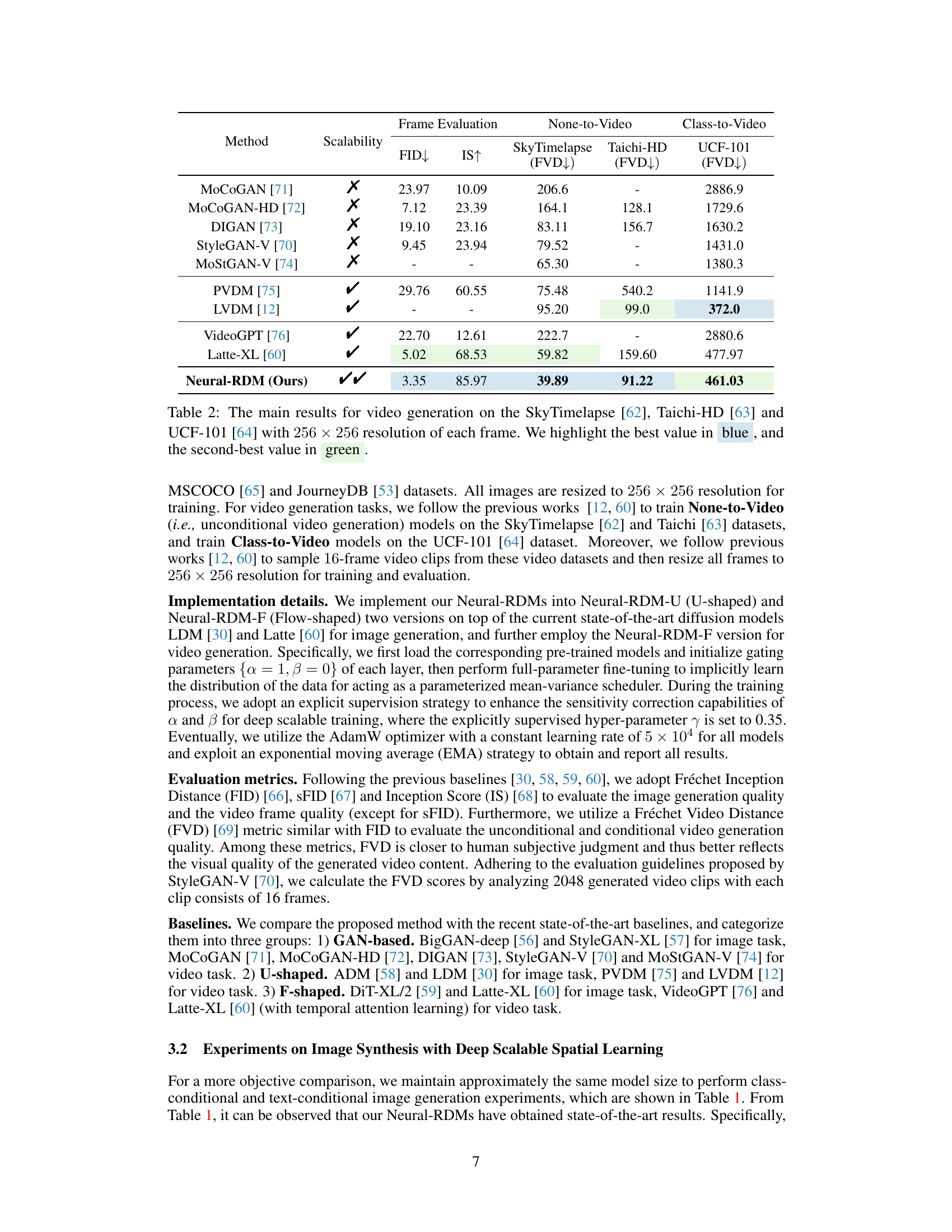
🔼 This figure compares video generation results from the proposed Neural-RDM model against the Latte-XL baseline model on three different datasets: SkyTimelapse, Taichi-HD, and UCF101. Each row shows a sequence of frames generated from a single video. The comparison highlights the superior frame quality, temporal consistency (smooth transitions between frames), and coherence (meaningful progression of events) achieved by the Neural-RDM model.
read the caption
Figure 4: Compared with the latest baseline (Latte-XL [60]), the sample videos from SkyTime-lapse [62], Taichi-HD[63] and UCF101 [64] all exhibit better frame quality, temporal consistency and coherence.
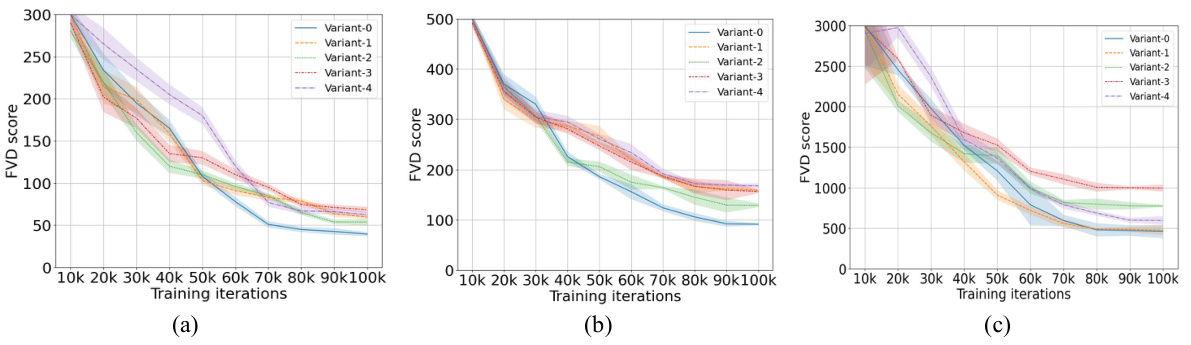
🔼 This figure displays the training curves for five different variants of residual structures in the Neural-RDM model. The performance is measured by FVD score (Fréchet Video Distance) across three different video datasets: SkyTimelapse, Taichi-HD, and UCF-101. Each curve represents a variant, showing how the FVD score changes over training iterations (10k-100k). The shaded regions around each line likely indicate confidence intervals, showing the variability in results for each variant.
read the caption
Figure 6: (a), (b), and (c) respectively illustrate the performance of the five residual structures variant models across the SkyTimelapsee [62], Taichi-HD[63], and UCF-101 [64].
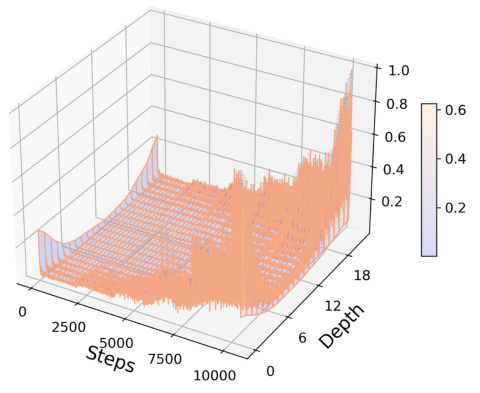
🔼 This figure shows the performance comparison of five different residual structure variants of the proposed Neural-RDM model on three video datasets: SkyTimelapse, Taichi-HD, and UCF-101. Each subfigure (a, b, c) represents a different dataset. The x-axis represents the number of training iterations, the y-axis represents the FVD score, and the z-axis represents the depth of the residual network. Different colored lines depict the performance of different residual structure variants. The figure aims to demonstrate the impact of different residual structures on training stability and final model performance across different video datasets.
read the caption
Figure 6: (a), (b), and (c) respectively illustrate the performance of the five residual structures variant models across the SkyTimelapsee [62], Taichi-HD[63], and UCF-101 [64].
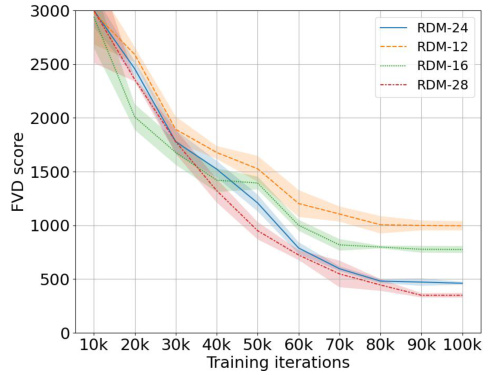
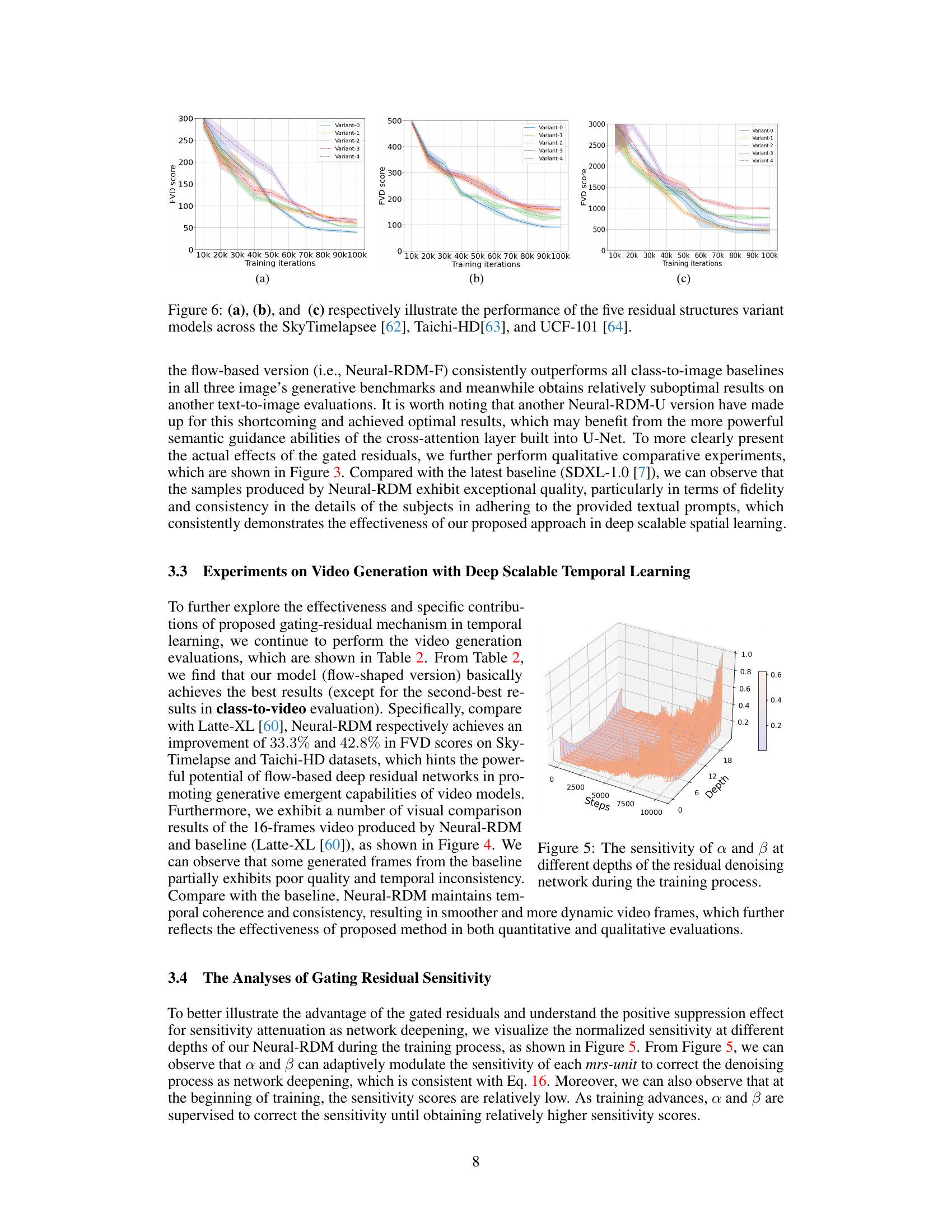
🔼 This figure shows the performance of Neural-RDM models with varying depths (number of residual units) on the UCF-101 video dataset. The x-axis represents the number of training iterations, and the y-axis represents the Fréchet Video Distance (FVD) score, a metric used to evaluate the quality of generated videos. Lower FVD scores indicate better video generation quality. The different colored lines represent Neural-RDM models trained with different depths. The shaded areas represent confidence intervals. The results demonstrate the effect of network depth on the model’s performance in terms of video generation quality.
read the caption
Figure 7: The performance of Neural-RDM with different network depths on the UCF-101 dataset [64].
🔼 This figure illustrates three different residual stacking network architectures: flow-shaped, U-shaped, and the proposed Neural-RDM. It highlights the key difference of Neural-RDM which introduces a learnable gating-residual mechanism. The figure also shows the process of residual denoising using Neural-RDM.
read the caption
Figure 2: Overview. (a) Flow-shaped residual stacking networks. (b) U-shaped residual stacking networks. (c) Our proposed unified and massively scalable residual stacking architecture (i.e., Neural-RDM) with learnable gating-residual mechanism. (d) Residual denoising process via Neural-RDM.
Full paper#